
目录
-
- 1. Dgraph 入门
- 2. GraphQL
- 3.DQL
DGraph 是由前 Google 员工 Manish Rai Jain 离职创业后, 在 2016 年推出的图数据库产品, 基于 Go 语言编写, 底层数据模型是 RDF, 存储引擎基于 BadgerDB 改造, 使用 RAFT 保证数据读写的强一致性。
Dgraph 不是另一个 SQL 或 No-SQL 数据库(如 Postgres 或 MongoDB)之上的层。相反, Dgraph 是一个从头开始构建的新数据库, 用于在图中本地管理数据。Dgraph 从磁盘读取数据, 访问 RAM, 并使用 HTTP 和 gRPC 通过网络进行对话。
1. Dgraph 入门
Dgraph从一开始就设计为在生产环境中运行, 是带有图形后端的原生 GraphQL 数据库。它是开源的、可扩展的、分布式的、高可用的和闪电般的速度。
Dgraph 集群由不同的节点(Zero、Alpha 和 Ratel)组成, 每个节点都有不同的用途。
- Dgraph Zero: 控制 Dgraph 集群, 将服务器分配给一个组, 并在服务器组之间重新平衡数据。
- Dgraph Alpha: 托管谓词和索引。谓词要么是与节点关联的属性, 要么是两个节点之间的关系。索引是可以与谓词相关联的标记器, 以启用使用适当函数的过滤。
- Ratel: 一个直接使用 DQL 的 GUI 层, 以运行查询、突变和改变模式。(Ratel 不适用于 graphql)。
1.1 运行Dgraph
对于快速入门来说, 使用 dgraph/standalone docker镜像是最快的方式。这个镜像是为快速入门而建的, 不建议在生产环境中使用。首先确保你的电脑已经安装并启动了Docker。
docker run --rm -it -v /data/dgraph:/dgraph -p 6080:6080 -p 8080:8080 -p 9080:9080 dgraph/standalone:latest
Dgraph通过 HTTP 为两个端点提供符合规范的 GraphQL : /graphql和/admin. 该实例将位于 alpha 端口和 url(http://localhost:8080如果您不更改任何设置, 则默认为)
在每种情况下, 都会提供 GET 和 POST 请求。
1.1.1 运行 Dgraph ratel UI界面
ratel 适用于 DQL 的接口操作和部分管理功能。
wget https://github.com/dgraph-io/ratel/releases/download/21.03/dgraph-ratel-linux.tar.gz
tar -xvf dgraph-ratel-linux.tar.gz
./ratel
1.1.2 Dgraph endpoints
DQL 端点:
- /query: 用于使用 DQL(Alpha) 发出查询请求, debug=true
- /mutate: 用于在 DQL(Alpha) 中发送突变(CRUD), commitNow=true
GraphQL 端点:
- /graphql: 于托管 GraphQL API, 将 GraphQL 重写为 DQL(Alpha)
- /admin: 用于管理 Dgraph 集群(Alpha)
其他端点
- /alter: 用于更改 DQL 架构(Alpha)
- /health- 用于查询健康(Alpha)
- /login- 用于登录 ACL 用户, 并为他们提供 JWT。(企业功能)
- /state- 用于查看有关属于集群的节点的信息。(Zero)
- /assign- 用于分配一系列 UID 和请求时间戳。(Zero)
- /removeNode- 用于从集群中删除死Zero或 Alpha 节点。(Zero)
- /moveTablet- 用于强制将平板电脑移动到一组。(Zero)
- /enterpriseLicense- 用于将企业许可证应用于集群。(Zero)
1.2 单机部署
依赖Node.js, 需要先安装Node.js, 并设置PATH环境变量
# Start dgraph zero
nohup /usr/local/dgraph/dgraph zero --my=192.168.137.3:5080 --wal=/data/dgraph/zero/zw 2>&1 > /data/logs/dgraph-zero.log &
# Start dgraph alpha
nohup /usr/local/dgraph/dgraph alpha --security whitelist=192.168.137.0/24 --my=192.168.137.3:7080 --zero=192.168.137.3:5080 --wal=/data/dgraph/zero/w --postings=/data/dgraph/zero/p --tmp=/data/dgraph/zero/t 2>&1 > /dev/null &
# Start dgraph ratel
nohup /usr/local/dgraph/dgraph-ratel 2>&1 > /dev/null &
# Close dgraph alpha
curl localhost:8080/admin/shutdown
1.2 节点(node)和边(edge)
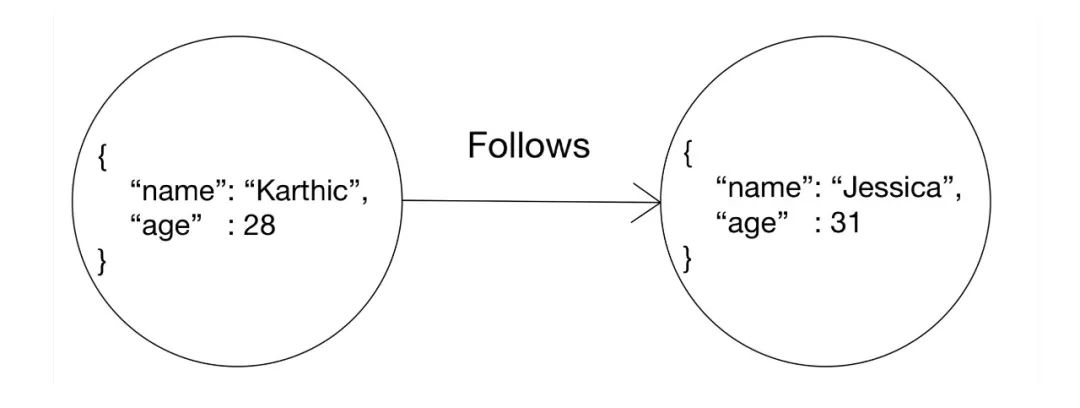
在图数据库中, 概念(concepts)或实体(entities)都是以nodes的形式来表达。不管它是一次拍卖、一笔交易、一处地点或一个人, 所有这些实体在图数据库中都以节点(nodes)的形式存在。
而边(edge)则是2个节点(nodes)间的关联关系。上图中2个节点(nodes)代表了2个人: Karthic和jessica。也能看到这些nodes有2个关联的属性: name 和 age。在Dgraph中, 这些属性(properties)叫作 谓词( predicates)。
1.3 GraphQL 和 DQL
Dgraph 是围绕 DQL 开发的, 它与 GraphQL 一样, 使用模式来分类和管理数据。
2. GraphQL
GraphQL 不是为 Graph 数据库开发的, 但其类似于图的查询语法、模式验证和子图形状的响应使其成为一个很好的语言选择。
GraphQL 请求可以包含一个或多个操作。操作包括query、mutation或subscription。如果一个请求只有一个操作, 那么它可以不命名.
