
目录
向量数据库是一种用于存储、索引和检索具有多个维度的数据点的数据库, 通常称为向量。与处理表中组织的数据(如数字和字符串)的数据库不同, 向量数据库是专门为管理多维向量空间中表示的数据而设计的。
与以结构化方式存储数据的传统关系数据库或非关系数据库不同, 向量数据库包含使用嵌入或转换函数构造的单个数据项的数学表示, 称为向量。向量通常表示特征或语义含义, 可以是短的, 也可以是长的。向量数据库使用距离度量(其中更接近意味着结果更相似)通过相似性搜索进行向量检索, 例如欧几里得、点积或余弦相似度。
为了加快检索过程, 使用索引机制组织矢量数据。这些组织方法的示例包括平面结构、倒置文件 (IVF)、分层可导航小世界 (HNSW) 和局部敏感哈希 (LSH) 等。这些方法中的每一种都有助于在需要时检索相似载体的效率和有效性。
矢量数据库的基础在于数据索引。通过倒排索引等技术, 向量数据库可以通过对向量特征进行分组和索引来有效地进行相似性搜索。此外, 矢量量化技术有助于将高维向量映射到低维空间, 从而减少存储和计算要求。通过利用索引技术, 向量数据库可以使用向量添加、相似性计算和聚类分析等各种作来高效搜索向量。
1. Embedding
Embedding 的基本内容大概就是这么多啦, 然而小普想说的是它的价值并不仅仅在于 word embedding 或者 entity embedding 再或者是多模态问答中涉及的 image embedding, 而是这种能将某类数据随心所欲的操控且可自学习的思想。
通过这种方式, 我们可以将神经网络、深度学习用于更广泛的领域, Embedding 可以表示更多的东西, 而这其中的关键在于要想清楚我们需要解决的问题和应用 Embedding 表示我们期望的内容。
语义理解中Embedding意义
理解了它是沟通两个世界的桥梁后, 我们再看个例子, 它是如何运用在文本数据中的?
如下图所示, 我们可以通过将两个无法比较的文字映射成向量, 接下来就能实现对他们的计算。
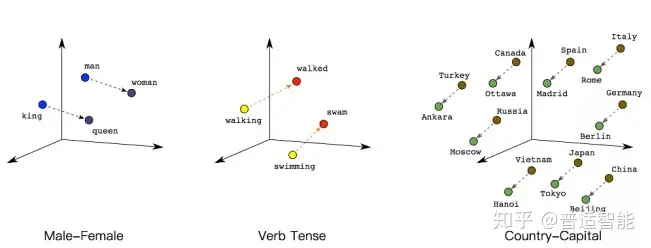
例如:
queen(皇后)= king(国王)- man(男人)+ woman(女人)
这样计算机能明白, “皇后啊, 就是女性的国王呗!”
walked(过去式)= walking(进行时)- swimming(进行时)+ swam(过去式)
同理计算机也能明白, “walked, 就是walking的过去式啦!“另外, 向量间的距离也可能会建立联系, 比方说"北京"是"中国"的首都, “巴黎"是"法国"的首都, 那么向量:|中国|-|北京|=|法国|-|巴黎|
2. Vector Database
对向量进行存储和索引, 以便快速检索。向量数据库有两种主要类型, 一种是已扩展为存储向量的传统数据库, 另一种是专门构建的向量数据库。提供向量支持的传统数据库的一些示例包括 Redis、pgvector、Elasticsearch 和 OpenSearch。专用矢量数据库的示例包括专有解决方案 Zilliz 和 Pinecone, 以及开源项目 Milvus、Weaviate、Qdrant、Faiss 和 Chroma。
开源向量搜索索引:
- faiss
- nmslib

2.1 Pinecone
Pinecone 是一个托管矢量数据库, 旨在实现速度、规模和快速部署到生产环境。它支持混合搜索, 是目前唯一原生支持 SPLADE 稀疏矢量的数据存储。
import pinecone
import os
# init connection to pinecone
os.environ['PINECONE_API_KEY'] = '<PINECONE_API_KEY>'
pinecone.init(
api_key=os.environ['PINECONE_API_KEY'], # app.pinecone.io
environment='us-east4-gcp' # find next to api key
)
print(pinecone.list_indexes())
2.2 Weaviate
Weaviate是一个开源矢量搜索引擎, 旨在无缝扩展到数十亿个数据对象。它支持开箱即用的混合搜索, 使其适合需要高效关键字搜索的用户。Weaviate 可以自托管或管理, 提供部署灵活性。
pip install weaviate-client llama-index-vector-stores-weaviate
docker run -p 8080:8080 -p 50051:50051 cr.weaviate.io/semitechnologies/weaviate:1.24.1
2.3 Zilliz
Zilliz 是一个托管的云原生矢量数据库, 专为数十亿级数据而设计。它提供了广泛的功能, 包括多种索引算法、距离指标、标量过滤、时间旅行搜索、带快照的回滚、完整的 RBAC、99.9% 的正常运行时间、分离的存储和计算以及多语言 SDK。
2.4 Milvus
Milvus 是一个开源的云原生向量数据库, 可扩展到数十亿个向量。它是 Zilliz 的开源版本, 并共享其许多功能, 例如各种索引算法、距离指标、标量过滤、时间旅行搜索、快照回滚、多语言 SDK、存储和计算分离以及云可扩展性。Milvus 混合搜索检索器, 它结合了密集向量搜索和稀疏向量搜索的优势。
Milvus 和 Weaviate 都有 GitHub 项目。
# required
lscpu | grep -e sse4_2 -e avx -e avx2 -e avx512
grep CONFIG_SECCOMP= /boot/config-$(uname -r)
wget https://github.com/milvus-io/milvus/releases/download/v2.5.5/milvus-standalone-docker-compose.yml -O docker-compose.yml
sudo docker compose up -d
