
目录
1. HBase 集群搭建
hbase是一款分布式的列式数据库, 其数据源寄生在hadoop上, 因而与hadoop共生, 广泛应用在大数据领域, 利用zookeeper作为其分布式协同服务, 存储非结构化和半结构化的松散数据, 其特点是高可靠, 高性能, 面向列, 可伸缩, 实时读写.
1.1 Hbase 集群说明
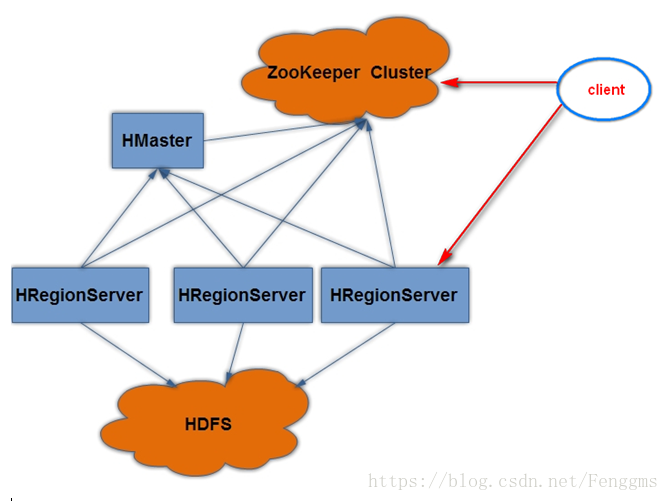
1.1.1 Client
包含访问Hbase的接口, 并维护cache来加快对Hbase的访问, 比如region的位置信息。
1.1.2 HMaster
是hbase集群的主节点, 可以配置多个, 用来实现HA
- 为RegionServer分配region
- 负责RegionServer的负载均衡
- 发现失效的RegionServer并重新分配其上的region
1.1.3 RegionServer:
Regionserver维护region, 处理对这些region的IO请求
Regionserver负责切分在运行过程中变得过大的region
1.1.4 Region:
分布式存储的最小单元。
1.1.5 Zookeeper:
Zookeeper作用:
- 通过选举, 保证任何时候, 集群中只有一个活着的HMaster, HMaster与RegionServers 启动时会向ZooKeeper注册
- 存贮所有Region的寻址入口
- 实时监控Region server的上线和下线信息。并实时通知给HMaster
- 存储HBase的schema和table元数据
- Zookeeper的引入使得HMaster不再是单点故障。
1.2 Hbase 集群搭建(以三叹机器为例)
- 使用三个机器部署集群, 需要修改hostname,以及hosts文件修改, 请使用有权限的用户执行以下操作
note:建议ip使用静态设置, 避免使用动态获取ip的方式, 否则Ip和机器名映射就出现错乱
- 分别下载zookeeper,hadoop,hbase, kafka 组件
国内镜像地址: http://mirror.bit.edu.cn/apache/
国内镜像地址: http://mirrors.aliyun.com/apache/ - 设置时区+时间同步crontab, 之后重启
1.2.1 jdk版本
下载jdk1.8,及配置环境变量, 以下版本为测试环境版本:
note:当前hbase版本必须使用jdk1.8或以上
java -version
java version "1.8.0_141"
Java(TM) SE Runtime Environment (build 1.8.0_141-b15)
Java HotSpot(TM) 64-Bit Server VM (build 25.141-b15, mixed mode)
1.2.2 Zookeeper 集群安装与配置
wget http://mirrors.aliyun.com/apache/zookeeper/zookeeper-3.5.7/apache-zookeeper-3.5.7.tar.gz
tar apache-zookeeper-3.5.7.tar.gz
mv apache-zookeeper-3.5.7 /usr/local/zookeeper-3.5.7
cd /usr/local/zookeeper-3.5.7/conf
cp zoo_sample.cfg zoo.cfg
修改配置文件zoo.cfg (note:在文件末尾加入以下配置, 其它默认, 注释掉原来的配置# dataDir=/tmp/zookeeper)
dataDir=/data/zookeeper/data
dataLogDir=/data/zookeeper/logs
server.1=<hostname>:2888:3888
server.2=<hostname>:2888:3888
server.3=<hostname>:2888:3888
设置zookeeper数据目录 (同上方配置)
mkdir -p /data/zookeeper/data
mkdir -p /data/zookeeper/logs
# 为不同的机器分配ID
echo 1 > /data/zookeeper/data/myid
# 设置 zookeeper环境变量
vim /etc/profile #在文件末尾加入以下配置
export ZOOKEEPER_HOME=/usr/local/zookeeper-3.4.12
export PATH=$PATH:$ZOOKEEPER_HOME/bin
source /etc/profile
将上面的步骤重复到其他2台机器后, 主要修改 /data/zookeeper/data/myid, 然后测试启动并配置开机启动:
zkServer.sh start
zkServer.sh status
vim /etc/rc.local
export JAVA_HOME=/usr/lib/jdk1.8.0_141
# startup zookeerper 使用iawen账户启动zookeeper,“-l”表示以登录方式执行
su iawen -l -c '/usr/local/zookeeper-3.4.12/bin/zkServer.sh start'
1.2.3 Hadoop 集群
设置ulimit:
ulimit -n
# 在文件 /etc/security/limits.conf末尾增加两行
iawen - nofile 32768
