
目录
在并发场景下, 为了保证并发安全, 我们常常要通过互斥(加锁)手段来保证数据同步安全。
分布式锁和我们平常讲到的锁原理基本一样, 目的就是确保在多个线程并发时, 只有一个线程在同一刻操作这个业务或者说方法、变量。
比如酒店的房间门锁, 当你入住的时候, 你需要先申请锁(的钥匙), 如果锁(的钥匙)已经被其他人拿走, 那么你将不能使用该房间资源; 如果你申请到锁(的钥匙)进入房间, 那么再有别人想申请进入则不被允许; 当你释放锁(的钥匙, 即办理退房)的时候, 则其他人可以再次申请锁。
那么分布式锁, 则在此基础上鉴于分布式系统而实现的在系统间进行互斥访问共享资源的一种方式。
1. 分布式相关的一些理论
1.1 CAP 定律
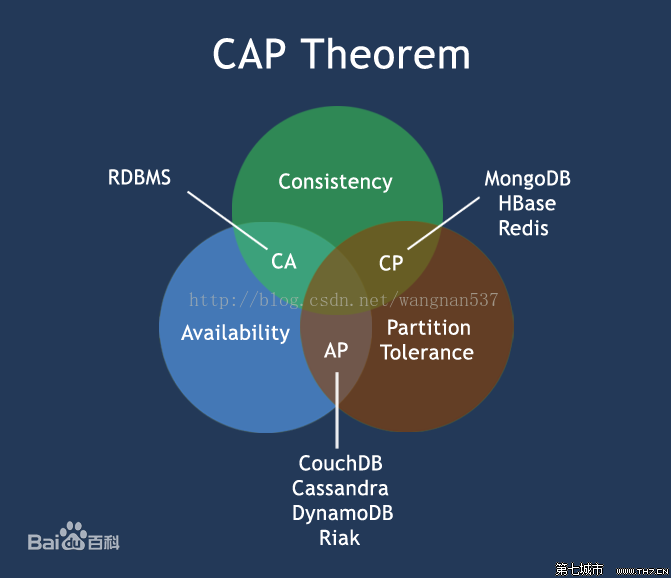
在理论计算机科学中, CAP定理(CAP theorem), 又被称作布鲁尔定理(Brewer’s theorem), 它指出对于一个分布式计算系统来说, 不可能同时满足以下三点:
- 一致性(Consistency) (等同于所有节点访问同一份最新的数据副本)
- 可用性(Availability)(每次请求都能获取到非错的响应——但是不保证获取的数据为最新数据)
- 分区容错性(Partition tolerance)(以实际效果而言, 分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性, 就意味着发生了分区的情况, 必须就当前操作在C和A之间做出选择。)
根据定理, 分布式系统只能满足三项中的两项而不可能满足全部三项。理解CAP理论的最简单方式是想象两个节点分处分区两侧。允许至少一个节点更新状态会导致数据不一致, 即丧失了C性质。如果为了保证数据一致性, 将分区一侧的节点设置为不可用, 那么又丧失了A性质。除非两个节点可以互相通信, 才能既保证C又保证A, 这又会导致丧失P性质。
这个定理起源于加州大学柏克莱分校(University of California, Berkeley)的计算机科学家埃里克·布鲁尔在2000年的分布式计算原理研讨会(PODC)上提出的一个猜想。在2002年, 麻省理工学院(MIT)的赛斯·吉尔伯特和南希·林奇发表了布鲁尔猜想的证明, 使之成为一个定理。
吉尔伯特和林奇证明的CAP定理比布鲁尔设想的某种程度上更加狭义。定理讨论了在两个互相矛盾的请求到达彼此连接不通的两个不同的分布式节点的时候的处理方案。
由于分区容错性是分布式系统必然需要面对和解决的问题, 因此 CAP 又分化为:
- CP, 如XA的两阶段提交, Seata AT的"读已提交"
- AP: 如TCC, 基于消息的最终一致性, Saga等
CAP 原理最初的提出者埃里克·布鲁尔在 CAP 猜想提出 12 年之际(2012年)对该原理重新进行了阐述问, 明确了 CAP 原理只适用于原子读写的场景, 而不支持数据库事务之类的场景。同时指出, 只有极少数网络分区在非常罕见的场景下, 三者才有可能做到有机的结合 。无独有偶, Lynch 也重写了论文"Perspectives on the CAP Theorem", 引入了活性(liveness)和安全属性(safety), 并认为 CAP 是活性与安全性之间权衡的一个特例。CAP 中的C(一致性)属于活性, A(可用性)属于安全性。
1.2 BASE 理论
BASE理论是由eBay架构师提出的。BASE是对CAP中一致性和可用性权衡的结果, 其来源于对大规模互联网分布式系统实践的总结, 是基于CAP定律逐步演化而来。其核心思想是即使无法做到强一致性(Strong consistency), 但每个应用都可以根据自身的业务特点, 采用适当的方式来使系统达到最终一致性(Eventual consistency)。
BASE理论是Basically Available(基本可用), Soft State(软状态)和Eventually Consistent(最终一致性)三个短语的缩写, 与ACID相对应.
