
目录
1. 交叉检验
交叉检验是构建机器学习模型过程中的一个步骤, 它可以帮助我们确保模型准确拟合数据, 同时确保我们不会过拟合。
交叉验证(cross-validation)是一种评估泛化性能的统计学方法, 它比单次划分训练集和测试集的方法更加稳定、全面。在交叉验证中, 数据被多次划分, 并且需要训练多个模型。最常用的交叉验证是 k 折交叉验证(k-fold cross-validation), 其中 k 是由用户指定的数字, 通常取 5 或 10。
有一个相当有名的红酒质量数据集(red wine quality dataset)。这个数据集有 11 个不同的特征, 这些特征决定了红酒的质量。这些属性包括:
- 固定酸度(fixed acidity)
- 挥发性酸度(volatile acidity)
- 柠檬酸(citric acid)
- 残留糖(residual sugar)
- 氯化物(chlorides)
- 游离二氧化硫(free sulfur dioxide)
- 二氧化硫总量(total sulfur dioxide)
- 密度(density)
- PH 值(pH)
- 硫酸盐(sulphates)
- 酒精(alcohol)
根据这些不同特征, 我们需要预测红葡萄酒的质量, 质量值介于 0 到 10 之间。
import pandas as pd
from sklearn import tree
from sklearn import metrics
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv("winequality-red.csv", sep=";")
quality_mapping = {3: 0, 4: 1, 5: 2, 6: 3, 7: 4, 8: 5}
df.loc[:,"quality"] = df.quality.map(quality_mapping)
df = df.sample(frac=1).reset_index(drop=True)
df_train = df.head(1000)
df_test = df.tail(599)
matplotlib.rc('xtick', labelsize=20)
matplotlib.rc('ytick', labelsize=20)
train_accuracies = [0.5]
test_accuracies = [0.5]
# 遍历几个不同的树深度值
for depth in range(1, 25):
# 初始化模型
clf = tree.DecisionTreeClassifier(max_depth=depth)
# 选择用于训练的列/特征
cols = [
'fixed acidity', 'volatile acidity', 'citric acid',
'residual sugar', 'chlorides', 'free sulfur dioxide',
'total sulfur dioxide', 'density', 'pH',
'sulphates', 'alcohol'
]
# 在给定特征上拟合模型
clf.fit(df_train[cols], df_train.quality)
# 创建训练和测试预测
train_predictions = clf.predict(df_train[cols])
test_predictions = clf.predict(df_test[cols])
# 计算训练和测试准确度
train_accuracy = metrics.accuracy_score(
df_train.quality, train_predictions
)
test_accuracy = metrics.accuracy_score(
df_test.quality, test_predictions
)
# 添加准确度到列表
train_accuracies.append(train_accuracy)
test_accuracies.append(test_accuracy)
# 使用 matplotlib 和 seaborn 创建两个图
plt.figure(figsize=(10, 5))
sns.set_style("whitegrid")
plt.plot(train_accuracies, label="train accuracy")
plt.plot(test_accuracies, label="test accuracy")
plt.legend(loc="upper left", prop={'size': 15})
plt.xticks(range(0, 26, 5))
plt.xlabel("max_depth", size=20)
plt.ylabel("accuracy", size=20)
plt.show()
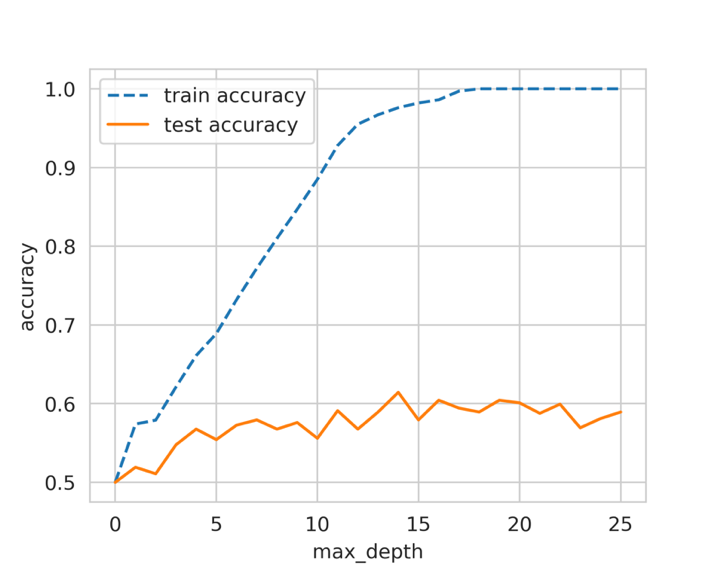
随着最大深度(max_depth)的增加, 决策树模型对训练数据的学习效果越来越好, 但测试数据的性能却丝毫没有提高。这就是所谓的过拟合。
模型在训练集上完全拟合, 而在测试集上却表现不佳。这意味着模型可以很好地学习训练数据, 但无法泛化到未见过的样本上。
在其中一部分上训练模型, 然后在另一部分上检查其性能。这也是交叉检验的一种, 通常被称为"暂留集"(hold-out set)。当我们拥有大量数据, 而模型推理是一个耗时的过程时, 我们就会使用这种(交叉)验证。
交叉检验有许多不同的方法, 它是建立一个良好的机器学习模型的最关键步骤。选择正确的交叉检验取决于所处理的数据集, 在一个数据集上适用的交叉检验也可能不适用于其他数据集。不过, 有几种类型的交叉检验技术最为流行和广泛使用。
其中包括:
- k 折交叉检验
- 分层 k 折交叉检验
- 暂留交叉检验
- 留一交叉检验
- 分组 k 折交叉检验
交叉检验是将训练数据分层几个部分, 我们在其中一部分上训练模型, 然后在其余部分上进行测试。
使用交叉验证最简单的方法是在估计器和数据集上调用 cross_val_score 辅助函数。默认情况下, cross_val_score 执行 3 折交叉验证, 返回 3 个精度值。
logreg = LogisticRegression()
scores = cross_val_score(logreg, iris.data, iris.target)
print("Cross-validation scores: {}".format(scores))
