
目录
PaddleNLP 是飞桨自然语言处理开发库, 具备易用的文本领域API, 多场景的应用示例、和高性能分布式训练 三大特点, 旨在提升飞桨开发者文本领域建模效率, 旨在提升开发者在文本领域的开发效率, 并提供丰富的NLP应用示例。
0. 前言
目前基于神经网络的语言模型根据学习方法不同大体可以分为两大类, 分别是Feature-based和Fine-tune.
0.1 Feature-based
Feature-based 方法是通过训练神经网络从而得到词语的embedding, 换句话说就是通过神经网络得到更恰当的向量来表示词库中的每一个词语, Feature-based 方法不使用模型本身, 而是使用模型训练得到的参数作为词语的 embedding; feature-base 方法最典型的例子就是ELMO和word2vec
0.2 Fine-tune
Fine-tune 方法会根据下游特定的任务, 在原来的模型上面进行一些修改, 使得最后输出是当前任务需要的。这些修改一般是在模型的最后一层, 或者在现有的网络后添加一个网络结构用于匹配下游的各种任务; GPT1 GPT2 就采用了Fine-tune 方法, GPT3得益于海量的与训练样本和庞大的网络参数, 不在需要 fine-tune过程; BERT论文采用了LM + fine-tuning的方法, 同时也讨论了BERT + task-specific model的方法。
随着深度学习的发展, 模型参数数量飞速增长, 为了训练这些参数, 需要更大的数据集来避免过拟合。然而, 对于大部分NLP任务来说, 构建大规模的标注数据集成本过高, 非常困难, 特别是对于句法和语义相关的任务。相比之下, 大规模的未标注语料库的构建则相对容易。最近的研究表明, 基于大规模未标注语料库的预训练模型(Pretrained Models, PTM)能够习得通用的语言表示, 将预训练模型Fine-tune到下游任务, 能够获得出色的表现。另外, 预训练模型能够避免从零开始训练模型。
1. 环境配置
1.1 系统需求
- Paddle currently only supported Ubuntu16.04 and Ubuntu18.04
- Python >=3.7
- protoc >= 3.19.0
1.2 安装
- paddlepaddle 2.2.0 (paddlepaddle-gpu)
- paddlenlp 2.3.1
- paddleocr 2.5
# Paddle currently only supported Ubuntu16.04 and Ubuntu18.04
apt install protobuf-compiler gcc g++ unzip python3.7 python3-pip python3.7-dev
# -i https://mirror.baidu.com/pypi/simple
# -i https://pypi.org/simple
# protobuf
wget https://github.com/protocolbuffers/protobuf/releases/download/v3.20.1/protoc-3.20.1-linux-x86_64.zip
unzip protoc-3.20.1-linux-x86_64.zip
cp bin/protoc /usr/bin/
python3 -m pip install --upgrade pip -i https://mirror.baidu.com/pypi/simple
python3 -m pip install --upgrade Pillow -i https://mirror.baidu.com/pypi/simple
python3 -m pip install --upgrade yacs -i https://mirror.baidu.com/pypi/simple
# paddlepaddle-gpu
python3 -m pip install --upgrade paddlepaddle==2.2.0 -i https://mirror.baidu.com/pypi/simple
python3 -m pip install --upgrade paddlenlp==2.3.1 -i https://mirror.baidu.com/pypi/simple
python3 -m pip install --upgrade paddleocr==2.5 -i https://mirror.baidu.com/pypi/simple
pip install yacs -i https://mirror.baidu.com/pypi/simple
pip3 install paddlepaddle==2.2.0 -i https://mirror.baidu.com/pypi/simple
pip3 install paddlenlp==2.3.1 -i https://mirror.baidu.com/pypi/simple
python3 -m pip uninstall protobuf
python3 -m pip install protobuf==3.20.1 -i https://mirror.baidu.com/pypi/simple
1.3 问题收集
- ERROR: Cannot uninstall ‘PyYAML’
python3 -m pip install --ignore-installed PyYAML -i https://mirror.baidu.com/pypi/simple
- your generated code is out of date and must be regenerated with protoc >= 3.19.0
python3 -m pip uninstall protobuf
# 注意: 这里的protobuf 版本最好同上面安装protobuf-compiler 版本一致
python3 -m pip install protobuf==3.20.1 -i https://mirror.baidu.com/pypi/simple
- ModuleNotFoundError: No module named ‘apt_pkg’
更新完python版本之后, 路径: /usr/lib/python3/dist-packages 下的文件 apt_pkg.cpython-36m-x86_64-linux-gnu.so, 文件名没有跟随 python 版本进行更改, 正确做法应该是把文件名中的 36m 更改为你更新后的 python 版本号, 如我更新后的 python 版本为 python3.7 , 所以文件名应该更改为 apt_pkg.cpython-37m-x86_64-linux-gnu.so 。
2. 功能演示
from pprint import pprint
from paddlenlp import Taskflow
schema = ['时间', '选手', '赛事名称']
ie = Taskflow('information_extraction', schema=schema)
pprint(ie("2月8日上午北京冬奥会自由式滑雪女子大跳台决赛中中国选手谷爱凌以188.25分获得金牌!"))
