
目录
大型语言模型是深度学习神经网络, 可以通过对大量文本进行训练来理解、处理和生成人类语言。LLM(Large Language Model) 可以归类为自然语言处理(NLP), 这是一个旨在理解、解释和生成自然语言的人工智能领域。
在训练过程中, LLM 被输入数据(数十亿字)以学习语言中的模式和关系。语言模型旨在根据之前的单词计算出下一个单词的可能性。该模型接收提示, 并使用在训练期间学习的概率(参数)来生成响应。
0.大模型
0.1 应用场景
- 文本生成
- 情绪分析
- 从非结构化数据中生成有价值的见解
- 内容创作
- 阅读理解、总结、分类
- 机器翻译
- 问答
0.2 大型语言模型是如何训练的?
ChatGPT 等大型语言模型使用称为监督学习的过程进行训练。在训练期间,
- 首先, 将大量文本输入及其相应的输出提供给模型, 以预测给定新输入的输出。
- 该模型使用优化算法来调整其参数, 以最小化其预测与实际输出之间的差异。
- 然后, 将训练数据小批量提供给模型。
- 该模型对每个批次进行预测, 并根据看到的误差更改其参数。
- 此过程重复多次, 使模型能够逐渐学习数据中的关系和模式。
1. LLM 的能力
1.1 Function calling
函数调用使开发人员能够描述函数(也称为工具, 您可以将其视为模型要执行的操作, 例如执行计算或下订单), 并让模型智能地选择输出包含参数的 JSON 对象来调用这些函数。Function call帮我们做了两件事情:
- 自主决策: 模型可以智能地选择工具来回答问题。
- 可靠的解析: 响应采用 JSON 格式, 而不是更典型的类似对话的响应。
函数调用是有效使用工具的关键技能, 但衡量函数调用性能的良好基准并不多。
函数调用允许您更可靠地从模型中获取结构化数据。例如, 您可以:
-
创建通过调用外部 API(例如 ChatGPT 插件)来回答问题的助手
- 例如, 定义像
send_email(to: string, body: string)或get_current_weather(location: string, unit: 'celsius' | 'fahrenheit')
- 例如, 定义像
-
将自然语言转换为 API 调用
- 例如, 将"Who are my top customers?“转换为
get_customers(min_revenue: int, created_before: string, limit: int)并调用您的内部API
- 例如, 将"Who are my top customers?“转换为
-
从文本中提取结构化数据
- 例如, 定义一个名为 的函数
extract_data(name: string, birthday: string)或者sql_query(query: string)
- 例如, 定义一个名为 的函数
-
gpt-4
-
gpt-4-1106-preview [parallel]
-
gpt-4-0613
-
gpt-3.5-turbo
-
gpt-3.5-turbo-1106 [parallel]
-
gpt-3.5-turbo-0613
Qwen-72B
一般的部署方式是不支持 Function Call功能的
参考: https://github.com/QwenLM/Qwen/issues/817
berkeley-function-calling-leaderboard
Benchmarking Agent Tool Use
benchmarking LLMs’ ability
1.2 LLM 类型
1.2.1 基本模型
基础模型在原始 Internet 文本上进行训练, 这意味着它们会生成补全, 但无法理解人类意图。
文本补全 - 即向模型提供未完成的文本, 它将尝试预测下一个单词。
基本模型几乎可以做任何事情。如果你给它一个看起来像聊天的提示, 它将继续聊天, 就好像它是一个聊天模型一样。如果你给它任务>执行的例子>任务>执行>任务, 它很可能会继续这种模式并执行你给它的任何任务。
示例一
例如, 如果你想知道法国的首都是什么, 你可以天真地问它: 法国的首都是哪里?
但是想想模型如何在数据集中遇到这样的问题……它可能会是这样的: 法国的首都是哪里? 这个看似简单的问题与更深层次的含义有许多相似之处<等等等等>
如果你真的想知道, 你可以尝试: 问: 法国的首都是哪里? 答: 或者: The capital of France is
示例二
如果你想让它编写代码: Write me a function in typescript that takes two numbers and multiplies them, 它可能会回复:
I need this for my assignment, and therefore it is critical that <blah blah blah>
模型不是幻觉, 而是在完成句子!相反, 请执行此操作
/**
* This function takes two numbers and multiplies them
* @param arg1 number
* @param arg2 number
* @returns number
*/
export function
在这一点上, 它将产生你想要的功能!
1.2.1 指令或聊天模型
如果你得到一个基本模型并教它遵循指令, 你就会得到一个"指示模型"或"指令调优模型”。您还可以教它以多轮方式响应, 这被称为"聊天模型"。
当然, 还有其他的, 比如"RP调优"、“分类器”、“主持人”、“填充”、“编码"等, 尽管在LLM的上下文中, 这些类别不是硬性规则, 而是更多地表明了训练它时的意图。
1.3 Reflection Agents
三种主要类型的reflection agents:
1.3.1 Basic Reflection Agents
顾名思义, 这是反射剂的最基本形式。在这个设置中, 我们有两个主要的 LLM 代理, 一个充当生成器, 另一个充当反射器, 批评生成器的响应并提出建设性的反馈。
reflection_prompt = ChatPromptTemplate.from_messages(
[
# this needs to be a tuple so do not forget the , at the end
(
"system",
"You are a senior researcher"
" Provide detailed recommendations, including requests for length, depth, style, etc."
