
目录
大型语言模型(LLM)通常太大而无法在消费者硬件上运行。这些模型可能超过数十亿个参数, 通常需要具有大量 VRAM 的 GPU 来加速推理。
因此, 越来越多的研究集中在通过改进训练、适配器等来缩小这些模型。该领域的一项主要技术称为量化。
| 数据类型 | 数字范围 | 精度 |
|---|---|---|
| float32 | -1.18e38 to 3.4e38 | 7 digits |
| float16 | -65k to 65k | 3 digits |
| bfloat16 | -3.39e38 to 3.39e38 | 3 digits |
| int8 | -128 to 127 | 0 digits |
| int4 | -8 to 7 | 0 digits |
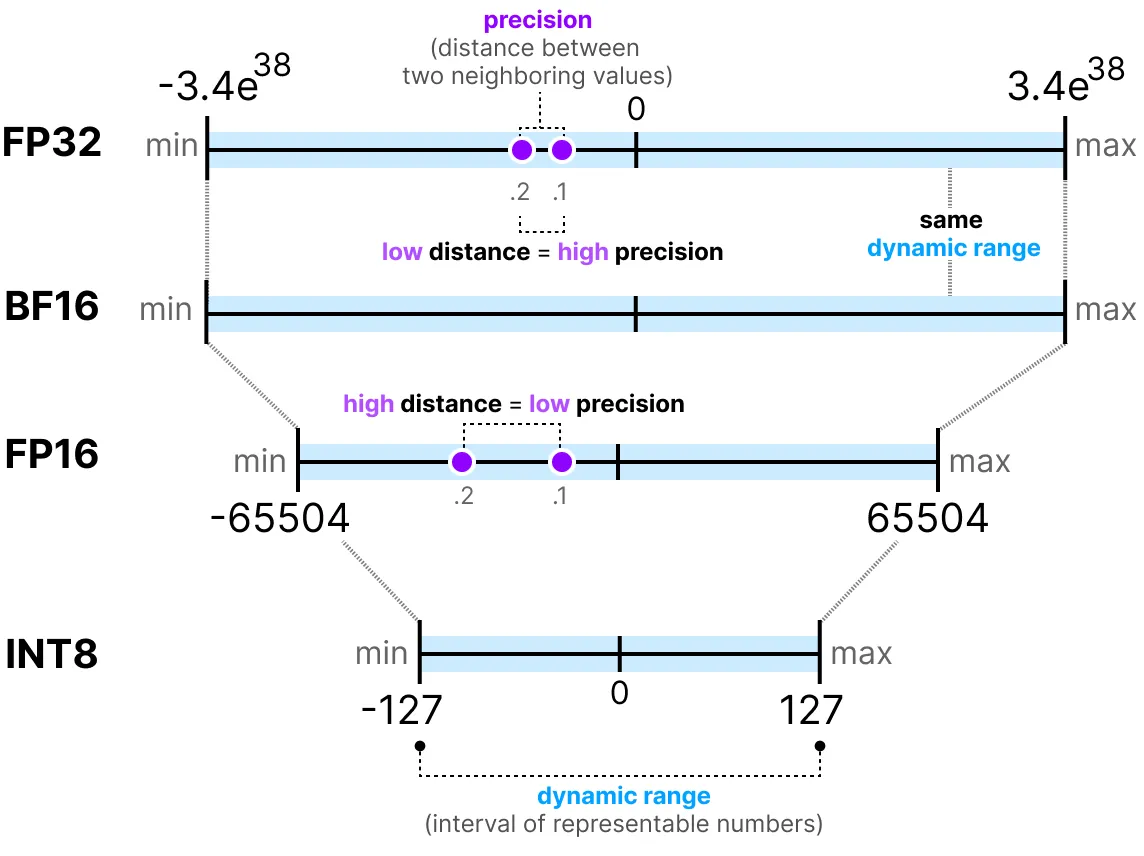
在 ML 术语中, FP32 通常被称为“全精度”(4 个字节), 而 BF16 和 FP16 是“半精度”(2 个字节)。但是, 我们能否做得更好, 使用单个字节存储权重?答案是 INT8 数据类型, 它由能够存储 (2^8 = 256)不同值的 8 位表示形式组成。在下一节中, 我们将了解如何将 FP32 权重转换为 INT8 格式。
1. 量化简介
量化旨在将模型参数的精度从较高的位宽(如 32 位浮点)降低到较低的位宽(如 8 位整数)。最小化表示模型参数的位数(以及在训练期间)是非常引人注目的。但是, 随着精度的降低, 模型的精度通常也会降低。
1.1 常见数据类型
首先, 让我们看一下常见的数据类型以及使用它们而不是 32 位(称为全精度或 FP32)表示形式的影响。
-
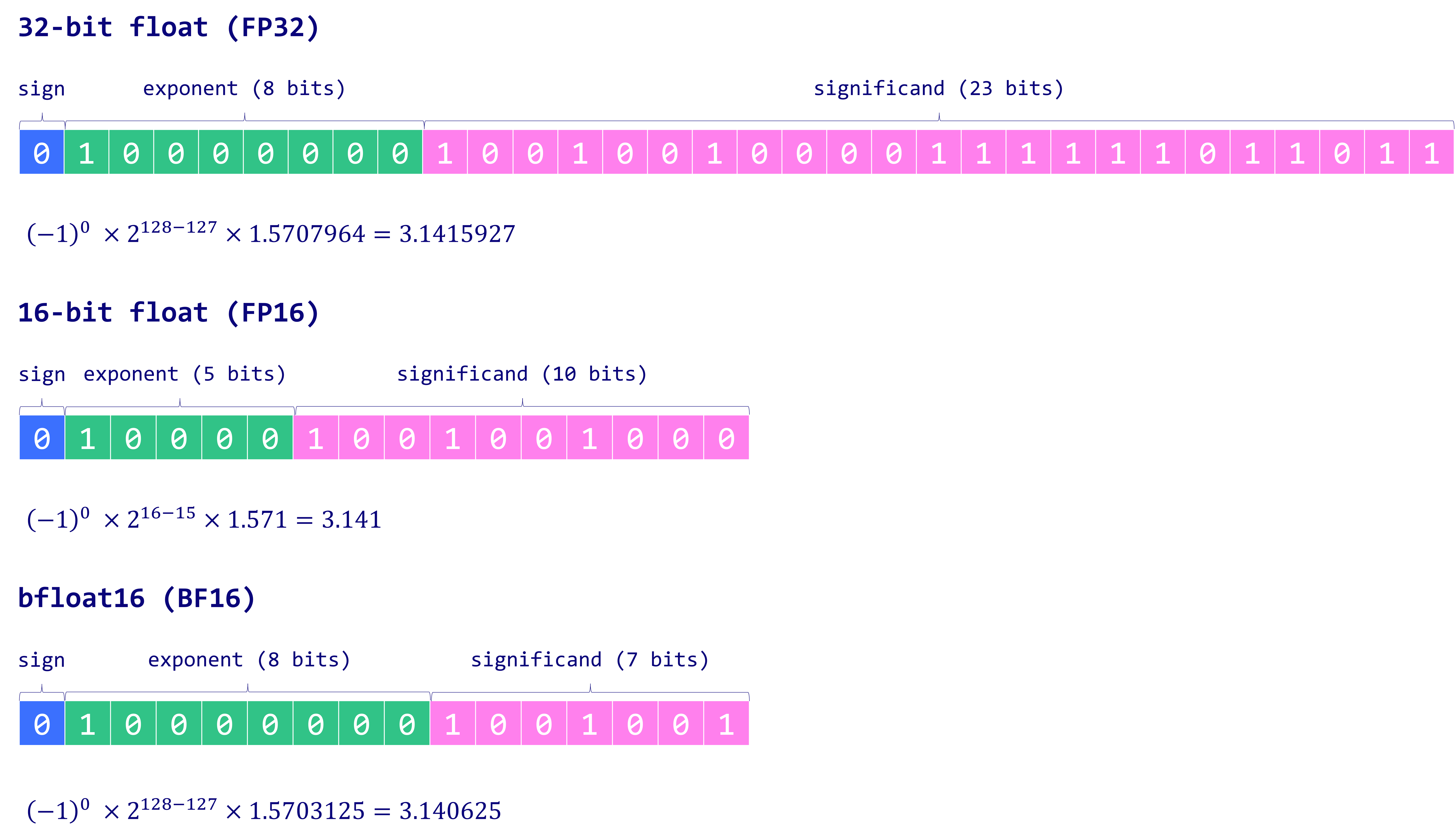
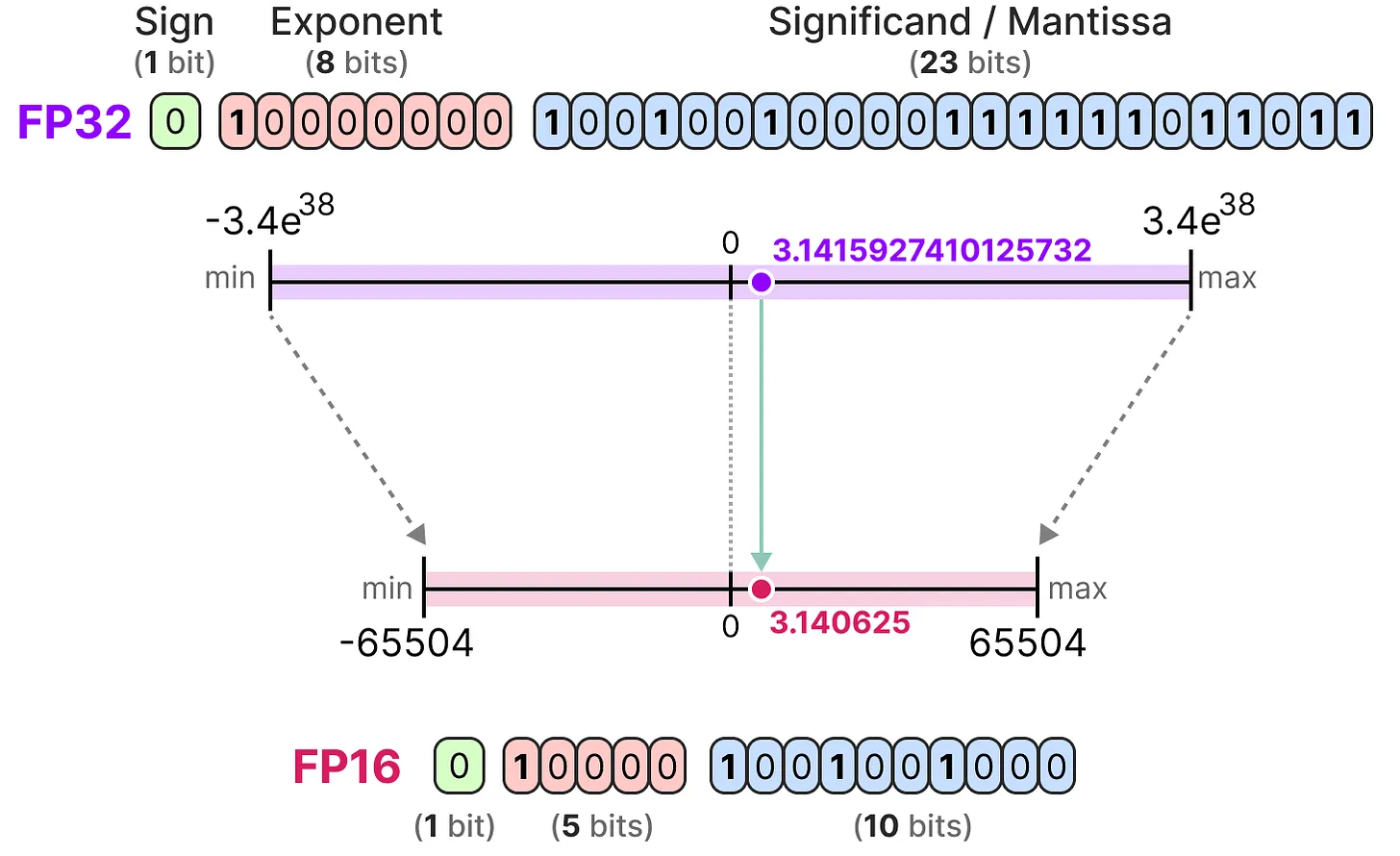
FP16型
让我们看一个从 32 位到 16 位(称为半精度或 FP16)浮点的示例:
-
BF16型
为了获得与原始 FP32 相似的值范围, 引入了 bfloat 16 作为“截断 FP32”的一种类型:
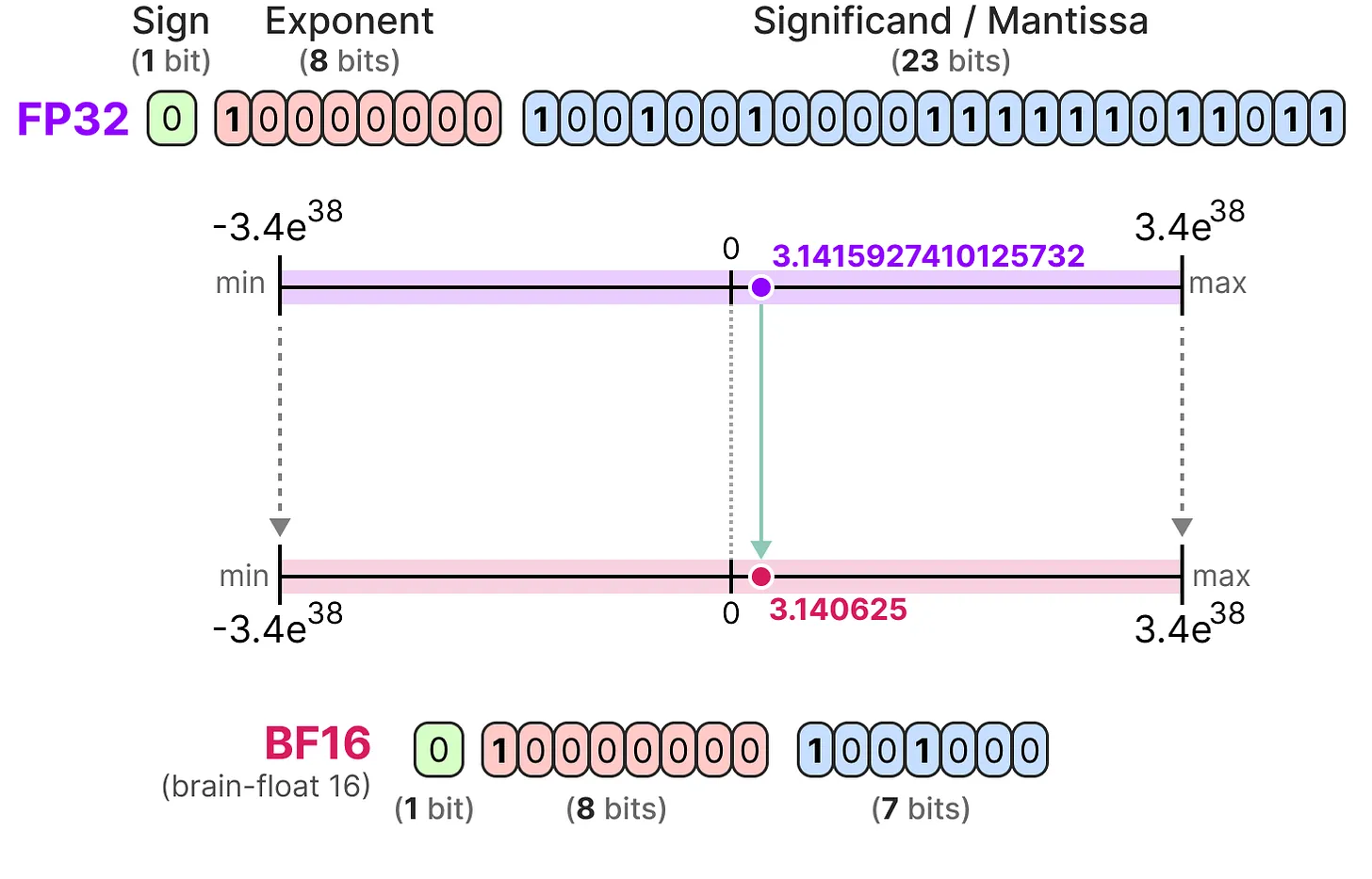
BF16 使用与 FP16 相同数量的比特, 但可以采用更广泛的值范围, 并且通常用于深度学习应用程序。
- INT8
