
目录
-
- 1. 了解文本相似度
- 2. 计算方法
-
3. 论文分享
- 3.1 Siamese Recurrent Architectures for Learning Sentence Similarity, AAAI 2016
- 3.2 Bilateral Multi-Perspective Matching for Natural Language Sentences, IJCAI 2017
- 3.3 BERT
- 3.4 Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks, EMNLP 2019
- 3.5 On the Sentence Embeddings from Pre-trained Language Models, EMNLP 2020
- 3.6 SimCSE: Simple Contrastive Learning of Sentence Embeddings, EMNLP 2021
- 3.7 ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer, ACL 2021
- 3.8 Exploiting Sentence Embedding for Medical Question Answering, AAAI 2018
- 4. 语义匹配应用
- 5. 模型训练
1. 了解文本相似度
1.1 文本相似度任务处理步骤
处理文本相似度任务时可以分为一下三个步骤:
- 预处理: 如数据清洗等。此步骤旨在对文本做一些规范化操作, 筛选有用特征, 去除噪音。
- 文本表示: 当数据被预处理完成后, 就可以送入模型了。在文本相似度任务中, 需要有一个模块用于对文本的向量化表示, 从而为下一步相似度比较做准备。这个部分一般会选用一些backbone模型, 如LSTM, BERT等。
- 学习范式的选择: 这个步骤也是文本相似度任务中最重要的模块, 同时也是区别于NLP领域其他任务的一个模块。其主要原因在于相似度是一个比较的过程, 因此我们可以选用各种各样的比较的方式来达成目标。可供选择的学习方式有: 孪生网络模型, 交互网络模型, 对比学习模型等。
1.2 文本相似度模型发展历程
从传统的无监督相似度方法, 到孪生模型, 交互式模型, BERT, 以及基于BERT的一些改进工作, 如下图:
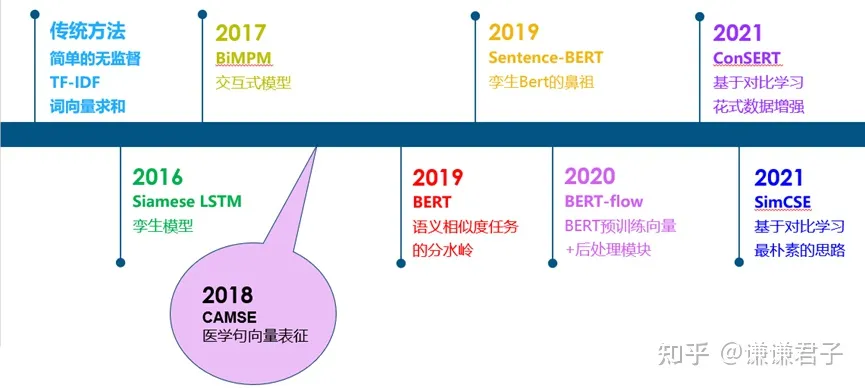
总体来说, 在BERT出现之前, 文本相似度任务可以说是一个百花齐放的过程。大家通过各种方式来做相似度比较的都有。从BERT出现之后, 由于BERT出色的性能, 之后的工作主要是基于BERT的改进。在这个阶段, 大家所采用的数据集, 评价指标等也逐渐进行了统一。
1.3 数据集
在BERT以后, 大家在文本相似度任务上逐渐统一了数据集的选择, 分别为STS12, STS13, STS14, STS15, STS16, STS-B, SICK-R七个数据集。STS12-16分别为SemEval比赛20122016年的数据集。此外, STS-B和SICK-R也是SemEval比赛数据集。在这些数据集中, 每一个文本对都有一个05分的人工打标相似度分数(也称为gold label), 代表这个文本对的相似程度。
中文自然语言推理与文本语义相似度任务中常用的数据集https://github.com/zejunwang1/CSTS:
- 哈工大 LCQMC 数据集
LCQMC是百度知道领域的中文问题匹配数据集, 目的是为了解决在中文领域大规模问题匹配数据集的缺失。该数据集从百度知道不同领域的用户问题中抽取构建数据。 - AFQMC 蚂蚁金融语义相似度数据集
- OPPO 小布对话文本语义匹配数据集
- 谷歌 PAWS-X 数据集
- 北大中文文本复述数据集 PKU-Paraphrase-Bank
- Chinese-STS-B 数据集