当一个操作包含多个查询时, 它们在每个查询的 Dgraph 只读事务中并发且独立地运行。
当一个操作包含多个突变时, 它们会按照请求中列出的顺序以及每个突变在一个事务中顺序运行。如果一个突变失败, 后面的突变不会执行, 之前的突变也不会回滚。
type Product {
productID: ID!
name: String @search(by: [term])
reviews: [Review] @hasInverse(field: about)
}
type Customer {
username: String! @id @search(by: [hash, regexp])
reviews: [Review] @hasInverse(field: by)
}
type Review {
id: ID!
about: Product!
by: Customer!
comment: String @search(by: [fulltext])
rating: Int @search
}
采用上面的模式, 将其剪切并粘贴到一个名为schema.graphql并运行以下 curl 命令的文件中。
curl -X POST localhost:8080/admin/schema --data-binary '@schema.graphql'
它将回传它当前为其提供模式的类型, 该模式应该与输入模式相同。
2.1 GraphQL 中的保留名称
以下名称是保留名称, 不能用于定义任何其他标识符:
- Int
- Float
- Boolean
- String
- DateTime
- ID
- uid
- Subscription
- as(不区分大小写)
- Query
- Mutation
- Point
- PointList
- Polygon
- MultiPolygon
- Aggregate(作为任何标识符名称的后缀)
对于每种类型, Dgraph 都会生成一些操作 GraphQL API 所需的 GraphQL 类型, 这些生成的类型名称也不能出现在输入模式中。例如, 对于 type Author, Dgraph 生成:
- AuthorFilter
- AuthorOrderable
- AuthorOrder
- AuthorRef
- AddAuthorInput
- UpdateAuthorInput
- AuthorPatch
- AddAuthorPayload
- DeleteAuthorPayload
- UpdateAuthorPayload
- AuthorAggregateResult
突变
- addAuthor
- updateAuthor
- deleteAuthor
查询
- getAuthor
- queryAuthor
- aggregateAuthor
ID类型很特殊。ID 是自动生成的、不可变的, 并且可以被视为字符串。类型的字段ID可以在模式中列为可空, 但 Dgraph 永远不会返回空。
- 架构规则: ID不允许列表 - 例如tags: [String]有效, 但ids: [ID]不可以
- Schema 规则: 您定义的每种类型最多可以有一个带有 type 的字段ID。这包括通过接口实现的 IDs
Dgraph 中的标量列表更像集合, 总是包含唯一
2.2 类型
2.2.1 标量
2.2.2 枚举
2.2.3 类型
2.2.4 接口
2.2.5 联合类型
GraphQL 联合表示一个对象, 它可能是 GraphQL 对象类型列表之一, 但在这些类型之间不提供保证字段。因此, 如果不使用类型精炼片段或内联片段, 则不能在此类型上查询任何字段。
如果定义不正确, 联合类型有可能无效:
- 一个Union类型必须包含一个或多个唯一的成员类型。
- 一个类型的成员类型Union必须都是 Object 基类型; Scalar、Interface和Uniontypes 不能是 Union 的成员类型。同样, 包装类型不能是联合的成员类型。
2.2.6 密码类型
@secret通过使用指令设置节点类型的架构来设置实体的密码。密码不能直接查询, 只能使用checkTypePasswordwhere 函数检查是否匹配。密码使用Bcrypt加密。
mutation {
addAuthor(input: [{name:"myname", pwd:"mypassword"}]) {
author {
name
}
}
}
query {
checkAuthorPassword(name: "myname", pwd: "mypassword") {
name
}
}
2.2.7 地理位置类型
Dgraph GraphQL 带有用于存储地理位置数据的内置类型。目前, 它支持Point,Polygon和MultiPolygon. 这些类型在存储位置的 GPS 坐标、在地图上表示城市等场景中很有用。
2.3 IDs
Dgraph 提供了两种类型的内置标识符: ID标量类型和@id指令。
- 当ID您不需要在 Dgraph 之外设置标识符时, 使用标量类型。
- 该@id指令用于外部标识符, 例如电子邮件地址。
2.3.1 ID类型
在 Dgraph 中, 每个节点都有一个唯一的 64 位标识符, 您可以使用该ID类型在 GraphQL 中公开该标识符。ID是自动生成的、不可变的并且从不重复使用。每种类型最多可以有一个ID字段。
2.3.2 @id指令
对于某些类型, 您需要从 Dgraph 外部设置一个唯一标识符。一个常见的例子是用户名。该@id指令告诉 Dgraph 保持该字段的值唯一并将它们用作标识符。例如, 您可以在模式中设置以下类型:
type User {
username: String! @id
...
}
带有指令的字段@id必须具有类型String!。
@id可以在一个类型中的多个字段上使用该指令。然后, 您可以在查询@id的参数中使用多个字段get, 并且在搜索时, 这些字段将与AND运算符组合, 从而产生布尔AND运算。例如, 您可以定义如下类型:
type Book {
name: String! @id
isbn: String! @id
genre: String!
...
}
query {
getBook(name: "The Metamorphosis", isbn: "9871165072") {
name
genre
...
