
目录
1. ptrace 说明
ptrace可以说是gdb的灵魂了。gdb通过执行 ptrace(PTRACE_ATTACH, pid, 0, 0) 来对目标进程进行追踪。ptrace原型如下:
long ptrace(enum __ptrace_request request, pid_t pid,void *addr, void *data);
ptrace()系统调用提供了一种方法可以使得追踪者(tracer)来对被追踪者(tracee)进行观察与控制。具体表现为可以检查tracee中内存以及寄存器的值。ptrace首要地被用于实现断点debug与系统调用追踪。
首先, tracee process必须要被tracer attach上(也就是我们启动gdb后的 attach pid), 需要注意的是, attach和后续的命令是针对每个线程来说的。如果是一个多线程的程序, 每个线程都要被单独的attach才行。这里主要强调了, tracee(被追踪者)是一个单独的thread, 而非一个整个的多线程程序。
当追踪时, tracee每次发送一个信号就会停一次, 即使这个signal会被忽略掉。而tracer将会捕捉到tracee的下一个调用(通过waitpid或wait类似系统调用)。而这个调用将会告诉tracer, tracee停止的原因以及相关信息。所以当tracee停下来, tracer可以通过ptrace的多种模式来进行监控甚至修改tracee, 然后tracer会告诉tracee继续运行。
ptrace四个参数的含义解释如下:
- request : request的值确定要执行的操作
- 第二参数 pid : 指示ptrace要跟踪的进程。
- 第三参数 addr : 指定ptrace要读取or监控的内存地址。
- 第四参数 data : 如果我们要向目标进程写入数据, 那么data是我们要写入的数据; 如果我们从目标进程中读出数据, 那么读出的数据放在data。
ptrace的第一个参数可以是如下的值:
PTRACE_TRACEME, 本进程被其父进程所跟踪。其父进程应该希望跟踪子进程
PTRACE_PEEKTEXT, 从内存地址中读取一个字节, 内存地址由addr给出
PTRACE_PEEKDATA, 同上
PTRACE_PEEKUSER, 可以检查用户态内存区域(USER area),从USER区域中读取一个字节, 偏移量为addr
PTRACE_POKETEXT, 往内存地址中写入一个字节。内存地址由addr给出
PTRACE_POKEDATA, 往内存地址中写入一个字节。内存地址由addr给出
PTRACE_POKEUSER, 往USER区域中写入一个字节, 偏移量为addr
PTRACE_GETREGS, 读取寄存器
PTRACE_GETFPREGS, 读取浮点寄存器
PTRACE_SETREGS, 设置寄存器
PTRACE_SETFPREGS, 设置浮点寄存器
PTRACE_CONT, 重新运行
PTRACE_SYSCALL, 重新运行
PTRACE_SINGLESTEP, 设置单步执行标志
PTRACE_ATTACH, 追踪指定pid的进程
PTRACE_DETACH, 结束追踪
1.1 PTRACE_TRACEME
这个模式 只被tracee使用, 使用它的进程将会被其父进程追踪。父进程通过wait()获知子进程的信号。
/**
* ptrace_traceme -- helper for PTRACE_TRACEME
*
* Performs checks and sets PT_PTRACED.
* Should be used by all ptrace implementations for PTRACE_TRACEME.
*/
static int ptrace_traceme(void)
{
int ret = -EPERM;
write_lock_irq(&tasklist_lock);
/* Are we already being traced? */
if (!current->ptrace) {
ret = security_ptrace_traceme(current->parent);
/*
* Check PF_EXITING to ensure ->real_parent has not passed
* exit_ptrace(). Otherwise we don't report the error but
* pretend ->real_parent untraces us right after return.