- Chinese-MNLI 自然语言推理数据集
- Chinese-SNLI 自然语言推理数据集
- OCNLI 中文原版自然语言推理数据集
- CINLID 中文成语语义推理数据集
1.4 评价指标
首先, 对于每一个文本对, 采用余弦相似度对其打分。打分完成后, 采用所有余弦相似度分数和所有gold label计算Spearman Correlation。
其中, Pearson Correlation与Spearman Correlation都是用来计算两个分布之间相关程度的指标。Pearson Correlation计算的是两个变量是否线性相关, 而Spearman Correlation关注的是两个序列的单调性是否一致。并且论文《Task-Oriented Intrinsic Evaluation of Semantic Textual Similarity》证明, 采用Spearman Correlation更适合评判语义相似度任务。Pearson Correlation与Spearman Correlation的公式如下:
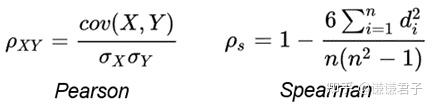
2. 计算方法
2.1 文本向量表示
- 字词粒度, 通过腾讯AI Lab开源的大规模高质量中文词向量数据(800万中文词), 获取字词的word2vec向量表示。
- 句子粒度, 通过求句子中所有单词词嵌入的平均值计算得到。
- 篇章粒度, 可以通过gensim库的doc2vec得到, 应用较少, 本项目不实现。
2.1.1 文本相似度计算
- 基准方法, 估计两句子间语义相似度最简单的方法就是求句子中所有单词词嵌入的平均值, 然后计算两句子词嵌入之间的余弦相似性。
- 词移距离(Word Mover’s Distance), 词移距离使用两文本间的词嵌入, 测量其中一文本中的单词在语义空间中移动到另一文本单词所需要的最短距离。
- rank_bm25方法, 使用bm25的变种算法, 对query和文档之间的相似度打分, 得到docs的rank排序。
2.1.2 无监督短文本匹配
- TF-IDF
- BM25
- 词向量相加平均句向量
- 词向量+sif或者usif或者TFIDF权重平滑
- Bert-flow:Bert这种预训练模型的句向量也不能直接用于短文本匹配
- Bert-whitening: 去除特征间的相关性和让所有特征具有相同的均值和方差
- SimCSE和ESimCSE: 通过对比学习, 进行自监督的方法, 使用计算交叉熵为loss通过softmax分类来学习正负样本相似度。ESimCSE是SimCSE升级版。
2.1.3 有监督短文本匹配
-
表示型短文本匹配模型(经典双塔模型DSSM)
优点:
能好, 速度快
效果还不错, 能学习到深层语义缺点:
表示型模型在匹配层进行点积交互, 点击交互信息太少会丢失一部分深层语义信息 -
交互型(单塔模型)
优点:
效果好, 能学习到深层语义缺点:
大数据量下速度太慢
2.2 传统方法(词汇层面)
传统的文本匹配技术有TF-IDF等算法, 主要解决词汇层面的匹配问题, 或者说词汇层面的相似度问题。而实际上, 基于词汇的匹配算法有很大的局限性。举例: “司机"和"驾驶员"虽然字面上不相似, 但实际表达一个意思。
2.2.1 simhash
Simhash是敏感哈希算法在文本特征提取任务中的应用。它会把一篇文档映射为一个长度为64、元素值为0或1的一维向量。这样我们就可以使用某种距离计算方式, 计算两篇文本的距离和相似度了。一般来说, 与simhash配合的是海明距离。
simhash的适用场景
Simhash的特点是, 对文本的"相同"与否特别敏感: 当两篇文档相同时, 相似度为1; 当其中一篇略有不同, 相似度会有明显降低。因此非常适合用来判断两篇文档内容是否相同。