当我们进一步减少比特数时, 我们接近基于整数的表示领域, 而不是浮点表示。举例来说, 将 FP32 升级到只有 8 位的 INT8 将导致原始位数的四分之一:
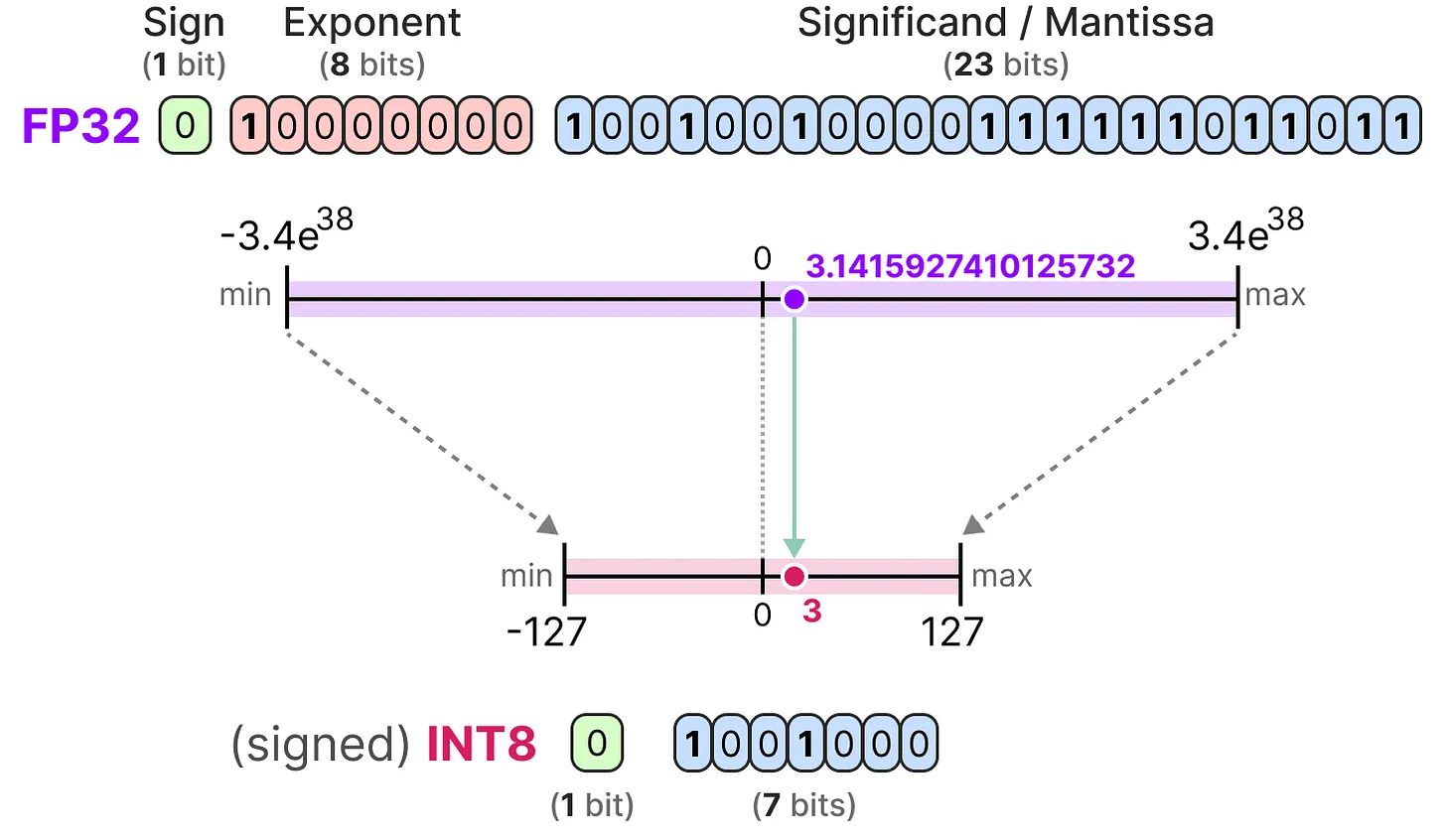
根据硬件的不同, 基于整数的计算可能比浮点计算更快, 但情况并非总是如此。但是, 当使用较少的位时, 计算速度通常更快。
在实践中, 我们不需要将整个 FP32 范围 [-3.4e38, 3.4e38] 映射到 INT8。我们只需要找到一种方法将我们的数据范围(模型的参数)映射到 IN8 中。常见的压缩/映射方法是对称量化和非对称量化, 是线性映射的形式。
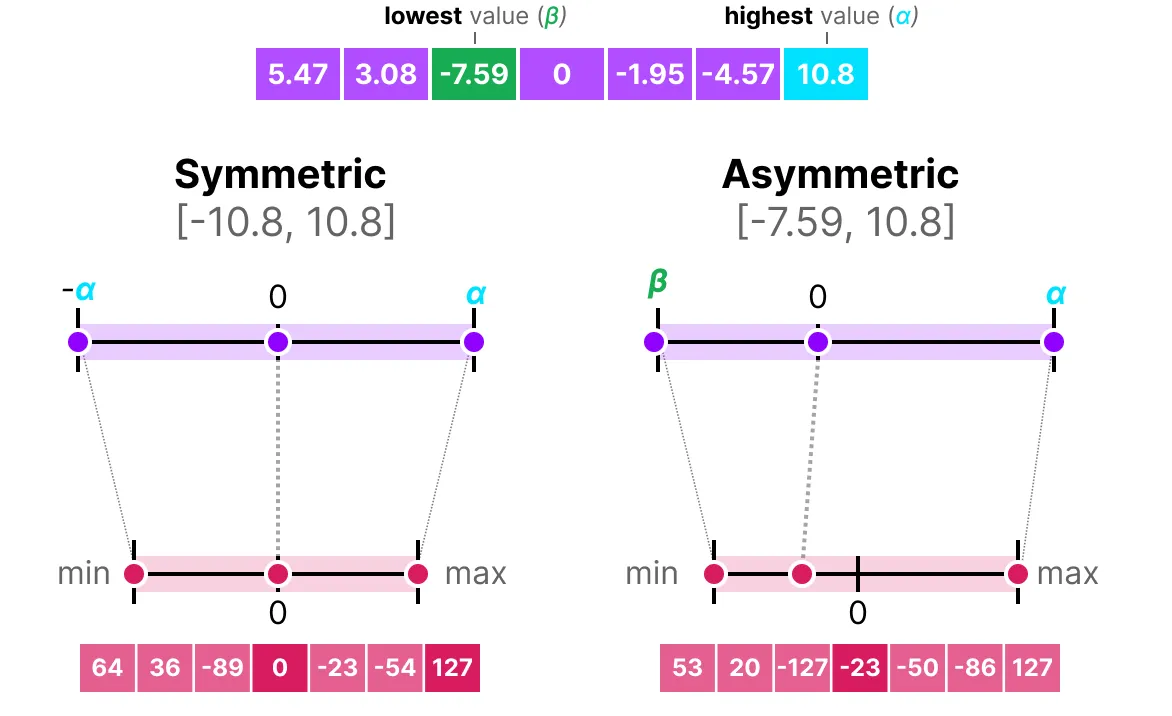
1.2 对称量化
在对称量化中, 原始浮点值的范围映射到量化空间中围绕零的对称范围。在前面的示例中, 请注意量化前后的范围如何保持以零为中心。
这意味着浮点空间中零的量化值在量化空间中恰好为零。
例如, 给定一个值列表, 我们将最高绝对值(α)作为执行线性映射的范围:
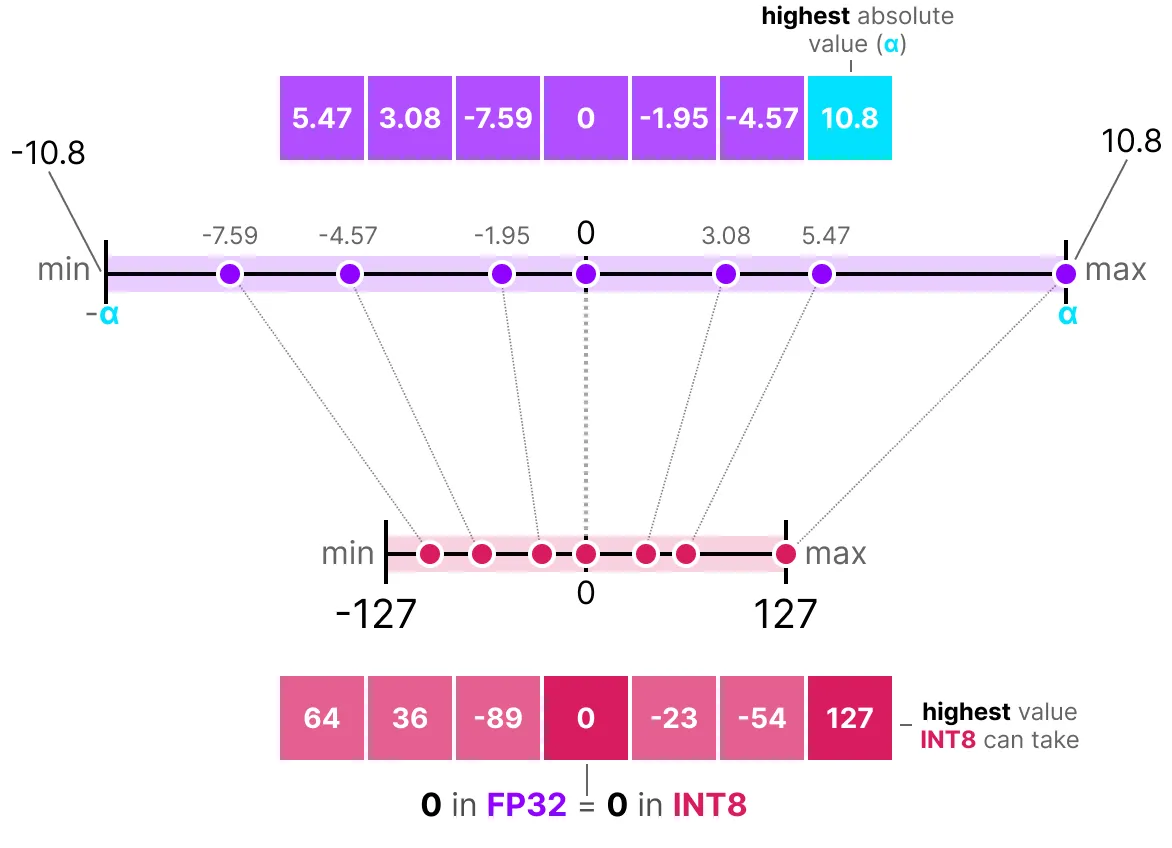
由于它是以零为中心的线性映射, 因此公式很简单。我们首先使用以下方法计算比例因子:
- b 是我们想要量化为(8)的字节数,
- a 是最高的绝对值,
然后, 我们使用 s 来量化输入 x: \( s = \frac{2^{b-1} - 1}{a} \)
然后, 填写这些值将得到以下内容: \( s = \frac{127}{10.8} = 11.76 \)
应用量化, 然后应用反量化过程来检索原始数据, 如下所示:
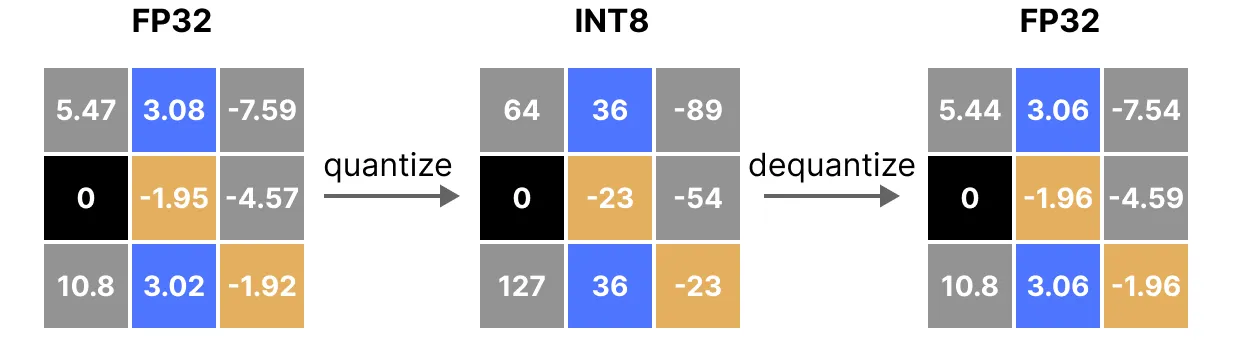
您可以看到某些值, 例如 3.08 和 3.02 被分配给 INT8, 即 36。当您对值进行反量化以返回到 FP32 时, 它们会失去一些精度并且不再可区分。
这通常被称为量化误差, 我们可以通过找到原始值和反量化值之间的差异来计算。
1.3 非对称量化
相比之下, 非对称量化在零附近不对称。相反, 它将浮点数范围的最小值(β)和最大值(α)映射到量化范围的最小值和最大值。
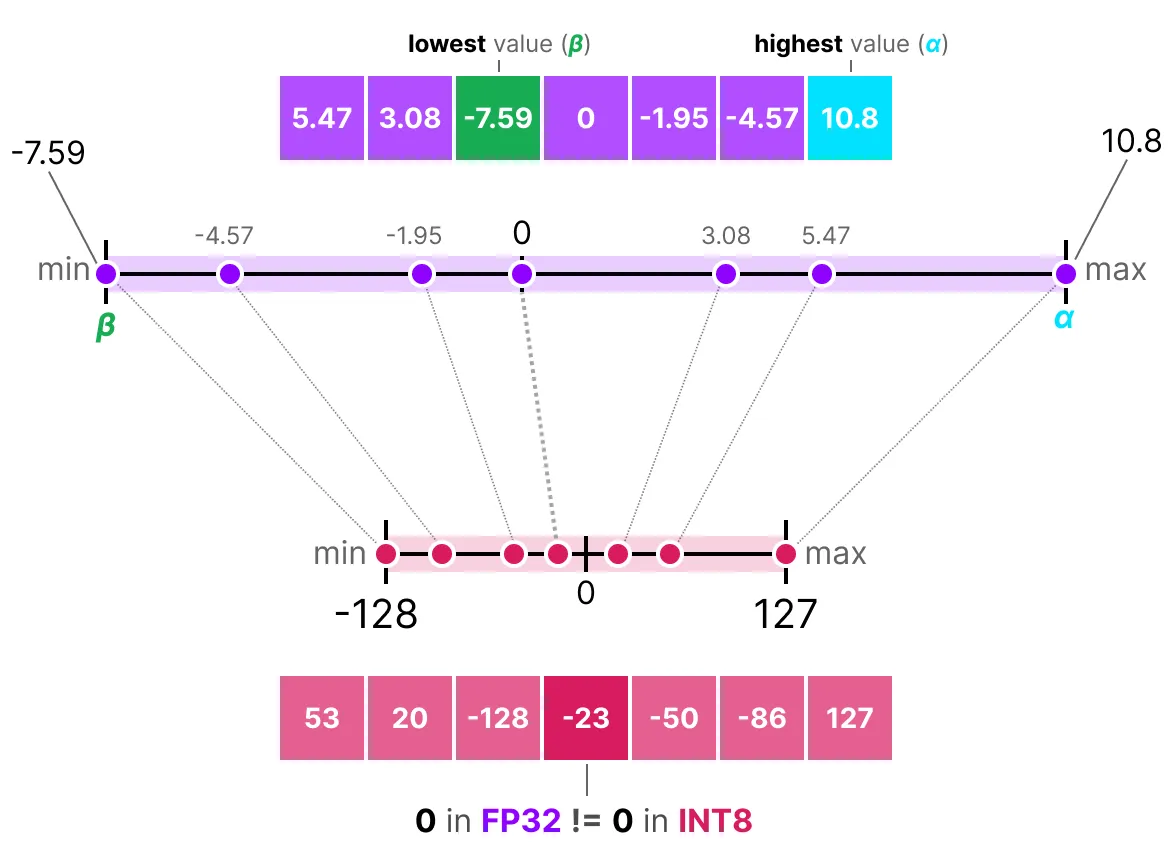
注意到 0 是如何移动位置的吗?这就是为什么它被称为非对称量化。最小值/最大值在 [-7.59, 10.8] 范围内与 0 的距离不同。
