
目录
BadgerDB 是一个用纯 Go 编写的可嵌入、持久且快速的键值 (KV) 数据库。它是Dgraph的底层数据库, 一个快速的分布式图数据库。它旨在成为 RocksDB 等非基于 Go 的键值存储的高性能替代品。
0. 源码目录结构
├── badger
│ └── cmd
├── docs: 文档
├── fb: Google flatbuffers
├── integration
│ └── testgc
├── options
├── pb: Protobuf 消息体
├── skl: 改编自 RocksDB inline inline skiplist, Skiplist实现
├── table: Table表的实现
├── trie: 字典树的实现
├── y: 可以归为工具类, 包含里引自 LevelDB的布隆过滤器实现、校验和、加密、文件处理、迭代器接口等
│ backup.go
│ batch.go
│ compaction.go
│ db.go
│ dir_plan9.go
│ dir_unix.go
│ dir_windows.go
│ discard.go
│ doc.go
│ errors.go
│ histogram.go
│ iterator.go
│ key_registry.go
│ levels.go
│ level_handler.go
│ logger.go
│ managed_db.go
│ manifest.go
│ memtable.go
│ merge.go
│ options.go
│ publisher.go
│ stream.go
│ stream_writer.go
│ structs.go
│ test.sh
│ txn.go
│ util.go
│ value.go
1. 数据结构
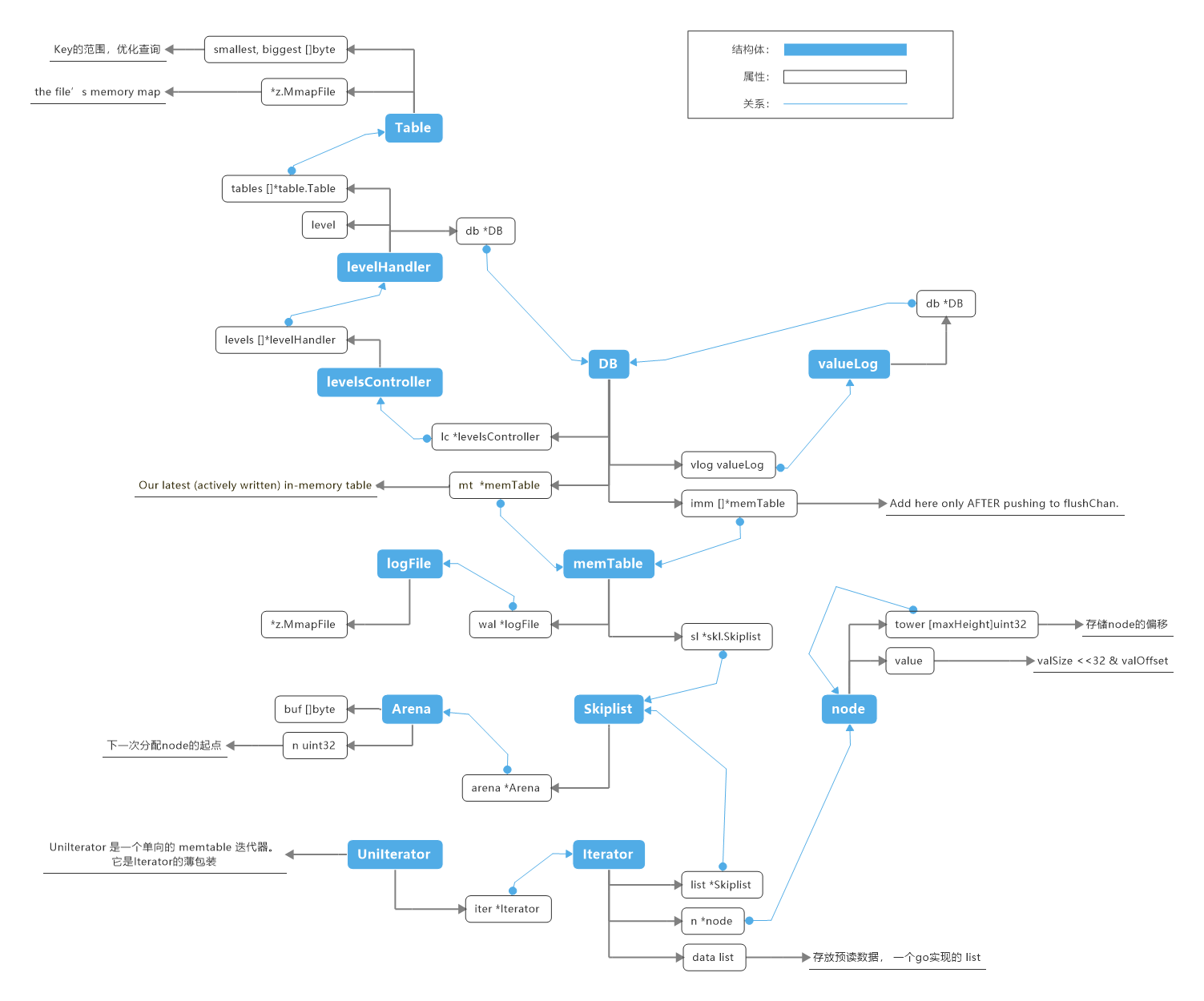
1.1 memTable 和 Table
memTable 结构存储了一个skiplist 和一个对应的WAL。对 memTable 的写入同时写入WAL和Skiplist。在崩溃时, 重播 WAL 以将Skiplist恢复到崩溃前的形式。
Table 表示一个加载的表文件, 其中包含我们所拥有的信息。smallest, biggest 可以在前缀查询时起到过滤作用。
type memTable struct {
sl *skl.Skiplist
wal *logFile
maxVersion uint64
opt Options
buf *bytes.Buffer
}
type Table struct {
sync.Mutex
*z.MmapFile
tableSize int // Initialized in OpenTable, using fd.Stat().
_index *fb.TableIndex // Nil if encryption is enabled. Use fetchIndex to access.
_cheap *cheapIndex
ref int32 // For file garbage collection. Atomic.
// The following are initialized once and const.
smallest, biggest []byte // Smallest and largest keys (with timestamps).
id uint64 // file id, part of filename
Checksum []byte
CreatedAt time.Time
indexStart int
indexLen int
hasBloomFilter bool