" to an asistant researcher to help improve this researches",
),
MessagesPlaceholder(variable_name="messages"),
]
)
reflect = reflection_prompt | llm
reflection = ""
for chunk in reflect.stream({"messages": [request, HumanMessage(content=research)]}):
print(chunk.content, end="")
reflection += chunk.content
1.3.2 Reflexion Agents
1.3.3 Language Agent Tree Search (LATS)
1.4 参数
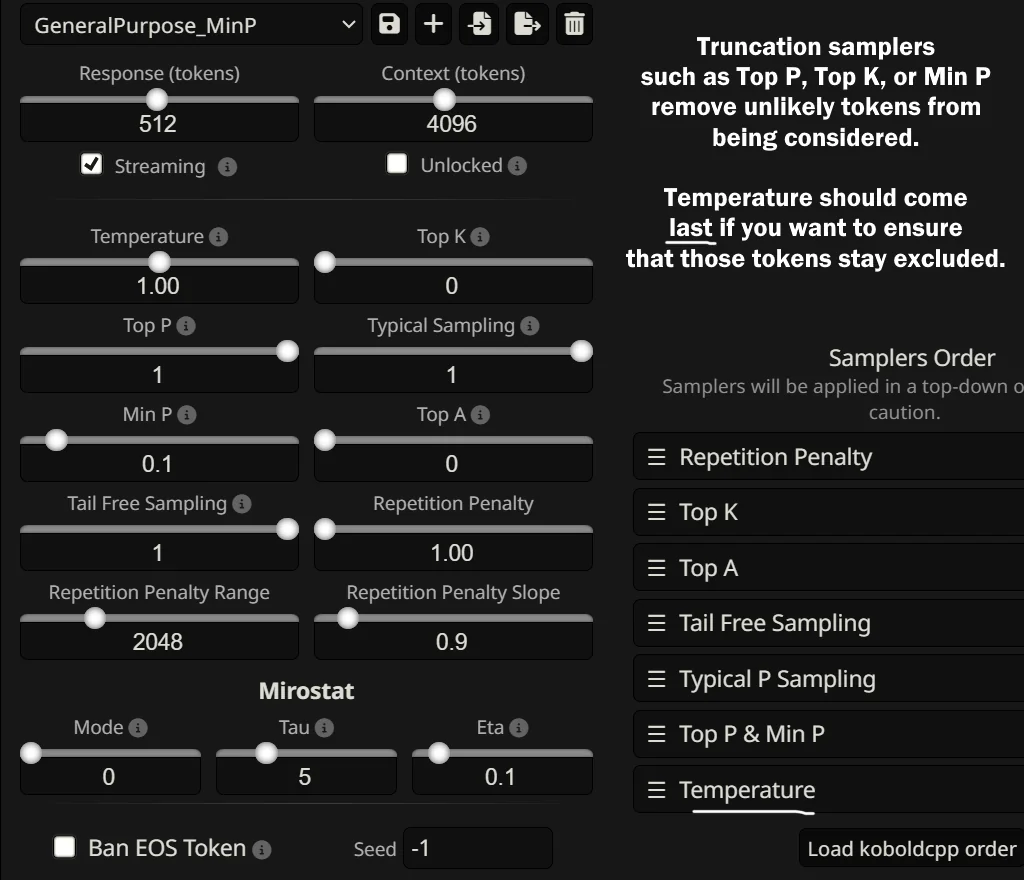
LLM 的核心是能够生成词汇表的每个标记成为下一个标记的概率列表。然后, 您选择的搜索机制会使用这些概率。
Temperature 改变了这些概率的生成方式, 而 Top-P 和 Top K 改变了我们可以考虑的概率。该考虑步骤可以使用"sampling”(因为我们根据该值在该子集中下一个的可能性从所有选项的子集中选择一个样本)或进行光束搜索。
采样有两种形式: Top K 和 Nucleus(或 Top-P)采样。
对比搜索, 利用了 Top K,被证明优于其他策略, 但速度较慢, 不适合许多需要性能的用例。
Beam Search, 它试图通过检查可能的选项来获得最佳完整响应, 从而找到最佳结果。
虽然对比搜索和光束搜索是从 LLM 获得良好结果的相关且强大的方法, 但它们速度较慢, 并且在响应时间不重要时使用。
1.4.1 Temperature
在传递给 softmax 之前, 所有概率都除以此值。因此, 它不能为零, 在 1 时分布不受影响, 而在无穷大时, 所有概率都相等(在 softmax 之前为 0)。
Temperature实际控制的是分数的缩放。因此, 0.5 温度并不是"两倍的置信度"。正如你所看到的, 在这种情况下, 0.75 温度实际上更接近于这种解释。
每次生成令牌时, 它都必须为词汇表中存在的所有令牌分配数千个分数(Llama 2 为 32,000 个), 而温度只是有助于减少(降低温度)或增加(较高温度)极低概率令牌的分数。
从数学角度来说, LLM 在计算下一个标记(称为"softmax"的函数)的概率之前所做的是将所有数字除以你的Temperature值。当模型正在训练时, 它实际上的Temperature为 1。此时使用Temperature没有任何意义, 因为训练需要完全按照计算概率的方式使用概率。但是, 一旦我们开始使用该模型, 我们可能希望更改Temperature来影响我们的结果。因为您是将数字除以您设置的Temperature值, 所以您可以理解为什么 Huggingface 不允许零 - 任何被0除以的东西都不是数字。Open AI 将0视为仅保留最高概率选项的简写。
温度最终可用于为 LLM 的输出增加多样性。
1.4.2 max_tokens
大型语言模型在单个请求中可以处理的最大令牌数称为上下文长度(或上下文窗口)。虽然上下文长度随着每次迭代和每个新模型而增加, 但我们能为模型提供的信息仍然存在限制。此外, 输入的大小与 LLM 生成的响应的上下文相关性之间存在负相关, 简短而集中的输入比包含大量信息的长上下文产生更好的结果。
虽然较长的上下文为模型提供了更全面的画面, 并帮助它理解关系并做出更好的推理, 但另一方面, 较短的上下文减少了模型需要理解的数据量, 从而减少了延迟, 使模型更具响应性。它还有助于最大限度地减少 LLM 的幻觉, 因为仅向模型提供相关数据。因此, 这是性能、效率和数据复杂程度之间的平衡, 我们需要运行实验, 确定多少数据是用合理资源产生最佳结果的合适数据量。
限制响应中生成的标记数。除了在系统消息中指定以保持答案简短之外, 我还可以使用此属性控制答案的长度。将max_tokens设置得太低可能会导致响应不完整或突然, 这可能没有用处或信息量。
1.4.3 Top-K
