
目录
-
-
1. 概述
- 1.1 人工智能、机器学习与深度学
-
1.2 深度学习
- 1.2.1 决策树(Decision Tree)算法
- 1.2.2 K-Means 算法(The k-means algorithm)
- 1.2.3 支持向量机(Support Vector Machine, SVM)
- 1.2.4 The Apriori algorithm
- 1.2.5 最大期望(EM)算法
- 1.2.6 PageRank 网页排名
- 1.2.7 AdaBoost
- 1.2.8 k-NN
- 1.2.9 Naive Bayes 朴素贝叶斯
- 1.2.10 logistic 回归
- 1.2.11 概率建模(probabilistic modeling)
- 1.2.12 长短期记忆(LSTM, long short-term memory)
- 1.3 机器学习的四个分支
- 2. 数学基础
- 3. 神经网络
- 4. 模型
- 5. 深度学习的使用
- 6. 深度学习的思考和局限性
-
1. 概述
1. 概述
1.1 人工智能、机器学习与深度学
人工智能、机器学习与深度学习三者之间的关系:
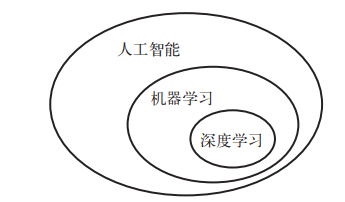
人工智能(artificial intelligence)是一个古老而宽泛的领域, 通常可将其定义为"将认知过程自动化的所有尝试", 换句话说, 就是思想的自动化。
机器学习和深度学习的核心问题在于有意义地变换数据, 换句话说, 在于学习输入数据的有用表示(representation)——这种表示可以让数据更接近预期输出。
机器学习中的学习指的是, 寻找更好数据表示的自动搜索过程。机器学习(machine learning)是人工智能的一个特殊子领域, 其目标是仅靠观察训练数据来自动开发程序[即模型(model)]。将数据转换为程序的这个过程叫作学习(learning)。
机器学习算法在寻找这些变换时通常没有什么创造性, 而仅仅是遍历一组预先定义好的操作, 这组操作叫作假设空间(hypothesis space)。
在预先定义好的可能性空间中, 利用反馈信号的指引来寻找输入数据的有用表示。
1.2 深度学习
深度学习的概念由Hinton等人于2006年提出。深度学习的概念源于人工神经网络的研究。含多隐层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层次表示属性类别或特征, 以发现数据的分布式特征表示。
深度学习是机器学习的一个分支领域: 它是从数据中学习表示的一种新方法, 强调从连续的层(layer)中进行学习, 这些层对应于越来越有意义的表示。“深度学习"中的"深度"指的并不是利用这种方法所获取的更深层次的理解, 而是指一系列连续的表示层。数据模型中包含多少层, 这被称为模型的深度(depth)。这一领域的其他名称包括分层表示学习(layered representations learning)和层级表示学习(hierarchical representations learning)。
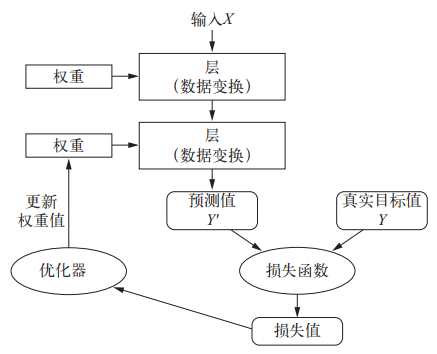
神经网络中每层对输入数据所做的具体操作保存在该层的权重(weight)中, 其本质是一串数字。用术语来说, 每层实现的变换由其权重来参数化(parameterize)。
想要控制一件事物, 首先需要能够观察它。想要控制神经网络的输出, 就需要能够衡量该输出与预期值之间的距离。这是神经网络损失函数(loss function)的任务, 该函数也叫目标函数(objective function)。损失函数的输入是网络预测值与真实目标值(即你希望网络输出的结果), 然后计算一个距离值, 衡量该网络在这个示例上的效果好坏。
深度学习的基本技巧是利用这个距离值作为反馈信号来对权重值进行微调, 以降低当前示例对应的损失值。这种调节由优化器(optimizer)来完成, 它实现了所谓的反向传播(backpropagation)算法, 这是深度学习的核心算法。
1.2.1 决策树(Decision Tree)算法
决策树是在已知各种情况发生概率的基础上, 通过构成决策树来求取净现值的期望值大于或等于零的概率, 从而评价项目风险, 判断其可行性的决策分析方法, 是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干, 故称决策树。
1.2.2 K-Means 算法(The k-means algorithm)
K-Means 算法算法是一个聚类算法, 把 n 的对象根据他们的属性分为 k个分割, \(k 支持向量机(Support Vector Machine, SVM), 简称 SV 机(论文中一般简称 SVM)。它是一种监督式学习的方法, 它广泛应用于统计分类以及回归分析中。支持向量机将向量映射到一个更高维的空间里, 在这个空间里建立了一个最大间隔的超平面。在分开数据的超平面的两边建有两个互相平行的超平面。分隔超平面使两个平行超平面的距离最大化, 并假定平行超平面间的距离或差距越大, 分类器的总误差越小。 核方法是一组分类算法, 其中最有名的就是支持向量机(SVM, support vector machine)。 Apriori 算法是一种挖掘关联规则的频繁项集算法, 其核心思想是通过候选集生成和情节的向下封闭检测两个阶段来挖掘频繁项集。该算法已经被广泛地应用到商业、网络安全等领域。 最大期望算法(Expectation-maximization algorithm, 又译期望最大化算法)在统计中被用于寻找, 依赖于不可观察的隐性变量的概率模型中, 参数的最大似然估计。 PageRank 是 Google 排名运算法则(排名公式)的一部分, 是 Google用来标识网页的等级/重要性的一种方法, 是 Google 用来衡量一个网站好坏的唯一标准。在融合了诸如 Title 标识和 Keywords 标识等所有因素之后, Google 通过 PageRank 来调整结果, 使那些更具"等级/重要性"的网页在搜索结果中获得排名提升, 从而提高搜索结果的相关性和质量。 AdaBoost 是一种迭代算法, 其核心思想是针对同一个训练, 集训练不同的分类器(弱分类器), 然后把这些弱分类器集合起来, 构成一个更强的最终分类器(强分类器)。 k 最近邻(k-Nearest Neighbor, k-NN)分类算法, 该方法的思路是:如果一个样本在特征空间中的 k 个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别, 则该样本也属于这个类别。是一个理论上比较成熟的方法, 也是最简单的机器学习算法之一。 贝叶斯分类器的分类原理是通过某对象的先验概率, 利用贝叶斯公式计算出其后验概率, 即该对象属于某一类的概率, 选择具有最大后验概率的类作为该对象所属的类。朴素贝叶斯模型发源于古典数学理论, 有着坚实的数学基础, 以及稳定的分类效率。 logistic 回归(logistic regression, 简称 logreg): logreg 是一种分类算法, 而不是回归算法 概率建模(probabilistic modeling)是统计学原理在数据分析中的应用。它是最早的机器学习形式之一, 至今仍在广泛使用。 长短期记忆(LSTM, long short-term memory)算法是深度学习处理时间序列的基础 深度学习从数据中进行学习时有两个基本特征: 第一, 通过渐进的、逐层的方式形成越来越复杂的表示; 第二, 对中间这些渐进的表示共同进行学习, 每一层的变化都需要同时考虑上下两层的需要。 梯度提升机用于处理结构化数据的问题, 而深度学习则用于图像分类等感知问题。使用前一种方法的人几乎都使用优秀的 XGBoost 库, 它同时支持数据科学最流行的两种语言: Python 和 R。使用深度学习的 Kaggle 参赛者则大多使用 Keras 库, 因为它易于使用, 非常灵活, 并且支持Python。1.2.3 支持向量机(Support Vector Machine, SVM)
1.2.4 The Apriori algorithm
1.2.5 最大期望(EM)算法
1.2.6 PageRank 网页排名
1.2.7 AdaBoost
1.2.8 k-NN
1.2.9 Naive Bayes 朴素贝叶斯
1.2.10 logistic 回归
1.2.11 概率建模(probabilistic modeling)
1.2.12 长短期记忆(LSTM, long short-term memory)
1.3 机器学习的四个分支
1.3.1 监督学习(Supervised Learning)
如图所示, 数据的每一行都与一个目标或标签相关联。列是不同的特征, 行代表不同的数据点, 通常称为样本。示例中的十个样本有十个特征和一个目标变量, 目标变量可以是数字或类别。如果目标变量是分类变量, 问题就变成了分类问题。如果目标变量是实数, 问题就被定义为回归问题。
有监督问题可分为两个子类:
- 分类: 预测类别, 如猫或狗
- 回归: 预测值, 如房价