另外simhash的计算比较简单, 速度上有一定优势。如果配合一定的检索策略来召回候选相似文档, simhash可以用来对海量文档进行去重——这就是simhash最常见的一个应用场景。
2.2.2 距离度量
基于编辑的算法计算将一个字符串转换为另一个字符串所需的最小作数(插入、删除、替换)。
- 编辑距离(Levenshtein Distance): 通过允许插入和删除来泛化汉明距离以处理不同长度的字符串。
print(td.levenshtein('kitten', 'sitting')) # Output: 3
- 欧氏距离
- 余弦距离
- 杰卡德相似度
- 海明距离: 海明距离是simhash算法的御用距离算法, 测量相同长度的两根弦之间的差异。
import textdistance as td
print(td.hamming('book', 'look')) # Output: 1
- Damerau-Levenshtein 距离: 为 Levenshtein 添加移调, 允许交换相邻字符。
print(td.damerau_levenshtein('act', 'cat')) # Output: 1
2.2.3 基于令牌的算法
基于标记的方法将文本分成更小的单元(单词、短语)并比较这些集合。
- Jaccard 相似度: 测量交集的大小除以两个集合的并集的大小。
tokens1 = "I love NLP".split()
tokens2 = "NLP is love".split()
print(td.jaccard(tokens1, tokens2)) # Output: 0.5
- Sorensen-Dice 相似性: 比 Jaccard 更重视共享代币, 使其对重叠更敏感。
- 特沃斯基指数: 一个可定制的指标, 根据上下文强调共享或唯一令牌。
**应用: **
- 文档聚类: 对相似的文本文档进行分组。
- 标签匹配: 比较关键字或标签进行分类。
2.2.4 基于序列的算法
这些算法专注于文本中的模式和序列。
- 最长公共子字符串(LCS): 查找两个字符串共享的最长连续序列。
- Ratcliff-Obershelp 算法: 递归匹配子字符串并根据重叠计算相似性分数。
**应用: **
- DNA分析: 识别遗传数据中的常见序列。
- 抄袭检测: 发现复制的内容。
2.3 深度语义匹配模型(语义层面)
一般来说, 深度文本匹配模型分为两种类型: 表示型和交互型
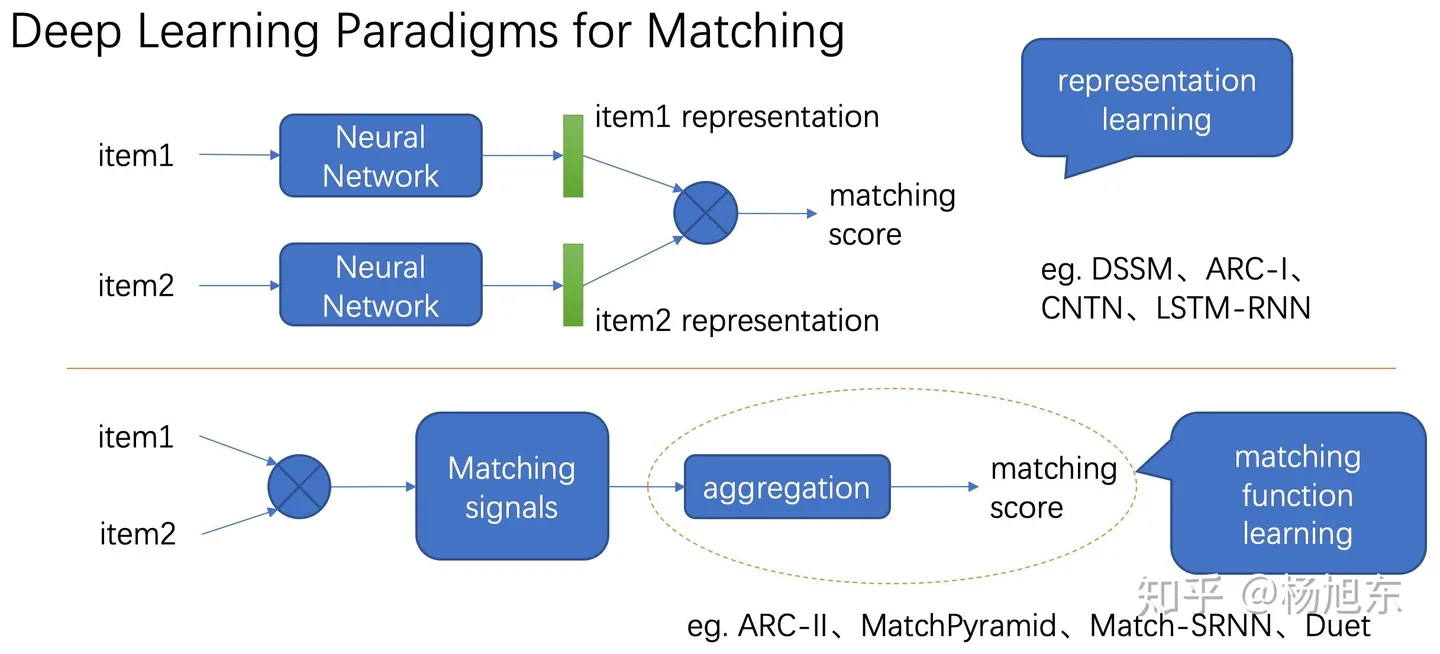
2.3.1 表示型
表示型模型更侧重对表示层的构建, 是典型的孪生网络结构, 双塔共享参数, 将两个句子映射到一个向量空间(句子层面, 整体的匹配)
表示层可以使用MLP, CNN, RNN, Self-attention, Transformer encoder, BERT等
匹配层进行交互计算, 采用点积、余弦、高斯距离、MLP、相似度矩阵均可
优点: 可以对离线计算句向量, 大幅度降低在线计算耗时
缺点:
- 对各文本抽取的仅仅是最后的语义向量, 其中的(词层面的细节)信息损失难以衡量
- 缺乏对文本pair间词法、句法信息的比较;
- 会导致会失去语义焦点, 易语义漂移(没有关注重要的点)。
- 可能准确率不如交互型模型;
比如, query: “今天天气好, 我的心情也好, 请问怎么去广场?”, 其实只有最后一句话重要, 前面都是废话。现在假如知识库里有一个问题是"请问怎么去广场?"。实际上query和问题是精确匹配的, 但两个句向量之间的夹角会受query里面那两个不相关的句子影响。
2.3.2 交互型
交互型(尽早在文本对间进行信息交互, 改善表示型模型的问题。类似于直接使用bert做相似计算, 可以注意到文本局部的重要性, 由局部(词)得到整体(句子))
抛弃后匹配的思路, 进行词间的先匹配, 将先匹配的结果作为灰度图, 进行后续的建模。
先算词间的相似度, 得到feature map, 过CNN得到一个分数??
