
目录
-
- 1. 简介
-
2. 公开榜单
- 2.1 Other
- 2.2 视觉语言模型一些排行榜:
- 2.1 开源评测榜单C-Eval
- 2.2 Open LLM Leaderboard
- 2.3 上海人工智能实验室的OpenCompass(CMMLU)
- 2.4 SuperCLUE中文大模型基准评
- 2.5 AlpacaEval Leaderboard
- 2.6 LMSYS ORG排行榜
- 2.7 其他
- 2.7.1 PromptCBLUE: 中文医疗场景的LLM评测基准
- 2.7.2 InstructEval Leaderboard
- 2.7.3 EvalPlus Leaderboard
- 2.7.4 HumanEval(页面有问题)
- 2.7.5 魔搭社区榜单
- 2.7.6 CLiB中文大模型能力评测榜单
- 2.7.7 智源研究院的FlagEval
- 2.7.8 code-generation-on-humaneval
- 2.7.9 BIRD-SQL
- 3. 测试数据集
- 4. 评估
评估语言模型的性能对于评估其质量和确定需要改进的领域至关重要。传统上, 语言模型的评估指标侧重于特定于任务的性能, 例如准确性、F1 分数和困惑度。这些指标用于评估专为特定任务(如文本分类、命名实体识别和机器翻译)设计的模型。
LLMs的不可思议的能力可以推广到广泛的NLP任务, 这要求研究人员设计全面的评估基准, 以有效地测试他们在各种任务上的能力。这些基准测试应该涵盖 LLM 的全部功能, 同时足够简单, 易于管理和解释。
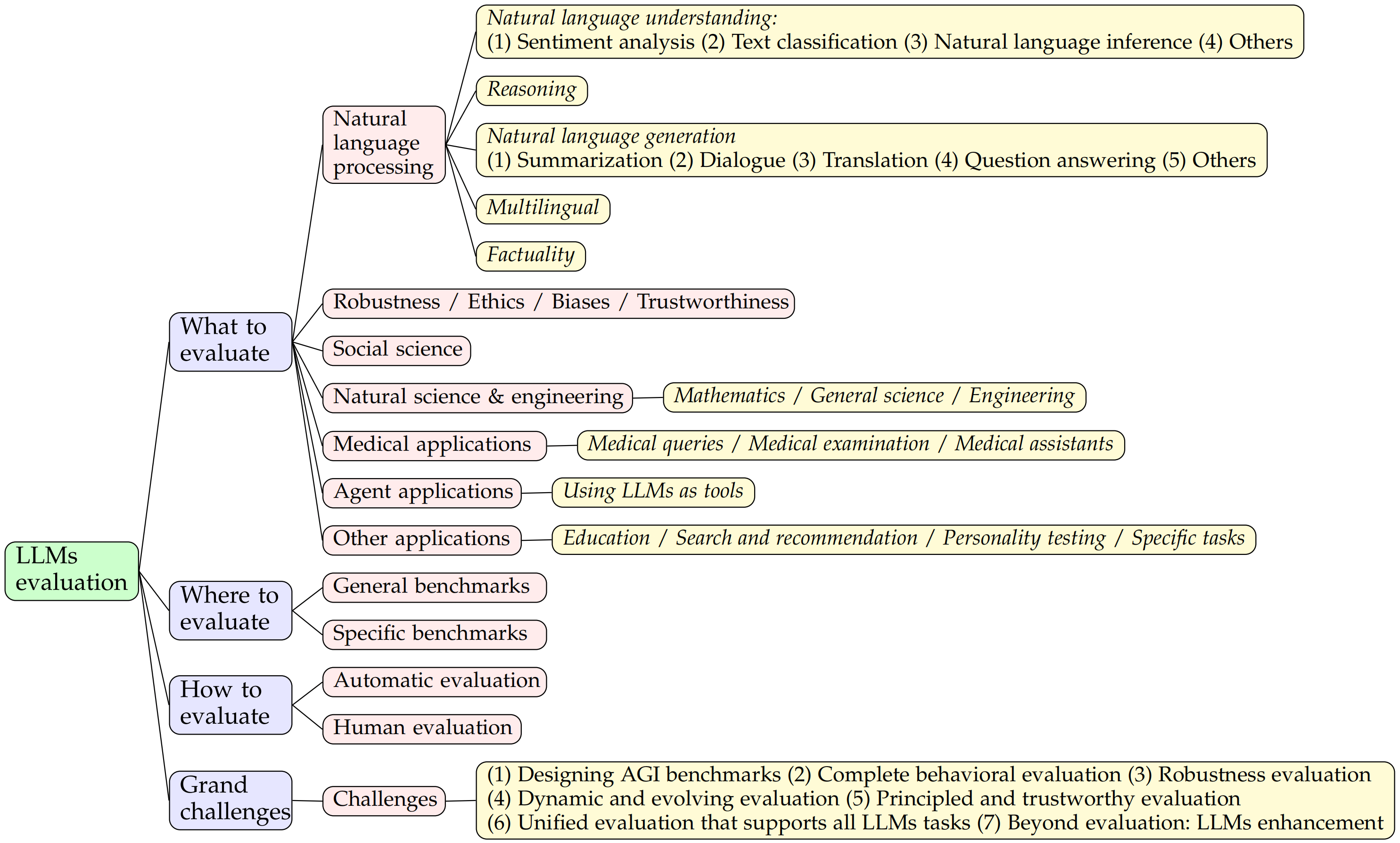
1. 简介
1.1 评测方向
综合能力(得分的平均值)
- 分类能力
- 信息抽取能力
- 阅读理解能力
- 数据分析能力
1.2 评测方法
1.2.1 评测基准
1.2.1.1 GLUE
是NLU任务的的评测基准, 通用语言理解评估基准。评估了语言模型在广泛的现有 NLU 任务中的性能, 从情感分析到文本蕴涵等。GLUE 不会对模型架构施加限制, 允许探索各种方法和技术。唯一的要求是能够处理单句和句子对输入并生成相应的预测。