Top K 允许我们限制采样时考虑的选项数量。在应用Temperature并通过称为 softmax 的公式计算我们的概率后, 我们可能有数千个标记(或单词)可供选择。
在做一些更线性的事情, 通过只考虑尽可能多的代币在最高指定值中, 因此前 K = 5 只有前 5 个代币始终被考虑。如果您不进行调试, 我建议完全关闭它。
top_k = 1 would disable randomness and is what you’d likely actually get if your software supports settingtemperatureto 0
指定前 K 名为 50 名, 表示"只看最好的 50 个衍生物"。这可能用于消除低质量选项, 因此我们不会考虑它们。但是, 一般来说, Top K 并不是一个非常有用的参数。更改温度或更改 Top-P是一个更可靠和可解释的选项。
1.4.4 Top-P
Top-P 说,“只考虑等于或超过这个值的可能性, 是最流行的采样方法, OpenAI 用于其 API
此参数表示为介于 0.0 和 1.0 之间的数字, 其中 1.0 表示 100%,0表示 0%。
使用 Top-P, 您可以保留尽可能多的代币以达到累积总和。但有时, 当模型对只有少数几个选项的置信度很高(但在这些选项中分配)时, 这会导致考虑一堆低概率的选项。
Top-P 可能会考虑过多或过少的标记, 具体取决于上下文
Top P 比 Top K 为您提供更多控制权, 因为它允许您选择更直观的截止值。这是一种专注于最可能的选择的方式。
一般来说, 不会同时修改Temperature和 Top P。这主要是因为如果事情不奏效, 你就会摧毁任何直觉的希望。他们都会严重影响结果, 而且他们很容易相互抵消或放大彼此的影响, 以至于两者都没有意义。
Temperature 为 0、Top K 为 1 或 Top P 为0等同于用 argmax 公式替换 softmax。实际上是说我们不会考虑最可能的下一个代币。这些选项之间可能存在性能差异, 具体取决于您用于搜索样本的光束数量以及 transformer 模型的实现效率, 但结果是相同的。
Top-p 表示最高概率, Top-k 表示最高基数。Top-k 中的"K"很可能来自希腊语 kappa, 因此说"Top-k experts"是正确的。
1.4.5 min_p
在设置一个最小值, 代币必须达到该值才能被考虑。该值根据最高概率令牌的置信度而变化。
因此, 如果您的 Min P 设置为 0.1, 这意味着它只允许至少是最佳选项可能性的 1/10 的令牌。如果设置为 0.05, 那么它将允许的令牌至少是顶部令牌的 1/20, 依此类推……
Min P 强调平衡, 根据首选的置信度设置最小值。
0.05 - 0.1 似乎是一个合理的调整范围, 但你也可以在不过于确定的情况下提高, 而且不包括尾端"无意义"概率。
98% 的用户不应该接触除了 Min-P 和 DRY 之外的任何采样器, 可能还有温度, 尽管后者在最新一代的型号中变得非常反复无常。
1.4.6 Repetition Penalty
更像是一种创可贴, 而不是防止重复的好方法;然而, 没有它, Mistral 7b 型号尤其困难。我称其为创可贴修复, 因为它会惩罚重复的标记, 即使它们有意义(像格式化星号和数字这样的事情会受到严重打击), 并且它会在如何选择标记时引入微妙的偏见。
建议, 如果您使用此值, 请不要将其设置为高于 1.20, 并将其视为有效的"最大值”。
1.4.7 frequency_penalty
1.4.8 presence_penalty
1.4.9 stop
2. Model
2.1 Code
- OpenAI Codex
- Tabnine
- CodeT5
- Polycoder
- starcodebases(BigCode)
- WizardCoder:
- Everyone-Coder-33b-Base
- MobiLlama
- Phind-CodeLlama-34b-v2 / Phind-Codellama-34B-v2-megacode-exl2-4.8
- Dolphin-2.5-Mixtral-7x8B
- OpenCoderInterpreter DS 6.7B
- WaveCoder Ultra 6.7B
2.1.1 针对语法纠正训练的本地模型(3B/7B)
