
目录
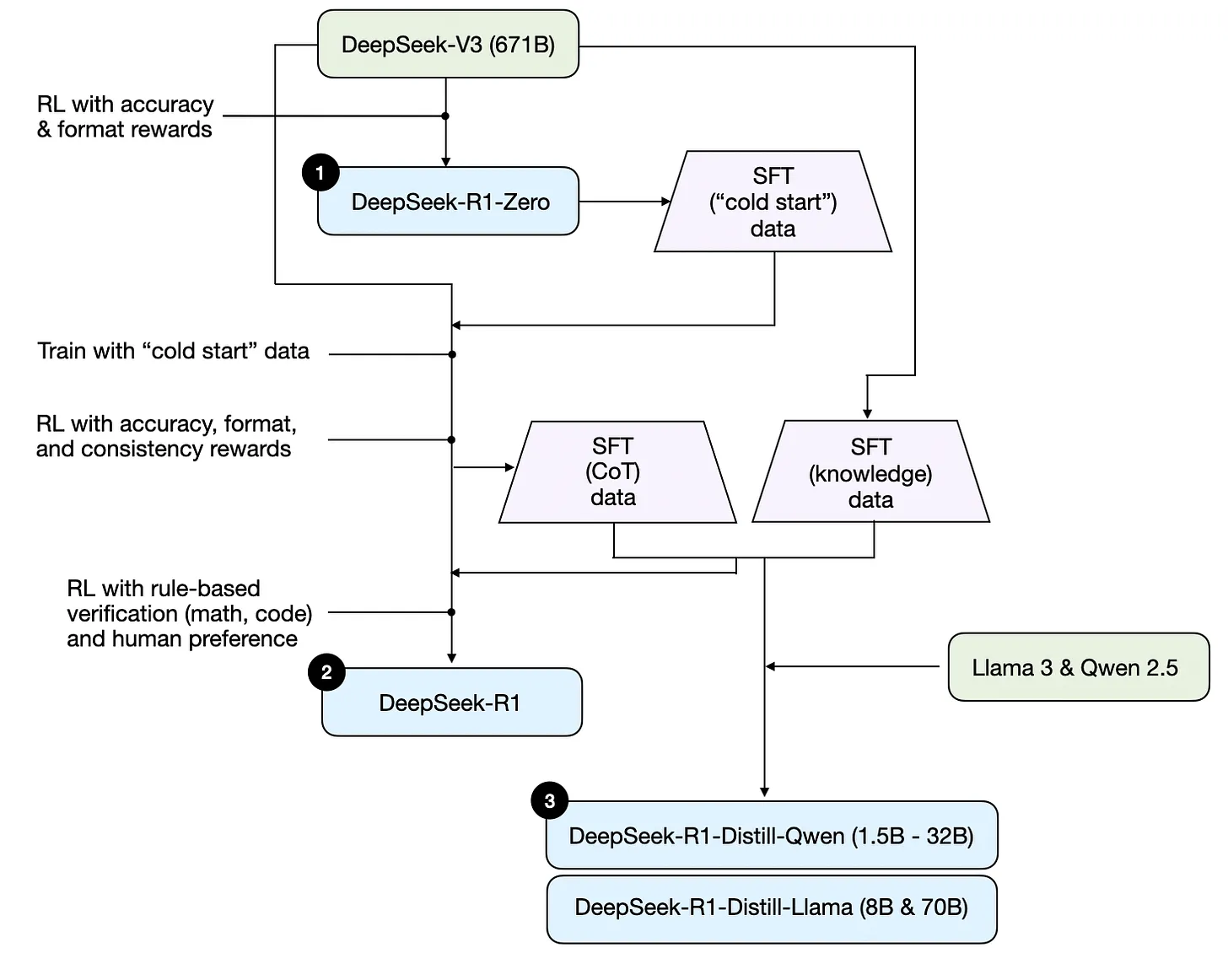
幻方旗下的深度求索公司探索了通过纯RL来提升大模型推理能力, 他们期望在没有任何监督数据的情况下, 强化大模型的推理能力, 特别是关注纯RL过程的自我进化。具体而言, 他们通过使用DeepSeek-V3-Base作为基础模型, 并采用GRPO作为RL框架来提高模型在推理方面的性能, 算是首次公开研究验证LLM的推理能力可以纯粹通过RL激励, 而无需SFT。
1. Deepseek
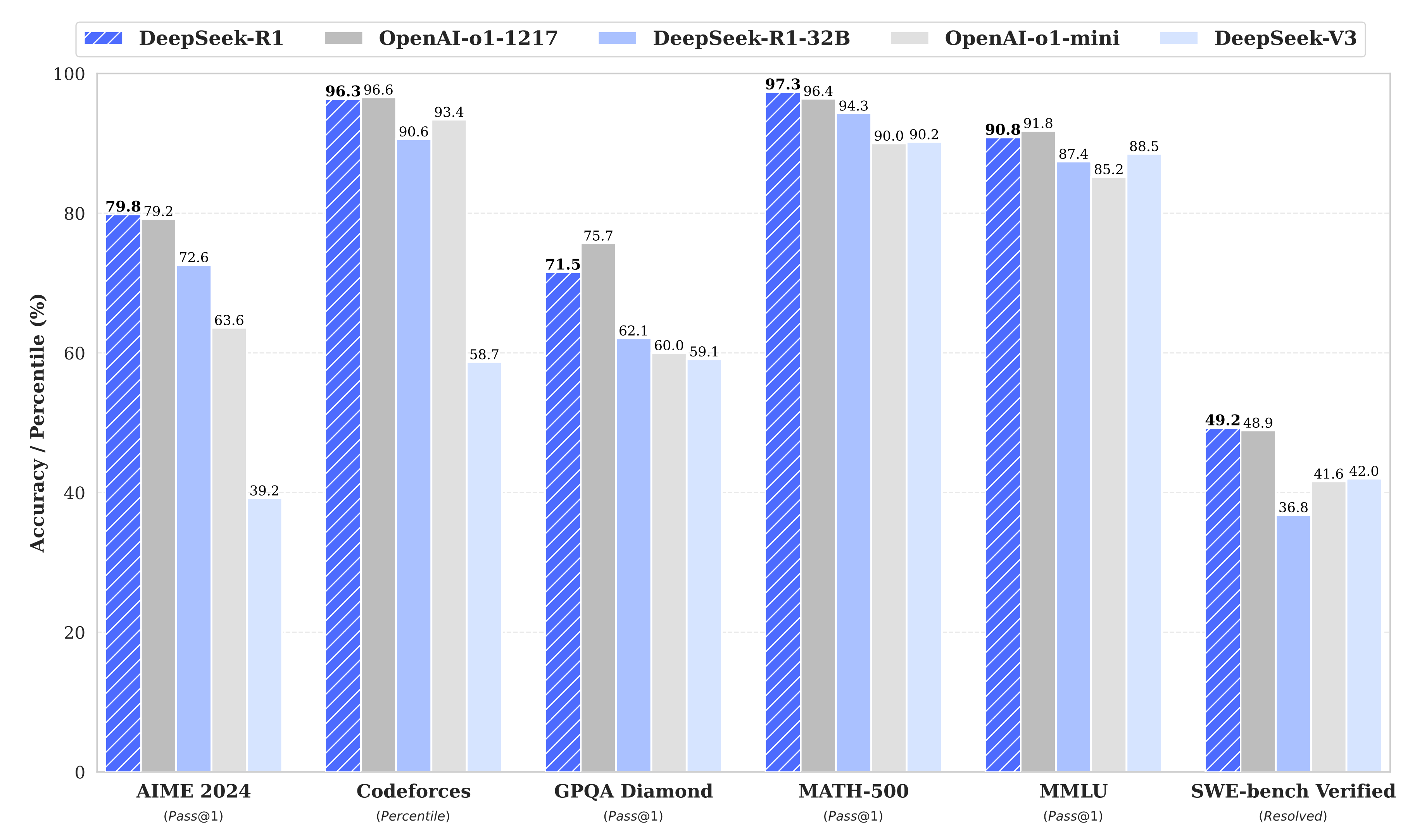
无论是 DeepSeek-v3 还是 DeepSeek-R1, 都以大约 1/20 的成本大大优于 SOTA 模型。DeepSeek R1 是一种可与 OpenAI 的 o1 相媲美但便宜 95% 的模型。
未公开冷启动数据、RL 训练数据集或合成数据的具体内容, 仅提供依赖的公开数据集名称(如 AI-MO、NuminaMath-TIR)
1.1 Deepseek V3
1.2 Deepseek R1
监督微调(SFT) 和来自人类反馈的强化学习(RLHF) 一直是大型语言模型(LLM) 的主要训练方法。假设很明确: 人类标记的数据对于教授结构化推理是必要的, 而没有人类偏好模型的强化学习(RL) 不足以创建竞争模型。
DeepSeek-R1的动机是探索纯RL方法能否在不依赖监督数据的情况下, 驱动LLMs自主进化出强大的推理能力, 同时解决模型输出的可读性与语言混合问题, 并验证通过蒸馏技术实现小模型高效推理的可行性。Deepseek R1 是一个纯粹的解码器唯一的 MoE 转换器, 它与其他 MoE 模型大多相似, 就像专家的混合一样。所以从架构上讲, r1 就像大多数其他 LLM 一样, 差别不大。但它们与训练方法不同, 它们使用一种特殊的强化学习算法 GRPO, 这实际上是 PPO 的一种更新形式。基本上在 GRPO 中, 模型产生多个输出, 奖励模型给它们奖励, 然后奖励是加权平均, 然后根据这个奖励模型在策略梯度方向上更新它的权重。
DeepSeek 引入了一种创新方法, 通过强化学习(RL)来提高大型语言模型(LLM)的推理能力, 这在他们最近关于 DeepSeek-R1 论文中进行了详细说明。Deepseek 研究人员表示, 训练 R1&R1-Zero 只花了 2-3 周, 相OpenAI仅去年一年就在 AI 训练上花费了超过 30 亿美元, DeepSeek模型的构建成本仅为 600 万美元。
-
DeepSeek-R1-Zero: 直接规则驱动的大规模RL训练, 去掉SFT。
代表了该团队使用纯强化学习的初始实验, 没有任何监督微调, 无冷启动、无SFT, 而其主要有三点独特的设计: RL算法GRPO、格式奖励、训练模板
存在一些重大局限性, 尤其是在可读性和语言一致性方面。它具有 6710 亿个参数, 利用专家混合(MoE)架构, 其中每个代币激活的参数相当于 370 亿个。该模型展示了涌现的推理行为, 例如自我验证、反思和长思维链(CoT)推理。 -
DeepSeek-R1: 解决Zero可读性差等问题
由于DeepSeek-R1-Zero 遇到了诸如可读性差和语言混杂等挑战, 而为了解决这些问题并进一步提升推理性能, 作者引入了 DeepSeek-R1, 它结合了一小部分冷启动数据和多阶段训练流程。
1.3 训练方法
怎么通过RL训练DeepSeek-V3-Base, 涉及到RL的常规训练方法, 简言之, 类似下图:
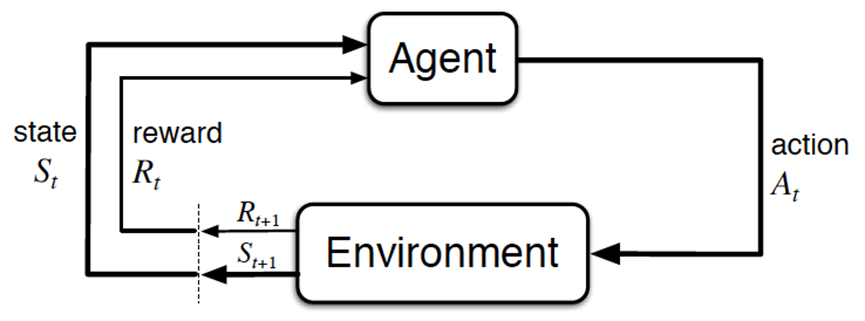
1.3.1 DeepSeek-R1-Zero
-
上图中的Agent便是我们需要训练的V3
当人类提出一个问题/prompt时, 这个问题/prompt就相当于V3所面临的Environment -
接下来, V3便要针对上述问题/prompt做出反应, 比如回答该问题/prompt, 即输出token给到该问题/Environment——这个V3输出token的动作便是上图中的action
而预测下一个token的策略越好, 越能通过实际的token输出, 得到更符合问题/Environment的答案。
故我们要做的就是不断优化V3的预测策略 -
最后, 问题/Environment会根据V3的回答给出反馈, 这个反馈便是上图中的reward
而V3追求奖励最大化, 从而在奖励最大化的目标下, V3不断优化它自身的预测策略 然后输出更好的token。
最终, 在经过数千个RL 步骤后, DeepSeek-R1-Zero 在推理基准测试中表现出超强性能。例如, AIME 2024 的pass@1 得分从15.6% 提高到71.0%, 通过多数投票, 得分进一步提高到86.7%, 与OpenAI-o1-0912 的性能相匹配。
1.3.2 DeepSeek-R1
