
目录
LLM 天生就不擅长规划。需要使用自定义模型和一种独特的方法来提高 LLM 的能力, 以通过 PDDL(规划领域定义语言)生成有效的计划基于严密的表示、微调和上下文学习, 采取行动的步骤仍然很复杂, 而且失败的次数比生产系统想要的要多最后, 它们很难大规模监控和调试。甚至不要谈论幻觉和成本。
许多人认为智能代理是 AI 的最终目标。Stuart Russell 和 Peter Norvig 的经典著作《人工智能: 一种现代方法》(Artificial Intelligence: A Modern Approach, Prentice Hall, 1995 年)将 AI 研究领域定义为"理性代理的研究和设计"。
这是最早的关于 LLM 代理的论文之一。虽然以今天的标准来看它似乎很基本, 但当时 ChatGPT 还没有发布, 教 LLM 使用工具的想法是开创性的。
“代理"可以通过多种方式定义。一些客户将代理定义为完全自主的系统, 这些系统在较长时间内独立运行, 使用各种工具完成复杂的任务。其他人使用该术语来描述遵循预定义工作流的更规范的实施。在 Anthropic, 我们将所有这些变体归类为代理系统, 但在工作流和代理之间划定了一个重要的架构区别:
- 工作流是通过预定义的代码路径编排 LLM 和工具的系统。
- 另一方面, 代理是 LLM 动态指导自己的流程和工具使用, 保持对他们完成任务方式的控制的系统。
0. 介绍
使用 LLM 构建应用程序时, 我们建议找到尽可能简单的解决方案, 并且仅在需要时增加复杂性。这可能意味着根本不构建代理系统。代理系统通常会以延迟和成本为代价来获得更好的任务性能, 您应该考虑何时进行这种权衡是有意义的。