*/
if (!ret && !(current->real_parent->flags & PF_EXITING)) {
current->ptrace = PT_PTRACED;
__ptrace_link(current, current->real_parent);
}
}
write_unlock_irq(&tasklist_lock);
return ret;
}
当我们只用traceme模式时, 内核首先会让写者拿到读写锁, 并禁止本地中断。接下来判断是否我们当前进程已经被追踪, 接着将子进程链接到父进程的ptrace链表中。最后放掉锁。
1.2 PTRACE_ATTACH
在attach模式下, 通过指定一个tracee的pid, tracee向tracer发送SIGSTOP信号。而tracer使用 waitpid()等待tracee停止。
if (request == PTRACE_ATTACH) {
if (child == current)
goto out;
if ((!child->dumpable || //这里检查了进程权限
(current->uid != child->euid) ||
(current->uid != child->suid) ||
(current->uid != child->uid) ||
(current->gid != child->egid) ||
(current->gid != child->sgid) ||
(!cap_issubset(child->cap_permitted, current->cap_permitted)) ||
(current->gid != child->gid)) && !capable(CAP_SYS_PTRACE))
goto out;
if (child->flags & PF_PTRACED)
goto out;
child->flags |= PF_PTRACED; //设置进程标志位PF_PTRACED
write_lock_irqsave(&tasklist_lock, flags);
if (child->p_pptr != current) { //设置进程为当前进程的子进程。
REMOVE_LINKS(child);
child->p_pptr = current;
SET_LINKS(child);
}
write_unlock_irqrestore(&tasklist_lock, flags);
send_sig(SIGSTOP, child, 1); //向子进程发送一个SIGSTOP, 使其停止
ret = 0;
goto out;
}
1.3 PTRACE_CONT
tracer通过这个模式, 向tracee发信号, 让停止的tracee继续运行。
case PTRACE_CONT:
long tmp;
ret = -EIO;
if ((unsigned long) data > _NSIG) //信号是否超过范围?
goto out;
if (request == PTRACE_SYSCALL)
child->flags |= PF_TRACESYS; //如果是PTRACE_SYSCALL就设置PF_TRACESYS标志
else
child->flags &= ~PF_TRACESYS; //如果是PF_CONT, 去除PF_TRACESYS标志