}
}
2.3.3 @id和接口
默认情况下, 如果在接口中使用, 该@id指令将分别确保每个实现类型的字段唯一性。在这种情况下, 接口中的@id字段对于接口来说不是唯一的, 而是对于它的每个实现类型都是唯一的。@id这允许实现相同接口的两种不同类型对继承的字段具有相同的值。
在某些情况下, 可能不需要此行为, 您可能希望将@id字段限制为在所有实现类型中都是唯一的。在这种情况下, 您可以将 @id 的 interface参数设置为 true, Dgraph 将确保该字段在接口的所有实现类型中具有唯一值。
interface Item {
refID: Int! @id(interface: true) # if there is a Book with refID = 1, then there can't be a chair with that refID.
itemID: Int! @id # If there is a Book with itemID = 1, there can still be a Chair with the same itemID.
}
type Book implements Item { ... }
type Chair implements Item { ... }
2.3.4 结合ID和@id
您可以在另一个字段定义上同时使用ID类型和@id指令来同时拥有唯一标识符和生成的标识符。例如, 您可以在模式中定义以下类型:
type User {
id: ID!
username: String! @id
...
}
2.4 GraphQL 图表中的链接
图中的边是有向的: 要么指向一个方向, 要么指向两个方向。使用 @hasInverse 指令告诉 Dgraph 如何处理双向边。
2.4.1 单向边
如果您只需要在特定方向上遍历节点之间的图, 那么您的模式可以简单地包含类型和链接。
在这个模式中, 帖子有一个作者——图中的每个帖子都链接到它的作者——但这条边是单向的。
type Author {
...
}
type Post {
...
author: Author
}
2.4.2 双向边 - 带有逆边的边
GraphQL 模式总是未指定, 如果我们将模式扩展为:
type Author {
...
posts: [Post]
}
type Post {
...
author: Author
}
模式表明: 作者有一个帖子列表, 一个帖子有一个作者。在 Dgraph 中, 指令@hasInverse用于创建双向边。
type Author {
...
posts: [Post] @hasInverse(field: author)
}
type Post {
...
author: Author
}
这样, posts和author只是图中同一链接的两个方向。
2.4.3 多边缘
自动检测模式设计器对双向边缘的含义实际上是不可能的。两种类型之间甚至不只有一种可能的关系。
2.5 搜索和过滤
2.5.1 @search 指令
@search指令告诉 Dgraph 在你的 GraphQL API 中构建什么搜索, 如果类型包含
type Post {
...
datePublished: DateTime @search
}
然后可以使用日期时间搜索过滤帖子, 例如:
query {
queryPost(filter: { datePublished: { ge: "2020-06-15" }}) {
...
}
}
| 类型 | 参数 | 过滤器 OR 搜索 |
|---|---|---|
| 整数、浮点数和日期时间 | none | lt, le, eq, in, between, ge, 和gt |
| 日期时间 | year, month, day, 或hour | lt, le, eq, in, between, ge, 和gt |
| 布尔值 | none | true和false |
| String | hash | eq和in |
| - | exact | lt, le, eq, in, between, ge, 和gt(按字典顺序) |
| - | regexp | regexp(常用表达) |
| - | term | eq, allofterms和anyofterms |
| - | fulltext | alloftext和anyoftext |
| - | trigram | regexp |
| 枚举 | none | eq和in |
| - | hash | eq和in |
| - | exact | lt, le, eq, in, between, ge, 和gt(按字典顺序) |
| - | regexp | regexp(常用表达) |
| Point | - | near,within |
| Polygon | - | near,within, contains,intersects |
| MultiPolygon | - | near,within, contains,intersects |
- 枚举在 Dgraph 中被序列化为字符串。
- 除了@search不带参数外, DateTime还允许指定如何构建搜索索引: 按年、月、日或小时。
- 按正则表达式搜索需要用/和将表达式括起来/
- fulltext搜索是谷歌风格的文本搜索, 带有停用词, 词干
- Union只能作为类型的字段进行查询。无法对Union查询进行排序, 但您可以对其进行过滤和分页。
2.6 指令
| 指令 | 说明 | 备注 |
|---|---|---|
| @auth | - | - |
| @cascade | 没有在查询中指定所有谓词的节点将被删除。这在应用了某些过滤器或节点可能没有所有列出的谓词的情况下很有用 | - |
| @custom | - | - |
| @deprecated | - | - |
| @dgraph | - | - |
| @hasInverse | - | - |
| @id | - | - |
| @include | - | - |
| @lambda | - | - |
| @remote | - | - |
| @remoteResponse | - | - |
| @generate | - | - |
| @search | - | - |
| @secret | - | - |
| @skip | - | - |
| @withSubscription | - | - |
| @lambdaOnMutate | - | - |
| @normalize | 返回别名谓词并将结果展平以删除嵌套 | DQL |
| @ignorereflex | 通过查询结果中的任何路径强制删除作为父节点可访问的子节点 | DQL |
2.5 GraphQL 变量
语法示例(使用默认值):
query title($name: string = “Bauman”) { … }
- query title($age: int = “95”) { … }
- query title($uids: string = “0x1”) { … }
- query title($uids: string = “[0x1, 0x2, 0x3]”) { … }. 变量的值是一个带引号的数组。
Variables可以在查询中定义和使用, 这有助于查询重用, 并通过传递单独的变量映射避免在运行时在客户端中构建成本高昂的字符串。变量以$符号开头。对于带有 GraphQL 变量的HTTP 请求Content-Type: application/json, 我们必须使用header 并使用包含queryand的 JSON 对象传递数据variables。
{
"query": "query test($a: string) { test(func: eq(name, $a)) { \n uid \n name \n } }",
"variables": { "$a": "Alice" }
}
- 变量可以有默认值
- 类型以
!为后缀的变量不能有默认值, 但必须有一个值作为变量映射的一部分。 - 变量的值必须可解析为给定类型, 否则将引发错误。
- 目前支持的变量类型有: int、float 和 bool、string
- 任何正在使用的变量都必须在命名查询子句的开头声明。
2.6 GraphQL 片段
GraphQL 片段是可重用的逻辑单元, 可以在多个查询和突变之间共享。片段允许重复使用常见的重复字段选择, 从而减少 DQL 文档中的重复文本。
fragment postData on Post {
id
title
text
author {
username
displayName
}
}
query {
debug(func: uid(1)) {
name@en
...TestFrag
}
}
fragment TestFrag {
initial_release_date
...TestFragB
}
fragment TestFragB {
country
}
2.6.1 使用带有接口的片段
可以在接口上定义片段. 下面是一个包含内联片段的示例:
interface Employee {
ename: String!
