
目录
随着信息技术和互联网的发展, 人们逐渐从信息匮乏的时代走入了信息过载(information overload)的时代。推荐系统的任务就是联系用户和信息, 一方面帮助用户发现对自己有价值的信息, 另一方面让信息能够展现在对它感兴趣的用户面前, 从而实现信息消费者和信息生产者的双赢。
从物品的角度出发, 推荐系统可以更好地发掘物品的长尾(long tail)。推荐系统通过发掘用户的行为, 找到用户的个性化需求, 从而将长尾商品准确地推荐给需要它的用户, 帮助用户发现那些他们感兴趣但很难发现的商品。
任何推荐系统的整体大框架都是两部分: 对某个用户user而言: 首先是从数百万种Item中粗略的选出千级别的Item(实现这种功能的方法叫做召回算法), 然后从几百上千的Item中精细的预测算出用户对每个Item的具体评价分数, 然后选出前十个评价分数最高的Item推荐给用户(实现该方法的过程称为排序算法)
基于召回的算法, 我们常常使用的有两种: 基于用户行为的以及基于内容的。基于用户行为的推荐算法我们也称为协同过滤算法, 基于内容的推荐算法后期详细讨论。而协同过滤算法又分为两大类, 一类是基于邻域的协同过滤算法, 一类是基于LFM(隐因子模型), 而我们今天重点讨论的SVD算法就是召回算法里的LFM算法。
基于排序的算法, 有LR,FM,GBDT+LR,GBDT+FM,深度学习的一些算法等等, 后期会重点更新。
1. 概述
1.1 个性化推荐系统
个性化推荐系统需要依赖用户的行为数据, 因此一般都是作为一个应用存在于不同网站之中。
- 基于物品的推荐算法(item-based method)
- EdgeRank 算法(Facebook)
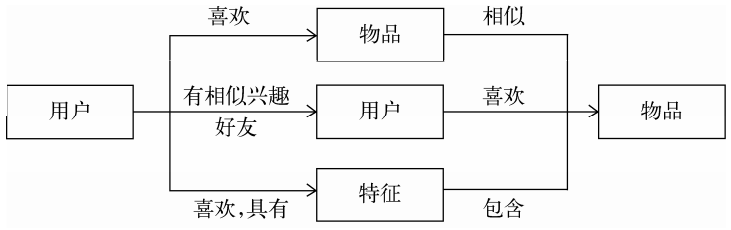
推荐系统的核心任务可以被拆解成两部分, 一个是如何为给定用户生成特征, 另一个是如何根据特征找到物品。
用户的特征种类非常多, 主要包括如下几类:
- 人口统计学特征
- 用户的行为特征
- 用户的话题特征
1.2 评分预测
评分预测问题都是推荐系统研究的核心。评分预测问题最基本的数据集就是用户评分数据集。该数据集由用户评分记录组成, 每一条评分记录是一个三元组(u,i, r), 表示用户u给物品i赋予了评分r, 本章用 rui 表示用户u对物品i的评分。
评分预测问题基本都通过离线实验进行研究。在给定用户评分数据集后, 研究人员会将数据集按照一定的方式分成训练集和测试集, 然后根据测试集建立用户兴趣模型来预测测试集中的用户评分。对于测试集中的一对用户和物品(u, i), 用户u对物品i的真实评分是 rui , 而推荐算法预测的用户u对物品i的评分为 rˆui , 那么一般可以用均方根误差RMSE度量预测的精度:
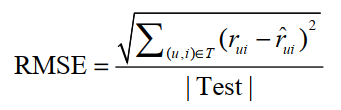
评分预测的目的就是找到最好的模型最小化测试集的RMSE。
- 平均值: 最简单的评分预测算法是利用平均值预测用户对物品的评分的。
- 全局平均值
- 用户评分平均值
- 物品评分平均值
- 用户分类对物品分类的平均值
1.3 用户标签
标签是一种无层次化结构的、用来描述信息的关键词, 它可以用来描述物品的语义。根据给物品打标签的人的不同, 标签应用一般分为两种: 一种是让作者或者专家给物品打标签; 另一种是让普通用户给物品打标签, 也就是UGC(User Generated Content, 用户生成的内容)的标签应用。
一个用户标签行为的数据集一般由一个三元组的集合表示, 其中记录(u, i, b) 表示用户u给物品i打上了标签b。
标签清理的另一个重要意义在于将标签作为推荐解释。如果我们要把标签呈现给用户, 将其作为给用户推荐某一个物品的解释, 对标签的质量要求就很高。首先, 这些标签不能包含没有意义的停止词或者表示情绪的词, 其次这些推荐解释里不能包含很多意义相同的词语。
一般来说有如下标签清理方法:
- 去除词频很高的停止词
- 去除因词根不同造成的同义词
- 去除因分隔符造成的同义词
4种标签解释:
- RelSort: 对推荐物品做解释时使用的是用户以前使用过且物品上有的标签, 给出了用户对标签的兴趣和标签与物品的相关度, 但标签按照和物品的相关度排序。
- PrefSort: 对推荐物品做解释时使用的是用户以前使用过且物品上有的标签, 给出了用户对标签的兴趣和标签与物品的相关度, 但标签按照用户的兴趣程度排序。
- RelOnly: 对推荐物品做解释时使用的是用户以前使用过且物品上有的标签, 给出了标签与物品的相关度, 且标签按照和物品的相关度排序。
- PrefOnly: 对推荐物品做解释时使用的是用户以前使用过且物品上有的标签, 给出了用户对标签的兴趣程度, 且标签按照用户的兴趣程度排序。
PrefOnly > RelSort >PrefSort > RelOnly
1.3.1 用户画像
用户画像是一个标签化的用户模型, 用于描述用户的基础属性、生活习性和关系链等信息, 对于业务了解用户具有非常重要的意义, 可以帮助大幅度的提升推荐的准确度。在设计推荐系统的同 时, 也需要重视对画像系统的构建。
1.4 推荐引擎的架构图
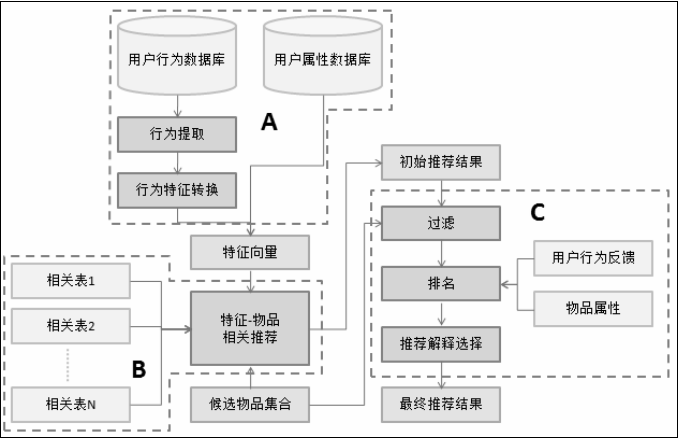
常见的数据清洗有: 空值检查、数值异常、类型异常、数据去重等。
重排过滤步骤会给用户提供一些探索性的内容, 避免用户在平台上看到的内容过于同质化而失去兴趣, 同时过滤掉低俗和违法的内容, 保持一个良好的平台环境。