- https://huggingface.co/vennify/t5-base-grammar-correction
- https://huggingface.co/pszemraj/flan-t5-large-grammar-synthesis
- https://huggingface.co/TheBloke/Karen_TheEditor_V2_STRICT_Mistral_7B-GGUF
2.2 翻译模型
- OPUS MT: 几乎适用于所有语言的微小、极快的模型, 使它们基本上具有多语言能力。这些模型的问题在于输出质量 - 它不烂, 但也不是很好。
- allenai
- madlad-400
- facebook-nllb-200
- deepl
- Seamless m4t
- opus-mt-XX-XX
2.3 Text2Image
- Midjourney
- Dall-e
- Stable Diffusion
- Googles Imagen
- Adobe Firefly
- Amazon Titan
- Getty Images AI 图像生成器
2.4 阅读新闻文章并生成摘要
- 基于 Mistral v0.2 的 dolphin 2.8
- Command R+: 针对 RAG 进行了微调, 因此在总结方面非常出色。
2.5 Text2Image
- ByteDance/SDXL-Lightning
2.6 MoE Model
- Gemini 1.5 Pro
- WizardLM-2 8x22B
- Mixtral 8x22B
- Qwen1.5-MoE-A2.7B
- Grok-1
- DBRX
“DBRX 是一个基于 Transformer 的纯解码器大型语言模型 (LM), 它是使用下一个令牌预测训练的。它使用细粒度的专家混合 (MoE) 架构, 总参数为 132B, 其中 36B 参数在任何输入上都处于活动状态。它是在 12T 文本和代码数据标记上预先训练的。与 Mixtral 和 Grok-1 等其他开放式 MoE 模型相比, DBRX 是细粒度的, 这意味着它使用了更多较小的专家。DBRX 有 16 名专家并选择 4 名, 而 Mixtral 和 Grok-1 有 8 名专家并选择 2 名。这提供了 65 倍以上的专家组合, 我们发现这提高了模型质量。DBRX 使用旋转位置编码 (RoPE)、门控线性单元 (GLU) 和分组查询注意力 (GQA)。它使用 tiktoken 存储库中提供的 GPT-4 分词器。我们根据详尽的评估和规模实验做出了这些选择。
DBRX 在精心策划的 12T 令牌上进行了预训练, 最大上下文长度为 32k 令牌。我们估计, 这些数据比我们用于预训练 MPT 系列模型的数据至少好 2 倍。这个新数据集是使用全套 Databricks 工具开发的, 包括用于数据处理的 Apache Spark™ 和 Databricks 笔记本、用于数据管理和治理的 Unity Catalog 以及用于试验跟踪的 MLflow。我们使用课程学习进行预训练, 在训练期间以我们发现可以显着提高模型质量的方式改变数据组合。
仅从基准测试来看, 它仅比 Mixtral 好一点点, 其大小是 Mixtral 的 2.5 倍, 推理速度只有 Mixtral 的一半。
3. Model 架构
3.1 Gemma
配备了更高级的分词器
3.2 MoE(Mixture-of-Experts) 架构
- 与密集模型相比, 预训练速度要快得多
- 与具有相同参数数量的模型相比, 推理速度更快
- 需要高 VRAM, 因为所有专家都加载在内存中
- 在微调方面面临许多挑战, 但最近在MoE指令调整方面的工作是有希望的
3.2.1 什么是专家混合(MoE)
模型的比例是提高模型质量的最重要轴之一。在给定固定计算预算的情况下, 训练较大的模型以更少的步骤比训练较小的模型以训练更多步骤要好。
在Transformer模型的上下文中, MoE 由两个主要元素组成:
- 使用稀疏 MoE 层代替密集前馈网络(FFN) 层。MoE 层有一定数量的"专家”(例如 8 个), 每个专家都是一个神经网络。在实践中, 专家是 FFN, 但他们也可以是更复杂的网络, 甚至是 MoE 本身, 从而导致分层的 MoE!
