
目录
DeepCTR 和 DeepMatch是知乎浅梦大神以及其他大佬开发的针对推荐系统排序召回算法训练推理的一套框架, 支持embedding matrix模块和类似tf estimator 的feature column, 并继承大量排序, 召回已有模型, 能够帮助学生和从业者很快搭建一套推荐算法架构。
可以通过pip install deepctr, pip install deepmatch安装包, 也可以去https://github.com/shenweichen/DeepCTR 下载源码放进自己项目里。
1. DeepCTR: 易用可扩展的深度学习点击率预测算法包
这个项目主要是对目前的一些基于深度学习的点击率预测算法进行了实现, 如PNN,WDL,DeepFM,MLR,DeepCross,AFM,NFM,DIN,DIEN,xDeepFM,AutoInt等,并且对外提供了一致的调用接口。 关于每种算法的介绍这里就不细说了, 大家可以看论文, 看知乎, 看博客, 讲的都很清楚。
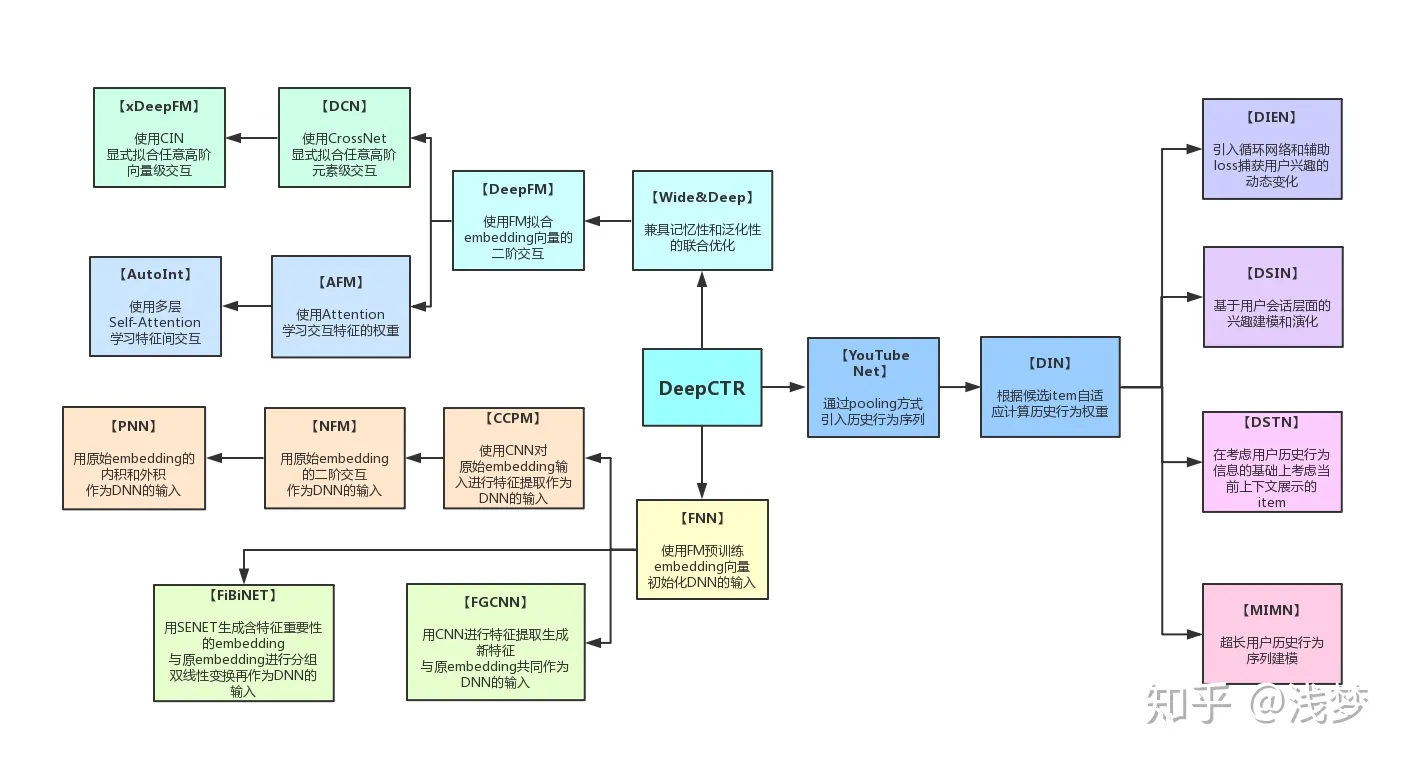
DeepCTR的设计主要是面向那些对深度学习以及CTR预测算法感兴趣的同学, 使他们可以利用这个包:
- 从一个统一视角来看待各个模型
- 快速地进行简单的对比实验
- 利用已有的组件快速构建新的模型
1.1 feature_column
DeepCTR 有自己独特的feature_column结构体, 比如SparseFeat, VarLenSparseFeat, DenseFeat, 先构建这种feature_column, 然后插入到模型中, 在输入的时候输入类似libsvm的格式(abc:1, def:2,ghi:3) , 其中libsvm 数据的key要和feature_column的key一致(数据变成libsvm 名字和feature_column名字对齐)。
DeepCTR中feature_column 用于构造特征列和处理输入,进行一定的数据处理, 关键是是模型中构建embedding matrix的基础。
feature_column大致可以分为三种: 类别特征、数值特征和序列特征, 因此feature_column.py中的类SparseFeat、DenseFeat、VarLenSparseFeat就是用来处理这三种特征的。只需要将原始特征转化为这三种特征列, 之后就可以得到通用的特征输入, 从而可调用models中的任意模型开始训练。

- SparseFeat: SparseFeat用于处理类别特征, 如性别、国籍等类别特征, 将类别特征转为固定维度的稠密特征。
- DenseFeat: 将稠密特征转为向量的形式, 并使用transform_fn 函数对其做归一化操作或者其它的线性或非线性变换。
- VarLenSparseFeat: 处理类似文本序列的可变长度类型特征。
1.2 输入模块
SparseFeat和VarLenSparseFeat对象需要创建嵌入矩阵, 嵌入矩阵的构造和查表等操作都是通过inputs.py模块实现的, 该模块包含9个方法, 每个方法的具体功能如下图所示:
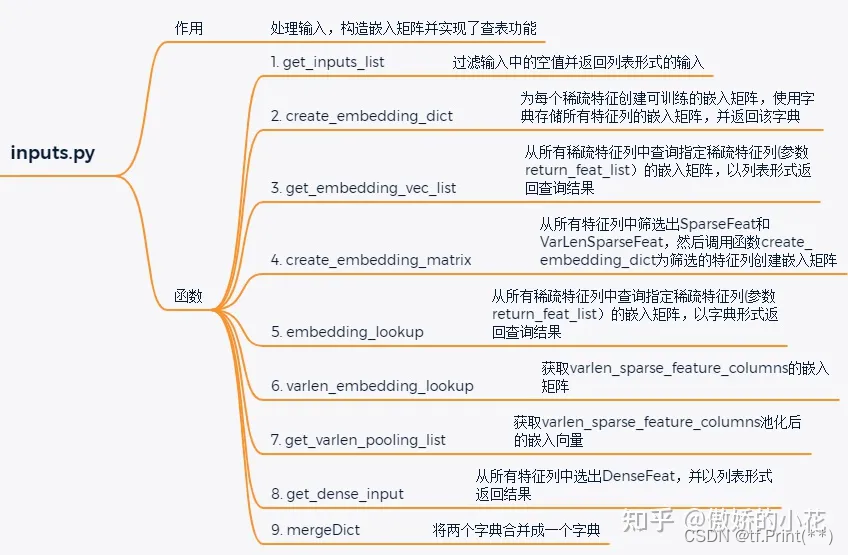
embedding_lookup 在嵌入层方法input_from_feature_columns中调用
1.3 用DeepFM模型在criteo数据集上训练的的例子
import pandas as pd
from sklearn.metrics import log_loss, roc_auc_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, MinMaxScaler
from deepctr.models import DeepFM
from deepctr.feature_column import SparseFeat, DenseFeat, get_feature_names
if __name__ == "__main__":
data = pd.read_csv('./criteo_sample.txt')
sparse_features = ['C' + str(i) for i in range(1, 27)]
dense_features = ['I' + str(i) for i in range(1, 14)]
data[sparse_features] = data[sparse_features].fillna('-1', )
data[dense_features] = data[dense_features].fillna(0, )
target = ['label']
# 1.Label Encoding for sparse features,and do simple Transformation for dense features
for feat in sparse_features:
lbe = LabelEncoder()
data[feat] = lbe.fit_transform(data[feat])
mms = MinMaxScaler(feature_range=(0, 1))
data[dense_features] = mms.fit_transform(data[dense_features])
# 2.count #unique features for each sparse field,and record dense feature field name
fixlen_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(),embedding_dim=4 )
for i,feat in enumerate(sparse_features)] + [DenseFeat(feat, 1,)
for feat in dense_features]
dnn_feature_columns = fixlen_feature_columns
linear_feature_columns = fixlen_feature_columns
feature_names = get_feature_names(linear_feature_columns + dnn_feature_columns)
# 3.generate input data for model
train, test = train_test_split(data, test_size=0.2, random_state=2018)
train_model_input = {name:train[name] for name in feature_names}
test_model_input = {name:test[name] for name in feature_names}
# 4.Define Model,train,predict and evaluate
model = DeepFM(linear_feature_columns, dnn_feature_columns, task='binary')
model.compile("adam", "binary_crossentropy",
metrics=['binary_crossentropy'], )
history = model.fit(train_model_input, train[target].values,
batch_size=256, epochs=10, verbose=2, validation_split=0.2, )
pred_ans = model.predict(test_model_input, batch_size=256)
print("test LogLoss", round(log_loss(test[target].values, pred_ans), 4))
print("test AUC", round(roc_auc_score(test[target].values, pred_ans), 4))
2. DeepMatch: 用于推荐&广告的深度召回匹配算法库
DeepMatch, 提供了若干主流的深度召回匹配算法的实现, 并支持快速导出用户和物品向量进行ANN检索。非常适合同学们进行快速实验和学习, 解放算法工程师的双手!
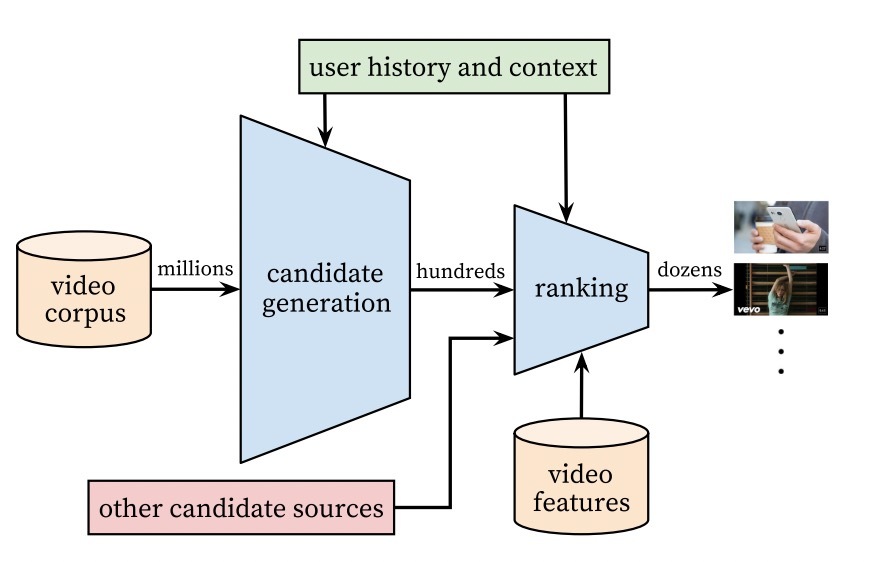
截止到2021-10-02, deepmatch只支持tf到1.x版本, tf-2.0.0及以上版本暂时不支持deepmatch, 且deepmatch依赖于deepctr的0.8.2版本。
2.1 什么是faiss
faiss是为稠密向量提供高效相似度搜索和聚类的框架。由Facebook AI Research研发。 具有以下特性。
- 提供多种检索方法
- 速度快
- 可存在内存和磁盘中
- C++实现, 提供Python封装调用
- 大部分算法支持GPU实现
参考:
https://github.com/shenweichen/DeepCTR
https://github.com/shenweichen/DeepMatch
https://zhuanlan.zhihu.com/p/53231955
https://zhuanlan.zhihu.com/p/126282487