必须注意的是, 有时我们可能会在分类设置中使用回归, 这取决于用于评估的指标。
监督学习是一个比较传统的机器学习研究领域。简单概括, 监督学习主要希望研究映射关系 y = f(x|𝜃)
- 𝜃: 它是待定系数
监督学习主要包括分类和回归, 但还有更多的奇特变体:
- 序列生成(sequence generation)。给定一张图像, 预测描述图像的文字。序列生成有时可以被重新表示为一系列分类问题, 比如反复预测序列中的单词或标记
- 语法树预测(syntax tree prediction)。给定一个句子, 预测其分解生成的语法树
- 目标检测(object detection)。给定一张图像, 在图中特定目标的周围画一个边界框。这个问题也可以表示为分类问题(给定多个候选边界框, 对每个框内的目标进行分类)或分类与回归联合问题(用向量回归来预测边界框的坐标)
- 图像分割(image segmentation)。给定一张图像, 在特定物体上画一个像素级的掩模(mask)。
- 线性回归(Linear Regression)
1.3.2 无监督学习(Unsupervised Learning)
非监督学习也是一个比较传统的机器学习领域。在机器学习入门阶段使用最多的算法 K-Means, 就是一个典型的非监督学习算法。
无监督学习是指在没有目标的情况下寻找输入数据的有趣变换, 其目的在于数据可视化、数据压缩、数据去噪或更好地理解数据中的相关性。无监督学习是数据分析的必备技能, 在解决监督学习问题之前, 为了更好地了解数据集, 它通常是一个必要步骤。降维(dimensionality reduction)和聚类(clustering)都是众所周知的无监督学习方法。
假设你在一家处理信用卡交易的金融公司工作。每秒钟都有大量数据涌入。唯一的问题是, 很难找到一个人来将每笔交易标记为有效交易、真实交易或欺诈交易。当我们没有任何关于交易是欺诈还是真实的信息时, 问题就变成了无监督问题。要解决这类问题, 我们必须考虑可以将数据分为多少个聚类。聚类是解决此类问题的方法之一, 但必须注意的是, 还有其他几种方法可以应用于无监督问题。对于欺诈检测问题, 我们可以说数据可以分为两类(欺诈或真实d)
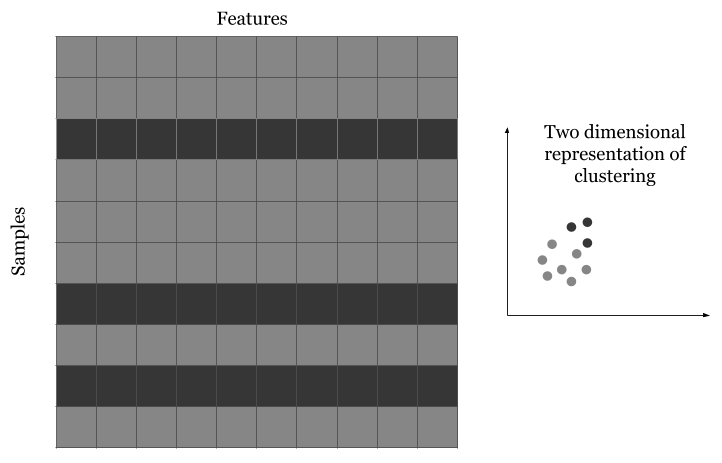
为了理解无监督问题, 我们还可以使用许多分解技术, 如主成分分析(PCAd)t-分布随机邻域嵌入(t-SNEd)。
然而, 对无监督算法的结果进行评估具有挑战性, 需要大量的人为干预或启发式方法。
一个经常出现的问题是, 如何在 k-means 聚类中找到最佳的簇数。这个问题没有正确答案。你必须通过交叉验证来找到最佳簇数。
1.3.3 自监督学习
自监督学习是监督学习的一个特例, 它与众不同, 值得单独归为一类。自监督学习是没有人工标注的标签的监督学习, 你可以将它看作没有人类参与的监督学习。标签仍然存在(因为总要有什么东西来监督学习过程), 但它们是从输入数据中生成的, 通常是使用启发式算法生成的。
1.3.4 强化学习(Reinforcement Learning)
强化学习是一个独立的机器学习研究领域。在强化学习中, 智能体(agent)接收有关其环境的信息, 并学会选择使某种奖励最大化的行动。强化学习希望机器人或者智能体在一个环境中, 随着"时间的流逝”, 不断地自我学习, 并最终在这个环境中学到一套最为合理的行为策略。
监督学习的方法是非常套路化的: 把输入的x和输出的y之间用一个函数 y = f(x|𝜃) 来映射, 把用来描述这种映射关系的误差描述成待定系数为 𝜃 的损失函数 Loss = ∑|f(xᵢ|𝜃) - yᵢ|, 通过最优化问题(Optimization Problem)的思路或方法来求解当损失函数 Loss(𝜃) 取极小值时 𝜃 的值。
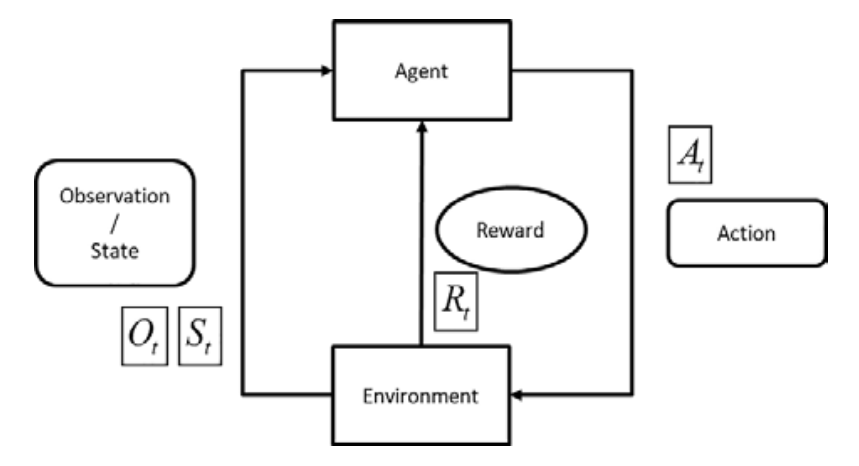
- Agent, 或者称为"Brain"、大脑、智能体, 就是机器人的智能主体部分
- Environment, 一般翻译成"环境", 是指机器人所处的环境
- Observation, 翻译成"观测" 可能比较好, Observation 是指 Agent 能够观测(感知)到的环境信息
- Action, 是指由 Agent 发出的行为和动作, 以及 Agent 与 Environment 之间发生的动作交互
- Reward, 一般翻译为"奖励值", 有时也翻译为"回报值"。在本书中会混用这两种称谓, 或者口语化地称之为"得分"。在强化学习中, 我觉得最为有趣、最为精妙的一个研究对象兼超参数(Hyperparameter)就是Reward
2. 数学基础
机器学习所需的一些基本统计和概率理论主要有: 组合学、概率规则和公理、贝叶斯定理、随机变量、方差和期望、条件和联合分布、标准分布(伯努利分布、二项式分布、多项式分布、均匀分布和高斯分布等)、动差生成函数、最大似然估计、先验和后验、最大后验估计和抽样方法。
多元微积分: 一些必要的内容包括微积分、偏导数、向量值函数、方向梯度、 Hessian、 Jacobian、 Laplacian 和 Lagragian 分布。入门之后, 我们需要矩阵分析、优化设计、离散数学、算法和优化理论。算法和优化理论对我们理解机器学习算法的计算效率和可拓展性, 以及怎么利用数据中的稀疏性很重要。需要的知识主要包括: 数据结构(二叉树、散列、堆、堆栈等)、动态规划、随机和次线性算法、图论、梯度/随机下降和原始-对偶方法。其他还包括: 复变函数(集合和序列、拓扑结构、度量空间、单值和连续函数、极限等)、信息论(熵、信息增益)、函数空间和流形。
2.1 线性代数
2.1.1 基本概念
- 张量这一概念的核心在于, 它是一个数据容器。它包含的数据几乎总是数值数据, 因此它是数字的容器。矩阵是二维张量。张量是矩阵向任意维度的推广[注意, 张量的维度(dimension)通常叫作轴(axis)]
- 仅包含一个数字的张量叫作标量(scalar, 也叫标量张量、零维张量、 0D 张量)
- 数字组成的数组叫作向量(vector)或一维张量(1D 张量)。一维张量只有一个轴
- 向量组成的数组叫作矩阵(matrix)或二维张量(2D 张量)。矩阵有 2 个轴(通常叫作行和列)
- 将多个矩阵组合成一个新的数组, 可以得到一个 3D 张量, 你可以将其直观地理解为数字组成的立方体
将多个 3D 张量组合成一个数组, 可以创建一个 4D 张量, 以此类推。深度学习处理的一般是 0D 到 4D 的张量, 但处理视频数据时可能会遇到 5D 张量。
常见的数据:
- 向量数据: 2D 张量, 形状为 (samples, features)
- 时间序列数据或序列数据: 3D 张量, 形状为 (samples, timesteps, features)
- 图像: 4D 张量, 形状为 (samples, height, width, channels) 或 (samples, channels,height, width)
- 视频: 5D 张量, 形状为 (samples, frames, height, width, channels) 或 (samples,frames, channels, height, width)。
图像张量的形状有两种约定: 通道在后(channels-last)的约定(在 TensorFlow 中使用)和通道在前(channels-first)的约定(在 Theano 中使用)。
2.1.2 张量运算
2.1.2.1 逐元素运算
relu 运算和加法都是逐元素(element-wise)的运算, 即该运算独立地应用于张量中的每个元素, 也就是说, 这些运算非常适合大规模并行实现(向量化实现)
def naive_relu(x):
assert len(x.shape) == 2
x = x.copy()
for i in range(x.shape[0]):
for j in range(x.shape[1]):
x[i, j] = max(x[i, j], 0)
return x
2.1.2.2 广播
- 向较小的张量添加轴(叫作广播轴), 使其 ndim 与较大的张量相同
- 将较小的张量沿着新轴重复, 使其形状与较大的张量相同
x = np.random.random((64, 3, 32, 10))
y = np.random.random((32, 10))
z = np.maximum(x, y)
print("x", x.shape)
print("y", y.shape)
print("z", z.shape)
2.1.2.3 点积运算
点积运算, 也叫张量积(tensor product, 不要与逐元素的乘积弄混), 是最常见也最有用的张量运算。与逐元素的运算不同, 它将输入张量的元素合并在一起。
在 Numpy、 Keras、 Theano 和 TensorFlow 中, 都是用 * 实现逐元素乘积。 TensorFlow 中的点积使用了不同的语法, 但在 Numpy 和 Keras 中, 都是用标准的 dot 运算符来实现点积。
两个向量之间的点积是一个标量, 而且只有元素个数相同的向量之间才能做点积.
