
目录
NebulaGraph 是由前 Facebook 员工叶小萌离职创业后, 在 2019年 推出的图数据库产品, 底层数据模型是属性图, 基于 C++ 语言编写, 存储引擎基于 RocksDB改造, 使用 RAFT 保证数据读写的强一致性。NebulaGraph 基于 C++ 实现, 架构设计支持存储千亿顶点、万亿边, 并提供毫秒级别的查询延时。
1. NebulaGraph 架构
一个完整的 NebulaGraph 集群包含三类服务, 即 Query Service、Storage Service 和 Meta Service。每类服务都有其各自的可执行二进制文件, 既可以部署在同一节点上, 也可以部署在不同的节点上。下面是NebulaGraph 架构设计的几个核心点:
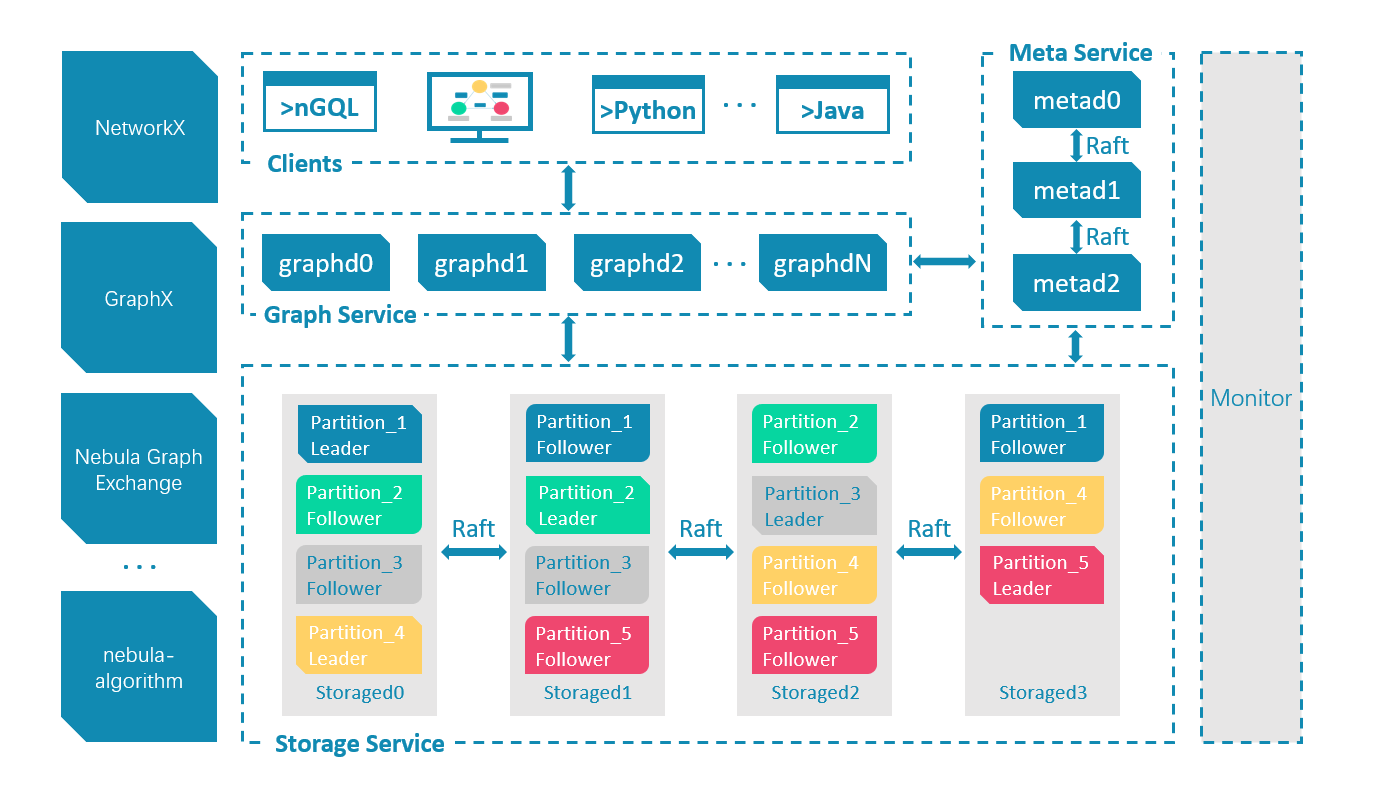
1.1 Meta Service
Meta Service: 架构图中右侧为 Meta Service 集群, 它采用 Leader/Follower 架构。
Leader 由集群中所有的 Meta Service 节点选出, 然后对外提供服务; Followers 处于待命状态, 并从 Leader 复制更新的数据。一旦 Leader 节点 Down 掉, 会再选举其中一个 Follower 成为新的 Leader。Meta Service 不仅负责存储和提供图数据的 Meta 信息, 如 Schema、数据分片信息等; 同时还提供 Job Manager 机制管理长耗时任务, 负责指挥数据迁移、Leader 变更、数据 compaction、索引重建等运维操作。
1.2 存储计算分离: NebulaGraph
存储计算分离: 在架构图中 Meta Service 的左侧, 为 NebulaGraph 的主要服务, NebulaGraph 采用存储与计算分离的架构, 虚线以上为计算, 以下为存储。
存储计算分离有诸多优势, 最直接的优势就是, 计算层和存储层可以根据各自的情况弹性扩容、缩容。存储计算分离还带来了另一个优势: 使水平扩展成为可能。此外, 存储计算分离使得 Storage Service 可以为多种类型的计算层或者计算引擎提供服务。当前 Query Service 是一个高优先级的 OLTP 计算层, 而各种 OLAP 迭代计算框架会是另外一个计算层。
无状态计算层: 每个计算节点都运行着一个无状态的查询计算引擎, 而节点彼此间无任何通信关系。计算节点仅从 Meta Service 读取 Meta 信息以及和 Storage Service 进行交互。这样设计使得计算层集群更容易使用 K8s 管理或部署在云上。每个查询计算引擎都能接收客户端的请求, 解析查询语句, 生成抽象语法树(AST)并将 AST 传递给执行计划器和优化器, 最后再交由执行器执行。
1.3 分布式存储层: Storage Service
Shared-nothing 分布式存储层: Storage Service 采用 Shared-nothing 的分布式架构设计, 共有三层, 最底层是 Store Engine, 它是一个单机版 Local Store Engine, 提供了对本地数据的get/put/scan/delete 操作, 该层定义了数据操作接口, 用户可以根据自己的需求定制开发相关 Local Store Plugin。目前, NebulaGraph 提供了基于 RocksDB 实现的 Store Engine。
在 Local Store Engine 之上是 Consensus 层, 实现了 Multi Group Raft, 每一个 Partition 都对应了一组 Raft Group。
在 Consensus 层上面是 Storage interfaces, 这一层定义了一系列和图相关的 API。 这些 API 请求会在这一层被翻译成一组针对相应 Partition 的 KV 操作。正是这一层的存在, 使得存储服务变成了真正的图存储。否则, Storage Service 只是一个 KV 存储罢了。而 NebulaGraph 没把 KV 作为一个服务单独提出, 最主要的原因便是图查询过程中会涉及到大量计算, 这些计算往往需要使用图的 Schema, 而 KV 层没有数据 Schema 概念, 这样设计比较容易实现计算下推, 是 NebulaGraph 查询性能优越的主要原因。
2. NebulaGraph 入门
2.1 快速体验
mkdir -p /data/nebula/logs
mkdir -p /data/nebula/data/meta
mkdir -p /data/nebula/data/storage
./scripts/nebula.service start all
./scripts/nebula.service status all