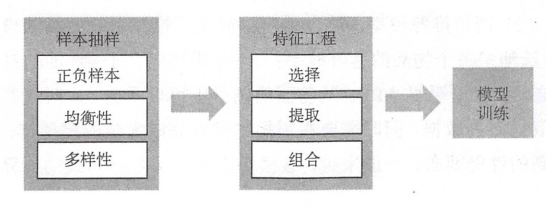
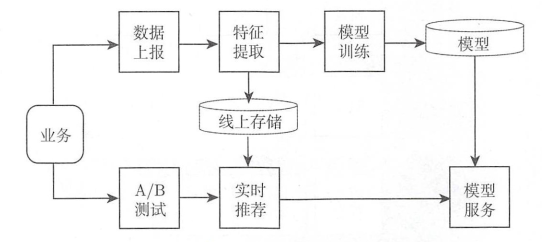
一个典型的面向深度学习的推荐系统架构如图所示, 和前一节提到的架构相比, 面向深度学习的推荐系统架构增加了特征提取和模型服务两个模块:
2. 评测推荐系统
离线算法评估常见的指标包括准确率、覆盖度、多样性、新颖性和 AUC 等。在线测试一般通过A/B Test进行, 常见的指标有点击率、用户停留时间、广告收入等, 需要注意分析统计显著性。
- 离线实验
- 用户调查
- 在线实验(A/B Test):
算法的覆盖率, 覆盖率反映了推荐算法发掘长尾的能力, 覆盖率越高, 说明推荐算法越能够将长尾中的物品推荐给用户。
召回率常用于信息检索, 它表示用户有效观看的物料中由推荐系统推荐的数量。召回率表示命中次数相对于测试次数的百分比。
实验研究的几条基本准则:
- 假设: 在执行实验之前, 必须形成一个假设
- 变量控制
- 泛化能力
2.1 性能指标
| 指标 | 说明 |
|---|---|
| RMSE | 均方根误差。值越低, 精度越高。 |
| MAE | 平均绝对误差, 均方差。值越低, 精度越高。 |
| HR | 命中率;我们多久能够推荐一次遗漏评级。越高越好。 |
| cHR | 累计命中率;命中率, 仅限于高于特定阈值的评级。越高越好。 |
| ARHR | 平均互惠命中率 - 考虑排名的命中率。越高越好。 |
| Coverage | 建议超过特定阈值的用户比例。越高越好。 |
| Diversity | 1-S, 其中 S 是给定用户的每个可能建议对之间的平均相似性分数。越高意味着越多样化。 |
| Novelty | 推荐商品的平均人气排名。越高越意味着更新颖。 |
2.1.1 均方根(RSME)
计算了预测值和实际值的平均误差, 一般来说, 对所有的样本同等看待。
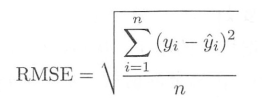
2.2 A/B test
为了明确指标的变化是由推荐服务变更引入, 通常会使用AB实验方式, 将流量进行划分, 对比两实验最终的业务指标。它通过一定的规则将用户随机分成几组, 并对不同组的用户采用不同的算法, 然后通过统计不同组用户的各种不同的评测指标比较不同算法, 比如可以统计不同组用户的点击率, 通过点击率比较不同算法的性能。
P值、置信区间、效应量是衡量试验结果的三个最重要的指标。

2.2.1 分流
常见的分流策略有:
- Random - 随机分流, 用于可变结果集
- Partition By User –「按用户切分」, 同一用户永远看到同样结果
- Partition By Category -「按分类切分」, 针对不同分类测试算法针对性。
2.2.2 置信区间
推荐系统的置信度可以定义为系统在推荐和预测上的可信度。
置信区间的不同表现, 可用作判断试验结果显著与否的标准: 在试验运行一段时间之后(一般来说是1-2周), 如果置信区间的上下限同为正, 说明试验结果是统计显著的, 并且试验版本优于对照版本; 如果同为负, 试验结果也是统计显著的, 且对照版本优于试验版本; 如果置信区间为一正一负, 则说明版本间差异不大。
值得注意的是, 置信区间同为正或负, 只能说明试验是统计显著的(也就是试验版本和对照版本有差异), 但是这个差异有可能是非常小的, 在实际应用中微不足道的。因此, 只有兼备统计显著和效果显著两个特征的结果, 才能说明该版本是可用, 值得发布的。
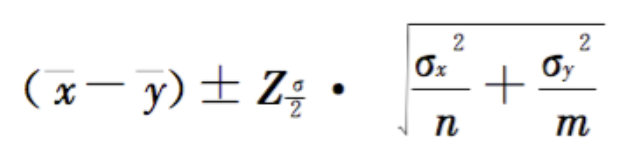
- x, y 是CTR均值 (实际用户*click物料 / 样本数)
- σᵪ, σᵧ 是CTR标准差
- Z是为下面查到的Z值
- n, m 是样本的数量
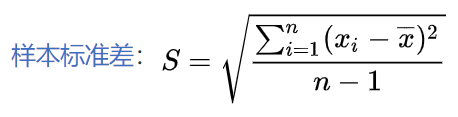
如:
| 分组 | 样本量 | CTR均值 | CTR标准差 |
|---|---|---|---|
| 实验组A | 10000 | 0.15 | 0.06 |
| 对照组B | 200000 | 0.13 | 0.05 |
则:
Z =((0.15 - 0.13) - (0-0))/√(0.06²/10000 + 0.05²/200000) = 32.79
CI = (0.15 - 0.13) ± z * √(0.06²/10000 + 0.05²/200000) = (0.00, 0.04)
p = 2 * (1-ɸ(|z|)) = 0.0
效应量: d = (0.15 - 0.13) / √((10000-1)0.06² + (200000-1)*0.05²)/(10000+200000-2) = 0.395875
| 80% | 85% | 90% | 95% | 99% | 99.5% | 99.9% | |
|---|---|---|---|---|---|---|---|
| Z | 1.282 | 1.440 | 1.654 | 1.960 | 2.576 | 2.807 | 3.291 |
2.2.3 灵敏度,P-value
p-value即概率, 反映某一事件发生的可能性大小, 主要在A/B Test中说明实验的提升的显著性, 并且往往与假设检验相挂钩, 即如果P值超过某一阈值那么算法A并不比算法B好。习惯上, 取P=0.05作为阈值值, 也就是置信度小于95%。在错误选择的代价较高的情况下可以使用更严格的显著性水平(如0.01或者更低)。