SuperGLUE提出了一组新的更具挑战性的语言任务, 突破了NLU模型所能实现的界限。SuperGLUE的创建是为了通过向NLU模型提供更具挑战性的任务来扩展它们可以实现的边界。它建立在GLUE奠定的基础之上, 继续强调多样化的语言任务和对语言现象的广泛覆盖。
1.2.1.2 HumanEval
是一个用于评估代码生成模型性能的数据集, 由OpenAI在2021年推出。这个数据集包含164个手工编写的编程问题, 每个问题都包括一个函数签名、文档字符串(docstring)、函数体以及几个单元测试。
1.2.1.3 MBPP
MBPP(Mostly Basic Programming Problems)是一个数据集, 主要包含了974个短小的Python函数问题, 由谷歌在2021年推出, 这些问题主要是为初级程序员设计的, 结果通过pass@k表示, 其中k表示模型一次性生成多少种不同的答案中, 至少包含1个正确的结果。
1.2.1.4 IFEval: 指令跟踪评估。
IFEval 是一个简单易行的评估基准。它侧重于一组“可验证的指令”, 例如“写出400字以上”和“至少提及AI关键字3次”。我们确定了 25 种类型的可验证指令, 并构建了大约 500 个提示, 每个提示都包含一个或多个可验证指令。
1.2.1.5 MT Bench
MT Bench也称为“多轮基准测试”, 是一种评估大型语言模型(LLM) 的方法。该基准测试提供了对 LLM 性能的详细分析, 特别关注它们在多轮对话中管理对话流和遵循指令的能力。它围绕 80 个多回合问题构建, 每个问题都旨在评估对话中 LLM 的深度。它涵盖了许多类别, 包括写作、推理、编码和科学, 确保了全面的法学硕士评估。
1.2.1.6 AGIEval
AGIEval: 以人为本的评估基础模型的基准。专门设计用于在以人为本的标准化考试(如高考、法学院入学考试、数学竞赛和律师资格考试)的背景下评估基础模型。
AGIEval基准(Zhong等人, 2023)包含了来自中国高考、中国律师资格考试和中国公务员考试的数据。
1.2.1.7 BIG-bench