1.2.1 基本可用
什么是基本可用呢? 假设系统, 出现了不可预知的故障, 但还是能用, 相比较正常的系统而言:
- 响应时间上的损失: 正常情况下的搜索引擎0.5秒即返回给用户结果, 而基本可用的搜索引擎可以在2秒作用返回结果。
- 功能上的损失: 在一个电商网站上, 正常情况下, 用户可以顺利完成每一笔订单。但是到了大促期间, 为了保护购物系统的稳定性, 部分消费者可能会被引导到一个降级页面。
1.2.2 软状态
什么是软状态呢? 相对于原子性而言, 要求多个节点的数据副本都是一致的, 这是一种“硬状态”。
软状态指的是: 允许系统中的数据存在中间状态, 并认为该状态不影响系统的整体可用性, 即允许系统在多个不同节点的数据副本存在数据延时。
1.2.3 最终一致性
上面说软状态, 然后不可能一直是软状态, 必须有个时间期限。在期限过后, 应当保证所有副本保持数据一致性, 从而达到数据的最终一致性。这个时间期限取决于网络延时、系统负载、数据复制方案设计等等因素。
而在实际工程实践中, 最终一致性分为5种:
- 因果一致性(Causal consistency): 如果节点A在更新完某个数据后通知了节点B, 那么节点B之后对该数据的访问和修改都是基于A更新后的值。于此同时, 和节点A无因果关系的节点C的数据访问则没有这样的限制。
- 读己之所写(Read your writes): 节点A更新一个数据后, 它自身总是能访问到自身更新过的最新值, 而不会看到旧值。其实也算一种因果一致性。
- 会话一致性(Session consistency): 将对系统数据的访问过程框定在了一个会话当中: 系统能保证在同一个有效的会话中实现 “读己之所写” 的一致性, 也就是说, 执行更新操作之后, 客户端能够在同一个会话中始终读取到该数据项的最新值。
- 单调读一致性(Monotonic read consistency): 如果一个节点从系统中读取出一个数据项的某个值后, 那么系统对于该节点后续的任何数据访问都不应该返回更旧的值。
- 单调写一致性(Monotonic write consistency): 一个系统要能够保证来自同一个节点的写操作被顺序的执行。
在实际的实践中, 这5种系统往往会结合使用, 以构建一个具有最终一致性的分布式系统。
实际上, 不只是分布式系统使用最终一致性, 关系型数据库在某个功能上, 也是使用最终一致性的。比如备份, 数据库的复制过程是需要时间的, 这个复制过程中, 业务读取到的值就是旧的。当然, 最终还是达成了数据一致性。这也算是一个最终一致性的经典案例。
1.3 一致性协议/共识算法
1.3.1 Paxos 协议
Paxos算法是莱斯利·兰伯特(英语: Leslie Lamport, LaTeX中的“La”)于1990年提出的一种基于消息传递且具有高度容错特性的共识(consensus)算法。需要注意的是, Paxos常被误称为“一致性算法”。但是“一致性(consistency)”和“共识(consensus)”并不是同一个概念。Paxos是一个共识(consensus)算法。
Google 在其分布式锁服务中应用了Multi-Paxos算法。Chubby lock应用于大表(Bigtable), 后者在谷歌公司所提供的各项服务中得到了广泛的应用。
具体参考: Paxos算法
1.3.2 zab 协议
Zab 一个类Multi-Paxos的共识算法作为底层存储协同的机制。
Zab协议 的全称是 Zookeeper Atomic Broadcast (Zookeeper原子广播)。Zookeeper 是通过 Zab 协议来保证分布式事务的最终一致性。
- Zab协议是为 Zookeeper 专门设计的一种支持崩溃恢复的原子广播协议, 是Zookeeper保证数据一致性的核心算法。Zab借鉴了Paxos算法, 但又不像Paxos那样, 是一种通用的分布式一致性算法。它是特别为Zookeeper设计的支持崩溃恢复的原子广播协议。
