
目录
Rust 是一门系统编程语言, 是支持函数式、命令式以及泛型等编程范式的多范式语言。Rust 在语法上和 C++类似。 Rust 快速、可靠、安全, 它提供了甚至超过 C/C++的性能和安全保证, 同时它也是一种学习曲线比较平滑的热门编程语言。
Rust 的灵感来自多种语言的知识, 其中值得一提的是 Cyclone(一种安全的 C 语言变体)的基于区域的内存管理技术、 C++的 RAII 原则、 Haskell 的类型系统、异常处理类型和类型类。
- 支持高并发
- 借鉴了 C++的 RAII 原则用于资源初始化
1. Rust 入门
1.1 安装和运行
# install
curl https://sh.rustup.rs -sSf | sh
# curl --proto '=https' --tlsv1.2 https://sh.rustup.rs -sSf | sh
# create、 run、test
cargo new <project_name> [--lib] [--vcs none]
cd <project_name>
cargo run --release -q
cargo check
cargo test
cargo update # 更新依赖关系
# 编译单个文件可以直接使用 rustc
# upgrade
rustup update
rustup self update
rustup show
# switch version
rustup override set nightly
1.2 基本特性
1.2.1 数据类型
- bool
- char
- 数字类型

- [T; N]: 固定大小的数组
- [T]: 动态数组
- str: 字符串切片, 主要用做引用, 即&str。字符串slice range的索引必须位于有效的UTF-8字符边界内, 如果尝试从一个多字节的中间位置创建字符串slice, 则程序将会因错误而退出。
&表示它是指向字符串文本的指针, 而 str 表示不定长类型。你碰到的任何其他&str 类型都是在堆上借用任何拥有String 类型的字符串切片。 &str 类型一旦创建就无法更改, 因为默认情况下它是不可变的。 - String
- chars 方法
- String 为 str 类型实现了类型强制性特征 Deref, 该特征确保了&String 到&str 的转换。
- String 和&str 之间主要的差异在于, &str 自身能够被编译器识别, 而 String 是标准库中的自定义类型。你可以在 Vec
之上实现自定义的类似 String 抽象。
- (T, U, …): 有限序列/元组
- fn(i32) -> i32: 函数
- vector 和 map
1.2.2 关键字
- use: 引入模块
- crate: 绝对导入前缀
- self: 相对导入前缀
- super: 相对导入前缀
- fn: 定义函数
- let 语句不仅是为变量分配值, 也是 Rust 中的模式匹配语句
- return: 函数基本上是返回值的表达式, 默认情况下是()( Unit)类型的值, 这与 C/C++ 中的 void 返回类型相似。
Rust 是一门基于表达式的语言。在源于这种传承的编程语言中, 所有表达式都会返回值, 而且大部分东西都是表达式。这种传承通过一些在其他语言中不合法的结构体现了它能不同之处。在Rust的惯用法中, 函数是会省略return关键字的, 如下面的代码所示:
fn is_even(n: i32) -> bool {
// 注意: 下面的表达式后面没有分号";"
n % 2 == 0
}
fn main() {
let n = 654321;
let desciption = match is_even(n) {
true => "even",
false => "odd",
};
println!("{} is {}", n, desciption);
}
- 闭包:
let my_closure = || {};
两个竖条“ ||”用于存放闭包的参数(如果有的话), 例如|a,b|。 - if: if 构造不是语句, 而是一个表达式, 这意味着 Rust 中的 if else 条件总是会返回一个值
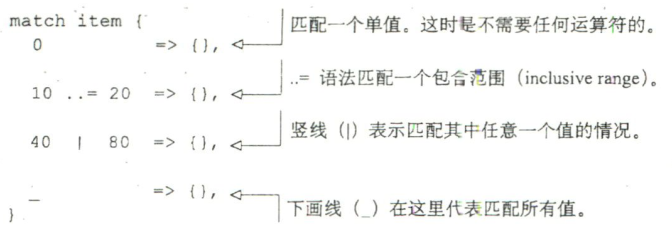
- match: 基本上类似于 C 语言的 switch 语句简化版, 允许用户根据变量的值, 以及是否具有高级过滤功能做出判断