优点:
- 准确率更好;
- 更好地把握了语义焦点;
- 可以对上下文重要性进行合理的建模。
缺点:
- 耗时长;
- 忽视了句法、句间对照等全局性信息, 无法由局部匹配信息刻画全局匹配信息。
经典做法: 稍早一点的做法, 类似于cv领域的图片分类, 把两个句子构造成二维的特征图的形式, 每一个点表示token之间的匹配信息, 不断二维卷积池化, 最终把二维特征图拉平, 最后做法分类。
2.3.3 软余弦相似度
软余弦通过考虑单词之间的语义关系来扩展余弦相似性。例如, “cat"和"feline"含义相似, 但词汇不同。
from gensim.matutils import softcossim
from gensim import corpora
import gensim.downloader as api
# Load word embeddings
fasttext = api.load("fasttext-wiki-news-subwords-300")
texts = [["I", "love", "food"], ["Meal", "is", "great"]]
dictionary = corpora.Dictionary(texts)
similarity_matrix = fasttext.similarity_matrix(dictionary)
# Calculate soft cosine similarity
bow1 = dictionary.doc2bow(texts[0])
bow2 = dictionary.doc2bow(texts[1])
print(softcossim(bow1, bow2, similarity_matrix))
2.4 举例
2.4.1 ARC-II
ARC-II模型是和表示型模型ARC-I模型在同一篇论文中提出的姊妹模型, 采用pair-wise ranking loss的目标函数。
其核心结构为匹配层的设计:
- 对文本对的(n-gram)Embedding结果进行拼接, 然后利用1-D CNN得到文本S_X中任一token i和文本S_Y中任一token j的交互张量元素M_{ij}。该操作既然考虑了n-gram滑动窗口对于local信息的捕捉, 也通过拼接实现了文本对间低层级的交互。
- 对交互张量进行堆叠的global max-pooling和2D-CNN操作, 从而扩大感受野。
- 最后拉平做分类
2.4.2 MatchPyramid(匹配金字塔 match疲弱门特)
无论是ARC-II中的n-gram拼接+1D conv还是Pair-CNN中的中间Matrix虽然均通过运算最终达到了信息交互的作用, 但其定义还不够显式和明确, MatchPyramid借鉴图像卷积网络的思想, 更加显式的定义了细粒度交互的过程。
MatchPyramid通过两文本各token embedding间的直接交互构造出匹配矩阵, 然后将其视为图片进行2D卷积和2D池化, 最后Flatten接MLP计算得匹配分数。本文共提出了三种匹配矩阵的构造方式:
- Indicator: 0-1型, 即一样的token取1, 否则取0; 这种做法无法涵盖同义多词的情况;
- Cosine: 即词向量的夹角余弦;
- Dot Product: 即词向量的内积
此外值得注意的是因为各个文本pair中句子长度的不一致, 本文并没有采用padding到max-lenght的惯用做法, 而是采用了更灵活的动态池化层, 以保证MPL层参数个数的固定。