- 在Zookeeper中主要依赖Zab协议来实现数据一致性, 基于该协议, zk实现了一种主备模型(即Leader和Follower模型)的系统架构来保证集群中各个副本之间数据的一致性。这里的主备系统架构模型, 就是指只有一台客户端(Leader)负责处理外部的写事务请求, 然后Leader客户端将数据同步到其他Follower节点。
1.3.3 Raft 协议
Raft是一种用于替代Paxos的共识算法。相比于Paxos, Raft的目标是提供更清晰的逻辑分工使得算法本身能被更好地理解, 同时它安全性更高, 并能提供一些额外的特性。Raft能为在计算机集群之间部署有限状态机提供一种通用方法, 并确保集群内的任意节点在某种状态转换上保持一致。Raft算法的开源实现众多, 在Go、C++、Java以及 Scala中都有完整的代码实现。Raft这一名字来源于"Reliable, Replicated, Redundant, And Fault-Tolerant"(“可靠、可复制、可冗余、可容错”)的首字母缩写。
1.4 复制状态机
复制状态机用于支持那些允许数据修改的场景, 比如分布式系统中的元数据。典型的例子是一个目录下的那些文件, 虽然文件本身可以做到一次写入永不修改, 但是目录的内容总是随文件的不断写入而发生动态变化的。
复制状态机由莱斯利·兰伯特在他那篇著名的"Time, Clocks, and the Ordering of Events in a Distributed System"(1978)论文中首次提出, 而比较系统的阐述则是在 Fred Schneider 的论文"Implementing fault-tolerant services using the state machine approach" (1990)中。它的基本思想是一个分布式的复制状态机系统由多个复制单元组成, 每个复制单元均是一个状态机, 它的状态保存在一组状态变量中。状态机的状态能够并且只能通过外部命令来改变。
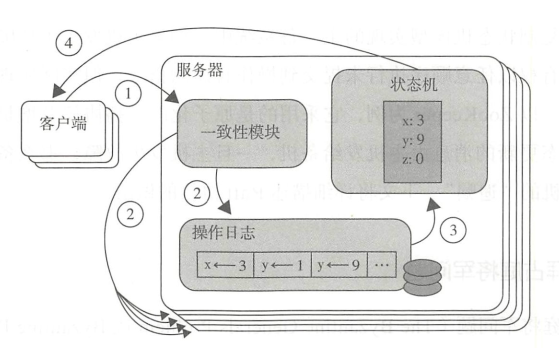
“一组状态变量” 通常是基于操作日志来实现的。每一个复制单元存储一个包含一系列指令的日志, 并且严格按照顺序逐条执行日志上的指令。因为每个状态机都是确定的, 所以每个外部命令都将产生相同的操作序列(日志)。又因为每一个日志都是按照相同的顺序包含相同的指令, 所以每一个服务器都将执行相同的指令序列, 并且最终到达相同的状态 。
注意: 指令在状态机上的执行顺序并不一定等同于指令的发出顺序或接收顺序
基于复制状态机模型实现的主-备系统中, 如果主机发生了故障, 那么理论上备机有权以任意顺序执行未提交到操作日志的指令。但实际实现中一般不会这么做。
1.5 FLP 不可能性定理
FLP 不可能性(FLP Impossibility, F、L、P 三个字母分别代表三个作者Fischer, Lynch and Patterson名字的首字母)是分布式领域中一个非常著名的定理(该定理的论文是由三位作者于1985年发表):
No completely asynchronous consensus protocol can tolerate even a single unannounced process death.
在异步通信场景下, 任何一致性协议都不能保证, 即使只有一个进程失败, 其他非失败进程也不能达成一致。
FLP 定理实际上说明了在允许节点失效的场景下, 基于异步通信方式的分布式协议, 无法确保在有限的时间内达成一致性。换句话说, 结合 CAP 理论和上文提到的一致式算法正确性衡量标准, 一个正确的一致性算法, 能够在异步通信模型下(P)同时保证一致性(C)和可终止性(A)一一这显然是做不到的!
因为同步通信中的一致性被证明是可以达到的, 因此在之前一直有人尝试各种算法解决以异步环境的一致性问题, 有个FLP的结果, 这样的尝试终于有了答案。
1.6 MVCC
多版本并发控制(Multiversion concurrency control, MCC或MVCC), 是数据库管理系统常用的一种并发控制, 也用于程序设计语言实现事务内存。
MVCC意图解决读写锁造成的多个、长时间的读操作饿死写操作问题。每个事务读到的数据项都是一个历史快照, 并依赖于实现的隔离级别。写操作不覆盖已有数据项, 而是创建一个新的版本, 直至所在操作提交时才变为可见。快照隔离使得事务看到它启动时的数据状态。
在关系数据库管理系统中, 悲观并发控制(又名“悲观锁”, Pessimistic Concurrency Control, .PCC )是一种并发控制的方法。它可以阻止一个事务以影响其他用户的方式来修改数据。如果一个事务执行的操作对某行数据应用了锁, 那么只有在这个事务将锁释放之后, 其他事务才能够执行与该锁冲突的操作。悲观并发控制主要用于数据争用激烈的环境, 以及发生并发冲突时使用锁保护数据的成本要低于回滚事务的成本的环境中。
乐观并发控制(又名“乐观锁”)也是一种并发控制的方法。它假设多用户并发的事务在处理时彼此之间不会互相影响, 各事务能够在不产生锁的情况下处理各自影响的那部分数据。在提交数据更新之前, 每个事务都会先检查在该事务读取数据之后, 有没有其他事务又修改了该数据。如果其他事务有更新的话, 那么正在提交的事务会进行回滚。
多版本并发控制并不是一个与乐观并发控制和悲观并发控制对立的概念, 它能够与两者很好地结合以增加事务的并发量, 目前最流行的 SQL 数据库 MySQL 和 PostgreSQL 都对 MVCC进行了实现。
在 MVCC 中, 每当想要更改或者删除某个数据对象时, DBMS 不会在原地删除或修改这个已有的数据对象本身, 而是针对该数据对象创建一个新的版本, 这样一来, 并发的读取操作仍然可以读取老版本的数据, 而写操作就可以同时进行。这个模式的好处在于, 可以让读取操作不再阻塞, 事实上根本就不需要锁。
2. 锁的概念
2.1 同步与异步、并发与并行
2.1.1 同步与异步
主要是对任务的发起方式的描述, 和I/O紧密相关。
- 同步(synchronous): 就是按时间顺序, 串行化地执行任务, 每一个时间点都只有一个任务在被执行。类似于电路中的串行。
- 异步(asynchronous): 就是按照时间顺序, 多个任务可以被分成多个分支去执行, 在同一个时间点, 可以有多个任务在同时被执行。类似于电路中的并行。
2.1.2 并发与并行
主要是对任务的处理方式的描述, 涉及到处理器(CPU)。对于单个CPU内核来说, 它在一个时间点只能处理一个任务。
- 并行意味着程序在任意时刻都是同时运行的
- 并发意味着程序在单位时间内是同时运行的
并发(concurrency): 在操作系统中, 是指一个时间段中有几个程序都处于已启动运行到运行完毕之间, 且这几个程序都是在同一个CPU内核上运行, 强调的是给外界的感觉, 实际上内部可能是分时操作的。并发重在避免阻塞, 使程序不会因为一个阻塞而停止处理。并发典型的应用场景: 分时操作系统就是一种并发设计(忽略多核 CPU)。