DeepSeek-R1 使用更复杂的多阶段训练方法。它不是纯粹的强化学习, 而是在应用强化学习之前, 首先对一小群精心策划的示例(称为"冷启动数据")进行监督微调。其训练流程, 简言之是 微调 → RL → 微调 → RL, 具体而言是
- 首先收集了数千个冷启动数据来微调 DeepSeek-V3-Base 模型
- 随后, 进行类似 DeepSeek-R1-Zero 的面向推理的强化学习
- 当强化学习过程接近收敛时, 通过对 RL 检查点进行拒绝采样, 结合 DeepSeek-V3 在写作、事实问答和自我认知等领域的监督数据, 创建新的 SFT 数据, 然后重新训练DeepSeek-V3-Base 模型
- 在用新数据微调后, 检查点会经历额外的 RL 过程——且会考虑到所有场景的提示
2. 模型使用指南
- 将温度设置在 0.5-0.7(推荐 0.6)的范围内, 以防止无休止的重复或不连贯的输出。
- 避免添加系统提示符;所有说明都应包含在用户提示符中。
- 对于数学问题, 建议在提示中包含一条指令, 例如: “请逐步推理, 并将您的最终答案放在 \boxed{} 中。
- 在评估模型性能时, 建议进行多次测试并平均结果。
几个需要改进的领域:
- 该模型有时难以完成需要特定输出格式的任务
- 软件工程任务的性能可以提高
- 在多语言环境中进行语言混合存在挑战
- 少镜头提示始终会降低性能
- 函数调用、多轮次交互和复杂角色扮演场景等领域
要让 DeepSeek 发挥作用, 有许多关键因素在发挥作用:
- 混合专家(MoE)
- 多头潜在注意力(MLA)
- 旋转位置编码(RoPE)
- 多令牌预测(MTP)
- 监督微调(SFT)
- 集团相对策略优化(GRPO)
3. 蒸馏
3.1 什么是蒸馏
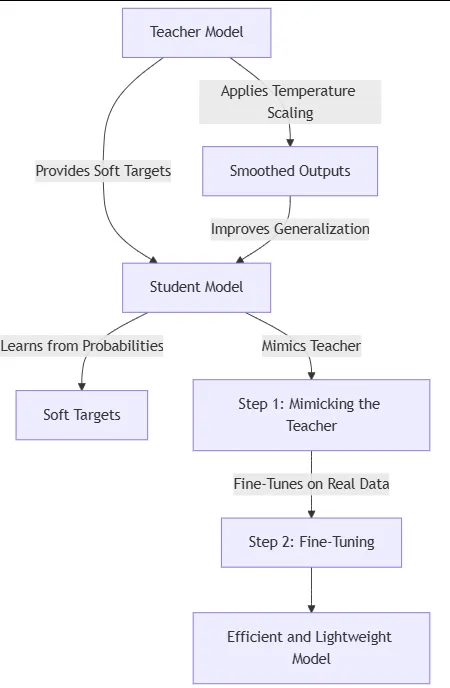
蒸馏是一种机器学习技术, 其中较小的模型(“学生”)经过训练以模仿较大的预训练模型(“老师”)的行为。目标是保留老师的大部分表现, 同时显着降低计算成本和内存占用。
LLM 中的蒸馏就像教一个聪明但缓慢的教授像他们最敏锐的学生一样快速思考和反应。这是将知识从大型、复杂的 AI 模型(“老师”)转移到更小、更快的 AI 模型(“学生”)的过程, 同时保留原始模型的大部分能力。
- 成本效率: 较小的模型需要更少的计算资源。
- 速度: 非常适合延迟敏感的应用程序(例如 API、边缘设备)。
- 专业化: 无需重新训练巨型模型即可针对特定领域定制模型。
3.2 蒸馏类型
这些蒸馏模型基于 Qwen 和 Llama 等架构, 表明复杂的推理可以封装在更小、更高效的模型中。蒸馏过程涉及使用完整 DeepSeek-R1 生成的合成推理数据对这些较小的模型进行微调, 从而在降低计算成本的同时保持高性能。
3.2.1 数据蒸馏
在数据蒸馏中, 教师模型生成合成数据或伪标签, 然后用于训练学生模型。
这种方法可以应用于广泛的任务, 即使是那些 logits 信息量较少的任务(例如开放式推理任务)。
3.2.2 Logits蒸馏:
Logits 是应用 softmax 函数之前神经网络的原始输出分数。
在 logits蒸馏中, 学生模型经过训练以匹配教师的 logits, 而不仅仅是最终预测。
这种方法保留了更多关于教师信心水平和决策过程的信息。
3.2.3 特征蒸馏
特征提炼涉及将知识从教师模型的中间层转移到学生。
通过对齐两个模型的隐藏表示, 学生可以学习更丰富、更抽象的特征。
3.3 Deepseek 的蒸馏模型
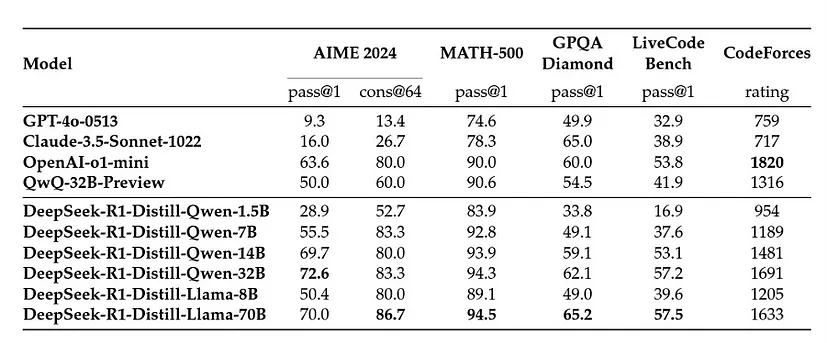
DeepSeek AI 发布了基于 Qwen(Qwen, 2024b)和 Llama(AI@Meta, 2024)等流行架构的六个蒸馏变体。他们使用 DeepSeek-R1 策划的 800k 个样本直接微调开源模型。
3.4 为什么要蒸馏自己的模型
-
定任务优化
预蒸馏模型在广泛的数据集上进行训练, 以在各种任务中表现良好。然而, 现实世界的应用程序通常需要专业化。 -
大规模成本效率
虽然预蒸馏模型效率很高, 但它们可能仍然不适合你的特定工作量。蒸馏你自己的模型可以让你针对确切的资源限制进行优化。 -
基准性能 ≠ 真实世界性能
预蒸馏模型在基准测试中表现出色, 但基准测试通常不能代表真实世界的任务。因此, 你通常需要一个在真实世界场景中表现比任何预蒸馏模型都更好的模型。 -
迭代改进
预蒸馏模型是静态的——它们不会随着时间的推移而改进。通过蒸馏自己的模型, 你可以在新数据可用时不断完善它。
3.5 将 DeepSeek-R1 知识蒸馏成自定义小模型
首先安装库:
pip install -q torch transformers datasets accelerate bitsandbytes flash-attn --no-build-isolation
