
目录
RAG 顾名思义就是: Retrieval Augmented Generation, 即使用 LLM 生成, 它由严格编程的自动化流程或代理辅助的自动化流程辅助, 这些流程收集、操作并向系统提供数据。RAG 不是 Vector DB 技术, 而是一个定义松散的概念, 描述了自动化系统协助 LLM 生成的过程, 并且可以使用数据库(如 vector dbs、sql dbs 甚至普通文件)来增强其操作。
在实验性大型语言模型(LLM)领域, 创建引人入胜的 LLM 最小可行产品(MVP)相对简单, 但实现生产级性能可能是一项艰巨的任务, 尤其是在构建用于上下文学习的高性能检索增强生成(RAG)管道时。
RAG 是一个提高模型性能的框架, 通过使用基础模型之外的相关数据增强提示, 将 LLM 响应建立在真实、可信的信息之上。用户可以轻松地将他们的公司文档"拖放"到向量数据库中, 使 LLM 能够有效地回答有关这些文档的问题。
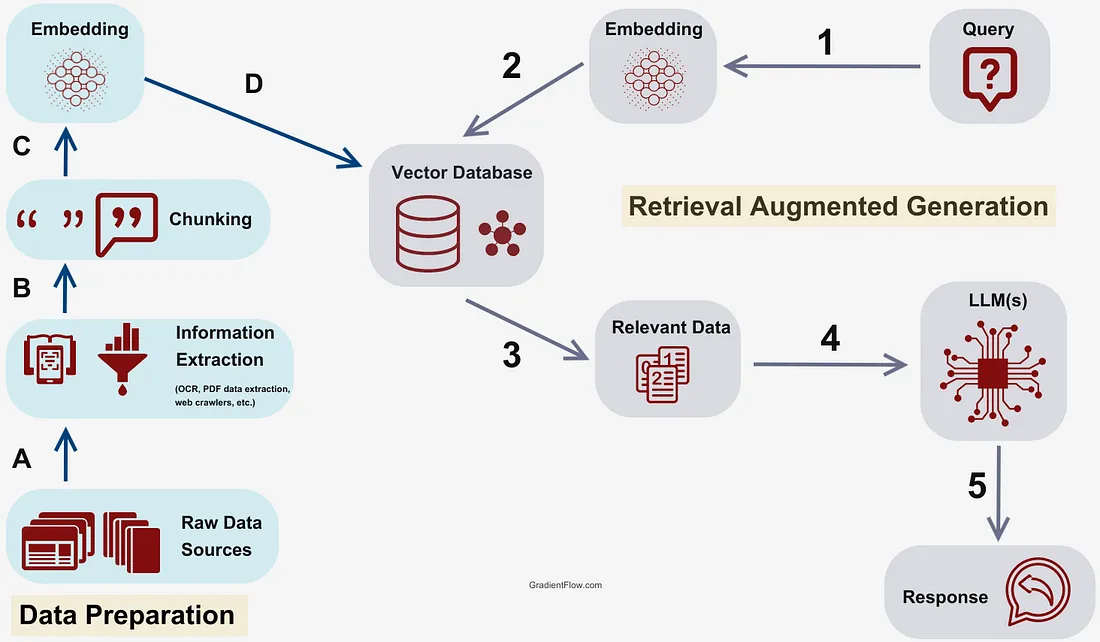
1. RAG
在讨论RAG中的有效信息检索时, 理解"相关性"和"相似性"之间的区别至关重要。相似性是关于单词匹配的相似性, 而相关性是关于思想的联系。您可以使用矢量数据库查询来识别语义上接近的内容, 但识别和检索相关内容需要更复杂的工具。
1.1 架构
RAG 架构主要有三种类型:朴素、模块化和高级 RAG。
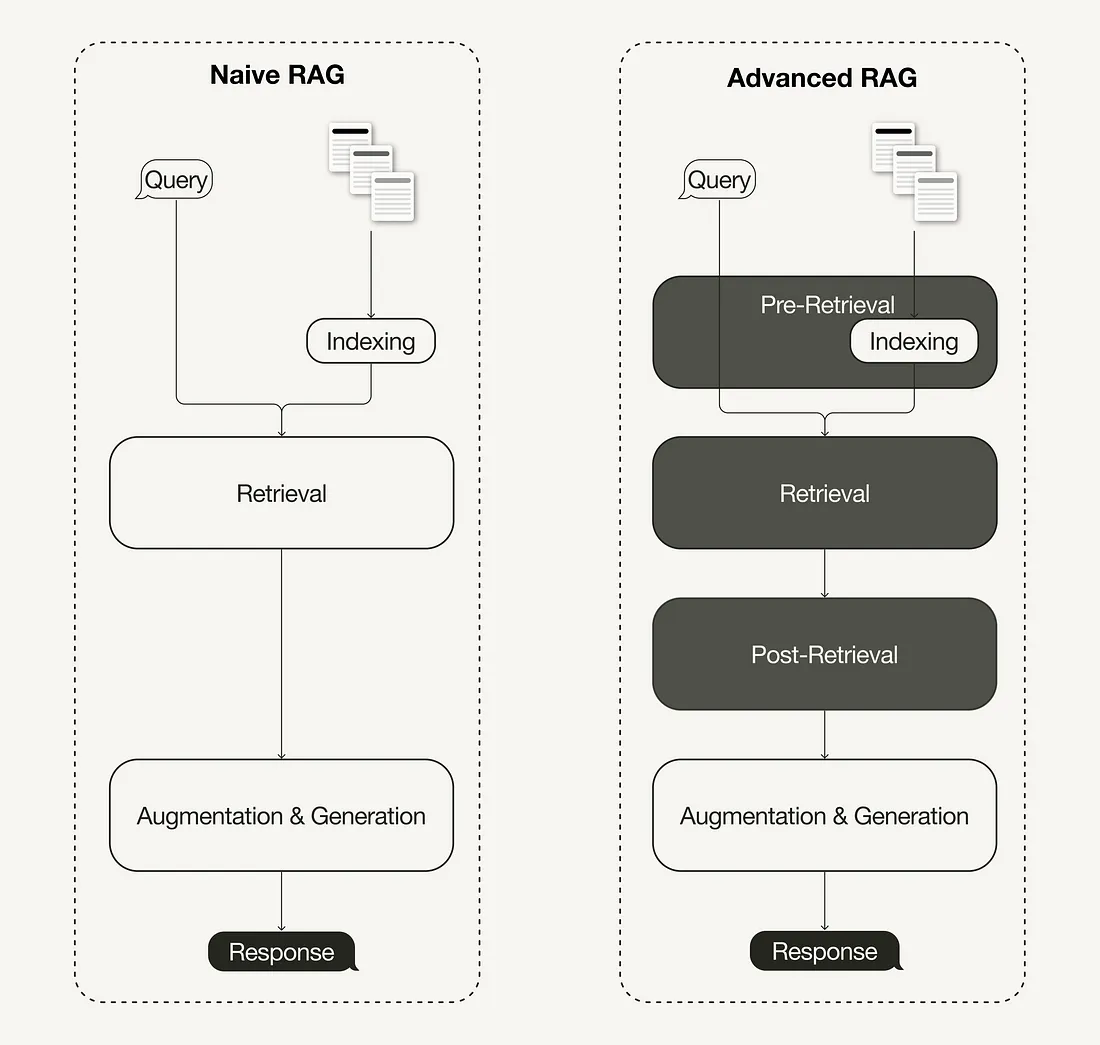
1.1.1 Naive RAG
采用像 GPT-3 这样的单体模型, 并简单地将其限制在检索到的证据段落上, 并将它们附加到输入上下文中。这种方法很简单, 但存在效率和连贯性问题。
Naive RAG(或简单的 RAG)是更复杂系统背后的基本概念。它涉及使用检索机制增强语言模型的功能, 使其能够访问外部数据源以提供更明智的响应。虽然 Naive RAG 对基本应用程序可能有效, 但它通常缺乏企业使用所需的复杂性。这种限制主要是由于它依赖于单一检索方法, 这会导致瓶颈和响应准确性降低。
此外, Naive RAG 没有采用多模态检索或动态上下文适应等高级技术, 这些技术对于处理各种数据类型和不断变化的用户需求至关重要。因此, 在需要细致入微的理解或实时更新的场景中, 其性能可能会下降。为了克服这些挑战, 开发人员通常会转向更高级的 RAG 模型, 这些模型集成了多种检索策略并利用上下文嵌入, 从而提高了生成响应的相关性和准确性。这种演变允许用户和 AI 系统之间实现更强大的交互, 尤其是在复杂环境中。
1.1.2 模块化 RAG
将系统分解为显式检索器、重新排序器和生成器模块。这提供了更大的灵活性和专业化。
1.1.3 Advanced RAG
高级 RAG 在每个阶段都采用更复杂的工具和方法嵌入模型、分块策略、LLM、混合搜索、重新排名、检索方法等, 以获得更简洁和上下文相关的响应。通过高阶检索器、交叉编码器重新排序器和证据操作架构等创新进一步增强了每个模块。它解锁了更高的准确性和可扩展性。
1.2 技术实施
1.2.1 分块策略
在自然语言处理的上下文中, “分块"是指将文本分割成小的、简洁的、有意义的"块”。与大型文档相比, RAG 系统可以更快、更准确地定位较小文本块中的相关上下文。
- 分块策略的有效性很大程度上取决于这些块的质量和结构。
- 确定最佳块大小是为了取得平衡–在不牺牲速度的情况下捕获所有基本信息。
- 分块的主要原因是确保我们嵌入的内容具有尽可能少的噪音, 并且在语义上仍然相关。
块的大小是一个需要考虑的参数, 它取决于你使用的嵌入模型及其在令牌中的容量、标准转换器编码器模型。
虽然较大的块可以捕获更多的上下文, 但它们会引入更多的噪音, 并且需要更多的时间和计算成本来处理。较小的块具有较少的噪声, 但可能无法完全捕获必要的上下文。重叠块是平衡这两个约束的一种方式。通过重叠块, 查询可能会在多个向量中检索足够的相关数据, 以便生成适当的上下文化响应。
一个限制是, 此策略假定必须在单个文档中找到必须检索的所有信息。如果所需的上下文被拆分为多个不同的文档, 您可能需要考虑利用文档层次结构和知识图谱等解决方案。
-
NLTK:
from langchain.text_splitter import NLTKTextSplitter -
spaCy:
from langchain.text_splitter import SpacyTextSplitter -
递归分块:
from langchain.text_splitter import RecursiveCharacterTextSplitter -
专用分块:
- Markdown:
from langchain.text_splitter import MarkdownTextSplitter - LaTeX:
from langchain.text_splitter import LatexTextSplitter
- Markdown:
-
语义分块
如何更好地捕获有意义的 chunk, 而不仅仅是某个长度的 chunk。这种方法称为语义分块。让我们使用 Flair 来检测句子边界或特定实体并创建有意义的块。使用 SegtokSentenceSplitter 将文本拆分为句子, 这可确保在有意义的边界处拆分文本。我们保持大小调整逻辑不变, 进行分组, 直到达到chunk_overlap的chunk_size重叠和重叠, 以确保保持上下文。 -
嵌入分块
在这种方法中, 我们首先拆分为句子, 并根据我们稍后将用于 RAG 检索的相同嵌入模型形成块。 -
代理分块
Embedding Chunking有一个主要缺点: 它无法理解文本的语义。“I Like You"与 “I Like You"对 “like"的讽刺, 这两个句子将具有相同的嵌入, 因此在计算时将对应于相同的余弦距离。这就是 Agentic(或基于 LLM)分块派上用场的地方。它分析内容, 以根据独立性和语义一致性确定逻辑中断点。
1.2.2 文档层次结构
文档层次结构是组织数据以改进信息检索的一种强大方法。您可以将文档层次结构视为 RAG 系统的目录。它以结构化的方式组织块, 使 RAG 系统能够有效地检索和处理相关的相关数据。文档层次结构在 RAG 的有效性中起着至关重要的作用, 它可以帮助 LLM 决定哪些块包含要提取的最相关数据。
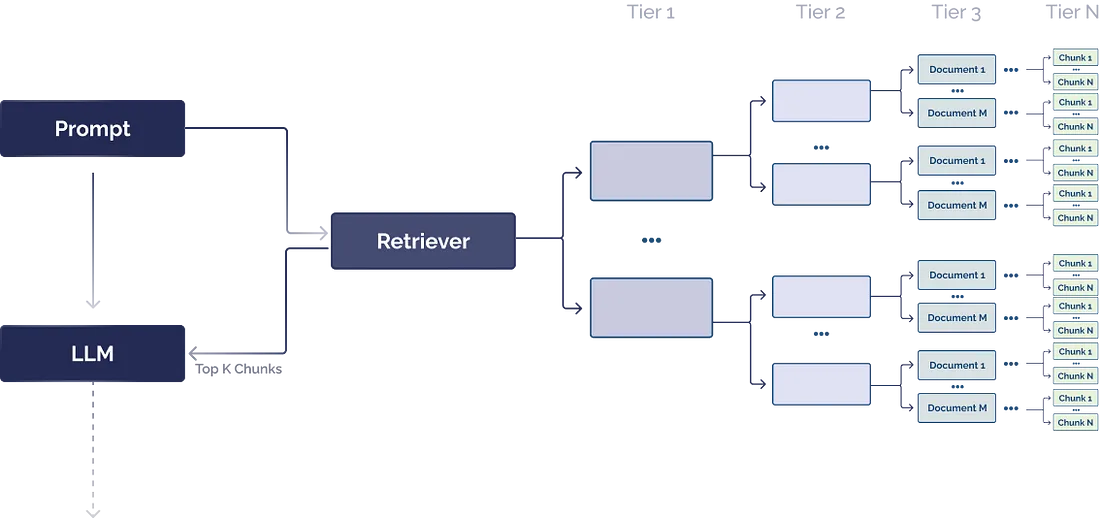
将文档层次结构视为目录或文件目录。尽管 LLM 可以从矢量数据库中提取相关的文本块, 但您可以通过使用文档层次结构作为预处理步骤来查找最相关的文本块来提高检索的速度和可靠性。此策略提高了检索的可靠性、速度和可重复性, 并有助于减少由于块提取问题而导致的幻觉。文档层次结构可能需要特定领域或特定问题的专业知识来构建, 以确保摘要与手头的任务完全相关。