iawen soft/hard nproc 32000
# iawen 替换成你运行Hbase和Hadoop的用户
在/etc/pam.d/common-session 加上这一行
note:pam_limits.so模块可以使用在对一般应用程序使用的资源限制方面。如果需要在SSH服务器上对来自不同用户的ssh访问进行限制, 就可以调用该模块来实现相关功能。当需要限制用户admin登录到SSH服务器时的最大连接数(防止同一个用户开启过多的登录进程), 就可以在/etc/pam.d/sshd文件中增加一行对pam_limits.so模块的调用:
vim /etc/pam.d/common-session
session required pam_limits.so
wget http://mirrors.aliyun.com/apache/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz
tar xzf hadoop-3.1.3.tar.gz
mv hadoop-3.1.3 /usr/local/
mkdir -p /data/hadoop/tmp
cd /usr/local/hadoop-3.1.3/etc/hadoop
# 修改以下6个文件:
# hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、workers
vim hadoop-env.sh
export JAVA_HOME=/usr/lib/jdk1.8.0_141
修改core-site.xml (fs.defaultFS指定NameNode的地址, hadoop.tmp.dir指定临时文件的目录)
<configuration>
<!-- hdfs地址, ha模式中是连接到nameservice -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster</value>
</property>
<!-- 这里的路径默认是NameNode、DataNode、JournalNode等存放数据的公共目录, 也可以单独指定 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/tmp</value>
</property>
<!-- 指定ZooKeeper集群的地址和端口。注意, 数量一定是奇数, 且不少于三个节点-->
<property>
<name>ha.zookeeper.quorum</name>
<value>iawen01:2181,iawen02:2181,iawen03:2181</value>
</property>
</configuration>
修改文件 hdfs-site.xml (dfs.replication指定数据文件冗余的份数)
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/data/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/data/hadoop/hdfs/data</value>
</property>
<!-- 指定副本数, 不能超过机器节点数 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 为namenode集群定义一个services name -->
<property>
<name>dfs.nameservices</name>
<value>cluster</value>
</property>
<!-- nameservice 包含哪些namenode, 为各个namenode起名 -->
<property>
<name>dfs.ha.namenodes.cluster</name>
<value>nn1,nn2</value>
</property>
<!-- 名为 nn1 的namenode的rpc地址和端口号, rpc用来和datanode通讯 -->
<property>
<name>dfs.namenode.rpc-address.cluster.nn1</name>
<value>iawen01:9000</value>
</property>
<!-- 名为 nn2 的namenode的rpc地址和端口号, rpc用来和datanode通讯 -->
<property>
<name>dfs.namenode.rpc-address.cluster.nn2</name>
<value>iawen02:9000</value>
</property>
<!--名为 nn1 的namenode的http地址和端口号, 用来和web客户端通讯 -->
<property>
<name>dfs.namenode.http-address.cluster.nn1</name>
<value>iawen01:50070</value>
</property>
<!-- 名为 nn2 的namenode的http地址和端口号, 用来和web客户端通讯 -->
<property>
<name>dfs.namenode.http-address.cluster.nn2</name>
<value>iawen02:50070</value>
</property>