3.5.1 生成和格式化数据集
通过在环境中使用 ollama 或任何其他部署框架部署 deepseek-r1 来生成自定义域相关数据集。但是, 对于本教程, 我们将使用 Magpie-Reasoning-V2 数据集, 其中包含 DeepSeek-R1 生成的 250K 思路链 (CoT)推理样本, 这些示例涵盖了数学推理、编码和一般问题解决等各种任务。
每个示例包括:
指令: 任务描述(例如, "解决这个数学问题")。
响应: DeepSeek-R1 的分步推理 (CoT)。
{
"instruction": "Solve for x: 2x + 5 = 15",
"response": "<think>First, subtract 5 from both sides: 2x = 10. Then, divide by 2: x = 5.</think>"
}
from datasets import load_dataset
# Load the dataset
dataset = load_dataset("Magpie-Align/Magpie-Reasoning-V2-250K-CoT-Deepseek-R1-Llama-70B", token="YOUR_HF_TOKEN")
dataset = dataset["train"]
# Format the dataset
def format_instruction(example):
return {
"text": (
"<|user|>\n"
f"{example['instruction']}\n"
"<|end|>\n"
"<|assistant|>\n"
f"{example['response']}\n"
"<|end|>"
)
}
formatted_dataset = dataset.map(format_instruction, batched=False, remove_columns=subset_dataset.column_names)
formatted_dataset = formatted_dataset.train_test_split(test_size=0.1) # 90-10 train-test split
将数据集构造为 Phi-3 的聊天模板格式:
<|user|>: 标记用户查询的开始。
<|assistant|>: 标记模型响应的开始。
<|end|>: 标记回合的结束。
每个 LLM 都使用特定格式来执行指令跟踪任务。将数据集与此结构对齐可确保模型学习正确的对话模式。因此, 请确保根据要提取的模型格式化数据。
3.5.2 加载模型和标记器
为了增强模型的推理能力, 我们引入了这些标记。
- <think>: 标记推理的开始。
- </think>: 标记推理的结束。
这些标记帮助模型学习生成结构化的、分步的解决方案。
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "microsoft/phi-3-mini-4k-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
# Add custom tokens
CUSTOM_TOKENS = ["<think>", "</think>"]
tokenizer.add_special_tokens({"additional_special_tokens": CUSTOM_TOKENS})
tokenizer.pad_token = tokenizer.eos_token
# Load model with flash attention
model = AutoModelForCausalLM.from_pretrained(
model_id,
trust_remote_code=True,
device_map="auto",
torch_dtype=torch.float16,
attn_implementation="flash_attention_2"
)
model.resize_token_embeddings(len(tokenizer)) # Resize for custom tokens
3.5.3 配置 LoRA 以实现高效微调
LoRA 通过冻结基础模型并仅训练小型适配器层来减少内存使用量。
from peft import LoraConfig
peft_config = LoraConfig(
r=8, # Rank of the low-rank matrices
lora_alpha=16, # Scaling factor
lora_dropout=0.2, # Dropout rate
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"], # Target attention layers