当需要更高的复杂性时, 工作流为定义明确的任务提供可预测性和一致性, 而当需要大规模的灵活性和模型驱动的决策时, 代理是更好的选择。但是, 对于许多应用程序, 使用检索和上下文示例优化单个 LLM 调用通常就足够了。
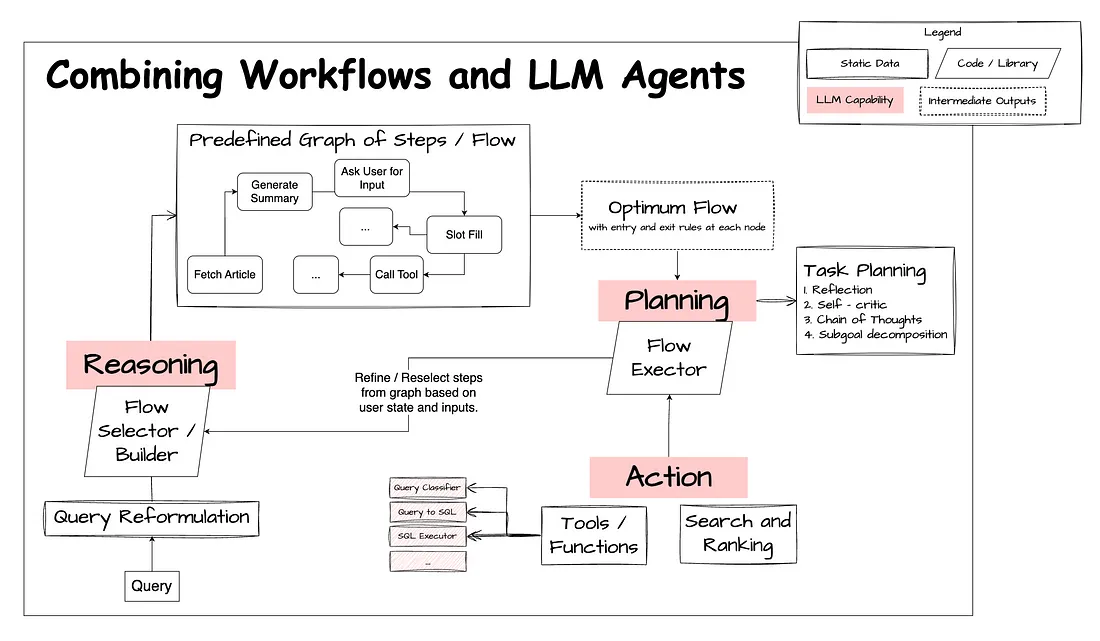
目前, 有许多工作流程设计。为了根据它们的重点对它们进行总结, 我们将迄今为止学到的工作流设计模式分为两组: 以 Reflection-focus 和 Planning-focused。
将推理、计划和行动分解为不同的组件可以减少65%的代币, 并在生成答案方面提高4-5%的准确性。
关键原则是, 我们不是循环访问计划->工具使用->观察->推理->计划, 而是在一次调用中生成有效计划的列表, 从工具中获取观察结果并在一次调用中生成最终答案。
1. 工作流设计模式
为了根据它们的重点对它们进行总结, 我们将迄今为止学到的工作流设计模式分为两组: 以 Reflection-focus 和 Planning-focused。
1.1 Reflection-focus
即使是最好的计划也需要不断评估和调整, 以最大限度地提高成功的机会。虽然反射不是代理作所必需的, 但代理成功是必要的。
在任务过程中, 反射在许多地方都很有用:
- 收到用户查询后, 评估请求是否可行。
- 在初始计划生成之后, 评估计划是否有意义。
- 在每个执行步骤之后, 以评估它是否在正确的轨道上。
- 执行整个计划后, 确定任务是否已完成。

Reflection 允许代理从经验中学习, 从而提高适应性和弹性。这些代理人强调反省和从过去的经验中学习。他们分析以前的行动和结果以改进未来的行为。通过评估他们的绩效, 他们发现错误和成功, 从而实现持续改进。这种反思过程使代理能够随着时间的推移调整其策略, 从而更有效地解决问题。
