
目录
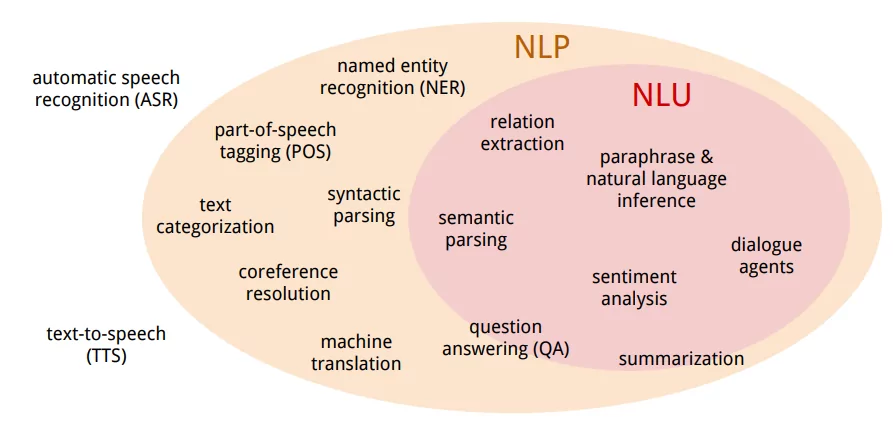
自然语言处理( Natural Language Processing, NLP)是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的科学。因此, 这一领域的研究将涉及自然语言, 即人们日常使用的语言, 所以它与语言学的研究有着密切的联系, 但又有重要的区别。自然语言处理并不是一般地研究自然语言, 而在于研制能有效地实现自然语言通信的计算机系统, 特别是其中的软件系统。因而它是计算机科学的一部分。
自然语言处理主要应用于机器翻译、舆情监测、自动摘要、观点提取、文本分类、问题回答、文本语义对比、语音识别、中文OCR等方面。
1. 一些概念
1.1 基本术语
- 分词: segment
- 词性标注: part-of-speech tagging
词性, 也称为词类, 式词汇的语法属性, 是连接词汇到句法的桥梁。现代汉语的词可以分为两类12种词性(一说是14种)。 - 命名实体识别: NER, Named Entity Recognition
又称"专名识别", 它的主要任务是对于一篇待处理文本, 识别出其中出现的人名、地名、组织机构名、日期、时间、百分数、货币这7类命名实体。 - 语义块: 可用于知识库的实体关系抽取
- 句法分析: syntax parsing
- 指代消解: anaphora resolution
- 情感识别: emotion recognition
- 纠错: correction(N-Gram, 字典树, 有限状态机)
- 问答系统: QA system
1.2 汉语词性对照表[北大标准/中科院标准]
| 词性编码 | 词性名称 | 注 解 |
|---|---|---|
| Ag | 形语素 | 形容词性语素。形容词代码为 a, 语素代码g前面置以A。 |
| a | 形容词 | 取英语形容词 adjective的第1个字母。 |
| ad | 副形词 | 直接作状语的形容词。形容词代码 a和副词代码d并在一起。 |
| an | 名形词 | 具有名词功能的形容词。形容词代码 a和名词代码n并在一起。 |
| b | 区别词 | 取汉字"别"的声母。 |
| c | 连词 | 取英语连词 conjunction的第1个字母。 |
| dg | 副语素 | 副词性语素。副词代码为 d, 语素代码g前面置以D。 |
| d | 副词 | 取 adverb的第2个字母, 因其第1个字母已用于形容词。 |
| e | 叹词 | 取英语叹词 exclamation的第1个字母。 |
| f | 方位词 | 取汉字"方" |
| g | 语素 | 绝大多数语素都能作为合成词的"词根", 取汉字"根"的声母。 |
| h | 前接成分 | 取英语 head的第1个字母。 |
| i | 成语 | 取英语成语 idiom的第1个字母。 |
| j | 简称略语 | 取汉字"简"的声母。 |
| k | 后接成分 | |
| l | 习用语 | 习用语尚未成为成语, 有点"临时性", 取"临"的声母。 |
| m | 数词 | 取英语 numeral的第3个字母, n, u已有他用。 |
| Ng | 名语素 | 名词性语素。名词代码为 n, 语素代码g前面置以N。 |
| n | 名词 | 取英语名词 noun的第1个字母。 |
| nr | 人名 | 名词代码 n和"人(ren)“的声母并在一起。 |
| ns | 地名 | 名词代码 n和处所词代码s并在一起。 |
| nt | 机构团体 | “团"的声母为 t, 名词代码n和t并在一起。 |
| nz | 其他专名 | “专"的声母的第 1个字母为z, 名词代码n和z并在一起。 |