3. 论文分享
3.1 Siamese Recurrent Architectures for Learning Sentence Similarity, AAAI 2016
Siamese LSTM是一个经典的孪生网络模型, 它将需要对比的两句话分别通过不同的LSTM进行编码, 并采用两个LSTM最后一个时间步的输出来计算曼哈顿距离, 并通过MSE loss进行反向传导。
3.2 Bilateral Multi-Perspective Matching for Natural Language Sentences, IJCAI 2017
BiMPM是一个经典的交互式模型, 它将两句话用不同的Bi-LSTM模型分别编码, 并通过注意力的方式使得当前句子的每一个词都和另一个句子中的每一个词建立交互关系(左右句子是对称的过程), 从而学习到更深层次的匹配知识。在交互之后, 再通过Bi-LSTM模型分别编码, 并最终输出。
对于交互的过程, 作者设计了四种交互方式, 分别为:
- 句子A中每个词与句子B的最后一个词进行交互
- 句子A中每个词与句子B的每个词进行交互, 并求element-wise maximum
- 通过句子A中的词筛选句子B中的每一个词, 并将句子B的词向量加权求和, 最终于A词对比
- 与c几乎一致, 只不过将加权求和操作变成element-wise maximum
具体的交互形式是由加权的余弦相似度方式完成。
3.3 BERT
BERT可以认为是语义相似度任务的分水岭。BERT论文中对STS-B数据集进行有监督训练, 最终达到了85.8的Spearman Correlation值。这个分数相较于后续绝大部分的改进工作都要高, 但BERT的缺点也很明显。对于语义相似度任务来说:
- 在有监督范式下, BERT需要将两个句子合并成一个句子再对其编码, 如果需要求很多文本两两之间的相似度, BERT则需要将其排列组合后送入模型, 这极大的增加了模型的计算量。
- 在无监督范式下, BERT句向量中携带的语义相似度信息较少。从下图可以看出, 无论是采用CLS向量还是词向量平均的方式, 都还比不过通过GloVe训练的词向量求平均的方式要效果好。
基于以上痛点, 涌现出一批基于BERT改进的优秀工作。
3.4 Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks, EMNLP 2019
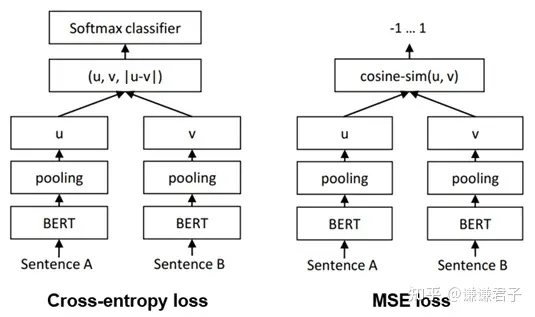
Sentence-BERT是一篇采用孪生BERT架构的工作。Sentence-BERT作者指出, 如果想用BERT求出10000个句子之间两两的相似度, 排列组合的方式在V100 GPU上测试需要花费65小时; 而如果先求出10000个句子, 再计算余弦相似度矩阵, 则只需要花费5秒左右。因此, 作者提出了通过孪生网络架构训练BERT句向量的方式。
Sentence-BERT一共采用了三种loss, 也就是三种不同的方式训练孪生BERT架构, 分别为Cross-entropy loss, MSE loss以及Triple loss, 模型图如下:
3.5 On the Sentence Embeddings from Pre-trained Language Models, EMNLP 2020