1.1 k折交叉检验
我们可以将数据分为 k 个互不关联的不同集合。这就是所谓的 k 折交叉检验。
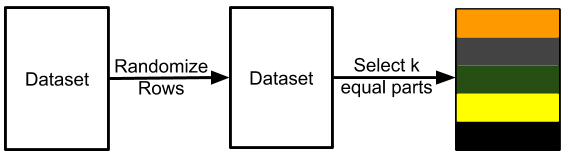
# 导入 pandas 和 scikit-learn 的 model_selection 模块
import pandas as pd
from sklearn import model_selection
if __name__ =="__main__":
# 训练数据存储在名为 train.csv 的 CSV 文件中
df = pd.read_csv("train.csv")
# 我们创建一个名为 kfold 的新列, 并用 -1 填充
df["kfold"] = -1
# 接下来的步骤是随机打乱数据的行
df = df.sample(frac=1).reset_index(drop=True)
# 从 model_selection 模块初始化 kfold 类
kf = model_selection.KFold(n_splits=5)
# 填充新的 kfold 列(enumerate的作用是返回一个迭代器)
for fold,(trn_, val_) in enumerate(kf.split(X=df)):
df.loc[val_, 'kfold'] = fold
# 保存带有 kfold 列的新 CSV 文件
df.to_csv("train_folds.csv", index=False)
1.2 分层 k 折交叉检验
如果你有一个偏斜的二元分类数据集, 其中正样本占 90%, 负样本只占 10%, 那么你就不应该使用随机 k 折交叉。对这样的数据集使用简单的 k 折交叉检验可能会导致折叠样本全部为负样本。在这种情况下, 我们更倾向于使用分层 k 折交叉检验。分层 k 折交叉检验可以保持每个折中标签的比例不变。因此, 在每个折叠中, 都会有相同的 90% 正样本和 10% 负样本。因此, 无论您选择什么指标进行评估, 都会在所有折叠中得到相似的结果。
import pandas as pd
from sklearn import model_selection
if __name__ =="__main__":
# 训练数据保存在名为 train.csv 的 CSV 文件中
df = pd.read_csv("train.csv")
# 添加一个新列 kfold, 并用 -1 初始化
df["kfold"] = -1
# 随机打乱数据行
df = df.sample(frac=1).reset_index(drop=True)
# 获取目标变量
y = df.target.values
# 初始化 StratifiedKFold 类, 设置折数(folds)为 5
kf = model_selection.StratifiedKFold(n_splits=5)
# 使用 StratifiedKFold 对象的 split 方法来获取训练和验证索引
for f,(t_, v_) in enumerate(kf.split(X=df, y=y)):
df.loc[v_, 'kfold'] = f
# 保存包含 kfold 列的新 CSV 文件
df.to_csv("train_folds.csv", index=False)
规则很简单, 如果是标准分类问题, 就盲目选择分层 k 折交叉检验。
选择合适的分层数有几种选择。如果样本量很大(> 10k, > 100k), 那么就不需要考虑分层的数量。只需将数据分为 10 或 20 层即可。如果样本数不多, 则可以使用 Sturge’s Rule 这样的简单规则来计算适当的分层数。
1.3 暂留交叉检验
但如果数据量很大, 该怎么办呢? 假设我们有 100 万个样本。5 倍交叉检验意味着在 800k 个样本上进行训练, 在 200k 个样本上进行验证。根据我们选择的算法, 对于这样规模的数据集来说, 训练甚至验证都可能非常昂贵。在这种情况下, 我们可以选择暂留交叉检验。
创建保持结果的过程与分层 k 折交叉检验相同。对于拥有 100 万个样本的数据集, 我们可以创建 10 个折叠而不是 5 个, 并保留其中一个折叠作为保留样本。这意味着, 我们将有 10 万个样本被保留下来, 我们将始终在这个样本集上计算损失、准确率和其他指标, 并在 90 万个样本上进行训练。
在处理时间序列数据时, 暂留交叉检验也非常常用。假设我们要解决的问题是预测一家商店 2020 年的销售额, 而我们得到的是 2015-2019 年的所有数据。在这种情况下, 你可以选择 2019 年的所有数据作为保留数据, 然后在 2015 年至 2018 年的所有数据上训练你的模型。
大多数情况下, 简单的 k 折交叉检验适用于任何回归问题。但是, 如果发现目标分布不一致, 就可以使用分层 k 折交叉检验。
1.4 留一交叉检验
在很多情况下, 我们必须处理小型数据集, 而创建大型验证集意味着模型学习会丢失大量数据。在这种情况下, 我们可以选择留一交叉检验, 相当于特殊的 k 折交叉检验其中 k=N , N 是数据集中的样本数。这意味着在所有的训练折叠中, 我们将对除 1 之外的所有数据样本进行训练。这种类型的交叉检验的折叠数与数据集中的样本数相同。
需要注意的是, 如果模型的速度不够快, 这种类型的交叉检验可能会耗费大量时间, 但由于这种交叉检验只适用于小型数据集, 因此并不重要。
1.5 分组 k 折交叉检验
交叉检验是构建机器学习模型的第一步, 也是最基本的一步。如果要做特征工程, 首先要拆分数据。如果要建立模型, 首先要拆分数据。
交叉检验也在很大程度上取决于数据, 你可能需要根据你的问题和数据采用新的交叉检验形式。
例如, 假设我们有一个问题, 希望建立一个模型, 从患者的皮肤图像中检测出皮肤癌。我们的任务是建立一个二元分类器, 该分类器接收输入图像并预测其良性或恶性的概率。
在这类数据集中, 训练数据集中可能有同一患者的多张图像。因此, 要在这里建立一个良好的交叉检验系统, 必须有分层的 k 折交叉检验, 但也必须确保训练数据中的患者不会出现在验证数据中。幸运的是, scikit-learn 提供了一种称为 GroupKFold 的交叉检验类型。 在这里, 患者可以被视为组。 但遗憾的是, scikit-learn 无法将 GroupKFold 与 StratifiedKFold 结合起来。所以你需要自己动手。
2. 评估指标
人们甚至会根据业务问题创建度量标准。虽然无监督学习可以使用一些指标, 但我们将只关注有监督学习。这是因为有监督问题比无监督问题多, 而且对无监督方法的评估相当主观。