还可以对一个矩阵 x 和一个向量 y 做点积, 返回值是一个向量, 其中每个元素是 y 和 x的每一行之间的点积。
对于两个矩阵 x 和 y, 当且仅当 x.shape[1] == y.shape[0] 时, 你才可以对它们做点积(dot(x, y))。
x = np.array([[12, 3, 6, 14, 7], [12, 3, 6, 14, 7]])
y = np.array([12, 3, 6, 14, 7])
z = np.dot(x, y)
z1 = np.dot(x, 3)
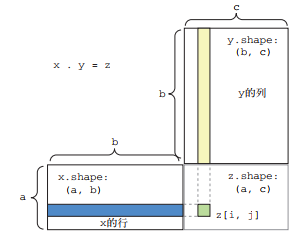
2.1.2.4 张量变形
张量变形是指改变张量的行和列, 以得到想要的形状。变形后的张量的元素总个数与初始张量相同。
x = np.array([[0., 1.], [2., 3.], [4., 5.]])
y = x.reshape((6, 1))
print("x.shape = {}, y.shape = {}".format(x.shape, y.shape))
# x.shape = (3, 2), y.shape = (6, 1)
2.2 微积分
- 导数
- 偏导数
- 方向导数和梯度
- 凸函数和凹函数
2.2.1 基于梯度的优化
- 抽取训练样本 x 和对应目标 y 组成的数据批量
- 在 x 上运行网络[这一步叫作前向传播(forward pass)], 得到预测值 y_pred
- 计算网络在这批数据上的损失, 用于衡量 y_pred 和 y 之间的距离
- 计算损失相对于网络参数的梯度[一次反向传播(backward pass)]
- 将参数沿着梯度的反方向移动一点, 比如 W -= step * gradient, 从而使这批数据上的损失减小一点
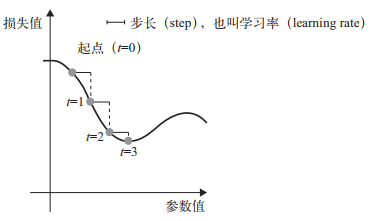
2.2.2 可微和梯度
光滑函数 f(x) = y, 即函数曲线没有突变的角度
对于每个可微函数 f(x)(可微的意思是"可以被求导"。例如, 光滑的连续函数可以被求导), 都存在一个导数函数 f’(x), 将 x 的值映射为 f 在该点的局部线性近似的斜率。例如, cos(x)的导数是 -sin(x), f(x) = a * x 的导数是 f’(x) = a, 等等。
梯度(gradient)是张量运算的导数。它是导数这一概念向多元函数导数的推广。多元函数是以张量作为输入的函数。
给定一个可微函数, 理论上可以用解析法找到它的最小值: 函数的最小值是导数为 0 的点, 因此你只需找到所有导数为 0 的点, 然后计算函数在其中哪个点具有最小值。
将这一方法应用于神经网络, 就是用解析法求出最小损失函数对应的所有权重值。可以通过对方程 gradient(f)(W) = 0 求解 W 来实现这一方法。
2.2.2 链式求导: 反向传播算法
将链式法则应用于神经网络梯度值的计算, 得到的算法叫作反向传播(backpropagation, 有时也叫反式微分, reverse-mode differentiation)。反向传播从最终损失值开始, 从最顶层反向作用至最底层, 利用链式法则计算每个参数对损失值的贡献大小。
符号微分(symbolic differentiation)
也就是说, 给定一个运算链, 并且已知每个运算的导数, 这些框架就可以利用链式法则来计算这个运算链的梯度函数, 将网络参数值映射为梯度值。对于这样的函数, 反向传播就简化为调用这个梯度函数。
2.3 概率与统计
2.3.1 常用统计变量
- 样本均值
- 样本方差
- 样本标准差
2.3.2 常见概率分布
- 均匀分布
- 正态分布(高斯分布)
- 指数分布
2.3.3 重要概率公式
- 条件概率
- 联合概率
- 全概率
- 贝叶斯
假设有两个随机变量X和Y, 他们分别可以取值为x和y, 则:
联合概率: “X取值为x"和"Y取值为y"两个事件同时发生的概率, 表示为 P(X=x, Y=y)
条件概率: 在"X取值为x"的前提下, “Y取值为y"的概率, 表示为 P(Y=y|X=x)
这个概率在机器学习中称之为后验概率(posterior probability), 即是说先知道了条件, 再去求解结果。
机器学习中的简写, 通常表示标签取到少数类的概率, 少数类往往使用正样本表示, 也就是P(Y=1), 本质就是所有样本中标签为1的样本所占的比例。
2.4 数学模型
数学模型表现为一组合理的数学公式, 这些公式能够在一定程度上详细描述大多数问题。算法用多个步骤来表示解决过程, 这些步骤需要用一种适当的编程语言或脚本来实现。
3. 神经网络
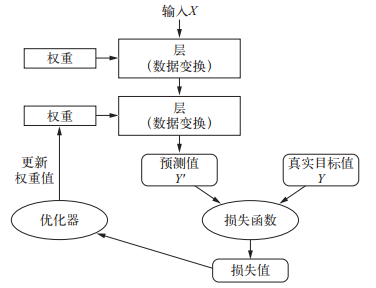
训练神经网络主要围绕以下四个方面:
- 层, 多个层组合成网络(或模型)
- 输入数据和相应的目标
- 损失函数, 即用于学习的反馈信号
- 优化器, 决定学习过程如何进行
3.1 层: 深度学习的基础组件
层是一个数据处理模块, 将一个或多个输入张量转换为一个或多个输出张量。有些层是无状态的, 但大多数的层是有状态的, 即层的权重。权重是利用随机梯度下降学到的一个或多个张量, 其中包含网络的知识。
不同的张量格式与不同的数据处理类型需要用到不同的层。例如:
- 简单的向量数据保存在形状为 (samples, features) 的 2D 张量中, 通常用密集连接层[ densely connected layer, 也叫全连接层(fully connected layer)或密集层(dense layer), 对应于 Keras 的 Dense 类]来处理
- 序列数据保存在形状为 (samples, timesteps, features) 的 3D 张量中, 通常用循环层(recurrent layer, 比如 Keras 的 LSTM 层)来处理
- 图像数据保存在 4D 张量中, 通常用二维卷积层(Keras 的 Conv2D)来处理。
层兼容性(layer compatibility)具体指的是每一层只接受特定形状的输入张量, 并返回特定形状的输出张量。
3.2 模型: 层构成的网络
深度学习模型是层构成的有向无环图。最常见的例子就是层的线性堆叠, 将单一输入映射为单一输出。
三种网络架构:
-
密集连接网络
密集连接网络是 Dense 层的堆叠, 它用于处理向量数据(向量批量)。 -
卷积网络
卷积层能够查看空间局部模式, 其方法是对输入张量的不同空间位置(图块)应用相同的几何变换。卷积神经网络的最后通常是一个 Flatten 运算或全局池化层, 将空间特征图转换为向量, 然后再是 Dense 层, 用于实现分类或回归。 -
循环网络
3.3 损失函数与优化器: 配置学习过程的关键
- 损失函数(目标函数)——在训练过程中需要将其最小化。它能够衡量当前任务是否已成功完成
- 优化器——决定如何基于损失函数对网络进行更新。它执行的是随机梯度下降(SGD)的某个变体
选择正确的目标函数对解决问题是非常重要的:
- 对于二分类问题, 你可以使用binary crossentropy(二元交叉熵: binary_crossentropy)损失函数
这并不是唯一可行的选择, 比如你还可以使用 mean_squared_error(均方误差, mse)。但对于输出概率值的模型, 交叉熵(crossentropy)往往是最好的选择。交叉熵是来自于信息论领域的概念, 用于衡量概率分布之间的距离. - 对于多分类问题, 可以用categorical crossentropy(分类交叉熵: categorical_crossentropy)损失函数
sparse_categorical_crossentropy: 整数标签 - 对于回归问题, 可以用均方误差(mean-squared error)损失函数
- 对于序列学习问题, 可以用联结主义时序分类(CTC, connectionist temporal classification)损失函数