| nx | 专名字母 | 英文单词均被标为nx。 |
| o | 拟声词 | 取英语拟声词 onomatopoeia的第1个字母。 |
| p | 介词 | 取英语介词 prepositional的第1个字母。 |
| q | 量词 | 取英语 quantity的第1个字母。 |
| qg | 量词 | |
| r | 代词 | 取英语代词 pronoun的第2个字母,因p已用于介词。 |
| s | 处所词 | 取英语 space的第1个字母。 |
| tg | 时语素 | 时间词性语素。时间词代码为 t,在语素的代码g前面置以T。 |
| t | 时间词 | 取英语 time的第1个字母。 |
| u | 助词 | 取英语助词 auxiliary |
| vg | 动语素 | 动词性语素。动词代码为 v。在语素的代码g前面置以V。 |
| v | 动词 | 取英语动词 verb的第一个字母。 |
| vd | 副动词 | 直接作状语的动词。动词和副词的代码并在一起。 |
| vn | 名动词 | 指具有名词功能的动词。动词和名词的代码并在一起。 |
| w | 标点符号 | |
| x | 非语素字 | 非语素字只是一个符号, 字母 x通常用于代表未知数、符号。 |
| y | 语气词 | 取汉字"语"的声母。 |
| z | 状态词 | 取汉字"状"的声母的前一个字母。 |
| un | 未知词 | 不可识别词及用户自定义词组。取英文Unkonwn首两个字母。(非北大标准, CSW分词中定义) |
1.3 宾州树库(PENN Treebank)
1.3.1 汉语词性标注规范
| 词性标记 | 英文名称 | 中文名称 | 例子 |
|---|---|---|---|
| AD | adverbs | 副词 | “还” |
| AS | Aspect marker | 体标记 | 了, 着, 过 |
| BA | in ba-const | 把/将 | 把, 将 |
| CC | Coordinating conjunction | 并列连词 | “和”, “与”, “或”, “或者” |
| CD | Cardinal numbers | 数词 | “一百” |
| CS | Subordinating conj | 从属连词 | 若, 如果, 如 |
| DEC | for relative-clause etc | 标句词, 关系从句"的” | 我买"的"书 |
| DEG | Associative | 所有格/联结作用"的” | 我"的"书 |
| DER | in V-de construction,and V-de-R | V得, 表示结果补语的"得” | 跑"得"气喘吁吁 |
| DEV | before VP | 表示方式状语的"地" | 高兴/VA 地/DEV 说/VV |
| DT | Determiner | 限定词 | 这 |
| ETC | Tag for words in coordination phrase | “等”, “等等” | 科技文教 等/ETC 领域 |
| FW | Foreign words | 外语词 | ISO |
| IJ | interjection | 感叹词 | 啊 |
| JJ | Noun-modifier other than nouns | 其他名词修饰语 | 共同/JJ 的/DEG 目的/NN 她/PN 是/VC 女/JJ 的/DEG |
| LB | in long bei-construction | 长"被" | “被"他打了 |
| LC | Localizer | 方位词 | 桌子"上” |