child->exit_code = data; //设置继续处理的信号
tmp = get_stack_long(child, EFL_OFFSET) & ~TRAP_FLAG; //清除TRAP_FLAG
put_stack_long(child, EFL_OFFSET,tmp);
wake_up_process(child); //唤醒停止的子进程
ret = 0;
goto out;
1.4 PTRACE_PEEKUSER
在tracee的USER区域的addr处读取一个word。读取的这个字为返回值。
1.5 PTRACE_SINGLESTEP
而具体到ptrace中的 PTRACE_SINGLESTEP 来说, 这是基于eflags寄存器的TF位(陷阱标志)实现的。他强迫子进程, 执行下一条汇编指令, 然后又停止他, 此时子进程产生一个 debug exception 而对应的异常处理程序负责清掉这个标志位, 并强迫当前进程停止。然后发送SIGCHLD信号给父进程。
2.2 Demo 演示
有了以上基础后我们来看如下demo
#include <sys/ptrace.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
#include <sys/reg.h> /* For constants ORIG_RAX etc */
#include <stdio.h>
int main()
{
char * argv[ ]={"ls","-al","/etc/passwd",(char *)0};
char * envp[ ]={"PATH=/bin",0};
pid_t child;
long orig_rax;
child = fork();
if(child == 0)
{
ptrace(PTRACE_TRACEME, 0, NULL, NULL);
printf("Try to call: execl\n");
execve("/bin/ls",argv,envp);
printf("child exit\n");
}
else
{
wait(NULL); //等待子进程
orig_rax = ptrace(PTRACE_PEEKUSER,
child, 8 * ORIG_RAX,
NULL);
printf("The child made a "
"system call %ld\n", orig_rax);
ptrace(PTRACE_CONT, child, NULL, NULL);
printf("Try to call:ptrace\n");
}
return 0;
}
2.1 Demo 的过程:
- fork一个子进程。子进程标记为tracee。(PTRACE_TRACEME)
- 子进程调用execve, 向父进程发送一个SIGCHLD。同时, 子进程由于SIGTRAP停止
- 父进程捕捉到SIGCHLD, 同时使用ptrace获取子进程的系统调用号(59)
- 父进程告诉子进程继续执行(PTRACE_CONT), 子进程输出ls的内容。
- 子进程的 printf(“child exit\n”); 不会被执行, 因为execve丢弃原来的子进程execve()之后的部分, 而子进程的栈、数据会被新进程的相应部分所替换。永不返回。