隐藏单元越多(即更高维的表示空间), 网络越能够学到更加复杂的表示, 但网络的计算代价也变得更大, 而且可能会导致学到不好的模式(这种模式会提高训练数据上的性能, 但不会提高测试数据上的性能)。
relu(rectified linear unit, 整流线性单元)函数将所有负值归零
sigmoid 函数则将任意值"压缩"到 [0,1] 区间内(见图 3-5), 其输出值可以看作概率值
将取值范围差异很大的数据输入到神经网络中, 这是有问题的。网络可能会自动适应这种取值范围不同的数据, 但学习肯定变得更加困难。对于这种数据, 普遍采用的最佳实践是对每个特征做标准化, 即对于输入数据的每个特征(输入数据矩阵中的列), 减去特征平均值, 再除以标准差, 这样得到的特征平均值为 0, 标准差为 1。
mse 损失函数, 即均方误差(MSE, mean squared error), 预测值与目标值之差的平方。这是回归问题常用的损失函数。
平均绝对误差(MAE, mean absolute error)。它是预测值与目标值之差的绝对值。
3.4 Embedding
在自然语言处理和文本分析的问题中, 词袋(Bag of Words, BOW) 和词向量(Word Embedding) 是两种最常用的模型。 更准确地说, 词向量只能表征单个词, 如果要表示文本, 需要做一些额外的处理。
所谓 BOW, 就是将文本 /Query 看作是一系列词的集合。
将意思相近的词的向量值安排的靠近一些, 将意思不同的词的距离靠近的远一些。 其原理大致就是在一段文本中的词意思一般来说是相近的, 在不同的文本中的词意思大致是不同的, 根据这个原理来计算Embedding 模型。
4. 模型
模型(Model) 这个词, 在不同的研究领域有着不同的释义。 在强化学习领域, 模型是用于预测环境中将发生什么的一套描述信息。
Model-Based 通常被翻译成"基于模型”, Model-Free 通常被翻译成"无模型”。这里的模型是指, 在一个环境中各个状态之间转换的概率分布描述。
动态规划是一种建模和解题的思路。在这种思路的指导下, 原始的问题(大的、 复杂的问题)会被分解成多个可解的且结果可保存的子问题。一旦所有的子问题获解, 原始的问题就获解了。
4.1 模型评估、数据预处理、特征工程、过拟合
如果基于模型在验证集上的性能来调节模型配置, 会很快导致模型在验证集上过拟合, 即使你并没有在验证集上直接训练模型也会如此。
4.1.1 模型评估
将数据划分为训练集、验证集和测试集可能看起来很简单, 但如果可用数据很少, 还有几种高级方法可以派上用场。
-
简单的留出验证(hold-out validation)
留出一定比例的数据作为测试集。在剩余的数据上训练模型, 然后在测试集上评估模型。为了防止信息泄露, 你不能基于测试集来调节模型, 所以还应该保留一个验证集。 -
K 折验证(K-fold validation)
K 折验证(K-fold validation)将数据划分为大小相同的 K 个分区。 对于每个分区 i, 在剩余的 K-1 个分区上训练模型, 然后在分区 i 上评估模型。最终分数等于 K 个分数的平均值。对于不同的训练集 - 测试集划分, 如果模型性能的变化很大, 那么这种方法很有用。与留出验证一样, 这种方法也需要独立的验证集进行模型校正 -
带有打乱数据的重复 K 折验证
如果可用的数据相对较少, 而你又需要尽可能精确地评估模型, 那么可以选择带有打乱数据的重复 K 折验证(iterated K-fold validation with shuffling)。
4.1.2 数据预处理
数据预处理的目的是使原始数据更适于用神经网络处理, 包括向量化、标准化、处理缺失值和特征提取:
-
向量化
神经网络的所有输入和目标都必须是浮点数张量(在特定情况下可以是整数张量)。无论处理什么数据(声音、图像还是文本), 都必须首先将其转换为张量, 这一步叫作数据向量化(data vectorization)。 -
标准化
一般来说, 将取值相对较大的数据(比如多位整数, 比网络权重的初始值大很多)或异质数据(heterogeneous data, 比如数据的一个特征在 01 范围内, 另一个特征在 100200 范围内)输入到神经网络中是不安全的。这么做可能导致较大的梯度更新, 进而导致网络无法收敛。为了让网络的学习变得更容易, 输入数据应该具有以下特征。- 取值较小: 大部分值都应该在 0~1 范围内
- 同质性(homogenous): 所有特征的取值都应该在大致相同的范围内
下面这种更严格的标准化方法也很常见, 而且很有用, 虽然不一定总是必需的:
- 将每个特征分别标准化, 使其平均值为 0:
x -= x.mean(axis=0) - 将每个特征分别标准化, 使其标准差为 1:
x /= x.std(axis=0)
-
处理缺失值
对于神经网络, 将缺失值设置为 0 是安全的, 只要 0 不是一个有意义的值。网络能够从数据中学到 0 意味着缺失数据, 并且会忽略这个值。 -
特征提取
特征工程(feature engineering)是指将数据输入模型之前, 利用你自己关于数据和机器学习算法(这里指神经网络)的知识对数据进行硬编码的变换(不是模型学到的), 以改善模型的效果。
特征工程的本质: 用更简单的方式表述问题, 从而使问题变得更容易。它通常需要深入理解问题。
4.1.3 过拟合
机器学习的根本问题是优化和泛化之间的对立。 优化(optimization)是指调节模型以在训练数据上得到最佳性能(即机器学习中的学习), 而泛化(generalization)是指训练好的模型在前所未见的数据上的性能好坏。
过拟合的另一个定义是, 当我们不断提高训练损失时, 测试损失也在增加。这种情况在神经网络中非常常见。
每当我们训练一个神经网络时, 都必须在训练期间监控训练集和测试集的损失。如果我们有一个非常大的网络来处理一个非常小的数据集(即样本数非常少d) 我们就会观察到, 随着我们不断训练, 训练集和测试集的损失都会减少。但是, 在某个时刻, 测试损失会达到最小值, 之后, 即使训练损失进一步减少, 测试损失也会开始增加。我们必须在验证损失达到最小值时停止训练。
奥卡姆剃刀用简单的话说, 就是不要试图把可以用简单得多的方法解决的事情复杂化。换句话说, 最简单的解决方案就是最具通用性的解决方案。一般来说, 只要你的模型不符合奥卡姆剃刀原则, 就很可能是过拟合。
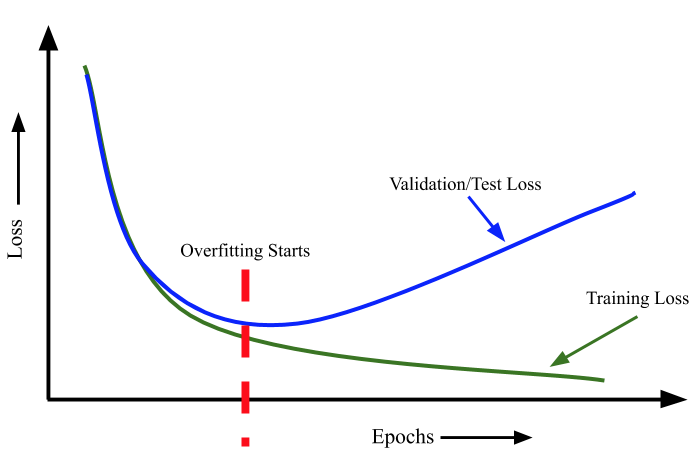
训练开始时, 优化和泛化是相关的: 训练数据上的损失越小, 测试数据上的损失也越小。这时的模型是欠拟合(underfit)的, 即仍有改进的空间, 网络还没有对训练数据中所有相关模式建模。但在训练数据上迭代一定次数之后, 泛化不再提高, 验证指标先是不变, 然后开始变差, 即模型开始过拟合。这时模型开始学习仅和训练数据有关的模式, 但这种模式对新数据来说是错误的或无关紧要的。
降低过拟合的方法叫作正则化(regularization):
4.1.3.1 减小网络大小
即减少模型中可学习参数的个数(这由层数和每层的单元个数决定)
直观上来看, 参数更多的模型拥有更大的记忆容量(memorization capacity), 因此能够在训练样本和目标之间轻松地学会完美的字典式映射, 这种映射没有任何泛化能力。深度学习模型通常都很擅长拟合训练数据, 但真正的挑战在于泛化, 而不是拟合。
要找到合适的模型大小, 一般的工作流程是开始时选择相对较少的层和参数, 然后逐渐增加层的大小或增加新层, 直到这种增加对验证损失的影响变得很小。
4.1.3.2 添加权重正则化
简单模型比复杂模型更不容易过拟合。这里的简单模型(simple model)是指参数值分布的熵更小的模型(或参数更少的模型)。因此, 一种常见的降低过拟合的方法就是强制让模型权重只能取较小的值, 从而限制模型的复杂度, 这使得权重值的分布更加规则(regular)。这种方法叫作权重正则化(weight regularization), 其实现方法是向网络损失函数中添加与较大权重值相关的成本(cost)。