match类似于其他语言中的switch关键字。但与C语言中的switch不同的是,match要保证一个类型的所有可能情况都会显式地得到处理。如果match的各个分支没有覆盖到所有可能的情况, 编译器会报错。另-个不同片是, 一个分支被匹配到以后不会默认地"掉到"(fallthrough)下一个分支中。相反, 如果匹配到一个分支,match就立即返回。
- loop、while 和 for
- for: 只适用于可以转换为迭代器的类型
- loop: 无限循环
- continue 和 break
- struct、enum 及 union
- 自定义类型的命名规则遵循驼峰命名法(CamelCase)。
- union非常类似于 C 语言的联合, 主要用于与 C 语言代码库交互。
- struct: 单元结构体, 元组结构体, 类 C 语言的结构体
- type
- impl 块: 它被视作某个类型提供实现
- mod <mod name>: 模块声明
- pub
- extern
- trait 特征
- dyn: dyn Trait 是一个不定长类型, 只能作为引用创建
- ref: 可以通过引用来匹配元素, 而不是根据值来捕获它们
- const 和 static:
- 读取和写入静态值都必须在某个 unsafe 代码块中完成。
- 静态值通常与同步原语搭配使用, 它们还用于实现全局锁定, 以及与 C 程序库集成。
lazy_static!宏: lazy_static 的第三方软件包实现的。它暴露了 lazy_static!宏, 可用于初始化任何能够从程序中的任何位置全局访问的动态类型。使用 lazy_static!宏声明的元素需要实现 Sync 特征。这意味着如果某个静态值可变, 那么必须使用诸如 Mutex 或 RwLock 这样的多线程类型, 而不是 RefCell。- expr: 匹配任意表达式
- unsafe
1.2.3 特殊符号
- =>
- ‘<name>: 标签或生命周期
- ||
- & 和 *
0..10, 是不包括 10 的, 而0..=10则包含#[<name>]: 适用于每个元素, 通常显示在它们定义的上方#[macro_use]属性:这意味着要使用来自此软件包的任何宏时。类似于 use 语句, 用于公开模块中的元素
#![<name>]: 适用于每个软件包, 通常位于用户软件包根目录的最顶端部分- turbofish 运算符
::<>, 如:str::parse::<u8>("34").unwrap(); - 运算符"?": 与 Result 类型交互时非常常见的另一种模式
它的运行机制如下: 当我们获得一个成功值时, 希望立即提取它;当我们获得一个错误值时, 希望提前返回, 并将错误传播给调用方。它几乎可以作为 try!宏的替代品, 在“?” 之前所做的事情已经由编译器提供相应的实现。 ..: 忽略
1.2.4 常用宏
#[derive(Debug)]: 允许用户在println!()中以{:?}格式输出#[derive(Eq, PartialEq)]#[cfg()]: 条件编译unimplemented!的宏: 有助于让编译器忽略未提供任何具体实现的函数, 并编译我们的代码#[repr(C)]#[macro_export]
1.2.5 工作区
工作区只是一个包含 Cargo.toml 文件的目录。它不包含任何[package]部分, 但是其中有一个[workspace]项。
2. 高级特性
2.1 for 循环
for item in container {
// TODO: this is here
}
有点儿违背直觉的是, 一旦此代码块执行结束, 再访问这个container将是无效的。虽然container变量还在当前局部作用域中, 但是它的生命周期已经结束。如果你在后面的代码中还想再用container, 那么应该使用引用。

2.2 泛型和特征
2.2.1 泛型
泛型编程是一种仅适用于静态类型编程语言的技术。泛型是语言设计特性的一部分, 可以实现代码复用, 并遵循不重复自己的原则( Don’t Repeat Yourself, DRY)。
Rust 允许我们将多种元素声明为泛型, 例如结构体、枚举、函数、特征、方法及代码实现块。它们的一个共同特征是泛型的参数是由一对尖头括号分隔, 并包含于其中。
泛型函数是一种提供多态代码错觉的简易方法。所谓错觉是因为在编译之后, 它们其实是包含具体类型参数的重复代码。
通过泛型实现多态仍然是首选的方案, 因为它没有运行时开销, 和特征对象类似。只有当泛型不能满足需要时, 以及需要在集合中存储一系列类型的情况下, 才会选择特征对象。
当为任何泛型编写 impl 代码块时, 都需要在使用它之前声明泛型参数。
impl<T> Container<T> {
fn new(item: T) -> Self {
Container { item }
}