bias="none", # No bias terms
task_type="CAUSAL_LM" # Task type
)
3.5.4 设置训练参数
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir="./phi-3-deepseek-finetuned",
num_train_epochs=3,
per_device_train_batch_size=2,
per_device_eval_batch_size=2,
gradient_accumulation_steps=4,
eval_strategy="epoch",
save_strategy="epoch",
logging_strategy="steps",
logging_steps=50,
learning_rate=2e-5,
fp16=True,
optim="paged_adamw_32bit",
max_grad_norm=0.3,
warmup_ratio=0.03,
lr_scheduler_type="cosine"
)
3.5.5 训练模型
SFTTrainer 简化了指令跟随模型的监督微调。 data_collator 批量处理示例, peft_config 支持基于 LoRA 的训练。
from trl import SFTTrainer
from transformers import DataCollatorForLanguageModeling
# Data collator
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
# Trainer
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=formatted_dataset["train"],
eval_dataset=formatted_dataset["test"],
data_collator=data_collator,
peft_config=peft_config
)
# Start training
trainer.train()
trainer.save_model("./phi-3-deepseek-finetuned")
tokenizer.save_pretrained("./phi-3-deepseek-finetuned")
3.5.6 合并保存最终模型
训练后, 必须将 LoRA 适配器与基础模型合并以进行推理。此步骤确保模型可以在没有 PEFT 的情况下独立使用。
final_model = trainer.model.merge_and_unload()
final_model.save_pretrained("./phi-3-deepseek-finetuned-final")
tokenizer.save_pretrained("./phi-3-deepseek-finetuned-final")
3.5.7 推理
from transformers import pipeline
# Load fine-tuned model
model = AutoModelForCausalLM.from_pretrained(
"./phi-3-deepseek-finetuned-final",
device_map="auto",
torch_dtype=torch.float16
)
tokenizer = AutoTokenizer.from_pretrained("./phi-3-deepseek-finetuned-final")
model.resize_token_embeddings(len(tokenizer))
# Create chat pipeline
chat_pipeline = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
device_map="auto"
)
# Generate response
prompt = """<|user|>
What's the probability of rolling a 7 with two dice?
<|end|>
<|assistant|>
"""
output = chat_pipeline(
prompt,
max_new_tokens=5000,
temperature=0.7,
do_sample=True,
eos_token_id=tokenizer.eos_token_id
)
print(output[0]['generated_text'])
4. 强化学习