由于其位置偏移, 我们必须计算 INT8 范围的零点才能执行线性映射。和以前一样, 我们还必须计算比例因子(s), 但使用 INT8 范围的差值 [-128, 127]
为了将从 INT8 反量化回 FP32, 我们需要使用先前计算的比例因子(s)和零点(z)。
当我们将对称量化和非对称量化并排放置时, 我们可以快速看到方法之间的区别:
1.4 范围映射和裁剪
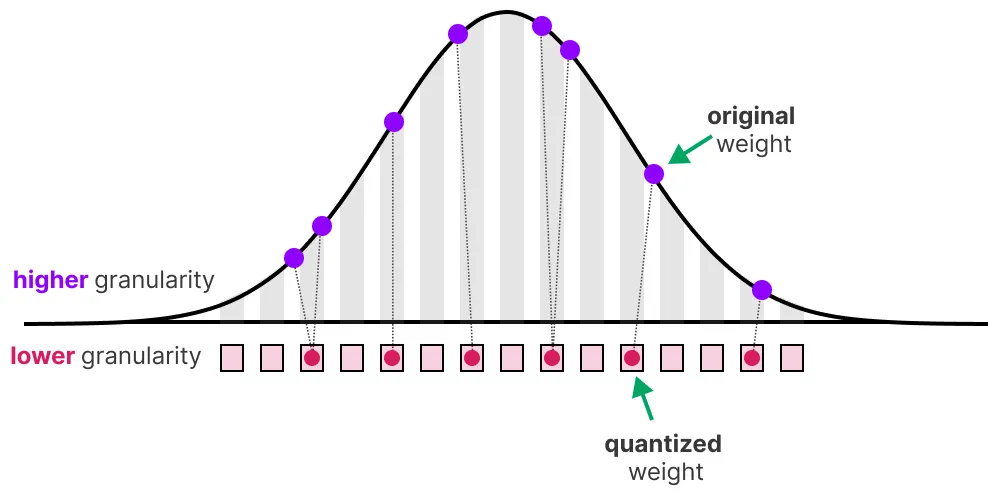
在前面的示例中, 我们探讨了如何将给定向量中的值范围映射到较低位的表示形式。虽然这允许映射所有范围的向量值, 但它有一个主要的缺点, 即异常值。
想象一下, 您有一个具有以下值的向量:

请注意, 一个值比所有其他值大得多, 可以被视为异常值。如果我们要映射此向量的整个范围, 则所有小值都将映射到相同的低位表示, 并失去它们的微分因子:
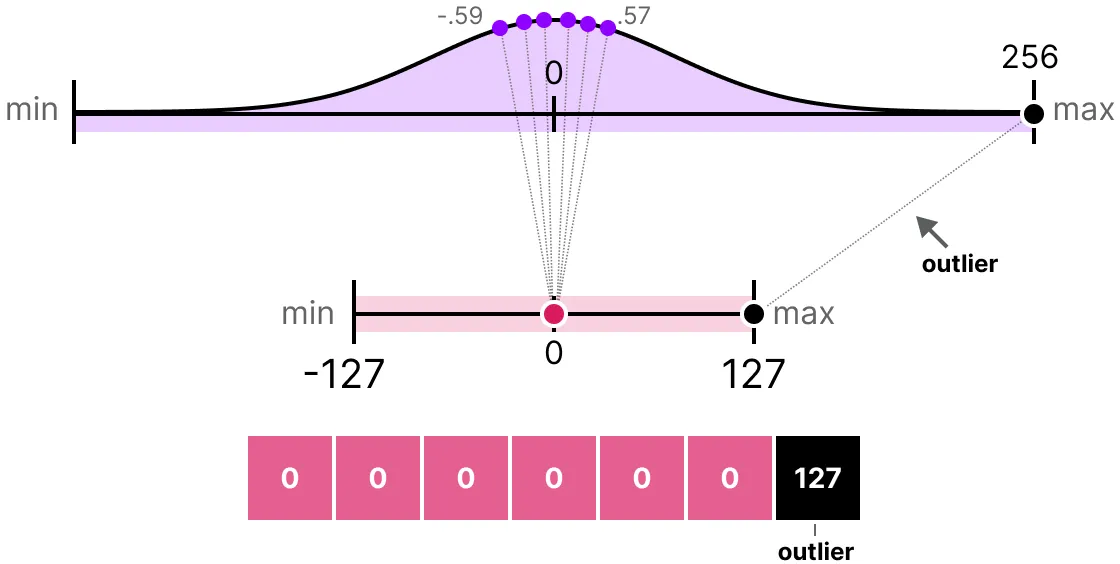
这就是我们之前使用的 absmax 方法。请注意, 如果我们不应用裁剪, 则非对称量化也会发生相同的行为。相反, 我们可以选择裁剪某些值。裁剪涉及设置原始值的不同动态范围, 以便所有异常值获得相同的值。
主要优点是非异常值的量化误差显著降低。但是, 异常值的量化误差会增加。
1.5 校准
在这个例子中, 我展示了一种选择任意范围 [-5, 5] 的幼稚方法。选择此范围的过程称为校准, 其目的是找到一个包含尽可能多的值的范围, 同时最小化量化误差。
对于所有类型的参数, 执行此校准步骤并不相同。
1.5.1 权重(和偏差)
我们可以将 LLM 的权重和偏差视为静态值, 因为它们在运行模型之前是已知的。例如, Llama 3 的 ~20GB 文件主要由其重量和偏差组成。
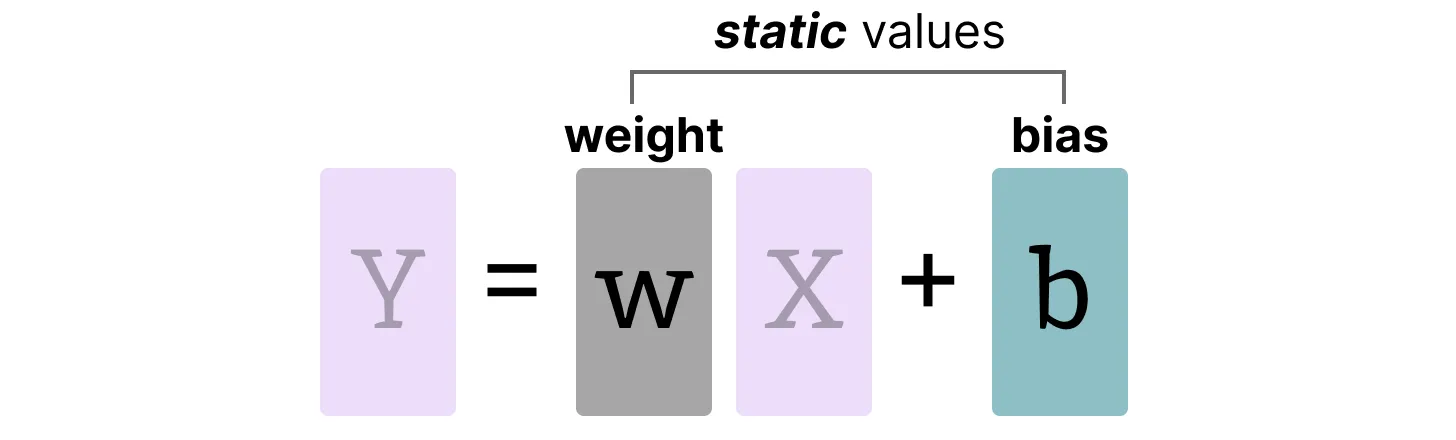
由于偏差(百万)明显少于权重(十亿), 因此偏差通常保持在更高的精度(例如INT16), 并且量化的主要精力都放在权重上。
对于静态和已知的砝码, 用于选择量程的校准技术包括:
- 手动选择 输入范围的百分位数
- 优化 原始权重和量化权重之间的均方误差(MSE)。
- 最小化 原始值和量化值之间的熵(KL 散度)

1.5.2 激活
在整个 LLM 中不断更新的输入通常称为“激活”。请注意, 这些值称为激活, 因为它们通常会经历一些激活函数, 例如 sigmoid 或 relu。