}
2.2.2 特征
特征是一个元素, 它定义了一组类型可以选择性实现的“契约”或共享行为。特征本身并没有什么用, 并且需要根据类型予以实现。特征有能力在不同类型之间建立关联, 它们是许多语言特性的基础, 例如闭包、运算符、智能指针、循环及编译期数据竞争校验等。Rust 中相当多的高级语言特性要归功于调用某些类型实现的特征方法。
- 在默认情况下, 特征是私有的
- 特征也可以在声明中表明它们依赖于其他特征
特征的多种形式
- 标记特征: 在 std::marker 模块中定义的特征被称为标记特征( marker trait)
- 简单特征: 标准库中的一个示例是 Default 特征, 它主要是针对可以使用默认值初始化的类型实现的
- 泛型特征: 在用户希望为多种类型实现特征的情况下非常有用
// 特征区间 :SomeTrait
pub trait From<T:SomeTrait> {
fn from(T) -> Self;
}
- 关联类型特征: 是泛型特征的更好选择, 因为它们能够在特征中声明相关类型, 关联类型特征的最佳用例之一是 Iterator 特征, 它用于迭代自定义类型的值。
pub trait Add<RHS = Self> {
type Output;
fn add(self, rhs: RHS) -> Self::Output;
}
- 继承特征
- where 语句: 当任何泛型元素的类型签名变得太长而无法在一行上显示时, 可使用此语法。where 语句将特征区间和函数签名解耦, 并使其可读。
- 使用“+”将特征组合为区间
- impl 特征语法: 为我们返回复杂或不方便表示的类型(例如函数的闭包)提供了便利
fn lazy_adder(a:u32, b: u32) -> impl Fn() -> u32 {
move || a + b
}
内置的特征
- Debug: 有助于在控制台上输出类型以便进行调试
- PartialEq 和 Eq: 允许两个元素相互比较以验证是否相等
- Copy 和 Clone: 定义了类型的复制方式
- Copy 特征复制类型的方式与 C 语言中的 memcpy 函数类似
- Clone 特征用于显式复制, 并附带 clone 方法, 类型可以实现该方法以获取自身的副本
- 来自 std::ops 模块的 Add 特征允许我们使用“ +”运算符将两个复数相加
- 来自 std::convert 模块的 Into 和 From 特征使用户能够根据其他类型创建复数类型
- Display 特征使用户能够输出人类可读版本的复数类型
2.2.3 特征对象
特征对象类似 C++中的虚方法。特征对象实现为胖指针, 并且是不定长类型, 这意味着它们只能在引用符号( &)后面使用。
特征对象是 Rust 执行动态分发的方式, 我们没有实际的具体类型信息。通过跳转到vtable 并调用适当的方法完成方法解析。特征对象的另一个用例是, 它们允许用户对可以具有多种类型的集合进行操作, 但是在运行时需要额外的间接指针引用开销。
2.3 生命周期
Rust的安全性检查是基于生命周期系统的, 因为生命周期系统能够验证所有对数据的访问是否有效。生命周期注解让程序员可以声明他们的意图。所有绑定到一个给定的生命周期的值, 必须与最后一次访问绑定到该生命周期的任何值"活"得一样长。
Rust 中的所有引用都附加了生命周期信息。生命周期定义了引用相对值的原始所有者的生存周期, 以及引用作用域的范围。
生命周期纯粹是一个编译期构造, 它可以帮助编译器确定某个引用有效的作用域, 并确保它遵循借用规则。它可以跟踪诸如引用的来源, 以及它们是否比借用值生命周期更长这类事情。 Rust 中的生命周期能够确保引用的存续时间不超过它指向的值。生命周期并不是你作为开发人员将要用到的, 而是编译器使用和推断引用的有效性时会用到的。
关键字 static 修饰的生命周期意味着这些引用在程序运行期间都是有效的。 'static 生命周期修饰符表示字符串在程序存续期间保持不变。
只要在函数或类型定义中存在引用, 就会涉及生命周期。
可以指定生命周期之间的关系, 以确定是否可以在同一位置使用两个引用。我们使用 where 语句在 impl 代码块中指定生命周期之间的关系。
struct Decoder<'a, 'b, S, R> {
schema: &'a S,
reader: &'b R
}
impl<'a, 'b, S, R> Decoder<'a, 'b, S, R>
where 'a: 'b {
// TODO:
}
- 输入型生命周期: 函数参数上的生命周期注释当作引用时被称为输入型生命周期。
- 输出型生命周期: 函数返回值上的生命周期参数当作引用时被称为输出型生命周期。