Beyond the Imitation Game Benchmark(BIG-bench)是一个全面的评估框架, 旨在评估语言模型在各种任务中的能力和局限性。BIG-bench 目前包括来自 132 个机构的 444 位作者贡献的 204 项任务, 重点关注语言学、儿童发展、数学、常识推理、生物学、物理学、社会偏见和软件开发等不同主题。
BBH(BIG-Bench Hard): 是 BIG-Bench 的一个子集, BIG-Bench 是一个用于语言模型的多样化评估套件。BBH 专注于 BIG-Bench 的 23 个具有挑战性的任务, 这些任务被发现超出了当前语言模型的能力。在这些任务中, 先前的语言模型评估没有优于普通的人类评估者。BBH 任务需要多步骤推理, 并且发现没有思维链(CoT) 的少量提示, 就像在 BIG-Bench 评估中所做的那样, 大大低估了语言模型的最佳性能和能力。当 CoT 提示应用于 BBH 任务时, 它使 PaLM 在 23 个任务中的 10 个任务中超过了人类评分者的平均表现, 而 Codex 在 23 个任务中的 17 个任务上超过了人类评分者的平均表现。
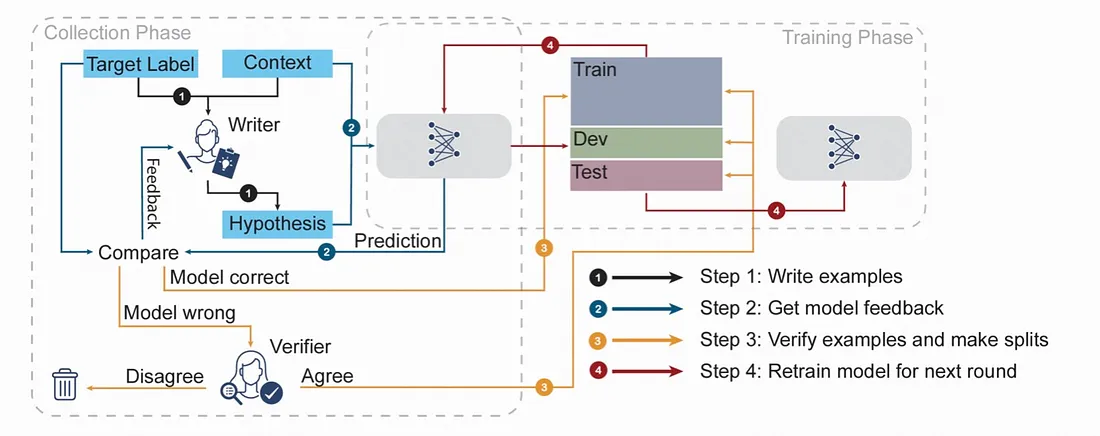
1.2.1.8 对抗性 NLI
对抗性 NLI(ANLI), 一个大规模的自然语言推理(NLI) 基准数据集, 使用迭代、对抗性的人与模型在环过程收集。这种方法旨在创建基准, 这些基准在不断学习和随着时间的推移而发展的同时, 提出了更困难的挑战。
1.2.1.9 其他
- GSM8K(小学数学)
- MMLU(多学科问答): 供了从真实世界的考试和书籍中收集的多领域和多任务评价。
- HELM基准: 汇总了42个不同的任务, 用从准确性到鲁棒性的7个指标来评估LLMs。
- AI2 推理挑战(ARC) - ARC 评估模型回答复杂问题的能力, 这些问题需要更深入的知识和推理, 而不仅仅是检索。它有大约 7.5k 个来自小学科学的问题, 它通过要求推理、常识和深入的文本理解来推动人工智能的进步。
- HellaSwag - HellaSwag 评估 AI 中的常识, 尤其是在以有意义的方式完成句子和段落方面.