- L1 正则化(L1 regularization): 添加的成本与权重系数的绝对值[权重的 L1 范数(norm)]成正比。
- L2 正则化(L2 regularization): 添加的成本与权重系数的平方(权重的 L2 范数)成正比。
在 Keras 中, 添加权重正则化的方法是向层传递权重正则化项实例(weight regularizerinstance)作为关键字参数。
model.add(layers.Dense(16, kernel_regularizer=regularizers.l2(0.001), activation='relu', input_shape=(10000,)))
l2(0.001) 的意思是该层权重矩阵的每个系数都会使网络总损失增加 0.001 * weight_coefficient_value。注意, 由于这个惩罚项只在训练时添加, 所以这个网络的训练损失会比测试损失大很多。
4.1.3.3 添加 dropout 正则化
dropout 是神经网络最有效也最常用的正则化方法之一, 它是由多伦多大学的 Geoffrey Hinton和他的学生开发的。对某一层使用 dropout, 就是在训练过程中随机将该层的一些输出特征舍弃(设置为 0)。
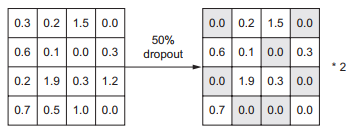
在 Keras 中, 你可以通过 Dropout 层向网络中引入 dropout, dropout 将被应用于前面一层的输出。
model.add(layers.Dropout(0.5))
4.2 为模型选择正确的最后一层激活和损失函数
| 问题类型 | 最后一层激活 | 损失函数 |
|---|---|---|
| 二分类问题 | sigmoid | binary_crossentropy |
| 多分类、单标签问题 | softmax | categorical_crossentropy |
| 多分类、多标签问题 | sigmoid | binary_crossentropy |
| 回归到任意值 | 无 | mse |
| 回归到0~1 范围内的值 | sigmoid | mse 或 binary_crossentrop |
4.3 决策
策略(Policy): a = 𝜋(s)
这里的 a 指的是动作, s 指的是状态, 函数𝜋(跟圆周率没有半点关系)就是用来描述策略的。从形式上看, 策略就像一个函数, 只要输入一个状态 s, 输出一个动作 𝑎。
值函数(Value Function) 来描述并期望尽可能精确地描述这个状态的价值。值函数的表达式可以这样写:
𝑣𝜋(s) = 𝐸𝜋[𝑅ₜ₊₁ + 𝛾𝑅ₜ₊₂ + 𝛾²𝑅ₜ₊₃ +. ..|𝑆ₜ = s]
4.3.1 马尔可夫决策
马尔可夫决策过程(Markov Decision Process, MDP)
5. 深度学习的使用
5.1 深度学习用于计算机视觉
卷积神经网络(convnet), 是计算机视觉应用几乎都在使用的一种深度学习模型。
密集连接层和卷积层的根本区别在于, Dense 层从输入特征空间中学到的是全局模式, 而卷积层学到的是局部模式。
卷积运算, 从局部输入图块中提取特征, 并能够将表示模块化, 同时可以高效地利用数据。这些性质让卷积神经网络在计算机视觉领域表现优异, 同样也让它对序列处理特别有效。时间可以被看作一个空间维度, 就像二维图像的高度或宽度。一维卷积神经网络[通常与空洞卷积核(dilated kernel)一起使用]已经在音频生成和机器翻译领域取得了巨大成功。
卷积神经网络具有以下两个有趣的性质:
- 卷积神经网络学到的模式具有平移不变性(translation invariant)
- 卷积神经网络可以学到模式的空间层次结构(spatial hierarchies of patterns)
对于包含两个空间轴(高度和宽度)和一个深度轴(也叫通道轴)的 3D 张量, 其卷积也叫特征图(feature map)。对于 RGB 图像, 深度轴的维度大小等于 3, 因为图像有 3 个颜色通道: 红色、绿色和蓝色。对于黑白图像(比如 MNIST 数字图像), 深度等于 1(表示灰度等级)。
对于 Keras 的 Conv2D 层, 这些参数都是向层传入的前几个参数: Conv2D(output_depth, (window_height, window_width))。
Keras 中的一维卷积神经网络是 Conv1D 层, 其接口类似于 Conv2D。它接收的输入是形状为 (samples, time, features) 的三维张量, 并返回类似形状的三维张量。卷积窗口是时间轴上的一维窗口(时间轴是输入张量的第二个轴)。
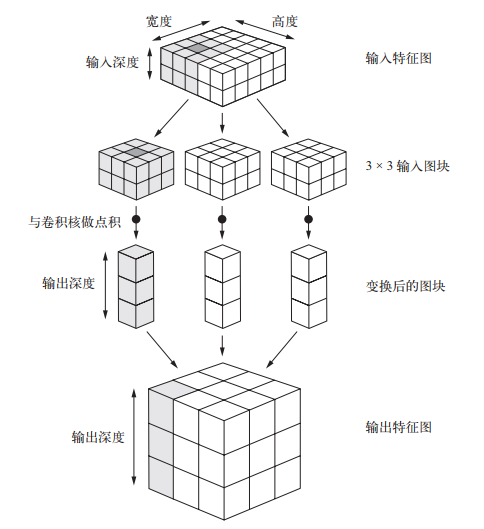
卷积的工作原理: 在 3D 输入特征图上滑动(slide)这些 3x3 或 5x5 的窗口, 在每个可能的位置停止并提取周围特征的 3D 图块[形状为 (window_height, window_width, input_depth)]。然后每个 3D 图块与学到的同一个权重矩阵[叫作卷积核(convolution kernel)]做张量积, 转换成形状为 (output_depth,) 的 1D 向量。然后对所有这些向量进行空间重组, 使其转换为形状为 (height, width, output_depth) 的 3D 输出特征图。输出特征图中的每个空间位置都对应于输入特征图中的相同位置。
5.1.1 边界效应与填充
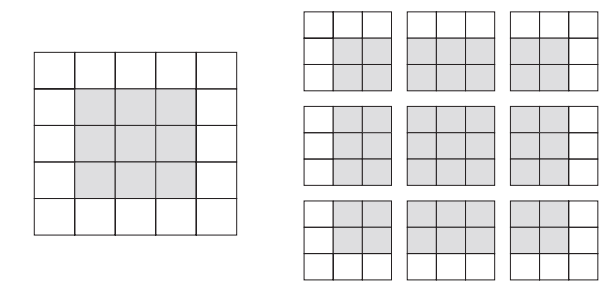
输出的宽度和高度可能与输入的宽度和高度不同。不同的原因可能有两点:
-
边界效应, 可以通过对输入特征图进行填充来抵消
对于 Conv2D 层, 可以通过 padding 参数来设置填充, 这个参数有两个取值: “valid” 表示不使用填充(只使用有效的窗口位置); “same” 表示"填充后输出的宽度和高度与输入相同"。padding 参数的默认值为 “valid”。
-
使用了步幅(stride), 稍后会给出其定义
目前为止, 对卷积的描述都假设卷积窗口的中心方块都是相邻的。但两个连续窗口的距离是卷积的一个参数, 叫作步幅, 默认值为 1。也可以使用步进卷积(strided convolution), 即步幅大于 1 的卷积。
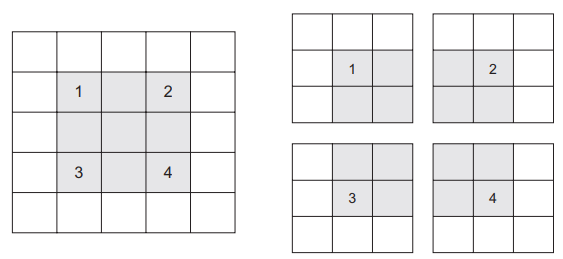
为了对特征图进行下采样, 我们不用步幅, 而是通常使用最大池化(max-pooling)运算
5.1.2 最大池化运算
在每个 MaxPooling2D 层之后, 特征图的尺寸都会减半。这就是最大池化的作用: 对特征图进行下采样, 与步进卷积类似。
最大池化是从输入特征图中提取窗口, 并输出每个通道的最大值。它的概念与卷积类似, 但是最大池化使用硬编码的 max 张量运算对局部图块进行变换, 而不是使用学到的线性变换(卷积核)。最大池化与卷积的最大不同之处在于, 最大池化通常使用 2x2 的窗口和步幅 2, 其目的是将特征图下采样 2 倍。与此相对的是, 卷积通常使用 3×3 窗口和步幅 1。
深度学习模型本质上具有高度的可复用性
5.1.3 数据增强(data augmentation)。
针对于计算机视觉领域的新方法, 在用深度学习模型处理图像时几乎都会用到这种方法。
数据增强是从现有的训练样本中生成更多的训练数据, 其方法是利用多种能够生成可信图像的随机变换来增加(augment)样本。其目标是, 模型在训练时不会两次查看完全相同的图像。这让模型能够观察到数据的更多内容, 从而具有更好的泛化能力。
在 Keras 中, 这可以通过对 ImageDataGenerator 实例读取的图像执行多次随机变换来实现。
from keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
rotation_range = 40,
width_shift_range = 0.2,
height_shift_range = 0.2,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True,