与主要依赖监督学习的传统模型不同, DeepSeek-R1 广泛使用 RL。该训练利用组相对策略优化(GRPO), 专注于准确性和格式奖励, 以增强推理能力, 而无需大量标记数据。
4.1 RL与监督学习的区别和RL方法的分类
4.1.1 RL和监督学习(supervised learning)的区别
-
监督学习有标签告诉算法什么样的输入对应着什么样的输出(譬如分类、回归等问题), 所以对于监督学习, 目标是找到一个最优的模型函数, 使其在训练数据集上最小化一个给定的损失函数, 相当于最小化预测误差:
最优模型 = arg minE { [损失函数(标签,模型(特征))] }RL没有标签告诉它在某种情况下应该做出什么样的行为, 只有一个做出一系列行为后最终反馈回来的reward, 然后判断当前选择的行为是好是坏, 相当于RL的目标是最大化智能体策略在和动态环境交互过程中的价值, 而策略的价值可以等价转换成奖励函数的期望, 即最大化累计下来的奖励期望
最优策略 = arg maxE { [奖励函数(状态,动作)] } -
监督学习如果做了比较坏的选择则会立刻反馈给算法
RL的结果反馈有延时, 有时候可能需要走了很多步以后才知道之前某步的选择是好还是坏 -
监督学习中输入是独立分布的, 即各项数据之间没有关联
RL面对的输入总是在变化, 每当算法做出一个行为, 它就影响了下一次决策的输入
4.1.2 RL方法的分类
RL为得到最优策略从而获取最大化奖励, 有:
- 基于值函数的方法
通过求解一个状态或者状态下某个动作的估值为手段, 从而寻找最佳的价值函数, 找到价值函数后, 再提取最佳策略, 比如Q-learning、DQN等, 适合离散的环境下, 比如围棋和某些游戏领域 - 基于策略的方法
一般先进行策略评估, 即对当前已经搜索到的策略函数进行估值, 得到估值后, 进行策略改进, 不断重复这两步直至策略收敛, 比如策略梯度法(policy gradient, 简称PG), 适合连续动作的场景, 比如机器人控制领域, 以及Actor-Criti(一般被翻译为演员-评论家算法), Actor学习参数化的策略即策略函数, Criti学习值函数用来评估状态-动作对, 不过, Actor-Criti本质上是属于基于策略的算法, 毕竟算法的目标是优化一个带参数的策略, 只是会额外学习价值函数, 从而帮助策略函数更好的学习。
此外, 还有对策略梯度算法的改进, 比如TRPO算法、PPO算法, 当然PPO算法也可称之为是一种Actor-Critic架构
4.2 组相对策略优化(GRPO): 一种无需单独奖励模型的强化学习方法
DeepSeek提出了群体相对策略优化GRPO——Group Relative Policy Optimization
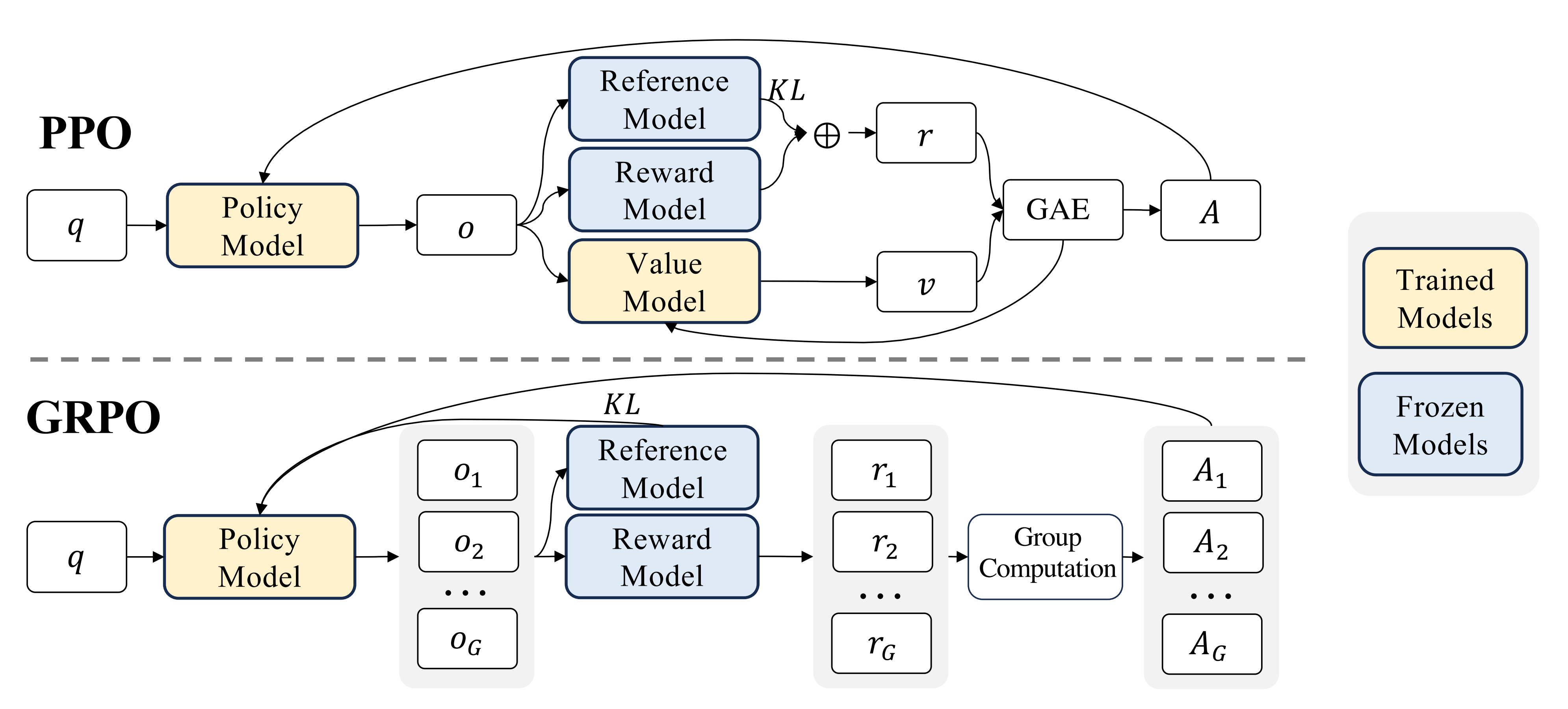
- 它避免了像 PPO 那样需要额外的价值函数近似——说白了 就是不要PPO当中的value model或value function去做价值评估
就是丢掉critic, 也就没有了value(不需要基于value做估计), 也就不需要GAE - 而是使用对同一问题的多个采样输出的平均奖励作为基线, 直接暴力采样 N 次求均值
策略函数(policy): 在强化学习中, \( a_t | s_t \) 表示在状态 \( s_t \)下采取动作 \( a_t \) 的条件概率。具体来说, 它是由策略函数 \( \pi(a_t|s_t) \) 决定的。
PPO(Proximal Policy Optimization) 是一种用于强化学习的策略优化算法, 由 OpenAI 提出。它通过限制策略更新的幅度, 确保训练过程的稳定性。
GRPO 是一种在线学习算法(online learning algorithm), 这意味着它通过使用训练过程中由训练模型自身生成的数据来迭代改进。GRPO 的目标直觉是最大化生成补全(completions)的优势函数(advantage), 同时确保模型保持在参考策略(reference policy)附近。
为了节省强化学习的训练成本, 作者采用组相对策略优化GRPO, 该方法放弃了通常与策略模型大小相同的critic模型, 而是从组得分中估baseline
具体来说, 对于每个问题q, GRPO 从旧策略 \(\pi_{\theta_{\text {old }}} \) 中抽取一组输出 \( \left\{o_{1}, o_{2}, \cdots, o_{G}\right\} \), 然后通过最大化以下目标来优化策略模型\(\pi_{\theta}\):
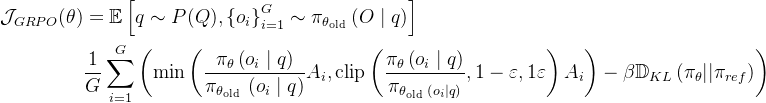
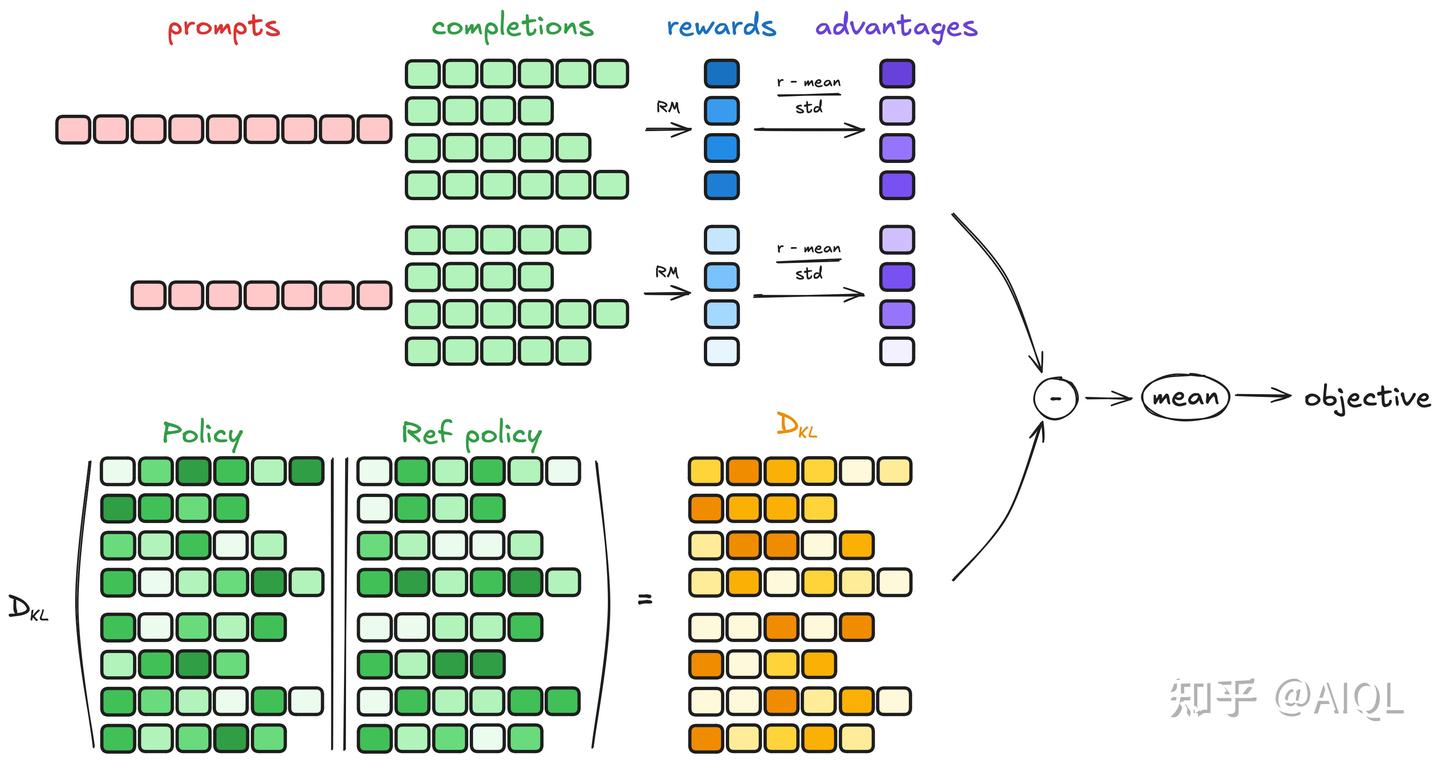
为了理解 GRPO 的工作原理, 可以将其分解为四个主要步骤:
4.2.1 生成补全(Generating completions)