应该越来越清楚的是, 构建 RAG 系统的大部分工作都是理解非结构化数据, 并添加额外的上下文护栏, 使 LLM 能够进行更具确定性的信息提取。我认为这类似于需要给实习生的指导, 让他们在开始工作时准备好如何通过数据语料库进行推理。像实习生一样, LLM 可以理解文档中的单个单词, 以及它们与所问问题的相似之处, 但它不知道拼凑出上下文化答案所需的首要原则。
1.2.3 知识图谱
知识图谱不仅仅是数据存储;它们也可以是推理结构。
知识图谱是文档层次结构的一个很好的数据框架, 可以强制保持一致性。知识图谱是概念和实体之间关系的确定性映射。与向量数据库中的相似性搜索不同, 知识图谱可以一致、准确地检索相关规则和概念, 并大大减少幻觉。使用知识图谱映射文档层次结构的好处是, 您可以将信息检索工作流映射到 LLM 可以遵循的指令中。(即要回答 X 问题, 我知道我需要从文档 A 中提取信息, 然后将 X 与文档 B 进行比较)
知识图谱使用自然语言映射关系, 这意味着即使是非技术用户也可以构建和修改规则和关系来控制他们的企业 RAG 系统。例如, 规则可以如下所示: “在回答有关休假政策的问题时, 首先参考正确办公室的人力资源政策文档, 然后在文档中查看假期部分。
1.2.4 查询增强
查询增强解决了措辞不当的问题, 这是我们在这里讨论的 RAG 中的一个常见问题。我们在这里要解决的是确保任何缺少特定细微差别的问题都得到适当的上下文, 以最大限度地提高相关性。
措辞不当的问题通常是由于语言的复杂性。例如, 根据使用该词的上下文, 单个词可能表示两种不同的东西。正如 Agustinus(CarSales.AU的AI 主管)所指出的那样, 这在很大程度上是一个特定领域的问题。考虑这个例子: “fried chicken"更类似于"chicken soup"还是"fried rice”? 答案因情况而异。如果以食材为重点, “fried chicken"与"chicken soup"最接近。但从准备的角度来看, 它更接近于"fried rice”。这种解释是以领域为中心的。
1.2.5 查询规划
查询规划表示生成子问题的过程, 这些子问题需要正确地进行上下文化和生成答案, 这些答案在组合时可以完全回答原始问题。此添加相关上下文的过程在原则上与查询增强类似。
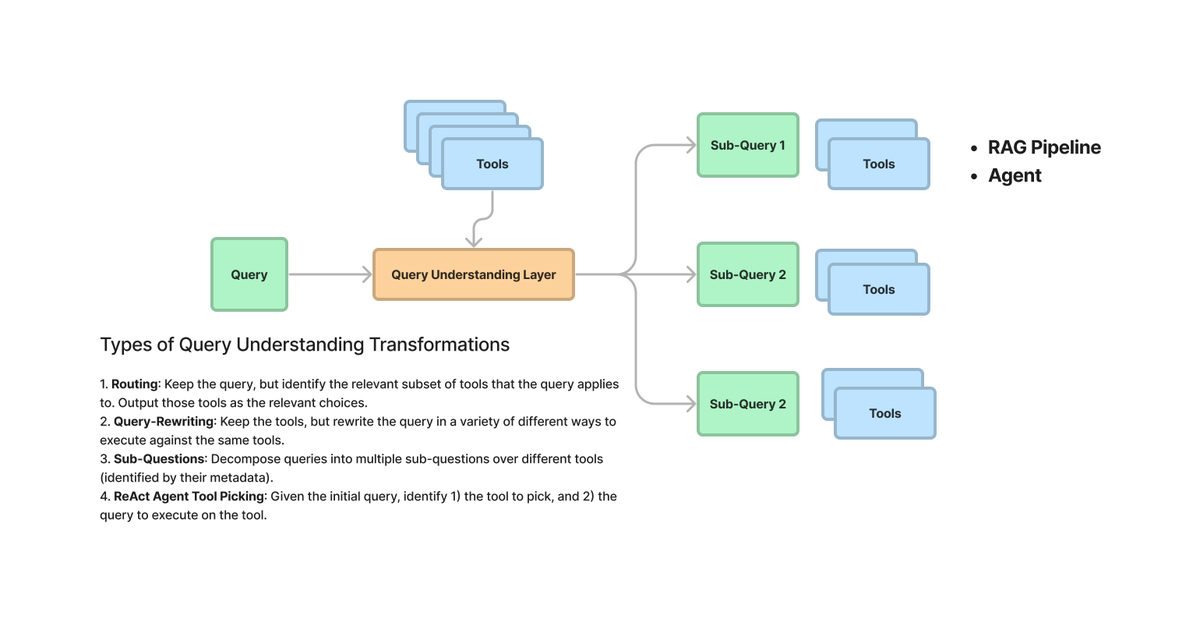
鉴于 LLM 的状态, 人们应该只在 LLM 失败时寻求外部推理规则的干预, 而不是寻求重新创建每个可能的子问题。
- Multi-Query 策略
- Decomposition Query
是一种将查询中的复杂任务分解为更小、更简单、更容易解决的子任务或部分的方法。之后, 我们合并这些答案, 要么递归求解它们, 要么单独解决它们。
1.2.6 多跳推理
构建多跳检索时出现的问题:
- 数据集成和质量: 互连的数据源必须具有高质量、相关性和最新性, 这一点至关重要。不良或有偏见的数据可能导致不准确的多步骤结论。
- 上下文理解和链接: 系统不仅要理解每个查询和子查询, 还要理解它们如何连接以形成一个连贯的整体。这涉及高级自然语言理解, 以辨别不同信息之间的微妙联系。
- 用户意图识别: 识别用户的潜在意图以及它如何随着每个跃点而演变是关键。系统应根据查询的演变性质调整其检索策略。这与查询扩充有显著重叠。
与向量数据库相比, 使用知识图谱进行查询增强的一个优点是, 知识图谱可以对已知关系的某些关键主题和概念强制执行一致的检索。在增强响应步骤中, RAG 系统可以自动包含某些警告或相关概念, 每当答案包含特定药物、疾病或概念时, 这些警告或相关概念都是必需的。
1.3 优化
1.3.1 检索前优化
检索前优化侧重于数据索引优化以及查询优化。数据索引优化技术旨在以有助于提高检索效率的方式存储数据:
- 滑动窗口使用块之间的重叠, 是最简单的技术之一。
- 增强数据粒度应用数据清理技术, 例如删除不相关的信息、确认事实准确性、更新过时信息等。
- 添加元数据, 例如日期、目的或章节, 以便进行筛选。
- 优化索引结构涉及对数据进行索引的不同策略, 例如调整块大小或使用多索引策略。我们将在本文中实现的一种技术是句子窗口检索, 它嵌入单个句子进行检索, 并在推理时将其替换为更大的文本窗口。
1.3.1.1 数据
对于高性能的 RAG 系统, 数据需要干净、一致且上下文丰富。文本应标准化, 以删除特殊字符和不相关的信息, 从而提高检索器的效率。为了保持一致性, 应消除实体和术语的歧义, 同时应消除重复或冗余的信息以简化检索器的焦点。以下是最佳实践列表:
- 文本清理: 标准化文本格式, 删除特殊字符和不相关信息。这提高了检索器的效率并避免了垃圾进垃圾出。
- 实体解析: 消除实体和术语的歧义, 以实现一致的引用。例如, 将"ML"“器学习"“器学习"准为一个通用术语。
- 重复数据删除: 删除重复文档或冗余信息, 以提高检索器的重点和效率。
- 文档分割: 将长文档分解为可管理的块, 或者相反, 将小片段组合成连贯的文档, 以优化检索器性能。
- 特定于域的批注: 使用特定于域的标签或元数据批注文档。例如, 鉴于您的云技术重点, 您可以标记与云相关的技术, 例如"AWS"“zure”。+ 数据增强: 使用同义词、释义, 甚至与其他语言的翻译, 以增加语料库的多样性。
- 层次结构和关系: 识别文档之间的父子关系或同级关系, 以提高上下文理解。
- 用户反馈循环: 使用基于真实世界交互的新问答对不断更新数据库, 并标记它们是否符合事实正确性。
- 时间敏感数据: 对于经常更新的主题, 请实施一种机制来使过时的文档失效或更新。
1.3.1.2 Embedding Model
- fine-tuning embeddings(with fine-tunable/trainable embeddings)
- Dynamic embeddings(with fine-tunable/trainable embeddings)
- Refresh embeddings(with fine-tunable/trainable embeddings)
1.3.1.3 调整分块
评估框架: LlamaIndex Response Evaluation
目标是尽可能多地收集相关背景信息, 并尽可能减少噪音。
在构建 RAG 系统时, 请始终记住chunk_size是一个关键参数。花时间仔细评估和调整您的块大小, 以获得无与伦比的结果。
研究实际上已经证明, 在大多数情况下, ~512-1024 代币是正确的块大小。
- 将引用(元数据)嵌入到您的区块中, 例如用于筛选的日期和用途。添加章节、子章节引用也可能是有用的元数据, 以改进检索。
- 基于多个索引的查询路由 - 这与以前的元数据过滤和分块方法密切相关。您可能有不同的索引, 并同时查询它们。如果查询是指向查询, 则可以使用标准索引, 或者如果是关键字搜索或基于元数据。