- 门网络或路由器, 用于确定将哪些令牌发送给哪个专家。例如, 在下图中, 令牌"More"被发送到第二个专家, 令牌"Parameters"被发送到第一个网络。正如我们稍后将探讨的那样, 我们可以向多个专家发送令牌。如何将令牌路由到专家是使用 MoE 时的重大决策之一 - 路由器由学习的参数组成, 并与网络的其余部分同时进行预训练。
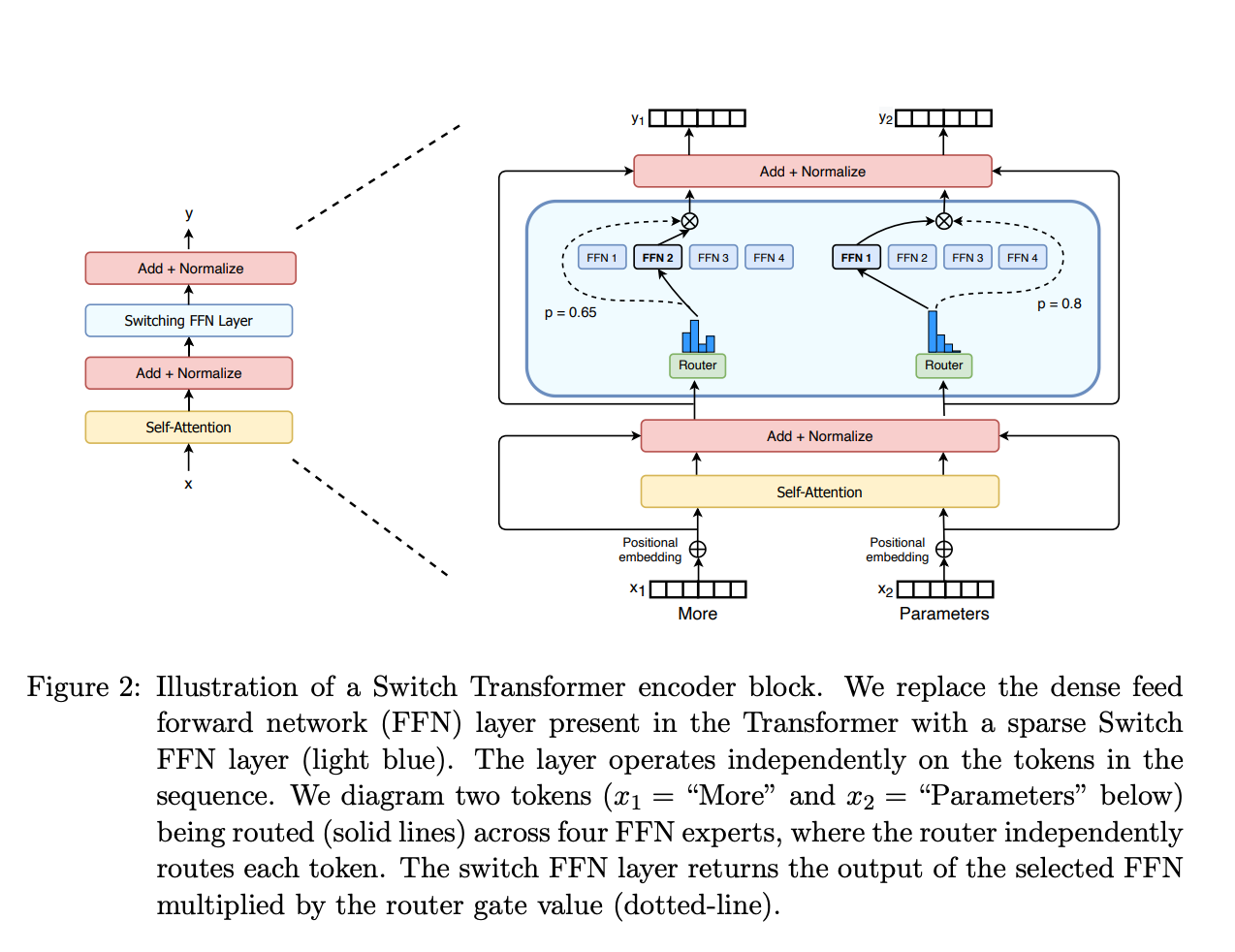
MoE 具有高效的预训练和更快的推理等优势, 但它们也带来了挑战:
- 训练: MoE 可以显著提高计算效率的预训练, 但从历史上看, 它们在微调过程中难以泛化, 从而导致过度拟合。
- 推理: 尽管 MoE 可能有许多参数, 但在推理过程中只使用其中一些参数。与具有相同参数数量的密集模型相比, 这导致推理速度更快。但是, 所有参数都需要加载到 RAM 中, 因此内存要求很高。例如, 给定像 Mixtral 8x7B 这样的 MoE, 我们需要有足够的 VRAM 来容纳密集的 47B 参数模型。为什么是 47B 参数而不是 8 x 7B = 56B? 这是因为在 MoE 模型中, 只有 FFN 层被视为单个专家, 其余模型参数是共享的。同时, 假设每个代币只使用两个专家, 推理速度(FLOP) 就像使用 12B 模型(而不是 14B 模型)一样, 因为它计算 2x7B 矩阵乘法, 但共享一些层(稍后会详细介绍)。
3.2.2 什么是稀疏性
稀疏性使用条件计算的思想。虽然在密集模型中, 所有参数都用于所有输入, 但稀疏性允许我们只运行整个系统的某些部分。
条件计算(网络的各个部分在每个示例的基础上处于活动状态)的想法允许人们在不增加计算的情况下扩展模型的大小, 因此, 这导致每个 MoE 层都使用了数千名专家。
3.2.3 MoE 的负载均衡令牌
在正常的MoE培训中, 门控网络会收敛, 以激活相同的少数专家。这种自我强化, 因为受青睐的专家培训得更快, 因此选择更多。为了缓解这种情况, 增加了辅助损失, 以鼓励给予所有专家同等的重要性。这种损失确保了所有专家获得大致相同数量的培训示例。
3.2.4 MoEs and Transformers
Transformer 是一个非常明显的例子, 即扩大参数数量可以提高性能, 因此 Google 在 GShard 中探索这一点也就不足为奇了, GShard 探索将 transformer 扩展到 6000 亿个参数以上。
GShard 在编码器和解码器中使用 top-2 门控将所有其他 FFN 层替换为 MoE 层。
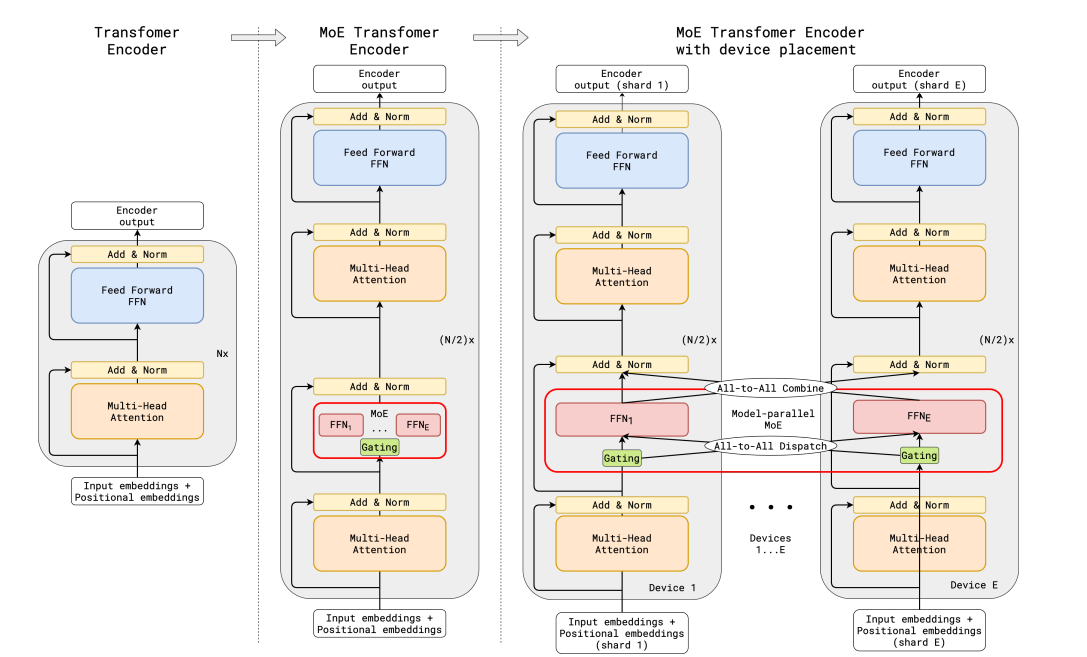
为了在规模上保持负载和效率的平衡, GShard的作者除了引入了一些类似于上一节中讨论的辅助损耗之外的更改:
- 随机路由: 在前 2 名设置中, 我们总是选择顶级专家, 但选择第二个专家的概率与其权重成正比。
- 专家容量: 我们可以设置一个阈值, 一个专家可以处理多少个代币。如果两个专家都处于满负荷状态, 则该令牌被视为溢出, 并通过剩余连接发送到下一层(或完全丢弃在其他项目中)。这个概念将成为教育部最重要的概念之一。为什么需要专家能力? 由于所有张量形状都是在编译时静态确定的, 但我们无法提前知道每个专家将有多少令牌, 因此我们需要修复容量因子。
3.2.5 Switch Transformers
Switch Transformer 使用简化的单专家策略。这种方法的效果是:
- 减少门控网络 (路由) 计算负担
- 每个专家的批量大小至少可以减半
- 降低通信成本
- 保持模型质量
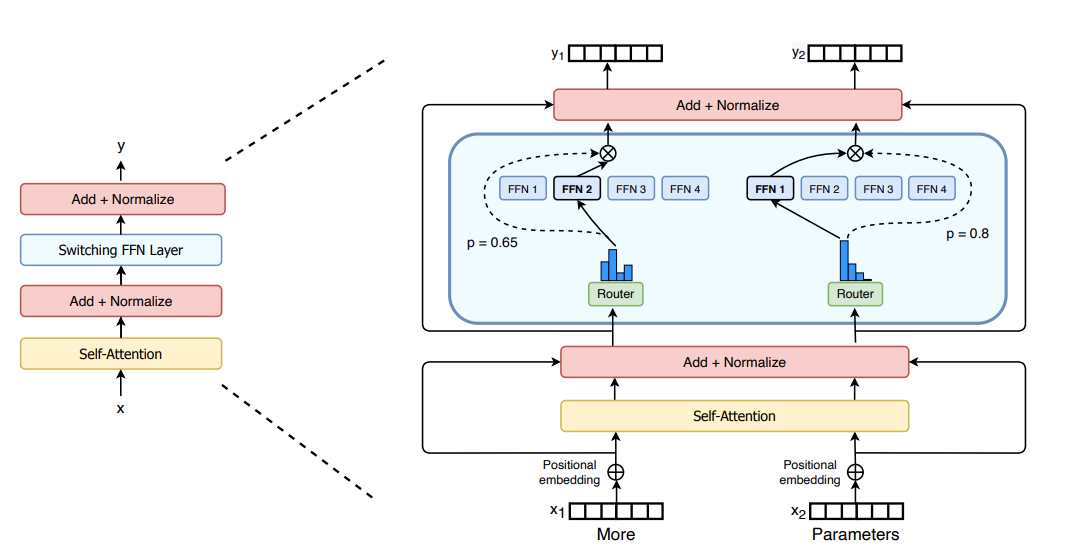
参考: https://colab.research.google.com/drive/1aGGVHZmtKmcNBbAwa9hbu58DDpIuB5O4?usp=sharing
3.2.6 用 Router z-loss 稳定模型训练
ST-MoE 引入的 Router z-loss 在保持了模型性能的同时显著提升了训练的稳定性。这种损失机制通过惩罚门控网络输入的较大 logits 来起作用, 目的是促使数值的绝对大小保持较小, 这样可以有效减少计算中的舍入误差。
3.2.7 微调混合专家模型