并行(parallellism): 当系统有一个以上CPU或者一个CPU中有多个内核时, 当执行一个任务时, 另一个进程也可以在其他CPU上执行, 或者在其他CPU的其他内核上面执行, 两个任务互不抢占CPU资源, 可以同时进行, 这种方式我们称之为并行, 就是在任一粒度的时间内都具备同时执行的能力: 最简单的并行就是多机, 多台机器并行处理; SMP 表面上看是并行的, 但由于是共享内存, 以及线程间的同步等, 不可能完全做到并行。
并行只是提升性能的方法之一, 这是非常重要的。其他熟知的方案, 按实现难度递增的顺序罗列如下:
-
- 运行多个串行应用实例
-
- 利用现有的并行软件构建应用
-
- 对串行应用进行性能优化
并行访问控制问题是如何协调访问资源。这种协调是由几种并行语言和环境提供的多种同步机制来处理的, 这些机制包括消息传递, 加锁, 事务, 引用计数, 显式计时, 共享原子变量, 以及数据所有权。需要传统的并行编程关注由此引出的死锁, 活锁, 和事务回滚。
2.2 什么是锁
在单进程的系统中, 当存在多个线程可以同时改变某个变量(可变共享变量)时, 就需要对变量或代码块做同步, 使其在修改这种变量时能够线性执行消除并发修改变量。
而同步的本质是通过锁来实现的。为了实现多个线程在一个时刻同一个代码块只能有一个线程可执行, 那么需要在某个地方做个标记, 这个标记必须每个线程都能看到, 当标记不存在时可以设置该标记, 其余后续线程发现已经有标记了则等待拥有标记的线程结束同步代码块取消标记后再去尝试设置标记。这个标记可以理解为锁。
不同地方实现锁的方式也不一样, 只要能满足所有线程都能看得到标记即可。
除了利用内存数据做锁其实任何互斥的都能做锁(只考虑互斥情况), 如流水表中流水号与时间结合做幂等校验可以看作是一个不会释放的锁, 或者使用某个文件是否存在作为锁等。只需要满足在对标记进行修改能保证原子性和内存可见性即可。
2.3 分布式锁
分布式锁其实就是, 控制分布式系统不同进程共同访问共享资源的一种锁的实现。如果不同的系统或同一个系统的不同主机之间共享了某个临界资源, 往往需要互斥来防止彼此干扰, 以保证一致性。在 Nancy A.Lynch 的《分布式算法》书里, 使用了互斥(mutual exclusion), 即对单个不可分资源的访问进行管理的问题, 该资源每次只能支持一个用户。另外, 互斥也被视为这样一个问题: 程序代码的特定部分在临界区中运行, 在同一时刻不允许有两个程序在临界区中运行。
分布式锁大多数是 Advisory Lock, 即在访问数据前先获取锁信息, 再根据信息决定是否可以访问。相对的是 Mandatory Lock, 未授权访问锁定的数据时产生异常。
2.3.1 分布式场景
在分布式许多的场景中, 我们为了保证数据的最终一致性, 需要很多的技术方案来支持, 比如分布式事务、分布式锁等。很多时候我们需要保证一个方法在同一时间内只能被同一个线程执行。在单机环境中, 我们可以通过普通的锁解决, 但是在分布式环境下, 就没有那么简单啦。