与权重不同, 在推理过程中, 每个输入数据的激活都会发生变化, 因此准确量化它们具有挑战性。
由于这些值在每个隐藏层之后都会更新, 因此我们只知道在输入数据通过模型时, 在推理过程中它们会是什么。
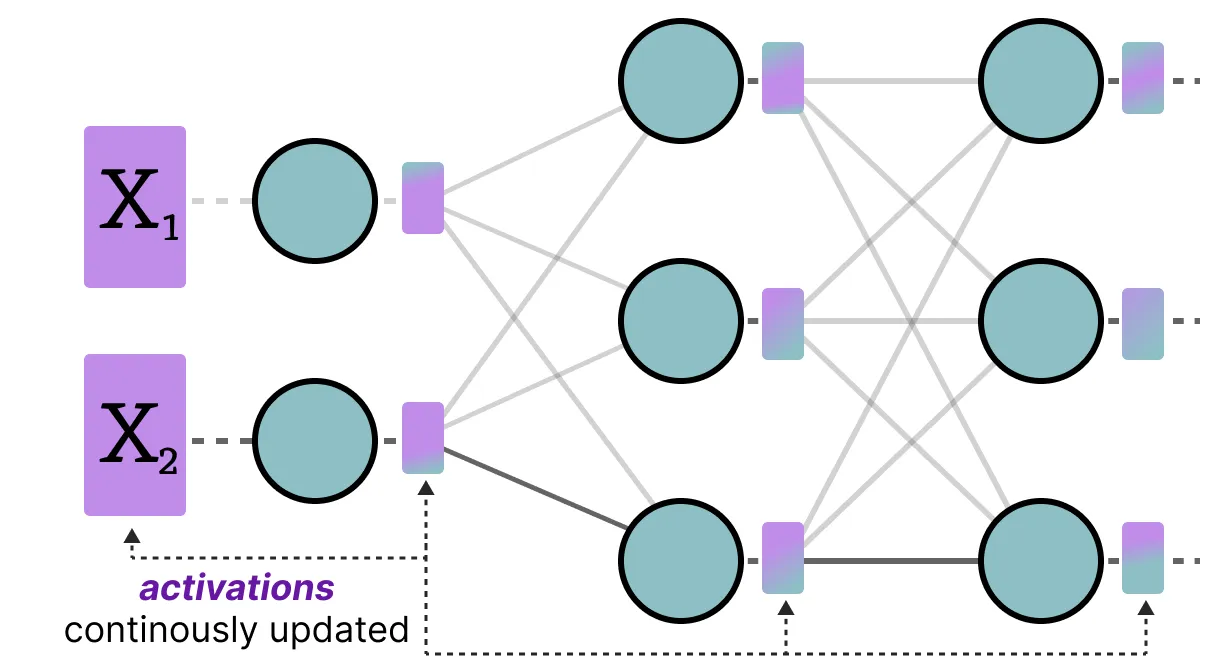
从广义上讲, 有两种方法可以校准权重和激活的量化方法:
- 训练后量化(PTQ)
- 训练后的量化
- 量化感知训练(QAT)
- 训练/微调期间的量化
2. 训练后量化(PTQ)
最流行的量化技术之一是训练后量化(PTQ)。它涉及在训练模型后量化模型的参数(权重和激活)。权重的量化 是使用对称或非对称量化来执行的。然而, 由于我们不知道它们的范围, 因此需要对激活进行量化, 从而获得模型的推理以获得它们的潜在分布。
激活的量化有两种形式:
- 动态量化
- 静态量化
2.1 动态量化
数据通过隐藏层后, 将收集其激活:
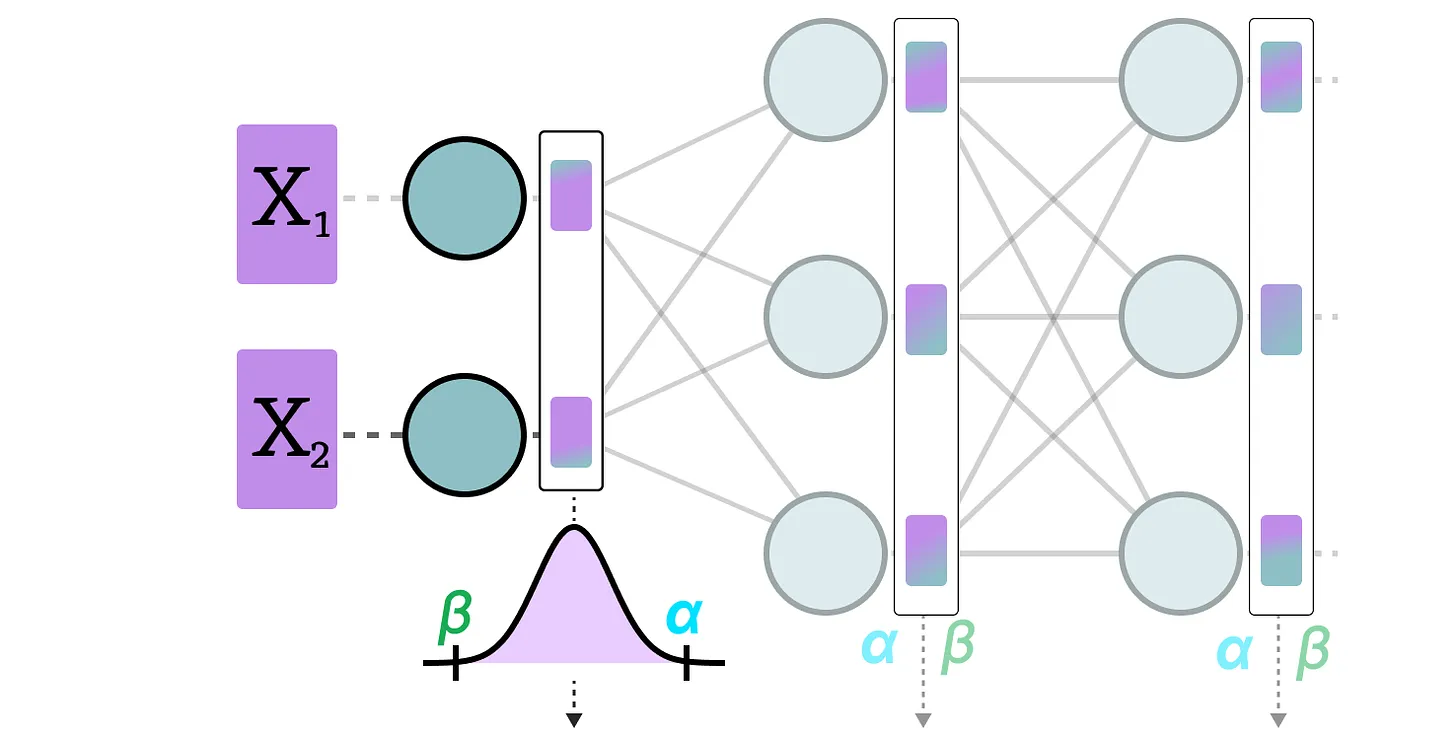
然后, 使用这种激活分布来计算量化输出所需的零点(z)和比例因子(s)值: 。
每次数据通过新层时, 都会重复该过程。因此, 每一层都有自己独立的 z 和 s 值, 因此具有不同的量化方案。
2.2 静态量化
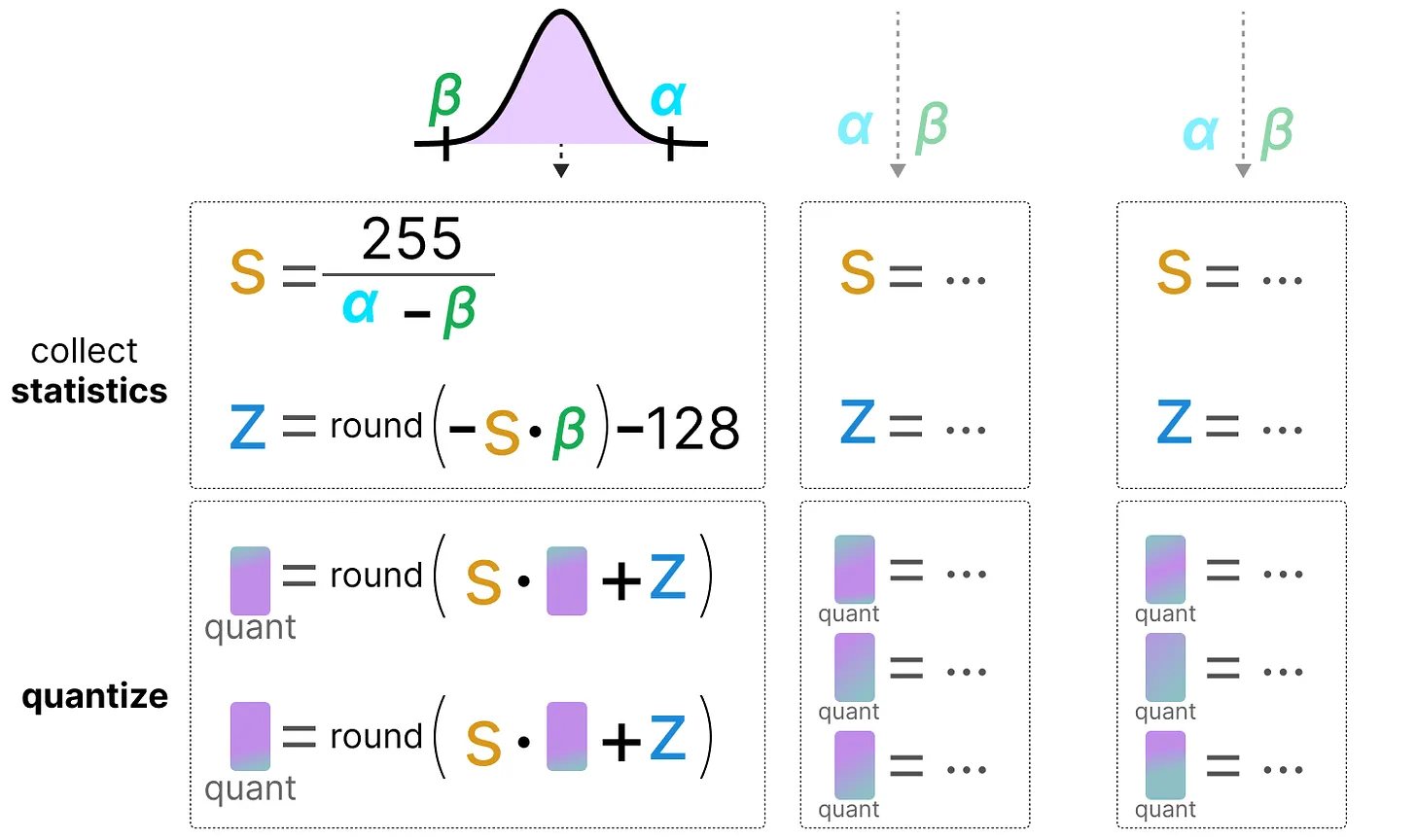
与动态量化相比, 静态量化不会在推理过程中计算零点(z)和刻度因子(s), 而是事先计算。
为了找到这些值, 使用校准数据集并将其提供给模型以收集这些潜在分布。
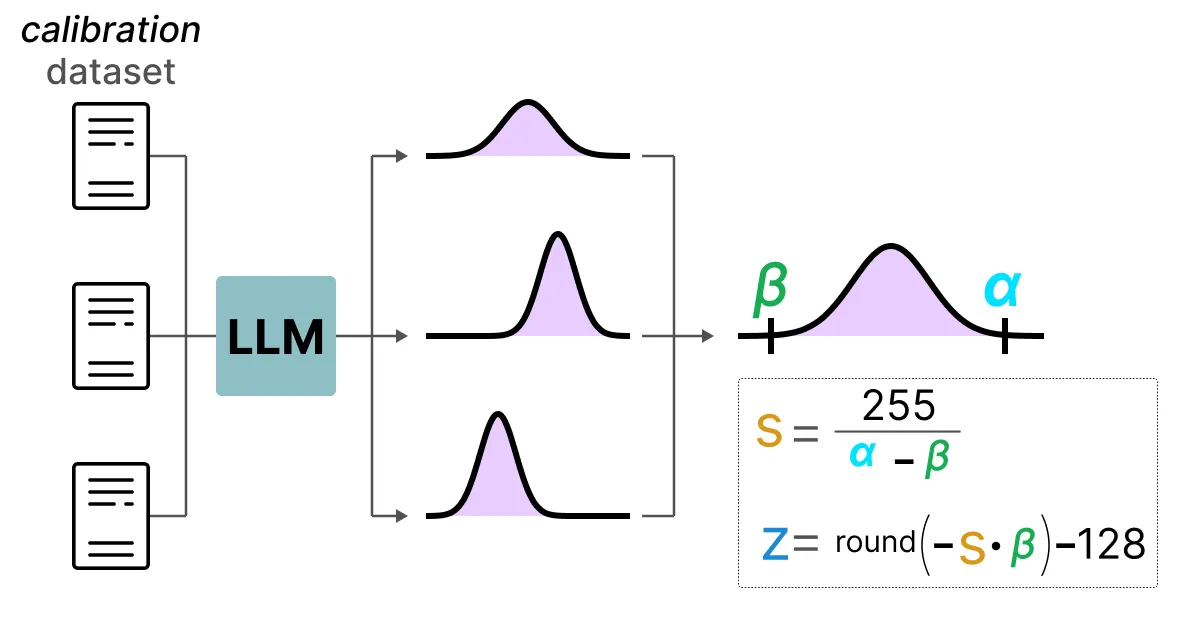
收集这些值后, 我们可以计算出在 推理过程中执行量化所需的 s 和 z 值。
当您执行实际推理时, s 和 z 值不会重新计算, 而是在所有激活上全局使用以量化它们。
一般来说, 动态量化往往更准确一些, 因为它只尝试计算每个隐藏层的 s 和 z 值。但是, 它可能会增加计算时间, 因为需要计算这些值。
相比之下, 静态量化的准确性较低, 但速度更快, 因为它已经知道用于量化的 s 和 z 值。
2.3 4位量化的领域
事实证明, 低于 8 位的量化是一项艰巨的任务, 因为量化误差随着每丢失一个比特而增加。幸运的是, 有几种聪明的方法可以将比特减少到 6 位、4 位甚至 2 位(尽管通常不建议使用这些方法低于 4 位)。
我们将探讨在HuggingFace上通常共享的两种方法:
- GPTQ(GPU 上的完整模型)
- GGUF(可能会卸载 CPU 上的层)
2.3.1 GPTQ的
它使用非对称量化, 并逐层进行量化, 以便每一层都独立处理, 然后再继续到下一层:
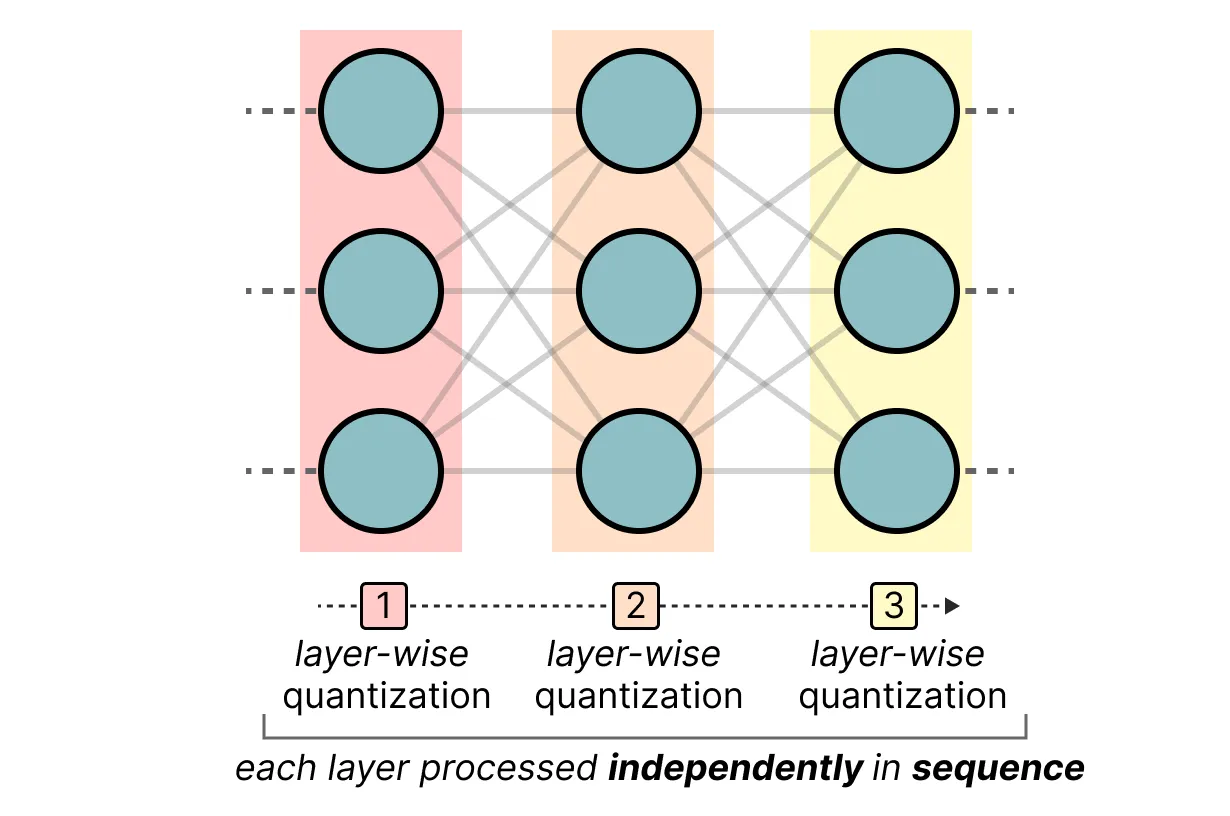
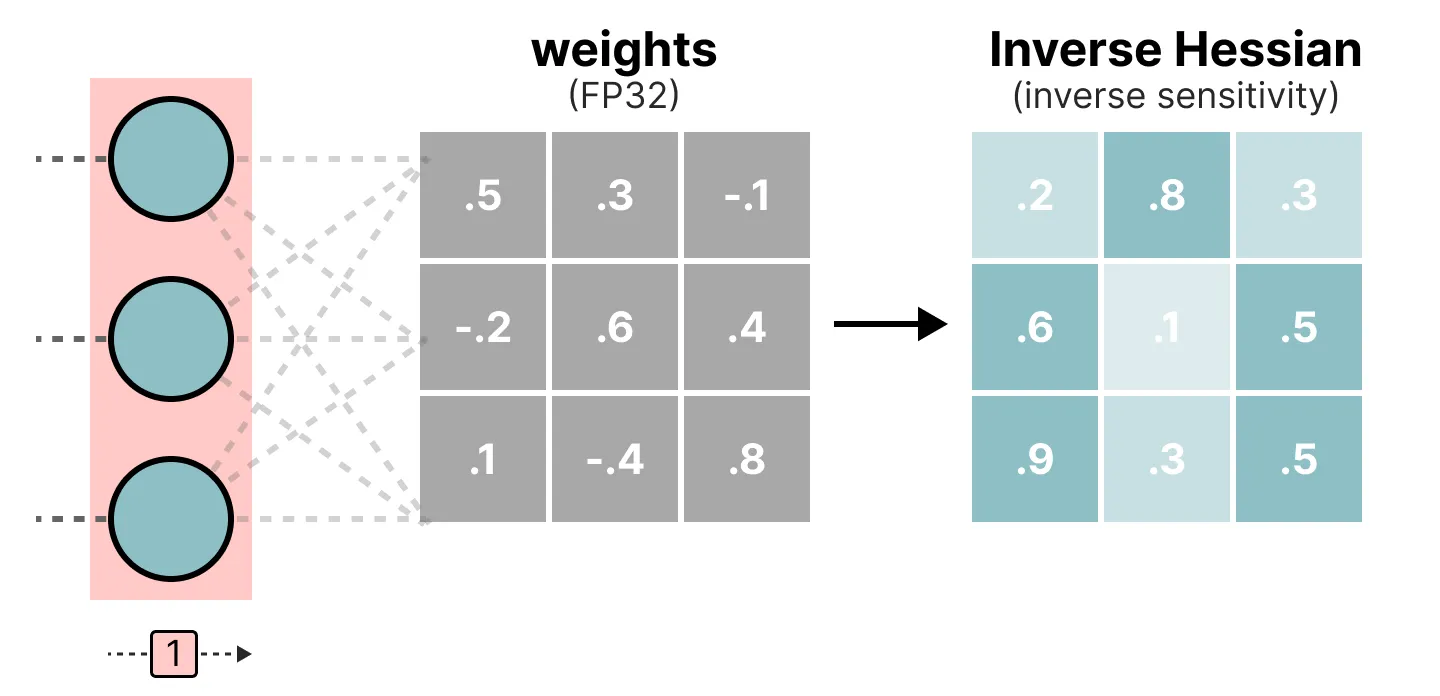
在这个逐层量化过程中, 它首先将层的权重转换为反混森系数。它是模型损失函数的二阶导数, 告诉我们模型的输出对每个权重变化的敏感程度。
简化而言, 它基本上展示了层中每个权重的(反向)重要性。
与 Hessian 矩阵中较小值相关的权重更为关键, 因为这些权重的微小变化会导致模型性能的重大变化。
接下来, 我们对权重矩阵中第一行的权重进行量化, 然后对权重矩阵进行反量化:
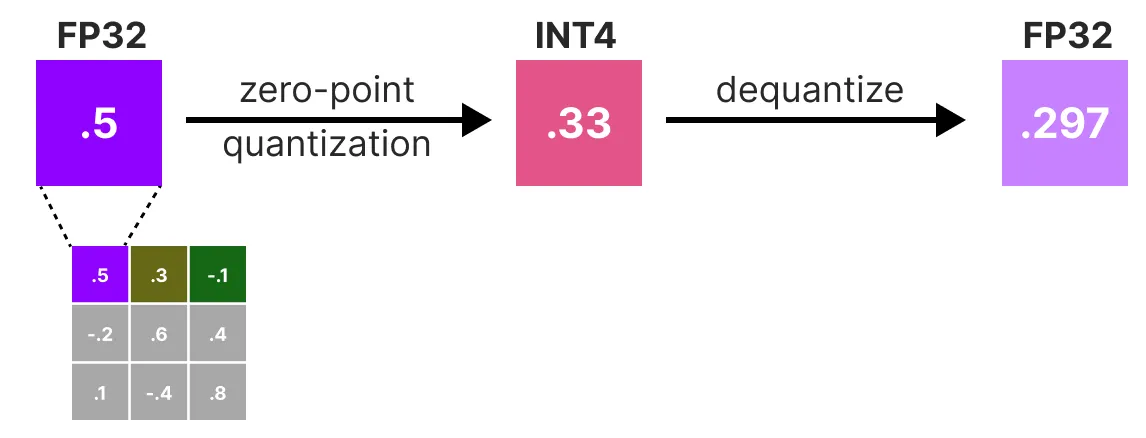
这个过程使我们能够计算量化误差(q), 我们可以使用我们事先计算的 逆 Hessian(h_1)来权衡该误差。
从本质上讲, 我们正在根据权重的重要性创建一个加权量化误差: \( q = \frac{X_1 - x_1}{h1} \)
接下来, 我们将此加权量化误差重新分布到行中的其他权重上。这样可以维持网络的整体功能和输出。
例如, 如果我们要对第二个权重(即 .3(x_2)执行此操作, 我们将将量化误差(q)乘以第二个权重的反混森(h_2): \( X_2 = x_2 + q * h_2 \)
我们可以对给定行中的第三个权重执行相同的过程:
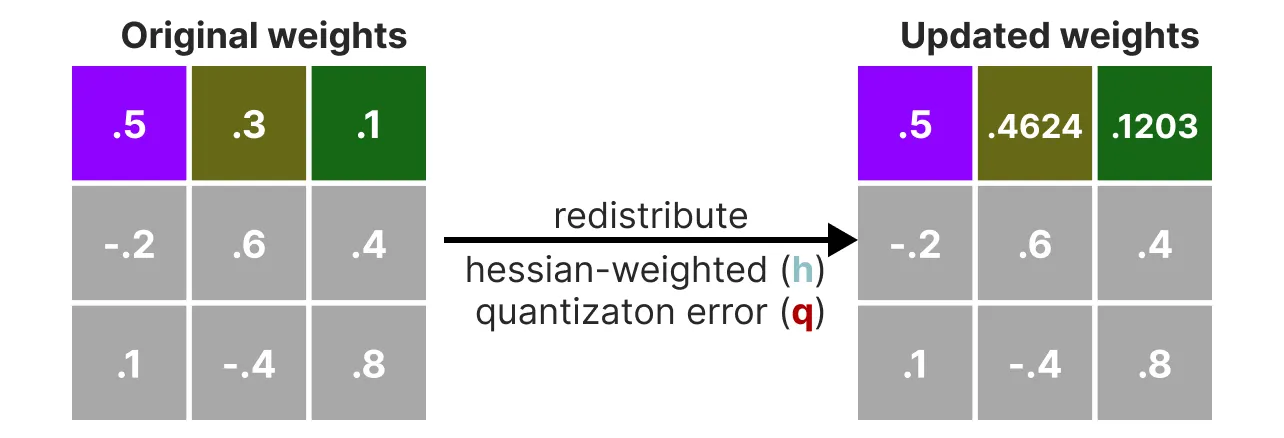
我们迭代了重新分配加权量化误差的过程, 直到所有值都被量化。
这非常有效, 因为权重通常彼此相关。因此, 当一个权重出现量化误差时, 相关权重会相应地更新(通过反混森)。
2.3.2 GGUF系列
虽然 GPTQ 是一种在 GPU 上运行完整 LLM 的绝佳量化方法, 但您可能并不总是具有这种容量。相反, 我们可以使用 GGUF 将 LLM 的任何层卸载到 CPU。
这使您可以在没有足够的 VRAM 时同时使用 CPU 和 GPU。
量化方法 GGUF 经常更新, 可能取决于比特量化的级别。但是, 一般原则如下。
首先, 给定层的权重被分割成“超级”块, 每个块包含一组“子”块。从这些块中, 我们提取比例因子(s)和 alpha(α):