2.3 推荐系统属性
- 用户偏好
- 预测准确度
- 覆盖率
- 置信度
- 信任度
- 新颖度
- 惊喜度
- 多样性
- 效用
- 风险
- 健壮性
- 隐私
- 适应性
- 可扩展性
3. 推荐算法
在推荐系统的众多算法中, 基于内容的推荐与基于领域的推荐在实践中得到了最广泛的应用。其中, 基于领域的算法有分为两大类, 一类是基于用户的协同过滤算法, 另一类是基于物品的协同过滤算法。
基于内容的推荐系统本质是对内容进行分析, 建立特征。这些特征通常可以分为两种: 结构化(structured)的特征与非结构化(unstructured)的特征。
- 基于内容(Content Based): 物品键的相似性是基于被比较的物品的特征来计算的
- 协同过滤(Collaborative Filtering)
- 基于领域的协同过滤方法(UserCF & ItemCF)
- 隐语义模型(LFM)
- 矩阵因子分解(如奇异值分解、SVD)
- Simon Funk的SVD分解
- 加入偏置项后的LFM
- 考虑邻域影响的LFM: 将用户历史评分的物品加入到了LFM模型中, Koren将该模型称为SVD++
- 基于人口统计学的
- 基于知识(Knowledge-based)
- 基于约束的
- 基于社区(Community-based)
- 混合推荐系统(Hybrid Recommender System)
- 模型级联融合
- 模型加权融合
- 加入时间信息
- 基于邻域的模型融合时间信息
- 基于矩阵分解的模型融合时间信息
3.1 基于内容的推荐算法
发掘用户曾经喜欢的产品, 从而尝试去推荐类似的产品使其满意。主要的处理方式在于利用用户已知的偏好、兴趣等属性和物品内容的属性相匹配, 以此为用户推荐新的感兴趣的物品。
优点:
- 用户独立性
- 透明度
- 新物品
缺点:
- 可分析的内容有限
- 过度特化
- 新用户
方法:
- 基于关键字向量空间模型(Vector Space Model, VSM)
- 运用本体的语义分析
- 概率方法和朴素贝叶斯
- 多元伯努利事件模型
- 多项式事件模型
- 相关反馈和 Rocchio 算法
3.2 基于协同过滤的推荐算法
协同过滤方法可以大致分为两类:
- 基于近邻方法
- 基于模型方法
- 贝叶斯聚类(Bayesian Clustering)
- 潜在语义分析(Latent Semantic Analysis)
- 潜在狄利克雷分布(Latent Dirichlet Allocation)
- 最大熵(Maximum Entropy)
- 玻尔兹曼机(Boltzmann Machines)
- 支持向量机(Support Vector Machines)
- 奇异值分解(Singular Value Decomposition)
基于近邻系统是在预测中直接使用已有数据预测, 而基于模型的方法是使用这些评分来学习预测模型。
- 可解释性
- 新的评分
3.2.1 基于记忆的协同过滤
基于用户行为分析的推荐算法是个性化推荐系统的重要算法, 学术界一般将这种类型的算法称为协同过滤算法。顾名思义, 协同过滤就是指用户可以齐心协力, 通过不断地和网站互动, 使自己的推荐列表能够不断过滤掉自己不感兴趣的物品, 从而越来越满足自己的需求。但是会过于依赖历史数据。
用户行为数据在网站上最简单的存在形式就是日志。网站在运行过程中都产生大量原始日志(raw log), 并将其存储在文件系统中。很多互联网业务会把多种原始日志按照用户行为汇总成会话日志(session log), 其中每个会话表示一次用户行为和对应的服务。
用户行为在个性化推荐系统中一般分两种——显性反馈行为(explicit feedback)和隐性反馈行为(implicit feedback):
- 显性反馈行为包括用户明确表示对物品喜好的行为
- 隐性反馈行为指的是那些不能明确反应用户喜好的行为。最具代表性的隐性反馈行为就是页面浏览行为
一个用户行为表示为6部分, 即产生行为的用户和行为的对象、行为的种类、产生行为的上下文、行为的内容和权重:
| 部分 | 说明 |
|---|---|
| user id | 产生行为的用户的唯一标识 |
| item id | 产生行为的对象的唯一标识 |
| behavior type | 行为的种类(比如是购买还是浏览) |
| context | 产生行为的上下文, 包括时间和地点等 |
| behavior weight | 行为的权重(如果是观看视频的行为, 那么这个权重可以是观看时长; 如果是打分行为, 这个权重可以是分数) |
| behavior content | 行为的内容(如果是评论行为, 那么就是评论的文本; 如果是打标签的行为, 就是标签) |
用户行为数据蕴含着长尾规律(Power Law分布, 或长尾分布):
仅仅基于用户行为数据设计的推荐算法一般称为协同过滤算法。学术界对协同过滤算法进行了深入研究, 提出了很多方法, 比如基于邻域的方法(neighborhood-based)、隐语义模型(latent factor model)、基于图的随机游走算法(random walk on graph)等。而基于邻域的方法主要包含下面两种算法:
- 基于user的CF:
- 对用户购买过物品的索引数据转化成物品被用户购买过的索引数据, 即物品的倒排索引, 然后根据相似度公式计算用户之间的相似度
- 针对用户U 挑选K个最相似的用户, 把他们购买过的物品中 U未购买过的物品推荐给用户U即可