}
interface Character {
id: ID!
name: String! @search(by: [exact])
}
type Human implements Character & Employee {
totalCredits: Float
}
type Droid implements Character {
primaryFunction: String
}
3.DQL
Dgraph 查询语言DQL, 以前称为GraphQL+-, 它是 Facebook 创建的查询语言GraphQL的变体. Dgraph 目前支持两种数据的变异: RDF 和 JSON.
Dgraph 中的字符串值是 UTF-8 格式。Dgraph 还支持多种语言的字符串谓词类型的值。多语言功能对于构建功能特别有用, 这需要您以多种语言存储相同的信息。
3.1 使用Ratel执行Mutations
在Dgraph中, 创建、更新和删除操作叫做mutations
3.1.1 用set来创建新节点
{
"set": [
{
"name": "Karthic",
"age": 28,
"follows": {
"name": "Jessica",
"age": 31
}
}
]
}
3.1.2 更新谓词
使用一个已存在节点的uid, 更新的是这个节点的谓词, 而不是创建一个新节点。
{
"set":[
{
"uid": "0x1",
"age": 41,
"country": "china"
}
]
}
OR
{
set{
<uid> < 谓词 > "新值" .
}
}
3.1.3 删除谓词
可以使用delete mutation删除节点的谓词。这是delete mutation的语法, 用于删除节点的任何谓词,
{
delete {
<0x1> <country> * .
}
}
{
delete {
<0x1> * * .
}
}
3.1.4 在已存在的节点之间添加边
{
"set": [
{
"uid": "0x2",
"follows": {
"uid": "0x3"
}
}
]
}
3.2 查询
3.2.1 使用 has 函数进行查询
{
people(func: has(name)) {
uid
name
age
}
}
- 查询的第一部分是用户定义的函数名。在上面例子中, 我们把它命名为 people。当然, 你也可以使用其它名字。
- func参数所关联的必须是Dgraph内置的函数。Dgraph提供了各种用途的内置函数。has 便是其中之一。可以在这里https://docs.dgraph.io/query-language检索更多的Dgraph内置函数。
- 内部的查询字段和SQL select语句中的列名或GraphQL查询中的类似, 可以利用它们指定你想要返回哪些谓词(predicates)
3.2.2 使用UIDS查询
节点可以使用他们的uid查询出来, 内置函数uid将UID列表做为可变参数, 因此无论他们是否存在于数据库中, 你都可以传递一个(例如uid(0x1))或任意多个(例如uid(0x1,0x2))
{
find_using_uid(func: uid(0x1)){
uid
name
age
}
}
3.2.3 遍历边
图数据库提供独特的功能, 遍历是其中之一。遍历解答问题或者查询相关节点的关系, 比如查询Michael追求的是谁, 就可以通过遍历follows关系得到解答
{
find_follower(func: uid(0x1)){
name
age
follows {
name
age
follows {
name
age
}
}
}
}
查询有三个部分
- 查询根节点
- 选择被遍历的边
- 指定要返回的谓词
3.2.4 递归遍历
递归查询查询让您遍历一组谓词(使用过滤器、构面等), 直到我们到达所有叶节点或达到depth参数指定的最大深度, 使执行多级深度遍历更加容易。它们使您可以轻松遍历图的子集, 如:
{
find_follower(func: uid(0x1)) @recurse(depth: 4) {
name
age
follows
}
}
使用递归查询时要记住的几点是:
- 您只能在 root 之后指定一级谓词。这些将被递归遍历。标量和实体节点的处理方式类似。
- 每个查询只建议一个递归块。
- 请小心, 因为结果大小可能会迅速爆炸, 如果结果集太大, 则会返回错误。在这种情况下, 请使用更多过滤器, 使用分页限制结果, 或在根处提供深度参数, 如上例所示。
- loop(未指定,默认为 false)参数可以设置为 false, 在这种情况下, 导致循环的路径将在遍历时被忽略。
- 如果loop参数的值为 false 且未指定深度, depth则默认为math.MaxUint64, 这意味着可能会遍历整个图, 直到到达所有叶节点。
3.2.5 过滤遍历
可以使用@filter指令过滤遍历的结果。
3.2.6 反向遍历
dgraph中的边是有方向的, 对于Dgraph来说, 沿边缘方向移动是很自然的。但是要以另一种方式遍历, 则需要与边缘方向相反。您仍然可以通过在查询中添加波浪号()来实现。必须在要遍历的边的名称的开头添加波浪号()。
{
devrel_tag(func: eq(tag_name,"devrel")) {
tag_name
~tagged {
title
content
~published {
author_name
}
}
}
}
3.3 谓词的数据类型
Dgraph自动检测其谓词的数据类型。数据类型包括string, float以及int和uid。除了它们, Dgraph还提供了另外三种基本数据类型: geo, dateTime和bool.
uid类型表示两个节点之间的谓词。换句话说, 它们表示连接两个节点的边
3.4 Dgraph中的索引
索引用于加快对谓词的查询。需要时必须将它们显式添加到谓词中。也就是说, 仅当您需要查询谓词的值时。另外, 也无需预料索引会在一开始就添加。您可以随时添加它们。
Dgraph提供了不同类型的索引。要添加的索引的选择取决于谓词的数据类型。下面为包含数据类型和可应用于它们的索引集的表。
| 数据类型 | Go 类型 | 可用索引类型 |
|---|---|---|
| default | string | string |
| int | int64 | int |
| float | float | float |
| string | string | hash,exact,term,fulltext,trigram |
| bool | bool | bool |
| geo | go-geom | geo |
| dateTime | time.Time | year,month,day,hour |
| uid | uint64 | |
| password | string (encrypted) |
只有string和dateTime数据类型可以选择一种或者多种索引类型.