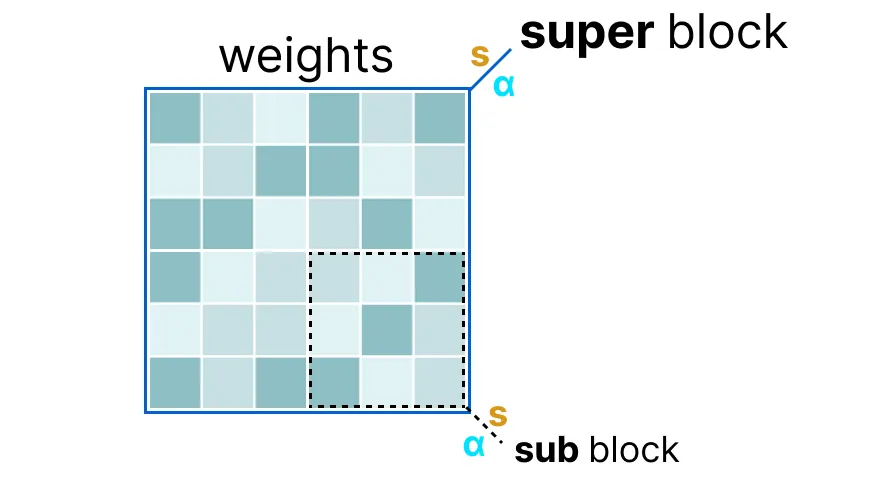
为了量化给定的“子”块, 我们可以使用我们之前使用的 absmax 量化。请记住, 它将给定的权重乘以比例因子(s): \( X = S * X \)
比例因子是使用来自“子”块的信息计算的, 但使用来自“super”块的信息进行量化, 该块有自己的比例因子: \( X = S_{sub} * X \)
这种按块量化使用来自“super”块的比例因子(s_super)来量化来自“sub”块的比例因子(s_sub)。
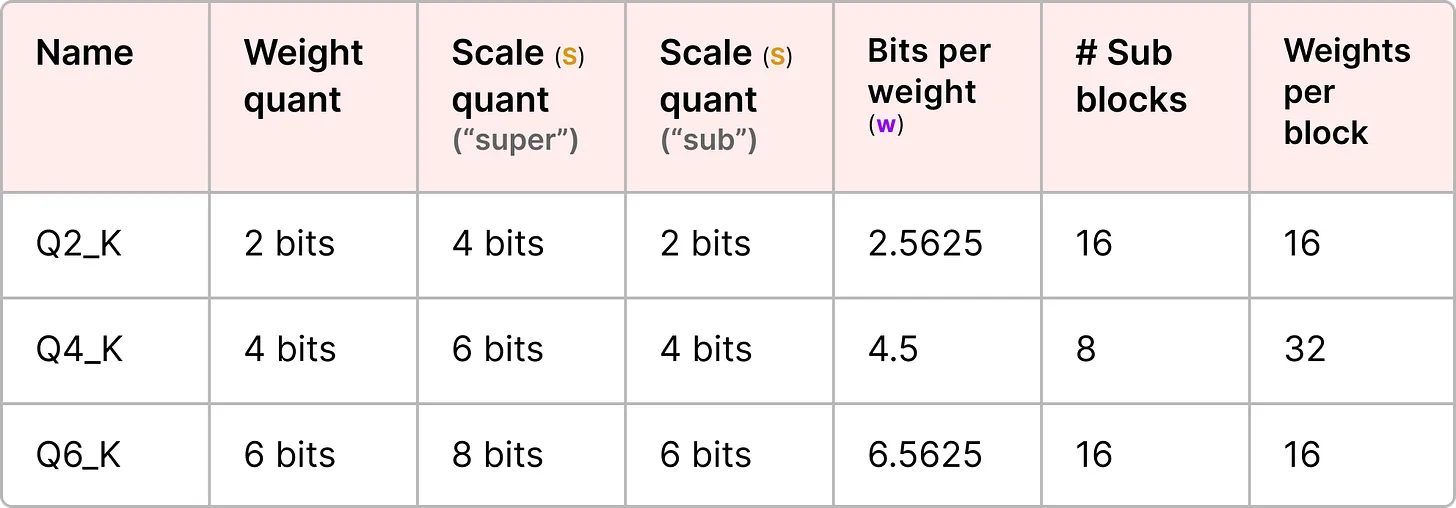
每个比例因子的量化级别可能不同, “超级”块的精度通常高于“子”块的比例因子。
为了说明这一点, 我们来探讨几个量化级别(2 位、4 位和 6 位):
2.3.3 bitsandbytes
BitsandBytes 是一个用于将 8 位和 4 位量化应用于模型的库。它可以在训练期间用于混合精度训练, 也可以在推理之前使用, 以使模型更小。
8 位量化使数十亿参数尺度的模型能够适应较小的硬件, 而不会降低性能。8bit 量化的工作原理如下:
- 从输入的隐藏状态中逐列提取较大的值(异常值)。
- 执行 FP16 中异常值和 int8 中非异常值的矩阵乘法。
- 放大非异常值结果以将值拉回 FP16, 并将它们添加到 FP16 中的异常值结果中。

4 位浮点数(FP4)和 4 位 NormalFloat(NF4)是引入的两种数据类型, 用于 QLoRA 技术, 这是一种参数高效的微调技术。这些数据类型还可用于在没有 QLoRA 的情况下缩小预训练模型。TGI 本质上使用这些数据类型在推理之前进行训练后量化。
2.3.4 ExLlamaV2
3. 量化感知训练(QAT)
训练后量化模型这种方法的一个缺点是, 这种量化不考虑实际的训练过程。这就是量化感知训练(QAT)的用武之地。 QAT 不是在使用训练后量化(PTQ)训练模型后对其进行量化, 而是在训练期间学习量化过程。
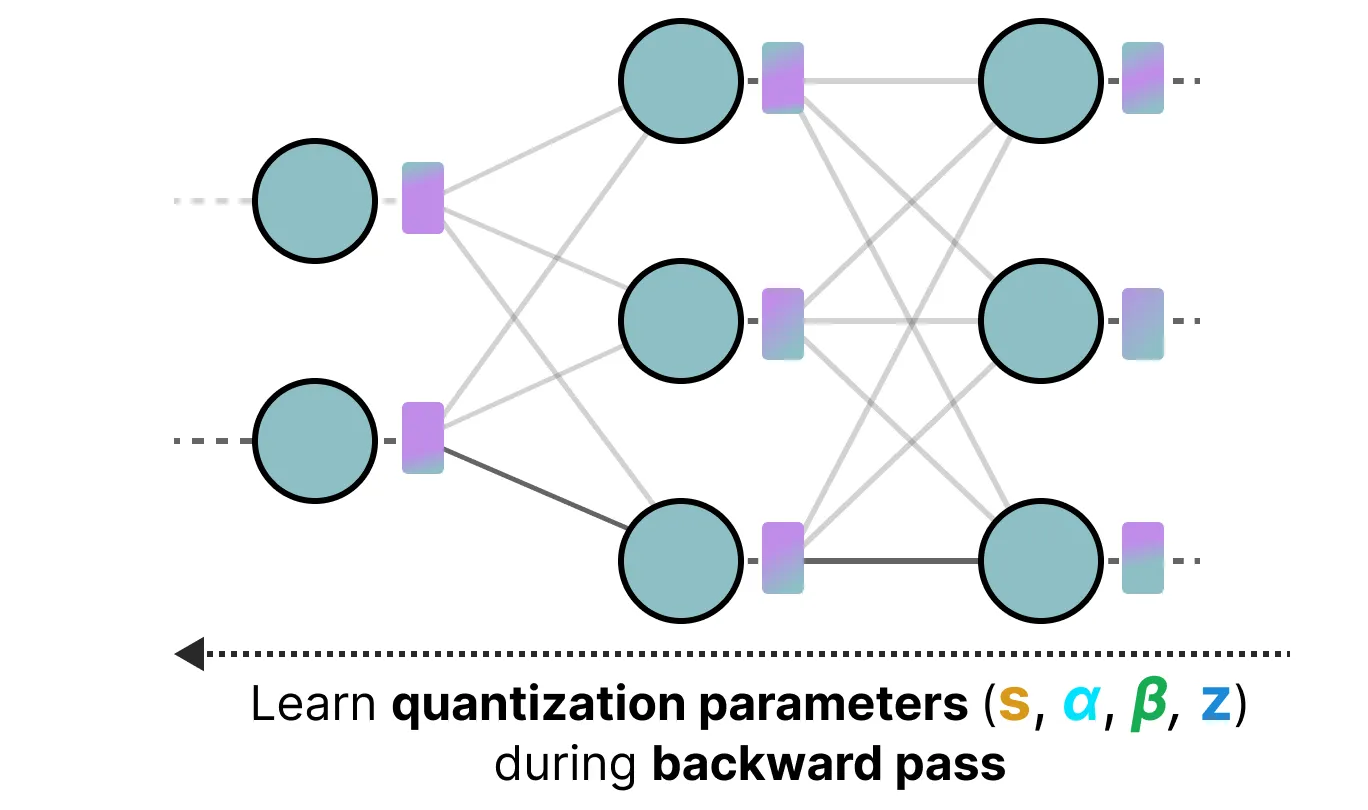
QAT 往往比 PTQ 更准确, 因为在训练期间已经考虑了量化。它的工作原理如下:
在培训期间, 引入了所谓的“假”量化。这是首先将权重量化为 INT4, 然后再反量化回 FP32 的过程:

此过程允许模型在训练期间考虑量化过程、损失的计算和权重更新。
