
目录
WiscKe一种基于 LSM 树的持久键值存储, 具有面向性能的数据分布, 其将键与值分离, 以最小化读写放大。WiscKey 的设计是为固态硬盘高度优化的, 其利用了固态硬盘的顺序和随机性能特征。Microbenchmark 结果显示, 在加载数据库方面, WiscKey 比 LevelDB 快2.5到111倍, 且具有明显更好的尾部延迟, 在随机查找方面快1.6到14倍。在YCSB场景中它比LevelDB和RocksDB都快。
1. 介绍
1.1 B-Tree
B树可以理解为二叉平衡树的多叉版本, 每一次更新可能需要平衡, 带来多次随机查找, 因此不适合固态或机械硬盘。
1.2 LSM-Tree(Log Structured Merge Tree)
目前的KV存储引擎中, 对写性能要求比较高的大多数都采用了LSM, 典型的有BigTable/LevelDB/Cassandra/HBase/RocksDB/PNUTS/Riak。
LSM相比其它索引树(如B树)的主要优势在于, 它的写都是顺序写。B树在有少量修改时, 都可能产生大量的随机写, 不管是SSD还是SATA上都表现不佳。
为了保证写性能, LSM会不停的批量把KV对写成文件; 为了保证读性能, LSM还需要不停的做背景compaction, 把这些文件合并成单个按Key有序的文件。这就导致了相同的数据在它的生命期中被反复读写。一个典型的LSM系统中数据的IO放大系数可以达到50倍以上。
LSM的成功在于, 它充分利用了SATA磁盘顺序IO性能远超随机IO的特点(100倍以上), 只要IO放大不超过这个数字, 那么用顺序IO来替代随机IO就是成功的。但到了SSD上就不一样了。SSD与SATA的几个不同:
- 顺序IO和随机IO的差别没那么大, 这让LSM为了减少随机IO而付出的额外的IO变得不再必要。
- SSD可以承受高并发的IO, 而LSM利用的并不好。
- 长期大量的重复写会影响SSD的性能和寿命。
以上3个因素综合起来, 会导致LSM在SSD上损失90%的吞吐, 并增加10倍的写负载。
WiscKey 优化了 LSM 树, 其核心思想是分离Key和Value, 只在LSM中维护Key, 把Value放在log中, 这样Key的排序和Value的GC就分开了。也就是排序和垃圾回收这两个过程分开。这样能够减少排序时不必要的值移动, 进而减小读写放大的倍数。此外这样还能减少 LSM 树大小, 减少读次数的同时, 在查询时有更好的缓存。
分离Key和Value带来的挑战:
- Scan时性能受影响, 因为Value不再按Key的顺序排列了。WiscKey的解法是充分利用SSD的高并发。
- 需要单独做GC来清理无效数据, 回收空间。WiscKey提出在线做轻量GC, 只需要顺序IO, 最小化对前台负载的影响。
- crash时如何保证一致性。WiscKey利用了现代文件系统的一个特性: append不会产生垃圾。
大多数场景WiscKey的性能都远超LevelDB和RocksDB, 除了一个场景: 小Value随机写, 且需要大范围的Scan。
2. 背景和动机
2.1 LSM
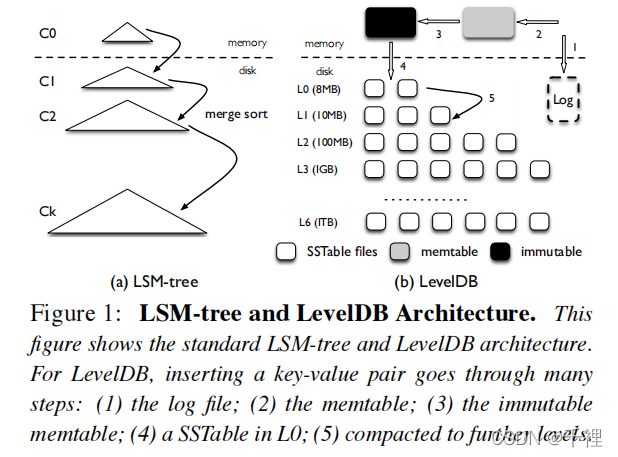
可以看到LSM中一个kv对要经历5次写:
- log文件
- memtable
- immutable memtable
- L0文件
- 其它level的文件
LSM用多次的顺序IO来避免随机IO, 从而在SATA磁盘上获得比B树高得多的写性能。
LSM 树是一个写, 删除频繁的场景下, 提供了有效索引的持续化结构。在写入时, 会延迟等待数据打包后, 一次性顺序写入磁盘。
LSM 树由许多组件(component)构成, C0放在内存, 是一个原地更新的排序好的树, 其他放在磁盘, 是只允许附加(append)的B树。组件大小随下标呈指数增长。插入时, 先将数据放到磁盘的顺序log文件中, 以防崩溃丢失数据, 然后插入排序好的C0。C0满了便与到磁盘的C1进行类似merge-sort的合并, 这个过程称为压缩(compaction)。磁盘上的组件也是如此, 一级满了会向下一级继续合并, 如图所示。
查询时, 从C0这样的热数据开始查询, 直到查询到最后一个Ci组件。因此与B树相比, LSM 需要多次读取, 所以 LSM 更适合插入、删除操作占主要操作的场景。
在读的时候, LSM需要在所有可能包含这个Key的memtable和文件中查找, 与B树相比, 多了很多IO。因此LSM适合于写多读少的场景。
2.2 LevelDB
LevelDB是一个广泛使用的键值存储, 它基于 LSM 树, 灵感来自于 BigTable。LevelDB 支持范围查询、快照和其他在现代应用程序中有用的特性。
LevelDB的整体架构见上节的图。LevelDB包括一个磁盘上的logfile, 两个内存中的memtable(memtable和immutable memtable), 以及若干个磁盘上的L0-L6的SSTable文件。
SStable 文件组织:
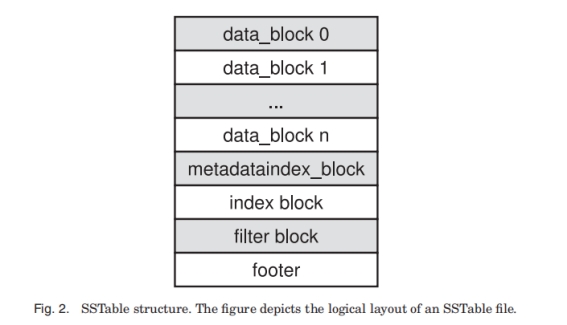
每个文件由许多块构成。每个块由三元对 <块数据, 类型, CRC循环冗余验证码> 构成。类型指的是数据的压缩状态。下面按照图2顺序依次介绍各个块内容:
- data_block: 每16个键值对采用前缀压缩方法储存, 即不保留各个键拥有的相同前缀, 只保留各自不同的后缀, 每16个键值对最后有一个重设点( restart point), 储存了原始键值。每个块最后有一堆偏移量(offset), 指向各个 restart point, 方便二分寻找。
- matadataindex_block: 保存一个指向 filter 块的指针。
- index_block: 如图3所示, 以三元对 <Key, Offset, Size> 构成, key指向每个块第一个key位置。
- Filter block: 采用 Bloom fifilter, 快速判断一个文件有没有某个键, 避免多余的二分查询。
- footer: 保存两个指针, 指向 matadata 以及 index 两个块。
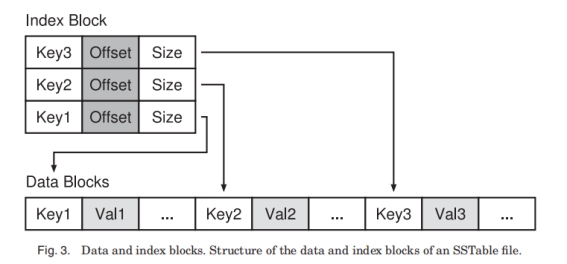
LevelDB插入时先写logfile, 再写进memtable; memtable满了之后变成immutable memtable(只读内存表), 再写成L0的SSTable文件(大约2MB)。每层SSTable文件的size比例差不多是10。L1-L6的SSTable都是通过compaction生成的, LevelDB保证每一层的各个SSTable文件的KeyRange不重叠, L0除外。
查找时就是在所有memtable和SSTable中做归并。
对于L1-L6层, 每层都有一个 MANIFEST 文件, 保存了本层各个文件的键范围, 以供快速查找本层哪个文件的范围覆盖了所查键值, 因此只需查1个文件。
2.3 读写放大
读写放大是LSM的主要问题。
写放大: 文件从Li-1到Li的过程中, 因为两层的size limit差10倍, 因此这次Compaction的放大系数最大可以到10。这样从L0到L6的放大系数可以达到50(L1-L6每层10)。
读放大: 假设L0有8个文件, 那么查找时最多需要读14个文件(L1-L6每层最多1个文件); 假设要读1KB的数据, 那么每个文件最多要读24KB的数据(index block + bloom-filter blocks + data block)。这么算下来读的放大系数就是14*24=336。如果要读的数据更小, 这个系数会更大。
一项测试中可以看到实际系统中的读写放大系数:
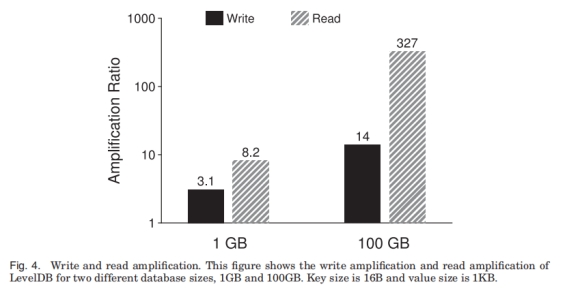
必须要说明的是, LSM的这种设计是为了在SATA磁盘上获得更好的性能。SATA磁盘的一组典型数据是寻址时间在10ms, 吞吐100MB/s, 而顺序读下一个Block的数据可能只要10us, 与寻址相比延时是1:1000, 因此只要LSM的写放大系数不超过1000, 就能获得比B树更好的性能。而B树的读放大也不低, 比如读1KB的数据, B树可能要读6个4KB的Block, 那么读放大系数是24, 没有完全拉开和LSM的差距。
2.4 快速存储硬件
SSD上仍然不推荐随机写, 因为SSD的整块擦除再写以及代价高昂的回收机制, 当SSD上预留的Block用光时, 它的写性能会急剧下降。LSM的最大化顺序写的特性很适合SSD。
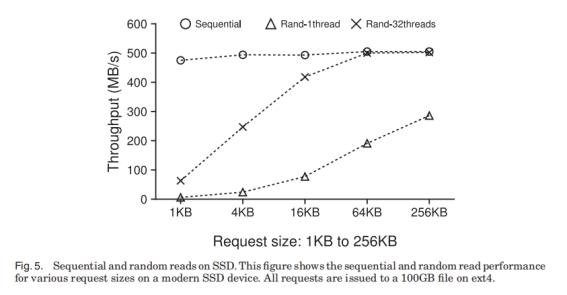
但与SATA非常不同的是, SSD的随机读性能非常好, 且支持高并发。
3. WiscKey
WickKey的设计出发点就是如何利用上SSD的新特性:
- Key与Value分离, Key由LSM维护, 而Value则写入logfile。
- 鉴于Value不再排序, WiscKey在读的时候会并发随机读。
- WiscKey在Value log的管理上有自己的一致性和回收机制。
- WiscKey在去除了LSM的logfile后仍然能保证一致性。
3.1 设计目标
WiscKey脱胎于LevelDB, 可以作为关系型DB和分布式KV的存储引擎。它兼容LevelDB的API。
设计目标:
- 低写放大: 既为了写性能, 也为了SSD的寿命。
- 低读放大: 读放大会降低读的吞吐, 同时还降低了cache效率。
- 面向SSD优化。
- 丰富的API。
- 针对实际的Key-Value大小, 不做太不实际的假设。通常的Key都很小(16B), Value则从100B到4KB都很常见。
3.2 Key与Value分离
LSM 树最大开销就是不断排序的压缩环节: 一遍遍的过数据。但不做compaction又没办法保证读的性能。
WiscKey受到了这么一个小发现的启示: 我们要排序的只是Key, Value完全可以另行处理。通常Key要比Value小很多, 那么排序Key的开销也就比Value要小很多。
WiscKey中与Key放在一起的只是Value的位置, Value本身存放在其它地方。
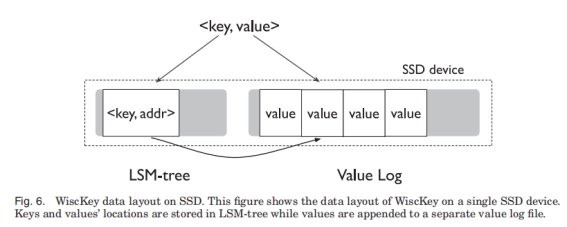
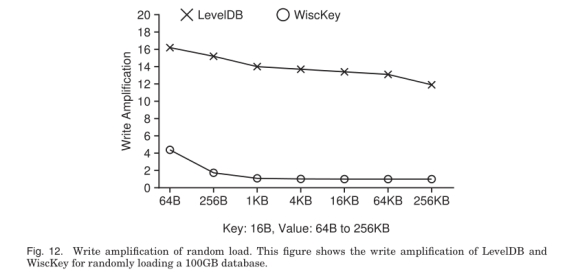
常见的使用场景下, WiscKey中的LSM要比LevelDB小得多。这样就大大降低了写的放大系数。Key为16B, Value为1KB的场景, 假设Key的放大系数是10(LSM带来的), Value的放大系数是1, 那么WiscKey的整体放大系数是(10 × 16 + 1024) / (16 + 1024) = 1.14。