2.1 分类问题
谈论分类问题, 最常用的指标是:
- 准确率(Accuracy)
- 精确率(P)
- 召回率(R)
- F1 分数(F1)
- AUC(AUC)
- 对数损失(Log loss)
- k 精确率(P@k)
- k 平均精率(AP@k)
- k 均值平均精确率(MAP@k)
2.1.1 准确率(Accuracy)
这是机器学习中最直接的指标之一。它定义了模型的准确度。
可以使用 scikit-learn 计算准确率:
from sklearn import metrics
l1 = [0,1,1,1,0,0,0,1]
l2 = [0,1,0,1,0,1,0,0]
metrics.accuracy_score(l1, l2)
2.1.2 精确率(P)
一个类别中的样本数量比另一个类别中的样本数量多很多。在这种情况下, 使用准确率作为评估指标是不可取的, 因为它不能代表数据。因此, 您可能会获得很高的准确率, 但您的模型在实际样本中的表现可能并不理想, 而且您也无法向经理解释原因。
在这种情况下, 最好还是看看精确率等其他指标。
-
真阳性(TP): 给定一幅图像, 如果您的模型预测该图像有气胸, 而该图像的实际目标有气胸, 则视为真阳性。
-
真阴性(TN): 给定一幅图像, 如果您的模型预测该图像没有气胸, 而实际目标显示该图像没有气胸, 则视为真阴性。
简单地说, 如果您的模型正确预测了阳性类别, 它就是真阳性;如果您的模型准确预测了阴性类别, 它就是真阴性。 -
假阳性(FP): 给定一张图像, 如果您的模型预测为气胸, 而该图像的实际目标是非气胸, 则为假阳性。
-
假阴性(FN): 给定一幅图像, 如果您的模型预测为非气胸, 而该图像的实际目标是气胸, 则为假阴性。
简单地说, 如果您的模型错误地(或虚假地)预测了阳性类, 那么它就是假阳性。如果模型错误地(或虚假地)预测了阴性类别, 则是假阴性。
用上述术语来定义准确率, 我们可以写为: AccuracyScore=(TP+TN)/(TP+TN+FP+FN)
精确率的定义是: Precision=TP/(TP+FP)
# 只适用于二元分类
def true_positive(y_true, y_pred):
# 初始化真阳性样本计数器
tp = 0
for yt, yp in zip(y_true, y_pred):
if yt == 1 and yp == 1:
tp += 1
return tp
def true_negative(y_true, y_pred):
# 初始化真阴性样本计数器
tn = 0
for yt, yp in zip(y_true, y_pred):
if yt == 0 and yp == 0:
tn += 1
return tn
def false_positive(y_true, y_pred):
# 初始化假阳性计数器
fp = 0
for yt, yp in zip(y_true, y_pred):
if yt == 0 and yp == 1:
fp += 1
return fp
def false_negative(y_true, y_pred):
# 初始化假阴性计数器
fn = 0
for yt, yp in zip(y_true, y_pred):
if yt == 1 and yp == 0:
fn += 1
return fn
def accuracy_v2(y_true, y_pred):
tp = true_positive(y_true, y_pred)
fp = false_positive(y_true, y_pred)
fn = false_negative(y_true, y_pred)
tn = true_negative(y_true, y_pred)
accuracy_score =(tp + tn) /(tp + tn + fp + fn)
return accuracy_score
2.1.2 召回率(R)
召回率的定义是: Recall=TP/(TP+FN)
def recall(y_true, y_pred):
# 真阳性样本数
tp = true_positive(y_true, y_pred)
# 假阴性样本数
fn = false_negative(y_true, y_pred)
# 召回率
recall = tp /(tp + fn)
return recall
对于一个"好"模型来说, 精确率和召回值都应该很高。
2.1.3 F1 分数(F1)
大多数模型都会预测一个概率, 当我们预测时, 通常会将这个阈值选为 0.5。这个阈值并不总是理想的, 根据这个阈值, 精确率和召回率的值可能会发生很大的变化。如果我们选择的每个阈值都能计算出精确率和召回率, 那么我们就可以在这些值之间绘制出曲线图。这幅图或曲线被称为"精确率-召回率曲线"。
精确率和召回率的范围都是从 0 到 1, 越接近 1 越好。
F1分数是精确率和召回率的综合指标。它被定义为精确率和召回率的简单加权平均值(调和平均值)。如果我们用 P 表示精确率, 用 R 表示召回率, 那么 F1 分数可以表示为: F1=2PR/(P+R)
根据 TP、FP 和 FN, 稍加数学计算就能得出以下 F1 等式: F1=2TP/(2TP+FP+FN)
def f1(y_true, y_pred):
# 计算精确率
p = precision(y_true, y_pred)
# 计算召回率
r = recall(y_true, y_pred)
# 计算f1值
score = 2 * p * r /(p + r)
return score
from sklearn import metrics
metrics.f1_score(y_true, y_pred)
# 0.5714285714285715
2.1.4 AUC(AUC)
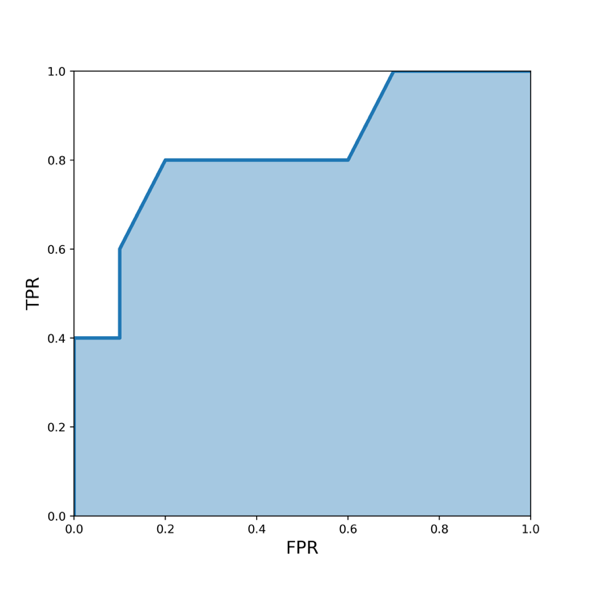
ROC 曲线下面积或曲线下面积, 简称 AUC。计算 ROC 曲线下面积的方法有很多。在此, 我们将采用 scikit- learn 的奇妙实现方法。
from sklearn import metrics
y_true = [0, 0, 0, 0, 1, 0, 1,
0, 0, 1, 0, 1, 0, 0, 1]
y_pred = [0.1, 0.3, 0.2, 0.6, 0.8, 0.05,
0.9, 0.5, 0.3, 0.66, 0.3, 0.2,
0.85, 0.15, 0.99]
metrics.roc_auc_score(y_true, y_pred)