Langchain的"multi-vector retriever"就是这样一种方法。为每个文档创建多个向量的方法包括:
- 较小的块: 将文档拆分为较小的块, 并将这些块与较长的块一起嵌入。
- 添加"摘要嵌入”: 为每个文档创建一个摘要, 将其与文档一起嵌入(或代替)文档。
- 假设性问题: 创建每个文档都适合回答的假设性问题, 将这些问题与文档一起嵌入(或代替)文档。
- 重新排序: 嵌入的向量相似搜索可能无法解释为语义相似性。通过重新放弃, 您可以解决这种差异。
- 探索混合搜索: 通过智能地混合基于关键字的搜索、语义搜索和向量搜索等技术, 您可以利用每种方法的优势。这种方法使您的 RAG 系统能够适应不同的查询类型和信息需求, 确保它始终如一地检索最相关和上下文最丰富的信息。混合搜索可以成为检索策略的有力补充, 从而增强 RAG 管道的整体性能。
- 递归检索和查询引擎: 在 RAG 系统中优化检索的另一种强大方法是实现递归检索和复杂的查询引擎。递归检索涉及在初始检索期间获取较小的文档块, 以捕获关键的语义含义。在此过程的后期, 为语言模型(LM)提供具有更多上下文信息的较大块。这种两步检索方法有助于在效率和上下文丰富的响应之间取得平衡。
1.3.1.4 Retrieval
为了提高 RAG 系统的检索效率, 请采用整体策略。首先完善您的分块过程, 探索各种尺寸以达到适当的平衡。嵌入元数据以改进过滤功能和上下文扩充。采用跨多个索引的查询路由, 满足各种查询类型的需求。考虑 Langchain 的多向量检索方法, 该方法采用较小的块、摘要嵌入和假设问题来提高检索的准确性。
1.3.1.5 假设问题和 HyDE
让 LLM 为每个块生成一个问题, 并将这些问题嵌入到向量中, 在运行时对这个问题向量索引执行查询搜索(在我们的索引中用问题向量替换块向量), 然后在检索后路由到原始文本块并将它们作为上下文发送给 LLM 以获得答案。这种方法提高了搜索质量, 因为与实际块相比, 查询和假设问题之间的语义相似性更高。
还有一种称为 HyDE的反向逻辑 apporach - 您要求 LLM 在给定查询的情况下生成一个假设响应, 然后将其向量与查询向量一起使用来提高搜索质量。
HyDE, 即假设文档嵌入, 源于 Gao 等人在 2022 年发表的题为“没有相关性标签的精确零样本密集检索”的论文中提出的创新工作。这项研究的主要目标是增强零样本密集检索, 这依赖于语义嵌入相似性。所提出的解决方案HyDE通过两步法运行。
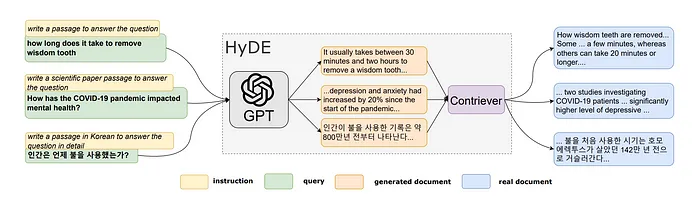
- 通过指令提示来指导语言模型, 以根据原始查询生成假设文档。
- 生成的假设文档通过使用 Contriever(称为"无监督对比编码器”)转换为嵌入向量。
1.3.2 检索优化
检索阶段旨在确定最相关的上下文。通常, 检索基于向量搜索, 它计算查询和索引数据之间的语义相似性。因此, 大多数检索优化技术都围绕着嵌入模型:
- 微调嵌入模型可根据特定于域的上下文自定义嵌入模型, 特别是对于具有不断发展或稀有术语的领域。
- 动态嵌入适应使用单词的上下文, 这与静态嵌入不同, 静态嵌入对每个单词使用单个向量。
除了向量搜索之外, 还有其他检索技术, 例如混合搜索, 它通常是指将向量搜索与基于关键字的搜索相结合的概念。如果您的检索需要完全匹配的关键字, 则此检索技术非常有用。
从小到大检索
使用较小的文本块可提高检索的准确性, 而较大的文本块可提供更多上下文信息。从小到大检索背后的概念是在检索过程中使用较小的文本块, 然后提供检索到的文本所属的较大文本块。
有两种主要技术:
- 较小的子块引用较大的父块: 首先在检索期间提取较小的块, 然后引用父 ID, 并返回较大的块。
- 句子窗口检索: 在检索过程中获取单个句子, 并在句子周围返回一个文本窗口
- 自动合并检索器(又名父文档检索器)
与句子窗口检索器非常相似——搜索更精细的信息片段, 然后在将所述上下文提供给 LLM 进行推理之前扩展上下文窗口。文档被拆分为较小的子块, 引用较大的父块。参考: https://docs.llamaindex.ai/en/stable/examples/retrievers/recursive_retriever_nodes.html
1.3.3 检索后优化
对检索到的上下文进行额外处理有助于解决超出上下文窗口限制或引入干扰等问题, 从而阻碍对关键信息的关注。检索后优化技术包括:
- 提示压缩通过删除不相关的内容并突出显示重要的上下文来减少整体提示长度。
- 重新排名使用机器学习模型来重新计算检索到的上下文的相关性分数。
1.3.3.1 检索与查询
递归检索和智能查询引擎的结合可以显著提高 RAG 系统的性能, 确保它不仅检索相关信息, 而且检索上下文完整的信息, 以获得更准确和信息丰富的答案。
- HyDE: 接受查询, 生成假设响应, 然后使用两者来嵌入查找。
- “Read Retrieve Read”/ReAct: 迭代评估问题是否缺少信息, 并在所有信息可用后制定响应。
- Parent Document Retriever: 在检索过程中获取小块以更好地捕获语义含义, 为您的 LLM 提供更多上下文的较大块
- Vector Search: 重点关注要搜索的邻居数量和使用的距离度量等因素。目标是在准确性和延迟之间取得适当的平衡。
1.3.3.2 索引算法
为了实现大规模的闪电般快速相似性搜索, 向量数据库和向量索引库使用近似最近邻(ANN)搜索, 而不是 k 最近邻(kNN)搜索。顾名思义, ANN 算法近似于最近邻, 因此可能不如 kNN 算法精确。
可以尝试不同的 ANN 算法, 例如 Facebook Faiss(聚类)、Spotify Annoy(树)、Google ScaNN(矢量压缩)和 HNSWLIB(邻近图)。此外, 这些 ANN 算法中的许多算法都有一些可以调整的参数, 例如HNSW。
1.4 性能改进
1.4.1 RAG 管道的引入阶段
- 数据预处理:
在将提取的数据发送到数据库之前, 可以实施可选的预处理步骤, 例如文档聚类和知识图谱构建。这些步骤主要增强了多跃点问答和跨文档查询。 - 嵌入模型
- 元数据
- 多索引
- 索引算法
1.4.2 在推理阶段(检索和生成), 可以调整
- 查询转换
- 改写: 使用 LLM 改写查询, 然后重试。
- 假设文档嵌入(HyDE): 使用 LLM 生成对搜索查询的假设响应, 并将两者用于检索。
- 子查询: 将较长的查询分解为多个较短的查询。
- 检索参数
首先要考虑的是语义搜索是否足以满足您的用例, 或者您是否要尝试混合搜索。在后一种情况下, 需要尝试在混合搜索中对稀疏和密集检索方法的聚合进行加权。因此, 调整参数 , 该参数控制semantic()和基于keyword-based search()之间的权重, 将变得必要。 - 高级检索策略