2.4 所有权
Rust 中的值只有一个所有者, 即创建它们的变量。每当我们将变量分配给某个其他变量或从变量读取数据时, Rust 会默认移动变量指向的值。所有权规则可以防止你通过多个访问点来修改值, 这可能导致访问已被释放的变量, 即使在单线程上下文中, 使用允许多个值的可变别名的语言也是如此。
Rust的所有权规则决定了值何时被删除。在Rust中, 所有权与针对不再需要的值的清理有关。
Rust代码中的移动指的是所有权的移动, 而不是数据的移动。所有权是Rust社区中使用的术语, 指的是编译时的检查过程该过程会检查每次使用的值是否有效, 还会检查所有的值是否都能被彻底清理。
在Rust中, 基本类型是有特殊行为的, 它们实现了: Copy trait。实现了Copy的类型在需要的时候会复制自身, 相反的情况就是如果类型没有实现Copy, 在需要复制的时候就会因为无法复制自身而导致操作非法。正式的说法是, 基本类型具有复制语义(copy semantics), 而对应地, 其他类型就都具有移动语义(move semantics)。
要想为一个类型提供一个自定义的析构器需要实现Drop。通常是在使用了unsafe块来分配内存的情况下才需要这样做°Drop有—个方法drop(&mut se1f), 在这个方法中你可以进行任何必要的清理操作。
- 通过赋值来转移所有权
- 通过函数传递数据, 将其作为参数或返回值
- 在 impl 代码块中, 任何以 self 作为第一个参数的方法都将获取调用该方法的值的所有权。
- 在 match 表达式中, 移动类型默认也会被移动
- 闭包也会出现类似的情况, 要获得副本, 可以在闭包内调用 clone(), 或者在闭包前面放置一个关键字 move
4个常见的策略:
- 不需要完整所有权的地方, 使用引用
- 重构代码, 减少长存活期的值
- 在需要完整所有权的地方, 复制长存活期的值
各种类型在被复制时, 都会采取两种可能的模式中的一种:克隆和复制。隆是由std::clone::Clone定义的, 而复制是由std::marker::Copy定义的。

- 把数据包装到能帮助解决移动问题的类型中
包装器(wrapper)类型, 与默认可用的那些类型相比,这样的类型更具灵活性。但是为了维护Rust的安全性保证, 这些包装器类型会产生一定的运行时开销。std::rc::Rc: Rc提供了T的共享式所有权(shared ownership), Rc 不支持修改, 是不可变的。要想使之支持修改, 我们需要再多包装—层, 如: Rc<RefCell<T>>
2.5 借用(&)
Rust的借用检查器(borrow checker)会检查所有数据访问是否台法。
借用的概念是规避所有权规则的限制。进行借用时, 你不会获取值的所有权, 而是根据需要提供数据。
借用不能销毁该值, 因为它不是所有者
一旦值被可变借用, 我们就不能再对它进行其他借用, 即使是进行不可变借用。
如果 mut 修饰的是变量名, 那么它代表这个变量可以被重新绑定; 如果 mut 修饰的是 “借用指针 & “, 那么它代表的是被指向的对象可以被修改。
借用规则
- 一个引用的生命周期可能不会超过其被引用的时间
- 如果存在一个值的可变借用, 那么不允许其他引用(可变借用或不可变借用)在该作用域下指向相同的值。可变借用是一种独占性借用。
- 如果不存在指向某些东西的可变借用, 那么在该作用域下允许出现对同一值的任意数量的不可变借用。
&mut型借用只能指向本身具有 mut 修饰的变量, 对于只读变量, 不可以有&mut型借用。&mut型借用指针存在的时候, 被借用的变量本身会处于"冻结” 状态。- 如果只有&借用指针, 那么能同时存在多个; 如果存在
&mut型借用指针, 那么只能存在一个; 如果同时有其他的& 或者&mut型借用指针存在, 那么会出现编译错误。
2.6 指针
2.6.1 引用——安全的指针
通过&或者&mut 运算符创建的。该运算符作为类型 T 的前缀时, 会创建一个引用, &T 表示不可变引用, &mut T 表示可变引用。
2.6.2 原始指针
这类指针拥有一个比较奇怪的类型签名, 其前缀为*, 这也恰好是解引用运算符。它们主要用于不安全代码中。人们需要一个不安全的代码块来解引用它们。
*const T: 它是 Copy 类型。这类似于&T, 只是它可以为空值。*mut T: 一个指向 T 的可变原始指针, 它不支持 Copy 特征( non-Copy)。
2.6.3 智能指针
智能指针的大部分特性要归功于两个特征, 它们被称为 Drop 和 Deref(和 DerefMut)。
pub trait Deref {
