
目录
BigCode 是由 HuggingFace和ServiceNow共同领导的开放式科学合作项目, 该项目致力于开发负责任的代码大模型。
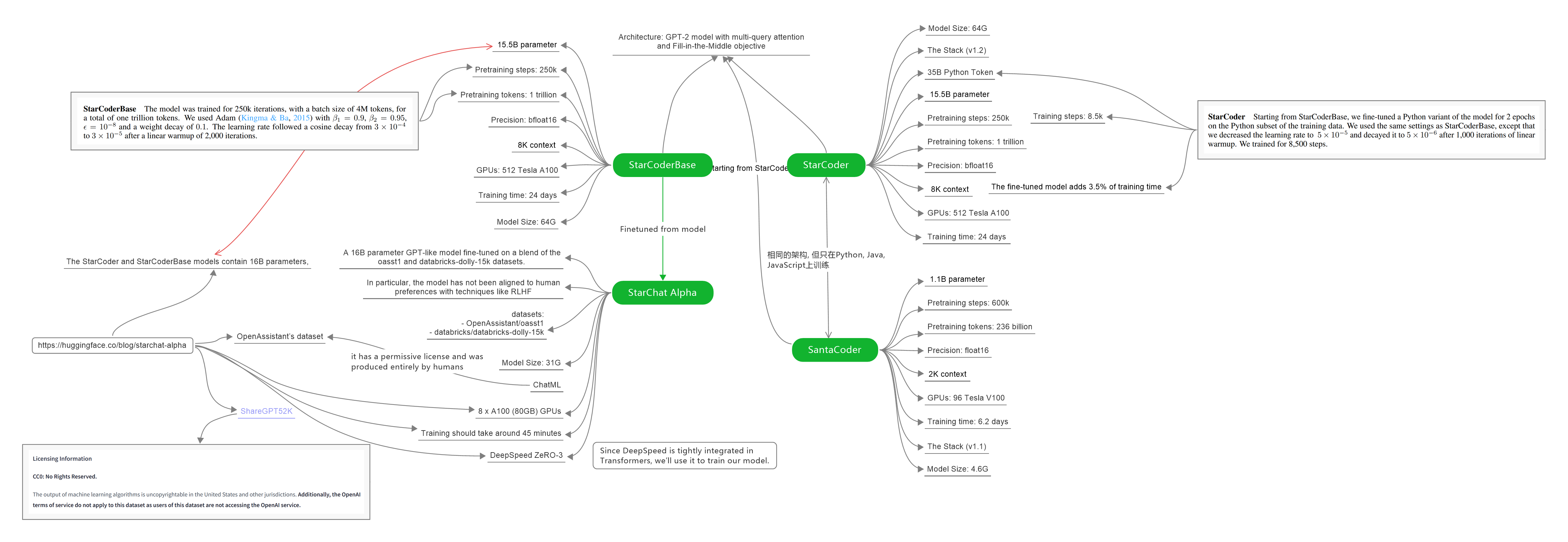
1. StarCoderBase
StarCoderBase 模型是使用 The Stack(v1.2)中的 80+ 种编程语言训练的 15.5B 参数模型, 不包括选择退出请求。该模型使用多查询注意力(包含 8192 个令牌的上下文窗口), 并使用 1 万亿个令牌的中间填充目标进行训练。
The Stack(v1.2)数据集(一个子集)仅包含许可的代码, 并包含一个选择退出过程, 以便代码贡献者可以从数据集中删除其数据。我们与 Toloka 合作, 从训练数据中删除了个人身份信息, 例如姓名、密码和电子邮件地址。
2. StarCoder / SantaCoder
2.1 StarCoder
在 StarCoderBase 模型上, 使用 35B Python Token进行了微调, 产生了一个名为 StarCoder 的新模型。with opt-out requests excluded.
StarCoder 是一种 15.5B 参数语言模型, 用于在 80+ 编程语言上为 1T tokens训练的代码。它使用 MQA(Multi Query Attention) 进行高效生成, 具有 8,192 tokens 上下文窗口, 并且使用了1 trillion tokens 进行Fill-in-the-Middle objective。
模型是在 GitHub 代码上训练的, 它不是一个指令模型, 像"Write a function that computes the square root.“这样的命令不能很好地工作。但是, 通过使用Tech Assistant prompt, 您可以将其转变为有能力的技术助手。
- Architecture: GPT-2 model with multi-query attention and Fill-in-the-Middle objective
- Pretraining steps: 250k
- Pretraining tokens: 1 trillion
- Precision: bfloat16
- GPUs: 512 Tesla A100
- Training time: 24 days
2.2 SantaCoder
SantaCoder aka smol StarCoder: 相同的架构, 但只在Python, Java, JavaScript上训练。
SantaCoder 模型是在 The Stack(v1.1) 的 Python、Java 和 JavaScript 子集上训练的一系列 1.1B 参数模型(不包括选择退出请求)。主模型使用Multi Query Attention(包含 2048 个令牌的上下文窗口), 并使用near-deduplication和comment-to-code ratio 作为过滤条件并使用中间填充目标进行训练。此外, 还有几个模型是在具有不同过滤器参数以及架构和目标变化的数据集上训练的。
最终模型是性能最好的模型, 训练的时间(236B tokens)是其他模型的两倍。
- Architecture: GPT-2 model with multi-query attention and Fill-in-the-Middle objective
- Pretraining steps: 600K
- Pretraining tokens: 236 billion
- Precision: float16
- GPUs: 96 Tesla V100
- Training time: 6.2 days
- Total FLOPS: 2.1 x 10e21
We also noticed that a failure case of the model was that it would produce # Solution here code, probably because that type of code is usually part of exercise. To force the model the generate an actual solution we added the prompt <filename>solutions/solution_1.py\n# Here is the correct implementation of the code exercise.