IsInmemory bool // Set to true if the table is on level 0 and opened in memory.
opt *Options
}
跳跃表在LevelDB中用于存储内存数据, 在LevelDB中被称作Memtable。
1.2 Inline Skiplist
改编自 RocksDB inline skiplist.内联跳跃表是对于LevelDB中的跳跃表的优化, 原理很简单, 通过更紧凑的内存安排:
- 减少了内存的使用
- 提供了更好的局部性
skiplist 的 Arena: 是提前预分配好的空间, 用来存放 node, Key, value(三者分开存放), 而node结构包含了key 和value在Arena中的位置偏移以及大小。
type Skiplist struct {
height int32 // Current height. 1 <= height <= kMaxHeight. CAS.
headOffset uint32
ref int32
arena *Arena
OnClose func()
}
type Arena struct {
n uint32
shouldGrow bool
buf []byte
}
type node struct {
value uint64 // valOffset & (valSize << 32)
keyOffset uint32 // Immutable. No need to lock to access key.
keySize uint16 // Immutable. No need to lock to access key.
height uint16
tower [maxHeight]uint32
}
s := skl.NewSkiplist(arenaSize(db.opt))
mt := &memTable{
sl: s,
opt: db.opt,
buf: &bytes.Buffer{},
}
func newArena(n int64) *Arena {
// Don't store data at position 0 in order to reserve offset=0 as a kind of nil pointer.
out := &Arena{
n: 1,
buf: make([]byte, n),
}
return out
}
func arenaSize(opt Options) int64 {
return opt.MemTableSize + opt.maxBatchSize + opt.maxBatchCount*int64(skl.MaxNodeSize)
}
func (s *Arena) putVal(v y.ValueStruct) uint32 {
l := uint32(v.EncodedSize())
offset := s.allocate(l)
v.Encode(s.buf[offset:])
return offset
}
func (s *Arena) putKey(key []byte) uint32 {
keySz := uint32(len(key))
offset := s.allocate(keySz)
buf := s.buf[offset : offset+keySz]
y.AssertTrue(len(key) == copy(buf, key))
return offset
}
1.3 logFile
type logFile struct {
*z.MmapFile
path string
// This is a lock on the log file. It guards the fd’s value, the file’s
// existence and the file’s memory map.
//
// Use shared ownership when reading/writing the file or memory map, use
// exclusive ownership to open/close the descriptor, unmap or remove the file.
lock sync.RWMutex
fid uint32
size uint32
dataKey *pb.DataKey
baseIV []byte
registry *KeyRegistry
writeAt uint32
opt Options
}
1.4 valueLog
type valueLog struct {
dirPath string
// guards our view of which files exist, which to be deleted, how many active iterators
filesLock sync.RWMutex
filesMap map[uint32]*logFile
maxFid uint32
filesToBeDeleted []uint32
// A refcount of iterators -- when this hits zero, we can delete the filesToBeDeleted.
numActiveIterators int32
db *DB
writableLogOffset uint32 // read by read, written by write. Must access via atomics.
numEntriesWritten uint32
opt Options
garbageCh chan struct{}
discardStats *discardStats
}
2. Inline Skiplist的实现
2.1 RocksDB InlineSkipList
之所以叫 InlineSkipList, 应该是因为 Node 将 key 和链表每层的指针连续存储:
template <class Comparator>
struct InlineSkipList<Comparator>::Node {
private:
// next_[0] is the lowest level link (level 0). Higher levels are
// stored _earlier_, so level 1 is at next_[-1].
std::atomic<Node*> next_[1];
};
格式如下:
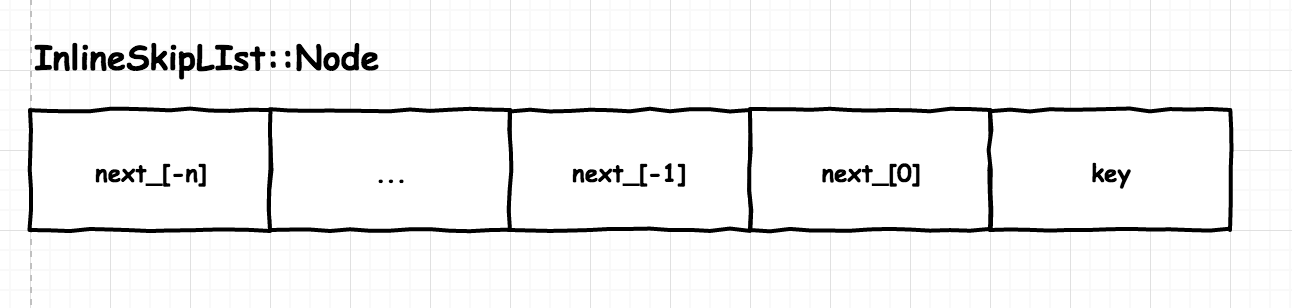
Node 直接存 key, 相比于 LevelDB 存 key 的指针, 可以减少部分内存使用, 更主要的是有更好的 cache locality, 访问 next_ 指针时, 因为内存连续会把 key 也一并放到 cache 中。而且 在遍历每层 list 时, 会 prefetch 后面的 Node:
#define PREFETCH(addr, rw, locality) __builtin_prefetch(addr, rw, locality)
2.2 Badger Skiplist
Badger Skiplist 改编自 RocksDB inline skiplist, 主要区别:
- 没有对顺序插入进行优化(没有"prev")。
- 没有自定义比较器。
- 支持覆盖。当我们在插入时看到相同的键时, 这需要小心。
对于 RocksDB 或 LevelDB, 覆盖是作为 key 中更新的序列号实现的, 所以不需要values。我们不打算支持版本控制。值的就地更新会更有效率。 - 我们丢弃所有非并发代码。
- 我们不支持Splices, 这大大简化了代码。
- 没有 AllocateNode 或其他指针算法。
- 我们将 findLessThan、findGreaterOrEqual 等组合成一个函数。
3. 操作的封装
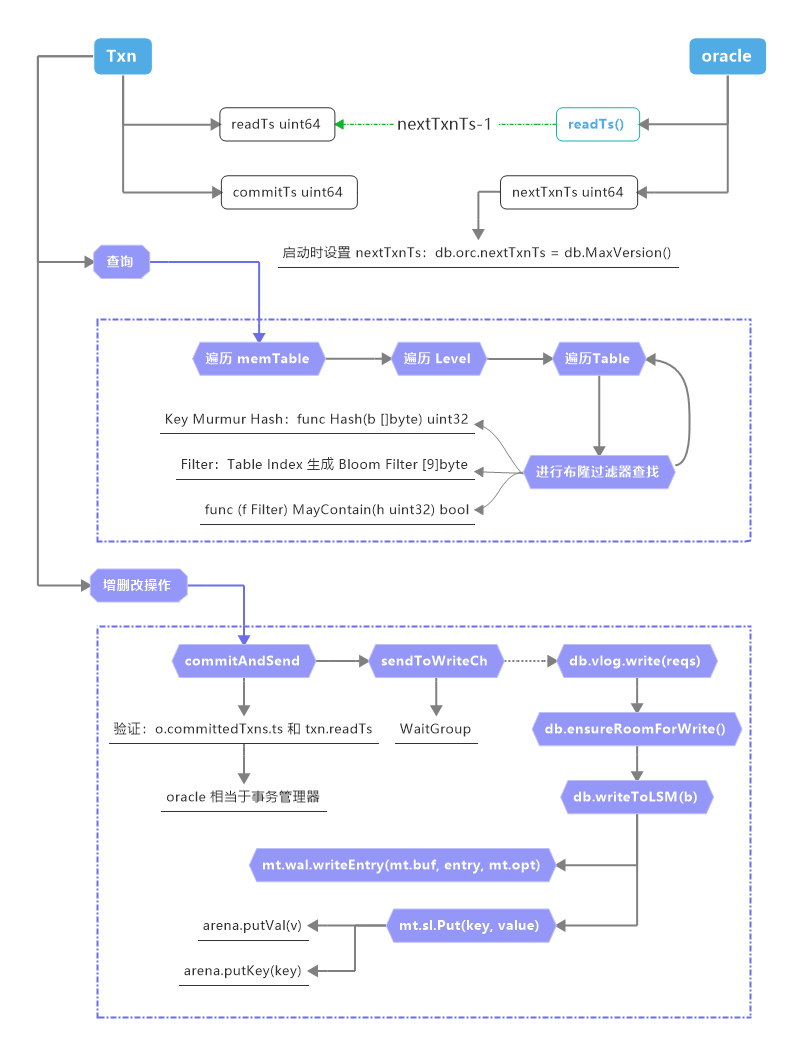
Badger提供了Get、Set、Delete和Iterate函数, 相关操作都封装到 Txn 和 oracle 两个结构体里. Txn 内部的信息主要是开始时间戳、提交时间戳、读写的 key 列表, oracle 相当于事务管理器, 内部维护近期提交的事务列表、全局时间戳、当前活跃事务的最早时间戳等。
WaterMark 结构体内部是个堆, 用于管理、查找事务开始、结束的区段。oracle 的 txnMarker 主要用于协调等待 Commit 授时与落盘的时间窗口, readMarker 管理当前活跃事务的最早时间戳, 用于清理过期的 committedTxns。
type Txn struct {
readTs uint64
commitTs uint64
size int64
count int64
db *DB
reads []uint64 // contains fingerprints of keys read.
// contains fingerprints of keys written. This is used for conflict detection.
conflictKeys map[uint64]struct{}
readsLock sync.Mutex // guards the reads slice. See addReadKey.
pendingWrites map[string]*Entry // cache stores any writes done by txn.
duplicateWrites []*Entry // Used in managed mode to store duplicate entries.
numIterators int32
discarded bool
doneRead bool
update bool // update is used to conditionally keep track of reads.
}
type oracle struct {
isManaged bool // Does not change value, so no locking required.
detectConflicts bool // Determines if the txns should be checked for conflicts.
sync.Mutex // For nextTxnTs and commits.
// writeChLock 确保事务以与其提交时间戳相同的顺序进入写入通道。
writeChLock sync.Mutex
nextTxnTs uint64
// Used to block NewTransaction, so all previous commits are visible to a new read.
txnMark *y.WaterMark
// Either of these is used to determine which versions can be permanently
// discarded during compaction.
discardTs uint64 // Used by ManagedDB.
readMark *y.WaterMark // Used by DB.
// committedTxns contains all committed writes (contains fingerprints
// of keys written and their latest commit counter).
committedTxns []committedTxn
lastCleanupTs uint64
// closer is used to stop watermarks.
closer *z.Closer
}
3.1 Key 的处理
Badger 对Key的处理有两种方式:
- 带有TS的Key
e.Key = y.KeyWithTs(e.Key, e.version)
func KeyWithTs(key []byte, ts uint64) []byte {
out := make([]byte, len(key)+8)
copy(out, key)
binary.BigEndian.PutUint64(out[len(key):], math.MaxUint64-ts)
return out
}
- Table 里的Key
keyNoTs := y.ParseKey(key)
func ParseKey(key []byte) []byte {
if key == nil {
return nil
}
return key[:len(key)-8]
}
更多细节可以查看文件y/y.go, 如:
func CompareKeys(key1, key2 []byte) int {
if cmp := bytes.Compare(key1[:len(key1)-8], key2[:len(key2)-8]); cmp != 0 {
return cmp
}
return bytes.Compare(key1[len(key1)-8:], key2[len(key2)-8:])
}
3.2 Badger 对事务的封装
DB.View()和DB.Update()方法可以被DB.NewTransaction()和Txn.Commit()方法封装 (或者在只读事务下使用Txn.Discard())。这些辅助方法将启动事务, 执行一个函数, 然后在返回错误时安全地丢弃您的事务。这是使用 Badger 事务的推荐方式。
err := db.View(func(txn *badger.Txn) error {
// Your code here…
return nil
})
err := db.Update(func(txn *badger.Txn) error {
// Your code here…
return nil
})
3.3 基本操作流程
3.3.1 键查找
- 对Key进行处理: 附加上Ts
seek := y.KeyWithTs(key, txn.readTs)
vs, err := txn.db.get(seek)
- 遍历每个 memTable 的 Skiplist (LSM查找)
tables, decr := db.getMemTables()
for i := 0; i < len(tables); i++ {
vs := tables[i].sl.Get(key)
}
func (s *Skiplist) Get(key []byte) y.ValueStruct {
n, _ := s.findNear(key, false, true) // findGreaterOrEqual.
if n == nil {
return y.ValueStruct{}
}
nextKey := s.arena.getKey(n.keyOffset, n.keySize)
if !y.SameKey(key, nextKey) {
return y.ValueStruct{}
}
valOffset, valSize := n.getValueOffset()
vs := s.arena.getVal(valOffset, valSize)
vs.Version = y.ParseTs(nextKey)
return vs
}
-
在Skiplist 查看Key 对应的Node的信息:
n, _ := s.findNear(key, false, true) -
在 arena 里获取 key 信息, 不存在则返回
-
在 arena 里获取 ValueStruct (它的Offset 和Size编码在 node.value)
-
最终, 还是要在 Level 里查找
db.lc.get(key, maxVs, 0)
version := y.ParseTs(key)
for _, h := range s.levels {
vs, err := h.get(key)
}
3.3.2 遍历查找(迭代)
Iterator 是迭代查询的底层数据结构。Badger 在 Iterator 之上又封装里UniIterator 和 MergeIterator. Badger 用 Go 实现了一个list 数据结构, 用来存放预读取的数据:
type Iterator struct {
list *Skiplist
n *node
data list
}
UniIterator 是一个单向的 memtable 迭代器。 它是迭代器的薄包装。 我们喜欢像以前一样保留迭代器, 因为它更强大, 并且我们将来可能会支持双向迭代器。
type UniIterator struct {
iter *Iterator
reversed bool
}
MergeIterator 合并多个迭代器, 并负责关闭它们。
type MergeIterator struct {
left node
right node
small *node
curKey []byte
reverse bool
}
在 Table 层实现了前缀查询基于表的过滤:
func (s *levelHandler) iterators(opt *IteratorOptions) []y.Iterator {
s.RLock()
defer s.RUnlock()
// ....