- 基于item的CF
- 基于共同喜欢物品的用户列表计算
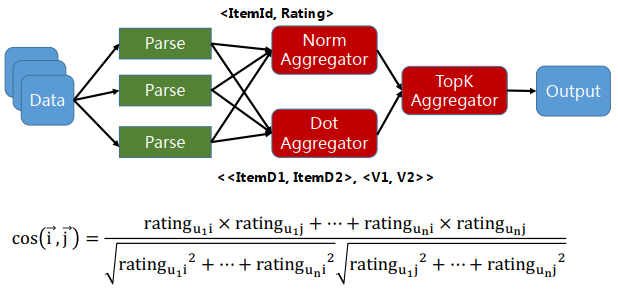
- 基于余弦(Cosine-bases)的相似度计算
- 热门物品的惩罚
UserCF 是推荐用户所在兴趣小组中的热点, 更注重社会化, 而ItemCF 则是根据用户历史行为推荐相似性物品, 更注重个性化。从技术上考虑, UserCF需要维护一个用户相似度的矩阵, 而ItemCF需要维护一个物品相似度矩阵。
3.2.1.1 基于用户的协同过滤
找到和目标用户兴趣相似的用户集合
协同过滤算法主要利用行为的相似度计算兴趣的相似度。
找到这个集合中的用户喜欢的, 且目标用户没有听说过的物品推荐给目标用户
3.2.1.2 基于物品的协同过滤
基于物品的协同过滤(item-basedcollaborativefiltering)算法是目前业界应用最多的算法。论是亚马逊网, 还是Netflix、Hulu、YouTube, 其推荐算法的基础都是该算法。基于物品的协同过滤算法(简称ItemCF)给用户推荐那些和他们之前喜欢的物品相似的物品。不过, ItemCF算法并不利用物品的内容属性计算物品之间的相似度, 它主要通过分析用户的行为记录计算物品之间的相似度。
基于物品的协同过滤算法主要分为两步:
- 计算物品之间的相似度
- 根据物品的相似度和用户的历史行为给用户生成推荐列表
如果将ItemCF的相似度矩阵按最大值归一化, 可以提高推荐的准确率。归一化的好处不仅仅在于增加推荐的准确度, 它还可以提高推荐的覆盖率和多样性。
当item数量很大时, 计算量会大到难以计算, 没有利用到矩阵稀疏的性质。
对于用户数量远远大于物品数量的大型商业系统, 基于物品的推荐方法更加准确, 同样, 用户数少于物品数的系统, 可能采用基于用户的近邻方法会更有益。
3.2.1.3 增强的基于领域的模型
- 基于全局最优化的邻域模型
- 因式分解的邻域模型
- 基于邻域的模型的动态时序
3.2.2 隐语义模型(LFM, Latent Factor Model)
该算法最早在文本挖掘领域被提出, 用于找到文本的隐含语义。相关的名词有LSI、 pLSA、 LDA和Topic Model。它的核心思想是通过隐含特征(latent factor)联系用户兴趣和物品。
用隐语义模型来进行协同过滤的目标是揭示隐藏的特征, 这些隐藏的特征能够解释观测到的评分。
隐含语义分析技术采取基于用户行为统计的自动聚类。
隐含语义分析技术从诞生到今天产生了很多著名的模型和方法, 其中和该技术相关且耳熟能详的名词有pLSA、LDA、隐含类别模型(latent class model)、隐含主题模型(latent topic model)、矩阵分解(matrix factorization)。这些技术和方法在本质上是相通的, 其中很多方法都可以用于个性化推荐系统。
LFM模型在实际使用中有一个困难, 那就是它很难实现实时的推荐。经典的LFM模型每次训练时都需要扫描所有的用户行为记录, 这样才能计算出用户隐类向量 (pᵤ)和物品隐类向量 (qᵢ)。而且LFM的训练需要在用户行为记录上反复迭代才能获得比较好的性能。
潜在因子推荐方法(奇异值分解, SVD)
SVD(Singular Value Deomposition)中文名字奇异值分解, 顾名思义, 是一种矩阵分解的方法, 任何矩阵, 都可以通过SVD的方法分解成几个矩阵相乘的形式。
SVD的一大优势是有增量算法来计算近似的分解。
A = U * S * V, 其中A就是被分解的矩阵, A矩阵是 m*n维的, U是一个正交矩阵 m*m 维的, S是一个特征值矩阵(即对角元素均为A的特征值) m*n 维, V也是一个正交矩阵 n*n维的。
给定一个矩阵, 我们都可以分解得到两种矩阵, 一种是用户信息矩阵, 一种是评价信息(产品)矩阵。这两种矩阵在本例中使用了n_features = 2, 即对于用户向量或者产品评价向量长度均为2, 实际上也可以为其他数字(比如3, 4, …)
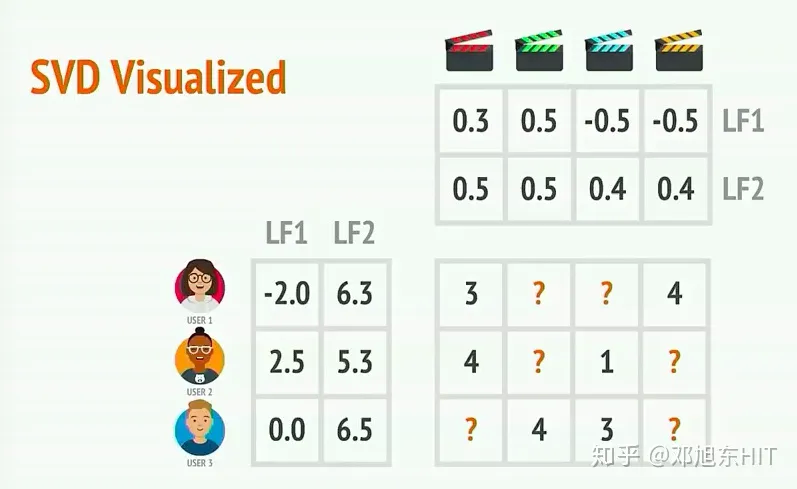
那么User1对于蓝色电影的喜欢程度是可以通过向量计算得出3.52

- SVD++
- time-SVD++
- 三维矩阵分解
# evaluate()方法在1.0.5版中已弃用(功能上已由model_selection.cross_validate()取代), 并在1.1.0版中删除
from surprise import SVD, Reader, Dataset
from surprise.model_selection import cross_validate
reader = Reader(line_format='user item rating timestamp', sep=',')
data = Dataset.load_from_file('E:/Learn/python/RecSys/test.csv', reader=reader)
# 评估效果
svd = SVD()
cross_validate(algo=svd,data=data,measures=['RMSE', 'MAE'],cv=5,verbose=True)
# 预测
data = data.build_full_trainset()
svd = SVD()
svd.fit(data)
print(svd.predict('user01', 'm03', 4))
3.3 基于知识图谱的增强