AUC 值从 0 到 1 不等:
- AUC = 1 意味着您拥有一个完美的模型。大多数情况下, 这意味着你在验证时犯了一些错误, 应该重新审视数据处理和验证流程。如果你没有犯任何错误, 那么恭喜你, 你已经拥有了针对数据集建立的最佳模型。
- AUC = 0 意味着您的模型非常糟糕(或非常好!)。试着反转预测的概率, 例如, 如果您预测正类的概率是 p, 试着用 1-p 代替它。这种 AUC 也可能意味着您的验证或数据处理存在问题。
- AUC = 0.5 意味着你的预测是随机的。因此, 对于任何二元分类问题, 如果我将所有目标都预测为 0.5, 我将得到 0.5 的 AUC。
但 AUC 对我们的模型有什么影响呢?
假设您建立了一个从胸部 X 光图像中检测气胸的模型, 其 AUC 值为 0.85。这意味着, 如果您从数据集中随机选择一张有气胸的图像(阳性样本)和另一张没有气胸的图像(阴性样本), 那么气胸图像的排名将高于非气胸图像, 概率为 0.85。
AUC 是业内广泛应用于偏斜二元分类任务的指标, 也是每个人都应该了解的指标。一旦理解了 AUC 背后的理念(如上文所述), 也就很容易向业界可能会评估您的模型的非技术人员解释它了。
2.1.5 对数损失(Log loss)
其中, 目标值为 0 或 1, 预测值为样本属于类别 1 的概率。
对于数据集中的多个样本, 所有样本的对数损失只是所有单个对数损失的平均值。需要记住的一点是, 对数损失会对不正确或偏差较大的预测进行相当高的惩罚, 也就是说, 对数损失会对非常确定和非常错误的预测进行惩罚。
import numpy as np
def log_loss(y_true, y_proba):
# 极小值, 防止0做分母
epsilon = 1e-15
# 对数损失列表
loss = []
# 遍历y_true, y_pred中所有元素
for yt, yp in zip(y_true, y_proba):
# 限制yp范围, 最小为epsilon, 最大为1-epsilon
yp = np.clip(yp, epsilon, 1 - epsilon)
# 计算对数损失
temp_loss = - 1.0 * (yt * np.log(yp)+ (1 - yt) * np.log(1 - yp))
# 加入对数损失列表
loss.append(temp_loss)
return np.mean(loss)
from sklearn import metrics
metrics.log_loss(y_true, y_proba)
# 0.49882711861432294
对数损失的实现很容易。解释起来似乎有点困难。你必须记住, 对数损失的惩罚要比其他指标大得多。因此, 在处理对数损失时, 你需要非常小心;任何不确定的预测都会产生非常高的对数损失。
2.1.6 k 精确率(P@k)
精确率取决于真阳性和假阳性。
2.1.6.1 宏观平均精确率(Macro averaged precision)
分别计算所有类别的精确率然后求平均值
import numpy as np
def macro_precision(y_true, y_pred):
# 种类数
num_classes = len(np.unique(y_true))
# 初始化精确率
precision = 0
# 遍历0~(种类数-1)
for class_ in range(num_classes):
# 若真实标签为class_为1, 否则为0
temp_true = [1 if p == class_ else 0 for p in y_true]
# 如预测标签为class_为1, 否则为0
temp_pred = [1 if p == class_ else 0 for p in y_pred]
# 真阳性样本数
tp = true_positive(temp_true, temp_pred)
# 假阳性样本数
fp = false_positive(temp_true, temp_pred)
# 计算精确度
temp_precision = tp / (tp + fp)
# 各类精确率相加
precision += temp_precision
# 计算平均值
precision /= num_classes
return precision
2.1.6.2 微观平均精确率(Micro averaged precision)
按类计算真阳性和假阳性, 然后用其计算总体精确率。然后以此计算总体精确率
import numpy as np
def micro_precision(y_true, y_pred):
# 种类数
num_classes = len(np.unique(y_true))
# 初始化真阳性样本数
tp = 0
# 初始化假阳性样本数
fp = 0
# 遍历0~(种类数-1)
for class_ in range(num_classes):
# 若真实标签为class_为1, 否则为0
temp_true = [1 if p == class_ else 0 for p in y_true]
# 若预测标签为class_为1, 否则为0
temp_pred = [1 if p == class_ else 0 for p in y_pred]
# 真阳性样本数相加
tp += true_positive(temp_true, temp_pred)
# 假阳性样本数相加
fp += false_positive(temp_true, temp_pred)
# 精确率
precision = tp / (tp + fp)
return precision
2.1.6.3 加权精确率(Weighted precision)
与宏观精确率相同, 但这里是加权平均精确率 取决于每个类别中的项目数
from collections import Counter
import numpy as np
def weighted_precision(y_true, y_pred):
# 种类数
num_classes = len(np.unique(y_true))
# 统计各种类样本数
class_counts = Counter(y_true)
# 初始化精确率
precision = 0
# 遍历0~(种类数-1)
for class_ in range(num_classes):
# 若真实标签为class_为1, 否则为0
temp_true = [1 if p == class_ else 0 for p in y_true]
# 若预测标签为class_为1, 否则为0
temp_pred = [1 if p == class_ else 0 for p in y_pred]
# 真阳性样本数
tp = true_positive(temp_true, temp_pred)
# 假阳性样本数
fp = false_positive(temp_true, temp_pred)
# 精确率
temp_precision = tp / (tp + fp)
# 根据该种类样本数分配权重
weighted_precision = class_counts[class_] * temp_precision
# 加权精确率求和
precision += weighted_precision
# 计算平均精确率
overall_precision = precision / len(y_true)
return overall_precision
from sklearn import metrics
y_true = [0, 1, 2, 0, 1, 2, 0, 2, 2]
y_pred = [0, 2, 1, 0, 2, 1, 0, 0, 2]
macro_precision(y_true, y_pred)
# 0.3611111111111111
metrics.precision_score(y_true, y_pred, average="macro")
# 0.3611111111111111
micro_precision(y_true, y_pred)
# 0.4444444444444444
metrics.precision_score(y_true, y_pred, average="micro")
# 0.4444444444444444
weighted_precision(y_true, y_pred)
# 0.39814814814814814
metrics.precision_score(y_true, y_pred, average="weighted")
# 0.39814814814814814
2.1.7 k平均精率(AP@k)
- k 精确率(P@k)
- k 平均精确率(AP@k)
- k 均值平均精确率(MAP@k)
- 对数损失(Log loss)
如果您有一个给定样本的原始类别列表和同一个样本的预测类别列表, 那么k平均精率(AP@k)的定义就是预测列表中仅考虑前 k 个预测结果的命中数除以 k。
def pk(y_true, y_pred, k):
# 如果k为0
if k == 0:
# 返回0
return 0
# 取预测标签前k个
y_pred = y_pred[:k]
# 将预测标签转换为集合
pred_set = set(y_pred)
# 将真实标签转换为集合
true_set = set(y_true)
# 预测标签集合与真实标签集合交集
common_values = pred_set.intersection(true_set)
return len(common_values) / len(y_pred[:k])
AP@k 是通过 P@k 计算得出的:
def apk(y_true, y_pred, k):
# 初始化P@k列表
pk_values = []
# 遍历1~k
for i in range(1, k + 1):
# 将P@k加入列表
pk_values.append(pk(y_true, y_pred, i))
# 若长度为0
if len(pk_values) == 0:
# 返回0
return 0
return sum(pk_values) / len(pk_values)
2.1.8 k均值平均精确率(MAP@k)
在机器学习中, 我们对所有样本都感兴趣, 这就是为什么我们有均值平均精确率 k 或 MAP@k。MAP@k 只是 AP@k 的平均值, 可以通过以下 python 代码轻松计算:
def mapk(y_true, y_pred, k):
# 初始化AP@k列表
apk_values = []
# 遍历0~(真实标签数-1)
for i in range(len(y_true)):
# 将AP@K加入列表
apk_values.append(
apk(y_true[i], y_pred[i], k=k)
)
# 计算平均AP@k
return sum(apk_values) / len(apk_values)
P@k、AP@k 和 MAP@k 的范围都是从 0 到 1, 其中 1 为最佳。
2.2 混淆矩阵
使用混淆矩阵, 您可以快速查看有多少样本被错误分类, 有多少样本被正确分类。
混淆矩阵由 TP、FP、FN 和 TN 组成。我们只需要这些值来计算精确率、召回率、F1 分数和 AUC。有时, 人们也喜欢把 FP 称为第一类错误, 把 FN 称为第二类错误。

一个完美的混淆矩阵只能从左到右斜向填充。
混淆矩阵提供了一种简单的方法来计算我们之前讨论过的不同指标。Scikit-learn 提供了一种简单直接的方法来生成混淆矩阵。
2.3 回归
说到回归, 最常用的评价指标是
- 平均绝对误差(MAE)
- 均方误差(MSE)
- 均方根误差(RMSE)
- 均方根对数误差(RMSLE)
- 平均百分比误差(MPE)
- 平均绝对百分比误差(MAPE)
- R2
回归中最常见的指标是误差(Error)。误差很简单, 也很容易理解: Error=True Value−Predicted Value
2.3.1 平均绝对误差(MAE)
绝对误差(Absolute error)只是上述误差的绝对值: Absolute Error=Abs(True Value−Predicted Value)
平均绝对误差(MAE), 它只是所有绝对误差的平均值。
import numpy as np
def mean_absolute_error(y_true, y_pred):
#初始化误差
error = 0
# 遍历y_true, y_pred
for yt, yp in zip(y_true, y_pred):
# 累加绝对误差
error += np.abs(yt - yp)
# 返回平均绝对误差
return error / len(y_true)
2.3.2 均方误差(MSE)
Squared Error=(TrueValue−Predicted Value) ²
def mean_squared_error(y_true, y_pred):
# 初始化误差
error = 0