分布式与单机情况下最大的不同在于其不是多线程而是多进程。多线程由于可以共享堆内存, 因此可以简单的采取内存作为标记存储位置。而进程之间甚至可能都不在同一台物理机上, 因此需要将标记存储在一个所有进程都能看到的地方。
2.3.2 分布式锁三个必备的性质
- 互斥性: 在任意时刻只有一个客户端可以获取锁
- 防死锁: 假如一个客户端在持有锁的时候崩溃了, 没有释放锁, 那么别的客户端无法获得锁, 则会造成死锁, 所以要保证客户端一定会释放锁。Redis中我们可以设置锁的过期时间来保证不会发生死锁
- 容错: 为了避免单点故障, 锁服务需要有一定的容错性
- 锁本身是一个集群, 能够自动故障切换, 如zookeeper, etcd
- 客户端向多个独立的锁服务发起请求
还有其他特性:
- 高可用: 高可用的获取锁与释放锁, 具备锁失效机制, 防止死锁
- 高性能: 高性能的获取锁与释放锁
- 可重入性: 当一个客户端获取对象锁之后, 这个客户端可以再次获取这个对象上的锁
- 持锁人解锁: 解铃还须系铃人, 加锁和解锁必须是同一个客户端, 客户端A的线程加的锁必须是客户端A的线程来解锁, 客户端不能解开别的客户端的锁。
这些不是非必须满足。如高可用和高性能本身就是互斥的, 在实现高可用的同时或多或少会对性能产生一定的影响, 再比如要不要实现锁的可重入性和阻塞性是根据实际业务来确定的, 所以分布式锁的设计还需灵活配置。
3. 分布式锁的实现
- 基于数据库(乐观锁、悲观锁)
- 基于分布式缓存(如: redis、memcahce)
- 基于一致性协调器(如: ZooKeeper、etcd、Consul等)
3.1 基于数据库实现分布式锁
- 适用场景: 一般适用于资源不存在数据库, 否则使用for update行锁或条件乐观锁(version)判断就可以满足基本的锁需求。
- 优点和缺点:
- 操作简单, 容易理解, 可以自定义时间戳, 重入次数等
- 性能开销大, 对于高并发, 高性能的系统难以容忍。没有失效时间需要考虑锁超时情况。单点需要考虑主从备份等。
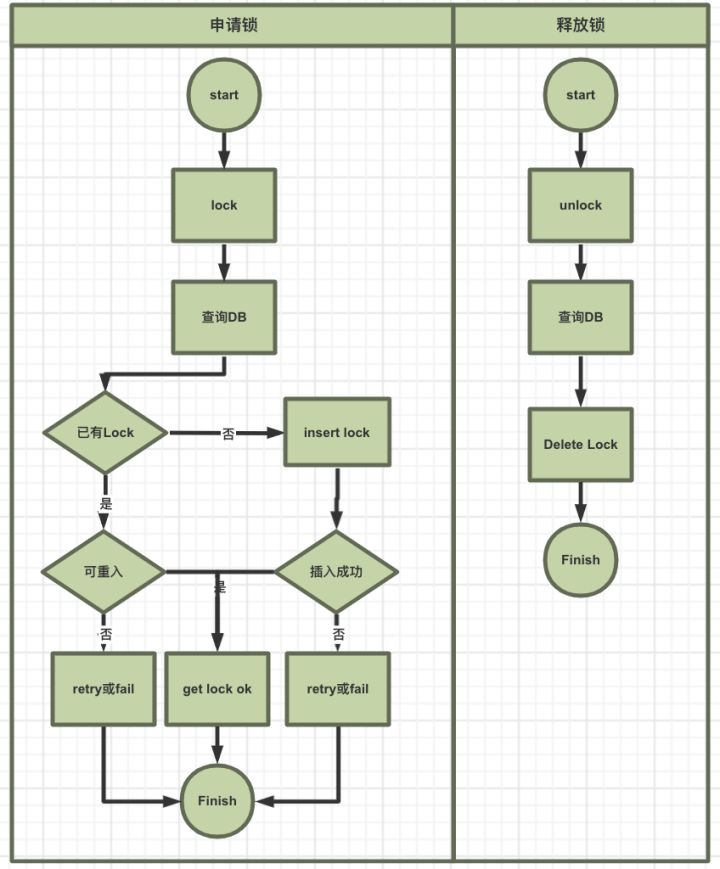
3.1.1 基于mysql实现
- 创建lock表(id, resource, node, count,create_time,update_time); insert/delete方式
- 加锁, 解锁如下:
3.2 基于分布式缓存
优点: 非阻塞, 天然分布式, 高性能
缺点: 需要良好的分布式逻辑, 否则容易造成死锁; 并且成本较高。
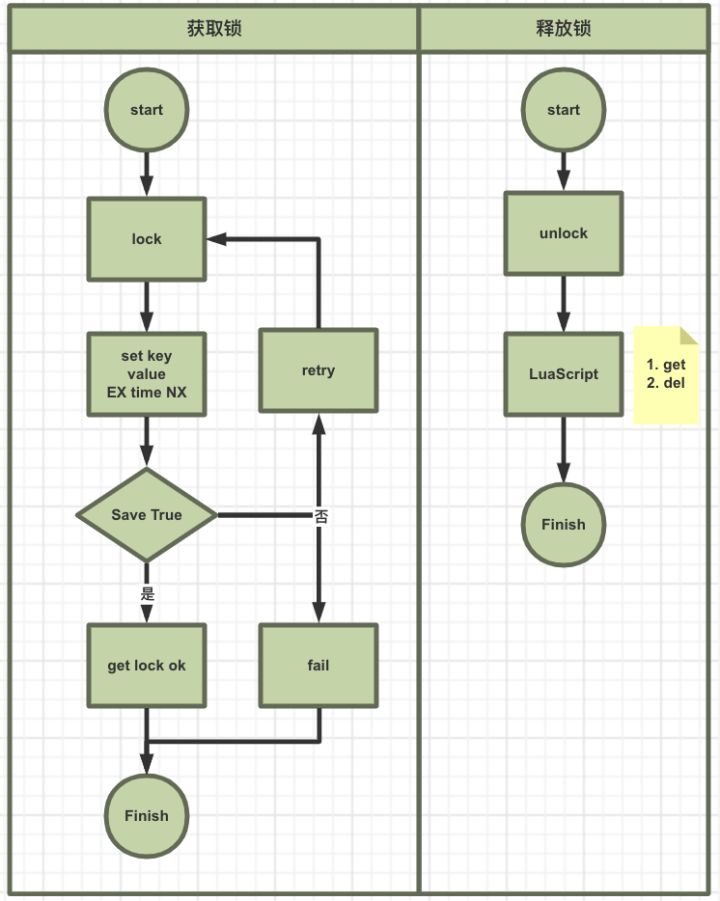
3.2.1 基于Redis
首先 Redis 是单线程的, 这里的单线程指的是网络请求模块使用了一个线程(所以不需考虑并发安全性), 即一个线程处理所有网络请求, 其他模块仍用了多个线程。
获取锁和释放锁需要是原子操作, 需要用lua执行保证原子性
3.3 基于一致性协调器
优点: 天然分布式, 强一致性; 可避免死锁的情况。
缺点: 相比于缓存, 性能较弱。
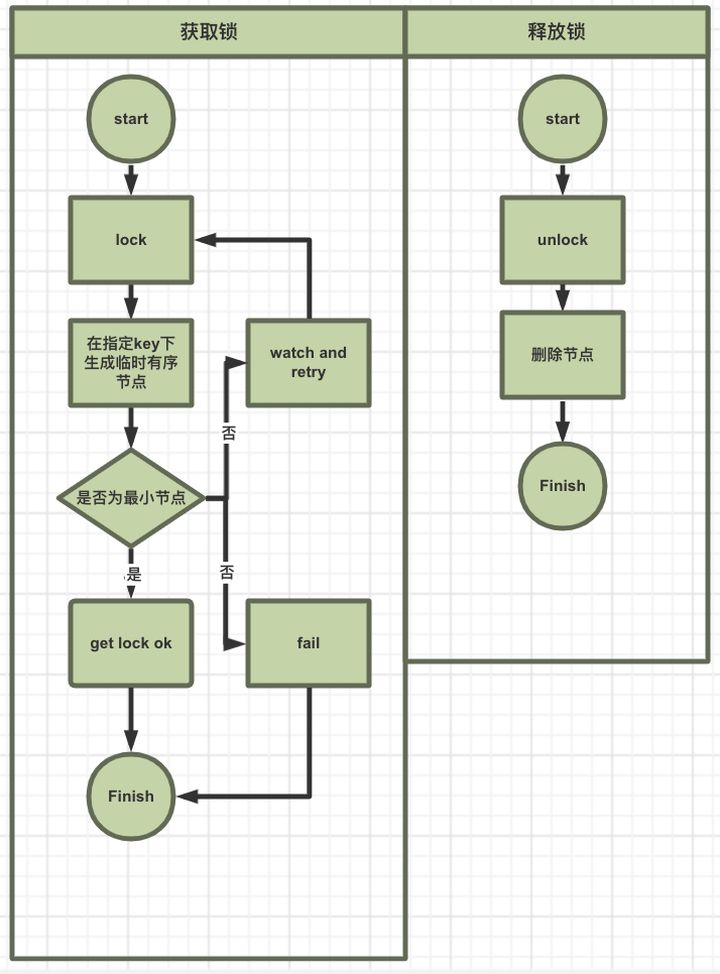
3.3.1 Zookeeper 实现分布式锁
优点: 自由定制读写锁, 公平锁等场景
ZooKeeper 可以创建 4 种类型的节点, 分别是:
- 持久性节点
- 持久性顺序节点
- 临时性节点
- 临时性顺序节点
使用 Zookeeper 来实现分布式锁主要是 利用了 zookeeper临时有序节点的特性:
- 一旦 ZooKeeper 客户端断开了连接, 那 ZooKeeper 服务端就不再保存临时性节点
- 顺序性节点是指, 在创建节点的时候, ZooKeeper 会自动给节点编号比如 0000001, 0000002 这种的
Zookeeper 有一个监听机制, 客户端注册监听它关心的目录节点, 当目录节点发生变化(数据改变、被删除、子目录节点增加删除)等, Zookeeper 会通知客户端。客户端可以检查自己创建的节点是不是当前所有节点中序号最小的, 如果是, 那么自己就获取到锁, 便可以执行业务逻辑了。
3.3.2 基于etcd
etcd 的定位是一个分布式的、一致的 key-value 存储, 主要用途是共享配置和服务发现, 它不是一个类似于 ceph 那样存储海量数据的存储系统, 也不是类似于 MySQL 这样的 SQL 数据库。也就是说 etcd 的使用场景是一种“读多写少”的场景, etcd 里的一个 key, 其实并不会发生频繁的变更, 但是一旦发生变更, etcd 就需要通知监控这个 key 的所有客户端。
解决分布式锁"三大问题":
- Etcd 支持事务, 通过事务创建key 和 检查key 是否存在, 可以保证互斥性
- 基于 Raft 共识算法, 写key成功至少需要超过半数节点确认, 保证了容错性
- 支持租约机制, 可以对key 设置租约存活时间(TTL), 到期后该key失效删除, 避免死锁; 也支持租约续期, 如果客户端还未处理完可以续期; 同时 Etcd 也有自增id。
实现机制:
- 在 prefix 下创建一个key, 类似 zookeeper 的顺序节点, 如:
/demo/lock/694d7f3530606165
/demo/lock/694d7f3530606168
/demo/lock/694d7f353060616c
- 第一创建key的客户端获取锁
- 其他的客户端:
- A). 获取自己前面的Key(m.myRev-1)
- B). 在前面的 Key 上监听delete 事件
// func (m *Mutex) Lock(ctx context.Context) error
_, werr := waitDeletes(ctx, client, m.pfx, m.myRev-1)
//
func waitDeletes(ctx context.Context, client *v3.Client, pfx string, maxCreateRev int64) (*pb.ResponseHeader, error) {
getOpts := append(v3.WithLastCreate(), v3.WithMaxCreateRev(maxCreateRev))
for {
resp, err := client.Get(ctx, pfx, getOpts...)