3.3.1 基于图的模型(graph-based model)
用户行为很容易用二分图表示, 因此很多图的算法都可以用到推荐系统中。其实, 很多研究人员把基于邻域的模型也称为基于图的模型, 因为可以把基于邻域的模型看做基于图的模型的简单形式。
- 基于随机游走的PersonalRank算法
3.3.2 RippleNet
3.3.3 KGCN
3.3.4 GNN
3.4 基于Deep Learn的推荐
和传统的推荐系统相比, 面向深度学习的推荐系统有着自动提取特征、建模用户时序行为和融合多方数据源的优点。深度学习对于推荐系统在以下几个方面确实起到了不可替代的作用:
- 能够直接从内容中提取特征, 表征能力强
- 容易对噪声数据进行处理, 抗噪能力强
- 可以使用循环神经网络对动态或者序列数据进行建模
- 可以更加准确地学习 user 和 item 的特征
面向深度学习的推荐系统中使用的常用算法有: 受限玻尔兹曼机(RBM)、自编码器(CAE)、卷积神经网络(CNN)、深度神经网络(DNN)和宽深学习(Wide & D eep)等。
基于在线训练的推荐系统中使用的常用的算法有: FTRL-Proximal、AdPredictor、Adaptive Online Learning和 PBODL 等。
Matrix Factorization
Autodiff
Bayesian bandit
RBM
神经元也叫作感知器
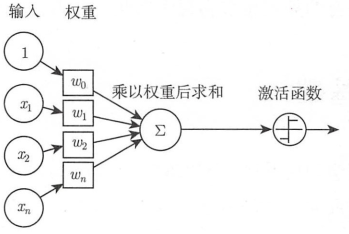
感知器的激活函数可以有很多选择, 比如阶跃函数: f(z) = max(z, 0)
感知器的输出由公式计算: y = f(wx +b), b为偏置项, 即上图中的w₀。
网络层的权重是随机初始化的。为了校正网络的权重, 就要利用神经网络反向传播的算法, 修正权重参数, 是输出值逼近目标值。反向传播算法是一种基于微积分链式求导的递归算法。
3.3.1 CNN,卷积神经网络
- 受到视觉系统的启发, 会考虑输入的空间结构。
- 整个网络可以表示成可微分的端到端函数:
f: x → u, 其中 z 是原始图像, u 是类别分数。卷积网络通过损失函数, 比如交叉熵来优化网络参数。 - 与标准神经网络相比, CNN 具有更少的参数, 从而可以有效地训练非常深的架构
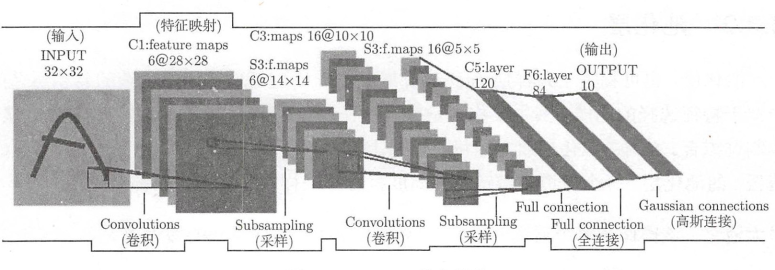
卷积层是卷积神经网络的核心图层, 用来提取局部区域的特征。
池化层, 也可称为子采样层(subsampling layer), 它通常被用在连续的卷积层之间, 类似于特征选择的功能, 其主要作用是减少特征和参数数量, 减少网络的计算量, 从而控制过拟合。
常见的网络结构:
-
LeNet-5: 手写体字母图形识别
-
AlexNet: 主要用于图像分类
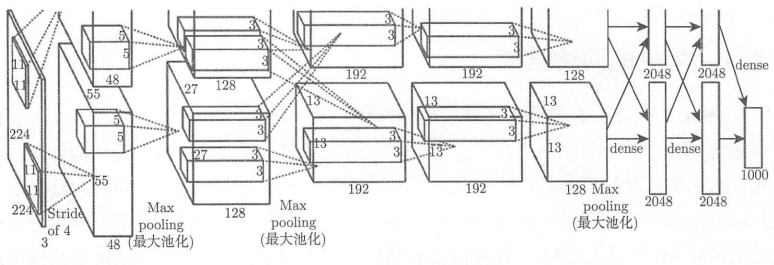
-
GoogLeNet
-
ResNet
3.3.2 RNN,循环神经网络
自回归模型, 该模型在序列中基于历史的许多项做加权平均, 并试图预测下一项, 没有隐藏状态。
RNN 有循环性, 因为序列的每个时刻都执行相同的任务, 每个时刻的输出依赖于当前时刻的输入和上一时刻的隐藏状态。
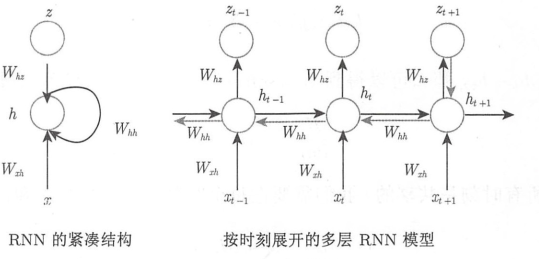
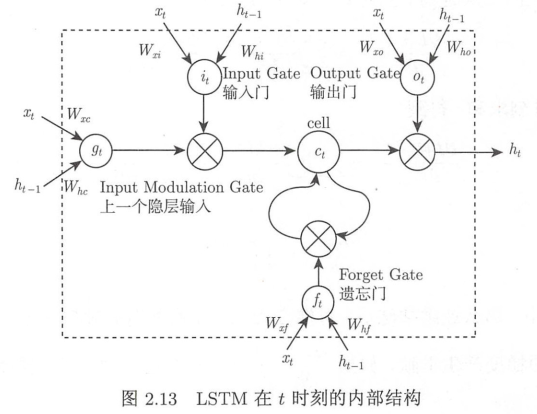
- LSTM: 长短期记忆网络, 同时引入记忆单元和门机制, 同时有效解决了梯度消失和梯度爆炸问题, 扩展了 RNNs 模型
3.3.3 GAN,生成对抗网络(Generative Adversarial Networks)
源自于 Ian J. Goodfellow 在 NIPS 2014 上的同名论文。GAN 的出现为无监督学习打开了另外一扇门。

-
CGAN: Conditional GAN
传统的 GAN 是一种无条件(Unconditional)的 GAN, 基于纯无标注数据的 GAN 网络生成器的输入是随机的向量, 无法控制图像的生成。为了可以控制 GAN 生成特定目的图像, CGAN (Conditional GAN)应运而生, 给 GAN 的图像生成加上额外的
条件(比如类别标签)作为上下文, 让 GAN 网络的生成与当前的条件上下文息息相关, 但是同时也需要原始图像和上下文条件配对的数据。CycleGAN、DualGAN 尝试降低 CGAN 对配对数据的依赖。 -
DCGAN: Deep Convolutional Generative Adversarial Networks
DCGAN 最主要的变化是替换掉原来的多层感知机, 采用深度卷积网络来作为生成器和判别器的基础组件, 并且还有很多优化技巧的改进让深度卷积网络工作得更好。StackGAN -
GGAN
-
SeqGAN
SeqGAN 打开了 GAN 在 NLP 上应用的一扇大门。Texygen 平台, 是一个新的 GAN 文本生成评测平台, 提供了最新的基于 GAN 的文本生成模型 -
IRGAN: 不应该被认为是推荐场景中 GAN 应用的标准范式, 它仅仅提供一种思路更好地去拓展 GAN 在推荐系统中的应用。它是一个初步的尝试, 而不应作为范例而限制大家的思路。
一些比较经典 GAN 的应用包括: 数据增强、草图生成实图、生成高分辨率的照片、拍照美颜等, 有兴趣可以了解 Pix2pix 项目。
3.3.4 DNN
使用外积特征变换的线性模型只需少量参数就能记住这些"特殊偏好".