- 句子窗口检索: 不要只检索相关句子, 而是检索到的句子之前和之后的适当句子窗口。
- 自动合并检索: 文档以树状结构组织。在查询时, 可以将单独但相关的较小块合并到较大的上下文中。
- 对模型进行重新排序
- LLM
- 提示工程
1.5 主要模块
RAG 系统三个主要组件的最新创新: 检索器模块、重新排序器模块和生成器模块
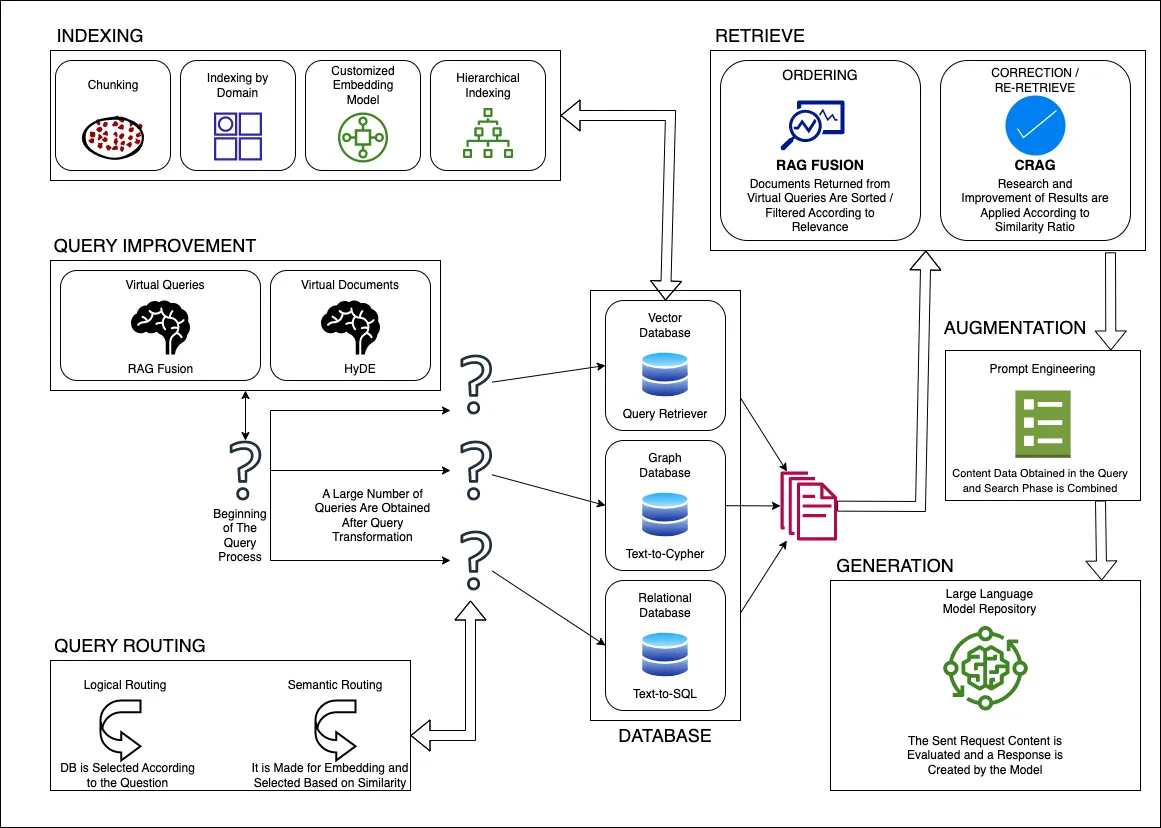
1.5.1 检索器模块
从知识源中检索与上下文相关的文本段落
常见的检索器架构包括dual-encoders和sparse models:
- dual-encoders检索器独立编码上下文和段落, 并根据向量相似性对段落相关性进行评分。
- sparse models检索器根据词汇术语匹配信号直接估计相关性概率。
1.5.2 重新排序器模块
对检索到的段落进行评分和重新排序
带有重新排序器的级联架构提供了在准确性、延迟和成本之间进行权衡的灵活性。重新排序器对初始检索结果进行重新评分, 并专注于对最终生成最有用的高精度段落。
1.5.3 生成器模块
将上下文与检索到的段落集成以生成输出文本
1.5.3.1 带入的问题:
- 要保留多少个段落
- 每个段落要提取多少
- 是连接段落还是单独呈现
- 如何对不同的段落进行加权或排序
1.5.3.2 设计Prompt
- 提示模板
帮助用户解决问题: {issue_description}。
请考虑以下文档: {document_snippets}。
- 提示条件
利用您对机器学习和云技术的理解, 回答以下问题:
1.5.3.3 函数调用和 RAG
函数调用功能通过在生成步骤中引入结构化、可操作的输出, 可以显著增强检索增强生成(RAG)管道。这允许实时 API 集成以获得最新答案, 优化查询执行以减少错误, 以及模块化检索方法以提高相关性。它还可以促进动态文档获取的反馈循环, 并为多步推理或数据聚合提供结构化的 JSON 输出。总体而言, 它使 RAG 系统更加动态、准确和响应迅速。
1.6 文本清理
在将文本输入任何类型的机器学习算法之前, 清理文本是标准做法。无论您是使用有监督算法还是无监督算法, 甚至是为生成式 AI(GAI)模型制作上下文, 让您的文本处于良好状态都有助于:
- 确保准确性: 通过消除错误并使所有内容保持一致, 您不太可能混淆模型或最终导致模型幻觉。
- 提高质量: 更清晰的数据可确保模型使用可靠且一致的信息, 帮助我们的模型从准确的数据中进行推断。
- 便于分析: 干净的数据易于解释和分析。例如, 使用纯文本训练的模型可能难以理解表格数据。
1.6.1 数据清理和降噪
首先删除不具有意义的符号或字符, 例如 HTML 标签(在抓取的情况下)、XML 解析、JSON、表情符号和主题标签。不必要的字符通常会混淆模型, 并增加上下文标记的数量, 从而增加计算成本。
常见的清理技术:
- 代币化: 将文本拆分为单个单词或标记。
- 消除噪音: 消除不需要的符号、表情符号、主题标签和 Unicode 字符。
- 正常化: 将文本转换为小写以保持一致性。
- 删除停用词: 丢弃不增加含义的常见或重复的单词, 例如"a”、“in”、“of"和"the”。
- 词形还原或词干提取: 将单词简化为基本形式或词根形式。
1.6.2 文本标准化和规范化
其次, 我们应该始终优先考虑整个文本的一致性和连贯性。这对于确保准确的检索和生成至关重要。
1.6.3 元数据处理
元数据收集, 例如识别重要的关键字和实体, 使我们能够轻松识别文本中的元素, 这些元素可用于改进语义搜索结果, 尤其是在内容推荐系统等企业应用程序中。此过程为模型提供了额外的上下文, 通常是提高 RAG 性能所必需的。
1.6.4上下文信息处理
在使用 LLM 时, 您可能通常使用多种语言或管理包含各种主题的大量文档, 这对您的模型来说可能很难理解。让我们看一下可以帮助您的模型更好地理解数据的两种技术
**主题建模: **
- 潜在狄利克雷分配(LDA)是一种统计模型, 它是一种统计模型, 通过仔细观察单词模式来帮助找到文本中隐藏的主题。
- 非负矩阵分解(NMF)非常适合负值没有意义的图像等内容。当您需要清晰、可理解的因素时, 它会很方便。例如, 在图像处理中, NMF 有助于提取特征而不会混淆负值。
- 潜在语义分析(LSA)在大量文本分布在多个文档中并希望找到单词和文档之间的联系时大放异彩。LSA 使用奇异值分解(SVD)来识别术语和文档之间的语义关系, 有助于简化按相似性对文档进行排序和检测抄袭等任务。
- 分层狄利克雷过程(HDP)可帮助您快速对大量数据进行排序, 并在不确定文档中有多少主题时识别文档中的主题。作为 LDA 的扩展, HDP 允许无限的主题和更大的建模灵活性。它识别文本数据中的层次结构, 以完成理解学术论文或新闻文章中主题的组织等任务。
- 概率潜在语义分析(PLSA)可帮助您确定文档与某些主题有关的可能性, 这在构建基于过去交互提供个性化推荐的推荐系统时非常有用。
2. 问题汇总
2.1 检索问题
- 语义歧义: 查询解释中的歧义。
- 向量相似性问题: 余弦相似度等向量相似度量的挑战。
- 粒度不匹配: 查询内容和检索内容之间的粒度级别不匹配。
- 矢量空间密度: 向量空间分布的不规则性。
- 稀疏检索挑战: 由于数据稀疏, 难以检索相关内容。
2.2. 增强问题
- 上下文不匹配: 内容集成问题。
- 冗余: 重复的信息。
- 排名不当: 检索到的内容排名不正确。
- 文体不一致: 写作风格不一致。
- 过度依赖检索到的内容: 严重依赖检索到的内容, 有时以牺牲原始生成为代价。
2.3 生成问题:
- 逻辑不一致: 矛盾或不合逻辑的陈述。
- 冗长: 生成的内容过于冗长。
- 过度泛化: 提供过于笼统的信息。
- 缺乏深度: 肤浅的内容。
- 错误传播: 源自检索数据的错误。
- 文体问题: 风格不一致。
- 未能调和矛盾: 无法解决冲突的信息。在这篇文章中, 我们将更多地关注修复 RAG 管道的方法……
2.4 半结构化 RAG
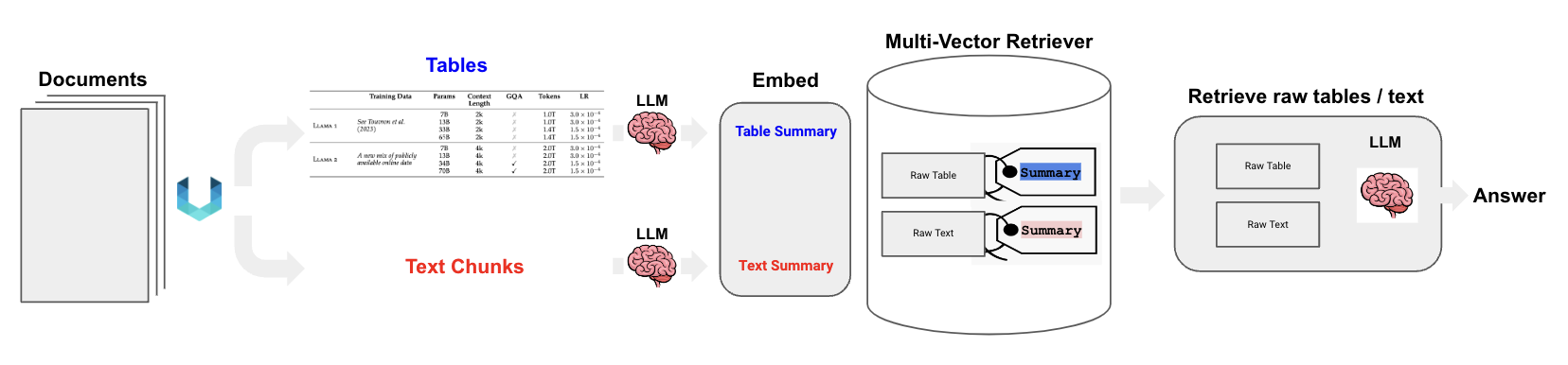
pip install langchain unstructured[all-docs] pydantic lxml langchainhub
- 解析文本和表格:
unstructured - 存储用于搜索的表格和文本:
multi-vector retriever
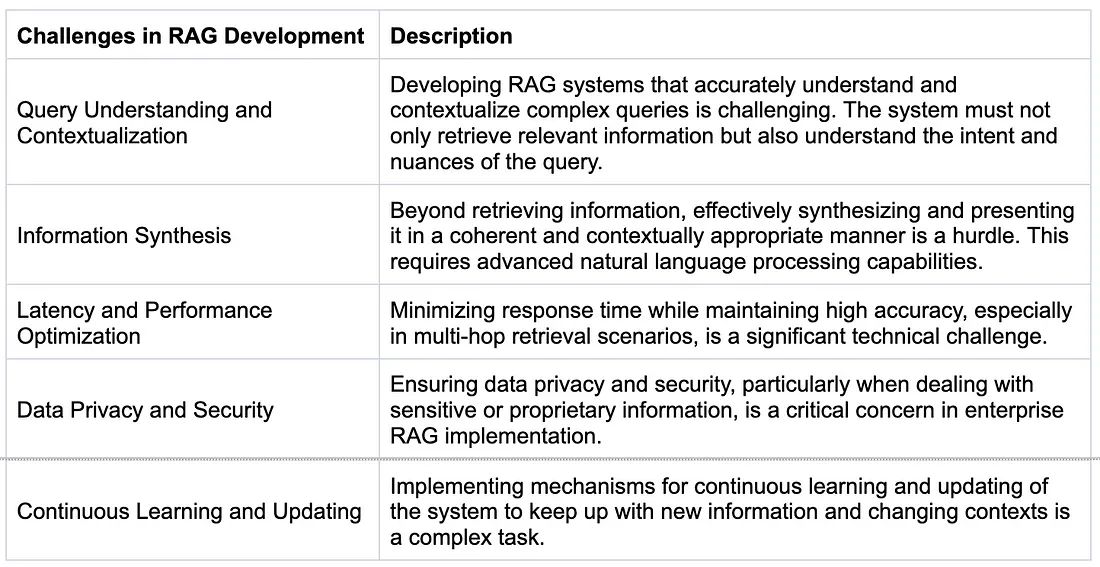
2.5 RAG开发中的挑战
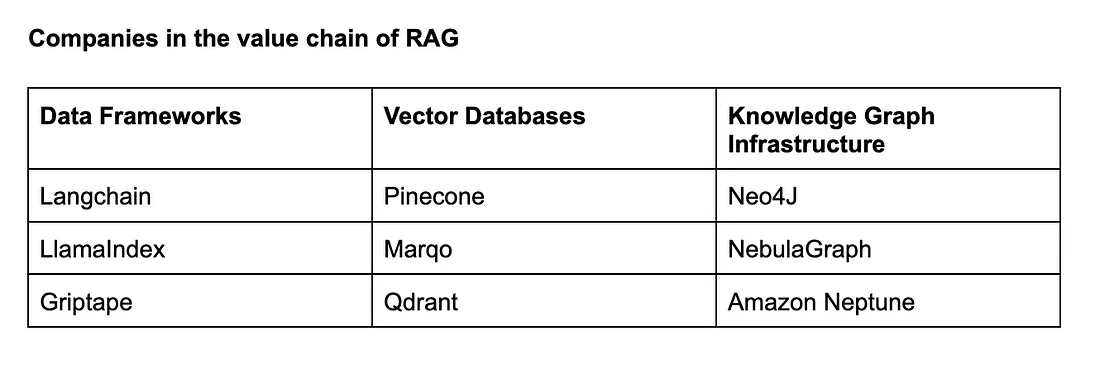
2.6 RAG vs Fine-tune

2.7 聊天记录和上下文
聊天历史记录记忆简单明了, 只是反映了扩展聊天窗口对话的方法, 以便可以在单个会话中继续对话。