type Target: ?Sized;
fn deref(&self) -> &Self::Target;
}
Drop特征类似于你在其他语言中遇到的被称为对象析构函数的东西。它包含一个 drop 方法, 当对象超出作用域时就会被调用。该方法将&mut self 作为参数。
为了能够解引用被指向类型的调用方法, 智能指针类型通常会实现 Deref 特征, 这允许用户对这些类型使用解引用运算符*。
标准库中的智能指针有如下几种:
- Box
: 它提供了最简单的堆资源分配方式。 - 可以用于创建递归类型定义
- 当你需要将类型存储为特征对象时
- 当你需要将函数存储在集合中时
- Rc
: 它用于引用计数(单线程环境)。 - Rc 内部会保留两种引用: 强引用( Rc
)和弱引用( Weak )。
- Rc 内部会保留两种引用: 强引用( Rc
- Arc
: 它用于原子引用计数(多线程环境)。 - Cell
: 它为我们提供实现了 Copy 特征的类型的内部可变性。
Cell类型是一种智能指针类型, 可以为值提供可变性, 甚至允许值位于不可引用之后。它以极低的开销提供此功能, 并具有最简洁的 API。 - RefCell
: 它为我们提供了类型的内部可变性, 并且不需要实现 Copy 特征。
如果你需要某个非 Copy 类型支持 Cell 的功能, 那么可以使用 RefCell 类型。它采用了和借用类似的读/写模式, 但是将借用检查移动到了运行时, 这很方便, 但不是零成本的。- 使用 borrow 方法会接收一个新的不可变引用。
- 使用 borrow_mut 方法会接收一个新的可变引用。
- std::borrow::Cow: 是一种智能指针类型, 能够从指针位置读取数据而无须先复制它。提供两种版本的字符串, 它表示在写入的基础上复制( Clone on Write, Cow)。
pub enum Cow<'a, B: ?Sized + 'a>
where
B: ToOwned,
{
/// Borrowed data.
#[stable(feature = "rust1", since = "1.0.0")]
Borrowed(#[stable(feature = "rust1", since = "1.0.0")] &'a B),
/// Owned data.
#[stable(feature = "rust1", since = "1.0.0")]
Owned(#[stable(feature = "rust1", since = "1.0.0")] <B as ToOwned>::Owned),
}
- String
- alloc::raw_vec::RawVec
- core::ptr::Unique
- core::ptr::Shared
2.7 异常
Rust 中的大多数错误处理都是通过 Option 和 Result 这两种通用类型完成的。任何人都可以使用枚举和泛型功能创建类似的错误抽象类型。
2.7.1 Option
pub enum Option<T> {
/// 没有值
None,
/// 包含某些值'T'
Some(T),
}
另一种不太安全的方法是在 Option 上调用解压缩方法, 即 unwrap()和expect()方法。
2.7.2 Result
Result 和 Option 类似, 但具有一些额外的优点, 即能够存储和错误上下文有关的任意异常值, 而不只是 None。当我们希望知道操作失败的原因时, 此类型是合适的。
enum Result<T, E> {
Ok(T),
Err(E),
}
- ok_or: 此方法将 Option 值转换为 Result 值, 同时将错误值作为第 2 个参数进行接收。
- ok: 此方法将 Result 转化为调用 self 的 Option, 并且会丢弃 Err 值。
2.7.3 panic!宏
panic(故障)的机制, 它会终止调用它的线程, 而不会影响任何其他线程。
当 panic!宏被调用时, 发生灾难性故障的线程开始展开函数调用堆栈, 从调用它的位置开始, 一直到线程的入口点。
设置环境变量 RUST_BACKTRACE=1 来查看线程中的回溯。
如果你需要更精细地控制如何在线程中处理灾难性故障后的堆栈展开, 那么可以使用std::panic::catch_unwind 函数。catch_unwind 不是 Rust 中处理错误的推荐方案。它不能确保捕获所有灾难性故障。
2.7.4 自定义错误和 Error 特征
Rust 没有类型层级继承, 但它具有特征继承, 并为我们提供了任何类型都可以实现的 Error 特征, 从而构造自定义错误类型。当使用诸如 Box<dyn Error>这样的特征对象作为 Err 变量函数返回类型返回 Result 时, 此类型可以与现有的标准库错误类型组合。