| M | Measure word | 量词 | 一"间"房子 |
| MSP | Some particles | 其他结构助词 | 他/PN 所/MSP 需要/VV 的/DEC。 所, 而, 以 |
| NN | Common nouns | 其他名词, 普通名词 | 桌子 |
| NR | Proper nouns | 专有名词 | 北京 |
| NT | Temporal nouns | 时间名词 | 一月, 汉朝 |
| OD | Ordinal numbers | 序数词 | 第一 |
| ON | Onomatopoeia | 拟声词 | “哗啦啦” |
| P | Prepositions | 介词 | “在” |
| PN | pronouns | 代词 | “你”, “我”, “他” |
| PU | Punctuations | 标点 | , 。 |
| SB | in short bei-construction | 短"被" | 他"被"/SB 训了/AS 一顿/M |
| SP | Sentence-final particle | 句末助词 | 他好 吧/SP |
| VA | Predicative adjective | 谓语形容词 | 花很 红/VA 红彤彤 雪白 丰富 |
| VC | Copula | 系动词 | “是”, “为”, “非” |
| VE | as the main verb | “有"作为主要动词 | “有”, “无” |
| VV | Other verbs | 其他动词, 普通动词 | 走, 可能, 喜欢 |
1.3.2 汉语短语类别表
| 标注 | 英文说明 | 中文说明 |
|---|---|---|
| ADJP | Adjective phrase | 形容词短语, 由JJ投射 |
| ADVP | Adverbial phrase headed by AD | 由副词开头的副词短语、状语 |
| CLP | Classifier phrase | 量词短语 |
| CP | Clause headed by C(complementizer) | 由补语引导的补语从句, 关系从句 |
| DNP | Phrase formed by “XP+DEG” | XP+DEG结构构成的短语 |
| DP | Determiner phrease | 限定词短语 |
| DVP | Phrase formed BY “XP+DEB” | XP+DEV结构构成的短语 |
| FRAG | fragment | 片段 |
| IP | InflectionPhrase | Simple clause headed by I(INFL或其他曲折成份) |
| LCP | Phrase formed by “XP+LC” | 处所词为中心语的短语 |
| LST | List marker | 用于解释说明性的列表标记短语 |
| NP | Noun phrase | 名词短语 |
| PP | Preposition phrase | 介词短语 |
| PRN | Parenthetical | 插入语 |
| QP | Quantifier phrase | 数词短语, 由数量词构成的短语结构 |
| UCP | Unidentical coordination phrase | 非一致性并列短语 |
| VP | Verb phrase | 动词短语 |
1.3.3 空范畴标记
| 标记 | 英文解释 | 中文解释 |
|---|---|---|
| *OP* | operator | 在relative constructions相关结构中的操作符 |
| *pro* | dropped argument | 丢掉的论元 |