uid类型表示节点-节点边; 在内部, 每个节点都表示为一个uint64id。
3.4.1 字符串索引
- hash:
- exact: 精确索引
- term: 允许您根据一个或多个关键字搜索字符串谓词, Dgraph 提供了两个专门用于搜索terms 的内置函数:
allofterms和anyofterms(对大小写和特殊字符不敏感) - full-text: 内置函数:
alloftext或anyoftext - trigram: 内置函数:
regexp
一个字符串谓词可以有多个索引, 但其中一些是不兼容的, 如: hash和exact。
以下是生成fulltext tokens 的步骤:
- 将推文分成称为 tokens (tokenizing) 的词块
- 将这些标记转换为小写
- Unicode 规范化标记
- 将标记简化为它们的根形式, 这称为词干(running to run, faster to fast and so on)
- 删除 stop words (并非所有语言都支持删除词干和停用词)
Dgraph 内部使用 Bleve 包进行词干提取. fulltext 分词器的实际应用, 使用说明的要点, 可以这里查看: https://gist.github.com/hackintoshrao/0e8d715d8739b12c67a804c7249146a3
正则表达式是表达搜索模式的强大方法。Dgraph 允许您基于正则表达式搜索字符串谓词. 在字符串谓词上设置 trigram 索引才能执行基于正则表达式的查询.
3.4.2 在 Dgraph 中实现模糊搜索
要在 Dgraph 中对字符串谓词使用模糊搜索, 首先要设置trigram索引, 然后使用 Dgraph 的内置函数match运行模糊搜索查询, 语法: match(predicate, search string, distance)
match 三个参数:
- 用于查询的字符串谓词的名称
- 用户提供的搜索字符串
- 一个整数, 表示 Levenshtein Distance前两个参数之间的最大值。此值应大于 0。例如, 当整数为 8 时, 返回距离值小于或等于 8 的谓词。
为参数使用更大的值distance可能会匹配更多的字符串谓词, 但也会产生不太准确的结果
3.4.3 原生地理定位功能
Dgraph 提供了多种查询地理位置数据的功能。要使用它们, 您必须先设置geo索引
- near(geo-predicate, [long, lat], distance)
3.5 DQL 知识点
3.5.1 多语言字符串
使用语言标签需要将@lang指令添加到Schema中, 使用语言标签(@ru、@jp、@*返回所有)作为谓词的后缀
| 占位符 | 说明 |
|---|---|
| 寻找未标记的字符串, 如果不存在, 则不返回任何内容 | |
| @ru | 查找标记为@ru, 如果未找到, 则查询不返回任何内容 |
| @。 | 查找未标记的字符串, 如果未找到, 则返回任何语言的。但是, 这仅返回一个值。 |
| @jp:。 | 寻找@jp标记的, 如果未找到, 则查找未标记的, 如果也没有找到, 则返回任何评论 |
| @jp:ru | 查找标记@jp, 然后@ru, 如果两者均未找到, 则不返回任何内容 |
| @jp:ru:。 | 查找标记@jp, 然后@ru, 如果两者都未找到, 则查找未标记的。 如果也没有找到, 则返回任何其他评论(如果存在 |
| @* | 返回所有 |
3.5.2 DQL 的函数
在根查询(aka func:), 比较函数 (eq, ge, gt, le, lt) 只能运用在设定了索引的 predicates 上。从 v1.2 开始, 可以在@filter指令上使用比较函数, 甚至可以在没有被索引的谓词上使用。对于大型数据集, 过滤非索引谓词可能会很慢, 因为它们需要在使用过滤器的级别上迭代所有可能的值。
- allofterms(predicate, “space-separated term list”) 和 anyofterms(predicate, “space-separated term list”)
- regexp(predicate, /regular-expression/)
- 模糊匹配: match(predicate, string, distance)
- 全文检索: alloftext(predicate, “space-separated text”) 和 anyoftext(predicate, “space-separated text”)
- between(predicate, startDateValue, endDateValue)
- has(predicate)
等于
- eq(predicate, value)
- eq(val(varName), value)
- eq(predicate, val(varName))
- eq(count(predicate), value)
- eq(predicate, [val1, val2, …, valN])
- eq(predicate, [\(var1, "value", ..., \)varN])
小于、小于或等于、大于和大于或等于(le, lt, ge, gt):
- IE(predicate, value)
- IE(val(varName), value)
- IE(predicate, val(varName))
- IE(count(predicate), value)
uid
- q(func: uid(
)) - predicate @filter(uid(
, …, )) - predicate @filter(uid(a))对于变量a
- q(func: uid(a,b))对于变量a和b
- q(func: uid($uids))对于 DQL 变量中的多个 uid
uid_in
uid_in 允许沿边向前查看以检查它是否指向特定的 UID, 这通常可以节省额外的查询块并避免返回边缘。
uid_in不能在根目录下使用. 它接受多个 UID 作为其参数, 并且它接受一个 UID 变量(可以包含 UID 的映射)。
- q(func: …) @filter(uid_in(predicate,
)) - predicate1 @filter(uid_in(predicate2,
)) - predicate1 @filter(uid_in(predicate2, [
, …, ])) - predicate1 @filter(uid_in(predicate2, uid(myVariable) ))
地理位置: 要使用地理功能, 您需要在谓词上建立索引. 对于地理查询, 任何带有孔的多边形都将替换为外部循环, 而忽略孔
loc: geo @index(geo) .
- near(predicate, [long, lat], distance)
- within(predicate, [[[long1, lat1], …, [longN, latN]]])
- contains(predicate, [long, lat]) 或 contains(predicate, [[long1, lat1], …, [longN, latN]])
- intersects(predicate, [[[long1, lat1], …, [longN, latN]]])
3.5.3 连接过滤器
在 @filter 多个函数内可以使用布尔(AND、OR 和 NOT)连接词, 如: (NOT A OR B) AND (C AND NOT (D OR E))
3.5.4 别名 Aliases
语法示例:
- aliasName : predicate
- aliasName : predicate { … }
- aliasName : varName as …
- aliasName : count(predicate)
- aliasName : max(val(varName))
3.5.5 DQL 中的分页
分页通常与排序一起使用.