<!-- namenode间用于共享编辑日志的journal节点列表 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://iawen01:8485;iawen02:8485;iawen03:8485/cluster</value>
</property>
<!-- 指定该集群出现故障时, 是否自动切换到另一台namenode -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- journalnode 上用于存放edits日志的目录 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/data/hadoop/tmp/data/dfs/journalnode</value>
</property>
<!-- 客户端连接可用状态的NameNode所用的代理类 -->
<property>
<name>dfs.client.failover.proxy.provider.cluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 一旦需要NameNode切换, 使用ssh方式进行操作 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 如果使用ssh进行故障切换, 使用ssh通信时用的密钥存储的位置 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/iawen/.ssh/id_rsa</value>
</property>
<!-- 启用webhdfs -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.journalnode.http-address</name>
<value>0.0.0.0:8480</value>
</property>
<property>
<name>dfs.journalnode.rpc-address</name>
<value>0.0.0.0:8485</value>
</property>
<!-- connect-timeout超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
配置项说明:
- dfs.namenode.name.dir, 配置元数据信息存储位置;
- dfs.datanode.data.dir, 配置具体数据存储位置;
- dfs.replication, 配置每个数据库备份数, 由于目前我们使用1台节点, 所以, 设置为1, 如果设置为2的话, 运行会报错。
- dfs.replications.enabled, 配置hdfs是否启用权限认证
修改文件 mapred-site.xml, 指定运行mapreduce的框架为YARN
<configuration>
<!-- 采用yarn作为mapreduce的资源调度框架 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.1.2</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.1.2</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.1.2</value>
</property>
</configuration>
修改文件 yarn-site.xml, 指定运行YARN的主机、地址和reducer获取数据的方式
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 启用HA高可用性 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定resourcemanager的名字 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 使用了2个resourcemanager,分别指定Resourcemanager的地址 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 指定rm1的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>iawen01</value>
</property>
<!-- 指定rm2的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>iawen02</value>
</property>
<!-- 指定当前机器iawen01作为rm1 -->
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value>
</property>
<!-- 指定zookeeper集群机器 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>iawen01:2181,iawen02:2181,iawen03:2181</value>
</property>
<!-- NodeManager上运行的附属服务, 默认是mapreduce_shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