| *PRO* | used in control structures | 在受控结构中使用 |
| *RNR* | right node raising | 右部节点提升的空范畴 |
| *T* | trace of A’-movement | A’移动的虚迹, 话题化 |
| * | trace of A-movement | A移动的虚迹 |
| *?* | other unknown empty categories | 其他未知的空范畴 |
1.4 LTP
1.4.1 依存句法关系
| 关系类型 | Tag | Description | Example |
|---|---|---|---|
| 主谓关系 | SBV | subject-verb | 我送她一束花 (我 <- 送) |
| 动宾关系 | VOB | 直接宾语, verb-object | 我送她一束花 (送 -> 花) |
| 间宾关系 | IOB | 间接宾语, indirect-object | 我送她一束花 (送 -> 她) |
| 前置宾语 | FOB | 前置宾语, fronting-object | 他什么书都读 (书 <- 读) |
| 兼语 | DBL | double | 他请我吃饭 (请 -> 我) |
| 定中关系 | ATT | attribute | 红苹果 (红 <- 苹果) |
| 状中结构 | ADV | adverbial | 非常美丽 (非常 <- 美丽) |
| 动补结构 | CMP | complement | 做完了作业 (做 -> 完) |
| 并列关系 | COO | coordinate | 大山和大海 (大山 -> 大海) |
| 介宾关系 | POB | preposition-object | 在贸易区内 (在 -> 内) |
| 左附加关系 | LAD | left adjunct | 大山和大海 (和 <- 大海) |
| 右附加关系 | RAD | right adjunct | 孩子们 (孩子 -> 们) |
| 独立结构 | IS | independent structure | 两个单句在结构上彼此独立 |
| 核心关系 | HED | head | 指整个句子的核心 |
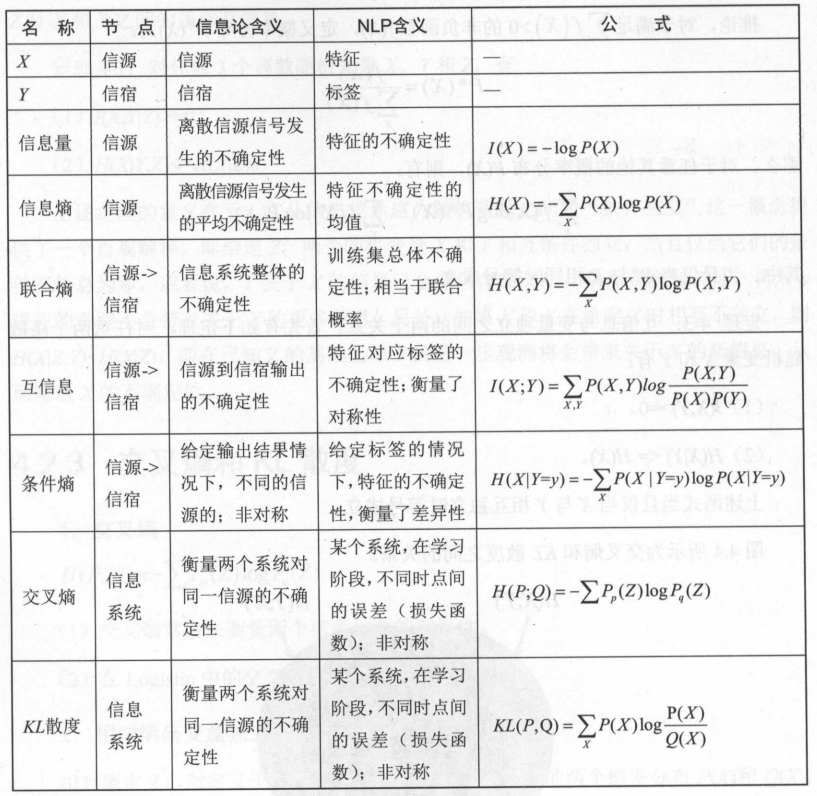
1.5 信息熵概念与公式
1.6 主要概率图模型
- 朴素贝叶斯模型(NB)
- 隐马尔科夫模型(HMM)
- 最大熵模型(ME)
- 条件随机场(CRF, Conditional Random Fields)
可以把条件随机场看成一个无向图模型或马尔科夫随机场, 它是一种用来标记和切分序列化数据的统计模型。
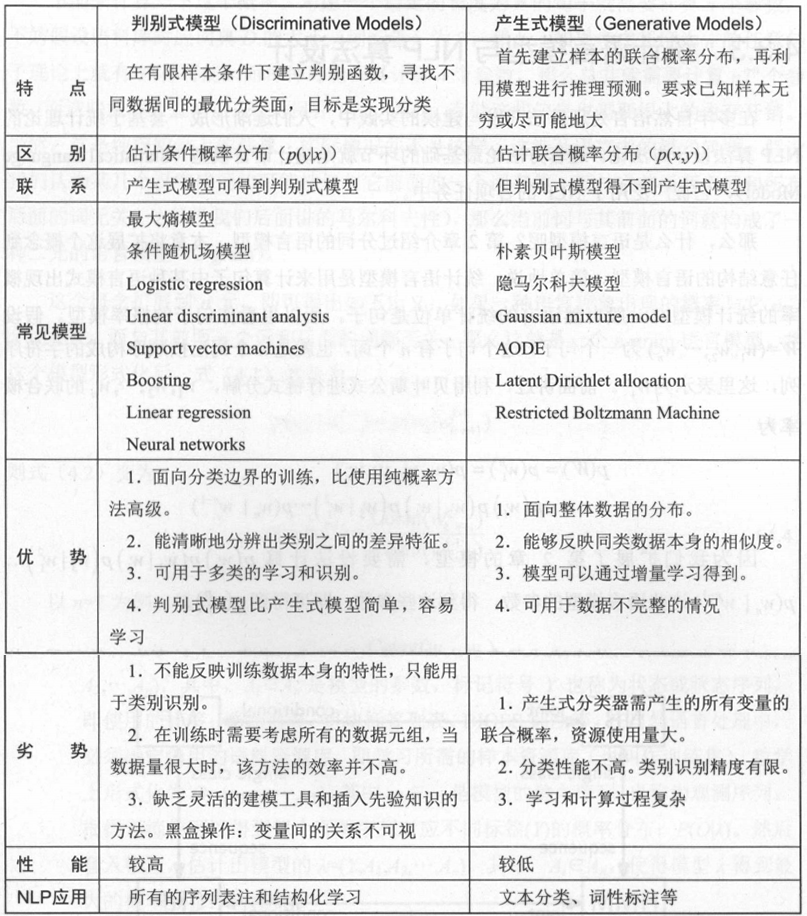
主要概率图模型中的关系:

判别式模型和产生式模型的区别与联系:
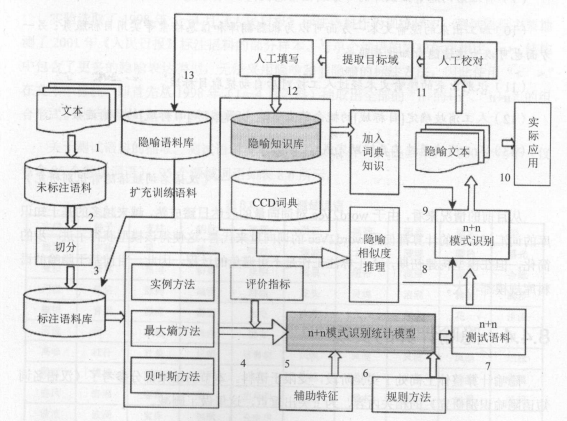
隐喻识别系统结构图:
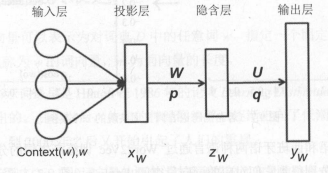
Word2Vec 神经网络架构:
2. 应用
2.1 应用领域
- 机器翻译
- 情感分析
- 智能问答
- 文摘生成
- 文本分类
- 舆论分析
- 知识图谱: 知识点相互连接而成的语义网络
高频词提取其实就是自然语言处理中的TF(Term Frequency)策略.
2.2
- nltk
- word2vec
- Jieba
- ChunkLinkCTB
- CRF++(crfpp)
- CRFsuite
- semi-CRF 算法: 组织机构识别