First 语法示例:
- q(func: …, first: N)
- predicate (first: N) { … }
- predicate @filter(…) (first: N) { … }
对于 正数N, 按排序或 UID 顺序, 检索第一个结果集: N
对于 负数N, 按排序或 UID 顺序, 检索最后的结果集: N。要使用排序实现负数的效果, 请颠倒排序的顺序并使用正数N
Offset 语法示例:
- q(func: …, offset: N)
- predicate (offset: N) { … }
- predicate (first: M, offset: N) { … }
- predicate @filter(…) (offset: N) { … }
与 first 结合使用, 如: first: M, offset: N 跳过N结果并返回M个结果(如有)
After 语法示例:
- q(func: …, after: UID)
- predicate (first: N, after: UID) { … }
- predicate @filter(…) (first: N, after: UID) { … }
跳过某些结果后获取结果的另一种方法是使用默认的 UID 排序并直接跳过由 UID 指定的节点。
3.5.6 Count in DQL
Count 可以在 root 和aliased中使用。语法示例:
- count(predicate): 计算predicate从节点引出的边数
- count(uid): 计算封闭块中匹配的 UID 的数量
3.5.7 排序
结果可以按谓词或变量按升序(orderasc)或降序(orderdesc)排序。, 语法示例:
- q(func: …, orderasc: predicate)
- q(func: …, orderdesc: val(varName))
- predicate (orderdesc: predicate) { … }
- predicate @filter(…) (orderasc: N) { … }
- q(func: …, orderasc: predicate1, orderdesc: predicate2)
默认情况下, 排序查询最多检索 1000 个结果。这可以用first改变。
3.6 变量 ( var) 块
变量块(varblocks)以关键字开头, var不会在查询结果中返回, 但会影响查询结果的内容。单个查询操作中可以使用多个块, 在任何后续块中使用一个var块中的变量, 但不能在同一块中使用。
{
var(func:allofterms(name@en, "angelina jolie")) {
name@en
actor.film {
A AS performance.film {
B AS genre
}
}
}
films(func: uid(B), orderasc: name@en) {
name@en
~genre @filter(uid(A)) {
name@en
}
}
}
3.6.1 DQL 中的查询变量
语法示例:
- varName as q(func: …) { … }
- varName as var(func: …) { … }
- varName as predicate { … }
- varName as predicate @filter(…) { … }
在查询中某个位置匹配的节点 (UID) 可以存储在变量中并在其他地方使用。查询变量可用于其他查询块或定义块的子节点。
查询变量不影响定义时查询的语义。查询变量被评估到与定义块匹配的所有节点。
通常, 查询块是并行执行的, 但变量会对某些块施加评估顺序。不允许由变量相关性引起的循环。
如果定义了变量, 则必须在查询的其他地方使用它。通过提取其中的 UID 来使用查询变量uid(var-name)。
语法 func: uid(A,B)or@filter(uid(A,B)) 表示变量 A和B 的 UID.
{
var(func:allofterms(name@en, "angelina jolie")) {
actor.film {
A AS performance.film { # All films acted in by Angelina Jolie
B As genre # Genres of all the films acted in by Angelina Jolie
}
}
}
var(func:allofterms(name@en, "brad pitt")) {
actor.film {
C AS performance.film { # All films acted in by Brad Pitt
D as genre # Genres of all the films acted in by Brad Pitt
}
}
}
films(func: uid(D)) @filter(uid(B)) { # Genres from both Angelina and Brad
name@en
~genre @filter(uid(A, C)) { # Movies in either A or C.
name@en
}
}
}
3.6.2 DQL 中的值变量
值变量在 DQL 中存储标量值。值变量是从封闭块的 UID 到相应值的映射。语法示例:
- varName as scalarPredicate
- varName as count(predicate)
- varName as avg(…)
- varName as math(…)
这些变量映射到以下类型: int, float, String, dateTime, default, geo,bool
只有在匹配相同 UID 的上下文中使用值变量的值才有意义 - 如果在匹配不同 UID 的块中使用, 则值变量是未定义的。
定义值变量但不在查询中的其他地方使用它是错误的。
val(var-name)通过使用 提取值或使用 提取 UID来使用值变量uid(var-name)
{
var(func:allofterms(name@en, "The Princess Bride")) {
starring {
pbActors as performance.actor {
roles as count(actor.film)
}
}
}
totalRoles(func: uid(pbActors), orderasc: val(roles)) {
name@en
numRoles : val(roles)
}
}
与查询变量一样, 值变量可以用于其他查询块和嵌套在定义块中的块中。当用于嵌套在定义变量的块中的块中时, 该值被计算为沿到使用点的所有路径的父节点的变量之和。这称为变量传播。
3.6.3 值变量的数学
可以使用数学函数组合值变量。例如, 这可以用于关联一个分数, 然后用于排序或执行其他操作.