DNN 的目标就是在用户信息和上下文信息为输入条件下学习用户的 embedding 向量 u。用公式表达DNN 就是在拟合函数 u = f _DNN(user_info, context_info)
把召回阶段的信息, 比如推荐来源和所在来源的分数, 传播到排序阶段同样能取得很好的提升效果。
DNN 更适合处理连续特征, 因此稀疏的特别是高基数空间的离散特征需要embedding到稠密的向量中。
直接在DNN上演变的模型有:
- AutoRec: 将自编码器(AutoEncoder)与协同过滤结合的单隐层神经网络模型, 利用协同过滤中的共现矩阵, 完成物品/用户向量的自编码, 基于自编码的结果得到用户对物品的预估评分, 进而排序。AutoRec模型结构和word2vec结构一致, 相对简单, 但优化目标和训练方法有所不同, AutoRec表达能力有限。
- Deep Crossing: 由微软于2016年发布, 用于其搜索引擎Bing中的搜索广告推荐场景。Deep Crossing完善了深度学习在推荐领域的实际应用流程, 提出了一套完整的从特征工程、稀疏向量稠密化、多层神经网络进行优化目标拟合的解决方案, 开启了无需任何人工特征工程的时代。
- NeuralCF: 2017年的NCF用“多层神经网络+输出层”的结构替代了矩阵分解中的简单内积操作, 让用户/物品向量做更充分的交叉, 引入更多的非线性特征, 增强模型表达能力。作者还提出一种“广义矩阵分解”(Generalized Matrix Factorization)模型融合了简单内积操作与多层神经网络两种特征交叉方式。NCF模型同协同过滤一样只利用了用户物品的共现矩阵, 并没有融合其他特征信息。
- PNN: 2016年的PNN模型在Deep&Crossing的基础上使用乘积层(Product Layer)代替Stacking层。即不同特征的Embedding向量不再是简单的拼接, 而是通过Product操作两两交互。这里的Product操作包含两种: 内积操作和外积操作。
- Wide&Deep: Google于2016年提出Wide&Deep模型, 模型使用单输入层的Wide部分处理大量稀疏的id特征, 提升记忆能力; 使用Embedding和多隐层的Deep部分处理全量特征, 赋予模型泛化能力。Wide部分的输入特征除了原始的id特征(已安装应用和曝光应用)外, 还包括转换后的特征, 如叉乘变换(Cross Product Transformation), 其实就是将单独的特征转换为组合特征, 给模型增加非线性能力。
- Deep&Cross: 斯坦福和Google合作基于Wide&Deep的改进。主要思路是使用Cross网络替代Wide部分, 目的是通过多层交叉(Cross layer)增加特征之间的交互力度; Deep部分则与Wide&Deep保持一致。
3.3.5 基于 DeepFM 的推荐算法
该模型的设计思路来自哈工大&华为诺亚方舟实验室, 主要关注如何学习user behavior背后的组合特征(feature nteractions), 从而最大化推荐系统的CTR。
DeepFM 是一个集成了FM(Factorization Machine)和 DNN 的神经网络框架, 思路和 Google 的 Wide&Deep有相似的地方, 都包括wide和deep两部分:
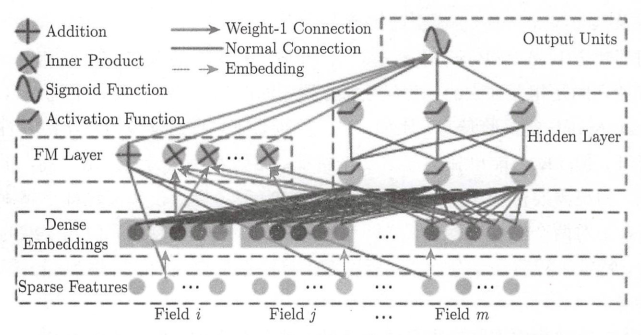
3.3.6 基于矩阵分解和图像特征的推荐算法(Matrix Factorization+, 缩写为MF+)
- 词嵌入表示模型(embedding models)
3.5 分类预测模型
3.5.1 基于逻辑回归的模型
逻辑回归模型是目前使用最多的机器学习分类方法, 在推荐系统中的应用非常广泛. 通常的做法是挑选两组人群进行对比实验, A组选择的是购买该商品的人群, B组选择未购买该商品的人群, 这两组实验人群具有不一样的用户画像特征和行为特征, 比如性别、年龄、城市和历史购买记录等, 产品经理经过统计找出购买某类商品的主要因素或者因素组合。
数值求解方法还有 Newton-Raphson方法、QuasiNewton方法等。
3.5.2 基于支持向量机的模型(SVM)
支持向量机模型把训练样本映射到高维空间中, 以使不同类别的样本能被清晰的超平面分割出来。而后, 新样本继续映射到相同的高维空间, 基于它落在超平面的哪一边预测样本的类别, 所以支持向量机模型是非概率的线性模型。支持向量机模型是非概率的线性模型.