# 取消 Seccomp 的限制, 使容器内的进程可以访问所有系统调用, 允许容器中运行一些特权命令
# 部分机器上, --security-opt=seccomp:unconfined 会导致无法启动, 可以移除掉
# Milvus WebUI, 网址是http://127.0.0.1:9091/webui/
# By default, the root user is created with the password Milvus
from pymilvus import MilvusClient
client = MilvusClient(
uri='http://10.201.195.138:19530', # replace with your own Milvus server address
# token="root:<Your Password>"
)
client.update_password(
user_name="root",
old_password="Milvus",
new_password="<Your Password>"
)
2.5 Qdrant
Qdrant 是一个能够存储文档和向量嵌入的向量数据库。它提供自托管和托管的Qdrant Cloud部署选项, 为具有不同需求的用户提供了灵活性。
- Qdrant
- Qdrant is licensed under the Apache License, Version 2.0.
Qdrant(read: quadrant)是一个向量相似性搜索引擎和向量数据库。它提供生产就绪服务, 并提供方便的 API 来存储、搜索和管理具有额外有效载荷的点 - 矢量。Qdrant 专为扩展过滤支持量身定制。它使其可用于各种神经网络或基于语义的匹配、分面搜索和其他应用程序。
# mkdir -p /data/qdrant/storage /qdrant/snapshots
docker run -p 6333:6333 -d --restart=always \
-v /data/qdrant/storage:/qdrant/storage \
qdrant/qdrant
-v /data/qdrant/custom_config.yaml:/qdrant/config/production.yaml \
qdrant/qdrant
pip install qdrant-client
from qdrant_client import QdrantClient
client = QdrantClient(":memory:") # Create in-memory Qdrant instance, for
client = QdrantClient(path="path/to/db") # Persists changes to disk, fast prototyping
client = QdrantClient("http://localhost:6333") # Connect to existing Qdrant instance, for production
vector_config = {
"plot_embedding": VectorParams(
distance=Distance.COSINE,
size=len(df["embedding"][0])
)
}
client.recreate_collection(
collection_name="mongoDB_embedded_movies_collection",
vectors_config=vector_config,
# This is to enable parallelism, between 2-4 is okay
shard_number=2,
)
2.5.1 多租户
多租户是指一种软件体系结构模型, 它允许软件或软件应用程序的单个实例为多个租户或客户组织提供服务。每个租户的数据只有他/她才能看到, 尽管必须驻留在同一个基础设施上。
response = client.search(
collection_name="mongoDB_embedded_movies_collection",
query_filter=models.Filter(
must=[
models.FieldCondition(
key="dataset",
match=models.MatchValue(
value="mongoDB_embedded_movies_2",
),
)
]
),
query_vector= ("plot_embedding", query_vector, ),
limit=10,
)
2.6 Redis
RediSearch: Redis Plus
Redis 是一个实时数据平台, 适用于各种用例, 包括日常应用程序和 AI/ML 工作负载。通过使用 Redis Stack docker 容器创建 Redis 数据库, 它可以用作低延迟矢量引擎。对于托管/托管解决方案, 可以使用 Redis 云。
docker run -d -p 6379:6379 --restart=always --name rec_redis \
-v /code/redis/new:/data redislabs/redisearch:latest
import redis
from redis.commands.search.indexDefinition import (
IndexDefinition,
IndexType
)
REDIS_HOST = "<HOST>"
REDIS_PORT = 6379
REDIS_PASSWORD = "" # default for passwordless Redis
# Connect to Redis
redis_client = redis.Redis(
host=REDIS_HOST,
port=REDIS_PORT,
password=REDIS_PASSWORD,
)
# Check if index exists
INDEX_NAME = "index-of-product-text2vec"
PREFIX = "product"
try:
redis_client.ft(INDEX_NAME).info()
print("Index already exists")
except:
# Create RediSearch Index
redis_client.ft(INDEX_NAME).create_index(
fields = fields,
definition = IndexDefinition(prefix=[PREFIX], index_type=IndexType.HASH)
)
2.7 LlamaIndex
LlamaIndex是将LLM与外部数据连接的中央接口。它为您的非结构化和结构化数据提供了一套内存中索引, 以便与 ChatGPT 一起使用。与标准矢量数据库不同, LlamaIndex支持针对不同用例优化的各种索引策略(例如树, 关键字表, 知识图谱)。它重量轻, 易于使用, 不需要额外部署。您需要做的就是指定一些环境变量(可选地指向现有的已保存索引 json 文件)。请注意, 尚不支持查询中的元数据筛选器。
2.8 Chroma
Chroma是一个AI原生开源嵌入数据库, 旨在使入门尽可能简单。Chroma在内存中运行, 或在客户端-服务器设置中运行。它支持开箱即用的元数据和关键字过滤。
- 用途: 向量数据库是用于存储向量的通用系统,而 ChromaDB 是专门为 AI 应用程序量身定制的,使其更易于在 ML 工作流程中使用。
- 重点: ChromaDB 针对简单性和与 AI 模型的集成进行了优化,而其他矢量数据库可能会在更通用的场景中优先考虑规模或性能。
pip install chromadb
2.9 Azure Cognitive Search
Azure 认知搜索是一项完整的检索云服务, 支持矢量搜索、文本搜索和混合(将矢量 + 文本组合在一起, 以产生两种方法中的最佳效果)。它还提供可选的 L2 重新排名步骤, 以进一步提高结果质量。
2.10 Other
2.10.1 Supabase
Supabase提供了一种简单有效的方法来通过Postgres数据库的pgvector扩展来存储向量。您可以使用Supabase CLI在本地或云中设置整个Supabase堆栈, 也可以使用docker-compose, k8s和其他可用的选项。对于托管/托管解决方案, 请尝试 Supabase.com 并通过内置身份验证、存储、自动 API 和实时功能解锁 Postgres 的全部功能。
2.10.2 Postgres
Postgres提供了一种通过pgvector扩展存储向量的简单有效的方法。要使用 pgvector, 您需要设置一个启用了 pgvector 扩展的 PostgreSQL 数据库。例如, 您可以使用 docker 在本地运行。对于托管/托管解决方案, 您可以使用任何支持 pgvector 的云供应商
- pgvector 在可扩展性方面有局限性
2.10.3 SingleStoreDB
SingleStoreDB 采用了一种新颖的方法, 将向量数据与各种数据类型一起存储在关系表中。这种创新的合并使您能够毫不费力地访问与矢量数据相关的综合元数据和其他属性, 同时利用 SQL 的广泛查询能力。
2.10.4 sqlite-vec
sqlite-vec v0.1.0: 一个无处不在的向量搜索 SQLite 扩展。
一个完全用 C 编写的无依赖 SQLite 扩展, “在任何地方运行”(MacOS、Linux、Windows、浏览器中的 WASM、Raspberry Pis 等)。它适用于所有编程语言的所有 SQLite 环境。您可以在客户端之间使用相同的 SQL 来插入、更新和删除向量, 而 KNN 查询只是 SQL 语句。它的速度非常快(比 NumPy 和许多其他类似的向量搜索工具还要快), 但不是世界上最快的(Faiss、usearch 等)。
3. 评估
- 分度速度
- 查询延迟
- 查询吞吐量
- 索引容量
- 集群大小
3.1 性能指标
衡量矢量数据库性能的关键指标:
- 加载延迟: 衡量将数据加载到向量数据库的内存中并构建索引所需的时间。索引是一种数据结构, 用于根据矢量数据的相似性或距离有效地组织和检索矢量数据。内存中索引的类型包括平面索引、IVF_FLAT、IVF_PQ、HNSW、可缩放最近邻 (ScaNN) 和 DiskANN。
- 召回率: 是在搜索算法检索到的前 K 个结果中找到的真匹配项或相关项的比例。召回率值越高, 表示对相关项目的检索越好。
- 每秒查询数(QPS): 是向量数据库处理传入查询的速率。QPS值越高, 查询处理能力越好, 系统吞吐量越好。
3.2 基准测试框架
对矢量数据库进行基准测试需要矢量数据库服务器和客户端。
- VectorDBBench: VectorDBBench 由 Zilliz 开发和开源, 帮助测试具有不同索引类型的不同向量数据库, 并提供方便的 Web 界面。
- vector-db-benchmark: vector-db-benchmark 由 Qdrant 开发并开源, 有助于测试 HNSW 索引类型的几个典型向量数据库。它通过命令行运行测试, 并提供 Docker Compose 文件以简化启动服务器组件。
3.3 公共数据集
大型数据集是测试负载延迟和资源分配的良好候选者。部分数据集具有高维数据, 有利于测试计算相似度的速度。
- LAION 数据集是一个开放的图像集合, 已被用于训练非常大的视觉和语言深神经模型, 如稳定扩散生成模型。
- 为了测试加载延迟, 我们需要大量向量, deep-image-96-angular 提供了这些向量。
- 为了测试指数生成和相似性计算的性能, 高维向量提供了更多的压力。为此, 我们选择了 1536 个维度向量的 500K 数据集。
参考:
https://zhuanlan.zhihu.com/p/164502624
https://github.com/openai/chatgpt-retrieval-plugin
RAG Vs VectorDB
Introducing sqlite-vec v0.1.0: a vector search SQLite extension that runs everywhere