BERT-flow是一篇通过对BERT句向量做后处理的工作。作者认为, 直接用BERT句向量来做相似度计算效果较差的原因并不是BERT句向量中不包含语义相似度信息, 而是其中包含的相似度信息在余弦相似度等简单的指标下无法很好的体现出来。
首先, 作者认为, 无论是Language Modelling还是Masked Language Modelling, 其实都是在最大化给定的上下文与目标词的共现概率, 也就是Ct和Xt的贡献概率。Language Modelling与Masked Language Modelling的目标函数如下:

因此, 如果两句话预测出的Xt一致, 那么两句话的Ct向量很有可能也是相似的! 考虑如下两句话:
- 今天中午吃什么?
- 今天晚上吃什么?
通过这两句话训练出的语言模型都通过上下文预测出了"吃"这个字, 那说明这两句话的句向量也很可能是相似的, 具有相似的语义信息。
其次, 作者通过观察发现, BERT的句向量空间是各向异性的, 且高频词距离原点较近, 低频词距离较远, 且分布稀疏。因此BERT句向量无法体现出其中包含的相似度信息。
因此, 作者认为可以通过一个基于流的生成模型来对BERT句向量空间进行映射。具体来说, 作者希望训练出一个标准的高斯分布, 使得该分布中的点可以与BERT句向量中的点一一映射。由于该方法采用的映射方式是可逆的, 因此就可以通过给定的BERT句向量去映射回标准高斯空间, 然后再去做相似度计算。由于标准高斯空间是各向同性的, 因此能够将句向量中的语义相似度信息更好的展现出来。
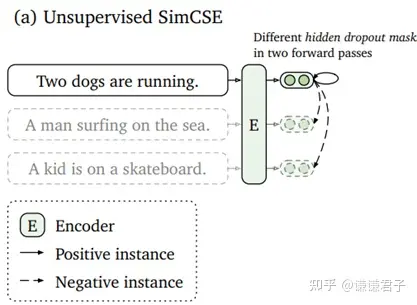
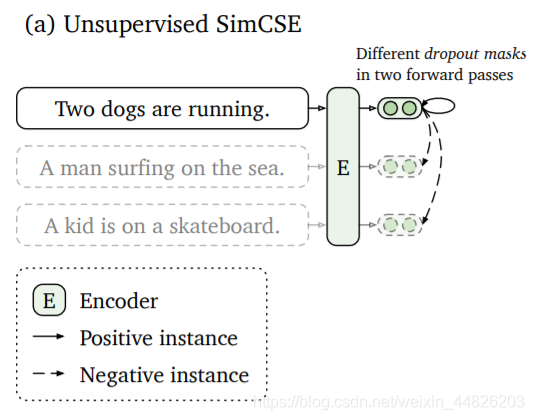
3.6 SimCSE: Simple Contrastive Learning of Sentence Embeddings, EMNLP 2021
SimCSE是一篇基于对比学习的语义相似度模型。首先, 对比学习相较于文本对之间的匹配, 可以在拉近正例的同时, 同时将其与更多负例之间的距离拉远, 从而训练出一个更加均匀的超球体向量空间。作为一类无监督算法, 对比学习中最重要的创新点之一是如何构造正样本对, 去学习到类别内部的一些本质特征。
SimCSE采用的是一个极其朴素, 性能却又出奇的好的方法, 那就是将一句话在训练的时候送入模型两次, 利用模型自身的dropout来生成两个不同的sentence embedding作为正例进行对比。模型图如下:
3.7 ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer, ACL 2021
ConSERT同样也是一篇基于对比学习的文本相似度工作。ConSERT是采用多种数据增强的方式来构造正例的。其中包括对抗攻击, 打乱文本中的词顺序, Cutoff以及Dropout。这里需要注意的是, 虽然ConSERT与SimCSE都采用了Dropout, 但ConSERT的数据增强操作只停留在embedding layer, 而SimCSE则是采用了BERT所有层中的Dropout。此外, 作者实验证明, 在这四种数据增强方式中, Token Shuffling和Token Cutoff是最有效的。
3.8 Exploiting Sentence Embedding for Medical Question Answering, AAAI 2018