修改文件 workers
iawen01
iawen02
iawen03
同步 Hadoop 到其他的机器, 修改yarn-site.xml
<!-- 指定当前机器iawen02作为rm2 -->
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm2</value>
</property>
在iawen03节点修改yarn-site.xml 删除以下属性
<!-- 指定当前机器iawen01作为rm1 -->
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value>
</property>
iawen01主机初次运行需要格式化hdfs, 后面运行就不需要步骤
# 每个hadoop节点启动journalnode
hdfs --daemon start journalnode
# 在节点iawen01上 (手动输入!手动输入!!手动输入!!!)
hdfs namenode –format # hadoop namenode -format
# 格式化 zk(在iawen01 手动输入!手动输入!!手动输入!!!)
hdfs zkfc –formatZK
#启动 iawen01 namenode
hadoop-daemon.sh start namenode
#iawen02上同步iawen01 namenode元数据
hdfs namenode -bootstrapStandby
启动Hadoop集群环境, 并查看主备节点启动状况
start-all.sh
# 或者启动
start-dfs.sh
start-yarn.sh
# 查看
hdfs haadmin -getServiceState nn1
hdfs haadmin -getServiceState nn2
验证hadoop
50070端口是Hadoop管理页面, 切到Datanodes选项卡可以看到集群所有Datanode的情况
8088端口是YARN管理页面, 可以看到集群节点运行任务的情况
# http://iawen01:50070/
# http://iawen01:8088/
# 或者jps命令 主备master节点一般都会驻留以下进程, 非master节点只有以下部分进程
21776 DataNode
22725 ResourceManager
21271 NameNode
22919 NodeManager
21005 JournalNode
22302 DFSZKFailoverController
1.2.4 HBase 集群
wget http://archive.apache.org/dist/hbase/2.0.5/hbase-2.0.5-bin.tar.gz
tar xzf hbase-2.0.5-bin.tar.gz
mv hbase-2.0.5 /usr/local/
cd /usr/local/hbase-2.0.5/conf
修改配置 hbase-env.sh
export JAVA_HOME=/usr/lib/jdk1.8.0_141
# Tell HBase whether it should manage it's own instance of ZooKeeper or not.
export HBASE_MANAGES_ZK=false
修改 hbase-site.xml 文件, 修改节点内容
hbase.rootdir表示HBase的存储目录, 要和Hadoop的core-site.xml配置一致
hbase.cluster.distributed表示是否分布式存储
hbase.zookeeper.quorum指定ZooKeeper管理的机器
<configuration>
<!-- 配置HBASE临时目录 -->
<property >
<name>hbase.tmp.dir</name>
<value>/data/hbase</value>
</property>
<!-- 设置HRegionServers共享目录, 请加上端口号 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://cluster/hbase</value>
</property>
<!--这里注意了, 只需端口即可, 不必再写主机名称了!-->
<property>
<name>hbase.master</name>
<value>60000</value>
</property>
<!-- 启用分布式模式 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 指定Zookeeper集群位置 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>iawen01,iawen02,iawen03</value>
</property>
<!-- 指定ZooKeeper集群端口 -->
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<!-- 完全分布式式必须为false -->
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
修改 regionservers 文件
iawen01
iawen02
iawen03
修改 HBase 支持对 Hmaster 的高可用配置, 创建文件conf/backup-masters
iawen02
复制Hadoop 节点中hadoop配置文件hdfs-site.xml到/usr/local/hbase-2.0.5/conf 下面, 并同步到其他节点
启动HBase 并验证
start-hbase.sh
# note: 如果有log4j错误
# 每个hbase安装的节点执行以下脚本删除jar
rm -rf /usr/local/hbase-2.0.5/lib/slf4j-log4j12-1.7.25.jar
# 验证hbase, 登录三台机器, 执行
jps
# master节点机器有以下进程
28117 HMaster
# 备用节点
31281 HMaster
31131 HRegionServer
# 其它节点
29371 HRegionServer
# 打开页面测试查看高可用是否启用
# http://iawen02:16010 / http://192.168.1.134:16010
异常处理
# 在master节点机器出现如下异常信息【Master startup cannot progress, in holding-pattern until region onlined】, 执行以下脚本, 清除在zk中hbase节点信息
stop-hbast.sh
zkCli.sh
rmr /hbase
start-hbase.sh