pub trait Error: Debug + Display {
fn description(&self) -> &str { ... }
fn cause(&self) -> Option<&dyn Error> { ... }
}
2.8 迭代器
- iter()通过引用获取元素
- iter_mut()用于获取元素的可变引用
- into_iter()用于获取值的所有权, 并在完全迭代后使用实际类型, 原始集合将无法再访问
3. 并发
如果我们想在多线程环境中共享相同类型的所有权, 那么可以使用 Arc 类型, 它和 Rc 类型类似, 但是具有原子引用计数功能。
标准库中的 std::sync 模块包含 Mutex 类型, 允许用户以线程安全的方式改变线程中的数据。Mutex 类型不提供共享可变性。为了允许 Mutex 类型中的值支持在多线程环境下被修改, 我们需要将它包装成 Arc 类型。
互斥锁适用于大多数应用场景, 但对于某些多线程环境, 读取的发生频率高于写入的。在这种情况下, 我们可以采用 RwLock 类型, 它提供共享可变性, 但可以在更细粒度上执行操作。
标准库中的 std::sync::mpsc 模块提供了一个无锁定的多生产者、单订阅者(消费者)队列, 以此作为希望彼此通信的线程的共享消息队列。 mpsc 模块标准库包含两种通道。
- channel: 这是一个异步的无限缓冲通道。
- sync_channel: 这是一个同步的有界缓冲通道。
Rust 仅保护用户不会受到数据竞争问题的困扰。它的目标不是防止死锁, 因为死锁很难被发现。它将借助第三方软件包来解决这个问题, 例如 parking_lot 程序库。
3.1 Send
Send 是一种标记性特征。它只用于类型级标记, 意味着可以安全地跨线程发送值;并且大多数类型都是发送型。未实现 Send 特征的类型是指针、引用等。此外, Send 是自动型特征或自动派生的特征。复合型数据类型, 例如结构体, 如果其中的所有字段都是 Send型, 那么该结构体实现了 Send 特征。
pub unsafe auto trait Send { }
3.2 Sync
Sync 特征具有类似的类型签名:
pub unsafe auto trait Sync { }
这表示实现此特征的类型可以安全地在线程之间共享。如果某些类型是 Sync 类型, 那么指向它的引用, 换句话说相关的&T 是 Send 类型。这意味着我们可以将对它的引用传递给多线程。
3.3 actor 模型
在 Rust 编译器中, 我们实现了 actor 模型的 actix 程序库。 该程序库的核心对象是 Arbiter 类型, 它只是一个简单的在底层生成事件循环的线程, 并且提供 Addr 类型作为该事件循环的句柄。一旦创建该类型, 我们就可以使用这个句柄向 actor 发送消息。
4. 宏与元编程
元编程是改变你查看程序中指令和数据方式的一种技术。它允许你像处理任何其他数据那样通过指令生成新的代码。许多语言都支持元编程, 例如 Lisp 的宏、 C 的#define 构造及 Python 的元类。
Rust 知道宏中引用的变量的作用域, 并且不会隐藏已经在外部声明的任何标识符。
4.1 宏的应用场景
一般的经验法则是, 宏可以在函数无法提供所需解决方案的情况下使用, 其中的代码具有相当的重复性, 或者在需要检查类型结构体并在编译期生成代码的情况下使用宏。
- 通过创建自定义领域特定语言( Domain-Specific Language, DSL) 来扩展语言语法。
- 编写编译期序列化代码, 就像 serde 那样。
- 将计算操作移动到编译期, 从而减少运行时开销。
- 编写样板测试代码和自动化测试用例。
- 提供零成本日志记录抽象, 例如 log 软件包
4.2 宏的类型
macro_rules!宏可以在项目的任何位置定义, 而过程宏需要通过将 Cargo.toml 文件中的属性设置为 proc-macro=true 来生成独立的软件包。
4.2.1 声明式宏
用 macro_rules!宏创建的, 其本身就是一个宏。
- expr: 匹配任意表达式
- ident: 匹配一个标识符
- item: 匹配元素, 模块级的内容可以被当作元素
- meta: 表示一个元项目。属性内的参数被称为元项, 由元捕获
- #![foo]
- #[baz]
- #[foo(bar)]
- #[foo(bar=“baz”)]
- pat: 这是一种模式。每个 match 表达式中的左侧都是模式, 它们由 pat 捕获
- path: 匹配限定名称。路径是限定名称, 即附加了命名空间的名称。它们与标识符非常相似, 只是它们在名称中允许使用双冒号, 因为这表示路径。
- stmt: 这表示一条语句
- tt: 这是一个标记树, 它由一系列其他标记构成
- ty: 这表示一个 Rust 类型
- vis: 这表示可见性修饰符, 它会捕获可见性修饰符 pub、 pub(crate)等
- lifetime: 表示生命周期, 例如’a、 ‘ctx、 ‘foo 等
- literal: 可以是任何标记的文字, 如字符串文字(例如"foo”)或标识符(例如 bar)
- $()*, 为了引用它们, 我们称它们为重复器
4.2.2 过程宏
过程宏是宏的一种更高级形式, 可以完全控制代码的操作和生成。这些宏没有任何 DSL 支持, 并在某种意义上是程序性的, 你必须为给定的标记树输入编写如何生成或转换代码的指令。
过程宏实现为函数, 这些函数接收宏输入作为标记流( TokenStream)类型, 并在编译时进行相关转换后, 将生成的代码作为标记流返回。要将函数标记为过程宏, 我们需要使用#[proc_macro]属性对其进行注释。
- 类函数过程宏: 它们在函数上使用#[proc_macro]属性
- 类过程宏: 它们在函数上使用#[proc_macro_attribute]属性
- 派生过程宏: 它们使用#[proc_macro_derive]属性
常用的过程宏软件包:
- derive-new: 该软件包为结构体提供了默认的全字段构造函数, 并且支持自定义
- derive-more: 该软件包可以绕过这样的限制, 即我们已经为类型包装了许多自动实现的特征, 但是失去了为其创建自定义类型包装的能力
- lazy_static: 该软件包提供了一个类函数的过程宏, 其名为 lazy_static!, 你可以在其中声明需要动态初始化类型的静态值
4.2.3 内置宏
- dbg!: 允许你使用它们的值输出表达式的值
- compile_error!: 可用于在编译期从代码中报告错误
- concat!: 可以用来链接传递给它的任意数量的文字, 并将链接的文字作为
&'static str返回 - env! or option_env!: 用于检查编译期的环境变量
- eprint!和 eprintln!: 与 println!类似, 不过会将消息输出到标准异常流
- include_bytes!: 可以作为一种将文件读取为字节数组的快捷方式, 例如
&'static [u8; N] - stringify!: 希望获得类型或标记作为字符串的字面转换, 那么此宏将会非常有用
5. 工具包
5.1 网络
Rust 在标准库中为我们提供了 net 模块。这包含传输层的上述网络单元。对于 TCP 通信, 我们有 TcpStream 和 TcpListener 类型。对于 UDP 通信, 我们有 UdpSocket 类型。 net模块还提供了用于正确表示 v4 和 v6 版本 IP 地址的数据类型。
当处理非阻塞套接字和底层套接字轮询机制时, 它为开发人员简化了大多数复杂状态机的处理。可供用户选择的两个底层抽象软件包是 futures 和 mio。
在 Linux 下出现了 epoll, 它是当前最高效的文件描述符多路复用 API。大多数想要进行异步 I/O 的网络和应用程序都会采用它。其他平台也有类似的抽象, 例如 macOS 和 BSD 中的 kqueue。在 Windows 下, 我们有 IO 完成端口( IO Completion Port, IOCP)。
5.1.1 mio
mio 是一款底层软件包, 它提供了一种为 socket 事件设置反应器的便捷方法。它的网络原语和标准库类型相似, 例如 TcpStream 类型, 不过默认情况下它是非阻塞的。
5.1.2 futures 与 tokio
mio 杂耍式的套接字轮询状态机用起来并不是很方便。为了提供可供应用程序开发人员使用的高级 API, 我们有 futures 软件包。它提供了一个名为 Future 的特征, 这是该软件包的核心组成部分。 future 表示一种不能立即有效的算法思路, 但可能在后续生效。
pub trait Future {
type Item;
type Error;
fn poll(&mut self) -> Poll<Self::Item, Self::Error>;
}
tokio 软件包在技术上是一种运行时, 由一个线程池、事件循环, 基于 mio 的 I/O 事件的反应器组成。
5.1.3 hyper(HTTP 通信)