当tracee触发一个exec的时候, 会通过 send_sig(SIGTRAP, current, 0) 产生一个 SIGTRAP , 导致停止。
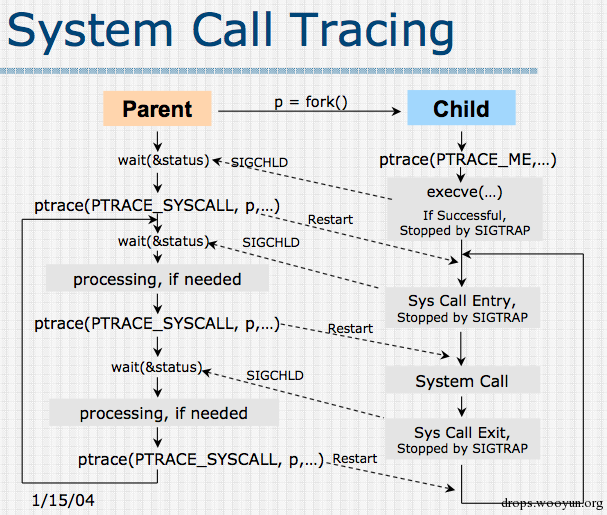
2.2 ptrace是如何起作用的:
- 通过 copy_from_user copy_to_user 读取与修改数据。
- 通过 copy_regset_from/to_user 访问寄存器。而寄存器数据保存在 task struct 中。
- 单步(Single Stepping): 每步进(step)一次, CPU会一直执行到有分支、中断或异常。而ptrace通过设置对应的标志位在进程的thread_info.flags和MSR中打标启用单步调试。
void user_enable_single_step(struct task_struct *child)
{
enable_step(child, 0);
}
/*
* Enable single or block step.
*/
static void enable_step(struct task_struct *child, bool block)
{
/*
* Make sure block stepping (BTF) is not enabled unless it should be.
* Note that we don't try to worry about any is_setting_trap_flag()
* instructions after the first when using block stepping.
* So no one should try to use debugger block stepping in a program
* that uses user-mode single stepping itself.
*/
if (enable_single_step(child) && block)
set_task_blockstep(child, true);
else if (test_tsk_thread_flag(child, TIF_BLOCKSTEP))
set_task_blockstep(child, false);
}
在 enable_single_step 中设置了 X86_EFLAGS_TF 以及 TIF_SINGLESTEP 标志位。
在 test_tsk_thread_flag 中检查了对应进程 thread_info中的 TIF_BLOCKSTEP 标志位。
void set_task_blockstep(struct task_struct *task, bool on)
{
unsigned long debugctl;
local_irq_disable();
debugctl = get_debugctlmsr();
if (on) {
debugctl |= DEBUGCTLMSR_BTF;
set_tsk_thread_flag(task, TIF_BLOCKSTEP);
} else {
debugctl &= ~DEBUGCTLMSR_BTF;
clear_tsk_thread_flag(task, TIF_BLOCKSTEP);
}
if (task == current)