tables := opt.pickTables(s.tables)
if len(tables) == 0 {
return nil
}
return []y.Iterator{table.NewConcatIterator(tables, topt)}
}
func (opt *IteratorOptions) pickTables(all []*table.Table) []*table.Table {
// ...
sIdx := sort.Search(len(all), func(i int) bool {
// table.Biggest >= opt.prefix
// if opt.Prefix < table.Biggest, then surely it is not in any of the preceding tables.
return opt.compareToPrefix(all[i].Biggest()) >= 0
})
// ...
}
在对链表遍历时进行过滤(基于Key的有序存储):
func (it *Iterator) Valid() bool {
if it.item == nil {
return false
}
if it.opt.prefixIsKey {
return bytes.Equal(it.item.key, it.opt.Prefix)
}
return bytes.HasPrefix(it.item.key, it.opt.Prefix)
}
badger 里也存储里里一些自身数据, 需要过滤:
// Skip badger keys.
if !it.opt.InternalAccess && isInternalKey {
mi.Next()
return false
}
通过预读取数据到链表 data 中, 发挥 SSD的顺序读能力:
func (it *Iterator) prefetch() {
prefetchSize := 2
if it.opt.PrefetchValues && it.opt.PrefetchSize > 1 {
prefetchSize = it.opt.PrefetchSize
}
i := it.iitr
var count int
it.item = nil
for i.Valid() {
if !it.parseItem() {
continue
}
count++
if count == prefetchSize {
break
}
}
}
func (it *Iterator) parseItem() bool {
mi := it.iitr
key := mi.Key()
setItem := func(item *Item) {
if it.item == nil {
it.item = item
} else {
it.data.push(item)
}
}
// ...
}
3.3.3 增删改操作
通过 Txn 对 Badger 的 增删改操作, 最终都会 转换为txn.modify(e), 例如:
func (txn *Txn) Delete(key []byte) error {
e := &Entry{
Key: key,
meta: bitDelete,
}
return txn.modify(e)
}
在验证通过后, 就会写入到写通道db.writeCh <- req, 请求进程阻塞, 由一个常驻的后台进程处理实际写入请求, 这个进程在程序启动时一并启动:
func Open(opt Options) (*DB, error) {
go db.doWrites(db.closers.writes)
}
具体写入流程分为:
- valueLog 的写入:
db.vlog.write(reqs) - 确保写入的前置条件, 如空间分配等:
err = db.ensureRoomForWrite() - 最后是写入 LSM树:
db.writeToLSM(b)- memTable的 wal 日志写:
mt.wal.writeEntry(mt.buf, entry, mt.opt) - memTable的 skiplist的写入:
mt.sl.Put(key, value)
- memTable的 wal 日志写:
memTable的 wal 日志写涉及到里日志WAL文件大小的管理, 具体逻辑可以查看
ensureRoomForWrite函数
If WAL exceeds opt.ValueLogFileSize, we’ll force flush the memTable. See logic in ensureRoomForWrite.
3.3.4 查找Table时的布隆过滤
在过Key 查找对应Table表是, 使用里布隆过滤以减小表范围(布隆过滤算法使用的是 LevelDB的算法, 详细请见文件y/bloom.go):
func (f Filter) MayContain(h uint32) bool {
if len(f) < 2 {
return false
}
k := f[len(f)-1]
if k > 30 {
// This is reserved for potentially new encodings for short Bloom filters.