3.5.3 基于梯度提升树的模型
被广泛应用到分类、回归和排序问题中。该算法是一种 Additive 树模型, 每棵树学习之前 Additive 树模型的残差, 它在被提出之初就和 SVM 一起被认为是泛化能力较强的算法。
3.6 基于上下文信息
3.6.1 时间上下文
时间是一种重要的上下文信息, 对用户兴趣有着深入而广泛的影响。
- 用户兴趣是变化的
- 物品也是有生命周期的
- 季节效应
研究一个时变系统, 需要首先研究这个系统的时间特性。包含时间信息的用户行为数据集由一系列三元组构成, 其中每个三元组(u,i,t)代表了用户u在时刻t对物品i产生过行为。
推荐算法需要平衡考虑用户的近期行为和长期行为, 即要让推荐列表反应出用户近期行为所体现的兴趣变化, 又不能让推荐列表完全受用户近期行为的影响, 要保证推荐列表对用户兴趣预测的延续性。
提高推荐结果的时间多样性需要分两步解决: 首先, 需要保证推荐系统能够在用户有了新的行为后及时调整推荐结果, 使推荐结果满足用户最近的兴趣; 其次, 需要保证推荐系统在用户没有新的行为时也能够经常变化一下结果, 具有一定的时间多样性。
3.6.2 地点上下文
不同地区的用户兴趣所不同, 用户到了不同的地方, 兴趣也会有所不同。
3.6.3 心情上下文
3.7 基于社交网络数据
- EdgeRank: Facebook
- node2vec: 通过network embedding 的方法来计算用户的坐标, 线上计算用户之间的相似度时, 只要计算坐标的距离或者余弦相似度即可
- random walk: 随机游走
- word2vec: 主流的特征构造方法, Word2Vec 模型中, 主要有Skip-Gram 和 CBOW两种模型。
在社交网络中, 需要表示用户之间的联系, 可以用图G(V,E,W)定义一个社交网络。
predicted rating
actual rating
error
3.8 基于位置的服务
3.9 混合推荐
- NetFlix: 三段式(在线–离线–近线)混合推荐系统
- YouTube: 深度学习的混合推荐算法(候选列表生成和精致排序)
分类:
- 加权型混合推荐: 利用不同的推荐算法生成的候选结果, 进行进一步的加权组合, 生成最终的推荐排序结果, 如P-Tango, Pazzani
- 切换型混合推荐: 根据问题的背景和实际情况来使用不同的推荐技术, 如DailyLearner, NewsDude
- 交叉型混合推荐: 将不同推荐算法的生成结果, 按照一定的配比组合在一起, 打包后集中呈现给用户
- 特征组合型混合推荐: 将来自不同推荐数据源的特征组合, 由一种单一的推荐技术使用
- 瀑布型混合推荐: 采用了过滤的设计思想, 将不同的推荐算法视为不同粒度的过滤器, 尤其是面对待推荐对象和所需的推荐结果数量相差极为悬殊时, 往往非常适用, 如: EntreeC
- 特征递增型混合推荐: 即将前一个推荐方法的输出作为后一个推荐方法的输入
- 元层次型混合推荐: 将不同的推荐模型在模型的层面上进行深度的融合
4. 过滤和排序
4.1 过滤
- 用户已经产生过行为物品
- 候选物品以外的物品
- 某些质量很差的物品
4.2 排序
作为排序任务, 优化的目标是维持一个相对偏序关系, 对预测分数的绝对值不是那么敏感。
经典的排序指标包括 MAP(Mean Reciprocal Rank)、MRR(Mean Average Precision),这两类指标是基于分类标签的取值, 只有相关(1)或者不相关(0)两个结果。
NDCG(Normalized Discounted Cumulative Gain)是一个更常用的指标。 DCG 的定义为:
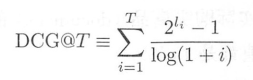
L2R 系列算法一般分成三类, 分别是Point-wise、Pair-wise和List-wise:
-
Point-wise的方案实现简单, 基于单个样本去优化, 排序问题退化成通用的回归/分类问题, 一般是一个二分类的任务, 是机器学习的典型判别问题。
-
Pair-wise的方案将排序问题约减成一个对偏序对的二分类问题, 即偏序对关系正确还是错误, 一个附带的好处是可以方便利用多粒度的相关性, 即使用户对商品有着非线性的多级评价程度, 例如, P(perfect)非常满意、G(Good)满意、满意B(Bad), 也可以方便地去构造这样的偏序对。
-
List-wise基于整个排序列表去优化, 对于单个用户(query)而言, 把整个需要排序的列表当成一个学习样本(instance), 直接通过 NDCG 等指标来优化。
5. 数据挖掘与特征
数据与特征决定了模型的上限, 而模型算法则为逼近这个上限。
特征转化包含对原始特征的各种变换, 更好第表达原始数据的内在规律, 便于模型算法进行训练, 而特征选择则提炼对模型表达有用的特征, 希望建立更灵活、更简单的模型。
5.1 数据挖掘
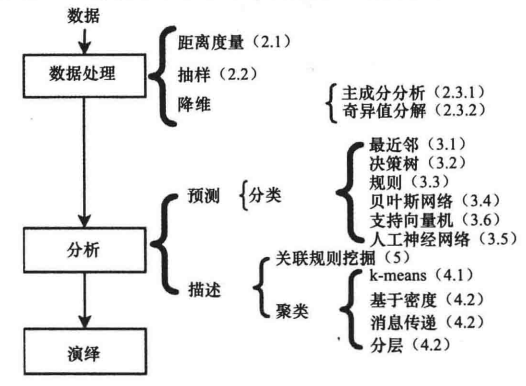
5.1.1 相似度或相关度
- 欧几里德距离
- 闵科夫斯基距离: 是欧几里德距离的扩展
- 马氏距离
- 余弦相似度(Adjusted Cosine, AC)
import numpy as np
from numpy.linalg import norm
from sklearn.metrics.pairwise import cosine_similarity
# define two lists or array
A = np.array([[2,1,2,3,2,9]])
B = np.array([[3,4,2,4,5,5]])
# compute cosine similarity
cosine = np.dot(A[0],B[0])/(norm(A[0])*norm(B[0]))
print("Cosine Similarity:", cosine)
print("Cosine Similarity:", cosine_similarity(A, B))
- 皮尔逊相关性(Pearson Correlation, PC):
df.corr() - Jaccard 相似度
- 均方差(Mean Squared Difference, MSD)
- 斯皮尔曼等级关联(Spearman Rank Correlation, SRC)
- 基于图
- 基于路径的相似度: 最短路径
- 随机游走相似性
- ItemRank 算法: 是基于 PageRank算法的一种推荐方法。基于用户在图中随机游走访问到物品i的概率, 对用户u对新物品i的喜爱程度进行排序, 其中图的节点表示评分物品, 有相同用户评分的节点间用边相连。
- 平均首次通过/往返次数
5.1.2 抽样
- 随机抽样
- 无替代的抽样
- 替代的抽样
- 交叉验证
5.1.3 降维
- 主成分分析: PCA
- 矩阵分解: MF
- 非负矩阵分解: NNMF
- 奇异值分解: SVD
- 正规化内核矩阵分解
5.1.4 去噪
5.2 分类
5.2.1 有监督分类
- 近邻分类: kNN
- 决策树
- 基于规则的分类
- 贝叶斯分类器
- 朴素贝叶斯
- 贝叶斯信念网络: BBN
- 人工神经网络: ANN
- 支持向量机分类
5.2.2 无监督分类
- 聚类
- 分层
- 划分
- k-means 聚类
5.3 特征处理
5.3.1 数值特征处理
- 无量纲处理
- 非线性变换
- 离散化
5.3.2 离散特征处理
- One-Hot 编码
- 特征哈希
- 时间特征处理
5.4 特征选择
5.4.1 单变量特征选择
单变量特征选择能够对每一个特征进行测试, 衡量该特征和响应变量之间的关系, 根据得分丢弃不好的特征。
- 皮尔森相关系数
- 距离相关系数
- 卡方检验
5.4.2 基于模型的特征选择
5.4.2.1 逻辑回归和正则化特征选择
越是重要的特征在模型中对应的系数就会越大, 而跟输出变量越是无关的特征对应的系数就会越接近于 0。
L1正则化将系数 w 的 L1范数作为惩罚项加到损失函数上, 由于正则项非零, 这就迫使那些弱的特征所对应的系数变成 0。
L2正则化将系数向量的L2范数添加到了损失函数中。由于L2惩罚项中系数是二次方的, 这使得L2和L1有着诸多差异, 最明显的一点就是, L2正则化会让系数的取值变得平均。
5.4.2.2 随机森林特征选择
随机森林具有准确率高、鲁棒性好、易于使用等优点, 这使得它成为了目前最流行的机器学习算法之一。随机森林提供了两种特征选择的方法: mean decrease impurity 和 mean decrease accuracy
5.4.2.3 XGBoost 特征选择
XGBoost 为工业级用的比较多的模型, 其某个特征的重要性(feature score), 等于它被选中为树节点分裂特征的次数的和, 比如特征A在第一次选代中(即第一棵树)被选中了1次去分裂树节点, 在第二次迭代被选中2次, 那么最终特征A的feature score就是 1+2, 可以利用其特征的重要性对特征进行选择.