在每一个训练步骤中, 我们从提示(prompts)中采样一个批次(batch), 并为每个提示生成一组 G 个补全(completions)(记为 Oᵢ)。
4.2.2 计算优势值(Computing the advantage)
对于每一个 G 序列, 使用奖励模型(reward model)计算其奖励(reward)。为了与奖励模型的比较性质保持一致——通常奖励模型是基于同一问题的输出之间的比较数据集进行训练的——优势的计算反映了这些相对比较。其归一化公式如下:
这种方法赋予了该方法其名称: 群体相对策略优化(Group Relative Policy Optimization, GRPO)
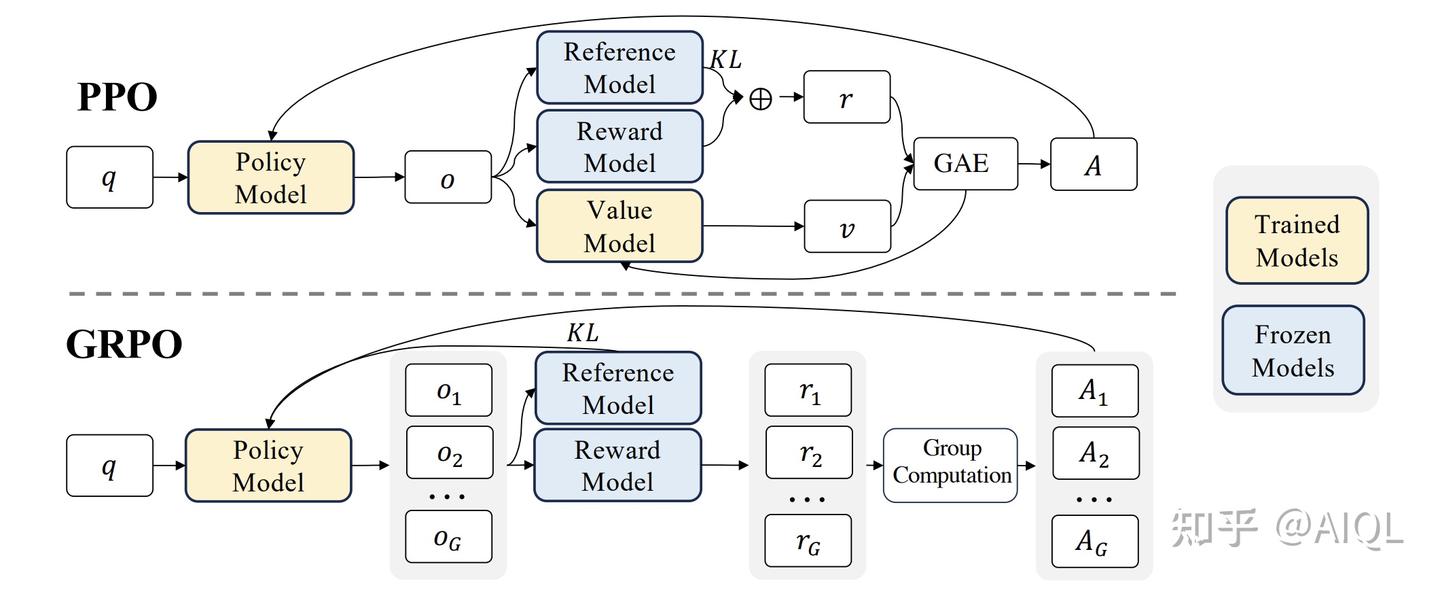
GRPO通过优化PPO算法, 解决了计算优势值时需要同时依赖奖励模型(reward model)和价值模型(value model)的问题, 成功移除了value model(价值模型), 显著降低了推理时的内存占用和时间开销。Advantage(优势值)的核心价值在于为模型输出提供更精准的评估, 不仅衡量答案的绝对质量, 还通过相对比较(与其他回答的对比)来更全面地定位其优劣。
4.2.3 估计KL散度(Estimating the KL divergence)
在实际算法实现中, 直接计算KL散度可能会面临一些挑战:
- 计算复杂度高: KL散度的定义涉及对两个概率分布的对数比值的期望计算。对于复杂的策略分布, 直接计算KL散度可能需要大量的计算资源;
- 数值稳定性: 在实际计算中, 直接计算KL散度可能会遇到数值不稳定的问题, 尤其是当两个策略的概率分布非常接近时, 对数比值可能会趋近于零或无穷大。近似器可以通过引入一些数值稳定性的技巧(如截断或平滑)来避免这些问题;
- 在线学习: 在强化学习中, 策略通常需要在每一步或每几步更新一次。如果每次更新都需要精确计算KL散度, 可能会导致训练过程变得非常缓慢。近似器可以快速估计KL散度, 从而支持在线学习和实时更新。
4.2.4 计算损失(Computing the loss)
这一步的目标是最大化优势, 同时确保模型保持在参考策略附近。因此, 损失定义如下:
在原始论文中, 该公式被推广为在每次生成后通过利用裁剪替代目标(clipped surrogate objective)进行多次更新。
GRPO通过优化PPO算法, 移除了价值模型, 降低了计算开销, 同时利用群体相对优势函数和KL散度惩罚, 确保策略更新既高效又稳定。
4.3 RLHF 与简单 RL(GRPO)
目标
- OpenAI(RLHF): 主要目标是使 AI 模型与人类偏好保持一致。这涉及训练模型以符合人类价值观和期望的方式理解和响应。
- DeepSeek(更简单的 RL): 重点是针对特定于任务的指标进行优化。这意味着模型经过训练, 可以在特定任务上表现良好, 从而最大限度地提高这些特定领域的性能。
复杂性
- OpenAI(RLHF): 这种方法很复杂, 需要人工反馈、奖励建模和高级 RL 技术。它涉及一个更复杂的过程, 以确保模型的响应与人类的偏好保持一致。
- DeepSeek(更简单的 RL): 复杂度较低, 利用轻量级、以任务为中心的 RL。对于特定任务, 此方法更直接、更简化。
范围
- OpenAI(RLHF): 该方法范围广泛且通用, 旨在在各种应用程序和方案中保持一致。
- DeepSeek(更简单的 RL): 范围狭窄且特定于任务, 针对特定任务而不是一般用途优化模型。
用例
- OpenAI(RLHF): 用例是通用 AI, 例如 ChatGPT, 其中模型需要以感觉自然且符合人类期望的方式与用户交互。
- DeepSeek(更简单的 RL): 该用例是特定于行业的应用程序, 其中模型经过定制, 可在特定领域或特定任务中实现最佳执行。
资源要求
- OpenAI(RLHF): 资源要求很高, 因为该过程的计算成本很高。它需要大量的计算能力和资源来实施和维护。
- DeepSeek(更简单的 RL): 该方法对资源的要求较低, 因此效率高且具有成本效益。它旨在更易于访问和部署。
4.4 R1之外的另一条推理模型训练路径: 微软rStar-Math的PRM + MCTS
25年1.8日, 来自Microsoft Research Asia的研究者Xinyu Guan、Li Lyna Zhang、Yifei Liu、Ning Shang、Youran Sun、Yi Zhu、Fan Yang、Mao Yang提出了OpenAI o1的复刻模型rStar-Math, 其对应的论文为《rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking》
rStar-Math旨在训练一个数学策略SLM和一个过程偏好模型PPM——来生成更高质量的训练数据, 并将两者整合到蒙特卡罗树搜索MCTS中, 以实现深度思考:
- 其这两个模型的参数大小均为7B, 如此, 较小的规模允许在可用硬件, 例如 4*40GB A100 GPU 上进行广泛的MCTS回溯。
- 其中数学策略模型SLM在测试时通过基于SLM的过程奖励模型进行搜索指导。
在一定程度上解决了上一节deepseek提到的PRM、MCTS等存在的问题。
5. 其他
5.1 deepseek.cpp
5.2 稀疏注意力
现代 LLM 和基础模型主要基于 transformer 模型构建, 而 transformer 的自注意力在上下文长度方面具有二次计算成本, 这使得扩展到长上下文(> 32k)和超长上下文长度(>128k)变得困难。有许多不同的方法可以解决二次计算成本问题, 例如, 将注意力转换为线性格式, 利用选择性状态模型, 将 softmax 注意力转换为 RNN 风格并执行并行计算。
由 OpenAI 于 2019 年推出的稀疏注意力设计, 从按块样式和滑窗样式开始, 然后在过去几年中逐渐演变为 top-k 选择样式。我们专注于最新模型: DeepSeek 的原生稀疏注意力(NSA)和 Kimi 的 MOBA 模型。
5.2.1 DeepSeek 原生稀疏注意力(NSA)
DeepSeek 原生稀疏注意力: 一种硬件对齐且原生可训练的稀疏注意力机制, 用于超快的长上下文训练和推理!核心组件:
- 动态分层稀疏策略
- 粗粒度 token 压缩
- 细粒度 token 选择
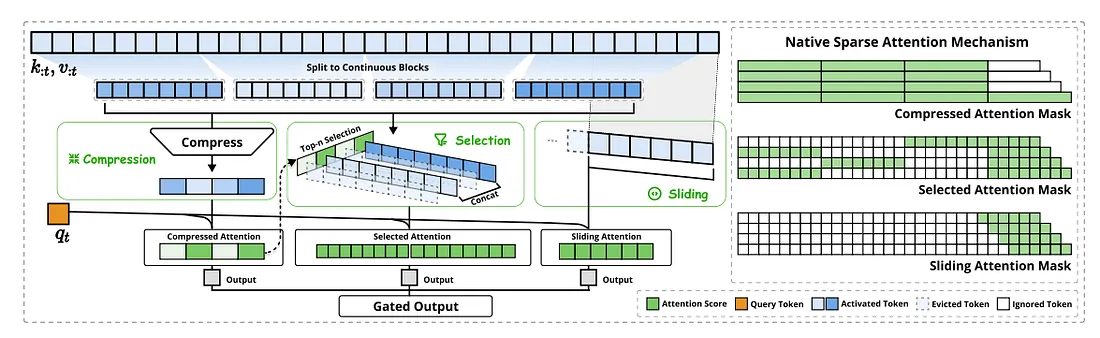
NSA 将 top-k 选择和滑动窗口与额外的压缩分支相结合, 并在 64k 上下文长度的解码阶段实现了近 11 倍的性能提升。虽然公众不太了解它, 但 MOBA 模型将序列扩展到了非凡的 10m 长度, 与 FlashAttention 实现相比, 性能提高了近 10 倍。
NSA 针对现代硬件进行了优化设计, 可加快推理速度, 同时降低预训练成本, 而不会影响性能。它在一般基准、长上下文任务和基于指令的推理方面与 Full Attention 模型相匹配或优于 Full Attention 模型。
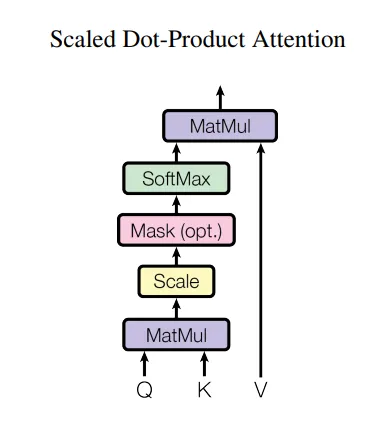
基本原理 — Vanilla Self-Attention
当我们谈论自我注意时, 我们通常会谈论原版 transformer 模型中的缩放点积自我注意。在下图中, Q 表示查询矩阵, K 表示键矩阵, V 表示值矩阵:
可训练的稀疏注意力概念类似于 Microsoft 的早期论文“SeerAttention: 在 LLM 中学习内在稀疏注意力”。
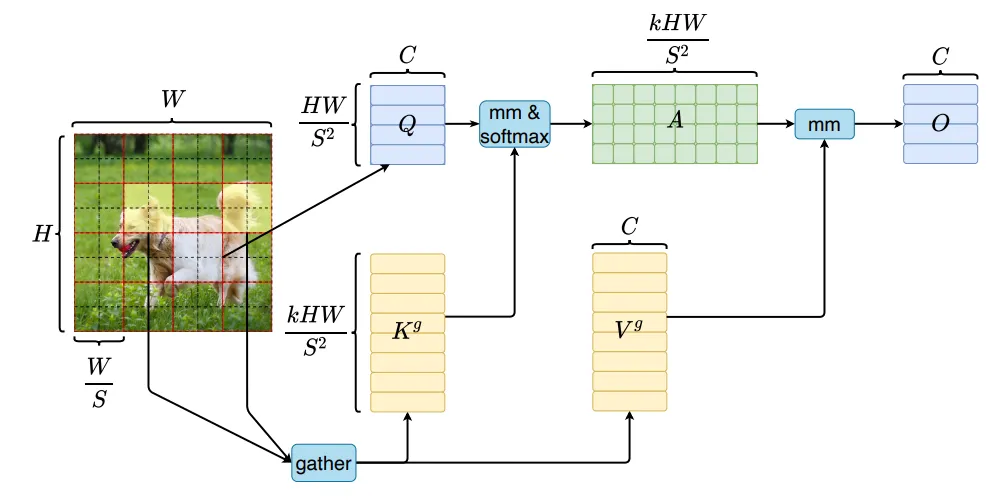
5.2.2 BiFormer — 具有路由稀疏注意力的 Vision Transformer
为了充分探索自我注意的稀疏性, CVPR'23 的一篇论文提出了 BiFormer。这个基于 ViT 的模型对 Vision Transformer 中 patch-wise 查询和 key 自然形成的邻接矩阵应用 top-k 门控。
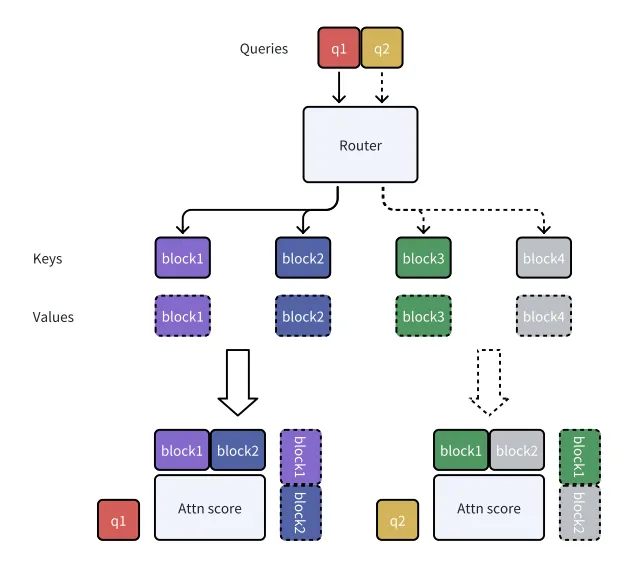
5.2.3 MOBA — 块注意力的混合
MOBA 的思路与 BiFormer 非常相似: 将长度为 N 的序列分解成 n 个小块, 并为每个块生成键和值, 然后将查询路由到不同的块组并在本地计算注意力分数。不同的是, MOBA 使用阻塞键的平均池化来计算 top-k 门控, 而不是全亲和矩阵, 进一步节省了计算成本。
5.4 Deepseek OpenSources(2025)
5.4.1 FlashMLA
FlashMLA 是适用于 Hopper GPU 的高效 MLA 解码内核, 针对可变长度序列服务进行了优化。vLLM 刚刚在 vLLM 中部署了 FlashMLA, 它已经将输出吞吐量提高了 2-16% - 预计未来几天会有更多改进
5.4.2 DeepEP - Expert parallel FP8 MOE kernels
DeepEP 是专为专家混合(MoE)模型和专家并行(EP)设计的专用通信库。
MoE 层的推理样式内核!Float8 支持专家级并行性, 并且可以重叠 GPU/CPU 通信和 GPU 计算。也可以用于训练大型 MoE 模型!
https://www.deepep.org/
5.4.3 DeepGEMM a library for efficient FP8 General Matrix
DeepGEMM 是一个库, 专为干净高效的 FP8 通用矩阵乘法(GEMM)而设计, 具有细粒度缩放, 如 DeepSeek-V3 中所建议的那样。
快速 float8 矩阵乘法内核, 动态编译!适合推理和训练!