- 层叠式隐马尔科夫模型: Cascaded HMM, Cascaded Hidden Markov Model
- Aho-Corasick 算法: 一个基于确定有限状态自动机快速模式匹配算法
- 转换生成语法
- 依存句法理论:
- 句法依存
- 语义依存
- 配价理论
- PCFG(即 Probabilistic CFG, 也称为Stochastic CFG)算法: 基于概率图模型
- LSTM 算法
- Viterbi 算法
- NShort 算法
- DBPedit
- CorMet 模型
- 梯度下降法: 一般作为最优化问题的一种求解方法, 是求解无约束多元函数极值的最早的数值方法。
- 循环神经网络, Recurrent Neural Networks RNNs
- Caffe(C++)
- Torch(Lua)
- Tensorflow(C++, Python)
- Gensim: 用于从原始的非结构化的文本中, 无监督地学习到文本隐层的主题向量表达。它支持包括TF-IDF、LSA、LDA和word2vec在内的多种主题模型算法, 支持流式训练, 并提供了诸如相似度计算, 信息检索等一些常用任务的API接口。
2.3 中文分词
- 规则分词: 正向最大匹配法, 逆向最大匹配法, 已经双向最大匹配法
- 统计分词: HMM, CRF, 或者深度学习
- 混合分词
2.4 长句切分
长句切分为单句最有效的算法是支持向量机(SVM)分类器。支持向量机是一种基于统计学习理论的常用机器学习算法之一, 具有较好的推广能力和非线性处理能力, 尤其在处理高维数据时, 有效地解决了“维数灾难”问题, 在人脸检测、网页分类、手写体数字识别、图像检索等领域应用广泛。
- Libsvm
2.4.1 分类器所使用的特征
| 特征 | 描述 | 特征 | 描述 |
|---|---|---|---|
| Jen | 片段长度是否大于4 | shi | 是否含有“是” |
| vg | 是否含有一般动词 | you | 是否含有“有” |
| vx | 是否含有系动词 | zhe | 是否含有“着、了、过” |
| vt | 是否含有及物动词 | vg_n | 是否含有动宾搭配 |
| VI | 是否含有不及物动词 | p_nd | 是否有介词和方位词的组合 |
| nd | 末尾是否为方位名词 | tagl | 第一个词的词性 |
| de | 是否含有“的” | tag_l | 最后一个词的词性 |
| lei | 是否含有“得” | punct | 片段末尾的标点 |
2.4.2 片段之间的依存关系类型
| 关系类型 | 描述 | 关系类型 | 描述 |
|---|---|---|---|
| IC | 独立分句 | vv | 连动结构 |
| SBV | 主谓结构 | ADV | 状中结构 |
| VOB | 动宾结构 | CNJ | 关联结构 |
2.5 关键词提取
2.5.1 相关算法
- TF-IDF 算法(Term Frequency-Inverse Document Frequency, 词频-逆文档频次算法)
一种基于统计的计算方法, 常用于评估在一个文档集中一个词对某份文档的重要程度。 - TextRank 算法: 最早用于文档的自动摘要, 基于句子纬度的分析, 利用TextRank对每个句子镜像打分, 挑选出分数最高的n个句子作为文档的关键词, 以达到自动摘要的效果。TextRank算法的基本思想来源于Google的PageRank 算法。
- 主题模型算法(包括LSA、LSI、LDA等)
LSA 主要是采用SVD(奇异值分解)的方法进行暴力破解, 而LDA则是通过贝叶斯学派的方法对分布信息进行拟合。- LSA: Latent Semantic Analysis, 潜在语义分析