5.4.2.4 基于深度学习的特征选择
对于图像特征的提取, 深度学习具有很强的自动特征抽取能力, 通常抽取其特征时将深度学习模型的某一层当作图像的特征。
6. 问题
6.1 冷启动
- 用户冷启动
- 物品冷启动
- 系统冷启动
解决方案:
- 有效利用用户帐号信息
- 用户设备信息
- 制作选项
- 利用物品的内容信息
- 利用专家标注的数据
- 深度学习
6.2 惊喜度
6.3 稀疏性(sparsity)和受限覆盖(limited coverage)
降维方法解决受限覆盖和数据稀疏性问题, 是通过将用户或者物品映射到隐变量空间以获取它们之间最突出的特征。
- 基于用户评分矩阵进行分解
- 隐式语义索引(Latent semantic indexing, LSI)
- 对稀疏的相似性矩阵进行分解
7. Engine Architecture
一套推荐系统常见的架构如下:
- 数据层: 提供数据接入、特征工程能能力
- 模型层: 提供召回、排序阶段的AI算法模型的开发、训练、部署、管理等能力
- 服务层: 提供模型封装API、结果干预、效果评估、AB实验等能力
7.1 智能推荐系统的比较
| 能力项 | 华为RES | 火山推荐服务 |
|---|---|---|
| 场景支持 | 不区分 | 区分电商/长视频/内容场景, 并根据不同场景提供定制化配置 |
| 历史数据导入方式 | 文件 | API、SDK |
| 增量数据导入方式 | API、SDK | API、SDK |
| 自定义字段 | 支持 | 支持 |
| 归因方式配置 | 未作说明, 不可自定义 | 默认提供马可夫链归因方式, 支持用户自定义 |
| 数据校验 | 仅支持历史数据质量校验; 支持指标为数据统计信息、分布信息 |
支持历史/增量数据质量校验; 支持指标为数据统计信息、分布信息、拼接率统计、归因率统计、业务指标统计; 支持数据质量阈值配置与告警; |
| 效果评估指标 | CTR | CTR、CVR、GMV、人均播放、订阅转化等多种指标 |
| 多推荐服务实例构建 | 不支持 | 支持 |
| AB实验 | 不支持 | 支持 |
7.2 推荐系统
7.2.1 基于约束的推荐系统
7.2.2 情境感知推荐系统(CARS)
在数据挖掘中, 情境有时被定义为能够标识顾客生活阶段的特征性事件, 这些事件可以改变她/他的喜好、状态和商业价值。
在电子商务场景中, 使用客户的购买意向作为一个情境。
在移动情境感知系统文献中, 情境最初定义为用户的地理位置、用户身边的人群的身份及用户附件的物品, 还有这些因素的变化。
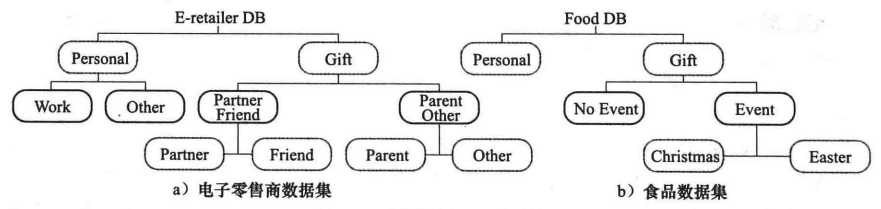
情境感知的SQL语句查询
- CoreDB
在推荐系统中利用情境信息:
- 通过情境驱动的查询和搜索产生的推荐
- 通过情境偏好提取和估计的推荐
- 情境预过滤
- 情境后过滤:(启发式和基于模型)
- 情境建模
来自于复杂的情境信息通常可被分成几个组成部分, 每个情境信息组成部分的作用可能是不同的, 从而有不同的实现选择。
7.3 深度学习推荐框架
7.3.1 TFRS - Tensorflow Recommenders
7.3.2 AWS DSSTNE
7.3.3 Keras
7.3.4 surprise
pip install scikit-surprise
# conda install -c conda-forge scikit-surprise
# https://sundog-education.com/RecSys/
7.4 MyMedia
MyMedia 是一个比较著名的开源推荐系统架构。它是由欧洲研究人员开发的一个推荐系统开源框架。该框架同时支持评分预测和TopN推荐, 全面支持各种数据和各种算法, 对该项目感兴趣的用户可以访问该项目的网站 http://www.mymediaproject.org/default.aspx。
8. Algorithm
8.1 Power Law
f(x) = axᵏ
两个变量之间通过幂定律(power law, 也称幂律)关联起来, 也就是说, 两个变量在对数空间下呈现出线性关系。
长尾(The Long Tail)这一概念是由《连线》杂志主编克里斯.安德森在2004年10月的《长尾》一文中最早提出。实际上是统计学中幂律(Power Laws)和帕累托分布(Pareto)特征的一个口语化表达。
当幂值大于1时, 幂定律的存在往往通过马太效应(Matthew effect)来解释。通俗说, “富者越富, 即一旦在某个特性获得高价值, 那么会导致该特性获得更大的价值。
齐夫定律 (英语: Zipf’s law, IPA /ˈzɪf/)是由哈佛大学的语言学家乔治·金斯利·齐夫于1949年发表的实验定律。它可以表述为: 在自然语言的语料库里, 一个单词出现的频率与它在频率表里的排名成反比。所以, 频率最高的单词出现的频率大约是出现频率第二位的单词的2倍, 而出现频率第二位的单词则是出现频率第四位的单词的2倍。这个定律被作为任何与幂定律概率分布有关的事物的参考。Zipf 定律, 最初来源于文档集中的词频统计
解决OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.报错问题
究其原因其实是, anaconda的环境下存在两个libiomp5md.dll文件。所以直接去虚拟环境的路径下搜索这个文件, 可以看到在环境里有两个dll文件:
其中第一个是torch路径下的, 第二个是虚拟环境本身路径下的, 转到第二个目录下把它剪切到其他路径下备份就好(最好把路径也备份一下)。
参考:
https://zhuanlan.zhihu.com/p/149600867
https://zhuanlan.zhihu.com/p/346602966
https://zhuanlan.zhihu.com/p/138446984
https://zhuanlan.zhihu.com/p/140894123
https://www.zhihu.com/question/19576347