4.36.0 版本的 transformers 库支持 Mixtral 模型。你可以用以下命令进行安装: pip install transformers==4.36.0 --upgrade
稠密模型和稀疏模型在过拟合的动态表现上存在显著差异。稀疏模型更易于出现过拟合现象, 因此在处理这些模型时, 尝试更强的内部正则化措施是有益的, 比如使用更高比例的 dropout。例如, 我们可以为稠密层设定一个较低的 dropout 率, 而为稀疏层设置一个更高的 dropout 率, 以此来优化模型性能。
一种可行的微调策略是尝试冻结所有非专家层的权重。实践中, 这会导致性能大幅下降, 但这符合我们的预期, 因为混合专家模型 (MoE) 层占据了网络的主要部分。我们可以尝试相反的方法: 仅冻结 MoE 层的参数。实验结果显示, 这种方法几乎与更新所有参数的效果相当。这种做法可以加速微调过程, 并降低显存需求。
在微调稀疏混合专家模型 (MoE) 时需要考虑的最后一个问题是, 它们有特别的微调超参数设置——例如, 稀疏模型往往更适合使用较小的批量大小和较高的学习率, 这样可以获得更好的训练效果。
论文 《MoEs Meets Instruction Tuning》 (2023 年 7 月) 带来了令人兴奋的发现:
当研究者们对 MoE 和对应性能相当的 T5 模型进行微调时, 他们发现 T5 的对应模型表现更为出色。然而, 当研究者们对 Flan T5 (一种 T5 的指令优化版本) 的 MoE 版本进行微调时, MoE 的性能显著提升。更值得注意的是, Flan-MoE 相比原始 MoE 的性能提升幅度超过了 Flan T5 相对于原始 T5 的提升, 这意味着 MoE 模型可能从指令式微调中获益更多, 甚至超过了稠密模型。此外, MoE 在多任务学习中表现更佳。与之前关闭 辅助损失 函数的做法相反, 实际上这种损失函数可以帮助防止过拟合。
稀疏混合专家模型 (MoE) 适用于拥有多台机器且要求高吞吐量的场景。在固定的预训练计算资源下, 稀疏模型往往能够实现更优的效果。相反, 在显存较少且吞吐量要求不高的场景, 稠密模型则是更合适的选择。
提高容量因子 (Capacity Factor, CF) 可以增强模型的性能, 但这也意味着更高的通信成本和对保存激活值的显存的需求。在设备通信带宽有限的情况下, 选择较小的容量因子可能是更佳的策略。一个合理的初始设置是采用 Top-2 路由、1.25 的容量因子, 同时每个节点配置一个专家。在评估性能时, 应根据需要调整容量因子, 以在设备间的通信成本和计算成本之间找到一个平衡点。
下面这些开源项目可以用于训练混合专家模型 (MoE):
- Megablocks: https://github.com/stanford-futuredata/megablocks
- Fairseq: https://github.com/facebookresearch/fairseq/tree/main/examples/moe_lm
- OpenMoE: https://github.com/XueFuzhao/OpenMoE
对于开源的混合专家模型 (MoE), 你可以关注下面这些:
- Switch Transformers (Google): 基于 T5 的 MoE 集合, 专家数量从 8 名到 2048 名。最大的模型有 1.6 万亿个参数。
- NLLB MoE (Meta): NLLB 翻译模型的一个 MoE 变体。
- OpenMoE: 社区对基于 Llama 的模型的 MoE 尝试。
- Mixtral 8x7B (Mistral): 一个性能超越了 Llama 2 70B 的高质量混合专家模型, 并且具有更快的推理速度。此外, 还发布了一个经过指令微调的模型。
3.3 Griffin 架构
论文在这里: https://arxiv.org/pdf/2402.19427.pdf
huggingface 上发布了一个 2B 版本: https://huggingface.co/google/recurrentgemma-2b-it
3.4 Mamba 架构
2023 年底, 卡内基梅隆大学和普林斯顿大学的研究人员发表了一篇研究论文, 揭示了一种名为 Mamba 的大型语言模型(LLM) 的新架构。Mamba 是一种与序列建模相关的新状态空间模型架构。它的开发是为了解决transformer模型的一些局限性, 特别是在处理长序列方面, 并显示出良好的性能。