update_debugctlmsr(debugctl);
local_irq_enable();
}
接下来在 set_task_blockstep 中设置或清除了 DEBUGCTLMSR_BTF 以及 对应thread info的 TIF_BLOCKSTEP:
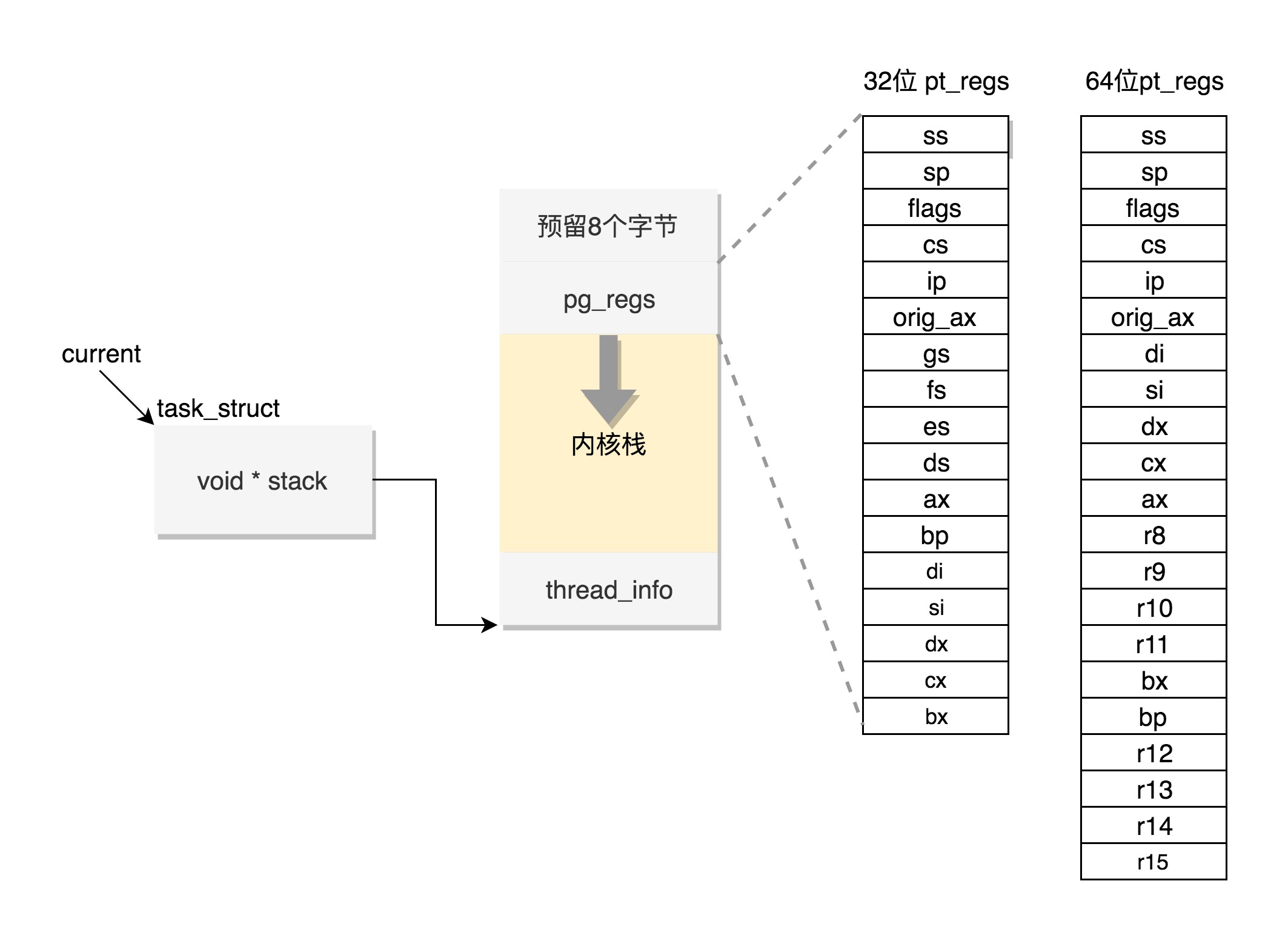
2.3 breakpoints(断点)
首先明确一点, breakpoints并不是ptrace的实现的一部分。并且, 当处于attach和traceme状态下, 交付给tracee的任何信号首先都会被GDB截获。breakpoints大体的实现如下:
假设我们想在addr处停下来。那么GDB会做如下事情。
-
1.读取addr处的指令的位置, 存入GDB维护的断点链表中。
-
2.将中断指令 INT 3 (0xCC)打入原本的addr处。也就是将addr处的指令掉换成INT 3
-
3.当执行到addr处(INT 3)时, CPU执行这条指令的过程也就是发生断点异常(breakpoint exception), tracee产生一个SIGTRAP, 此时我们处于attach模式下, tracee的SIGTRAP会被tracer(GDB)捕捉。
然后GDB去他维护的断点链表中查找对应的位置, 如果找到了, 说明hit到了breakpoint。 -
4.接下来, 如果我们想要tracee继续正常运行, GDB将INT 3指令换回原来正常的指令, 回退重新运行正常指令, 然后接着运行。
2.4 watchpoint(硬件断点)
在GDB中另一个非常有用的是watch命令。用于监控某一内存位置或者寄存器的变化。watch的实现与CPU的相关寄存器有关。我们以80386为例。存在DR0到DR7这八个特殊的寄存器来实现硬件断点。
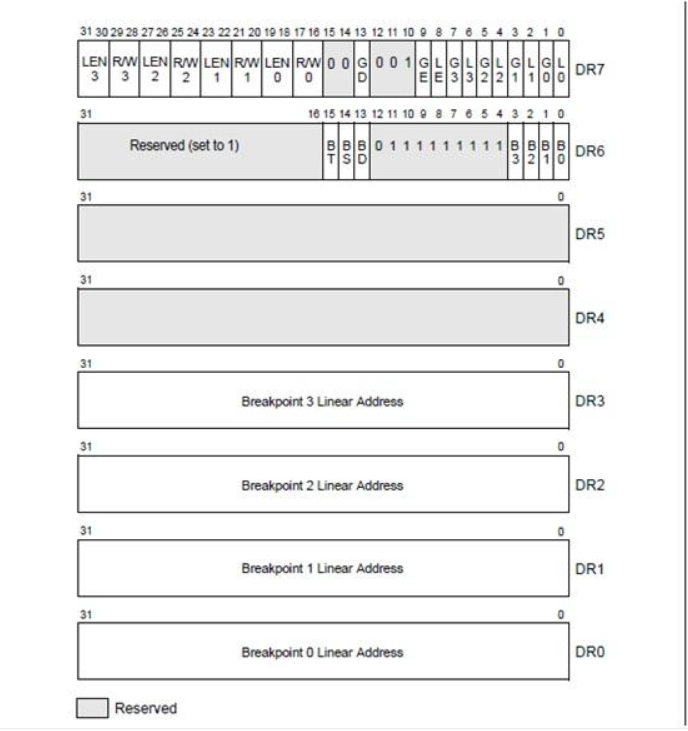
2.4.1 DR0-DR3
每个寄存器都保存着对应条件断点的线性地址。而每个断点更进一步的信息储存在DR7中。需要注意的是, 由于储存的是线性地址, 所以是否开启分页是不影响的。如果开启paging, 那么线性地址由mmu转换到物理地址; 否则线性地址与物理地址等效。
2.4.2 DR7
调试控制寄存器debug control: DR7的低八位(0、2、4、6和1、3、5、7)有选择地启用四个条件断点。启用级别有两个: 本地(0,2,4,6)和全局(1,3,5,7)。处理器会在每个任务切换时自动重置本地启用位, 以避免在新任务中出现不必要的断点情况。全局启用位不会由任务开关重置; 因此, 它们可以用于所有任务的全局条件。
16-17位(对应于DR0), 20-21(DR1), 24-25(DR2), 28-29(DR3)定义了断点触发的时间。每个断点都有一个两位对应, 用于指定它们是在执行(00b), 数据写入(01b), 数据读取还是写入(11b)时中断。10b被定义为表示IO读取或写入中断, 但没有硬件支持它。位18-19(DR0), 22-23(DR1), 26-27(DR2), 30-31(DR3)定义了断点监视多大的内存区域。同样, 每个断点都有一个两位对应, 指定他们watch一个(00b), 两个(01b), 八(10b)还是四(11b)个字节。
2.4.3 DR6
调试状态寄存器: 告诉调试器哪些断点已经发生了。