QAT试图探索“宽”最小值的损失情况, 以最小化量化误差, 因为“窄”最小值往往会导致更大的量化误差。
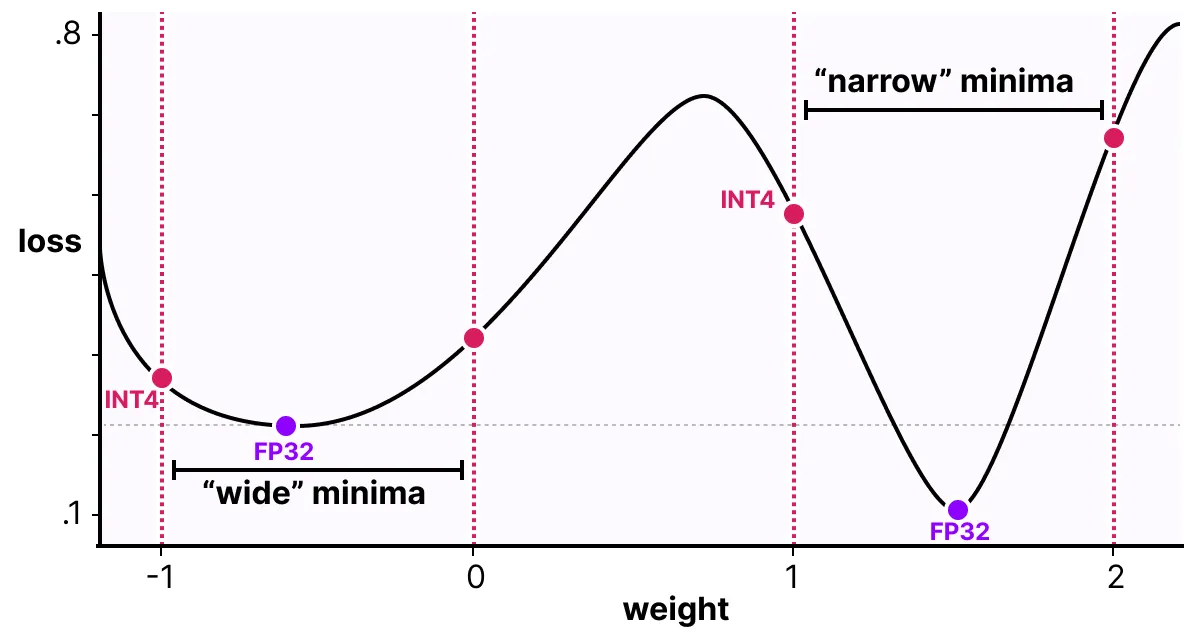
例如, 想象一下, 如果我们在后向传递过程中不考虑量化。我们根据梯度下降选择损失最小的重量。但是, 如果它处于“窄”最小值中, 则会引入更大的量化误差。
相反, 如果我们考虑量化, 将在“宽”最小值中选择不同的更新权重, 并且量化误差要低得多。
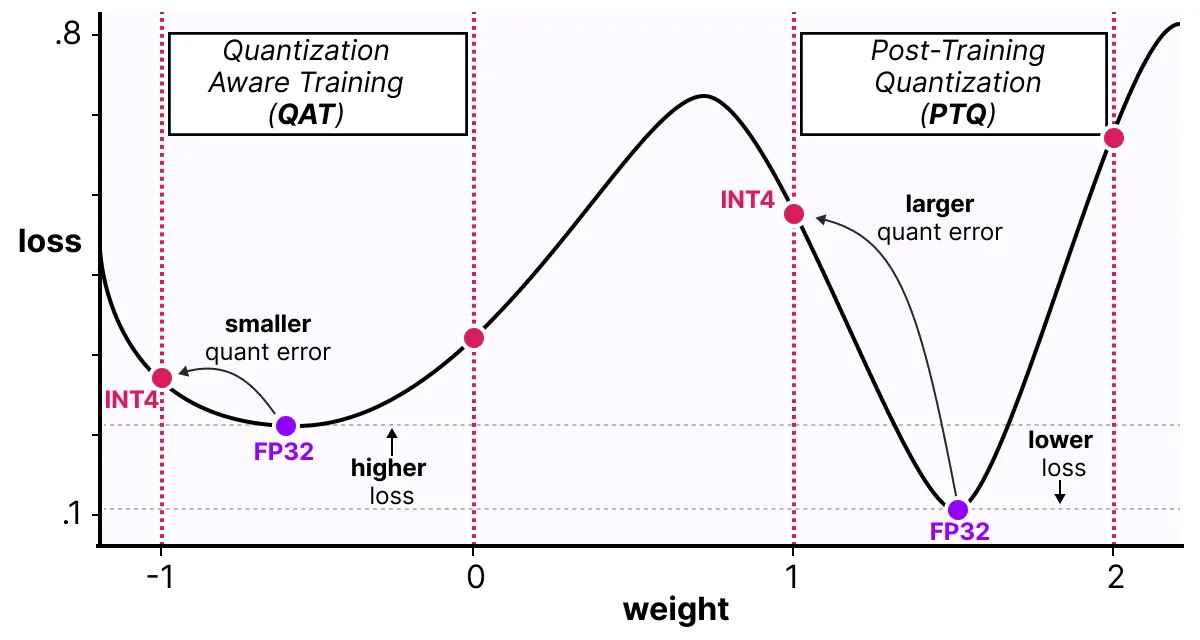
因此, 尽管PTQ在高精度(例如FP32)下具有较低的损耗, 但QAT在较低精度(例如INT4)下导致的损耗较低, 这正是我们的目标。
3.1 1位 LLM 时代: BitNet
它表示模型单个 1 位的权重, 使用 -1 或 1 表示给定的权重。它通过将量化过程直接注入到 Transformer 架构中来实现这一点。Transformer 架构被用作大多数 LLM 的基础, 它由涉及线性层的计算组成:
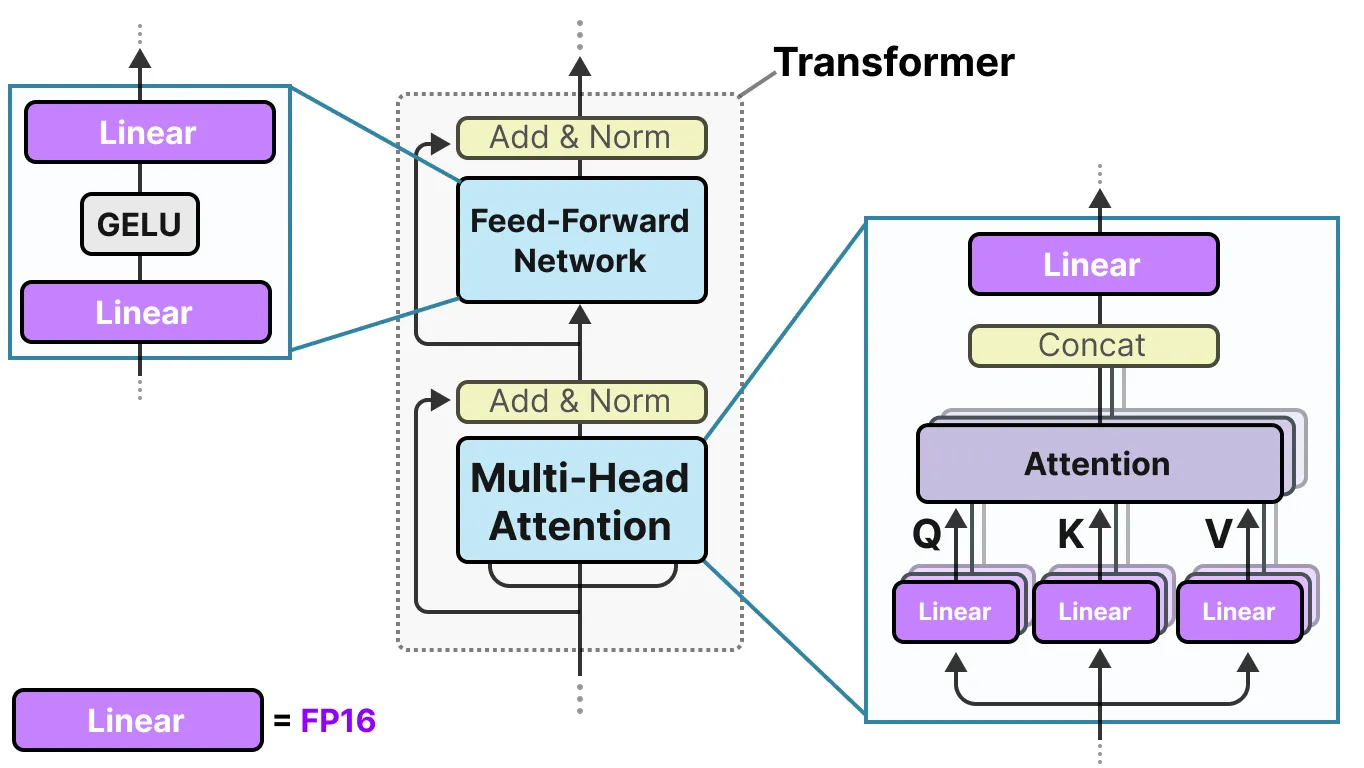
这些线性层通常以更高的精度表示, 如 FP16, 并且是大多数权重所在的位置。BitNet 用他们称之为 BitLlinear 的东西替换了这些线性层:
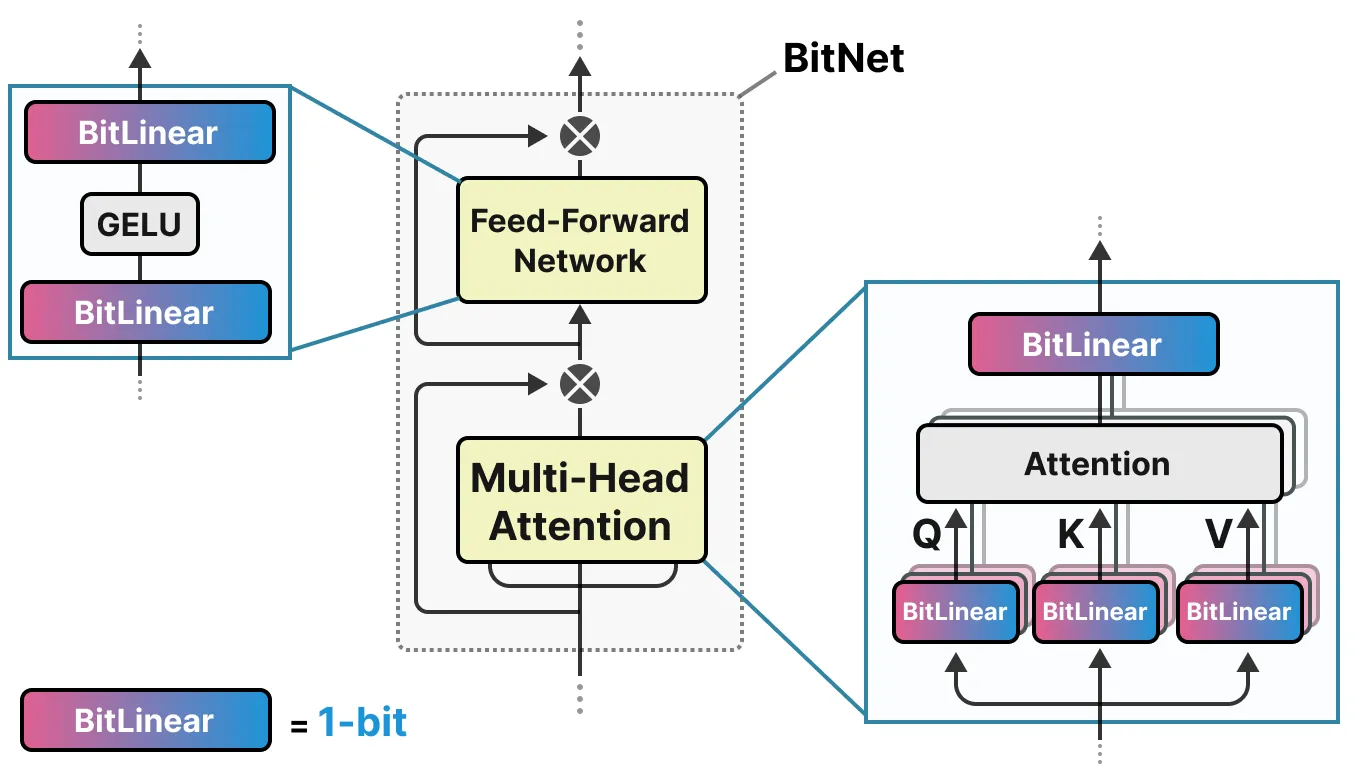
BitLinear层的工作方式与常规线性层相同, 并根据权重乘以激活来计算输出。相比之下, BitLinear 层使用 1 位表示模型的权重, 并使用 INT8 表示激活:
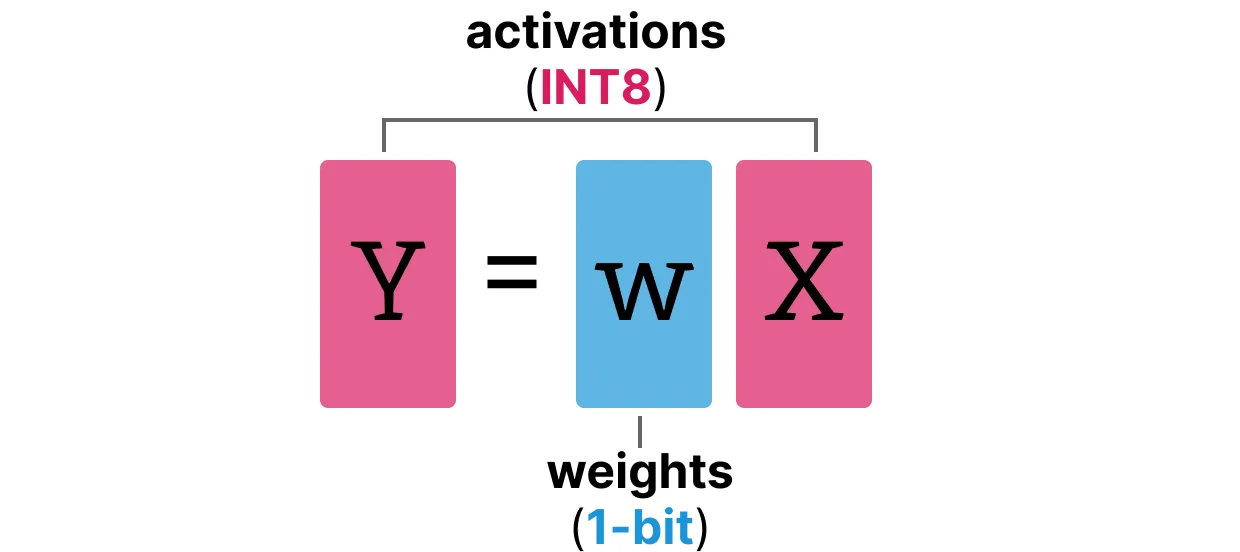
BitLinear层(如量化感知训练(QAT))在训练期间执行一种形式的“假”量化, 以分析权重和激活量化的效果:
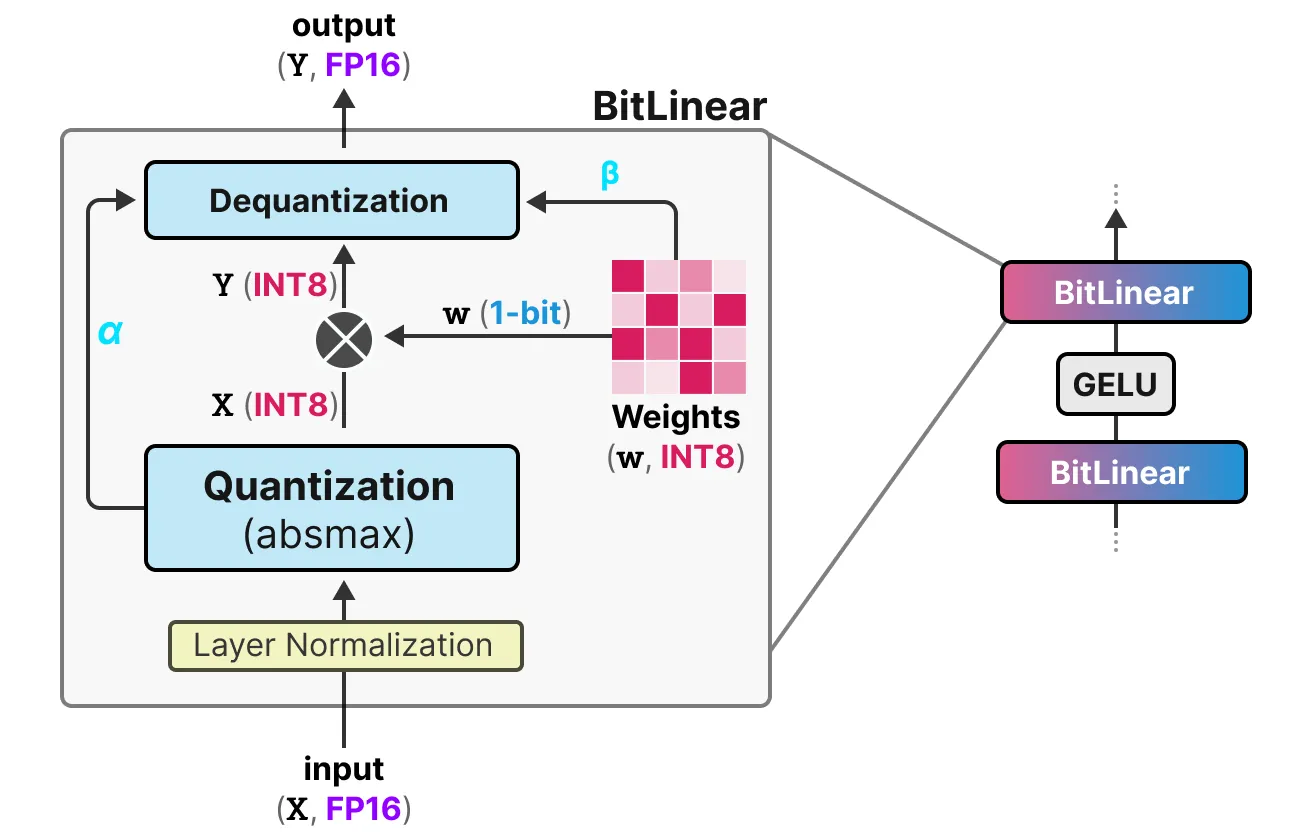
3.1.1 权重量化
在训练时, 权重存储在 INT8 中, 然后使用称为符号函数的基本策略量化为 1 位。
从本质上讲, 它将权重分布以 0 为中心, 然后将左边的所有 0 赋值为 -1, 将右边的所有内容赋为 1:
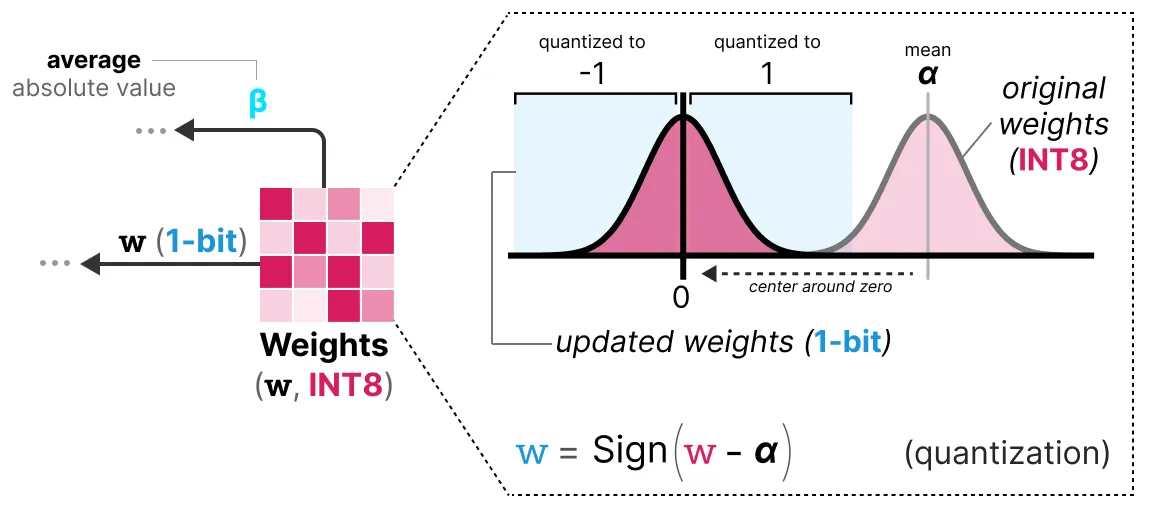
此外, 它还跟踪一个值β(平均绝对值), 我们稍后将使用该值进行反量化。
3.1.2 激活量化