./bin/nebula-console -addr 127.0.0.1 -port 9669 -u root -p 123456
add hosts 127.0.0.1:9779
show hosts;
2.2 基本语法
CREATE SPACE basketballplayer(partition_num=15, replica_factor=1, vid_type=fixed_string(30));
USE basketballplayer;
CREATE TAG player(name string, age int);
CREATE TAG team(name string);
CREATE EDGE follow(degree int);
CREATE EDGE serve(start_year int, end_year int);
INSERT VERTEX player(name, age) VALUES "player100":("Tim Duncan", 42);
INSERT VERTEX player(name, age) VALUES "player101":("Tony Parker", 36);
# INSERT VERTEX player(name, age, edu) VALUES "player101":("Tony Parker", 36, "school");
INSERT VERTEX player(name, age) VALUES "player102":("LaMarcus Aldridge", 33);
INSERT VERTEX team(name) VALUES "team203":("Trail Blazers"), "team204":("Spurs");
INSERT EDGE follow(degree) VALUES "player101" -> "player100":(95);
INSERT EDGE follow(degree) VALUES "player101" -> "player102":(90);
INSERT EDGE follow(degree) VALUES "player102" -> "player100":(75);
INSERT EDGE serve(start_year, end_year) VALUES "player101" -> "team204":(1999, 2018),"player102" -> "team203":(2006, 2015);
GO FROM "player101" OVER follow YIELD id($$);
CREATE TAG INDEX IF NOT EXISTS player_name ON player(name(20));
CREATE EDGE INDEX IF NOT EXISTS follow_index on follow();
REBUILD TAG INDEX player_name;
REBUILD EDGE INDEX follow_index;
CREATE TAG actor(edu int);
INSERT VERTEX actor(edu) VALUES "player100":(6);
CREATE TAG INDEX IF NOT EXISTS actor_index on actor();
REBUILD TAG INDEX actor_index;
3. 查询
3.1 匹配多个 Tag 的点时, 不支持进行属性过滤。
# 例如, 不支持
MATCH (v1:player:team) WHERE v1.player.name=="Tim Duncan" RETURN v1 limit 10;
# To
MATCH (v1:player) WHERE v1.player.name=="Tim Duncan" AND "actor" IN tags(v1) RETURN v1 limit 10;
# Or
MATCH (v1:actor) WHERE v1.player.name=="Tim Duncan" RETURN v1;
3.2 路径查询
# Need version >= v3.2.0
MATCH p = shortestPath( (a:player{name:"Tim Duncan"})-[e*..5]-(b:player{name:"Tony Parker"}) ) RETURN p
4. Nebula 数据与安全
| 功能 | BR(Backup&Restore) | 快照 |
|---|---|---|
| 版本限制 | v3.1.0+ | v3.1.0+ |
| 指定路径 | Yes | No |
| 指定namespace | Yes | No |
| 集群备份 | No | Yes |
| 备份移除 | Yes | No |
| 备份恢复 | Yes | 需要手动 |
| 增量备份 | No | No |