1.2.5 Kafka 集群
wget http://archive.apache.org/dist/kafka/2.0.0/kafka_2.11-2.0.0.tgz
tar xzf kafka_2.11-2.0.0.tgz
mv kafka_2.11-2.0.0 /usr/local/kafka_2.11
cd /usr/local/kafka_2.11
mkdir -p /data/kafka
编辑配置文件conf/server.properties
修改以下配置项,由于上面的机器已经修改了hostname,可以使用hostname或者ip, 当前执行命令的机器在iawen01所以listeners对应的机器名是iawen01(localhost或者ip均可)
broker.id 每个broker都有一个唯一的id值用来区分彼此, Kafka broker的id值必须大于等于0时才有可能正常启动
zookeeper.connect属性指需要指向的zookeeper, 可以两台或以上即可, 目前三台zookeeper, 所以均写上。
broker.id=1
listeners=PLAINTEXT://iawen01:9092
zookeeper.connect=iawen01:2181,iawen02:2181,iawen03:2181
log.dirs=/data/kafka/logs
启动kafka
./bin/kafka-server-start.sh ./config/server.properties
2. hbase
./hbase shell
2.1 常用命令
- list 查看表
- count ‘staff’ 查询表行数:
- 查看表是否存在: exists ‘member’
- 判断表是否enable: is_enabled ‘member’
- 判断表是否disable: is_disabled ‘member’
- 查看表中所有数据: scan ‘staff’
- 查看表结构: desc ‘staff’
- 查看表中某个列族里某个属性: scan ‘staf_staf_113b’,{COLUMNS =>‘c:staf_114’}
- 根据id查询: get ‘staff’,‘b9cb51e146794ffba8d838335ca300fb’
- 根据id查询某个列族里面的数据: get ‘staff’,‘b9cb51e146794ffba8d838335ca300fb’,‘c’
- 更新一条记录: put ‘staff’,‘b9cb51e146794ffba8d838335ca300fb’,‘c:staf_001’ ,‘99’
- 删除数据属性 : delete ‘staff’’,‘b9cb51e146794ffba8d838335ca300fb’,‘c:staf_001’
- 删除整行数据: deleteall ‘staff’,‘b9cb51e146794ffba8d838335ca300fb’
- drop一个表: 先 disable ’temp_table’ 然后在: drop ’temp_table’
- 清空表: truncate ’t1’
2.2 Namespace操作
HBase系统默认定义了两个缺省的namespace
hbase: 系统内建表, 包括namespace和meta表
default: 用户建表时未指定namespace的表都创建在此
- 创建namespace : create_namespace ’test_ns’
- 删除 namespace : drop_namespace ’test_ns’
- 查看namespace : describe_namespace ’test_ns’
- 列出所有namespace: list_namespace
- 在namespace下创建表: create ’test_ns:emp’,‘id’,’name’,‘age’,‘address’
- 查看namespace下的表 : list_namespace_tables ‘yx’
3. Thrift
Thrift是一个轻量级、跨语言的远程服务调用框架, 最初由Facebook开发, 后面进入Apache开源项目。它通过自身的IDL中间语言, 并借助代码生成引擎生成各种主流语言的RPC服务端/客户端模板代码。
Thrift支持多种不同的编程语言, 包括C++、Java、Python、PHP、Ruby等, 本系列主要讲述基于Java语言的Thrift的配置方式和具体使用。
Thrift软件栈分层从下向上分别为: 传输层(Transport Layer)、协议层(Protocol Layer)、处理层(Processor Layer)和服务层(Server Layer)。
- 传输层(Transport Layer): 传输层负责直接从网络中读取和写入数据, 它定义了具体的网络传输协议; 比如说TCP/IP传输等。
- 协议层(Protocol Layer): 协议层定义了数据传输格式, 负责网络传输数据的序列化和反序列化; 比如说JSON、XML、二进制数据等。
- 处理层(Processor Layer): 处理层是由具体的IDL(接口描述语言)生成的, 封装了具体的底层网络传输和序列化方式, 并委托给用户实现的Handler进行处理。
- 服务层(Server Layer): 整合上述组件, 提供具体的网络线程/IO服务模型, 形成最终的服务。
3.1 Thrift 安装
git clone https://github.com/apache/thrift.git
cd thrift
./bootstrap.sh
./configure --with-as3=no --with-qt5=no --with-java=no --with-erlang=no --with-nodejs=no --with-nodets=no --with-lua=no \
--with-python=no --with-py3=no --with-perl=no --with-php=no --with-php_extension=no --with-dart=no --with-ruby=no --with-haskell=no \
--with-swift=no --with-rs=no --with-cl=no --with-haxe=no --with-netstd=no --with-d=no --with-boost=/usr/local/boost
# go c_glib cpp
make -j4
mv compiler/cpp/thrift /usr/local/bin/
3.2 生成 Go 代码
wget https://github.com/apache/hbase/archive/rel/2.2.4.tar.gz
tar xzf 2.2.4.tar.gz
cd ..