import torch
from time import time
from transformers import AutoModelForCausalLM, AutoTokenizer,StoppingCriteriaList, StoppingCriteria
checkpoint = "E:\Learn\models\santacoder"
device = "cuda" # for GPU usage or "cpu" for CPU usage
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint, trust_remote_code=True).to(device)
class KeywordsStoppingCriteria(StoppingCriteria):
def __init__(self, keywords_ids:list):
self.keywords = keywords_ids
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
if input_ids[0][-1] in self.keywords:
return True
return False
stop = KeywordsStoppingCriteria([tokenizer.encode(w)[0] for w in ["<|endoftext|>", "```"]])
text = """"Below are a series of dialogues between various people and an AI technical assistant. The assistant tries to be helpful, polite, honest, sophisticated, emotionally aware, and humble-but-knowledgeable. The assistant is happy to help with code questions, and will do its best to understand exactly what is needed. It also tries to avoid giving false or misleading information, and it caveats when it isn't entirely sure about the right answer. That said, the assistant is practical and really does its best, and doesn't let caution get too much in the way of being useful.
-----
Human: Draw me a map of the world using geopandas. Make it so that only Germany and Spain are colored red.
Assistant: Sure. Here is a python file that does that.
\```
"""
inputs = tokenizer.encode(text, return_tensors="pt").to(device)
outputs = model.generate(inputs,
max_length=2000,
top_p=0.95,
top_k=10,
temperature=0.3,
do_sample=True,
stopping_criteria=StoppingCriteriaList([stop]))
print(tokenizer.decode(outputs[0]))
3. StarChat Alpha
StarChat是一个系列语言模型, 这些模型由StarCoder微调, 充当有用的编码助手。StarChat Alpha是这些模型中的第一个, 作为alpha版本仅用于教育或研究目的。特别是, 该模型没有与RLHF等技术的人类偏好保持一致, 因此可能会产生有问题的内容(尤其是在提示这样做时)。
- Model type: 一个16B参数类 GPT 模型, 在 oasst1 和 databricks-dolly-15k 数据集的混合上进行了微调。
- Language(s) (NLP): English
- License: BigCode Open RAIL-M v1
- Finetuned from model: bigcode/starcoderbase
4. GPT-2
4.1 Attention
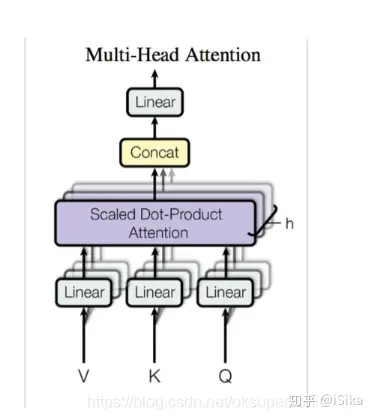
Attention模块的结构如上图所示, 只有Linear部分是可训练的, 第一次Linear将嵌入向量转换为Q, K, V, 第二次Linear将Attention的结果重新转换为嵌入向量, 作为下一层的输入。
从信息的角度来说, 嵌入向量首先被转换为三种信息, 即Query, Key和Value。信息的本性由用法(去向)决定, 而非由来源决定, 例如, Query之所以是Query, 是因为它在下式中与Key做点积, 只有当Query真正是Query的时候, 点积的结果才有效, 模型的效果才会好, 而模型在训练过程中就是根据结果学习Linear层, 让Query是Query。
在得到本次输入的Q, K和V之后, 将K, V和之前的K, V拼接起来, 使用下式做Attention:
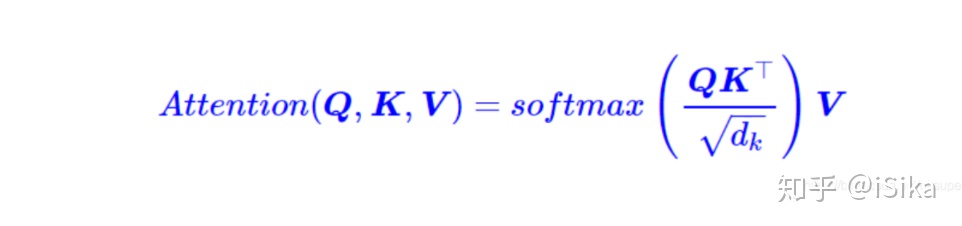
\(QK^T\)根据Query衡量上文的所有Key, 归一化为权重, 然后将权重附加给已经上文所有Value, 完成对上文的利用。
参考:
StarCoder: A State-of-the-Art LLM for Code
Homepage
A technical report about StarCoder
Creating a Coding Assistant with StarCoder
How to train a Language Model with Megatron-LM
注意力,多头注意力,自注意力及Pytorch实现