Mamba 是一种新的 LLM 架构, 它集成了结构化状态空间序列(S4) 模型来管理冗长的数据序列。结合循环、卷积和连续时间模型的最佳功能, S4 可以有效且高效地模拟长期依赖关系。这使它能够处理不规则采样的数据, 具有无限的上下文, 并在整个训练和测试过程中保持计算效率。
**Mamba 的关键组件包括: **
- 选择性状态空间(SSM): 循环模型根据当前输入有选择地处理信息, 是 Mamba SSM 的基础。这使他们能够过滤掉无关的数据并专注于相关信息, 这可能会导致更有效的处理。
- 简化架构: Mamba 用一个单一的、有凝聚力的 SSM 块取代了变形金刚错综复杂的注意力和 MLP 块。这旨在加速推理并降低计算复杂性。
- 硬件感知并行性: Mamba 的性能可能更好, 因为它使用循环模式和专门为硬件效率而创建的并行算法。
3.5 Hawk 架构
hawk是纯线性架构
4. 相关社区
5. 其他
5.1 2023年最热门的十大LLM模型
- 谷歌的LLaMa
- OpenAI的GPT3.5和4
- 谷歌的LaMDA和PaLM 2
- 阿里巴巴的Tongyi Qianwen
- Meta的Vicuna 33B
- Anthropic的Claude
- 谷歌的Bard
- Summarization模型Falcon
- 代码生成模型Codex
- 为艺术家设计的Alpaca。
5.2 GenAI Tools
- Grammarly: 写作
- Jasper: 生成
- Synthesia: 视频创作
- CopyAI: 内容生成
- cohere: 各种任务
- VeeD.io
- Speechify: 文本转语音
- Notion: 笔记和任务管理工具
- DALL-E: 文生图
5.3 学习资源
- DeepLearning.ai 短期课程
- TDS 文章: 通过 LangChain 链接 LLM、代理和实用程序的温和介绍
- Greg Kamradt 的 LangChain Youtube 播放列表
- 1littlecoder LangChain Youtube播放列表
- LangChain上的教程页面
5.4 Self Attention
自我注意力是使 LLM 能够理解上下文的原因。它是如何工作的?
<video src="/uploads/llm/llm_tools_00.mp4" controls="controls" width="500" height="300"></video>
参考: https://x.com/ProfTomYeh/status/1797249951325434315
- [1] Given
- A set of 4 feature vectors (6-D): x1,x2,x3,x4
- [2] Query, Key, Value
- Multiply features x’s with linear transformation matrices WQ, WK, and WV, to obtain query vectors (q1,q2,q3,q4), key vectors (k1,k2,k3,k4), and value vectors (v1,v2,v3,v4).
- “Self” refers to the fact that both queries and keys are derived from the same set of features.
- [3] 🟪 Prepare for MatMul
- Copy query vectors
- Copy the transpose of key vectors
- [4] 🟪 MatMul
- Multiply K^T and Q
- This is equivalent to taking dot product between every pair of query and key vectors.
- The purpose is to use dot product as an estimate of the “matching score” between every key-value pair.
- This estimate makes sense because dot product is the numerator of Cosine Similarity between two vectors.