数学语句必须包含在值变量中math(
| 运营商 | 接受的类型 | 它能做什么 |
|---|---|---|
| + - * / % | int,float | 执行相应的操作 |
| min max | geo除,之外的所有类型bool (二进制函数) | 选择两者中的最小值/最大值 |
| < > <= >= == != | geo除,之外的所有类型bool | 根据值返回真或假 |
| floor ceil ln exp sqrt | int, float(一元函数) | 执行相应的操作 |
| since | dateTime | 返回从指定时间开始的浮点秒数 |
| pow(a, b) | int,float | 退货a to the power b |
| logbase(a,b) | int,float | 返回log(a)基地b |
| cond(a, b, c) | 第一个操作数必须是布尔值 | 选择b如果a为真, 否则c |
注意: 如果发生整数溢出, 或者将操作数传递给数学运算(例如ln, logbase, sqrt, pow)导致非法运算, Dgraph 将返回错误。
3.7 DQL 中的聚合
聚合只能应用于值变量。不需要索引(值已经找到并存储在值变量映射中)。
语法示例: AG(val(varName)) (对于AG替换为)
- min: 选择 value 变量中的最小值varName
- max: 选择最大值
- sum: 对 value 变量中的所有值求和varName
- avg: 计算值的平均值varName
| 聚合 | Schema 类型 |
|---|---|
| min/max | int, float, string, dateTime,default |
| sum/avg | int,float |
3.8 GroupBy 分组
语法示例:
- q(func: …) @groupby(predicate) { min(…) }
- predicate @groupby(pred) { count(uid) }
在设定的属性上, 通过对元素进行分组, 聚合查询结果。例如, friend @groupby(age) { count(uid) } , 沿着朋友边, 查找可达的所有节点, 根据年龄将这些节点划分为组, 然后计算每个组中有多少个节点。返回的结果是分组的边和聚合。
- 在一个groupby块内, 只允许聚合并且count只能应用于uid
- 如果将groupby应用于uid谓词, 则生成的聚合可以保存在变量中(将分组的 UID 映射到聚合值)并在查询中的其他地方使用以提取除分组或聚合边之外的信息
3.9 在 DQL 中展开谓词
expand()函数可用于将谓词扩展到节点之外. 要使用expand(), 需要类型系统
- 按类型展开谓词: 可以传递类型expand()以扩展指定类型的所有谓词
- 展开所有谓词: 如果_all_作为参数传递给expand(), 则要扩展的谓词将是分配给给定节点的类型中的字段的并集
- 展开期间过滤: 扩展查询支持对传出边类型的过滤器。例如,
expand(_all_) @filter(type(Person))将扩展所有谓词
{
all(func: eq(name@en, "Harry Potter")) @filter(type(Series)) {
name@en
expand(Series) {
name@en
expand(Film)
}
}
}
3.10 @Cascade 指令
@Cascade: 没有在查询中指定所有谓词的节点将被删除。这在应用了某些过滤器或节点可能没有所有列出的谓词的情况下很有用, 如:
{
HP(func: allofterms(name@en, "Harry Potter")) @cascade {
name@en
starring{
performance.character {
name@en
}
performance.actor @filter(allofterms(name@en, "Warwick")){
name@en
}
}
}
}
@cascade 指令还可以选择将字段列表作为参数。这会更改默认行为, 仅将提供的字段视为必需字段, 而不是类型的所有字段。列出的字段会自动级联为嵌套选择集的必需参数。参数化级联适用于级别(例如, 在根函数或较低级别上), 因此您需要@cascade(param)在您希望应用它的确切级别上指定。如果要检查多个字段, 只需用逗号分隔它们, 如:
{
nodes(func: allofterms(name@en, "jones indiana")) @cascade(produced_by,written_by) {
name@en
genre @filter(anyofterms(name@en, "action adventure")) {
name@en
}
produced_by {
name@en
}
written_by {
name@en
}
}
}
@cascade指令在查询之后处理节点, 但在 Dgraph 返回查询结果之前。这意味着在内部查询过程中仍然会触及在没有应用时通常会返回的所有节点。如果您在使用该指令时发现性能低于预期, 这可能是因为内部查询过程返回了大量节点, 但级联将这些节点减少到查询结果中的一小部分节点。为了提高使用该@cascade指令的查询的性能, 您可能需要使用var块或has过滤器:
- 使用var块的性能影响在于它减少了为生成最终查询结果而触摸的图形
- 在@cascade 只会应用到一小部分节点具有的predicates 的情况下, 为这些谓词包含一个has 过滤器, 可能对查询性能有益
3.11 @normalize 指令
@normalize指令, 仅返回别名谓词并将结果展平以删除嵌套。@normalize 可以应用于嵌套查询块, 但只会展平已应用的嵌套查询块的结果
3.12 调试
将查询参数debug=true附加到查询, extensions:
- parsing_ns: 解析查询的延迟(以纳秒为单位)。
- processing_ns: 处理查询的延迟(以纳秒为单位)。
- encoding_ns: 以纳秒为单位对 JSON 响应进行编码的延迟。
- start_ts: 事务的逻辑开始时间戳。
3.13 添加或修改 Schema
通过将模式指定为列表类型, 也可以为 a 添加多个标量值, 如:
name: string @index(exact, fulltext) @count .
multiname: string @lang .
age: int @index(int) .
friend: [uid] @count .
dob: dateTime .
location: geo @index(geo) .
occupations: [string] @index(term) .
- @index: 指定索引
- @count: 指定计数
- @lang: 设定语言标签(多语言支持)
- @upsert: 更新插入
- @noconflict: 防止在谓词级别检测冲突。这是一个实验性功能, 不是推荐的指令
- @reverse: 计算反向边
如果由模式突变指定, 也会计算反向边。
注意: 以 dgraph. 开头的谓词名称, 被保留为 Dgraph 内部类型/谓词的命名空间。
如果谓词是 URI 或具有特定于语言的字符, 则在执行模式突变时将其用尖括号括起来, 如: <职业>: string @index(exact) .。
password 类型: 不能直接查询密码, 只能使用该checkpwd功能检查是否匹配。密码使用bcrypt加密
列表类型:
- 设置操作会添加到值列表中。存储值的顺序是不确定的。
- 删除操作从列表中删除值。
- 查询这些谓词将返回数组中的列表。
- 索引可以应用于具有列表类型的谓词, 您可以在它们上使用函数。
- 不允许使用这些谓词进行排序。
- 这些列表就像一个无序集。例如: [“e1”, “e1”, “e2”]可能会被存储为[“e2”, “e1”], 即不会存储重复值并且可能不会保留顺序。
Dgraph 支持基于列表的过滤。过滤的工作方式类似于它在边缘上的工作方式, 并且具有相同的可用功能。但是, 不支持对值边缘进行过滤。
查询 Schema
# All
schema {}
schema(pred: [name, friend]) {
type
index
reverse
tokenizer
list
count
upsert
lang
}
schema(type: Movie) {}
schema(type: [Person, Animal]) {}
3.14 DQL 类型系统
3.14.1 DQL 类型定义
类型是使用类似 GraphQL 的语法定义的, 使用 Alter 端点与模式一起声明类型。例如:
type Student {
name
dob
home_address
year
friends
<~children>
}
为了正确支持上述类型, 还需要为该类型中的每个属性添加一个谓词, 例如:
name: string @index(term) .
dob: datetime .
home_address: string .
year: int .
friends: [uid] .
children: [uid] @reverse .
3.14.2 节点类型
dgraph.type
标量节点不能有类型, 因为它们只有一个属性, 其类型就是节点的类型。UID 节点可以有一个类型。通过设置该dgraph.type节点的谓词值来设置类型。一个节点可以有多种类型。以下是如何设置节点类型的示例:
{
set {
_:a <name> "Garfield" .