MACSE是一篇针对医学文本的句向量表征工作, 虽然其主要关注的是QA任务, 但他的句向量表征方式在文本相似度任务中同样适用。
医学文本区别于通用文本的一大特征就是包含复杂的多尺度信息, 如下:

因此, 我们就需要一个能够关注到医学文本多尺度信息的模型。通过多尺度的卷积操作, 就可以有效的提取到文本中的多尺度信息, 并且通过注意力机制对多尺度信息进行加权, 从而有效的关注到特定文本中在特定尺度上存在的重要信息。
4. 语义匹配应用
工业界的很多应用都有在语义上衡量文本相似度的需求, 我们将这类需求统称为"语义匹配”。
根据文本长度的不同, 语义匹配可以细分为三类:
- 短文本-短文本语义匹配;
- 短文本-长文本语义匹配;
- 长文本-长文本语义匹配
4.1 短文本-短文本语义匹配
该类型在工业界的应用场景很广泛。如, 在网页搜索中, 需要度量用户查询(Query)和网页标题(web page title)的语义相关性;
在Query查询中, 需要度量 Query和其他 Query之间的相似度。
由于主题模型在短文本上的效果不太理想, 在短文本-短文本匹配任务中词向量的应用 比主题模型更为普遍。简单的任务可以使用Word2Vec这种浅层的神经网络模型训练出来的词向量。如, 计算两个Query的相似度, q1 = “推荐好看的电影"与 q2 = “2016年好看的电影”。通过词向量按位累加的方式, 计算这两个Query的向量表示(表示型)
利用余弦相似度(Cosine Similarity)计算两个向量的相似度。
对于较难的短文本-短文本匹配任务, 考虑引入有监督信号并利用"DSSM(一个query对多个文档, 计算交叉熵)“或"CLSM"这些更复杂的神经网络进行语义相关性的计算。
4.2 短文本-长文本语义匹配
短文本-长文本语义匹配的应用场景在工业界非常普遍。例如, 在搜索引擎中, 需要计算用户 Query 和一个网页正文(content)的语义相关度。由于 Query 通常较短, 因此 Query 与 content 的匹配与上文提到的短文本-短文本不同, 通常需要使用短文本-长文本语义匹配, 以得到更好的匹配效果。
在计算相似度的时候, 我们规避对短文本直接进行主题映射, 而是根据长文本的主题分布, 计算该分布生成短文本的概率, 作为他们之间的相似度。
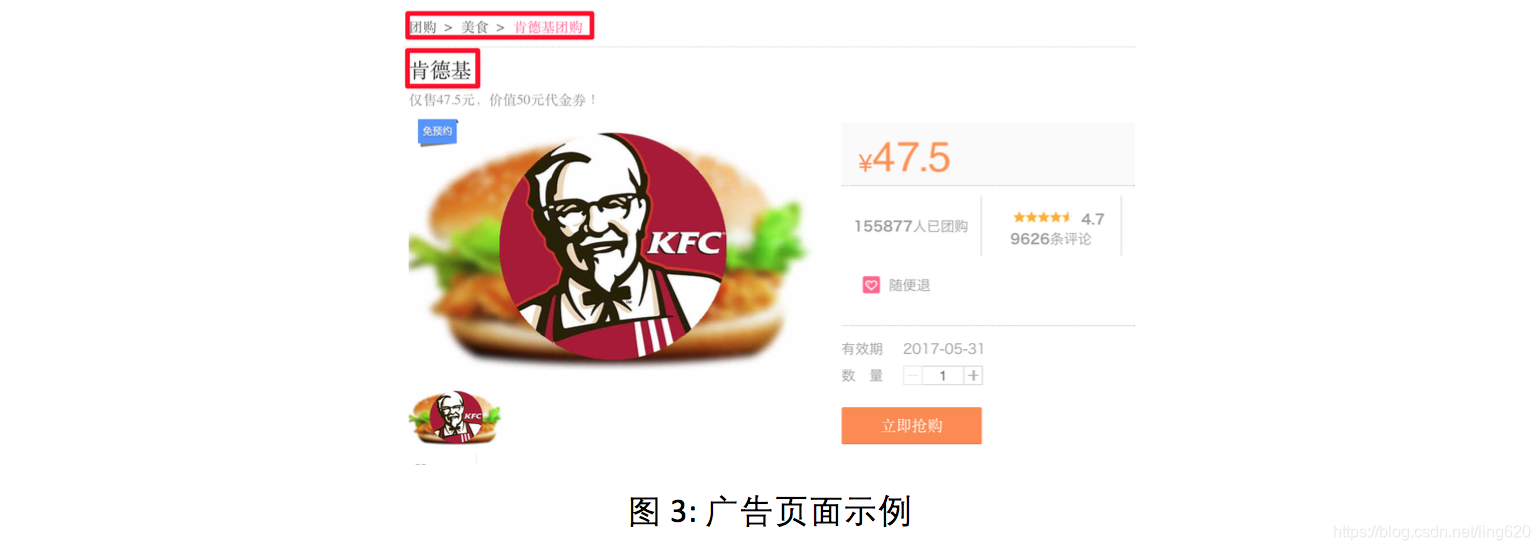
4.2.1 案例1-用户查询-广告页面相似度
在线广告场景中, 需要计算用户查询和广告页面的语义相似度。这时可应用sentence LDA, 将广告页面中各个域的文本视为句子, 如下图所示, 红框内为句子。
- 通过主题模型学习得到广告的主题分布
- 使用上面的公式计算查询和广告页面的语义相似度
该相似度可作为一维特征, 应用在更复杂的排序模型中。
4.2.2 案例2: 文档关键词抽取
在分析文档时, 往往会抽取一些文档的关键词做标签(tag), 这些tag在用户画像和推荐任务中扮演着重要角色。从文档中抽取关键词, 常用方法是TF和IDF信息。此外, 还可利用主题模型, 估计一个文档产生单词的概率作为该单词的重要度指标:
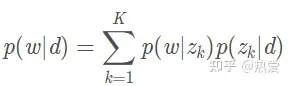
下面一段文字是我们随机从网上取的一个新闻片段, 对其进行分词处理以及应用主题模型LDA 或 TWE后, 然后分别选取公式(2)或公式(3)计算每个词的重要度。在表5中, 我们列出了 LDA 和 TWE模型计算得到的 Top-10 关键词集合 (已去除停用词)。从表中可以看出, 采用 TWE 得到的 Top-10 关键词 能更好地体现出新闻的重要信息。