dialogue = Taskflow("dialogue")
dialogue.interactive_mode(max_turn=3)
schema = ['单位']
ie = Taskflow('information_extraction', schema=schema)
pprint(ie("本部分主要参加起草单位:中国质量认证中心、天津摩托车质量监督检验所、五羊-本田摩托(广州)有限公司、新大洲本田摩托有限公司、江苏金彭车业有限公司、宗申产业集团有限公司。"))
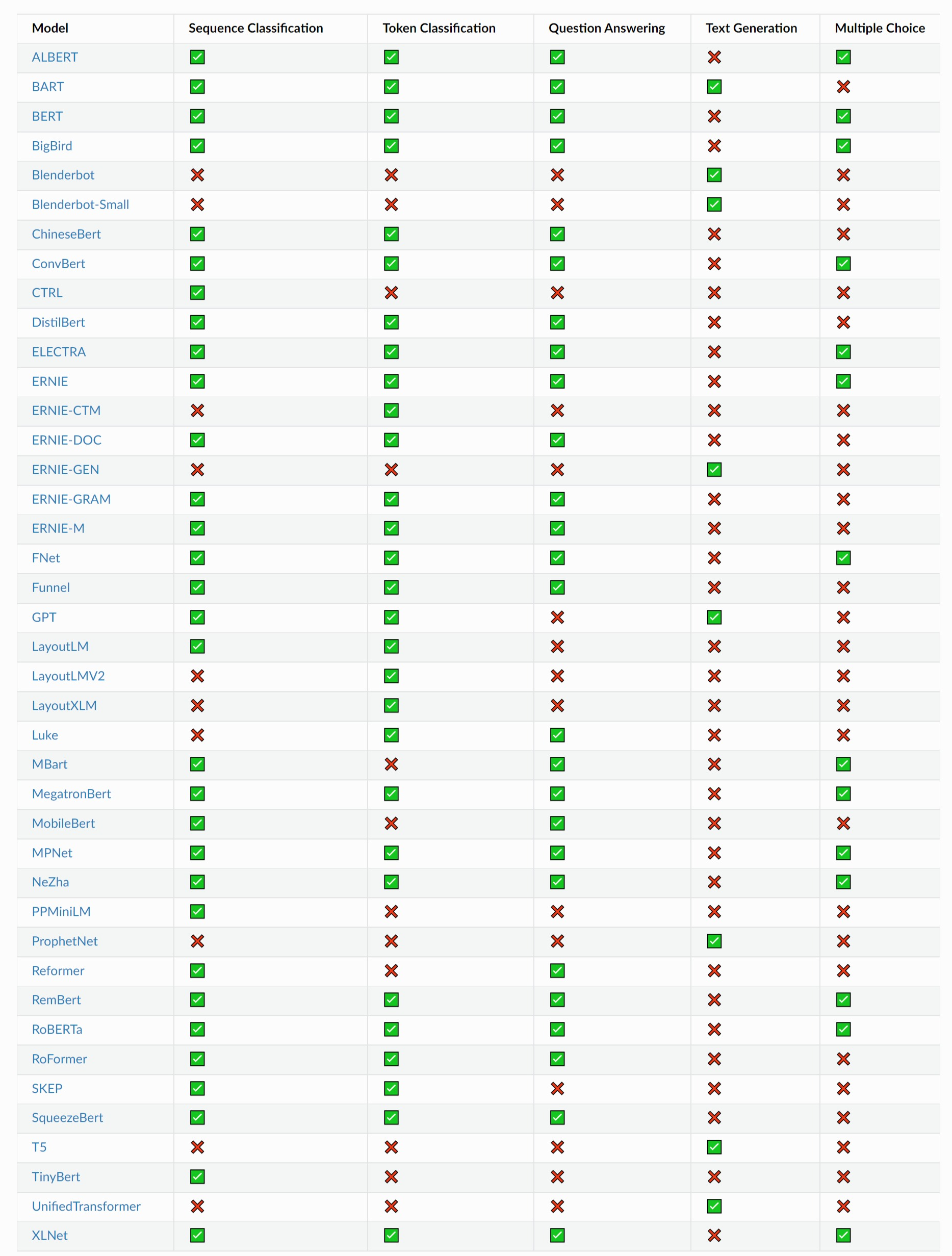
2.1 PaddleNLP内置的预训练模型及其使用范围
2.2 PaddleNLP数据处理流程
要成为一名合格的调参侠, 要对各个模型所能接受的数据类型要足够熟悉
通过查阅官方文档, PaddleNLP通用数据处理流程如下:
- 加载数据集(内置数据集或者自定义数据集, 数据集返回 原始数据)
- 定义 trans_func() , 包括tokenize, token to id等操作, 并传入数据集的 map() 方法, 将原始数据转为 feature
- 根据上一步数据处理的结果定义 batchify 方法和 BatchSampler
- 定义 DataLoader , 传入 BatchSampler 和 batchify_fn()
以Bert的文本分类任务为例, 其数据处理流程:
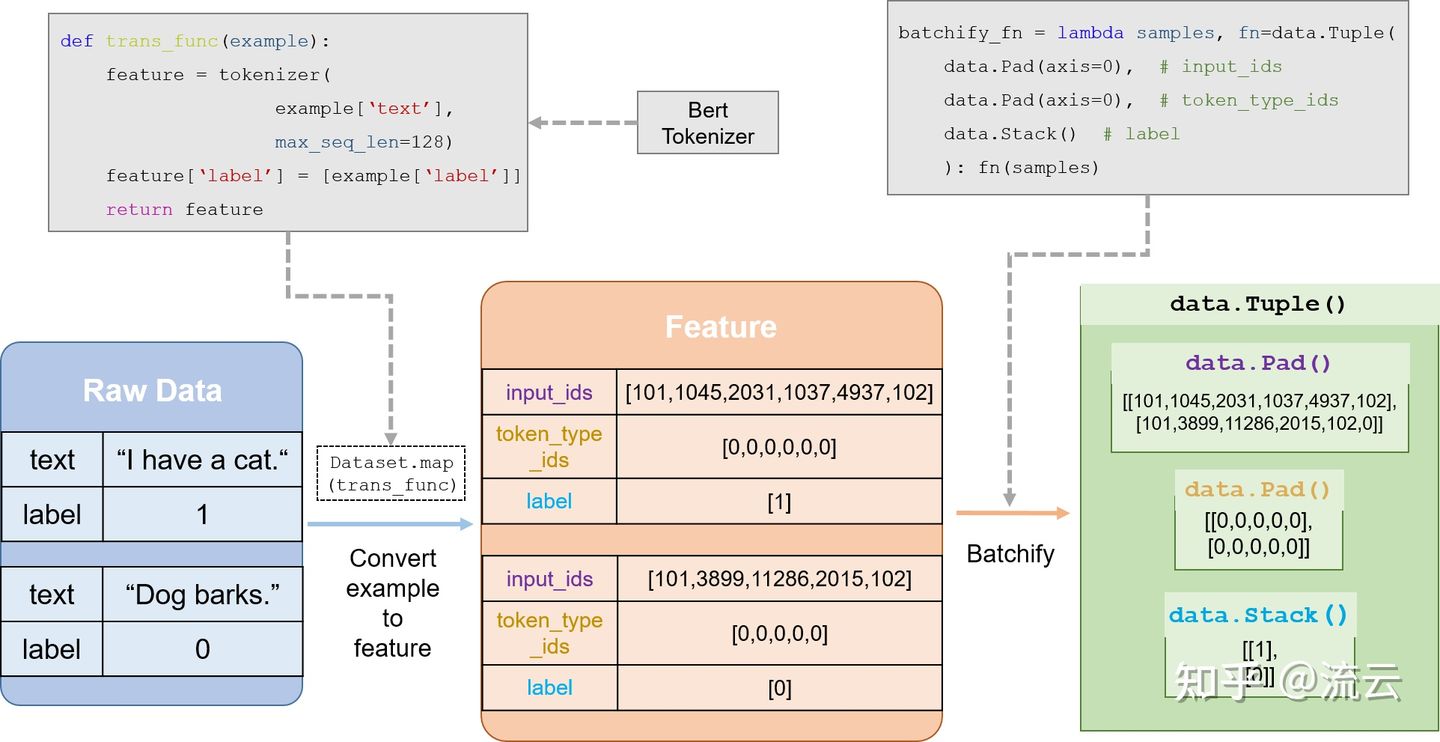
主要分为两个部分:
- 第一个部分是利用paddle内置的分词器(有预训练好的, 也可以自己训练)将现实中的文字(中文或者英文)转换为计算机能识别的编码, 这个最好就用已经预训练好的吧, 因为普通人很难找到那么庞大的语料库。
- 第二个部分是通过一些pad, stack函数, 将多个数据组成Batch
tips: 要记得看一下这个分词器支持什么语言的, Ernie1.0支持中文, 效果也不错, 2.0及以上, 百度还没有开源。目前大部分中文分词器使用的都是字粒度的输入, tokenzier会将句子转换为字粒度的形式, 模型无法收到词粒度的输入。
2.3 PaddleNLP提供了以下数据集的快速读取API, 实际使用时请根据需要添加splits信息
- 阅读理解
- 文本分类
- 文本匹配
- 序列标注
- 机器翻译
- 机器同传
- 对话系统
- 文本生成
- 语料库
3. Paddle OCR
PaddleOCR 旨在打造一套丰富、领先、且实用的OCR工具库, 不仅提供了通用场景下的中英文模型, 也提供了专门在英文场景下训练的模型, 和覆盖80个语言的小语种模型。
ppocr 支持使用自己的数据进行自定义训练或finetune, 其中识别模型可以参考法语配置文件 修改训练数据路径、字典等参数。
pip install paddlepaddle paddleocr
# gpu
pip install paddlepaddle-gpu
# C:\Users\Administrator/.paddleocr
参考:
https://paddlenlp.readthedocs.io/zh/latest/data_prepare/dataset_list.html