| 跨集群恢复 | 图空间只能恢复到原集群, 全数据仅支持在相同拓扑的集群上进行 | No |
| 性能 | 图空间中的 DDL 和 DML 语句将会阻塞 | 恢复需要重启 |
| 适用场景 |
相同拓扑, 是严格意义上的, 还是?
BR 对镜像部署的环境有限制, 使用麻烦(不支持本地备份, 且恢复数据操作麻烦).
4.1 Nebula BR(Backup&Restore)
git clone https://github.com/vesoft-inc/nebula-br.git
cd nebula-br/
make
# 得单独安装nebula-agent, 并在集群中的每个主机上运行代理服务, 否则报错:
# Error: parse cluster response failed: response is not successful, code is E_LIST_CLUSTER_NO_AGENT_FAILURE
git clone https://github.com/vesoft-inc/nebula-agent.git
cd nebula-agent/
make
./nebula-agent --agent="127.0.0.1:8888" --meta="127.0.0.1:9559"
4.1.1 限制
- Nebula Graph 版本需要为 v3.1.0
- 数据备份仅支持全量备份, 不支持增量备份
- 仅支持单 metad 部署的本地文件的备份和恢复
- Nebula Listener 暂时不支持备份, 且全文索引也不支持备份
- 如果备份数据到本地磁盘, 备份的文件将会放置在每个服务器的本地路径中。也可以在本地挂载 NFS 文件系统, 以便将备份数据还原到不同的主机上。
- 备份图空间只能恢复到原集群, 不能跨集群恢复。
- 数据备份过程中, 指定图空间中的 DDL 和 DML 语句将会阻塞, 我们建议在业务低峰期进行操作, 例如凌晨 2 点至 5 点。
- 数据恢复仅支持在相同拓扑的集群上进行, 即原集群和目标集群的主机数量必须相同。
- 数据恢复需要删除数据并重启, 建议离线进行。
- (实验性功能)如果备份 A 集群中的某个指定图空间, 此备份无法还原至另一个集群 B, 还原该指定图空间时将清除集群中其余所有图空间。
# 在集群中的每个主机上运行代理服务
# 如果在本地保存备份文件, 需要在 Meta 服务器、Storage 服务器和 BR 机器上创建绝对路径相同的目录, 并记录绝对路径, 同时需要保证账号对该目录有写权限
./bin/nebula-agent --agent="127.0.0.1:8888" --meta="127.0.0.1:9559"
./bin/nebula-br backup full --meta "127.0.0.1:9559" --storage "local:///data/nebula/backups/"
./bin/nebula-br show --storage "local:///data/nebula/backups/"
./bin/nebula-br restore full --meta "127.0.0.1:9559" --storage "local:///data/nebula/backups/" --name BACKUP_2022_07_25_17_10_36
./bin/nebula-br cleanup --meta "127.0.0.1:9559" --storage "local:///data/nebula/backups/" --name BACKUP_2022_07_25_17_10_36
# 如果用户新集群的IP和备份集群不同, 在恢复集群后需要使用 add host 向新集群中添加 Storage 主机。
4.2 快照
- 只支持创建所有图空间的快照, 不支持创建指定图空间的快照。
- 如果身份认证开启, 仅 God 角色用户可以使用快照功能
- 系统结构发生变化后, 建议立刻创建快照, 例如在add host、drop host、create space、drop space、balance等操作之后
- 不支持自动回收创建失败的快照垃圾文件, 需要手动删除
- 不支持指定快照保存路径, 默认路径为: {nebula-dir}/data(快照目录会自动在 leader Meta 服务器和所有 Storage 服务器的目录checkpoints内创建)
- 当前未提供恢复快照命令, 需要手动拷贝快照文件到对应的文件夹内, 也可以通过 shell 脚本进行操作
CREATE SNAPSHOT;
SHOW SNAPSHOTS;
DROP SNAPSHOT <snapshot_name>;
find /data/nebula/ | grep 'SNAPSHOT_2022'