// Consider it a match.
return true
}
nBits := uint32(8 * (len(f) - 1))
delta := h>>17 | h<<15
for j := uint8(0); j < k; j++ {
bitPos := h % nBits
if f[bitPos/8]&(1<<(bitPos%8)) == 0 {
return false
}
h += delta
}
return true
}
而对应的Key 则采用了 Murmur hash:
func Hash(b []byte) uint32 {
const (
seed = 0xbc9f1d34
m = 0xc6a4a793
)
h := uint32(seed) ^ uint32(len(b))*m
for ; len(b) >= 4; b = b[4:] {
h += uint32(b[0]) | uint32(b[1])<<8 | uint32(b[2])<<16 | uint32(b[3])<<24
h *= m
h ^= h >> 16
}
switch len(b) {
case 3:
h += uint32(b[2]) << 16
fallthrough
case 2:
h += uint32(b[1]) << 8
fallthrough
case 1:
h += uint32(b[0])
h *= m
h ^= h >> 24
}
return h
}
4. 其他
// 系统预留的Key 命名前缀:
var (
badgerPrefix = []byte("!badger!") // Prefix for internal keys used by badger.
txnKey = []byte("!badger!txn") // For indicating end of entries in txn.
bannedNsKey = []byte("!badger!banned") // For storing the banned namespaces.
)
// 省略了大部分属性
type DB struct {
mt *memTable // Our latest (actively written) in-memory table
imm []*memTable // Add here only AFTER pushing to flushChan.
lc *levelsController
vlog valueLog
writeCh chan *request
orc *oracle
}
node 是存储到 Skiplist 到数据结构, 从 ValueStruct 转换而来, 这里的 value已经不是用户数据里的value。
type ValueStruct struct {
Meta byte
UserMeta byte
ExpiresAt uint64
Value []byte
Version uint64 // This field is not serialized. Only for internal usage.
}
// findSpliceForLevel returns (outBefore, outAfter) with outBefore.key <= key <= outAfter.key.
// The input "before" tells us where to start looking.
// If we found a node with the same key, then we return outBefore = outAfter.
// Otherwise, outBefore.key < key < outAfter.key.
func (s *Skiplist) findSpliceForLevel(key []byte, before uint32, level int) (uint32, uint32) {
for {
// Assume before.key < key.
beforeNode := s.arena.getNode(before)
next := beforeNode.getNextOffset(level)
nextNode := s.arena.getNode(next)
if nextNode == nil {
return before, next
}
nextKey := nextNode.key(s.arena)
cmp := y.CompareKeys(key, nextKey)
if cmp == 0 {
// Equality case.
return next, next
}
if cmp < 0 {
// before.key < key < next.key. We are done for this level.
return before, next
}
before = next // Keep moving right on this level.
}
}
func (s *Arena) putVal(v y.ValueStruct) uint32 {
l := uint32(v.EncodedSize())
offset := s.allocate(l)
v.Encode(s.buf[offset:])
return offset
}
func (v *ValueStruct) Encode(b []byte) uint32 {
b[0] = v.Meta
b[1] = v.UserMeta
sz := binary.PutUvarint(b[2:], v.ExpiresAt)
n := copy(b[2+sz:], v.Value)
return uint32(2 + sz + n)
}
func (s *Arena) putKey(key []byte) uint32 {
keySz := uint32(len(key))
offset := s.allocate(keySz)
buf := s.buf[offset : offset+keySz]
y.AssertTrue(len(key) == copy(buf, key))
return offset
}
func newNode(arena *Arena, key []byte, v y.ValueStruct, height int) *node {
// The base level is already allocated in the node struct.
nodeOffset := arena.putNode(height)
keyOffset := arena.putKey(key)
val := encodeValue(arena.putVal(v), v.EncodedSize())
node := arena.getNode(nodeOffset)
node.keyOffset = keyOffset
node.keySize = uint16(len(key))
node.height = uint16(height)
node.value = val
return node
}
Entry 是存储到 wal 里的数据结构, 是对用户上层数据的一层封装:
type Entry struct {
Key []byte
Value []byte
ExpiresAt uint64 // time.Unix
version uint64
offset uint32 // offset is an internal field.
UserMeta byte
meta byte
// Fields maintained internally.
hlen int // Length of the header.
valThreshold int64
}
mt.wal.writeEntry(mt.buf, entry, mt.opt)