- TruthfulQA - 该基准测试旨在衡量语言模型在回答各种问题时的准确性, 涵盖 38 个类别的 817 个问题, 重点关注反映训练数据中常见误解的误导性回答。
- CLUE基准(Xu等人, 2020)是第一个大规模的中文NLU基准, 现在仍然是使用最广泛和最好的中文基准。
- MMCU基准(Zeng, 2023)包括来自医学、法律、心理学和教育等四大领域的测试, 这些数据也是从中国高考、资格考试以及大学考试中收集的。
- LLM Creativity 基准: 评估大型语言模型用作未经审查的创意写作助手的能力
2. 公开榜单
| 榜单 | 类型 | 排行榜 | 备注 |
|---|---|---|---|
| C-Eval | 中文指令 | 榜单 | checked |
| OpenCompass | 中文指令 | 榜单 | |
| SuperCLUE | 中文指令 | 榜单 | |
| FlagEval | 中文指令 | 榜单 | |
| EvalPlus Leaderboard | 代码 | 榜单 | checked |
| code-generation-on-humaneval | 代码 | 榜单 | |
| Open LLM Leaderboard | 指令 | 榜单 | |
| AlpacaEval Leaderboard | 指令 | 榜单 | |
| LMSYS ORG | 指令 | 榜单 | |
| ConTextual Leaderboard | 对包含文本的图像进行解析/推理 | 榜单 | |
| LMSYS Leaderboard | Chatbot Arena | 榜单 | |
| vellum Leaderboard | math-science-reasoning | 榜单 | |
| mteb Leaderboard | Embedding | 榜单 | |
| bigcode Leaderboard | 代码 | 榜单 | |
| can-ai-code | 代码 | 榜单 | |
| UGI Leaderboard | General | 榜单 | |
| TTS-Arena | TTS | 榜单 | |
| open_asr | TTS | 榜单 | |
| open_medical_llm | 医学模型 | 榜单 | |
| livecodebench | 代码 | 榜单, https://livecodebench.github.io/leaderboard.html | |
| Berkeley Function-Calling Leaderboard | Function Call | 榜单 | |
| open_vlm Leaderboard | VISION | 榜单 |
2.1 Other
- https://livebench.ai/#
- https://huggingface.co/spaces/Pendrokar/TTS-Spaces-Arena
- https://github.com/eosphoros-ai/Awesome-Text2SQL/blob/main/README.zh.md
- https://huggingface.co/hysts
- https://artificialanalysis.ai/leaderboards/models
- https://huggingface.co/blog/leaderboard-medicalllm
- https://huggingface.co/spaces/openlifescienceai/open_medical_llm_leaderboard
- https://huggingface.co/spaces/open-rl-leaderboard/leaderboard
- https://prollm.toqan.ai/leaderboard
- https://github.com/NousResearch/Hermes-Function-Calling
- https://aider.chat/docs/leaderboards/
- https://mathvista.github.io/#leaderboard
- https://oobabooga.github.io/benchmark.html
- https://scale.com/leaderboard
- http://eqbench.com/
- https://huggingface.co/blog?tag=leaderboard
- 字节跳动推出 SuperGPQA
2.2 视觉语言模型一些排行榜:
- https://mmbench.opencompass.org.cn/leaderboard
- https://mmmu-benchmark.github.io/#leaderboard
- https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models/tree/Evaluation
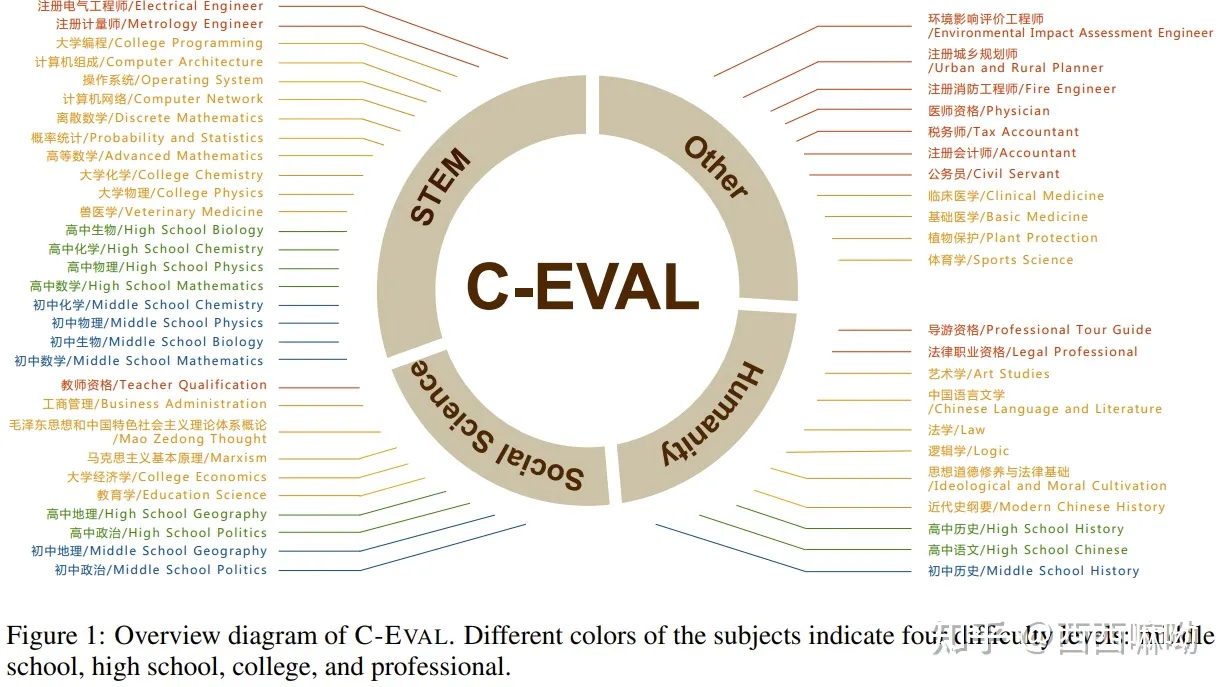
2.1 开源评测榜单C-Eval
C-Eval是一个针对基础模型的综合中文评估套件。它由 13948 道多项选择题组成, 涵盖 52 个不同学科和四个难度级别, 如下所示。请访问我们的网站或查看我们的论文以了解更多详细信息。
构造中文大模型的知识评估基准, 该评测基准是由上海交通大学, 清华大学, 爱丁堡大学共同完成的, 构造了一个覆盖人文, 社科, 理工, 其他专业四个大方向, 52 个学科(微积分, 线代 …), 从中学到大学研究生以及职业考试, 一共 13948 道题目的中文知识和推理型测试集。此外还给出了当前主流中文LLM的评测结果。
- Git主页: https://github.com/hkust-nlp/ceval
- 榜单地址: https://cevalbenchmark.com/static/leaderboard_zh.html
- Data: https://cevalbenchmark.com/static/javascript/leaderboard_subject_data.js
2.2 Open LLM Leaderboard
HuggingFace发布的开源LLM的排行榜, 主要是跟踪、排名和评估最新的大语言模型和聊天机器人, 让所有人方便的观察到开源社区的进展和评估这些模型。
2.3 上海人工智能实验室的OpenCompass(CMMLU)
OpenCompass 是一个开源开放的大模型评测平台, 构建了包含学科、语言、知识、理解、推理五大维度的通用能力评测体系, 支持了超过 50 个评测数据集和 30 万道评测题目, 支持零样本、小样本及思维链评测.
- 官方地址: https://opencompass.org.cn/leaderboard-llm
- 榜单地址: https://huggingface.co/spaces/opencompass/opencompass-llm-leaderboard
2.4 SuperCLUE中文大模型基准评
中文通用大模型综合性测评基准(SuperCLUE), 是针对中文可用的通用大模型的一个测评基准。
2.5 AlpacaEval Leaderboard
来自斯坦福的团队, 基于 AlpacaFarm 评估集, 该评估集测试模型遵循一般用户指令的能力。然后, 通过所提供的 GPT-4 或基于 Claude 或 ChatGPT 的自动注释器将这些响应与参考 Davinci003 响应进行比较, 从而得出上述获胜率。AlpacaEval 与真实人类注释的一致性很高, AlpacaEval 上的排行榜排名与基于人类注释者的排行榜排名非常相关。
项目链接: https://github.com/tatsu-lab/alpaca_eval
榜单地址: https://tatsu-lab.github.io/alpaca_eval/
Data: https://raw.githubusercontent.com/tatsu-lab/alpaca_eval/main/docs/data_AlpacaEval_2/weighted_alpaca_eval_gpt4_turbo_leaderboard.csv
2.6 LMSYS ORG排行榜
UC伯克利主导的「LLM排位赛」(LMSYS Org)。该研究团队选择了目前在开源社区很火的开源模型, 还有GPT-4、PaLM 2等众多「闭源」模型。
This leaderboard is based on the following three benchmarks.
- Chatbot Arena - a crowdsourced, randomized battle platform. We use 100K+ user votes to compute Elo ratings.
- MT-Bench - a set of challenging multi-turn questions. We use GPT-4 to grade the model responses.
- MMLU (5-shot) - a test to measure a model’s multitask accuracy on 57 tasks.