mkdir thrift.go
cd thrift.go
thrift -gen go ../hbase-rel-2.2.4/hbase-thrift/src/main/resources/org/apache/hadoop/hbase/thrift2/hbase.thrift
3.3 使用HBase thrift
修改 /usr/local/hbase-2.0.5/conf/hbase-site.xml 文件, 增加属性
<property>
<name>hbase.thrift.server.socket.read.timeout</name>
<value>6000000</value>
<description>eg:milisecond</description>
</property>
<property>
<name>hbase.regionserver.handler.count</name>
<value>200</value>
</property>
启动
/usr/local/hbase-2.0.5/bin/hbase-daemon.sh start thrift2 -threadpool
4. 踩过的坑
4.1 Could not start ZK at requested port of 2181. ZK was started at port: 2182
在Hbase单机安装或伪分布式启动时, 出现此问题。根据提示, 在hbase-site.xml中增加一条配置信息:
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2182</value>
</property>
保存退出后再执行一次start-hbase.sh即可。
4.2 hbase Master is initializing
hbase 元数据有问题,尝试删除 hdfs上的/hbase/* 但是无效
查看hbase在zk的元数据:
[zk: localhost:2181(CONNECTED) 21] ls /hbase/
meta-region-server rs splitWAL backup-masters table-lock flush-table-proc master-maintenance online-snapshot switch master
running draining namespace hbaseid table
rmf /hbase/online-snapshot
rmf /hbase/master-maintenance
rmf /hbase/running
删除 online-snapshot, master-maintenance, running 等后重启hbase
4.3 HBase Master启动失败 报 master.HMaster: Failed to become active master 解决方法
在配置文件 hbase-site.xml中添加:
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
重启之后, 问题就解决了。
4.4 java.io.IOException: Timed out waiting 20000ms for a quorum of nodes to respond.
今天发现测试环境Hadoop集群开始频繁宕掉, 查看namenode日志发现有如下报错信息:
java.io.IOException: Timed out waiting 20000ms for a quorum of nodes to respond.
原因是因为namenode与journalnode通信时, 超过20000ms, 触发了默认设置的超时时长, 解决办法:
在hdfs-site.xml中加入如下配置
<property>
<name>dfs.qjournal.start-segment.timeout.ms</name>
<value>90000</value>
</property>
<property>
<name>dfs.qjournal.select-input-streams.timeout.ms</name>
<value>90000</value>
</property>
<property>
<name>dfs.qjournal.write-txns.timeout.ms</name>
<value>90000</value>
</property>
在core-site.xml中加入如下配置:
<property>
<name>ipc.client.connect.timeout</name>
<value>90000</value>
</property>
5. 启动脚本
#!/bin/bash
export JAVA_HOME=/usr/lib/jdk1.8.0_141
# 使用iawen账户启动 “-l”表示以登录方式执行
# startup zookeeper
su iawen -l -c '/usr/local/zookeeper-3.4.12/bin/zkServer.sh start'
# startup kafka
sleep 3s
su iawen -l -c '/usr/local/kafka_2.11/bin/kafka-server-start.sh /usr/local/kafka_2.11/config/server.properties &'
# startup hadoop
sleep 3s
su iawen -l -c '/usr/local/hadoop-3.1.3/sbin/start-dfs.sh'
sleep 3s
su iawen -l -c '/usr/local/hadoop-3.1.3/sbin/start-yarn.sh'
# startup hbase
sleep 3s
su iawen -l -c '/usr/local/hbase-2.0.5/bin/start-hbase.sh'
# startup trift
sleep 3s
su iawen -l -c '/usr/local/hbase-2.0.5/bin/hbase-daemon.sh start thrift2 -threadpool'