fill_mode = 'nearest')
5.1.4 使用预训练的卷积神经网络
预训练网络(pretrained network)是一个保存好的网络, 之前已在大型数据集(通常是大规模图像分类任务)上训练好。如果这个原始数据集足够大且足够通用, 那么预训练网络学到的特征的空间层次结构可以有效地作为视觉世界的通用模型, 因此这些特征可用于各种不同的计算机视觉问题, 即使这些新问题涉及的类别和原始任务完全不同。这种学到的特征在不同问题之间的可移植性, 是深度学习与许多早期浅层学习方法相比的重要优势, 它使得深度学习对小数据问题非常有效。
使用预训练网络有两种方法: 特征提取(feature extraction)和微调模型(fine-tuning)。
5.1.4.1 特征提取
特征提取是使用之前网络学到的表示来从新样本中提取出有趣的特征。然后将这些特征输入一个新的分类器, 从头开始训练。
对于卷积神经网络而言, 特征提取就是取出之前训练好的网络的卷积基, 在上面运行新数据, 然后在输出上面训练一个新的分类器。
某个卷积层提取的表示的通用性(以及可复用性)取决于该层在模型中的深度。模型中更靠近底部的层提取的是局部的、高度通用的特征图(比如视觉边缘、颜色和纹理), 而更靠近顶部的层提取的是更加抽象的概念(比如"猫耳朵"或"狗眼睛")。因此, 如果你的新数据集与原始模型训练的数据集有很大差异, 那么最好只使用模型的前几层来做特征提取, 而不是使用整个卷积基。
- 在你的数据集上运行卷积基, 将输出保存成硬盘中的 Numpy 数组, 然后用这个数据作为输入, 输入到独立的密集连接分类器中
import numpy as np
datagen = ImageDataGenerator(rescale=1./255)
batch_size = 20
def extract_features(directory, sample_count):
features = np.zeros(shape=(sample_count, 4, 4, 512))
labels = np.zeros(shape=(sample_count))
generator = datagen.flow_from_directory(
directory,
target_size = (150, 150),
batch_size = batch_size,
class_mode = 'binary')
i = 0
for inputs_batch, labels_batch in generator:
features_batch = conv_base.predict(inputs_batch)
features[i*batch_size: (i+1)*batch_size] = features_batch
labels[i*batch_size: (i+1)*batch_size] = labels_batch
i+=1
if i*batch_size >= sample_count:
break
return features, labels
train_features, train_labels = extract_features(train_dir, 2000)
validation_features, validation_labels = extract_features(validation_dir, 1000)
test_features, test_labels = extract_features(test_dir, 1000)
- 在顶部添加 Dense 层来扩展已有模型(即 conv_base), 并在输入数据上端到端地运行整个模型
from keras.applications import VGG16
conv_base = VGG16(weights='imagenet', include_top=False, input_shape=(150, 150, 3))
model = models.Sequential()
model.add(conv_base)
model.add(layers.Flatten())
model.add(layers.Dense(256, activation='relu'))
# model.add(layers.Dropout(0.5))
model.add(layers.Dense(1, activation='sigmoid'))
在编译和训练模型之前, 一定要"冻结"卷积基。 冻结(freeze)一个或多个层是指在训练过程中保持其权重不变。如果不这么做, 那么卷积基之前学到的表示将会在训练过程中被修改。因为其上添加的 Dense 层是随机初始化的, 所以非常大的权重更新将会在网络中传播, 对之前学到的表示造成很大破坏。为了让这些修改生效, 你必须先编译模型。如果在编译之后修改了权重的 trainable 属性, 那么应该重新编译模型, 否则这些修改将被忽略。
conv_base.trainable = False
5.1.4.2 微调模型
微调是指将其顶部的几层"解冻", 并将这解冻的几层和新增加的部分联合训练。之所以叫作微调, 是因为它只是略微调整了所复用模型中更加抽象的表示, 以便让这些表示与手头的问题更加相关。
微调网络的步骤如下
- 在已经训练好的基网络(base network)上添加自定义网络
- 冻结基网络
- 训练所添加的部分
- 解冻基网络的一些层
- 联合训练解冻的这些层和添加的部分
卷积神经网络中每一层都学习一组过滤器, 以便将其输入表示为过滤器的组合。这类似于傅里叶变换将信号分解为一组余弦函数的过程。随着层数的加深, 卷积神经网络中的过滤器变得越来越复杂, 越来越精细。
5.2 深度学习用于文本和序列
深度学习模型处理文本(可以将其理解为单词序列或字符序列)、时间序列和一般的序列数据。用于处理序列的两种基本的深度学习算法分别是循环神经网络(recurrent neural network)和一维卷积神经网络(1D convnet)。
5.2.1 文本处理
深度学习用于自然语言处理是将模式识别应用于单词、句子和段落, 这与计算机视觉是将模式识别应用于像素大致相同。
文本向量化(vectorize)是指将文本转换为数值张量的过程。它有多种实现方法:
- 将文本分割为单词, 并将每个单词转换为一个向量
- 将文本分割为字符, 并将每个字符转换为一个向量
- 提取单词或字符的 n-gram, 并将每个 n-gram 转换为一个向量。 n-gram 是多个连续单词或字符的集合(n-gram 之间可重叠)
n-gram 是从一个句子中提取的 N 个(或更少)连续单词的集合。这一概念中的"单词" 也可以替换为"字符"。
在使用轻量级的浅层文本处理模型时(比如 logistic 回归和随机森林), n-gram 是一种功能强大、不可或缺的特征工程工具。
将文本分解而成的单元(单词、字符或 n-gram)叫作标记(token), 将文本分解成标记的过程叫作分词(tokenization)。所有文本向量化过程都是应用某种分词方案, 然后将数值向量与生成的标记相关联。
- 对标记做 one-hot 编码(one-hot encoding)
- 标记嵌入(token embedding, 通常只用于单词, 叫作词嵌入word embedding)
Keras 的内置函数可以对原始文本数据进行单词级或字符级的 one-hot 编码。它们实现了许多重要的特性, 比如从字符串中去除特殊字符、只考虑数据集中前 N 个最常见的单词(这是一种常用的限制, 以避免处理非常大的输入向量空间)。
one-hot 编码得到的向量是二进制的、稀疏的(绝大部分元素都是 0)、维度很高的(维度大小等于词表中的单词个数), 而词嵌入是低维的浮点数向量(即密集向量, 与稀疏向量相对)。与 one-hot 编码得到的词向量不同, 词嵌入是从数据中学习得到的。常见的词向量维度是 256、 512 或 1024(处理非常大的词表时)。与此相对, onehot 编码的词向量维度通常为 20 000 或更高(对应包含 20 000 个标记的词表)。因此, 词向量可以将更多的信息塞入更低的维度中。获取词嵌入有两种方法:
- 在完成主任务(比如文档分类或情感预测)的同时学习词嵌入
- 在不同于待解决问题的机器学习任务上预计算好词嵌入, 然后将其加载到模型中
词嵌入的作用应该是将人类的语言映射到几何空间中。一般来说, 任意两个词向量之间的几何距离(比如 L2 距离)应该和这两个词的语义距离有关(表示不同事物的词被嵌入到相隔很远的点, 而相关的词则更加靠近)。除了距离, 你可能还希望嵌入空间中的特定方向也是有意义的。
在真实的词嵌入空间中, 常见的有意义的几何变换的例子包括"性别"向量和"复数"向量。例如, 将 king(国王)向量加上 female(女性)向量, 得到的是 queen(女王) 向量。
有许多预计算的词嵌入数据库, 你都可以下载并在 Keras 的 Embedding 层中使用。word2vec 就是其中之一。另一个常用的是 GloVe(global vectors for word representation, 词表示全局向量), 由斯坦福大学的研究人员于 2014 年开发。
5.2.2 理解循环神经网络
要想处理数据点的序列或时间序列, 你需要向网络同时展示整个序列, 即将序列转换成单个数据点。这种网络叫作前馈网络(feedforward network)。
循环神经网络(RNN, recurrent neural network): 它处理序列的方式是, 遍历所有序列元素, 并保存一个状态(state), 其中包含与已查看内容相关的信息。实际上, RNN 是一类具有内部环的神经网络。
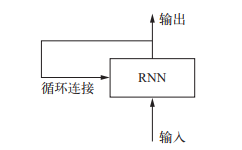
RNN 的关键点之一就是他们可以用来连接先前的信息到当前的任务上. 总之, RNN 是一个 for 循环, 它重复使用循环前一次迭代的计算结果, 仅此而已。
与 Keras 中的所有循环层一样, SimpleRNN 可以在两种不同的模式下运行: 一种是返回每个时间步连续输出的完整序列, 即形状为 (batch_size, timesteps, output_features)的三维张量; 另一种是只返回每个输入序列的最终输出, 即形状为(batch_size, output_features) 的二维张量。这两种模式由 return_sequences 这个构造函数参数来控制。为了提高网络的表示能力, 将多个循环层逐个堆叠有时也是很有用的。
model = Sequential()
model.add(Embedding(10000, 32))
model.add(SimpleRNN(32, return_sequences=True))
model.add(SimpleRNN(32, return_sequences=True))
model.add(SimpleRNN(32, return_sequences=True))
model.summary()
SimpleRNN 不擅长处理长序列, 比如文本。SimpleRNN 并不是 Keras 中唯一可用的循环层, 还有另外两个: LSTM 和 GRU。在实践中总会用到其中之一, 因为 SimpleRNN 通常过于简化, 没有实用价值。
长短期记忆(LSTM, long short-term memory)算法由 Hochreiter和 Schmidhuber 在 1997 年开发, 是二人研究梯度消失问题的重要成果。 LSTM 通过刻意的设计来避免长期依赖问题。 记住长期的信息在实践中是LSTM的默认行为, 而非需要付出很大代价才能获得的能力!
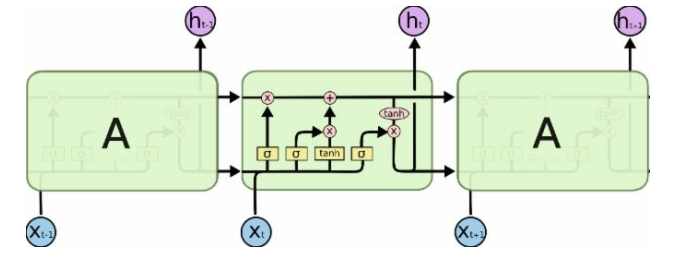
LSTM 通过刻意的设计来避免长期依赖问题。 记住长期的信息在实践中是LSTM的默认行为, 而非需要付出很大代价才能获得的能力!
LSTM 的原理: 它保存信息以便后面使用, 从而防止较早期的信号在处理过程中逐渐消失。
5.2.3 循环神经网络的高级用法
-
循环 dropout(recurrent dropout)。这是一种特殊的内置方法, 在循环层中使用 dropout来降低过拟合
2015 年, 在关于贝叶斯深度学习的博士论文中, Yarin Gal 确定了在循环网络中使用 dropout 的正确方法: 对每个时间步应该使用相同的 dropout 掩码(dropoutmask, 相同模式的舍弃单元), 而不是让 dropout 掩码随着时间步的增加而随机变化。此外, 为了对 GRU、 LSTM 等循环层得到的表示做正则化, 应该将不随时间变化的 dropout 掩码应用于层的内部循环激活(叫作循环 dropout 掩码)。
使用 dropout正则化的网络总是需要更长的时间才能完全收敛, 所以网络训练轮次增加为原来的 2 倍。 -
堆叠循环层(stacking recurrent layers)。这会提高网络的表示能力(代价是更高的计算负荷)
增加网络容量的通常做法是增加每层单元数或增加层数。循环层堆叠(recurrent layer stacking)是构建更加强大的循环网络的经典方法。
在 Keras 中逐个堆叠循环层, 所有中间层都应该返回完整的输出序列(一个 3D 张量), 而不是只返回最后一个时间步的输出。这可以通过指定 return_sequences=True 来实现。 -
双向循环层(bidirectional recurrent layer)。将相同的信息以不同的方式呈现给循环网络, 可以提高精度并缓解遗忘问题
双向 RNN 是一种常见的RNN 变体, 它在某些任务上的性能比普通 RNN 更好。它常用于自然语言处理, 可谓深度学习对自然语言处理的瑞士军刀。
门控循环单元(GRU, gated recurrent unit)层的工作原理与 LSTM 相同。但它做了一些简化, 因此运行的计算代价更低(虽然表示能力可能不如 LSTM)。机器学习中到处可以见到这种计算代价与表示能力之间的折中。
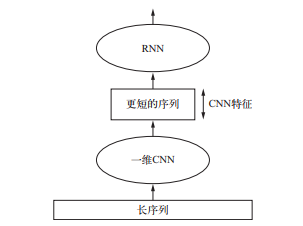
5.2.4 结合CNN 与 RNN
要想结合卷积神经网络的速度和轻量与 RNN 的顺序敏感性, 一种方法是在 RNN 前面使用一维卷积神经网络作为预处理步骤。对于那些非常长, 以至于 RNN 无法处理的序列(比如包含上千个时间步的序列), 这种方法尤其有用。卷积神经网络可以将长的输入序列转换为高级特征组成的更短序列(下采样)。然后, 提取的特征组成的这些序列成为网络中 RNN 的输入。
5.2.5 其他
- RNN(循环神经网络): 它们逐步处理数据, 将信息从一个步骤传递到下一个步骤。把它们想象成一次一个字地读一个句子, 记住之前发生的事情。他们擅长处理序列, 但速度可能很慢, 并且难以处理长序列。
- CNN(卷积神经网络): 最初是为图像构建的, 但有时也用于文本。他们专注于学习当地模式。F或示例, 检测文本中的小块或短语。在某些情况下, 它们比 RNN 更快, 但依赖关系更长仍然有限制。
- 序列转导模型(如 Seq2Seq 模型): 这些模型接受一个序列并产生另一个序列。经典例子?翻译和总结。你给它一个句子, 它会用另一种语言或更短的版本输出一个新句子。
5.3 生成式深度学习
5.3.1 LSTM 算法
用循环网络生成序列数据的成功应用在 2016 年才开始出现在主流领域。但是, 这些技术都有着相当长的历史, 最早的是 1997 年开发的 LSTM 算法。这一新算法早期用于逐字符地生成文本。
5.3.2 DeepDream
DeepDream 是一种艺术性的图像修改技术, 它用到了卷积神经网络学到的表示。 DeepDream由 Google 于 2015 年夏天首次发布, 使用 Caffe 深度学习库编写实现(当时比 TensorFlow 的首次公开发布要早几个月)。
是反向运行一个卷积神经网络: 对卷积神经网络的输入做梯度上升, 以便将卷积神经网络靠顶部的某一层的某个过滤器激活最大化。
Keras 中有许多这样的卷积神经网络: VGG16、 VGG19、 Xception、 ResNet50 等。