事实证明, 上下文记忆要困难得多, 并且是一个如何在未来以可靠的方式注入特定上下文的问题。
3. 高级 RAG
3.1 使用 LlamaIndex 实现
3.1.1 索引优化示例: 句子窗口检索
SentenceWindowNodeParser
from llama_index.core.node_parser import SentenceWindowNodeParser
# create the sentence window node parser w/ default settings
node_parser = SentenceWindowNodeParser.from_defaults(
window_size=3,
window_metadata_key="window",
original_text_metadata_key="original_text",
)
它做了两件事:
- 它将文档分成单个句子, 这些句子将被嵌入。
- 对于每个句子, 它创建一个上下文窗口。如果指定 , 则生成的窗口长度为三个句子, 从嵌入句子的前一个句子开始, 跨越后面的句子。该窗口将存储为元数据。
window_size = 3
在检索过程中, 将返回与查询最匹配的语句。检索后, 您需要通过定义 a 并在 列表中使用它来将该句子替换为元数据中的整个窗口。
3.1.2 检索优化示例: 混合搜索
在 LlamaIndex 中实现混合搜索就像对基础向量数据库是否支持混合搜索查询进行两次参数更改一样简单。该参数指定向量搜索和基于关键字的搜索之间的权重, 其中表示基于关键字的搜索和表示纯向量搜索。
query_engine = index.as_query_engine(
...,
vector_store_query_mode="hybrid",
alpha=0.5,
...
)
3.1.3 检索后优化示例: 重新排名
将重新排名器添加到高级 RAG 管道只需三个简单的步骤:
- 首先, 定义一个重新排名器模型。
- 在查询引擎中, 将 reranker 模型添加到 的列表中。
- 在查询引擎中增加 以检索更多上下文段落, 这些段落可以减少到重新排名后:
similarity_top_ktop_n
from llama_index.core.postprocessor import SentenceTransformerRerank
# Define reranker model
rerank = SentenceTransformerRerank(
top_n = 2,
model = "BAAI/bge-reranker-base"
)
# Add reranker to query engine
query_engine = index.as_query_engine(
similarity_top_k = 6,
...,
node_postprocessors = [rerank],
...,
)
3.2 使用 LangGraph 改进 RAG
def classify(question):
return llm("classify intent of given input as greeting or not_greeting. Output just the class.Input:{}".format(question)).strip()
3.3 Agentic RAG
Agentic RAG 是一种设计模式, 其中由 LLM 提供支持的模块根据可用的工具集来推理和计划如何回答问题。在高级场景中, 我们还可以连接多个智能体以创造性的方式解决 RAG, 其中智能体不仅可以检索, 还可以进行验证、总结等。
Agentic RAG 是一种基于代理的方法, 用于以编排的方式对多个文档进行问答。比较不同的文档, 总结特定文档或比较各种摘要。Agentic RAG 是一种灵活的问答方法和框架。
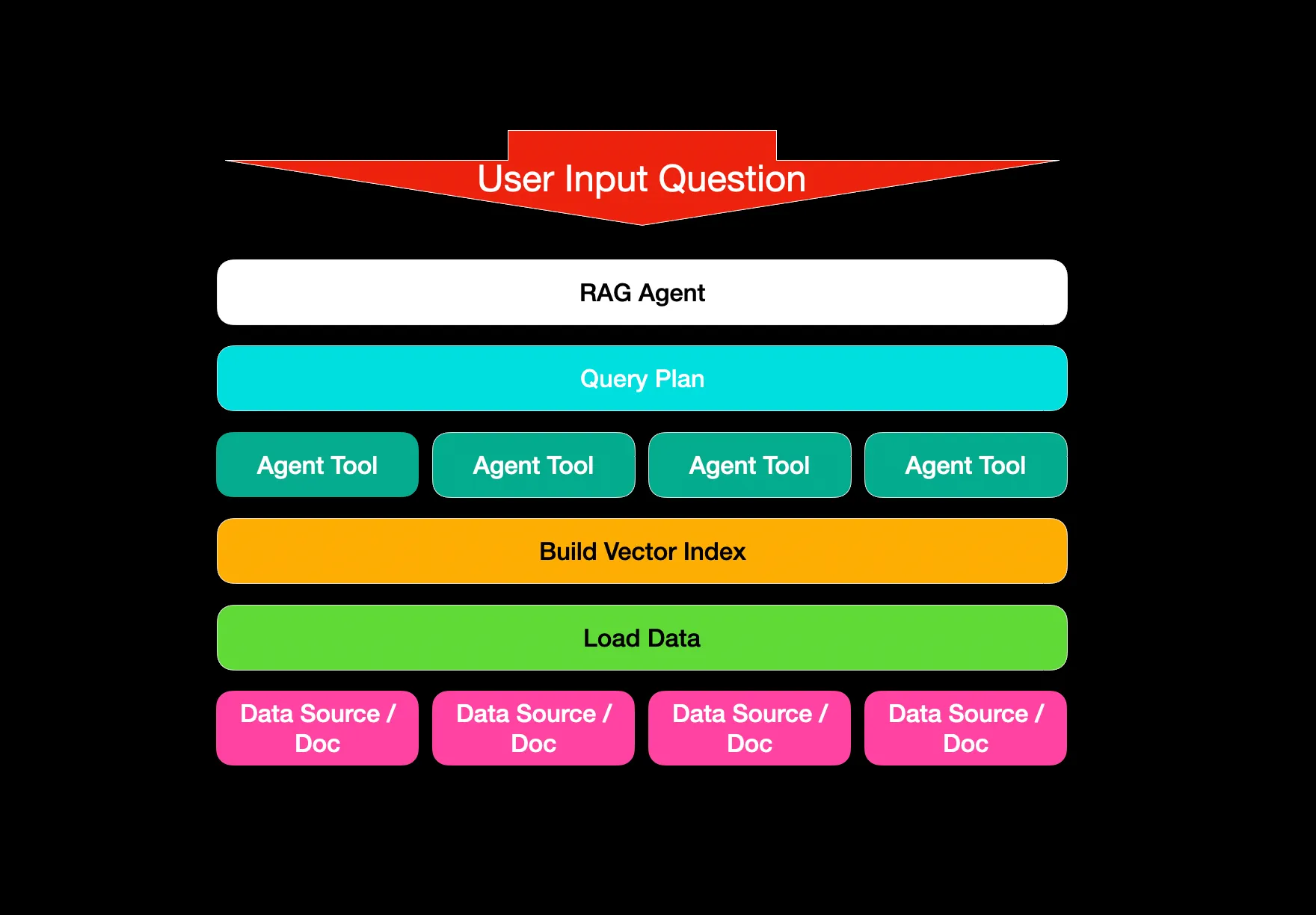
每个Agent都与所描述的文档或文档集相关。每个Agent的描述允许代理知道要选择哪个Agent, 或者要组合哪些Agent。
3.3.1 基本架构
基本体系结构是设置每个文档的文档代理, 每个文档代理都能够在自己的文档中执行问答和摘要。
然后设置一个顶级代理(元代理)来管理所有低阶文档代理。
3.3.2 需要细化的关键步骤和组成部分
- 基于推理、子任务制定和系统安排进行计划。
- 基于自一致性的自我纠正, 由于生成了多条路径和推理, 基于计划的 RAG 方法(ReWoo 和 Plan+)比仅基于推理(ReAct)的效果更好。
- 能够根据执行进行调整, 这是一种更加多智能体的范式。
3.4 RAPTOR: 用于树组织检索的递归抽象处理
Github Homepage:https://github.com/parthsarthi03/raptor/tree/master
原始论文: RAPTOR: 用于树组织检索的递归抽象处理
Demo: Implementing Advanced RAG in Langchain using RAPTOR
Recursive Abstractive Processing for Tree Organized Retrieval(RAPTOR)是一种新的、强大的 LLM 索引和检索技术。它采用自下而上的方法, 通过对文本段(块)进行聚类和汇总来形成分层树结构。
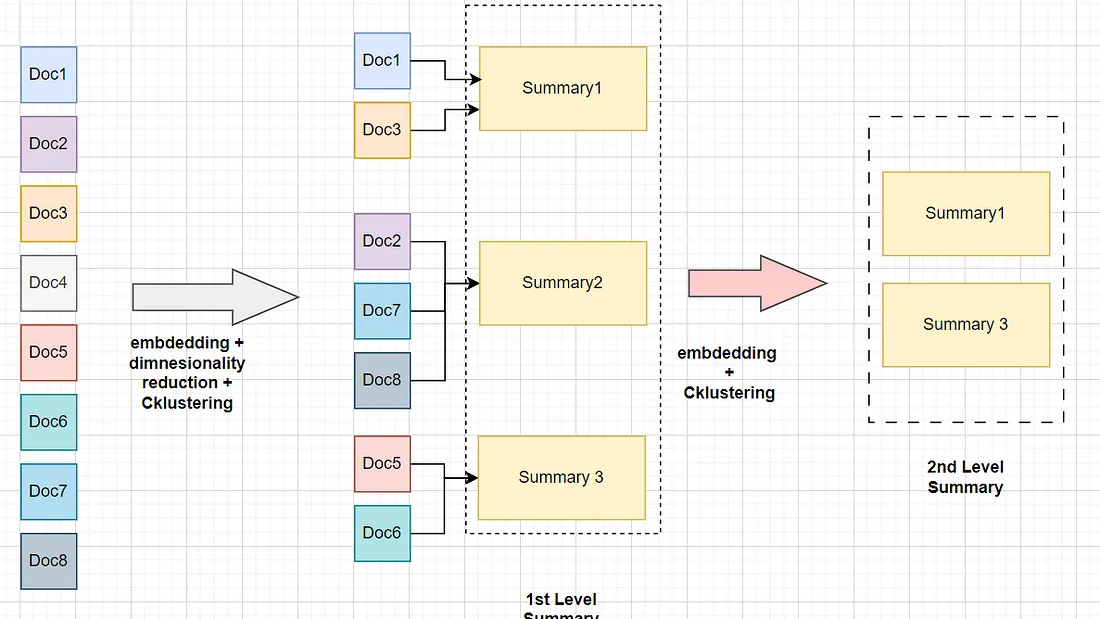
RAPTOR背后的直觉如下:
- 对相似文档进行聚类和汇总。
- 将相关文档中的信息捕获到摘要中。
- 对于需要从较少上下文中回答的内容的问题提供帮助。
基本上有两种检索方式:
-
树遍历检索
树遍历从树的根级别开始, 根据向量嵌入的余弦相似度检索节点的前 k 个文档。因此, 在每个级别, 它都会从子节点中检索前 k 个文档。 -
倒塌的树木检索
折叠树检索是一种简单得多的方法。它将所有树折叠到一个层中, 并检索节点, 直到根据查询向量的余弦相似度达到标记的阈值数。
3.5 Template Matching
模板匹配是一种基于感兴趣区域(ROI)几何坐标的技术。一个条件是要对感兴趣的区域进行静态定位, 假设我们确定发票中的"总金额"始终位于具有坐标(x、y、长度、高度)的区域内。在这种情况下, 我们可以直接对特定区域进行 OCR 并获取输出文本, 这不仅可以减少整个文档的处理时间, 还可以获得结构化输出, 我们可以将其直接插入到需要该数据的数据库或其他服务中。
- OCR 引擎可以接受 ROI 参数
- 需要将区域的裁剪图像直接提供给 OCR
TM 仅限于遵循模板的文档, 其中区域的位置是静态的, 例如, 如果您的文档在扫描仪上略微旋转或放错位置, 导致区域位置发生变化, 则输出将不正确。
3.6 自查询检索器