榜单地址: https://chat.lmsys.org/
2.7 其他
2.7.1 PromptCBLUE: 中文医疗场景的LLM评测基准
榜单地址: https://github.com/michael-wzhu/PromptCBLUE
为推动LLM在医疗领域的发展和落地, 华东师范大学王晓玲教授团队联合阿里巴巴天池平台, 复旦大学附属华山医院, 东北大学, 哈尔滨工业大学(深圳), 鹏城实验室与同济大学推出PromptCBLUE评测基准, 对CBLUE基准进行二次开发, 将16种不同的医疗场景NLP任务全部转化为基于提示的语言生成任务,形成首个中文医疗场景的LLM评测基准。
2.7.2 InstructEval Leaderboard
An Evaluation Suite for Instructed Language Models
榜单地址: https://declare-lab.net/instruct-eval/
2.7.3 EvalPlus Leaderboard
EvalPlus evaluates AI Coders with rigorous tests.
榜单地址: https://evalplus.github.io/leaderboard.html
Data:
2.7.4 HumanEval(页面有问题)
榜单地址: https://huggingface.co/spaces/HuggingFaceH4/human_eval_llm_leaderboard
2.7.5 魔搭社区榜单
榜单地址: https://www.modelscope.cn/leaderboard/58/ranking?type=free
2.7.6 CLiB中文大模型能力评测榜单
榜单地址: https://github.com/jeinlee1991/chinese-llm-benchmark
2.7.7 智源研究院的FlagEval
FlagEval是一个面向AI大模型的开源评测工具包, 同时也是一个开放的评测平台。
FlagEval 评测平台的目标是覆盖三个主要的评估对象——基础模型、预训练算法以及微调/压缩算法, 以及四个关键领域下丰富的下游任务, 包括自然语言处理(NLP)、计算机视觉(CV)、语音(Audio)和多模态(Multimodal)。
没有开源评测代码, 但也公开了所用的数据集
榜单地址: https://flageval.baai.ac.cn/#/trending
2.7.8 code-generation-on-humaneval
榜单地址: https://paperswithcode.com/sota/code-generation-on-humaneval
2.7.9 BIRD-SQL
BIRD(用于LaRge-scale数据库基础文本到 SQL 评估的 BIg Bench)代表了一个开创性的跨领域数据集, 它检查了大量数据库内容对文本到 SQL 解析的影响。BIRD 包含超过 12,751 个独特的问题 SQL 对、95 个大数据库, 总大小为 33.4 GB。它还涵盖了超过37个专业领域, 如区块链、曲棍球、医疗保健和教育等。
榜单地址: BIRD-SQL
3. 测试数据集
- https://huggingface.co/datasets/haonan-li/cmmlu?row=2
- Spider dataset eval
4. 评估
4.1 框架
- defog eval
- HumanEval
- Lighteval
- 带有 training/eval 循环的 Python API: 与 Python API 的简单集成, 轻松将 Lighteval 集成到您的训练循环中
- 速度: 使用 vllm 作为快速评估的后端
- 完整性: 从多个后端中进行选择, 以启动来自几乎任何提供商的模型, 并以光速比较封闭式模型和开源模型。您可以从本地后端(变形金刚,VLLM,TGI 系列)或 API 提供程序(利特尔姆,推理终端节点)
- 无缝存储: 将结果保存在S3或Hugging Face数据集中
- 自定义任务: 轻松添加自定义任务
- 多功能性: 吨指标和任务准备好了
4.2 大海捞针
大海捞针(NIAH)是一种广受欢迎的测试, 用于评估 LLM 如何有效地关注其上下文窗口中的内容。随着 LLM 的改进, NIAH 变得太容易了。Needle in a Needlestack(NIAN)是一种新的、更具挑战性的基准测试。
代码: https://github.com/llmonpy/needle-in-a-needlestack
网址: https://nian.llmonpy.ai/
RULER: 你的长上下文语言模型的实际上下文大小是多少?
RULER相关论文: RULER: What’s the Real Context Size of Your Long-Context Language Models
尽管在普通大海捞针(NIAH)测试中取得了近乎完美的性能, 但随着序列长度的增加, 所有型号(Gemini-1.5-pro除外)在RULER中的任务都表现出很大的退化。
4.3 DataSet
参考
Evaluation of Large Language Model (LLM): Introduction
https://github.com/MLGroupJLU/LLM-eval-survey
《A Survey on Evaluation of Large Language Models》
https://llm-eval.github.io/pages/leaderboard/advprompt.html
Benchmark of LLMs (Part 1): Glue & SuperGLUE, Adversarial NLI, Big Bench