当数据丢失需要通过快照恢复时, 用户可以找到合适的时间点快照, 将内部的文件夹 data 和 wal 分别拷贝到各自的上级目录(和 checkpoints 平级), 覆盖之前的 data 和 wal , 然后重启集群即可。
需要同时覆盖所有 Meta 节点的 data 和 wal 目录, 因为存在重启集群后发生 Meta 重新选举 leader 的情况, 如果不覆盖所有 Meta 节点, 新的 leader 使用的还是最新的 Meta 数据, 导致恢复失败。
4.3 数据导入与导出
配置 yaml 文件并准备好待导入的 CSV 文件, 即可使用nebula-importer 向 Nebula Graph 批量写入数据。
$ ./nebula-importer --config <yaml_config_file_path>
5. 实践
5.1 Compaction
Compaction是最重要的后台操作, 对性能有极其重要的影响。Compaction操作会读取硬盘上的数据, 然后重组数据结构和索引, 然后再写回硬盘, 可以成倍提升读取性能。将大量数据写入 Nebula Graph 后, 为了提高读取性能, 需要手动触发Compaction操作(全量Compaction)。
- 自动Compaction
- 全量Compaction
USE <your_graph_space>;
SUBMIT JOB COMPACT;
SHOW JOB <job_id>;
操作建议:
- 数据导入完成后, 请执行SUBMIT JOB COMPACT。
- 业务低峰期(例如凌晨)执行SUBMIT JOB COMPACT。
- 为控制Compaction的读写速率, 请在配置文件nebula-storaged.conf中设置如下参数:
# 不支持动态调整
--rocksdb_rate_limit=20 (in MB/s)
- 开始后不可以停止, 必须等待操作完成
读写速率限制为 20MB/S。
–rocksdb_rate_limit=20 (in MB/s)
5.2 负载均衡和数据同步
5.2.1 负载均衡
BALANCE 平衡分片和 Raft leader 的分布, 或者清空某些 Storage 服务器方便进行维护.(仅企业版支持均衡分片分布)
USE basketballplayer;
BALANCE DATA;
// RECOVER JOB <job_id>
RECOVER JOB <job_id>
// 停止负载均衡作业:不会停止正在执行的子任务, 而是取消所有后续子任务, 状态会置为 INVALID , 然后等待正在执行的子任执行完毕根据结果置为 SUCCEEDED 或 FAILED 。用户可以执行命令 SHOW JOB <job_id> 检查停止的作业状态
STOP JOB <job_id>
5.2.3 数据同步
Nebula Graph 支持在集群间进行数据同步, 即主集群 A 的数据可以近实时地复制到从集群 B 中, 方便用户进行异地灾备或分流, 降低数据丢失的风险, 保证数据安全。(仅企业版支持本功能)
- 数据同步的基本单位是图空间, 即只可以设置从一个图空间到另一个图空间的数据同步
- 主从集群的数据同步是异步的(近实时)
# master
SHOW HOSTS STORAGE;
SHOW HOSTS STORAGE LISTENER;
SHOW HOSTS META LISTENER;
USE basketballplayer;
SIGN IN DRAINER SERVICE(192.168.10.104:9889);
SHOW DRAINER CLIENTS;
ADD LISTENER SYNC META 192.168.10.103:9569 STORAGE 192.168.10.103:9789 TO SPACE replication_basketballplayer;
SHOW LISTENER SYNC;
#slaver
SHOW HOSTS STORAGE;
SHOW HOSTS DRAINER;
ADD DRAINER 192.168.10.104:9889;
SHOW DRAINERS;
use replication_basketballplayer;
SET VARIABLES read_only=true;
GET VARIABLES read_only;
stop sync
restart sync
5.3 其他建议
- 大批量的数据写入可以使用 sst 加载的方式; 小批量的写入使用INSERT语句
- 选择合适的时间运行 COMPACTION 和 BALANCE, 来分别优化数据格式和存储分布
- Storaged 不支持预热数据, 只有 RocksDB 自身的 LSM-tree 和 BloomFilter 会启动时加载到内存中
- 点和边被访问过后, 会各自缓存在 Storaged 的两种 (LRU) Cache 中
- EXPLAIN 和 PROFILE
- 当一个点的出入度超过 1 万时, 就可以视为是稠密点。需要考虑一些特殊的设计和处理