目前, DeepGEMM 仅支持 NVIDIA Hopper Tensor Core
5.4.4 DualPipe & EPLB & profile-data
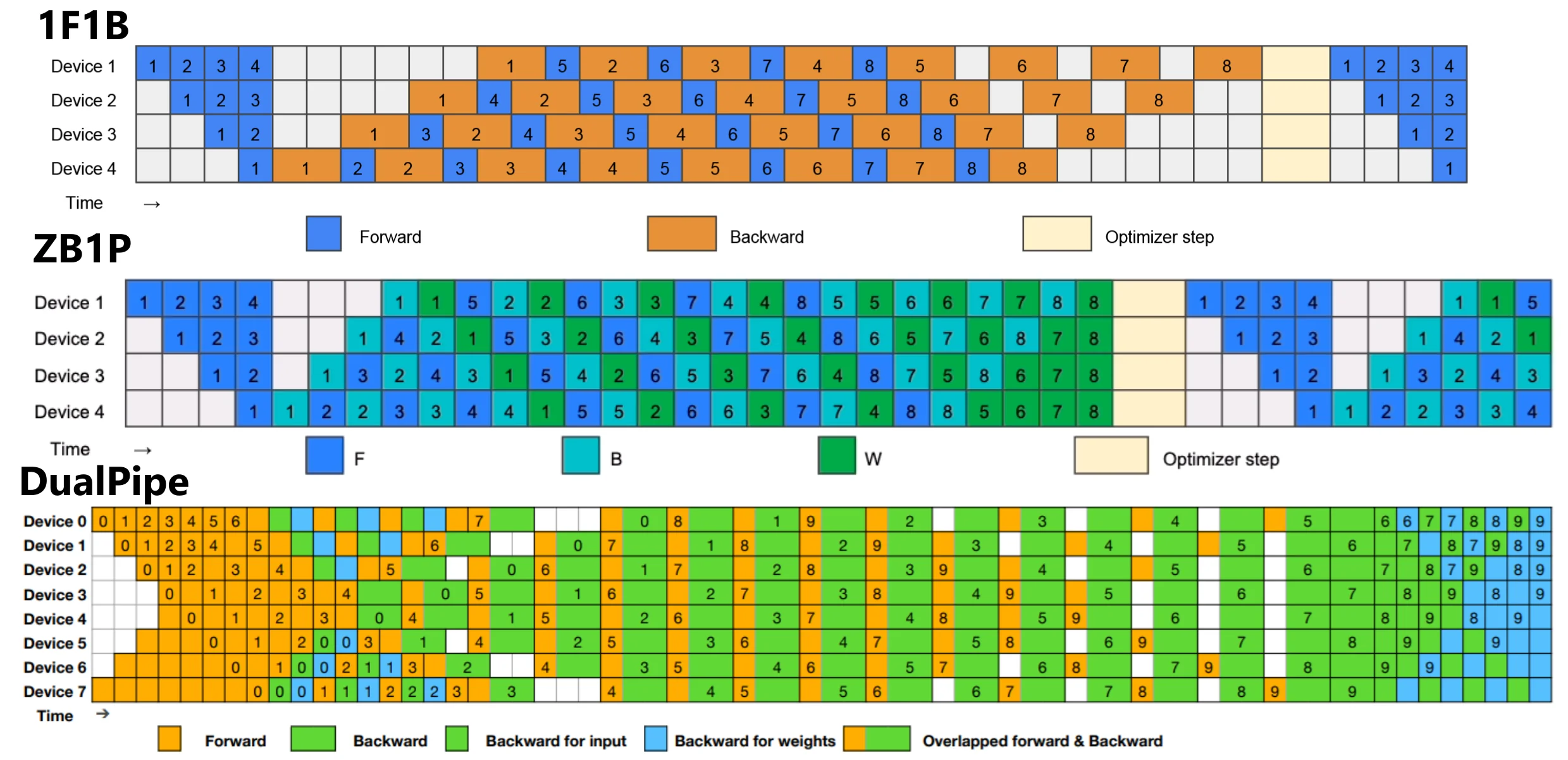
DualPipe 是 DeepSeek-V3 技术报告中介绍的一种创新的双向管道平行算法。它实现了前向和后向计算通信阶段的完全重叠, 还减少了管道气泡。有关 computation-communication overlap 的详细信息, 请参阅 profile data。
EPLB - 适用于 V3/R1 的专家并行负载均衡器。)
在 V3/R1 中分析计算通信重叠(在 DeepSeek Infra 中分析数据)
5.4.5 3FS, Thruster for All DeepSeek Data Access
Fire-Flyer File System(3FS) - a parallel file system that utilizes the full bandwidth of modern SSDs and RDMA networks.
总而言之, 如果您可以使用多个 Nvidia Hopper GPU 托管 DeepSeek-V3, 这些库将使您的运行速度至少提高 3 倍。否则, 本地用户只能从 DeepGEMM 中受益, 因为它更通用, 而不是为 Nvidia Hopper GPU 量身定制。
5.5 MLA 多头潜在注意力
多头潜在注意力(MLA)是 DeepSeek-V2 论文中引入的多头注意力的一种变体。多头注意力有几种变体, 其目的主要是减小 KV 缓存大小, 这是扩展大型模型时出现的内存瓶颈。这些方法(包括 Group-Query Attention 和 Multi-Query Attention)主要被认为是性能权衡, 即性能更差, 但您可以通过减少内存开销来进一步扩展它们。
相比之下, MLA 通过使用低秩因式分解投影矩阵来实现这一点, 其作有点像多查询注意力, 其中不是多次重复单个头, 而是解压缩潜在向量以为每个 Q 头产生唯一、适当的对应 K 和 V 头。DeepSeek 声称这不仅有助于内存开销, 还可以改进模型, 而不是为包含它而受苦。基本思路如下:
- 通过使用低秩分解来转换一个 dim 矩阵来替换 QKV 计算(in,out) 转换为 2 个矩阵(in,rank)和(rank,out)
- 投影每个磁头的压缩 KV 潜在向量, 以获得对应于每个 Q 磁头的完整 K 和 V 磁头。
- 缓存压缩的潜在 KV 向量而不是每个 KV 头, 并从潜在向量动态计算 KV 头。
参考:
模型卡
How to distill Deepseek-R1: A Comprehensive Guide
Deepseek R1 (Ollama)Hardware benchmark for LocalLLM
Deepseek的RL算法GRPO解读
强化学习极简入门: 通俗理解MDP、DP MC TC和Q学习、策略梯度、PPO
一文速览火爆全球的推理模型DeepSeek R1: 如何通过纯RL训练以比肩甚至超越OpenAI o1
一文总览OpenAI o1相关的技术: 从CoT、Quiet-STaR、Self-Correct、Self-play RL、MCTS等到类o1模型rStar-Math
从零复现DeepSeek R1: 从V3中对MoE、MLA、MTP的实现, 到Open R1对R1中SFT、GRPO的实现
Understanding Multi-Head Latent Attention
Hello, DeepSeek Open Infra!
DeepSeek-R1: RL for LLMs Rethought
RLHF (OpenAI) vs Simple RL (DeepSeek)
Using DeepSeek R1 for RAG: Do’s and Don’ts
MOBA: MIXTURE OF BLOCK ATTENTION FOR LONG-CONTEXT LLMS