5.3.3 神经风格迁移
神经风格迁移(neural style transfer), 它由 Leon Gatys 等人于 2015 年夏天提出。
神经风格迁移是指将参考图像的风格应用于目标图像, 同时保留目标图像的内容。
实现风格迁移背后的关键概念与所有深度学习算法的核心思想是一样的: 定义一个损失函数来指定想要实现的目标, 然后将这个损失最小化。
如果我们能够在数学上给出内容和风格的定义, 那么就有一个适当的损失函数, 我们将对其进行最小化:
loss = distance(style(reference_image) - style(generated_image)) +
distance(content(original_image) - content(generated_image))
Gatys 等人发现了一个很重要的观察结果, 就是深度卷积神经网络能够从数学上定义 style 和 content 两个函数。
内容损失的一个很好的候选者就是两个激活之间的 L2 范数, 一个激活是预训练的卷积神经网络更靠顶部的某层在目标图像上计算得到的激活, 另一个激活是同一层在生成图像上计算得到的激活。
内容损失只使用了一个更靠顶部的层, 但 Gatys 等人定义的风格损失则使用了卷积神经网络的多个层。对于风格损失, Gatys 等人使用了层激活的格拉姆矩阵(Gram matrix), 即某一层特征图的内积。这个内积可以被理解成表示该层特征之间相互关系的映射。这些特征相互关系抓住了在特定空间尺度下模式的统计规律, 从经验上来看, 它对应于这个尺度上找到的纹理的外观。
5.3.4 变分自编码器(VAE, variational autoencoder)
从图像的潜在空间中采样, 并创建全新图像或编辑现有图像, 这是目前最流行也是最成功的创造性人工智能应用。
图像生成的关键思想就是找到一个低维的表示潜在空间(latent space, 也是一个向量空间), 其中任意点都可以被映射为一张逼真的图像。能够实现这种映射的模块, 即以潜在点作为输入并输出一张图像(像素网格), 叫作生成器(generator, 对于 GAN 而言)或解码器(decoder, 对于 VAE 而言)。 一旦找到了这样的潜在空间, 就可以从中有意地或随机地对点进行采样, 并将其映射到图像空间, 从而生成前所未见的图像。
概念向量(concept vector): 给定一个表示的潜在空间或一个嵌入空间, 空间中的特定方向可能表示原始数据中有趣的变化轴。
自编码器由 Kingma 和 Welling 于2013年12月与 Rezende、 Mohamed 和 Wierstra 于2014年1月同时发现, 它是一种生成式模型, 特别适用于利用概念向量进行图像编辑的任务。它是一种现代化的自编码器, 将深度学习的想法与贝叶斯推断结合在一起。自编码器是一种网络类型, 其目的是将输入编码到低维潜在空间, 然后再解码回来。
VAE 不是将输入图像压缩成潜在空间中的固定编码, 而是将图像转换为统计分布的参数, 即平均值和方差。本质上来说, 这意味着我们假设输入图像是由统计过程生成的, 在编码和解码过程中应该考虑这一过程的随机性。然后, VAE 使用平均值和方差这两个参数来从分布中随机采样一个元素, 并将这个元素解码到原始输入。
VAE 的参数通过两个损失函数来进行训练: 一个是重构损失(reconstruction loss), 它迫使解码后的样本匹配初始输入; 另一个是正则化损失(regularization loss), 它有助于学习具有良好结构的潜在空间, 并可以降低在训练数据上的过拟合。
大规模名人人脸属性(CelebA)数据集。
5.3.5 生成式对抗网络(GAN, generative adversarial network)
生成式对抗网络(GAN, generative adversarial network)由 Goodfellow 等人于2014年提出, 它可以替代 VAE 来学习图像的潜在空间。它能够迫使生成图像与真实图像在统计上几乎无法区分, 从而生成相当逼真的合成图像。
GAN 的工作原理: 一个伪造者网络和一个专家网络, 二者训练的目的都是为了打败彼此。因此, GAN 由以下两部分组成:
- 生成器网络(generator network): 它以一个随机向量(潜在空间中的一个随机点)作为输入, 并将其解码为一张合成图像
- 判别器网络(discriminator network)或对手(adversary): 以一张图像(真实的或合成的均可)作为输入, 并预测该图像是来自训练集还是由生成器网络创建
深度卷积生成式对抗网络(DCGAN, deep convolutional GAN), 即生成器和判别器都是深度卷积神经网络的 GAN。特别地, 它在生成器中使用 Conv2DTranspose 层进行图像上采样。
6. 深度学习的思考和局限性
6.1 思考
6.1.1 深度学习中的表示瓶颈
任何信息的丢失都是永久性的。残差连接可以将较早的信息重新注入到下游数据中, 从而部分解决了深度学习模型的这一问题。
6.1.2 深度学习中的梯度消失
反向传播是用于训练深度神经网络的主要算法, 其工作原理是将来自输出损失的反馈信号向下传播到更底部的层。如果这个反馈信号的传播需要经过很多层, 那么信号可能会变得非常微弱, 甚至完全丢失, 导致网络无法训练。这个问题被称为梯度消失(vanishing gradient)。
残差连接在前馈深度网络中的工作原理与此类似, 但它更加简单: 它引入了一个纯线性的信息携带轨道, 与主要的层堆叠方向平行, 从而有助于跨越任意深度的层来传播梯度。
6.1.3 超参数优化
构建深度学习模型时, 你必须做出许多看似随意的决定: 应该堆叠多少层?每层应该包含多少个单元或过滤器?激活应该使用 relu 还是其他函数?在某一层之后是否应该使用BatchNormalization ?应该使用多大的 dropout 比率?还有很多。这些在架构层面的参数叫作超参数(hyperparameter), 以便将其与模型参数区分开来, 后者通过反向传播进行训练。
超参数优化的过程通常如下所示:
- 选择一组超参数(自动选择)
- 构建相应的模型
- 将模型在训练数据上拟合, 并衡量其在验证数据上的最终性能
- 选择要尝试的下一组超参数(自动选择)
- 重复上述过程
- 最后, 衡量模型在测试数据上的性能
有多种不同的技术可供选择: 贝叶斯优化、遗传算法、简单随机搜索等。
通常情况下, 随机搜索(随机选择需要评估的超参数, 并重复这一过程)就是最好的解决方案, 虽然这也是最简单的解决方案。但我发现有一种工具确实比随机搜索更好, 它就是Hyperopt。它是一个用于超参数优化的 Python 库, 其内部使用 Parzen 估计器的树来预测哪组超参数可能会得到好的结果。另一个叫作 Hyperas 的库将 Hyperopt 与 Keras 模型集成在一起。
6.2 局限性
对于深度学习可以实现的应用, 其可能性空间几乎是无限的。但是, 对于当前的深度学习技术, 许多应用是完全无法实现的, 即使拥有大量人工标注的数据也无法实现。
一般来说, 任何需要推理(比如编程或科学方法的应用)、长期规划和算法数据处理的东西, 无论投入多少数据, 深度学习模型都无法实现。
深度学习模型从输入到输出的简单几何变形与人类思考和学习的方式之间存在根本性的区别。
6.3 其他常见的问题
6.3.1 梯度消失与梯度爆炸
深度神经网络训练的时候, 采用反向传播方式, 该方式背后其实是链式求导, 计算每层梯度的时候会涉及一些连乘操作, 因此如果网络过深, 那么如果连乘的因子大部分小于 1, 最后乘积可能趋于 0; 另一方面, 如果连乘的因子大部分大于 1, 最后乘积可能趋于无穷。这就是所谓的梯度消失与梯度爆炸。
6.3.2 梯度消失问题
由于反向传播使用链式规则来计算梯度(通过微分), 朝向 n 层神经网络的"前"(输入)层将使其修改的梯度以一个较小的值乘以 n 次方, 然后再更新之前的固定值。这意味着梯度将指数性减小。 n 越大, 网络将需要越来越多的时间来有效地训练。