- LSI: Latent Semantic Index, 潜在语义索引
- LDA: Latent Dirichlet Allocation, 隐含狄利克雷分布
2.6 句法分析
统计句法分析模型本质是一套面向候选树的评价方法, 其会给正确的句法树赋予一个较高的分值, 而给不合理的句法树赋予一个较低的分值, 这样就可以借用候选句法树的分值进行消歧。
2.6.1 PCFG
PCFG(Probabilistic Context Free Grammar), 是基于概率的短语结构分析方法, 也可以认为是规则方法与统计方法的结合。
- 基于单纯PCFG的句法分析方法
- 基于词汇化的PCFG的句法分析方法
- 基于子类划分PCFG的句法分析方法
2.6.2 基于最大间隔马尔科夫网络的句法分析
fₓ(x) = arg maxᵧ∈G(x)<w, ∮(x,y)>
2.6.3 基于CRF的句法分析
CRF, 条件数据场。CRF模型最大化的是句法树的条件概率值而不是联合概率值, 并且对概率进行归一化。
2.6.4 基于移进-归约的句法分析模型
Shift-Reduce Algorithm, 移进-归约方法是一种自下而上的方法。其从输入串开始, 逐步进行"归约”, 直至归约到文法的开始符号。
2.6.5 句法分析评测
PARSEVAL 评测体系, 主要指标有准确率、召回率、交叉括号数。
3. 语料OR语义库
3.1 中文分词语料库
- PFR 语料库: 1998年人民日报标注语料库
- MSR 语料库: 微软亚洲研究院中文分词语料库
- 宾州大学 CTB
3.2 语义知识库
- WordNet: 普林斯顿大学认知科学实验室George A. Miller 等开发的英语词汇知识库
- HowNet(知网): 一个典型的语义场论的知识库体系
3.3 语义角色标注
- FrameNet
- PropBank
- NomBank
3.4 语法树库
- PTB, Penn TreeBank: 英文宾州树库
- CTB, Chinese TreeBank: 中文宾州树库
- TCT, Tsinghua Chinese TreeBank: 清华树库
- Sinica TreeBank: 台湾中研院树库
4. Framework
4.1
- Haptik
- Knowledge base
- AI recommendations
- Smart variants
- Microsoft
- Knowledge Exploration Service
- Language Understanding Intelligent Service (LUIS)
- Azure Translator APIs
- Google
- Dialogflow
- Translate API
- Cloud Natural Language API
- IBM
- Watson Conversation Service
- Watson Tone Analyzer
- Amazon
- Comprehend
- Lex
4.2 Open-source alternatives
4.2.1 NLTK
开源协议: Apache License 2.0
4.2.2 RASA
4.2.3 PyNLPl
4.2.4 Stanford CoreNLP
4.2.5 Baidu paddlenlp
LAC
LAC全称Lexical Analysis of Chinese, 是百度自然语言处理部研发的一款联合的词法分析工具, 实现中文分词、词性标注、专名识别等功能。
4.2.6 spaCy
开源协议: MIT License
https://github.com/explosion/spaCy
4.2.7 LTP
相关网站:
参考:
