
目录
视觉语言模型是可以同时从图像和文本中学习以处理许多任务的模型, 从视觉问答到图像描述。
视觉语言模型被广泛定义为可以从图像和文本中学习的多模态模型。它们是一种生成模型, 用于获取图像和文本输入, 并生成文本输出。大型视觉语言模型具有良好的零样本功能, 泛化性好, 并且可以处理多种类型的图像, 包括文档、网页等。这些使用案例包括聊天图像、通过说明进行图像识别、视觉问答、文档理解、图像字幕等。一些视觉语言模型还可以捕获图像中的空间属性。这些模型可以在提示检测或分割特定主题时输出边界框或分割掩码, 或者它们可以定位不同的实体或回答有关其相对或绝对位置的问题。现有的大型视觉语言模型集、它们训练的数据、它们如何编码图像以及它们的能力都有很多多样性。
1. 基础
1.1 跨模态基准
- VQAv2: 视觉问答
- OK-VQ
- TextVQA
- ST-VQA
- ChartQA
- infoVQA
- DocVQA
- MM-Vet
- POPE
- MathVista: 视觉数学推理
- AI2D: 图表理解
- OCRBench: 文档理解
- ScienceQA: 科学问答
- MMMU: 评估视觉语言模型的最全面的基准。它包含 11.5K 个多模态挑战, 需要跨艺术和工程等不同学科的大学水平学科知识和推理。
Vision Arena 是一个完全基于模型输出匿名投票的排行榜, 并且会持续更新。在这个领域中, 用户输入图像和提示, 两个不同模型的输出被匿名采样, 然后用户可以选择他们喜欢的输出。这样, 排行榜就完全根据人类的偏好构建。
Open VLM Leaderboard 是另一个排行榜, 其中各种视觉语言模型根据这些指标和平均分数进行排名。您还可以根据模型大小、专有或开源许可证筛选模型, 并针对不同的指标进行排名。
1.2 技术细节
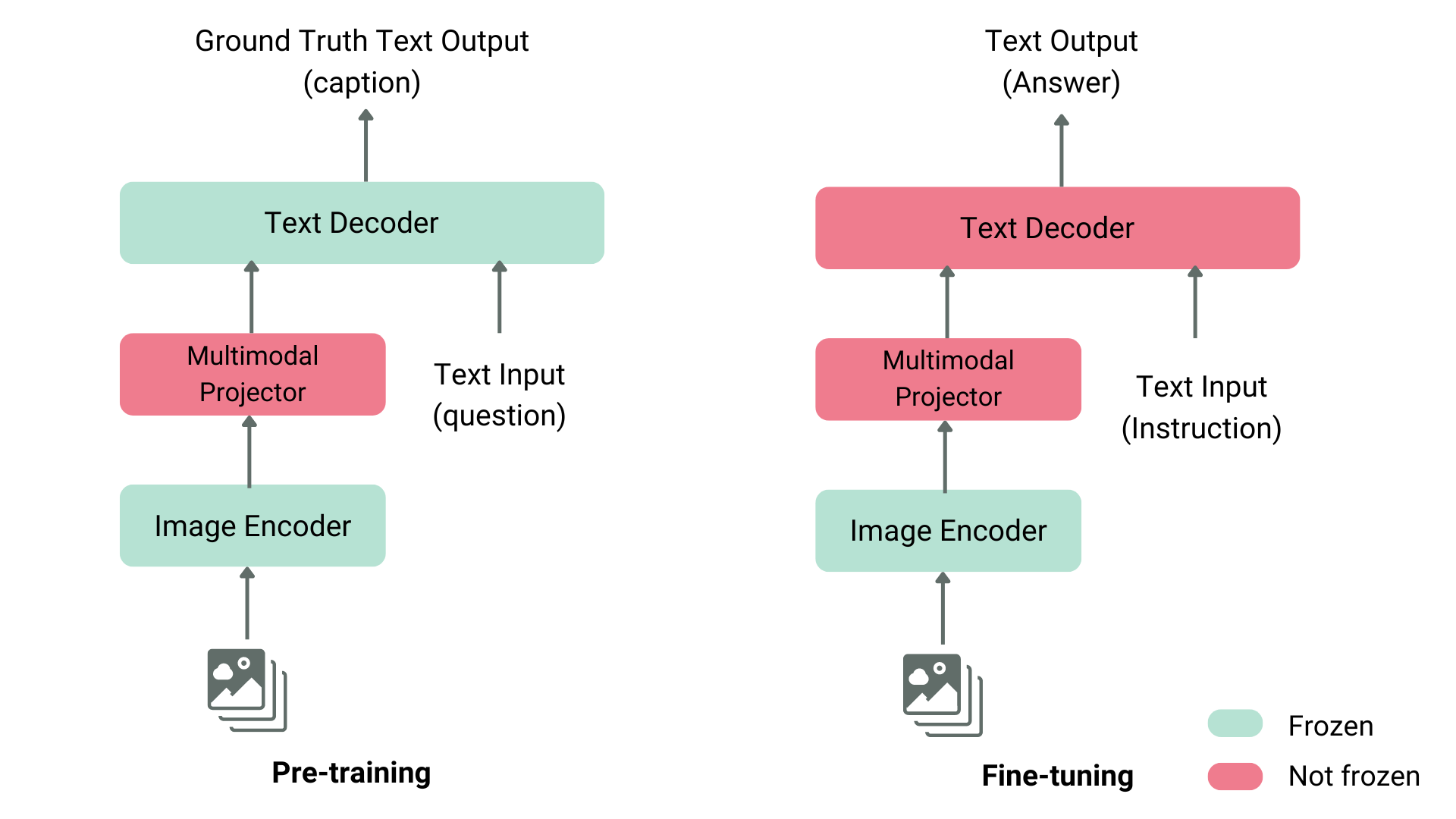
有多种方法可以预训练 Vision Language 模型。主要技巧是统一图像和文本表示, 并将其提供给文本解码器进行生成。最常见和最突出的模型通常由一个图像编码器、一个用于对齐图像和文本表示的嵌入投影仪(通常是一个密集的神经网络)和一个按此顺序堆叠的文本解码器组成。至于训练部分, 不同的模型一直遵循不同的方法。
例如, LLaVA 由一个 CLIP 图像编码器、一个多模态投影仪和一个 Vicuna 文本解码器组成。作者将图像和标题的数据集提供给 GPT-4, 并生成了与标题和图像相关的问题。作者冻结了图像编码器和文本解码器, 并且仅通过向模型提供图像和生成的问题并将模型输出与真实字幕进行比较来训练多模态投影仪来对齐图像和文本特征。投影仪预训练后, 他们保持图像编码器冻结, 解冻文本解码器, 并使用解码器训练投影仪。这种预训练和微调方式是训练视觉语言模型的最常见方式。
1.3 OpenAI的API接口
Doc: https://platform.openai.com/docs/guides/vision
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "What’s in this image?"},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
},
],
}
],
max_tokens=300,
)
print(response.choices[0])
import base64
import requests
# OpenAI API Key
api_key = "YOUR_OPENAI_API_KEY"
# Function to encode the image
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
# Path to your image
image_path = "path_to_your_image.jpg"
# Getting the base64 string
base64_image = encode_image(image_path)
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
payload = {
"model": "gpt-4-vision-preview",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What’s in this image?"
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
}
]
}
],
"max_tokens": 300
}
response = requests.post("https://api.openai.com/v1/chat/completions", headers=headers, json=payload)
print(response.json())
1.4 Vision Model
1.4.1 LLaVA-1.5
模型的训练, 只需要8个A100就可以在1天内完成。LaVA表现出一些接近GPT-4水平的多模态能力,
在视觉聊天方面, GPT-4相对评分85%。
而在推理问答方面, LLaVA甚至达到了新SoTA——92.53%, 击败多模态思维链。
在视觉推理上, 它的表现十分抢眼。
从图中提取信息, 按照要求的格式进行回答, 比如以JSON格式输出。
OCR识别
通用 LLaVa 架构:
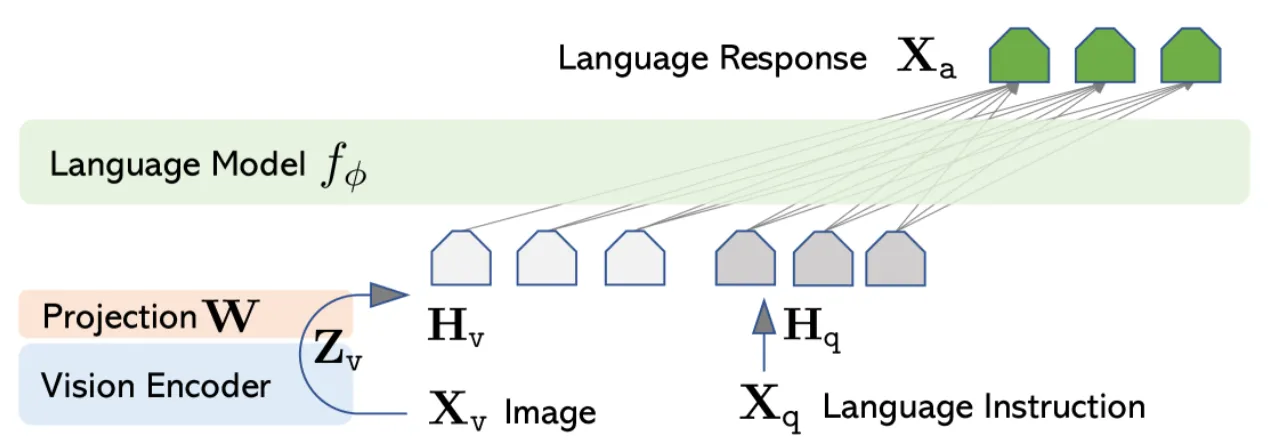
1.4.2 LLaVA-NeXT
与LLaVA-1.5相比, LLaVA-NeXT有几点改进:
- 将输入图像分辨率提高到 4 倍以上的像素。这使它能够掌握更多的视觉细节。它支持三种纵横比, 最高分辨率为 672x672、336x1344、1344x336。
- 更好的视觉推理和 OCR 功能, 以及改进的视觉指令调整数据组合。
- 更好的可视化对话, 适用于更多场景, 涵盖不同的应用程序。更好的世界知识和逻辑推理。
- 使用 SGLang 进行高效部署和推理。
除了性能改进外, LLaVA-NeXT 还保持了 LLaVA-1.5 的极简设计和数据效率。它重用了 LLaVA-1.5 的预训练连接器, 仍然使用不到 1M 的视觉指令调优样本。最大的 34B 变体在 ~1 天内完成训练, 配备 32 架 A100。代码、数据、模型将公开提供。
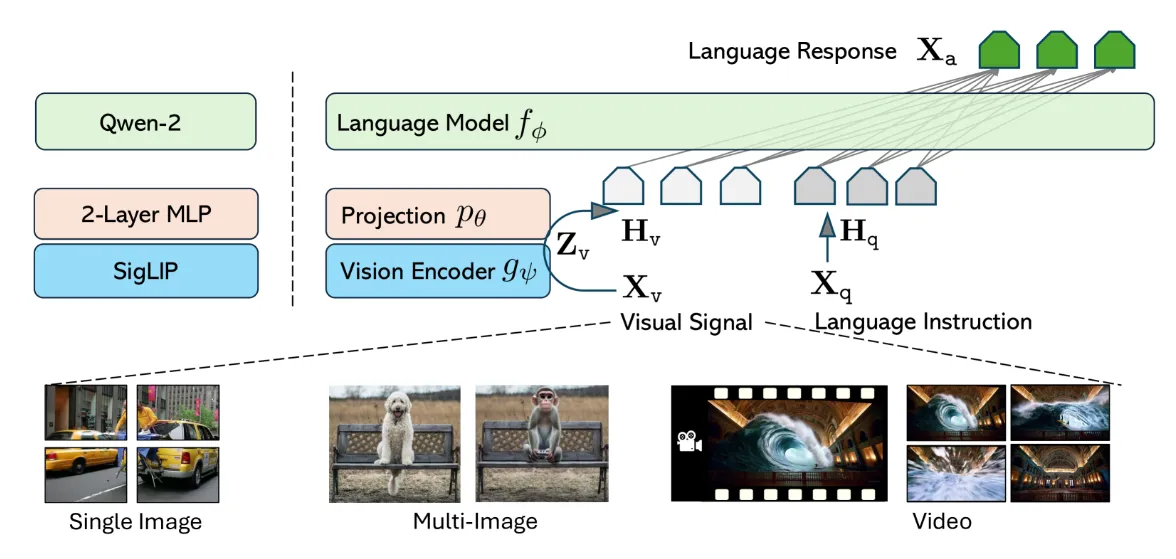
1.4.3 LLaVA-OneVision 架构
为了实现融合, LLaVA-OneVision 架构使用了 MLP。原始 LLaVA 模型使用线性投影。MLP 是一种特殊类型——全连接前馈神经网络。MLP 能够学习和表示数据中复杂的非线性关系。
与使用图像和文本进行训练的 CLIP 或 LLaVA 不同, LLaVA-OneVison 使用图像/视频 + 文本进行训练。
简单的伪代码传达了这个想法:
# Multimodal fusion approaches using cross-attention:
class CrossModalAttention(nn.Module):
def __init__(self): super().__init__()
self.vision_proj = nn.Linear(768, 512) # Project vision features
self.text_proj = nn.Linear(4096, 512) # Project text features self.
Attention = nn.MultiheadAttention(512, 8)
1.4.4 具有交叉注意力的多模态融合
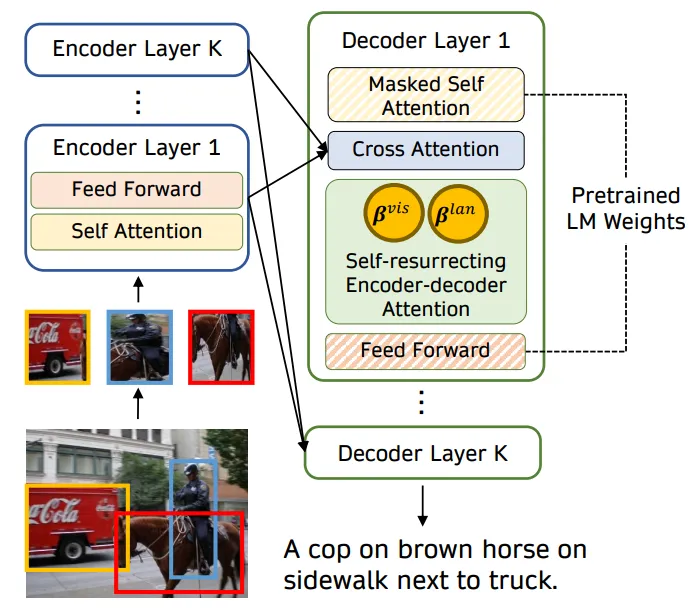
多模态融合与交叉注意力策略侧重于跨模态最相关的元素。这种方法允许系统以上下文精度理解多模态输入之间的复杂关系。
交叉注意力使用查询键值系统, 其中查询来自一种模态(例如, 文本短语), 键/值来自另一种模态(例如, 图像区域)。
1.4.5 现代 VLM 架构趋势
- 统一编码器: LLaVA-1.5 等模型通过投影矩阵将 ViT 与 LLM 结合起来, 而不是维护单独的编码器。
- 跨模态预训练: Gemini 的架构通过专家混合方法实现视觉/语言组件之间的动态路由。
- 融合层演进/训练范式转变: 现代 VLM 已经超越了简单的图像-文本对, 转向了使用多模态提示进行指令调整。指令调整对于带有文本提示的 LLM 来说很常见。同样的概念也适用于具有多模态提示的 VLM。
开发多模态 LLM 架构的两种主要方法
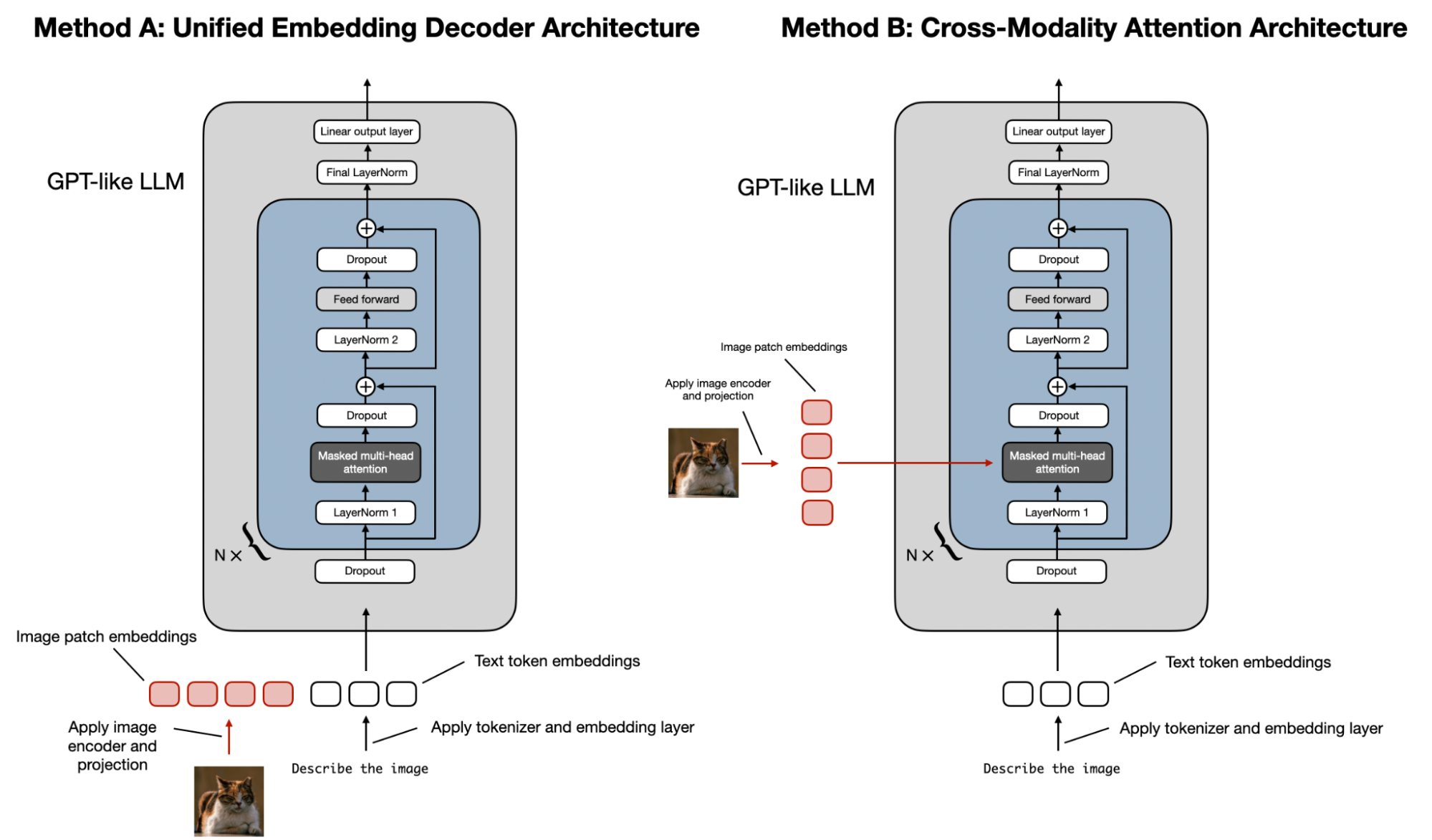
- 统一嵌入-解码器架构使用单一解码器模型, 很像未经修改的 LLM 架构, 例如 GPT-2 或 Llama 3.2。在这种方法中, 图像被转换为与原始文本标记具有相同嵌入大小的标记, 允许 LLM 在串联后同时处理文本和图像输入标记。
- 跨模态注意力架构采用交叉注意力机制, 将图像和文本嵌入直接集成到注意力层中。
1.5 Vision Model Prompt
VLM 通常使用交叉注意力等技术, 使用在同一表示或矢量空间中对齐图像和文本表示的机制进行训练。此类系统的优点是您可以通过文本作为方便的界面进行交互或“查询”图像。由于其多模态能力, VLM 对于弥合文本和视觉数据之间的差距至关重要, 从而开辟了纯文本模型无法解决的大量用例。
1.5.1 零样本提示
零样本提示表示用户仅通过系统和用户提示提供任务描述以及要处理的图像的场景。在此设置中, VLM 仅依赖于任务描述来生成输出。如果我们要根据提供给 VLM 的信息量对谱系上的提示方法进行分类, 则零样本提示向模型提供的信息量最少。
{
"role": "system",
"content": "You are a helpful assistant that can analyze images and provide captions."
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "Please analyze the following image:"
},
{
"type": "image_url",
"image_url": {
"url": "data:image/jpeg;base64,{base64_image}",
"detail": "detail"
}
}
]
}
1.5.2 少样本提示
Few-Shot Prompting 涉及提供任务的示例或演示作为 VLM 的上下文, 以便为模型提供有关要执行的任务的更多参考和上下文。
def build_few_shot_messages(few_shot_prompt, user_prompt = "Please analyze the following image:", detail="auto"):
"""
Generates few-shot example messages from image-caption pairs.
Args:
few_shot_prompt(dict): A dictionary mapping image paths to metadata,
including "image_caption".
detail(str, optional): Level of image detail to include. Defaults to "auto".
Returns:
list: A list of few-shot example messages.
"""
few_shot_messages = []
for path, data in few_shot_prompt.items():
base64_image = encode_image(path)
if not base64_image:
continue # skip if failed to encode
caption = data
few_shot_messages.append(
{
"role": "user",
"content": [
{"type": "text", "text": user_prompt},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}",
"detail": detail
}
},
]
}
)
few_shot_messages.append({"role": "assistant", "content": caption})
return few_shot_messages
用户可以通过仔细选择少镜头样本来指导模型的输出更接近他们喜欢的风格、色调或细节量。
1.5.3 思维链提示
思维链(CoT)提示最初是为LLM开发的, 它使他们能够解决复杂的问题, 方法是将复杂的问题分解为更简单的中间步骤, 并鼓励模型在回答之前“思考”。该技术无需任何调整即可应用于VLM。主要区别在于, VLM 在 CoT 下推理回答问题时, 可以使用图像和文本作为输入。
1.6 视觉转换器
Vision Transformer(ViT)采用了 Transformer 架构(最初设计用于处理顺序数据)来理解非顺序数据。
超越语言的生成式人工智能: ViT 现在支持许多最先进的计算机视觉人工智能模型, 提供超越传统卷积神经网络(CNN)的功能。
1.6.1 ViT vs CNN
在 ViT 之前, CNN 主导计算机视觉, 但针对特定任务。对于每个基本视觉任务, 都有专门的CNN模型架构: 图像分类、对象检测、分割等。
ViT 用途广泛, 通过微调带来统一的架构, 可适应多种视觉任务。他们完成上述所有视觉任务以及更多任务——有时会进行一些修改。
以前, CNN 分析局部图像区域, 但遗漏了全局像素关系。CNN 使用卷积一次处理一个小区域的输入数据。这意味着它们还面临着远程依赖关系的挑战, 例如彼此不靠近的像素之间的关系。
ViT 可以广泛理解图像内容, 并克服 CNN 的这些限制。LVM(现代计算机视觉模型)越来越多地建立在基于 ViT 的架构之上。
然而, 总是有权衡的。CNN 从事专门任务, 需要更小的数据集和更低的计算能力。相比之下, 灵活且上下文丰富的 ViT 可能需要更大的数据集和更高的计算能力。
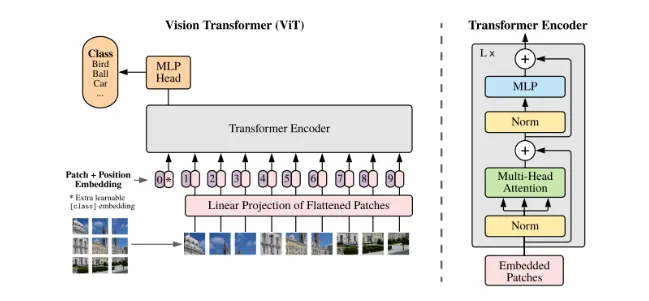
1.6.2 ViT
ViT 架构主要组件细分:
- 补丁嵌入
- 位置嵌入
- 注意力层
- 多头注意力
- MLP(多层感知器)块
- Softmax
2. Model分类
2.1 Any-to-Any Model
顾名思义, Any-to-Any模型是可以采用任何模态并输出任何模态(图像、文本、音频)的模型。它们通过对齐模态来实现这一点, 其中来自一种模态的输入可以被翻译成另一种模态(例如,“dog"一词将与狗的形象或单词的发音相关联)。
这些模型具有多个编码器(每个模态一个), 然后将嵌入融合在一起以创建一个共享的表示空间。解码器(多个或单个)使用共享的潜在空间作为输入, 并解码为所选的模态。最早尝试构建任意对任意模型的是 Meta 的 Chameleon, 它可以接收图像和文本并输出图像和文本。在这个模型中, Meta 没有发布图像生成功能, 因此 Alpha-VLLM 发布了 Lumina-mGPT, 它在 Chameleon 之上构建了图像生成。
最新、功能最强大的 any-to-any 模型 Qwen 2.5 Omni(下图)是理解 any-to-any 模型架构的一个很好的例子。
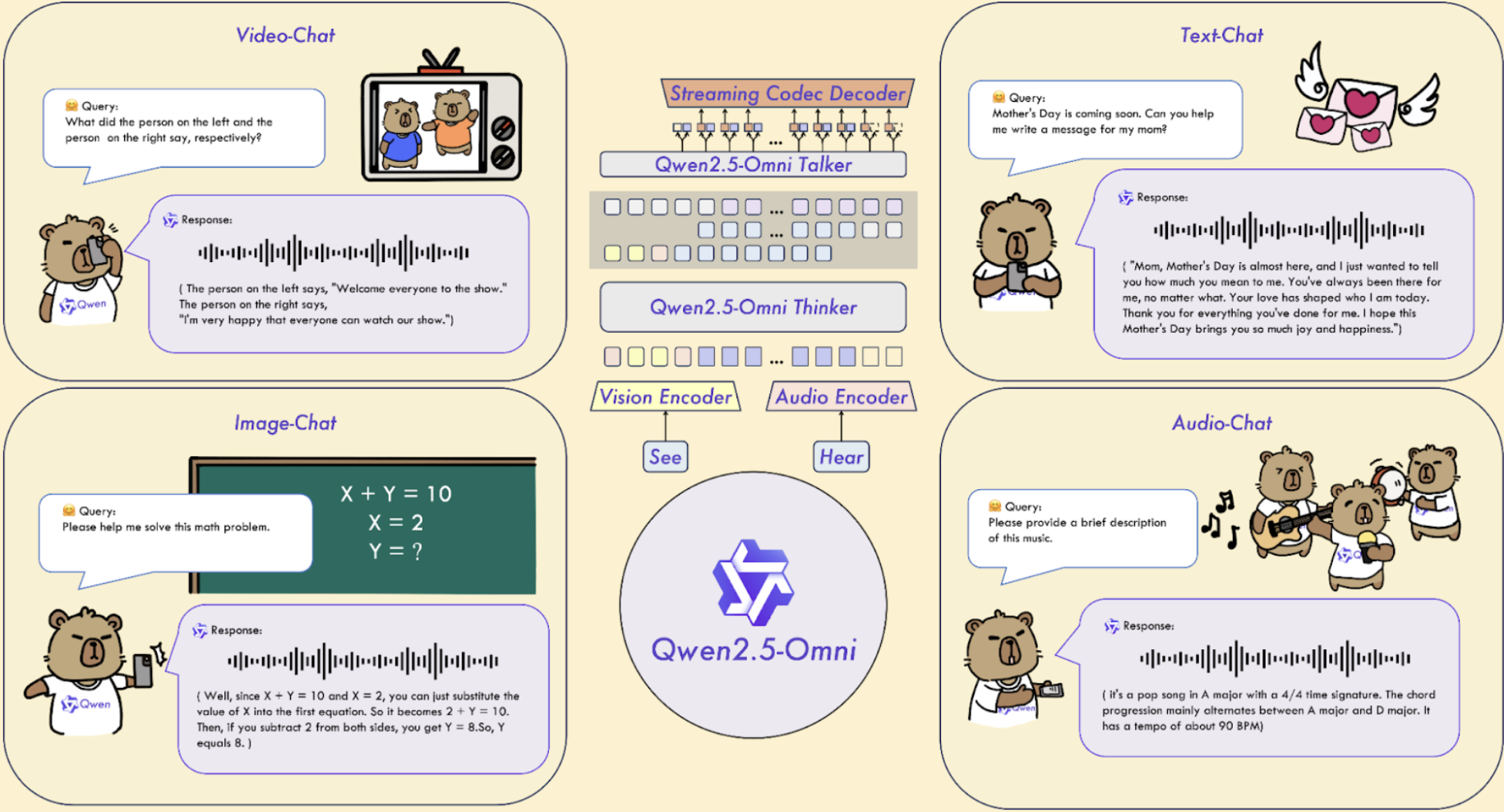
Qwen2.5-Omni 采用了一种新颖的"Thinker-Talker” 架构, 其中"Thinker" 处理文本生成, 而"Talker" 以流式方式产生自然的语音响应。MiniCPM-o 2.6 是一种 8B 参数多模态模型, 能够理解和生成跨视觉、语音和语言模态的内容。由 DeepSeek AI 推出的 Janus-Pro-7B 是一个统一的多模态模型, 在理解和生成跨模态内容方面表现出色。它具有解耦的视觉编码架构, 将理解和生成过程分开。
2.2 推理模型
推理模型是可以解决复杂问题的模型。我们首先看到它们使用大型语言模型, 现在是视觉语言模型。直到 2025 年, 只有一个开源的多模态推理模型, 即 Qwen 的 QVQ-72B-preview。这是由阿里巴巴 Qwen 团队开发的实验模型, 并附带许多免责声明。
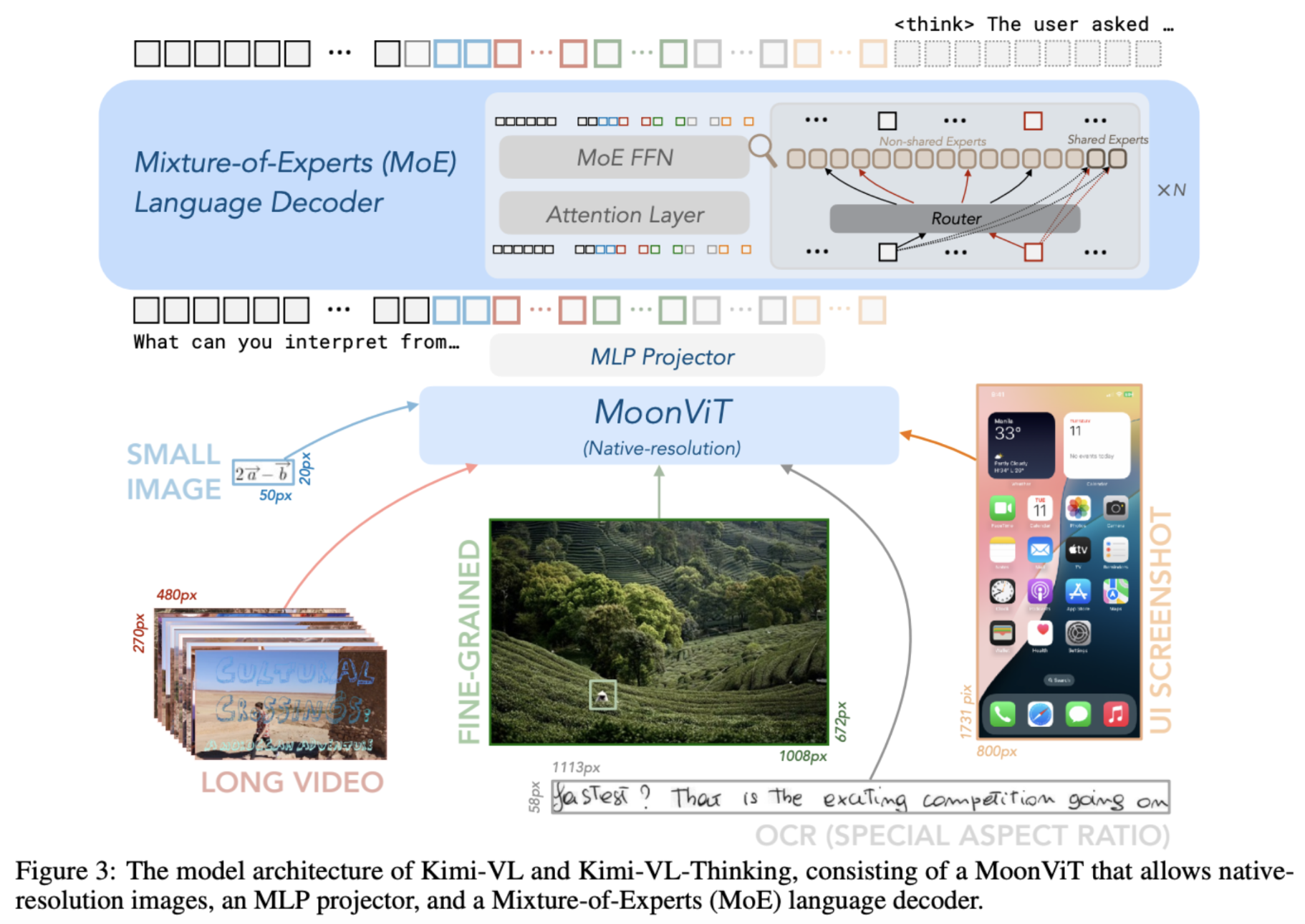
今年还有另一个参与者, Moonshot AI 团队的 Kimi-VL-A3B-Thinking。它由作为图像编码器的 MoonViT(SigLIP-so-400M) 和一个具有 16B 总参数和只有 2.8B 活动参数的专家混合(MoE) 解码器组成。该模型是 Kimi-VL 基本视觉语言模型的长思维链微调和进一步对齐(强化学习)版本。
2.3 Smol 但功能强大的模型
该社区过去常常通过参数数量和高质量的合成数据来扩展情报。在某个时间点之后, 基准饱和和缩放模型的收益递减。社区通过各种方法(如蒸馏)来缩小更大的模型。这是有道理的, 因为它降低了计算成本, 简化了部署, 并解锁了本地执行等使用案例, 从而增强了数据隐私。
当我们说小型视觉语言模型时, 我们通常指的是参数小于 2B 的模型, 这些模型可以在消费类 GPU 上运行。SmolVLM 是较小视觉语言模型的一个很好的示例模型系列。与其缩小更大的模型, 不如一路尝试将模型拟合到少量参数中, 例如 256M、500M 和 2.2B。例如, SmolVLM2 试图解决这些大小的视频理解问题, 发现 500M 是一个很好的权衡。在 Hugging Face, 我们构建了一个 iPhone 应用程序 HuggingSnap, 以证明这些模型大小可以在消费类设备上实现视频理解。
另一个引人注目的模型是 Google DeepMind 的 gemma3-1b-it。这特别令人兴奋, 因为它是最小的多模态模型之一, 具有 32k 标记上下文窗口, 并支持 140+ 种语言。该模型带有 Gemma 3 系列模型, 其最大的模型在当时的 Chatbot Arena 上排名第一。然后将最大的模型蒸馏成 1B 变体。
最后, 虽然不是最小的, 但 Qwen2.5-VL-3B-Instruct 值得注意。该模型可以执行各种任务, 从定位(对象检测和指向)到文档理解, 再到代理任务;上下文长度高达 32k 个令牌。
2.4 作为解码器的专家混合
专家混合(MoE) 模型通过动态选择和激活最相关的子模型(称为"专家")来处理给定的输入数据段, 从而为密集架构提供了一种替代方案。这种选择性激活(由路由器完成)机制已证明具有显著提高模型性能和作效率的潜力, 同时利用更少的计算资源。
MoE 的推理速度比类似的参数密集的对应物更快, 因为可以选择性地激活较小的网络切片。它们在训练期间也会迅速收敛。每件好事都有成本, 因为 MoE 需要更多的内存成本, 因为整个模型都在 GPU 上, 即使使用较小的块也是如此。
在广泛采用的 Transformer 架构中, MoE 层最常见的集成方式是替换每个 Transformer 模块中的标准前馈网络(FFN) 层。密集网络使用整个模型来运行推理, 而类似大小的 MoE 网络会选择性地激活一些专家。这有助于提高计算利用率和加快推理速度。
具有混合专家解码器的视觉语言模型似乎具有增强的性能。例如, Kimi-VL 是目前最先进的开放推理模型, 具有混合专家解码器。Mixture-of-Experts 显示出有希望的结果, MoE-LLaVA 专注于效率和减少幻觉, 而 DeepSeek-VL2 也具有广泛的多模式功能。最新版本的 Llama(Llama 4) 是具有视觉功能的 MoE。MoE 作为解码器是一个很有前途的研究领域, 我们怀疑此类模型会增加。
2.5 视觉-语言-行动模型
VLM 甚至在机器人领域留下了自己的印记!在那里, 它们被称为视觉-语言-行动模型(VLA)。但不要被骗了, 那些主要是带有小胡子和帽子的 VLM。VLA 获取图像和文本指令, 并返回指示机器人直接执行的作的文本。VLA 通过添加作和状态令牌来与物理环境交互和控制物理环境, 从而扩展了视觉语言模型。这些额外的标记表示系统的内部状态(它如何感知环境)、作(它根据命令做什么) 和与时间相关的信息(如任务中的步骤顺序)。这些令牌将附加到视觉语言输入中, 以生成作或策略。
VLA 通常在基本 VLM 之上进行微调。有些人进一步扩展了这个定义, 将 VLA 定义为与真实或数字世界进行视觉交互的任何模型。在此定义中, VLA 可以执行 UI 导航或用于代理工作流。但许多人认为这些应用程序属于 VLM 领域。
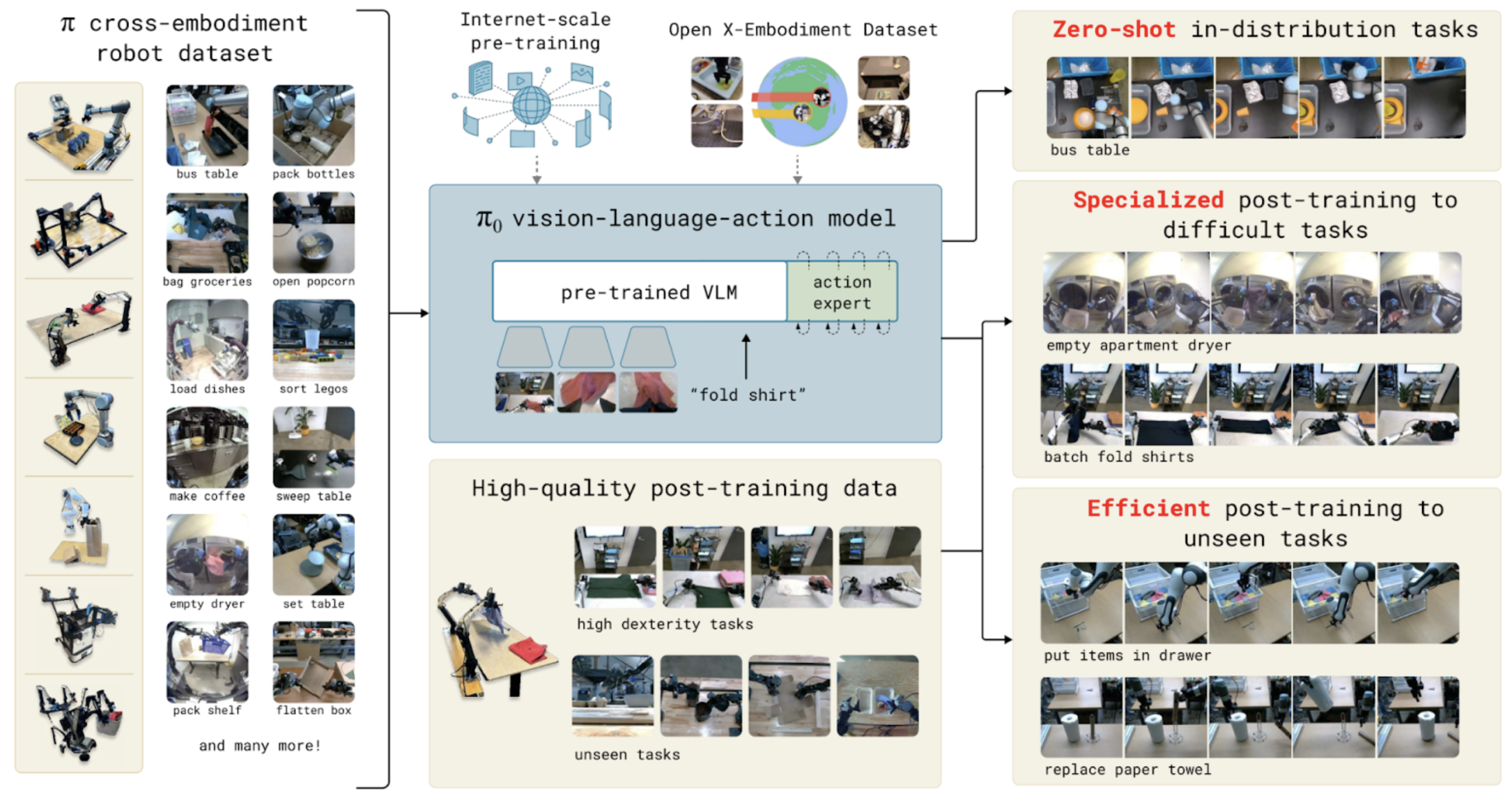
VLA 的一个很好的例子是 π0 和 π0-FAST, 它们是 Physical Intelligence 的第一个机器人基础模型, 移植到 Hugging Face 的 LeRobot 库中。这些模型在 7 个机器人平台和 68 个独特任务中进行了训练。它们在复杂的实际活动(如洗衣折叠、餐桌搬运、杂货店装袋、箱子组装和物品检索)上表现出强大的零镜头和微调性能。
GR00T N1 是 NVIDIA 面向多面手类人机器人的开放式 VLA 基础模型。它理解图像和语言, 并将它们转化为行动, 例如移动手臂或遵循指示, 这要归功于将智能推理与实时运动控制相结合的系统。GR00T N1 还基于 LeRobot 数据集格式构建, 该开放标准旨在简化机器人演示的共享和培训。
3. 专业能力
3.1 使用 Vision Language 模型进行对象检测、分割、计数
VLM 支持对传统计算机视觉任务的泛化。模型现在可以接收图像和各种提示(例如开放式文本), 并输出带有本地化标记的结构化文本(用于检测、分割等)。
去年, PaliGemma 是第一个尝试解决这些任务的模型。该模型采用图像和文本, 其中 text 是相关对象的描述以及任务前缀。文本提示类似于"segment striped cat" 或"detect bird on the roof"。
为了进行检测, 模型将边界框坐标输出为标记。另一方面, 对于分割, 模型会输出检测标记和分割标记。这些分割标记并不都是分割的像素坐标, 而是由经过训练的变分自动编码器解码为有效分割掩码的码簿索引。
在 PaliGemma 之后, 已经引入了许多模型来执行定位任务。去年年底, PaliGemma 的升级版 PaliGemma 2 出现了, 具有相同的功能和更好的性能。后来出现的另一个模型是 Allen AI 的 Molmo, 它可以指向带有点的实例并对对象实例进行计数。
Qwen2.5-VL 还可以检测、指向和计数对象, 这也包括作为对象的 UI 元素!
3.2 多模式安全模型
生产中的视觉语言模型需要过滤输入和输出, 以防止越狱和有害输出以实现合规性。有害内容包括暴力内容和露骨的色情内容。这就是多模态安全模型的用武之地: 它们在视觉语言模型之前和之后使用, 以过滤它们的输入和输出。它们就像 LLM 安全模型一样, 但具有额外的图像输入。
2025 年初, Google 推出了第一个开放式多模式安全模型 ShieldGemma 2。它建立在纯文本安全模型 ShieldGemma 之上。此模型采用图像和内容策略, 并返回图像对于给定策略是否安全。策略是指图像不合适的标准。ShieldGemma 2 还可用于筛选图像生成模型的输出。
Meta 的 Llama Guard 4 是一个密集的多模式和多语言安全模型。它是从 Llama 4 Scout(一种多模式专家混合物)中密集修剪而成的, 并进行了安全微调。
3.3 多模态 RAG: 检索器、重新排序器
现在有多模态检索器和重新排序器。
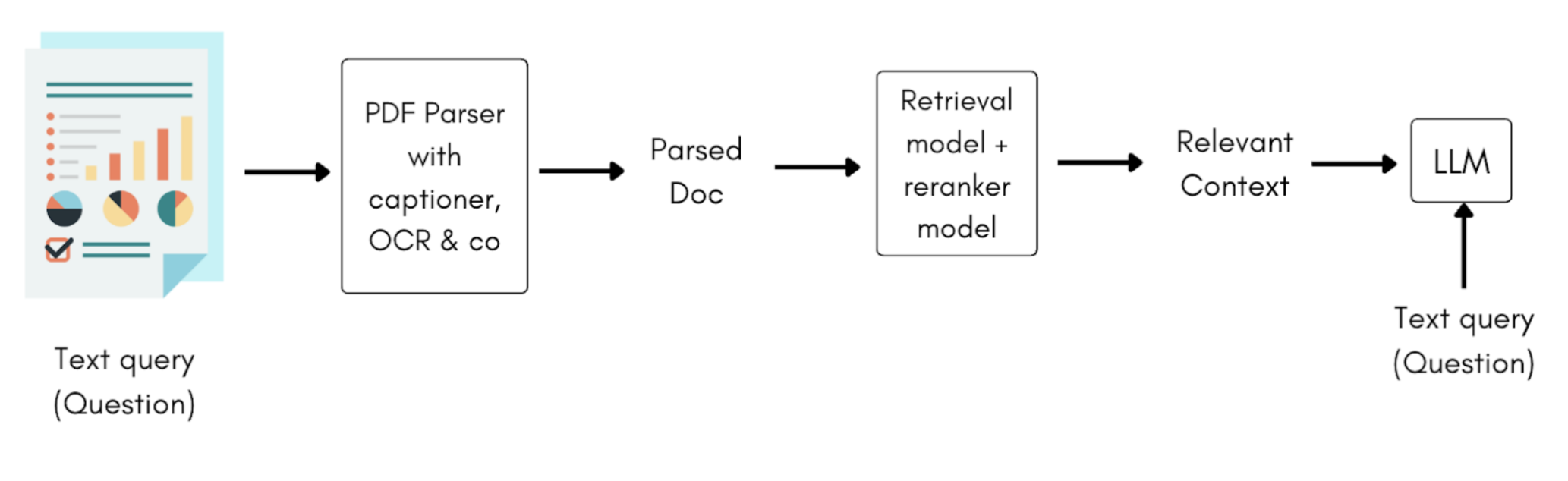
多模态检索器将一堆 PDF 和一个查询作为输入, 并返回最相关的页码及其置信度分数。分数表示页面包含查询答案的可能性, 或查询与页面的相关性。这绕过了 brittle 解析步骤。
然后将最相关的页面与查询一起提供给视觉语言模型, VLM 生成答案。
有两种主要的多模态检索器架构:
- 文档屏幕截图嵌入(DSE、MCDSE)
- 类似 ColBERT 的模型(ColPali、ColQwen2、ColSmolVLM)
DSE 模型由文本编码器和图像编码器组成, 每个查询返回一个向量。返回的分数是嵌入的点积上的 softmax。它们每段返回一个向量。
类似 ColBERT 的模型(如 ColPali)也是双编码器模型, 但有一个不同之处: ColPali 有一个视觉语言模型作为图像编码器, 还有一个大型语言模型作为文本编码器。这些模型本质上不是编码器, 而是模型输出嵌入, 然后将其传递给"MaxSim"。与 DSE 不同, 输出是多个向量, 每个 token 一个。在 MaxSim 中, 计算每个文本标记嵌入和每个图像块嵌入之间的相似性, 这种方法可以更好地捕捉细微差别。由于这个原因, 类似 ColBERT 的模型成本效益较低, 性能更好。
在 Hugging Face Hub 上, 您可以在“Visual Document Retrieval”任务下找到这些模型。
这项任务最流行的基准是 ViDoRe, 它由英语和法语文件组成, 文件从财务报告、科学数据到行政文件不等。ViDoRe 的每个示例都包含文档图像、查询和可能的答案。与查询匹配的文档有助于对比预训练, 因此 ViDoRe 训练集用于训练新模型。
3.3.1 联合嵌入和检索
- 利用 CLIP(对比语言-图像预训练)或 ALIGN(大规模 ImaGe 和嘈杂文本嵌入)等模型为文本和图像创建统一的嵌入。
- 使用 FAISS 或 Annoy 等库实现近似最近邻搜索, 以实现高效检索。
- 将检索到的多模态内容(原始图像和文本块)馈送到多模态 LLM, 例如 LLaVa、Pixtral 12B、GPT-4V、Qwen-VL 以生成答案。
3.3.2 图像到文本的转换
- 使用 LLaVA 或 FUYU-8b 等模型从图像生成摘要。
- 使用基于文本的嵌入模型(如 Sentence-BERT)为原始文本和图像标题创建嵌入。
- 将文本块传递给 LLM 以进行最终答案合成。
3.3.3 混合检索与原始图像访问
- 使用多模态 LLM 从图像生成文本摘要。
- 嵌入和检索这些摘要, 并引用原始图像以及其他文本块。这可以通过 Multi-Vector Retriever 和 Chroma、Milvus 等矢量数据库来实现, 以存储原始文本和图像及其摘要以供检索。
- 对于最终答案生成, 请使用 Pixtral 12B、LLaVa、GPT-4V、Qwen-VL 等多模态模型, 这些模型可以同时处理文本和原始图像输入。
3.4 多模式代理
视觉语言模型解锁了许多代理工作流, 从与文档聊天到计算机使用。在这里, 我们将介绍后者, 因为它需要更高级的代理功能。最近, 有许多 Vision Language Models 版本可以理解 UI 并对其进行作。最新的是字节跳动的 UI-TARS-1.5, 它在浏览器、电脑和手机上运行方面显示出很好的效果。它还可以进行推理游戏, 并在开放世界游戏中运行。今年另一个有影响力的版本是 MAGMA-8B, 它是 UI 导航和与现实世界物理交互的基础模型。此外, Qwen2.5-VL(尤其是它的 32B 变体, 因为它在代理任务上进行了进一步训练)和 Kimi-VL 推理模型在 GUI 代理任务中表现良好。
2025 年初, 我们推出了 smolagents, 这是一个实现 ReAct 框架的新型轻量级代理库。不久之后, 我们为该库实现了 Vision Language 支持。这种集成发生在两个用例中:
- 在运行开始时, 提供一次图像。这对于使用工具的文档 AI 非常有用。
- 动态检索图像。这对于使用 VLM 代理进行 GUI 控制等情况非常有用, 其中代理会重复截取屏幕截图。
该库为用户提供了构建基块, 以便他们使用图像理解来构建自己的代理工作流。我们提供不同的脚本和单行 CLI 命令, 让用户轻松入门。
agent = CodeAgent(tools=[], model=model) # no need for tools
agent.run("Describe these documents:", images=[document_1, document_2, document_3])
对于后一种用例, 我们需要代理获取屏幕截图, 我们可以定义一个回调, 以便在每个 .对于需要动态获取图像的您自己的用例, 请根据需要修改回调。
3.5 视频语言模型
现在大多数视觉语言模型都可以处理视频, 因为视频可以表示为一系列帧。但是, 由于帧之间的时间关系和大量帧, 视频理解很棘手, 因此使用不同的技术来选择一组具有代表性的视频帧。
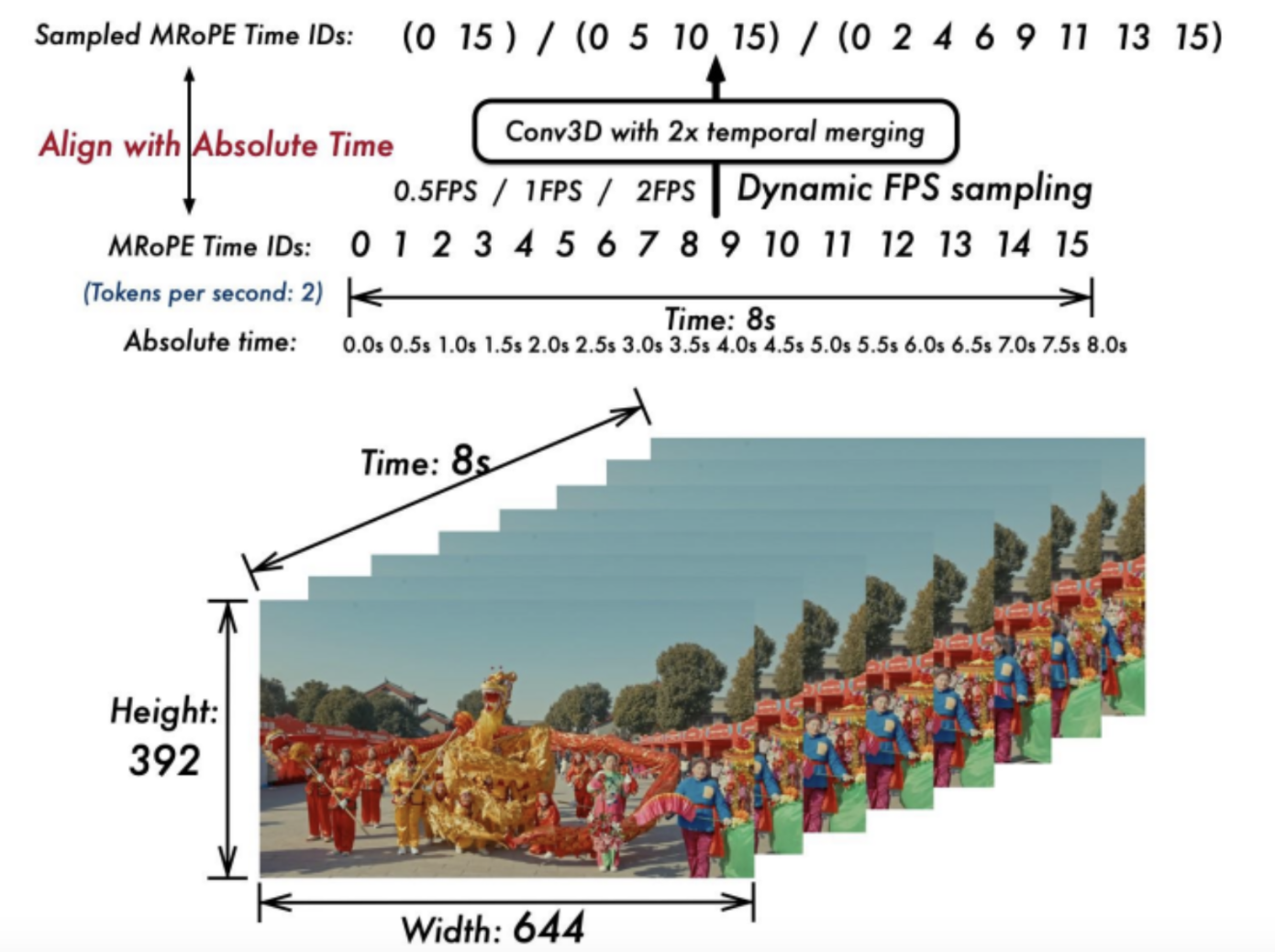
一个很好的例子是 Meta 的 LongVU 模型。它通过将视频帧传递给 DINOv2 来选择最相似的视频帧来对其进行下采样以将其删除, 然后模型通过根据文本查询选择最相关的帧来进一步细化帧, 其中文本和帧被投影到相同的空间并计算相似度。Qwen2.5VL 可以处理长上下文并适应动态 FPS 速率, 因为该模型使用不同帧速率的视频进行训练。通过扩展的多模态 RoPE, 它可以理解帧的绝对时间位置, 并且可以处理不同的速率, 并且仍然了解现实生活中发生的事件的速度。另一种模型是 Gemma 3, 它可以接受文本提示中带有时间戳的视频帧, 例如"Frame 00.00: ..", 对于视频理解任务来说性能非常高。
4. 新技术
4.1 Vision Language 模型的新对齐技术
Preference optimization 是语言模型的另一种微调方法, 也可以扩展到视觉语言模型。此方法不依赖于固定标签, 而是侧重于根据偏好对候选响应进行比较和排名。trl库支持直接首选项优化(DPO), 包括 VLM。
以下是如何构建 VLM 微调的 DPO 首选项数据集的示例。每个条目都包含一个图像 + 问题对和两个相应的答案: 一个被选中, 一个被拒绝。自动柜员机经过微调, 以生成与首选(选择)答案一致的响应。
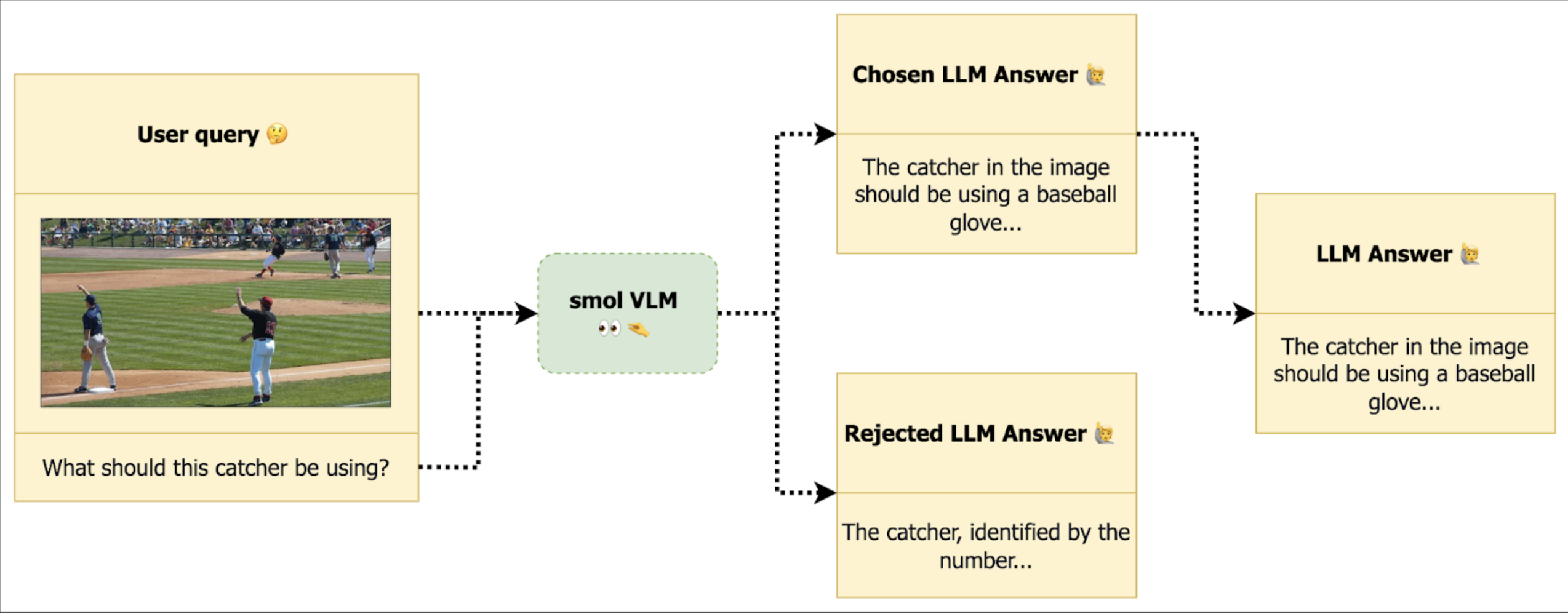
此过程的一个示例数据集是 RLAIF-V, 其中包含超过 83000 个根据上述结构格式化的带注释样本。每个条目都包含一个图像列表(通常为一个)、一个提示、一个选定的答案和一个被拒绝的答案, 正如 DPOTrainer 所期望的那样。
有一个 RLAIF-V 格式的数据集, 该数据集已进行相应的格式设置。下面是单个示例的示例:
{'images': [<PIL.JpegImagePlugin.JpegImageFile image mode=L size=980x812 at 0x154505570>],
'prompt': [ { "content": [ { "text": null, "type": "image" }, { "text": "What should this catcher be using?", "type": "text" } ], "role": "user" } ],
'rejected': [ { "content": [ { "text": "The catcher, identified by the number...", "type": "text" } ], "role": "assistant" } ],
'chosen': [ { "content": [ { "text": "The catcher in the image should be using a baseball glove...", "type": "text" } ], "role": "assistant" } ]}
准备好数据集后, 您可以使用 trl 库中的 DPOConfig 和 DPOTrainer 类来配置和启动微调过程。
以下是使用 DPOConfig 的示例配置:
from trl import DPOConfig
training_args = DPOConfig(
output_dir="smolvlm-instruct-trl-dpo-rlaif-v",
bf16=True,
gradient_checkpointing=True,
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=32,
num_train_epochs=5,
dataset_num_proc=8, # tokenization will use 8 processes
dataloader_num_workers=8, # data loading will use 8 workers
logging_steps=10,
report_to="tensorboard",
push_to_hub=True,
save_strategy="steps",
save_steps=10,
save_total_limit=1,
eval_steps=10, # Steps interval for evaluation
eval_strategy="steps",
)
要使用 DPOTrainer 训练模型, 您可以选择提供参考模型来计算奖励差异。如果您使用的是 Parameter-Efficient Fine-Tuning(PEFT), 您可以通过设置 ref_model=None 来省略参考模型。
from trl import DPOTrainer
trainer = DPOTrainer(
model=model,
ref_model=None,
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
peft_config=peft_config,
tokenizer=processor
)
trainer.train()
参考:
https://mp.weixin.qq.com/s/LDVgCTvUcfnMX4Dl78gDHg
Vision Language Models(Better, Faster, Stronger)
Vision Language Models Explained
A Survey of State of the Art Large Vision Language Models: Alignment, Benchmark, Evaluations and Challenges
Generative AI Model Architecture — Part4: Vision Language Model
Multi-Modal RAG: A Practical Guide
Understanding Multimodal LLMs
Generative AI Model Architecture — Part3: Vision Transformer