- [5] 🟨 Scale
- Scale each element by the square root of dk, which is the dimension of key vectors (dk=3).
- The purpose is to normalize the impact of the dk on matching scores, even if we scale dk to 32, 64, or 128.
- To simplify hand calculation, we approximate [ □/sqrt(3) ] with [ floor(□/2) ].
- [6] 🟩 Softmax: e^x
- Raise e to the power of the number in each cell
- To simplify hand calculation, we approximate e^□ with 3^□.
- [7] 🟩 Softmax: ∑
- Sum across each column
- [8] 🟩 Softmax: 1 / sum
- For each column, divide each element by the column sum
- The purpose is normalize each column so that the numbers sum to 1. In other words, each column is a probability distribution of attention, and we have four of them.
- The result is the Attention Weight Matrix (A) (yellow)
- [9] 🟦 MatMul
- Multiply the value vectors (Vs) with the Attention Weight Matrix (A)
- The results are the attention weighted features Zs.
- They are fed to the position-wise feed forward network in the next layer.
5.5 其他
- LLM-Model-VRAM-Calculator
- https://www.llmpricing.app/
- https://docsbot.ai/tools/gpt-openai-api-pricing-calculator
- https://dmatora.github.io/LLM-inference-speed-benchmarks/
- https://llmprices.dev/
5.5.1 无代码框架
- Flowise
- FlowLang
- Dify
- Bisheng: dify+flowise的结合体
- DB-GPT: 是一个开源的AI原生数据应用开发框架
- Kurtale - 个人LLM讲故事项目
- Rivet
- Vellum
参考:
Function calling
Flowise|无代码 ChatBot 构建平台|LangChain
LLM By Examples — Use GGUF Quantization
An Introduction to the Mamba LLM Architecture: A New Paradigm in Machine Learning
Reflection Agents With LangGraph | Agentic LLM Based Applications
Mixture of Experts Explained
How to Tune LLM Parameters for Top-Performance: Understanding Temperature, Top K, and Top-P
一个交互式可视化, 用于了解 softmax 温度对概率分布的影响
Avocados are rich in monounsaturated fats
Your settings are (probably) hurting your model - Why sampler settings matter