查找的时候, WiscKey先在LSM中查找Key, 再根据Key中Value的位置查找Value。因为WiscKey中的LSM比LevelDB中的小很多, 前面的查找会快很多, 绝大多数情况下都能命中cache, 这样整个开销就是一次随机查找。而SSD的随机查找性能又这么好, 因此WiscKey的读性能就比LevelDB好很多。
插入一组kv时, WiscKey先把Value写入ValueLog, 然后再把Key插入到LSM中。删除一个Key则只从LSM中删除它, 不动ValueLog。
3.3 挑战
虽然键值分离很容易想到, 但是也带来了很多挑战和优化空间。比如, 键值分离导致范围查询需要随机读写。此外, 分离将会带来垃圾回收和崩溃一致性的挑战。
3.3.1 并发范围查找
LevelDB中这么做RangeQuery: 先Seek(), 然后根据需求反复调用Next()或Prev()读出数据。LevelDB中Key和Value是存放在一起的, 这么扫一遍对应底层就只有顺序IO, 性能很好(不考虑读放大)。
WiscKey中Key和Value是分开存放的, 这么做就会带来大量的串行随机IO, 不够高效。WiscKey利用SSD的高并发随机读的特性, 在对LSM调用RangeQuery期间, 并发预读后面的N个Value。
3.3.2 垃圾回收
LSM都是通过compaction来回收无效数据的。WiscKey中Value不参与compaction, 就需要单独为Value设计GC机制。
一个土办法是扫描LSM, 每个Key对应的Value就是有效的, 没有Key对应的Value就是无效的。这么做效率太低。WiscKey的做法是每次写入Value时也写入对应的Key。

上图中的head总是指向Value Log的尾部, 新数据写到这里。而tail会随着GC的进行向后移动。所有有效数据都在tail~head区间中, 每次GC都从tail开始, 也只有GC线程可以修改tail。
GC时WiscKey每次从tail开始读若干MB的数据, 然后再查找对应的Key, 看这个Key现在对应的Value还是不是log中的Value, 如果是, 再把数据追加到head处。最终, ValueLog中的无效数据就都被清理掉了。
为了避免GC时crash导致丢数据, WiscKey要保证在真正回收空间前先把新追加的数据和新的tail持久化下去:
- 追加数据
- GC线程调用fsync()将新数据写下去
- 向LSM中同步写一条记录: <‘tail’, tail-vlog-offset>
- 回收空间
WiscKey的GC是可配置的, 如果Key的删除和更新都很少发生, 就不需要怎么做GC。
3.3.3 崩溃时的一致性
WiscKey为了保证系统崩溃时的一致性, 使用了现代文件系统(ext4/btrfs/xfs等)的一个特性: 追加写不会产生垃圾, 只可能在尾部缺少一些数据。在WiscKey中这个特性意味着: 如果Value X在一次crash后从Value Log中丢失了, 那么所有X后面写入的Value就都丢了。
crash中丢失的Key是没办法被发现的, 这个Key对应的Value会被当作无效数据GC掉。如果查找时发现Key存在, 但对应的Value不在Value Log中, 就说明这个Value丢失了, WiscKey会将这个Key从LSM中删除, 并返回"Key不存在"。(没办法找回上一个Value了是吗?)
如果用户配置了sync, WiscKey会在每次写完Value Log后, 写LSM前, 调用一次fsync。
总之WiscKey保证了与LevelDB相同的一致性。
3.4 优化
键值分离提供了一个重新思考的机会, 即 vLog 如何更新?LSM log 是否有存在的必要性?
3.4.1 ValueLog的写缓冲
WiscKey不会每笔写入都调用一次ValueLog的write, 这样效率太低。WiscKey为ValueLog准备了一个buffer, 所有写都写进buffer, 当写满或者有sync请求时再write写到ValueLog中。读取的时候优先读取buffer。
缺点是在crash丢的数据会多一些, 这点与LevelDB类似。
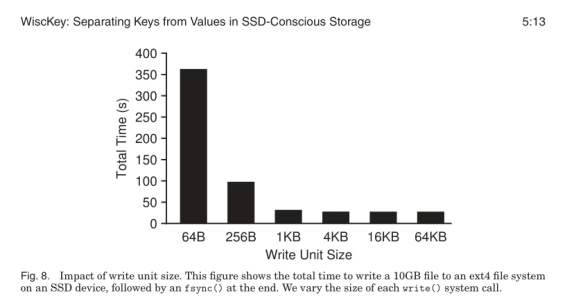
下图显示了 ext4 (Linux 3.14) 中连续写入10GB文件的总时间。对于较小的写操作, 每个系统调用的开销会显著增加, 导致运行时间很长。而对于较大的写操作(大于4KB), 设备吞吐量则得到充分利用。
3.4.2 优化LSM的log
日志文件通常用于 LSM 树。LSM 树在日志文件中跟踪插入的键值对, 这样, 如果用户请求同步插入时出现崩溃, 则可以在重启后扫描日志, 并恢复插入的键值对。
WiscKey中LSM只用于存储Key, 而Value Log中也存储了Key, 那么就没必要再写一遍LSM的log了。
WiscKey在LSM中存储了一条记录<‘head’, head-vlog-offset>, 在打开一个DB时就可以从head-vlog-offset处开始恢复数据。将head保存在LSM中也保证了一致性不低于LevelDB, 因此整体的一致性仍然不低于LevelDB。
3.5 实现
Wisckey 基于LevelDB 1.18。Wisckey 在创建新数据库时创建一个 vLog, 并管理 LSM 树中的键和值地址。vLog 被内部多个组件访问的模式不同。
Value Log会被两种方式访问:
- 读取时会随机访问ValueLog
- 写入时会顺序写入ValueLog
WiscKey用pthread_fadvise()在不同场景声明不同的访问模式。
WiscKey为RangeQuery准备了一个32个线程的背景线程池来随机读Value Log。这些线程在线程安全的队列中休眠, 等待新值地址到达。当触发预取时, Wisckey 将固定数量的值地址插入到工作队列中, 然后唤醒所有处于睡眠状态的线程。这些线程将开始并行读取值, 并自动将它们缓存到缓冲区缓存中。
为了有效地从Value Log中回收空间, WiscKey利用了现代文件系统的另一个特性: 可以给文件打洞(fallocate)。在文件上穿孔可以释放对应分配的物理空间, 并允许Wisckey 弹性地使用存储空间。现代文件系统允许的最大文件大小足够WiscKey用了(ext4允许64TB, xfs允许8EB, btrfs允许16EB), 这样就不需要考虑Value Log的切换了。
3.5.1 fallocate的功能
具体可以参考: fallocate(2) - Linux manual page (man7.org)
fallocate 传入参数有4个:
fd: 文件的描述符
mod: 模式, 有四种模式
offset: 文件的偏移量, 作为起点
len: 长度, offset+len 作为终点
Mod 有四大选项, 对应四大功能:
分配磁盘空间。默认选项, 扩大文件所占磁盘空间大小并初始化为0
给文件打洞。起点和终点之间的数据块被移除, 但是依然能访问, 后续访问返回0, 文件大小不变
折叠文件。起点和终点之间的数据被移除, 终点后数据附加到起点, 文件大小变小
给文件置零。起点和终点之间数据被置为0, 但是并不涉及物理设备置零, 而是修改 matadata。后续对范围内的数据读将返回0
4. 评估
机器配置:
CPU: Intel(R) Xeon(R) CPU E5-2667 v2 @ 3.30GHz * 2;
内存: 64GB;
OS: 64-bit Linux 3.14;
文件系统: ext4;
SSD: 500-GB Samsung 840 EVO SSD, 顺序读500MB/s, 顺序写400MB/s。
4.1 基准测试
工具: db_bench;
DB: LevelDB/WiscKey;
Key: 16B;
Value: 很多大小;
压缩: 关闭。
4.1.1 Load
第一轮: 顺序插入100GB的数据。第二轮: uniform随机写。注意第一轮顺序写不会导致LevelDB和WiscKey做compaction。

即使在256KB场景中, LevelDB的写入吞吐仍然距离磁盘的带宽上限很远。
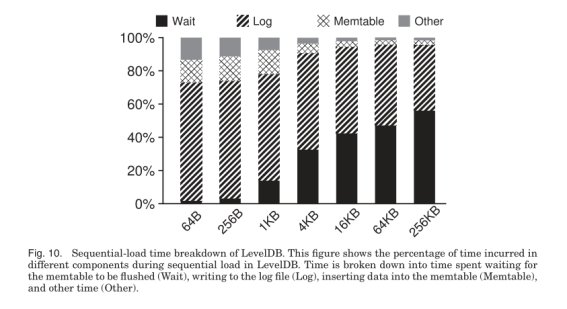
可以看到小Value时LevelDB的延时主要花在写log上, 而大Value时延时主要花在等待写memtable上。
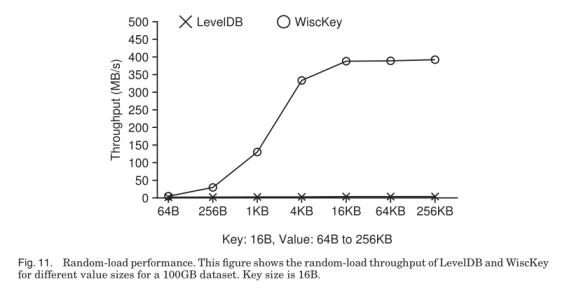
LevelDB的吞吐如此之低, 原因在于compaction占了太多资源, 造成了太大的写放大。WiscKey的compaction则只占了很少的资源。
下图是不同ValueSize下LevelDB的写放大系数。
4.1.2 Query
第一轮: 在100GB随机生成的DB上做100000次随机查找。第二轮: 在100GB随机生成的DB上做4GB的范围查找。
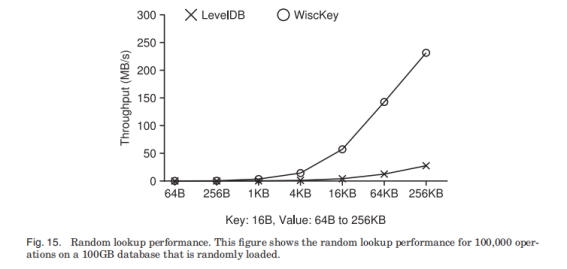
LevelDB的低吞吐原因是读放大和compaction资源占用多。
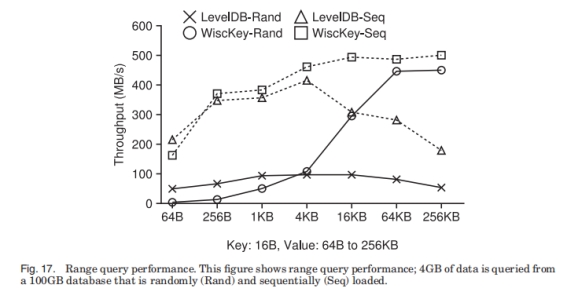
ValueSize超过4KB后, LevelDB生成的SSTable文件变多, 吞吐变差。此时WiscKey吞吐是LevelDB的8.4倍。而在ValueSize为64B时, 受限于SSD的随机读能力, LevelDB的吞吐是WiscKey的12倍。如果换一块支持更高并发的盘, 这里的性能差距会变小一些。
但如果数据是顺序插入的, 那么WiscKey的ValueLog也会被顺序访问, 差距就没有这么大。64B时LevelDB是WiscKey的1.3倍, 而大Value时WiscKey是LevelDB的2.8倍。
4.1.3 垃圾回收
测试内容: 1. 随机生成DB; 2. 删掉一定比例的kv; 3. 随机插入数据同时后台做GC。作者固定Key+Value为4KB, 但第二步删除的kv的比例从25%-100%不等。
100%删除时, GC扫过的都是无效的Value, 也就不会写数据, 因此只降低了10%的吞吐。后面的场景GC都会把有效的Value再写进ValueLog, 因此降低了35%的吞。
无论哪个场景, WiscKey都比LevelDB快至少70倍。
4.1.4 崩溃时的一致性
作者一边做异步和同步的Put(), 一边用ALICE工具来模拟多种系统崩溃场景。ALICE模拟了3000种系统崩溃场景, 没有发现WiscKey引入的一致性问题。(不比LevelDB差)
WiscKey在恢复时要做的工作比LevelDB多一点, 但都与LSM最后一次持久化memtable到崩溃发生之间写入的数据量成正比。在一个最坏的场景中, ValueSize为1KB, LevelDB恢复花了0.7秒, 而WiscKey花了2.6秒。
WiscKey可以通过加快LSM中head记录的持久化频率来降低恢复时间。
4.1.5 空间放大
我们在评估一个kv系统时, 往往只看它的读写性能。但在SSD上, 它的空间放大也很重要, 因为单GB的成本变高了。所谓空间放大就是kv系统实际占用的磁盘空间除以用户写入的数据大小。压缩能降低空间放大, 而垃圾、碎片、元数据则在增加空间放大。作者关掉了压缩, 简化讨论。
完全顺序写入的场景, 空间放大系数很接近1。而对于随机写入, 或是有更新的场景, 空间放大系数就会大于1了。
下图是LevelDB和WiscKey在载入一个100GB的随机写入的数据集后的DB大小。
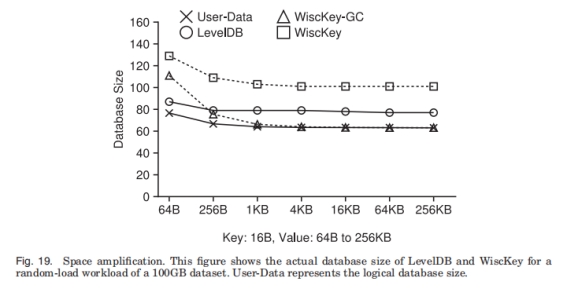
LevelDB多出来的空间主要是在加载结束时还没来得及回收掉的无效kv对。WiscKey多出来的空间包括了无效的数据、元数据(LSM中的Value索引, ValueLog中的Key)。在GC后无效数据就没有了, 而元数据又非常少, 因此整个DB的大小非常接近原始数据大小。
KV存储没办法兼顾写放大、读放大、空间放大, 只能从中做取舍。LevelDB中GC和排序是在一起的, 它选择了高的写放大来换取低的空间放大, 但与此同时在线请求就会受影响。WiscKey则用更多的空间来换取更低的IO放大, 因为GC和排序被解耦了, GC可以晚一点做, 对在线请求的影响就会小很多。
4.1.6 CPU使用率
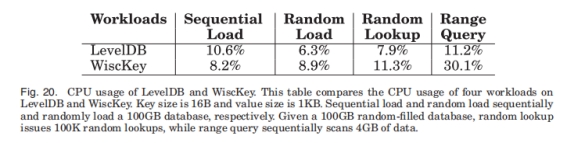
可以看到除了顺序写入之外, LevelDB的CPU使用率都要比WiscKey低。
顺序写入场景LevelDB要把kv都写进log, 还要编码kv, 占了很多CPU。WiscKey写的log更少, 因此CPU消耗更低。
范围读场景WiscKey要用32个读线程做背景的随机读, 必然用多得多的CPU。
LevelDB不是一个面向高并发的DB, 因此CPU不是瓶颈, 这点RocksDB做得更好。
4.2 YCSB测试
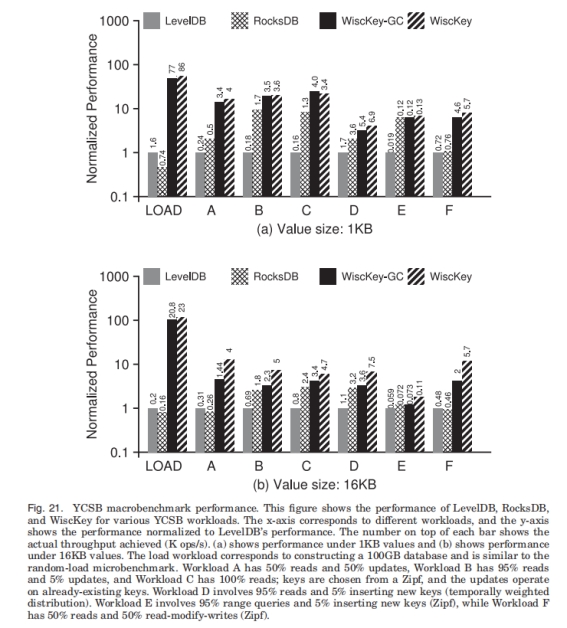
4.2.1 Zipf分布
Zipf 分布也叫齐夫分布, 他是一个自然语言学家, 提出了一个齐夫定律: 在自然语言的语料库里, 一个单词出现的频率与它在频率表里的排名成反比。所以, 频率最高的单词出现的频率大约是出现频率第二位的单词的2倍, 而出现频率第二位的单词则是出现频率第四位的单词的2倍。即一个频率是减半减少, 或指数下降的频率分布
5. RELATED WORK
现如今, 针对固态硬盘已经提出了各种基于哈希表的键值存储。FAWN 将键值对保存固态硬盘上的只追加日志中, 并使用内存中的哈希表索引进行快速查找。FlashStore 采用了相同的设计, 但进一步优化了内存中的哈希表; FlashStore 使用布谷鸟哈希( cuckoo hashing)和紧凑的密钥签名, 而 SkimpyStash 使用线性链接将表的一部分移动到固态硬盘。BufferHash 使用多个内存哈希表, 且使用 Bloom 过滤器选择使用哪个哈希表进行查找。 SILT 对内存进行了高度优化, 并使用了日志结构、哈希表和排序表的组合。 WiscKey 与这些键值存储都使用了同样的日志结构数据分布。但是, 这些存储使用散列表进行索引, 因此不支持构建在 LSM 树存储之上的现代特性, 如范围查询或快照。相反, WiscKey 旨在实现一个功能丰富的键值存储, 可以在各种情况下使用。
优化原始 LSM 树键值存储方面也有很多相关工作。bLSM 提出了一种新的合并调度程序来限制写延迟, 从而保持稳定的写吞吐量, 并使用 Bloom 过滤器来提高性能。VT-tree 通过使用间接层来避免在压缩过程中对之前已经排序过的键值再次进行排序。WiscKey 则直接将值与键分离, 大大减少了写放大, 而不用管工作负载中的键分布如何。LOCS 将内部 flash 通道暴露给 LSM-tree 键值存储, 于是可以利用丰富的并行性进行更有效的压缩。Atlas 是一种基于 ARM 处理器和擦除编码的分布式键值存储, 将键和值存储在不同的硬盘上。 WiscKey 是一个独立的键值存储, 其中键和值之间的分离为固态硬盘进行了高度优化, 以获得显著的性能增益。LSM-trie 使用字典树结构来组织键, 并提出了一种更有效的基于字典树的压缩方法; 然而, 这种设计牺牲了 LSM 树的特性, 比如对范围查询的有效支持。之前描述过的RocksDB, 由于其设计与 LevelDB 基本相似, 所以仍然具有很高的写放大倍数; RocksDB 的优化与 WiscKey 的设计是正交的。
Walnut 是一种混合对象存储, 它将小对象存储在 LSM-tree 中, 并将大对象直接写入文件系统。IndexFS 使用列模式将元数据存储在 LSM-tree 中, 以提高插入的吞吐量。Purity 通过仅对索引进行排序并按时间顺序存储元组, 进而将其索引从数据元组中分离出来。这三个系统使用了和 WiscKey 相似的技术。然而, 我们以一种更通用和完整的方式解决了这个问题, 并在广泛的工作负载中优化了固态硬盘的加载和查找性能。
基于其他数据结构的键值存储也被提出过。TokuDB 基于分形树索引, 在内部节点中缓存更新; 其键是没有排序的, 因此为了获得良好的性能, 必须在内存中维护一个大的索引。ForestDB 使用HB±trie 来高效地索引长键, 以提高性能并减少内部节点的空间开销。NVMKV 是一个 FTL-aware 的键值存储, 它使用了原生的 FTL 功能, 比如稀疏寻址和事务支持。对于键值存储, 也提出了将多个请求分组为单个操作的向量接口。由于这些键值存储基于不同的数据结构, 它们在性能方面都有不同的权衡; 而 WiscKey 则提出了改进广泛使用的 LSM 树结构的方案。
许多被提出的技术寻求克服内存中键值存储的可扩展性瓶颈, 如 Masstree 、MemC3 、Memcache 、MICA 和cLSM 。这些技术可以用于 WiscKey , 以进一步提高其性能。
6. CONCLUSIONS
键值存储已经成为数据密集型应用程序的基石。在本文中, 我们提出了 WiscKey, 一种基于 LSM 树的新的键值存储, 它分离键和值, 以最小化读写放大。 WiscKey 的数据格式和读写模式针对固态硬盘进行了高度优化。我们的结果表明, 对于大多数工作负载, WiscKey 可以显著提高性能。
我们相信未来还有很多工作方向。例如, 在 WiscKey 中, 垃圾收集是由单个后台线程完成的。线程从 vLog 文件的尾部读取一个键值对块; 然后, 对于每个键值对, 它在 LSM 树中检查是否有效; 最后, 有效的键值对被写回 vLog 文件的头。我们可以通过两种方式改进垃圾回收。首先, LSM-tree 中的查找很慢, 因为可能设计多次随机读取。为了加快这个过程, 我们可以使用多个线程并发地执行不同键值对的查找。其次, 我们可以通过在 vLog 文件中维护一个无效键值对的位图来提高垃圾收集的效率。当触发垃圾收集时, 它将首先回收空闲空间百分比最高的块。
另一个扩展 LevelDB 或 WiscKey 的有趣方向是对数据库进行分片。由于只有一个共享数据库, LevelDB 的许多组件都是单线程的。正如我们前面讨论的, 有一个 memtable 在内存中缓冲写入。当 memtable 被填满时, 前台写操作将会停止, 直到压缩线程将memtable 刷新到磁盘。在 LevelDB中, 只允许一个写线程更新数据库。数据库由一个全局互斥锁保护。后台压缩线程在对键值对进行排序时也需要获取这个互斥锁, 因此便与前台写操作竞争。对于多线程写入的工作负载, 这种架构会不必要地阻塞并发写。一种解决方案是将数据库和相关内存结构划分为多个较小的片。每个片的键不与其他片重叠。在这种设计下, 对不同键值范围的写入可以并发地执行到不同的分片。随机查找也可以分布到一个目标分片, 而不需要搜索所有分片。由于要搜索的数据集更小, 这种新设计可能会使查找速度更快。我们初步实现了一个分片 WiscKey 的原型, 这已经产生了性能的提升, 因此这是另一个未来工作的明确方向。
总的来说, 键值存储在现代可扩展系统中是一个越来越重要的组件。因此, 使键值储存提供更高和更一致的性能将可能持续成为未来几年的重点。随着更新、更快的储存介质取代固态硬盘, 未来可能需要更进一步的软件创新。