LangChain 博客
与计划生成相比, 反射相对容易实现, 并且可以带来非常好的性能改进。这种方法的缺点是延迟和成本。想法、观察结果, 有时还需要作来生成大量令牌, 这会增加成本和用户感知的延迟, 尤其是对于具有许多中间步骤的任务。为了促使他们的代理遵循这种格式, ReAct 和 Reflexion 的作者在他们的提示中使用了大量示例。这会增加计算 input token 的成本, 并减少可用于其他信息的上下文空间。
1.2 Planning-focused
规划使代理能够有条不紊地处理任务, 从而提高效率和效果。这些代理在采取行动之前会优先考虑制定结构化计划。他们将复杂的任务分解为可管理的子任务, 并对它们进行逻辑排序以实现特定目标。通过制定详细的计划, 这些代理可以预测潜在的挑战并有效地分配资源, 从而产生更有条理和目标导向的行为。
https://arxiv.org/pdf/2402.02716
- 计划与解决: 重新计划→→任务列表。
- LLM 编译器: →联合执行并行→ 计划行动。
- REWOO: 计划(包括依赖项)→ 操作(取决于上一步)。
- Storm: 搜索大纲 → 在大纲中搜索每个主题 → Summarize 转换为长文本。
在查看这些设计模式时, 我们将工作流视为业务流程协调程序。每个节点可以表示一个 LLM 任务、一个函数调用和其他任务, 例如检索增强生成(RAG)任务, 我们通常将其视为另一种类型的函数调用。这个概念是我们开发自己的代理的主要驱动力之一。我们将工作流设计为灵活的任务编排器, 允许开发人员创建各种工作流来解决不同的问题。
1.3 两种特定的工作流设计模式
1.3.1 ReAct 模式