_:a <dgraph.type> "Pet" .
_:a <dgraph.type> "Animal" .
}
}
3.15 DQL 中的 Facets 和 边属性
Dgraph 支持 facets(边上的键值对)作为 RDF 三元组的扩展。也就是说, facets 将属性添加到边, 而不是节点。在 Dgraph 中, Facet 并不是像谓词那样的一等公民。
Facet 键是字符串, 值可以是string、bool、int和。对于和, 只接受 32 位有符号整数和 64 位浮点数。对于 int 和 float, 只接受 32 位有符号整数和 64 位浮点数
@facets(facet-name)用于查询构面数据(@facets 查询所有), 可以在请求特定谓词时指定别名, 如:
{
data(func: eq(name, "Alice")) {
name
mobile @facets(since)
car @facets(car_since: since)
}
}
Dgraph 支持基于 facets 过滤边缘。过滤的工作方式类似于它在没有面的边上的工作方式, 并且具有相同的可用功能。facets 查询可以由AND、OR和组成NOT。
{
data(func: eq(name, "Alice")) {
friend @facets(eq(close, true) AND eq(relative, true)) @facets(relative) { # filter close friends in my relation
name
}
}
}
可以对 uid 边缘上的facets 进行排序。
UID 边上的 facets 可以存储在值变量中。该变量是从边缘目标到构面值的映射。
Facet 里 int 和 float 类型的值可以分配给变量, 因此这些值会传播。
{
var(func: anyofterms(name, "Alice Bob Charlie")) {
num_raters as math(1)
rated @facets(r as rating) {
total_rating as math(r) # sum of the 3 ratings
average_rating as math(total_rating / num_raters)
}
}
data(func: uid(total_rating)) {
name
val(total_rating)
val(average_rating)
}
}
3.16 最短路径查询
可以使用查询块名称的关键字找到源 ( from) 节点和目标 ( ) 节点之间的最短路径。它需要源节点 UID、目标节点 UID 和必须考虑遍历的谓词(至少一个)。查询块返回查询响应中的最短路径。路径也可以存储在其他查询块中使用的变量中。
3.16.1 K-最短路径查询
默认情况下返回最短路径. 使用 numpaths: k, 和 k > 1, 返回K-最短路径查询. 从 k 最短路径查询的结果中修剪出循环路径. 使用 depth: n, 返回到 n 深度的路径.我们可以通过指定返回更多路径numpaths。设置numpaths: 2返回最短的两条路径, 如:
{
A as var(func: eq(name, "Alice"))
M as var(func: eq(name, "Mallory"))
path as shortest(from: uid(A), to: uid(M), numpaths: 2) {
friend
}
path(func: uid(path)) {
name
}
}
- Dgraph 中的最短路径实现依赖于 facets 来提供权重.
- 可以将约束应用于中间节点
- k-最短路径算法(在numpaths> 1 时使用)也接受参数minweight和maxweight, 它们的值是浮点数
最短路径查询需要记住的几点:
- 权重必须为非负数。Dijkstra 算法用于计算最短路径。
- 最短查询块中的每个谓词只允许一个方面。
- 每个查询只允许一个shortest路径块。结果中只_path_返回一个。对于numpaths大于 1 的查询, _path_包含所有路径。
- k-最短路径查询的结果中不包含循环路径。
- 对于 k 最短路径(当numpaths> 1 时), 最短路径查询变量的结果将仅返回一条路径, 该路径将是 k 条路径中的最短路径。所有 k 路径都在 中返回_path_。
3.17 使用自定义标记器进行索引
Dgraph 带有一个内置索引的大型工具包, 但有时对于小众用例, 它们并不总是足够的。
Dgraph 允许您通过插件系统实现自定义标记器, 以填补空白。
插件系统使用 Go 的pkg/plugin:
- 插件必须用 Go 编写。
- 从 Go 1.9 开始, pkg/plugin仅适用于 Linux
- 用于编译插件的 Go 版本应该与用于编译 Dgraph 本身的 Go 版本相同
具体参考: https://dgraph.io/docs/query-language/indexing-custom-tokenizers/
3.18 Mutations
3.18.1 DQL 中的空白节点和 UID
Mutation 中的空白节点, 书写如: _:identifier
3.18.2 外部 ID
Dgraph 的输入语言 RDF 也支持三元组形式<a_fixed_identifier>
3.18.3 外部 ID 和 Upsert 块
3.18.4 语言和 RDF 类型
RDF N-Quad 允许为字符串值和 RDF 类型指定语言。语言是使用@lang, 如:
<0x01> <name> "Adelaide"@en .
<0x01> <name> "Аделаида"@ru .
<0x01> <name> "Adélaïde"@fr .
<0x01> <dgraph.type> "Person" .
RDF 类型使用标准^^分隔符附加到文字, 如:
<0x01> <age> "32"^^<xs:int> .
<0x01> <birthdate> "1985-06-08"^^<xs:dateTime> .
| Storage Type | Dgraph type |
|---|---|
| xs:string | string |
| xs:dateTime | dateTime |
| xs:date | datetime |
| xs:int | int |
| xs:integer | int |
| xs:boolean | bool |
| xs:double | float |
| xs:float | float |
| geo:geojson | geo |
| xs:password | password |
| http://www.w3.org/2001/XMLSchema#string | string |
| http://www.w3.org/2001/XMLSchema#dateTime | dateTime |
| http://www.w3.org/2001/XMLSchema#date | dateTime |
| http://www.w3.org/2001/XMLSchema#int | int |
| http://www.w3.org/2001/XMLSchema#positiveInteger | int |
| http://www.w3.org/2001/XMLSchema#integer | int |
| http://www.w3.org/2001/XMLSchema#boolean | bool |
| http://www.w3.org/2001/XMLSchema#double | float |
| http://www.w3.org/2001/XMLSchema#float | float |
3.18.5 其他
JSON 中提供了对地理位置数据的支持。地理位置数据以 JSON 对象的形式输入, 键为“type”和“coordinates”。
如果 JSON 对象包含名为 的字段"uid", 则该字段被解释为图中现有节点的 UID
可以通过使用|字符来分隔 JSON 对象字段名称中的谓词和构面键来创建构面