# 遍历y_true, y_pred
for yt, yp in zip(y_true, y_pred):
# 累加误差平方和
error += (yt - yp) ** 2
# 计算均方误差
return error / len(y_true)
2.3.3 均方根误差(RMSE)
MSE 和 RMSE(均方根误差)是评估回归模型最常用的指标: RMSE=SQRT(MSE)
同一类误差的另一种类型是平方对数误差。有人称其为 SLE, 当我们取所有样本中这一误差的平均值时, 它被称为 MSLE(平均平方对数误差), 实现方法如下:
import numpy as np
def mean_squared_log_error(y_true, y_pred):
# 初始化误差
error = 0
# 遍历y_true, y_pred
for yt, yp in zip(y_true, y_pred):
# 计算平方对数误差
error += (np.log(1 + yt) - np.log(1 + yp)) ** 2
# 计算平均平方对数误差
return error / len(y_true)
2.3.4 均方根对数误差(RMSLE)
均方根对数误差只是其平方根。它也被称为 RMSLE。
2.3.5 平均百分比误差(MPE)
def mean_percentage_error(y_true, y_pred):
# 初始化误差
error = 0
# 遍历y_true, y_pred
for yt, yp in zip(y_true, y_pred):
# 计算百分比误差
error += (yt - yp) / yt
# 返回平均百分比误差
return error / len(y_true)
2.3.6 平均绝对百分比误差(MAPE)
绝对误差的绝对值(也是更常见的版本)被称为平均绝对百分比误差或 MAPE。
import numpy as np
def mean_abs_percentage_error(y_true, y_pred):
# 初始化误差
error = 0
# 遍历y_true, y_pred
for yt, yp in zip(y_true, y_pred):
# 计算绝对百分比误差
error += np.abs(yt - yp) / yt
#返回平均绝对百分比误差
return error / len(y_true)
回归的最大优点是, 只有几个最常用的指标, 几乎可以应用于所有回归问题。与分类指标相比, 回归指标更容易理解。
2.3.7 R2
回归指标 R²(R方), 也称为判定系数。
简单地说, R方表示模型与数据的拟合程度。R方接近 1.0 表示模型与数据的拟合程度相当好, 而接近 0 则表示模型不是那么好。当模型只是做出荒谬的预测时, R方也可能是负值。
import numpy as np
def r2(y_true, y_pred):
# 计算平均真实值
mean_true_value = np.mean(y_true)
# 初始化平方误差
numerator = 0
denominator = 0
# 遍历y_true, y_pred
for yt, yp in zip(y_true, y_pred):
numerator += (yt - yp) ** 2
denominator += (yt - mean_true_value) ** 2
ratio = numerator / denominator
# 计算R方
return 1 – ratio
2.4 二次加权卡帕
也称为 QWK。它也被称为科恩卡帕。QWK 衡量两个"评分"之间的"一致性"。评分可以是 0 到 N 之间的任何实数, 预测也在同一范围内。一致性可以定义为这些评级之间的接近程度。因此, 它适用于有 N 个不同类别的分类问题。如果一致度高, 分数就更接近 1.0。Cohen’s kappa 在 scikit-learn 中有很好的实现。
from sklearn import metrics
y_true = [1, 2, 3, 1, 2, 3, 1, 2, 3]
y_pred = [2, 1, 3, 1, 2, 3, 3, 1, 2]
metrics.cohen_kappa_score(y_true, y_pred, weights="quadratic")
# 0.33333333333333337
metrics.accuracy_score(y_true, y_pred)
# 0.4444444444444444
可以看到, 尽管准确度很高, 但 QWK 却很低。QWK 大于 0.85 即为非常好!
一个重要的指标是马修相关系数(MCC)。1 代表完美预测, -1 代表不完美预测, 0 代表随机预测。MCC 的计算公式非常简单。
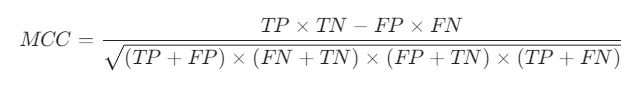
def mcc(y_true, y_pred):
# 真阳性样本数
tp = true_positive(y_true, y_pred)
# 真阴性样本数
tn = true_negative(y_true, y_pred)
# 假阳性样本数
fp = false_positive(y_true, y_pred)
# 假阴性样本数
fn = false_negative(y_true, y_pred)
numerator = (tp * tn) - (fp * fn)
denominator = (
(tp + fp) *
(fn + tn) *
(fp + tn) *
(tp + fn)
)
denominator = denominator ** 0.5
return numerator/denominator
在评估非监督方法(例如某种聚类)时, 最好创建或手动标记测试集, 并将其与建模部分的所有内容分开。完成聚类后, 就可以使用任何一种监督学习指标来评估测试集的性能了。
3. 分类变量
分类变量/特征是指任何特征类型, 可分为两大类:
- 无序
- 有序
就定义而言, 我们也可以将分类变量分为二元变量, 即只有两个类别的分类变量。有些人甚至把分类变量称为"循环"变量。周期变量以"周期"的形式存在, 例如一周中的天数: 周日、周一、周二、周三、周四、周五和周六。周六过后, 又是周日。这就是一个循环。另一个例子是一天中的小时数, 如果我们将它们视为类别的话。
3.1 无序变量
无序变量是指有两个或两个以上类别的变量, 这些类别没有任何相关顺序。例如, 如果将性别分为两组, 即男性和女性, 则可将其视为名义变量。
3.2 有序变量
有序变量则有"等级"或类别, 并有特定的顺序。例如, 一个顺序分类变量可以是一个具有低、中、高三个不同等级的特征。顺序很重要。
3.3 标签编码
标签编码d(abel Encoding)我们将每个类别编码为一个数字标签。我们也可以使用 scikit-learn 中的 LabelEncoder 进行编码。
import pandas as pd
from sklearn import preprocessing
df = pd.read_csv("../../data/cat-in-the-dat-2/train.csv")
# scikit-learn 的 LabelEncoder 无法处理 NaN 值
df.loc[:,"ord_2"] = df.ord_2.fillna("NONE")
lbl_enc = preprocessing.LabelEncoder()
df.loc[:,"ord_2"] = lbl_enc.fit_transform(df.ord_2.values)
可以在许多基于树的模型中直接使用它:
- 决策树
- 随机森林
- 提升树
- 或任何一种提升树模型
- XGBoost
- GBM
- LightGBM
这种编码方式不能用于线性模型、支持向量机或神经网络, 因为它们希望数据是标准化的。
3.3.1 二值化d(inarize)处理
这只是将类别转换为数字, 然后再转换为二值化表示。这样, 我们就把一个特征分成了三个d(本例中)特征d(列)。如果我们有更多的类别, 最终可能会分成更多的列。
Freezing --> 0 --> 0 0 0
Warm --> 1 --> 0 0 1
Cold --> 2 --> 0 1 0
Boiling Hot --> 3 --> 0 1 1
Hot --> 4 --> 1 0 0
Lava Hot --> 5 --> 1 0 1
如果我们用稀疏格式存储大量二值化变量, 就可以轻松地存储这些变量。稀疏格式不过是一种在内存中存储数据的表示或方式, 在这种格式中, 你并不存储所有的值, 而只存储重要的值。在上述二进制变量的情况中, 最重要的就是有 1 的地方。
3.3.2 独热编码
独热编码也是一种二值编码, 因为只有 0 和 1 两个值。但必须注意的是, 它并不是二值表示法。我们可以通过下面的例子来理解它的表示法。
import numpy as np
from sklearn import preprocessing
example = np.random.randint(1000, size=1000000)
ohe = preprocessing.OneHotEncoder(sparse=False)
ohe_example = ohe.fit_transform(example.reshape(-1, 1))
print(f"Size of dense array: {ohe_example.nbytes}")
# 独热编码, 稀疏矩阵
ohe = preprocessing.OneHotEncoder(sparse=True)
# 将随机数组展平
ohe_example = ohe.fit_transform(example.reshape(-1, 1))
print(f"Size of sparse array: {ohe_example.data.nbytes}")
full_size = (
ohe_example.data.nbytes +
ohe_example.indptr.nbytes +
ohe_example.indices.nbytes
)
print(f"Full size of sparse array: {full_size}")
应该把哪些类别结合起来呢? 这并没有一个简单的答案。这取决于您的数据和特征类型。一些领域知识对于创建这样的特征可能很有用。但是, 如果你不担心内存和 CPU 的使用, 你可以采用一种贪婪的方法, 即创建许多这样的组合, 然后使用一个模型来决定哪些特征是有用的, 并保留它们。
第一个术语是 TPR 或真阳性率(True Positive Rate), 它与召回率相同: TPR=TP/(TP+FN)
FPR 或假阳性率(False Positive Rate)的定义是: FPR=FP/(TN+FP)
1 - FPR 被称为特异性或真阴性率或 TNR。
4. 特征工程
4.1 特征提取
只有当你对问题的领域有一定的了解, 并且在很大程度上取决于相关数据时, 才能以最佳方式完成特征工程。不过, 可以尝试使用一些通用技术, 从几乎所有类型的数值变量和分类变量中创建特征。特征工程不仅仅是从数据中创建新特征, 还包括不同类型的归一化和转换。
在处理时间序列数据时, 日期时间特征非常重要, 例如, 在预测一家商店的销售额时, 如果想在聚合特征上使用 xgboost 等模型, 日期时间特征就非常重要。
4.2 统计特征
- 平均值
- 最大值
- 最小值
- 独特性
- 偏斜
- 峰度
- Kstat
- 百分位数
- 定量
- 峰值到峰值
- 以及更多
4.3 特征转换
时间序列数据(数值列表)可以转换成许多特征。在这种情况下, 一个名为 tsfresh 的 python 库非常有用。tsfresh 提供了数百种特征和数十种不同特征的变体, 你可以将它们用于基于时间序列(值列表)的特征。
from tsfresh.feature_extraction import feature_calculators as fc
# 计算 x 数列的绝对能量(abs_energy), 并将结果存储在 feature_dict 字典中的 'abs_energy' 键下
feature_dict['abs_energy'] = fc.abs_energy(x)
# 计算 x 数列中高于均值的数据点数量, 将结果存储在 feature_dict 字典中的 'count_above_mean' 键下
feature_dict['count_above_mean'] = fc.count_above_mean(x)
# 计算 x 数列中低于均值的数据点数量, 将结果存储在 feature_dict 字典中的 'count_below_mean' 键下
feature_dict['count_below_mean'] = fc.count_below_mean(x)
# 计算 x 数列的均值绝对变化(mean_abs_change), 并将结果存储在 feature_dict 字典中的 'mean_abs_change' 键下
feature_dict['mean_abs_change'] = fc.mean_abs_change(x)
# 计算 x 数列的均值变化率(mean_change), 并将结果存储在 feature_dict 字典中的 'mean_change' 键下
feature_dict['mean_change'] = fc.mean_change(x)
可以使用 scikit-learn 的 PolynomialFeatures 创建两次多项式特征。
另一个有趣的功能是将数字转换为类别。这就是所谓的分箱。
另一种可以从数值特征中创建的有趣特征类型是对数变换。
有时, 也可以用指数来代替对数。一种非常有趣的情况是, 您使用基于对数的评估指标, 例如 RMSLE。
4.4 缺失值
在处理分类变量和数值变量时, 可能会遇到缺失值。在上一章中, 我们介绍了一些处理分类特征中缺失值的方法, 但还有更多方法可以处理缺失值/NaN 值。这也被视为特征工程。
填补缺失值的一种高级方法是使用 K 近邻法。 您可以选择一个有缺失值的样本, 然后利用某种距离度量(例如欧氏距离)找到最近的邻居。然后取所有近邻的平均值来填补缺失值。您可以使用 KNN 来填补这样的缺失值。
import numpy as np
from sklearn import impute
X = np.random.randint(1, 15, (10, 6))
X = X.astype(float)
X.ravel()[np.random.choice(X.size, 10, replace=False)] = np.nan
knn_imputer = impute.KNNImputer(n_neighbors=2)
knn_imputer.fit_transform(X)
另一种弥补列缺失值的方法是训练回归模型, 试图根据其他列预测某列的缺失值。因此, 您可以从有缺失值的一列开始, 将这一列作为无缺失值回归模型的目标列。
对于基于树的模型, 没有必要进行数值归一化, 因为它们可以自行处理。
5 特征选择
5.1 删除方差非常小的特征
绝不应该创建成百上千个无用的特征。特征过多会带来一个众所周知的问题, 即 “维度诅咒”。
选择特征的最简单方法是删除方差非常小的特征。如果特征的方差非常小(即非常接近于 0), 它们就接近于常量, 因此根本不会给任何模型增加任何价值。
from sklearn.feature_selection import VarianceThreshold
data = ...
# 创建 VarianceThreshold 对象 var_thresh, 指定方差阈值为 0.1
var_thresh = VarianceThreshold(threshold=0.1)
# 使用 var_thresh 对数据 data 进行拟合和变换, 将方差低于阈值的特征移除
transformed_data = var_thresh.fit_transform(data)
5.2 删除相关性较高的特征
我们还可以删除相关性较高的特征。要计算不同数字特征之间的相关性, 可以使用皮尔逊相关性。
import pandas as pd
from sklearn.datasets import fetch_california_housing
# 加载数据
data = fetch_california_housing()
# 从数据集中提取特征矩阵 X
X = data["data"]
# 从数据集中提取特征的列名
col_names = data["feature_names"]
# 从数据集中提取目标变量 y
y = data["target"]
df = pd.DataFrame(X, columns=col_names)
# 添加 MedInc_Sqrt 列, 是 MedInc 列中每个元素进行平方根运算的结果
df.loc[:, "MedInc_Sqrt"] = df.MedInc.apply(np.sqrt)
# 计算皮尔逊相关性矩阵
df.corr()
5.3 单变量特征选择方法
单变量特征选择只不过是针对给定目标对每个特征进行评分。互信息、方差分析 F 检验和卡方检验 是一些最常用的单变量特征选择方法。在 scikit-learn 中, 有两种方法可以使用这些方法。
必须注意的是, 只有非负数据才能使用卡方检验。在自然语言处理中, 当我们有一些单词或基于 tf-idf 的特征时, 这是一种特别有用的特征选择技术。最好为单变量特征选择创建一个包装器, 几乎可以用于任何新问题。
请注意, 创建较少而重要的特征通常比创建数以百计的特征要好。单变量特征选择不一定总是表现良好。大多数情况下, 人们更喜欢使用机器学习模型进行特征选择。
5.3.1 使用模型进行特征选择
使用模型进行特征选择的最简单形式被称为贪婪特征选择。在贪婪特征选择中, 第一步是选择一个模型。第二步是选择损失/评分函数。第三步也是最后一步是反复评估每个特征, 如果能提高损失/评分, 就将其添加到 “好 “特征列表中。这种贪婪特征选择方法会返回分数和特征索引列表。
另一种贪婪的方法被称为递归特征消除法(RFE)。在前一种方法中, 我们从一个特征开始, 然后不断添加新的特征, 但在 RFE 中, 我们从所有特征开始, 在每次迭代中不断去除一个对给定模型提供最小值的特征。但我们如何知道哪个特征的价值最小呢?如果我们使用线性支持向量机(SVM)或逻辑回归等模型, 我们会为每个特征得到一个系数, 该系数决定了特征的重要性。而对于任何基于树的模型, 我们得到的是特征重要性, 而不是系数。在每次迭代中, 我们都可以剔除最不重要的特征, 直到达到所需的特征数量为止。因此, 我们可以决定要保留多少特征。
也可以根据数据拟合模型, 然后通过特征系数或特征的重要性从模型中选择特征。如果使用系数, 则可以选择一个阈值, 如果系数高于该阈值, 则可以保留该特征, 否则将其剔除。
可以从一个模型中选择特征, 然后使用另一个模型进行训练。例如, 你可以使用逻辑回归系数来选择特征, 然后使用随机森林(Random Forest)对所选特征进行模型训练。Scikit-learn 还提供了 SelectFromModel 类, 可以帮助你直接从给定的模型中选择特征。
使用 L1(Lasso)惩罚模型进行特征选择。当我们使用 L1 惩罚进行正则化时, 大部分系数都将为 0(或接近 0), 因此我们要选择系数不为 0 的特征。只需将模型选择片段中的随机森林替换为支持 L1 惩罚的模型(如 lasso 回归)即可。所有基于树的模型都提供特征重要性。
参考:
AAAMLP-CN
Approaching (Almost) Any Machine Learning Problem