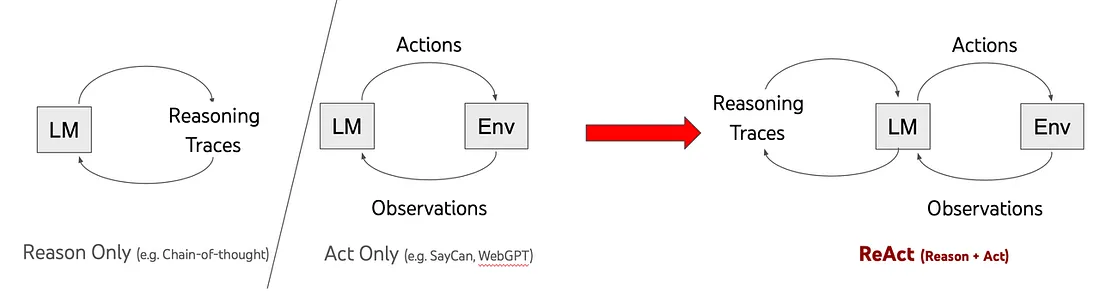
ReAct 原则很简单, 反映了人类智能的一个核心方面: “由语言推理指导的行动”。每次行动后, 都有一个内心的"观察"或自我反省: “我刚刚做了什么?我实现了我的目标吗?这使代理能够保留短期记忆。在 ReAct 之前, 推理和行动被视为单独的过程。
例如, 假设你让某人在你的桌子上找到一支笔, 你给出分步说明(类似于 Chain-of-Thought 提示策略):
- 首先, 检查笔架。
- 然后, 看看抽屉里。
- 最后, 检查计算机显示器后面。
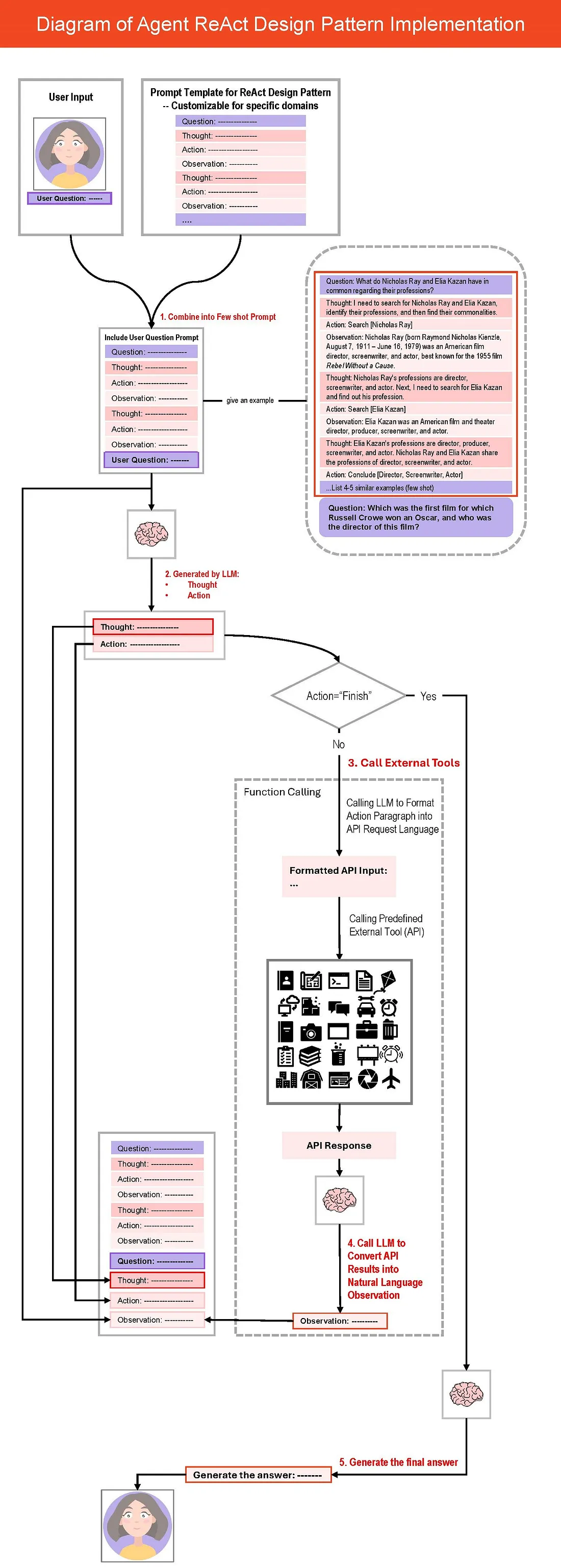
在特定场景中实现 Agent 需要自定义两个关键组件:
- 提示模板中的少数镜头示例
- 函数调用的外部工具的定义
少数镜头的例子基本上反映了结构化的人类思维模式。查看不同设计模式的提示模板是了解 Agent 设计的好方法。一旦掌握了这种方法, 它就可以类似地应用于其他设计模式。
1.3.2 Plan-Solve 模式
顾名思义, 这种设计模式涉及先规划, 后执行。如果说ReAct更适合于像"从桌子上拿笔"这样的任务, 那么Plan & Solve更适合像"制作一杯纯白的"这样的任务。您需要计划, 并且计划在此过程中可能会发生变化(例如, 如果您打开冰箱发现没有牛奶, 则可以在计划中添加"购买牛奶"作为新步骤)。
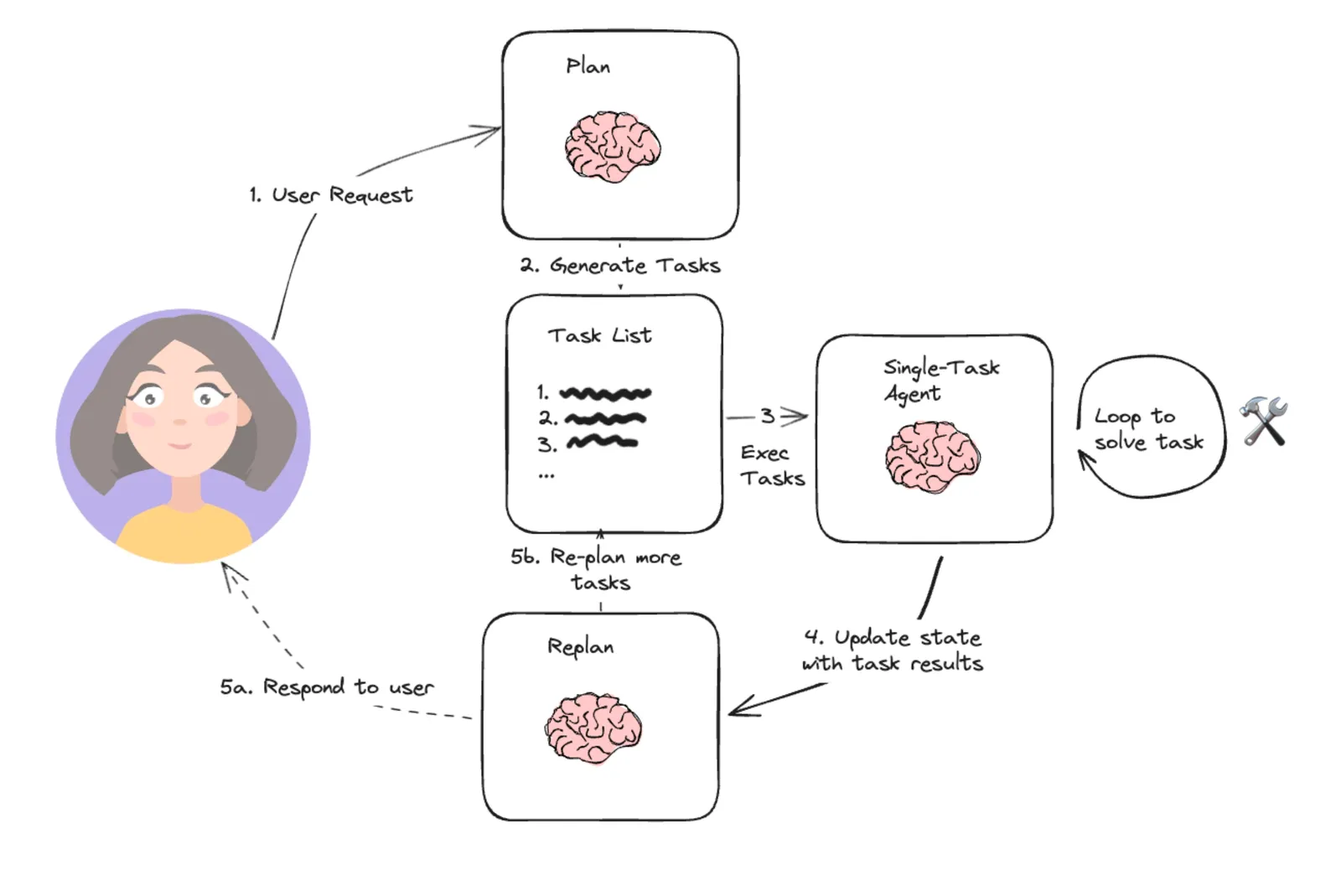
- Planner: 负责使 LLM 能够生成多步骤计划以完成大型任务。在代码中, 既有 Planner 又有 Replanner。Planner 最初负责生成计划;另一方面, Replanner 在每个单独的任务完成后开始发挥作用, 根据当前进度调整计划。因此, Replanner 的提示不仅包括零镜头输入, 还包括目标、原始计划和已完成步骤的状态。
- 执行程序: 接收用户的查询和计划中的步骤, 然后调用一个或多个工具来完成任务。
1.4 其他工作流设计模式
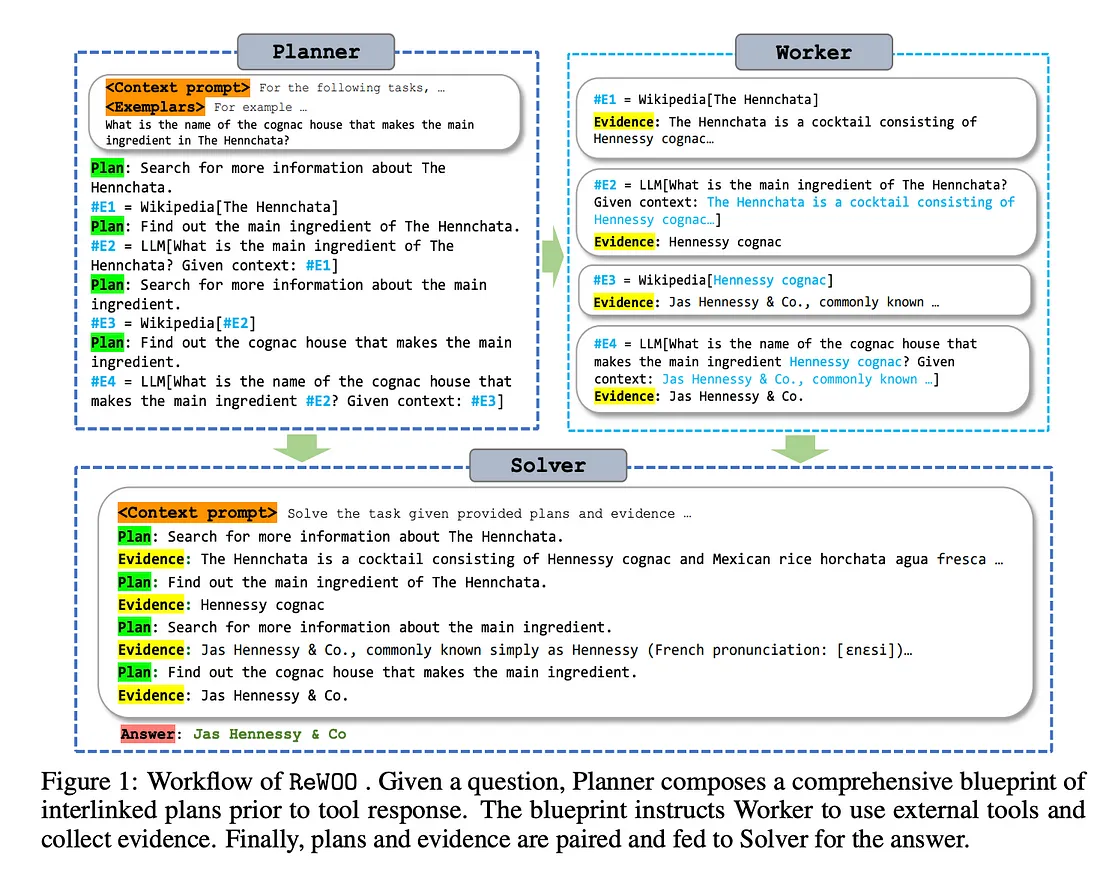
1.4.1 无观察的理性(REWOO)
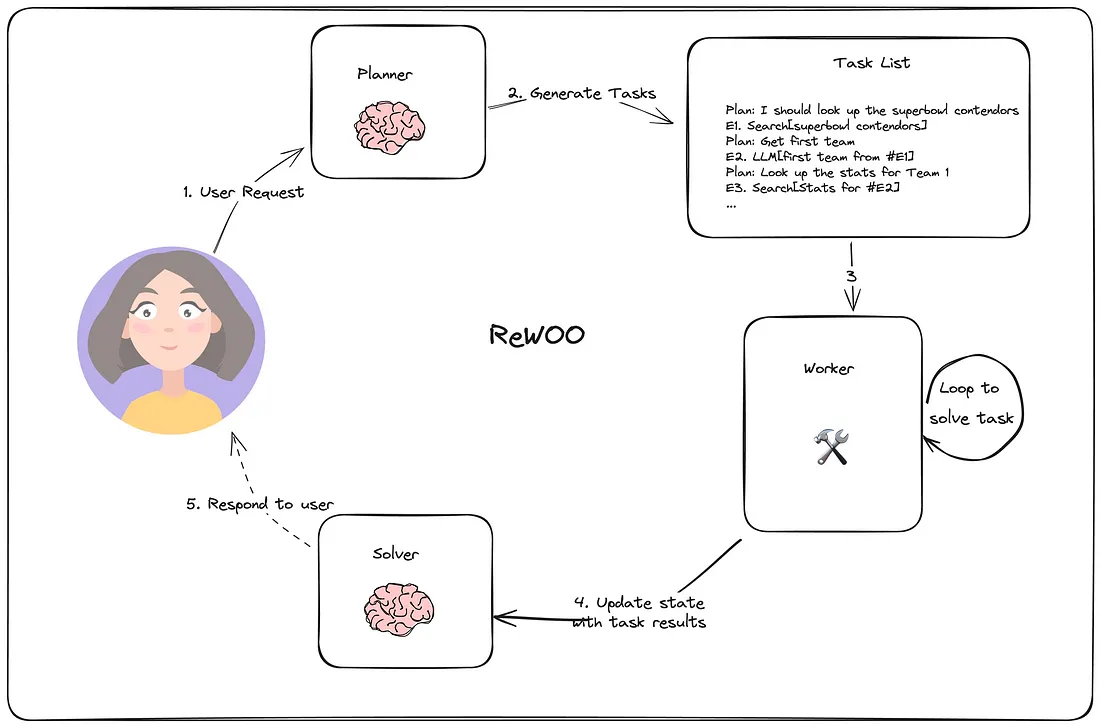
REWOO(Reason without Observation) 是 ReAct 中观察过程的变体。虽然 ReAct 遵循以下结构: Thought → Action → Observation, 而 REWOO 通过删除显式观察步骤来简化此操作。相反, 它将 observation 隐式嵌入到下一个执行单元中。在实践中, 下一个执行程序会自动观察上一步的结果, 从而简化流程。
1.4.2 LLMCompiler
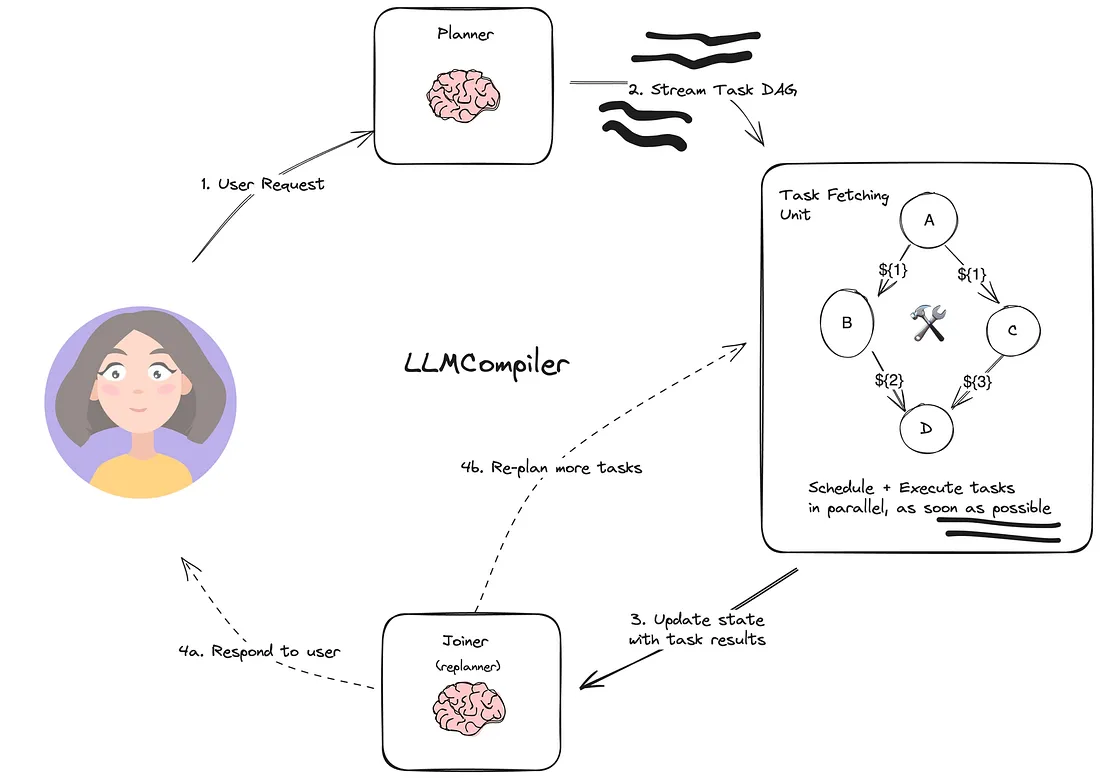
在计算机科学中, 编译器是指为优化计算效率而编排任务的过程。正如原始论文中概述的那样, 用于并行函数调用的 LLM 编译器背后的概念简单而有效: 它旨在通过启用并行函数调用来提高效率。例如, 如果用户问"AWS Glue 和 MWAA 之间有什么区别”, 编译器将同时搜索 AWS 服务定义并合并结果, 而不是按顺序处理每个查询。
1.4.3 基本反射
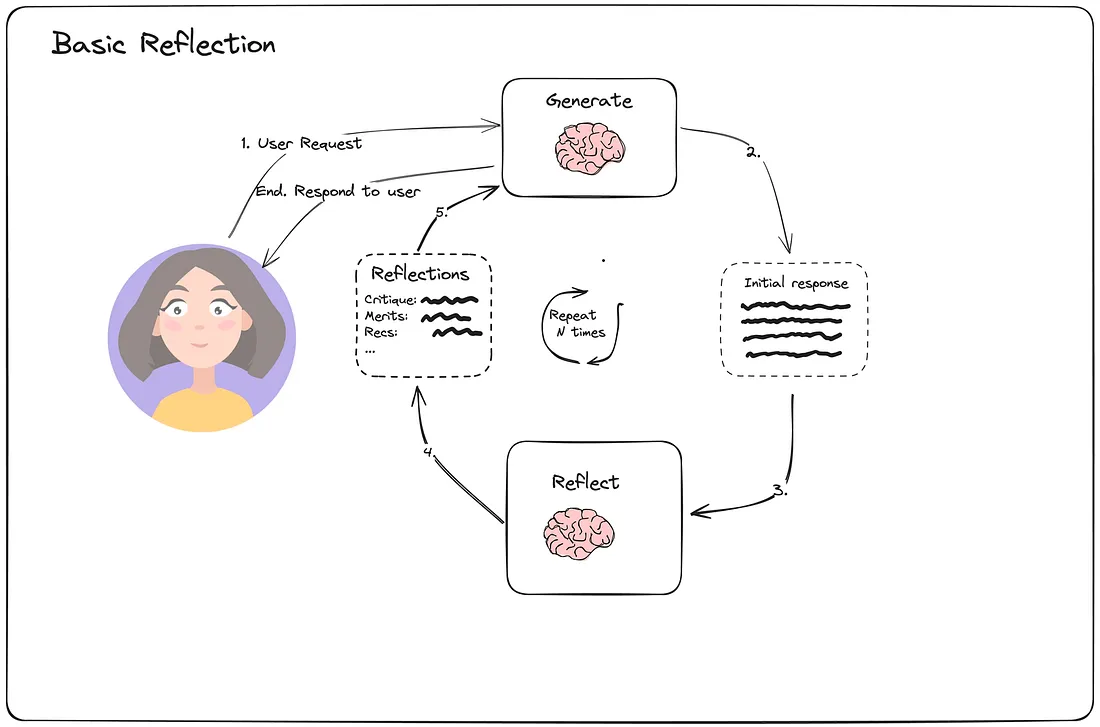
基本反射可以比作学生(Generator)和教师(Reflector)之间的反馈循环。学生完成作业, 教师提供反馈, 学生根据此反馈修改他们的作业, 重复这个循环, 直到任务圆满完成。
1.4.3 反射
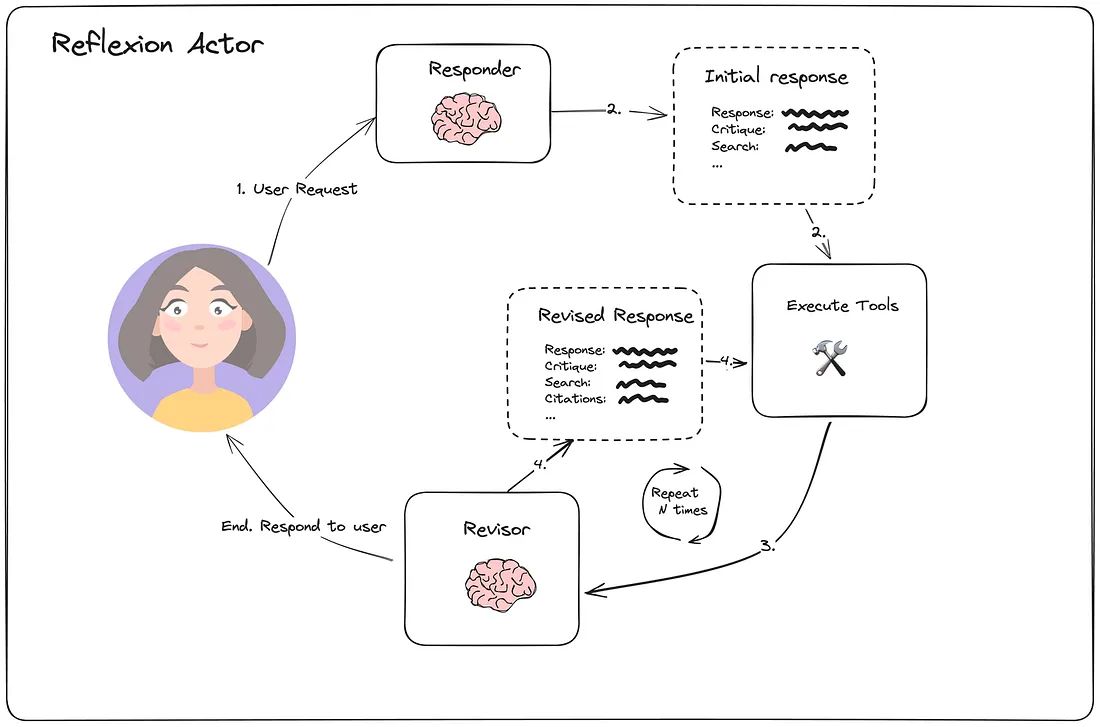
Reflexion 建立在基本反射的基础上, 结合了强化学习的原则。在论文 Reflexion: Language Agents with Verbal Reinforcement Learning 中描述, 这种方法超越了简单的反馈。它使用外部数据评估响应, 并强制模型解决任何冗余或遗漏, 从而使反射过程更加稳健, 输出更加精细。
1.4.4 语言代理树搜索(LATS)
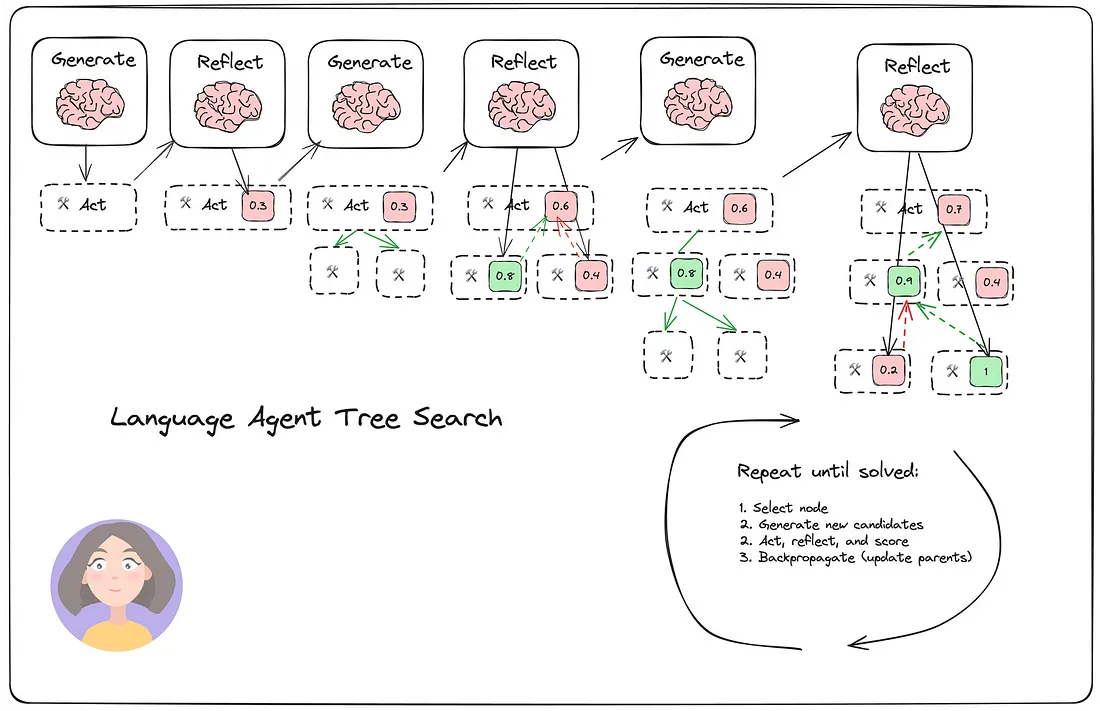
语言代理树搜索在语言模型中统一推理、行动和规划一文中详细介绍了 LATS。它结合了多种技术, 包括Tree Search、ReAct和Plan & Solve。LATS 使用树搜索来评估结果(从强化学习中汲取), 同时还集成反射以实现最佳结果。实质上, LATS 可以用以下公式表示:
LATS = 树搜索 + 反应 + 计划与解决 + 反思 + 强化学习。
在提示设计方面, LATS与早期的方法如Reflection、Plan & Solve和ReAct之间的差异微乎其微。关键的新增功能是树搜索评估步骤, 并在任务上下文中返回这些评估结果。在架构上, LATS 涉及多轮基本反射, 多个生成器和反射器协同工作。
1.4.5 自我发现
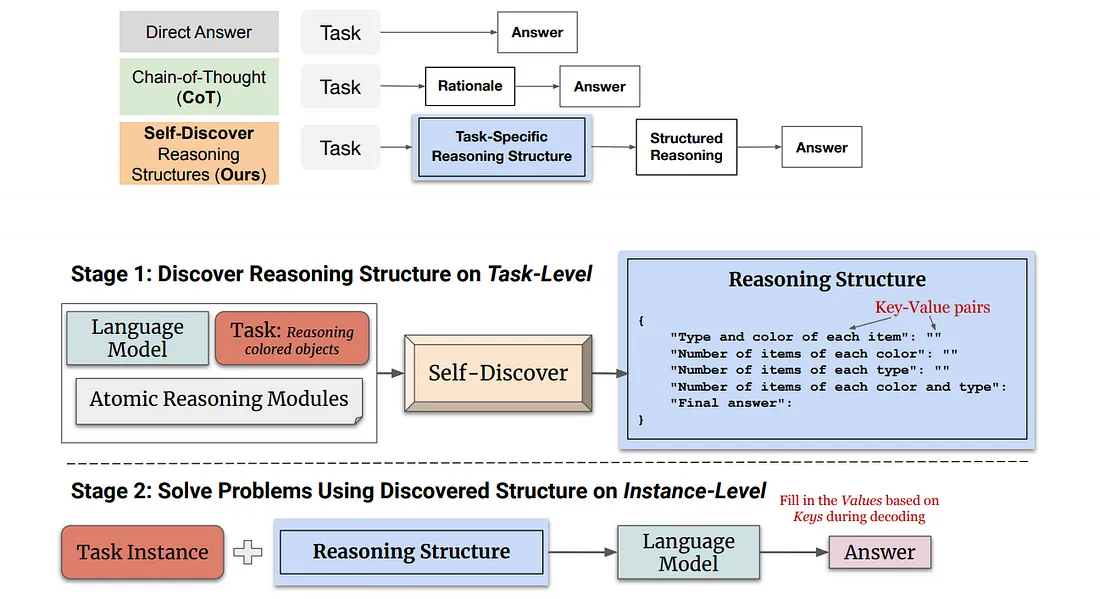
Self-Discovery 的核心是允许大型模型在更精细的级别上反映。虽然计划与解决侧重于任务是否需要额外的步骤或调整, 但自我发现更进一步, 鼓励对任务本身的反思。这涉及评估任务的每个组件以及这些组件的执行。
1.4.5 Storm
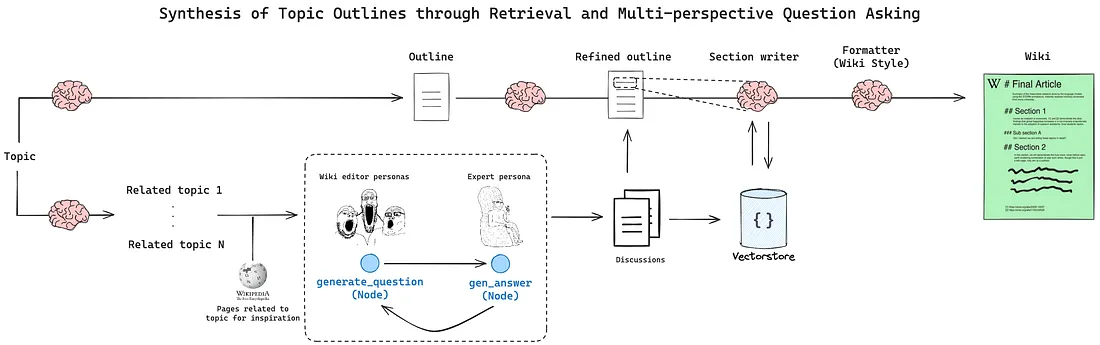
Storm 在论文 Assisted in Writing Wikipedia-like Articles From Scratch with Large Language Models 中进行了概述, 介绍了一种从头开始生成综合文章的工作流程, 类似于 Wikipedia 条目。代理首先使用外部工具搜索信息并生成大纲。然后, 它根据大纲为每个部分生成内容, 使过程结构化且高效。
1.5 规划
虽然有很多轶事证据表明 LLM 的计划很糟糕, 但目前尚不清楚是因为我们不知道如何以正确的方式使用 LLM, 还是因为 LLM 从根本上无法计划。
规划的核心是一个搜索问题。您在通往目标的不同路径中搜索, 预测每条路径的结果(奖励), 并选择结果最有希望的路径。通常, 您可能会确定不存在可以带您实现目标的路径。
2. 护栏
护栏是确保AI代理在安全和道德范围内运作的机制, 使其操作与用例、组织政策和社会规范保持一致。在传统软件中, 护栏侧重于安全措施、错误处理和用户输入验证。虽然这些元素仍然与代理AI相关, 但代理的自主性需要额外的监督, 例如道德准则、实时验证和动态监控, 以防止意外后果。
传统AI在人类的密切监督下运行, 自主行动的风险最小。相比之下, 代理AI必须独立运行, 需要复杂的护栏来管理安全性、监控道德行为、验证操作, 并通过日志记录和审计提供透明度。这种监督确保代理人即使在做出独立决策时也能负责任地行事, 降低风险并保持与道德标准的一致性。
- 企业级安全性和合规性
- 防止偏离主题的操作
- 合乎道德的AI框架和验证
- 日志记录和监控
- 增强的可观察性
2.1 防御性提示工程
3. 实现
3.1 ReWOO 的 langgraph 实现
ReWOO 的 langgraph 实现实现了 Planner(Re)、Worker(Act) 和 Solver
参考: https://github.com/langchain-ai/langgraph/blob/main/examples/rewoo/rewoo.ipynb
3.1.1 计划
计划器生成执行工具和其他步骤的可能策略, 这将以最佳方式解决问题。这些被提供给工人进行执行和证据收集。
3.1.2 Worker
执行任务的几个函数, 这里没什么特别的。
3.1.3 Solver
根据Woker的结果, 即计划员生成的计划, 求解器生成最终答案。
3.2 多代理系统
涉及AI代理网络协作解决问题或实现需要不同专业知识的目标。想想一个团队协作, 它在内部相互沟通, 互相批评, 并相互改进结果, 以解决给定的任务, 而单个代理只能从与之通信的人那里获得反馈。
多智能体系统特别引人注目, 因为它们可以动态地适应新的挑战、委派责任, 甚至相互协商以优化结果。多智能体系统旨在将人在回路中减少到最低限度, 仅在需要时或设计时才要求人工监督和/或批准采取行动。
参考:
ReAct: Synergizing Reasoning and Acting in Language Models
Plan-and-Solve Prompting: Improving Zero-Shot-Chain-of-Thought Reasoning by Large Language Models
Building effective agents
Agents