自查询检索器是一种具有自我查询能力的检索器。具体来说, 给定任何自然语言查询, 检索器使用查询构造 LLM 链来编写结构化查询, 然后将该结构化查询应用于其基础 VectorStore。这样, 检索器不仅可以使用用户输入查询与存储文档的内容进行语义相似性比较, 还可以从用户对存储文档元数据的查询中提取筛选器并执行这些筛选器。
使用 LLM 展开查询可改善使用稀疏和统计检索器时的搜索结果。
3.7 REALM
REALM 代表 REtrieval Augmented Language Model, 是开创性的 RAG 算法之一, 它证明了这种方法在问答方面的早期有效性。
REALM 架构的 4 个主要步骤:
- 输入问题: 一个自然语言问题, 例如"亚历山大·弗莱明出生在哪里?”
- 检索相关段落: 使用 BM25 获取给定问题嵌入的前 k 个维基百科段落的稀疏向量索引检索。
- 独立编码: 问题和证据段落由 RoBERTa 单独编码, 无需先串联。
- 联合情境化: 编码的向量通过交叉注意力层进行交互, 以产生最终的上下文化表示, 从而为输出文本生成提供动力。
基于REALM的衍生作品:
- ORQA(Optimized Retrieval Question Answering): 优化的 RAG 架构
- RAG Token: 统一文本和知识检索
3.8 Safety RAG
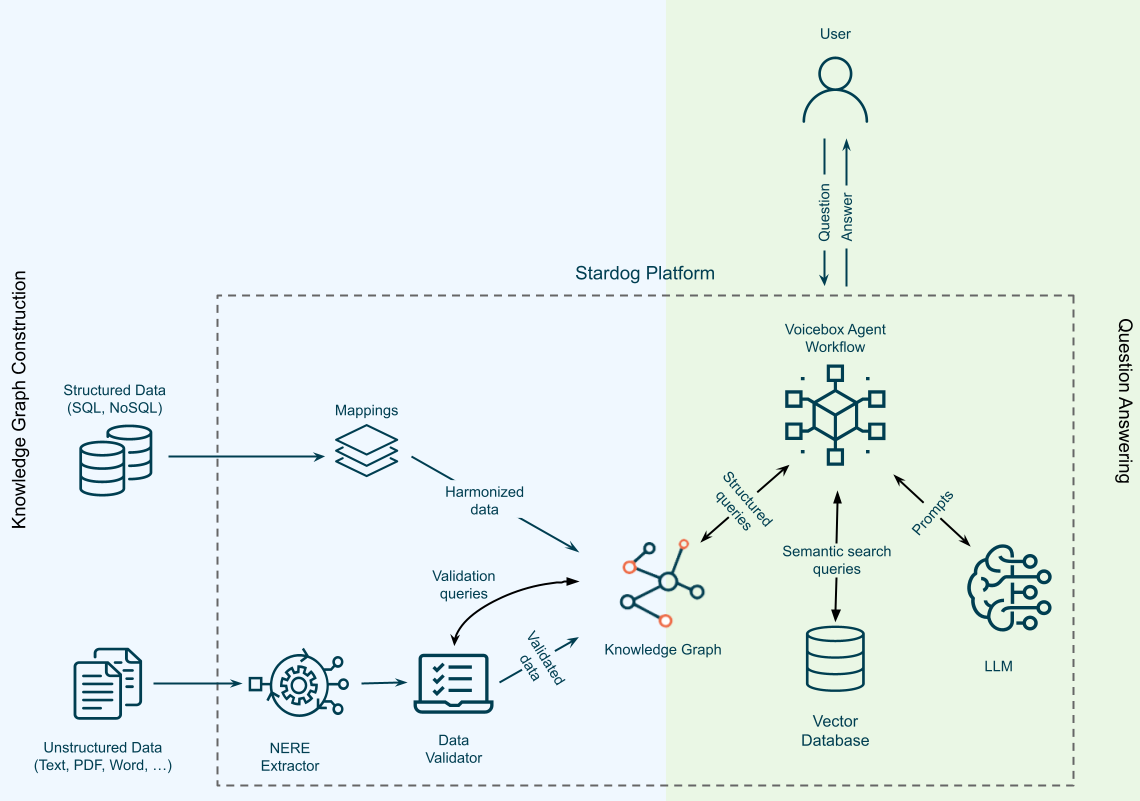
幻觉对企业不利, 尤其是银行、制药和制造业等受监管的行业, 需要对 RAG 和 LLM 进行纠正性补充, 仅靠 RAG 和 LLM 不足以提供安全的 AI。
SRAG 的基本思想是通过将企业数据库统一到一个知识图谱中, 然后使用该知识图谱和语义解析来建立 LLM 输出, 从而消除幻觉, 从而完成 GenAI 对企业数据的访问。SRAG 的基本前提是从数据库中引导一个 KG, 然后使用该 KG 来过滤 LLM 从文档中提取知识时发生的幻觉。
3.9 混合矢量搜索
-
关键词搜索: BM25 算法
- BM25 大放异彩的例子:
- 错误代码: 准确查找"错误 XYZ-123”
- 产品编号: 精确定位"AB-9000 型”
- 具体术语: 在生物学文本中查找"线粒体"
- BM25 大放异彩的例子:
-
语义搜索:
唯一的诀窍是将检索到的结果与不同的相似性分数正确地组合在一起——这个问题通常在Reciprocal Rank Fusion算法的帮助下解决, 对检索到的结果进行重新排序, 以获得最终输出。
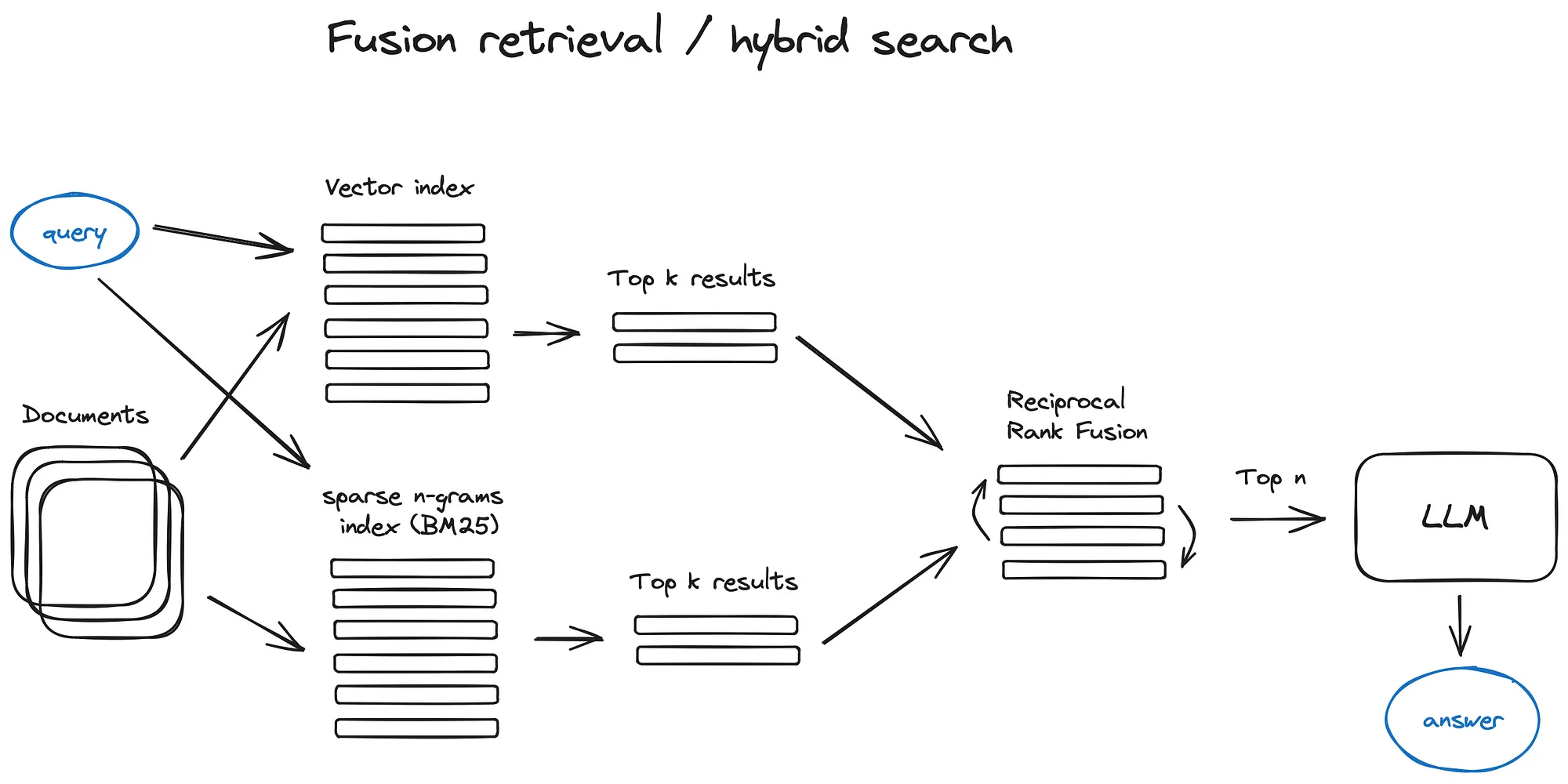
在LangChain中, 这是在Ensemble Retriever类中实现的, 它结合了你定义的检索器列表, 例如faiss向量索引和基于BM25的检索器, 并使用RRF进行重新排序。
在 LlamaIndex 中, 这是以非常相似的方式完成的。
3.9.1 ReRank
在 LlamaIndex 中, 有各种可用的后处理器, 根据相似性分数、关键字、元数据过滤掉结果, 或者使用其他模型(如 LLM、句子转换器交叉编码器、Cohere 重新排名端点)或基于日期新近度等元数据对它们进行重新排序——基本上, 你所能想象到的一切。
这种混合方法使 RAG 系统能够利用语义理解和传统信息检索技术的优势, 从而产生更可靠和上下文感知的响应。据 Anthropic 报道, 这种方法将结果提高了 ~1%。
3.10 其他
3.10.1 CGRAG
CGRAG 代表 Contextual-Guided Retrieval Augmented Generation:
基本要点是, 首先使用 LLM 生成更好、更精确的关键字, RAG 的嵌入模型将能够使用这些关键字来创建更接近相关匹配的嵌入向量。LLM 再次运行, 其中包含 RAG 发现的更相关的信息, 希望能产生更准确的响应。
4. RAG Framework
4.1 RAGFlow
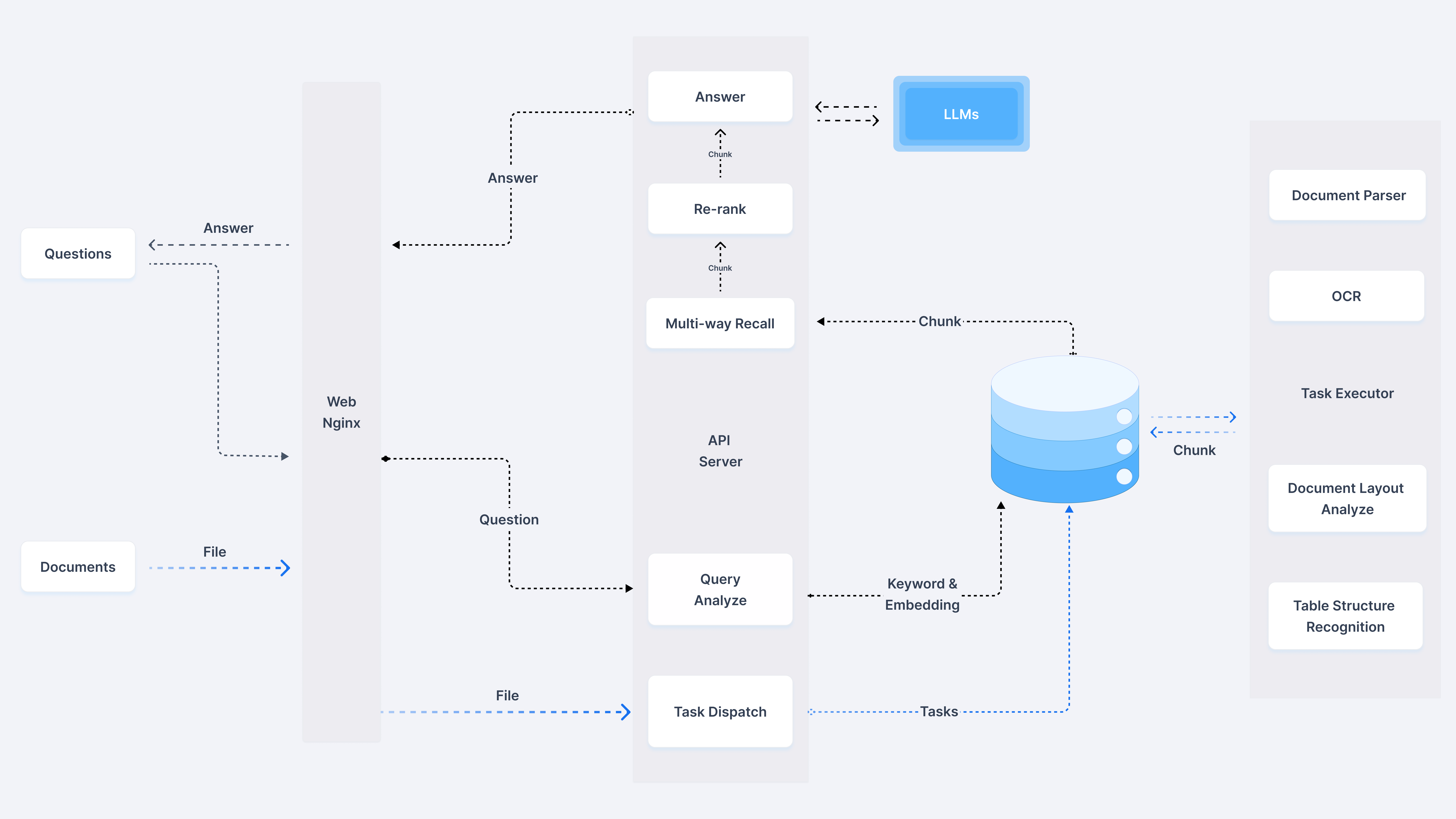
RAGFlow是一个基于深度文档理解的开源 RAG(检索增强生成)引擎。它为任何规模的企业提供了简化的 RAG 工作流程, 结合了 LLM(大型语言模型)以提供真实的问答功能, 并由来自各种复杂数据的有根据的引用提供支持。
RAGFlow 引入了对 GraphRAG 的支持, GraphRAG 最近由 Microsoft 开源, 据称是下一代检索增强生成(RAG)。
4.1.1 主要特点
- “质量进, 质量出”
- 从具有复杂格式的非结构化数据中提取基于文档理解的深度知识。
- 找到"数据大海捞针", 从字面上看是无限的Token。
- 基于模板的分块
- 智能且可解释。
- 大量模板选项可供选择。
- 减少幻觉的有根据的引文
- 文本分块的可视化, 以允许人工干预。
- 快速查看关键参考文献和可追溯的引文, 以支持有根据的答案。
- 与异构数据源的兼容性
- 支持 Word、幻灯片、excel、txt、图像、扫描副本、结构化数据、网页等。
- 自动化且轻松的 RAG 工作流程
- 简化的 RAG 编排, 可满足个人和大型企业的需求。
- 可配置的 LLM 以及嵌入模型。
- 多次召回与融合重新排名配对。
- 直观的 API, 可与业务无缝集成。
4.2 AutoRAG
AutoRAG, RAG AutoML 工具, 用于为您的数据自动查找最佳 RAG 管道。

AutoRAG 是一种为"您的数据"寻找最佳 RAG 管道的工具。 您可以使用自己的评估数据自动评估各种 RAG 模块 并找到适合您自己的使用案例的最佳 RAG 管道。
AutoRAG 支持一种简单的方法来评估许多 RAG 模块组合。 立即试用, 找到最适合您自己使用案例的 RAG 管道。
相关资源:
4.3 deepset-ai的Haystack
Haystack 是一个功能强大且灵活的框架, 用于构建端到端问答和搜索系统。它提供了一个模块化架构, 允许开发人员轻松为各种 NLP 任务创建管道, 包括文档检索、问答和摘要。Haystack 的主要功能包括:
- 支持多个文档存储(Elasticsearch、FAISS、SQL 等)
- 与流行的语言模型(BERT、RoBERTa、DPR 等)集成
- 可扩展的架构, 用于处理大量文档
- 易于使用的 API, 用于构建自定义 NLP 管道
4.4 Neuml的TXTAI
TXTAi 是一个多功能的AI驱动的数据平台, 超越了传统的 RAG 框架。它提供了一套全面的工具, 用于构建语义搜索、语言模型工作流和文档处理管道。txtai 的主要功能包括:
- 嵌入数据库以实现高效的相似性搜索
- 用于集成语言模型和其他AI服务的 API
- 用于自定义工作流的可扩展架构
- 支持多种语言和数据类型
TXTAi 的一体化方法使其成为希望在单个框架中实施各种AI驱动功能的组织的绝佳选择。
4.5 斯坦福的STORM
STORM(斯坦福开源 RAG 模型)是由斯坦福大学开发的面向研究的 RAG 框架。虽然与其他一些框架相比, 它的星级可能较少, 但其学术血统和对尖端技术的关注使其成为对 RAG 技术最新进展感兴趣的研究人员和开发人员的宝贵资源。STORM 的显著特点包括:
- 实施新颖的 RAG 算法和技术
- 专注于提高检索机制的准确性和效率
- 与最先进的语言模型集成
- 广泛的文档和研究论文
对于那些希望探索 RAG 技术前沿的人来说, STORM 提供了以学术严谨为后盾的坚实基础。
4.6 pathwaycom的LLM-App
LLM-App 是用于构建动态 RAG 应用程序的模板和工具的集合。它以专注于实时数据同步和容器化部署而著称。LLM-App 的主要功能包括:
- 即用型 Docker 容器, 可快速部署
- 支持动态数据源和实时更新
- 与流行的 LLM 和向量数据库集成
- 适用于各种 RAG 用例的可定制模板
LLM-App 强调运营方面和实时功能, 使其成为希望部署生产就绪型 RAG 系统的组织的一个有吸引力的选择。
4.7 truefoundry的Cognita
Cognita 是 RAG 框架领域的新进入者, 专注于为构建和部署AI应用程序提供统一的平台。虽然与其他一些框架相比, 它的星级较少, 但其全面的方法和对 MLOps 原则的强调使其值得考虑。Cognita 的显着功能包括:
- 用于 RAG 应用程序开发的端到端平台
- 与流行的 ML 框架和工具集成
- 内置监控和可观测性功能
- 支持模型版本控制和实验跟踪
Cognita 的整体AI应用程序开发方法使其成为希望简化整个 ML 生命周期的组织的绝佳选择。
4.8 SciPhi-AI的R2R
R2R (Retrieval-to-Retrieval) 是一个专门的 RAG 框架, 专注于通过迭代优化来改进检索过程。虽然它的星星可能较少, 但其创新的检索方法使其成为一个值得关注的框架。R2R 的关键方面包括:
- 新型检索算法的实施
- 支持多步骤检索过程
- 与各种嵌入模型和向量存储集成
- 用于分析和可视化检索性能的工具
对于有兴趣突破检索技术界限的开发人员和研究人员, R2R 提供了一套独特而强大的工具。
4.9 Neurite
Neurite 是一个新兴的 RAG 框架, 旨在简化构建AI驱动的应用程序的过程。虽然与其他一些框架相比, 它的用户群较小, 但它对开发人员体验和快速原型设计的关注使其值得探索。Neurite 的显着特征包括:
- 用于构建 RAG 管道的直观 API
- 支持多个数据源和嵌入模型
- 内置缓存和优化机制
- 自定义组件的可扩展架构
Neurite 强调简单性和灵活性, 这使其成为希望在其应用程序中快速实现 RAG 功能的开发人员的有吸引力的选择。
4.10 RUC-NLPIR的FlashRAG
FlashRAG是由中国人民大学自然语言处理与信息检索实验室开发的一个轻量级且高效的RAG框架。虽然它的星级可能较少, 但它对性能和效率的关注使其成为一个值得注意的竞争者。FlashRAG 的主要方面包括:
- 优化的检索算法以提高速度
- 支持分布式处理和扩展
- 与流行的语言模型和向量存储集成
- 用于基准测试和性能分析的工具
对于速度和效率至关重要的应用程序, FlashRAG 提供了一套专门的工具和优化。
4.11 Canopy
Canopy 是由 Pinecone 开发的 RAG 框架, 该公司以其矢量数据库技术而闻名。它利用 Pinecone 在高效载体搜索方面的专业知识来提供强大且可扩展的 RAG 解决方案。Canopy 的显着功能包括:
- 与 Pinecone 的矢量数据库紧密集成
- 支持流式处理和实时更新
- 高级查询处理和重新排名功能
- 用于管理知识库和版本控制知识库的工具
Canopy 专注于可扩展性以及与 Pinecone 生态系统的集成, 这使其成为已经使用或考虑使用 Pinecone 来满足其向量搜索需求的组织的绝佳选择。
5. RAG 评估
5.1 评估框架
- Microsoft的PromptFlow
- Hegel-ai.com的Prompttools
- 评估框架Truelens
- LlamaIndex 有一个 rag_evaluator llama包
- Ragas: Ragas是一个框架, 可帮助你评估检索增强生成(RAG)管道。这提供了有助于评估 RAG 的关键指标。
5.2 评估指标
高效检索系统的重要要求是 (R1) 良好的检索性能, (R2) 合理的索引速度, (R3) 查询期间的低延迟。
- 检索到的上下文与查询的上下文相关性、扎根性(提供的上下文支持LLM答案的程度)和答案与查询的相关性
- 命中率
- 平均互惠排名
- 生成的答案指标, 例如忠诚度和相关性
5.2.1 平均互惠排名
平均互惠排名(Mean Reciprocal Rank, MRR)是一种衡量信息检索系统性能的指标, 特别是在评估排序问题时。它通常用于评估搜索引擎、推荐系统或其他排序任务的准确性。
平均互惠排名是通过计算每个查询的正确答案的排名倒数的平均值来得到的。具体来说, 对于每个查询, 如果正确答案在结果列表中的排名是 ( r ), 则其倒数排名为 ( \frac{1}{r} )。然后, 将所有查询的这些倒数排名值求平均, 得到平均互惠排名。
计算公式
对于 \( n \) 个查询, 平均互惠排名 \( \text{MRR} \) 的计算公式为:
示例
假设有三个查询, 正确答案的排名分别为 1、3 和 2。则:
- 第一个查询的倒数排名为 \( \frac{1}{1} = 1 \)
- 第二个查询的倒数排名为 \( \frac{1}{3} = 0.333 \)
- 第三个查询的倒数排名为 \( \frac{1}{2} = 0.5 \)
平均互惠排名为:
应用
平均互惠排名广泛应用于评估搜索引擎的性能, 尤其是在评估答案的准确性和及时性时。它也常用于推荐系统中, 评估推荐列表中用户感兴趣项目的排名情况。
优点:
- 简单直观, 易于理解和计算。
- 能够反映正确答案的相对位置, 对排名的敏感性较高。
局限性:
- 对排名的敏感性可能导致对小排名变化的过度反应。
- 不适用于评估多个正确答案的情况, 因为它只考虑第一个正确答案的排名。
通过这种方式, 平均互惠排名提供了一种衡量排序系统性能的有效方法, 尤其是在需要快速定位正确答案的场景中。
5.3 关注 RAG
- VectorDB 的选择很重要 - 对于> 1000 万个文档来说, 只有少数几个会站得住脚 - 我想到了 Weaviate、PGVector、Pinecone。Weaviate 和 Pinecone 已经做了一些令人难以置信的工作来优化索引和总结这种规模的索引等, 这将派上用场
- 您需要一个可靠的重新排名策略 - RRF(倒数排名融合)或最好的是, 为您的数据集/文档内容量身定制的混合版本将决定您的 RAG 的成败。不要对嵌入模型过多担心 - 好的模型很少, 选择一个并更多地关注 reranker。在没有 reranker 的情况下, 您将获得所有这些结果相似的结果。