hyper 将客户端和服务器端功能拆分为单独的模块。 客户端允许你使用可配置的请求主体、首部及其他底层配置来构建和发送 HTTP 请求。服务器端允许你打开侦听套接字, 并将请求处理程序附加给它。
5.1.4 Web框架
- Rocket
- actix-web
- Gotham
- Tower
- Tide
- Warp
- Axum
5.2 日志类
- log
- env_logger
- imple_logger
- log4rs
- fern
5.3 数据库
- rusqlite: 集成 SQLite
- r2d2: 数据库连接池
利用特征提供了维护各种数据库连接池的通用方法。它包含处理多种后端的子软件包, 并支持 PostgreSQL、 Redis、 MySQL、 MongoDB、 SQLite, 以及一些其他已知的数据库系统。 - diesel 软件包: 对象关系映射器
Rust 的 ORM(对象关系映射器)和查询构建器。它采用了大量过程宏, 会在编译期检测大多数数据库交互错误, 并在大多数情况下能够生成非常高效的代码, 有时甚至可以用 C 语言进行底层访问。
cargo install diesel_cli --no-default-features --features postgres
.env 文件中, 它包含如下内容:
DATABASE_URL=postgres://postgres:postgres@localhost/linksnap
diesel setup
diesel migration generate linksnap
diesel migration run
5.4 Python 插件开发
5.4.1 rust-cpython
配置Cargo.toml
[lib]
name = "rust2py"
crate-type = ["cdylib"]
[dependencies.cpython]
version = "0.7"
features = ["extension-module"]
开发lib.rs
use cpython::{Python, PyResult, PyObject, py_module_initializer, py_fn};
py_module_initializer!(hello, |py, m| {
m.add(py, "__doc__", "Module documentation string")?;
m.add(py, "run", py_fn!(py, run()))?;
Ok(())
});
fn run(py: Python) -> PyResult<PyObject> {
println!("Rust says: Hello Python!");
Ok(py.None())
}
在苹果电脑上, 需要重命名文件 *.dylib 到 *.so, 在Window电脑上则需要重命名文件 *.dll 到 *.pyd.
5.4.2 Pyo3
PyO3 主要用于创建原生 Python 的扩展模块。PyO3 还支持从 Rust 二进制文件运行 Python 代码并与之交互, 可以实现 rust 与 Python 代码共存。在一些对性能要求较高的模块上, 可以考虑使用 PyO3 构建对应的功能模块。PyO3 的功能分离, 不用过多担心模块之间的耦合性, 并且在速度上能有一定的提升。
5.4.3 Pyo3 和 Rust-cpython 的不同
- Pyo3 基于 Rust 宏和 specialization 实现。 Rust-cpython 基于 Macro Dsl 来申明模块和类
- Rust-cpython 一般 own python 的对象。而 Pyo3 允许 borrow 对象, 大部分都是采用应用方式
- 异常处理方式的不同
6. 测试
6.1 单元测试
一个单元测试就是一个函数, 它实例化应用程序的一小部分, 并独立于代码库的其他部分验证其行为。在 Rust 中, 单元测试通常是在模块中编写的。
rustc --test file_name.rs
6.2 集成测试
Rust 希望所有集成测试都在 tests/目录下进行。
6.3 基准测试
Rust 内置的基准测试框架不稳定, 幸运的是, 社区开发的基准测试软件包能够兼容稳定版的 Rust。这里我们将介绍的一款当前非常流行的软件包是 criterion-rs。
- 添加了一个名为
[[bench]]的新属性
[[bench]]
name = "fibonacci"
harness = false
- 将基准测试代码放到
benches/目录下
参考:
在 Rust 里面调用 Python
Writing Python inside your Rust code — Part 1
Rust 源码阅读俱乐部 | 第一期 : 名称解析