if err != nil {
return nil, err
}
if len(resp.Kvs) == 0 {
return resp.Header, nil
}
lastKey := string(resp.Kvs[0].Key)
if err = waitDelete(ctx, client, lastKey, resp.Header.Revision); err != nil {
return nil, err
}
}
}
// func waitDelete(ctx context.Context, client *v3.Client, key string, rev int64) error
wch := client.Watch(cctx, key, v3.WithRev(rev))
for wr = range wch {
for _, ev := range wr.Events {
if ev.Type == mvccpb.DELETE {
return nil
}
}
}
从源码里, 不难看出实现机制(本质上, etcd和zookeeper对分布式锁的实现是类似的):
- revision 机制
- prefix 机制
- watch 机制
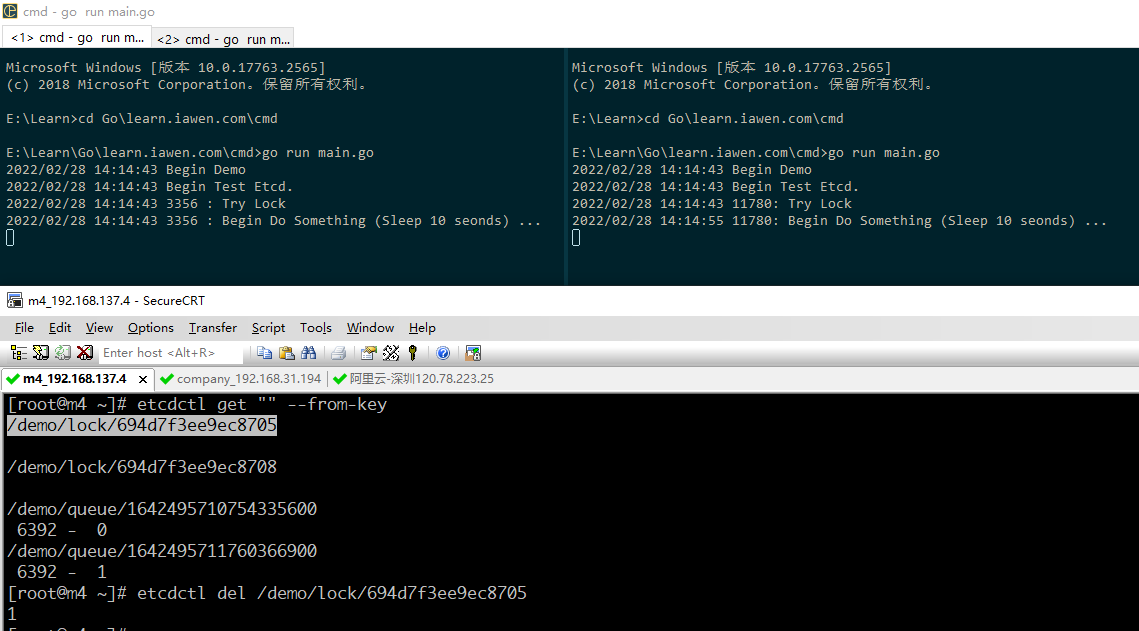
补充: 之所以说分布式锁一般都是建议锁, 因为它无法强制控制锁的所有权, 如下图, 我们使用客户端接口删除了一个锁’标志位’(意即人为释放了一把锁):
3.3.3 基于Chubby
Google Chubby是以paxos为基础的一致性实现, 其目的和zookeeper不同, 仅仅是一个面向松耦合的高可用分布式锁服务。
- 场景: GFS使用chubby来实现对GFS Master服务器的选举。
- 实现: 采用Martin所说的自增序列方案解决分布式不安全的问题
特点:
- 分布式锁和序列: 解决分布式锁安全问题
- CheckSequencer():调用chubby API检查序列号是否有效
- 访问资源服务器, 判断分布式锁服务端的序列号和client的序列号大小
- lock-delay:client如果因为网络抖动或阻塞, chubby并不会立即释放锁, 而是在一定时间(1min)内阻止其他client获取这个锁
- 事件通知机制(发布与订阅)client可以向chubby注册事件通知
- 缓存机制 chubbyClient通过租期机制保证了本地缓存和chubby的强一致性
- 心跳机制 通过TCP连接使用心跳保持会话
- paxos协议 同zookeeper
4. 分布式锁的问题
矛盾点所引发的问题包括但不限于:
- 分布式锁只是同一自然时间段的互斥, 不同时间段不保证
- 如果业务需要处理两个不同时间段的互斥锁, 需要自己实现逻辑
- 锁没有按照预期续租
- 因为网络, GC, 瞬时时间等问题, 不能正常续租的锁, 则会被过期
- 提供分布式锁的服务中断、不可用
- redis集群, master挂了, 主从切换中; zk, etcd leader挂了, 选举过程中
- raft日志数据同步发生错误或者不一致的情况