总结:
- 利用主题模型或者其他方法如TF-IDF方法获取长本文的主题分布/提取关键词
- 计算Querry与文档主题/提取关键词之间的相似度
4.3 长文本-长文本语义匹配
通过使用主题模型, 我们可以得到两个长文本的主题分布, 再通过计算两个多项式分布的距离来衡量它们之间的相似度。衡量多项式的距离 可以利用Hellinger Distance和Jensen-Shannon Divergence(JSD)
4.3.1 案例3: 新闻个性化推荐
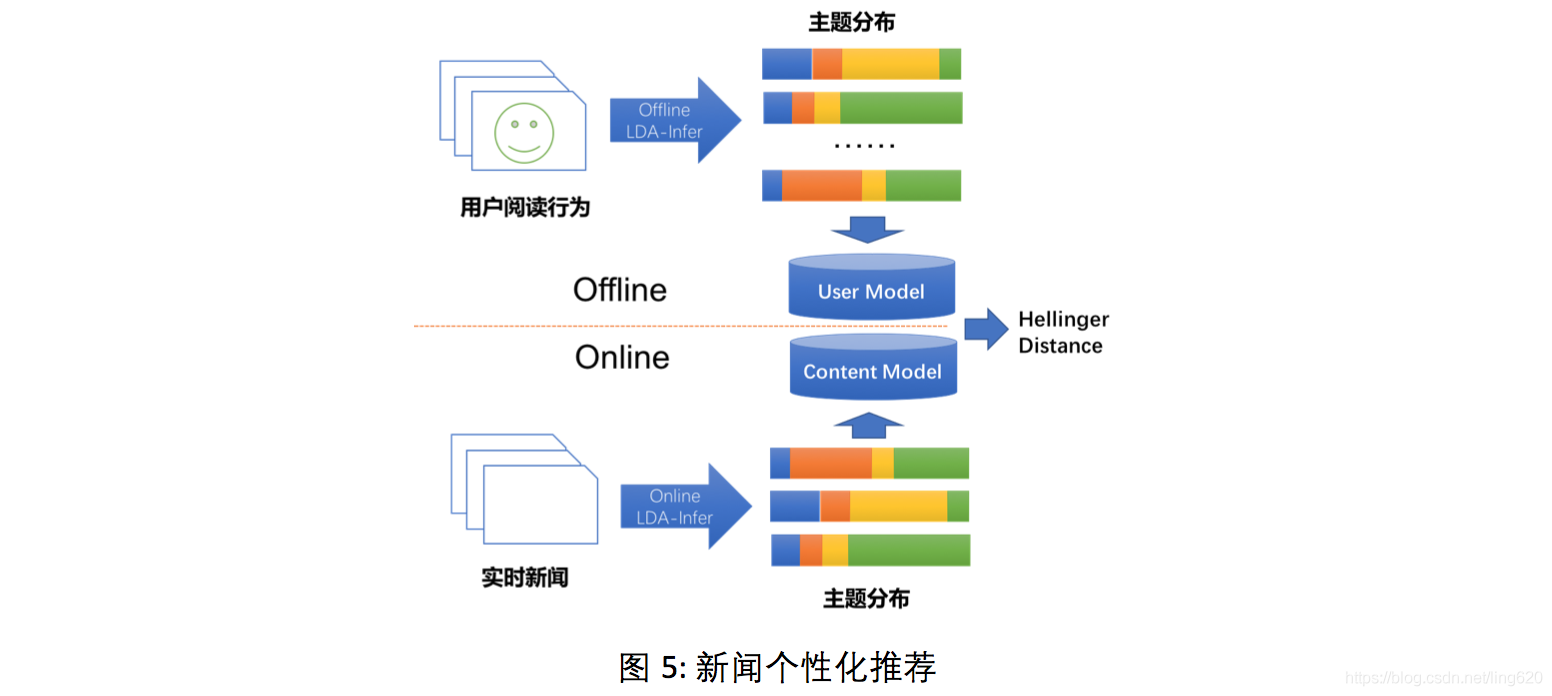
长文本-长文本的语义匹配可用于个性化推荐的任务中。在互联网应用中, 当我们积累了用户大量的行为信息后, 这些行为信息对应的文本内容可以组合成一篇抽象的"文档”, 对该"文档"进行主题映射后获得的主题分布作为用户画像。
例如, 在新闻个性化推荐中, 我们可以将用户近期阅读的新闻(或新闻标题)合并成一篇长"文档”, 并将该"文档"的主题分布作为表达用户阅读兴趣的用户画像。如图所示, 通过计算每篇实时新闻的主题分布与用户画像之间的Hellinger Distance, 可作为向用户推送新闻的选择依据, 达到新闻个性化推荐的效果。
总结:
- 分别计算长文本的主题分布
- 计算两个多项式分布之间的距离作为相似度度量
知识点:
Hellinger Distance(海林格距离): 又称Bhattacharyya distance, 因为作者的姓氏叫Anil Kumar Bhattacharya。在概率和统计学中, 海林格距离被用来衡量两个概率分布之间的相似性, 属于f-divergence的一种。而f-divergence又是什么呢? 一个f-divergence是一个函数 Dƒ(P||Q) 用来衡量两个概率分布P 和Q 之间的不同。
5. 模型训练
对称语义搜索问题(query和answer的长度相近,例如两句话比较语义相似度)则采用https://www.sbert.net/docs/pretrained_models.html#sentence-embedding-models中给出的预训练模型.
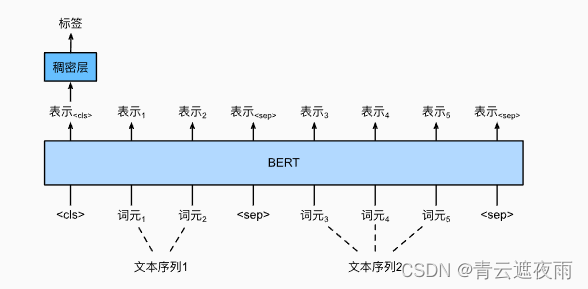
在微调过程中, BERT 的作者建议使用以下超参 (from Appendix A.3 of the BERT paper):
- 批量大小: 16, 32
- 学习率(Adam): 5e-5, 3e-5, 2e-5
- epochs 的次数: 2, 3, 4
5.1 SimCSE
SimCSE采用一个编码器,利用dropout机制中的随机原理,构建训练的正样本,拉进空间中正例之间的距离。
参考:
NLP实践——基于SBERT的语义搜索, 语义相似度计算, SimCSE、GenQ等无监督训练
语义相似度计算(文本匹配)
语义相似度模型SBERT ——一个挛生网络的优美范例
中文自然语言推理与语义相似度数据集汇总
使用 Transformers 预训练语言模型进行 Fine-tuning(文本相似度任务)
【译】BERT Fine-Tuning 指南(with PyTorch)
无监督语义相似度哪家强?我们做了个比较全面的评测
【文本匹配】Text Matching中的单塔方法和双塔方法(附源码)
LCQMC文本相似度(单塔模型)