- 索引 - HNSW(Hierarchical Navigational Small World) 索引策略是一种基于图的多层索引, 它非常可靠, 可以在性能和功效之间取得良好的平衡。确保在创建数据库和索引之前 _ 正确选择参数
- 最后但并非最不重要的一点是 - 简单地将文档放入摄取管道不会带来任何好处。您需要一个谨慎的策略, 并且可能需要将文档“分割”为逻辑组(由您的用例/内容类型决定), 并使用“智能查询路由器”将其路由到正确的 Vector DB。
6. 其他
6.1 文档解析
6.1.1 PDF
- Pdfminer - 用于执行布局分析和数据解析的库;
- Pdfplumber - 基于 Pdfminer, 专为从 PDF 中提取表格而设计。
pip install pdfminer.six pdfplumber
- PyMuPDF: 也称为 fitz
pip install PyMuPDF
最好的PDF处理器。它生成 xml: https://grobid.readthedocs.io/en/latest/Introduction/
6.1.2 Text2Table
https://huggingface.co/gretelai/text2table
对于 OCR, Azure 视觉服务 OCR 用于从中提取文本(如果 Azure OCR 因任何原因失败, 则 PyPDF2 用作本地脱机备份)。此外, 还实现了 PyTesseract,
能试试paddleocr吗? 我发现在某些情况下它比 pytesseract 更好
6.2. RAT
检索增强思想(RAT)是一种简单而有效的提示策略, 它结合了思维链(CoT)提示和检索增强生成(RAG), 以解决长期推理和生成任务。
6.3 RAG 的四个级别

- 显式事实查询
- 隐式事实查询
- 可解释的理由查询
- 隐藏的理由查询

6.4 检索方法
人们一致认为, 当人们考虑RAG时, 他们过度关注基于向量的检索。下面是个一个融合的检索方法, 它具有一些最先进的检索技术, 并且可以很容易地扩展以添加其他技术, 下面是粗略的伪代码:
answer_from_docs(query):
extracts = get_relevant_extracts(query):
passages = get_relevant_chunks(query):
p1 = get_semantic_search_results(query) # semantic/dense retrieval + learned sparse
p2 = get_similar_chunks_bm25(query)# lexical/sparse
p3 = get_fuzzy_matches(query)# lexical/sparse
p = rerank(p1 + p2 + p3) # rerank for lost-in-middle, diversity, relevance
return p
# use LLM to get verbatim relevant portions of passages if any
extracts = get_verbatim_extracts(passages)
return extracts
# use LLM to get final answer from query augmented with extracts
return get_summary_answer(query, extracts)
7. 指令调整的嵌入、重新排名和 LLM
7.1 指令调优的嵌入
Instruction-Tuned 嵌入的功能类似于双编码器, 其中查询和文档嵌入被单独处理, 然后比较它们的嵌入。通过为每个 embedding 提供额外的指令, 我们可以将它们带到一个新的 embedding 空间, 在那里可以更有效地比较它们。
指令调整嵌入的主要优势在于, 它们允许我们将特定的指令或上下文编码到嵌入本身中。这在处理职位描述-简历匹配等复杂任务时特别有用, 其中查询(职位描述)和文档(简历)具有不同的结构和内容。
7.2 重新排名
虽然指令/常规嵌入模型可以在一定程度上缩小我们的候选范围, 但我们显然需要更强大的模型来更好地理解我们文档之间的关系。
在使用指令调整的嵌入检索初始结果后, 我们采用交叉编码器(reranker)来进一步细化排名。reranker 会考虑特定的上下文和说明, 从而允许在查询和检索到的文档之间进行更准确的比较。
重新排名至关重要, 因为它使我们能够以更细致的方式评估检索到的文档的相关性。与仅依赖于查询和文档嵌入之间的相似性的初始检索步骤不同, 重新排名会考虑查询和文档的实际内容。
通过联合处理查询和每个检索到的文档, 重新排序器可以捕获细粒度的语义关系并更准确地确定相关性分数。这在初始检索可能返回表面层面相似但与特定查询不真正相关的文档的情况下尤为重要。
7.3 LLM
如果重新排名后仍存在歧义, 则可以利用LLM来分析检索到的结果并提供额外的上下文或生成有针对性的摘要。
LLM, 例如 GPT-4, 能够根据给定的上下文理解和生成类似人类的文本。通过将检索到的文档和查询提供给LLM, 我们可以获得更细致的见解并生成量身定制的响应。
参考:
Semi-structured RAG
How to improve RAG peformance - Advanced RAG Patterns - Part2
Advanced RAG for LLMs/SLMs
Unlocking LLM’s Potential with RAG: A Complete Guide from Basics to Advanced Techniques
full end-to-end advanced RAG pipeline in this Jupyter Notebook
Extract custom table from PDF with LLMs
Improving RAG using LangGraph and LangChain
Enhancing RAG with Graph
From Conventional RAG to Graph RAG
Advanced RAG Techniques: an Illustrated Overview
构建和评估高级RAG
Evaluate RAG with LlamaIndex
RAG 101: Chunking Strategies
Four Levels of RAG — Research from Microsoft
Task-Aware RAG Strategies for When Sentence Similarity Fails