为了量化激活, BitLinear利用absmax量化将激活从FP16转换为INT8, 因为它们需要以更高的精度进行矩阵乘法(x)。
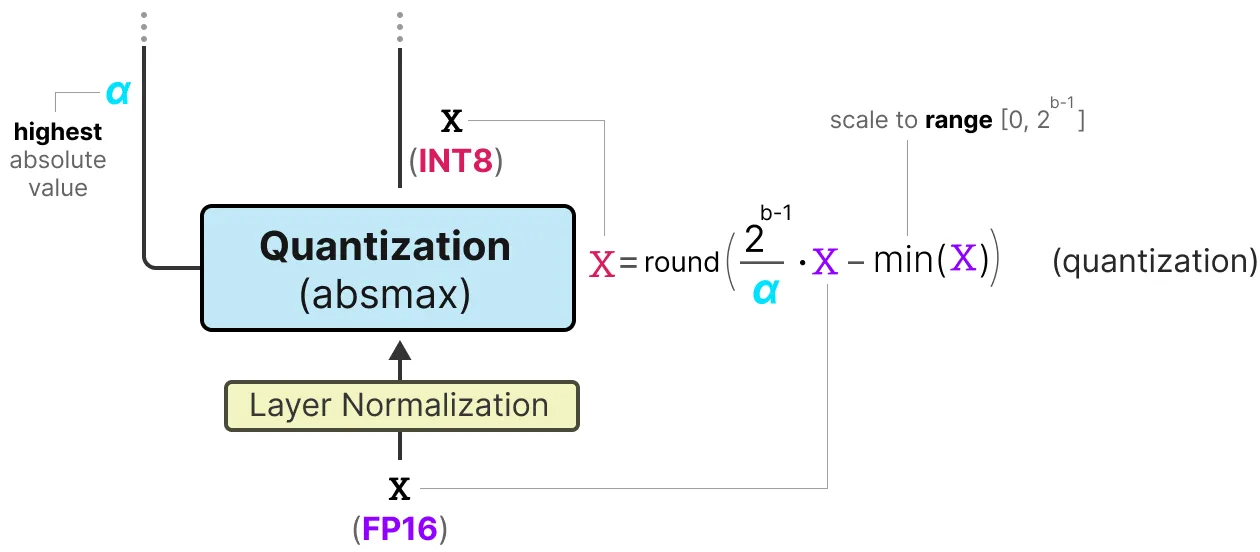
此外, 它还跟踪 我们稍后将用于反量化的α(最高绝对值)。
3.1.3 去量化
我们跟踪了 \(\alpha\)(激活的最高绝对值)和 \(\beta\)(权重的平均绝对值), 因为这些值将帮助我们将激活去量化回 FP16。
输出激活使用 {\(\alpha\), \(\gamma\)} 重新缩放, 以将它们去量化到原始精度:
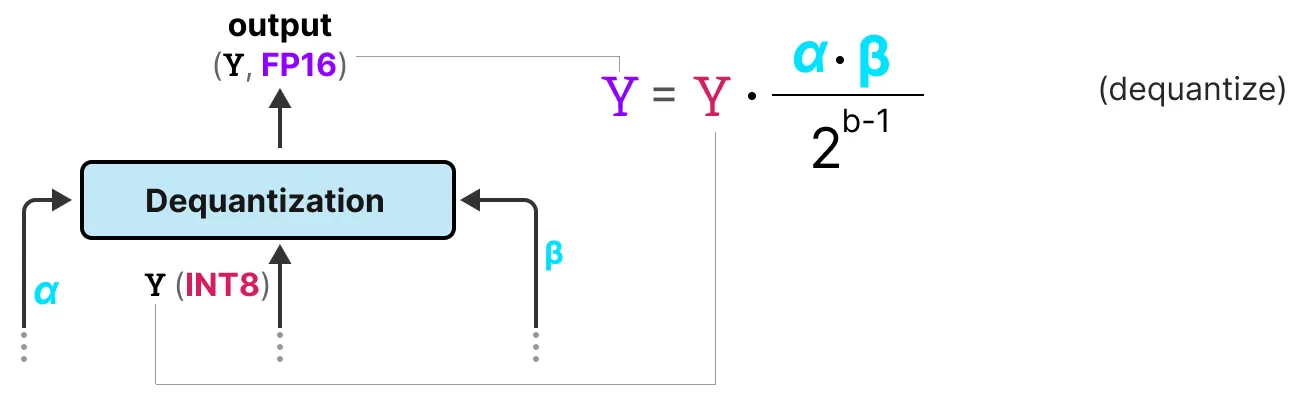
就是这样!此过程相对简单, 允许仅用两个值(-1 或 1)表示模型。
使用此过程, 作者观察到, 随着模型大小的增长, 1 位和 FP16 训练之间的性能差距就越小。
但是, 这仅适用于较大的模型(>30B 参数), 而较小模型的 gab 仍然相当大。
3.2 所有大型语言模型均为 1.58 位
BitNet 1.58b 的引入是为了改进前面提到的缩放问题。在这种新方法中, 模型的每个权重不仅仅是 -1 或 1, 而且现在还可以将 0 作为值, 使其成为三元。有趣的是, 只添加 0 极大地改进了 BitNet, 并允许更快的计算。
3.2.1 0的力量
为什么添加 0 会如此重大的改进呢?它与矩阵乘法有关!
首先, 让我们探讨一下矩阵乘法的一般工作原理。在计算输出时, 我们将权重矩阵乘以输入向量。下面, 可视化了权重矩阵第一层的第一次乘法:

请注意, 此乘法涉及两个操作, 将 单个权重与输入相乘, 然后将它们相加。相比之下, BitNet 1.58b 设法放弃了乘法行为, 因为三元权重基本上告诉您以下内容:
- 1: 我想添加此值
- 0: 我不想要这个值
- -1: 我想减去这个值
因此, 仅当权重量化为 1.58 位时, 才需要执行加法:
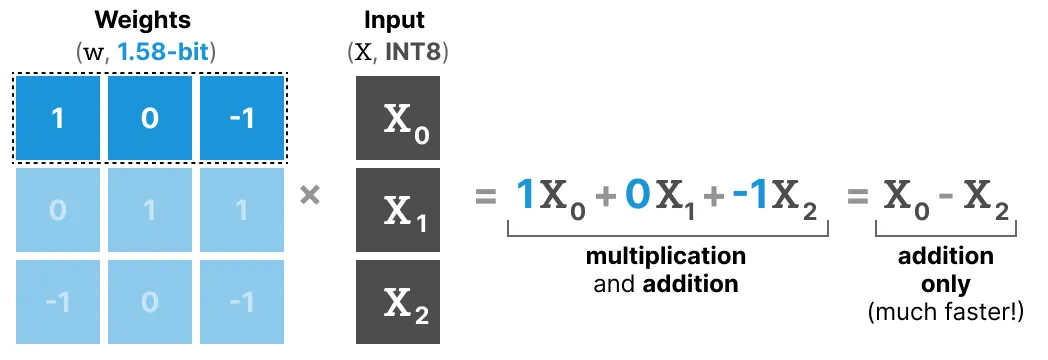
这不仅可以显着加快计算速度, 而且还允许进行特征过滤。通过将给定的权重设置为 0, 您现在可以忽略它, 而不是像 1 位表示那样添加或减去权重。
3.2.2 量化
为了执行权重量化, BitNet 1.58b 使用 absmean 量化, 这是我们之前看到的 absmax 量化的变体。它只是压缩权重的分布, 并使用绝对平均值(α)来量化值。然后, 将它们四舍五入为 -1、0 或 1:
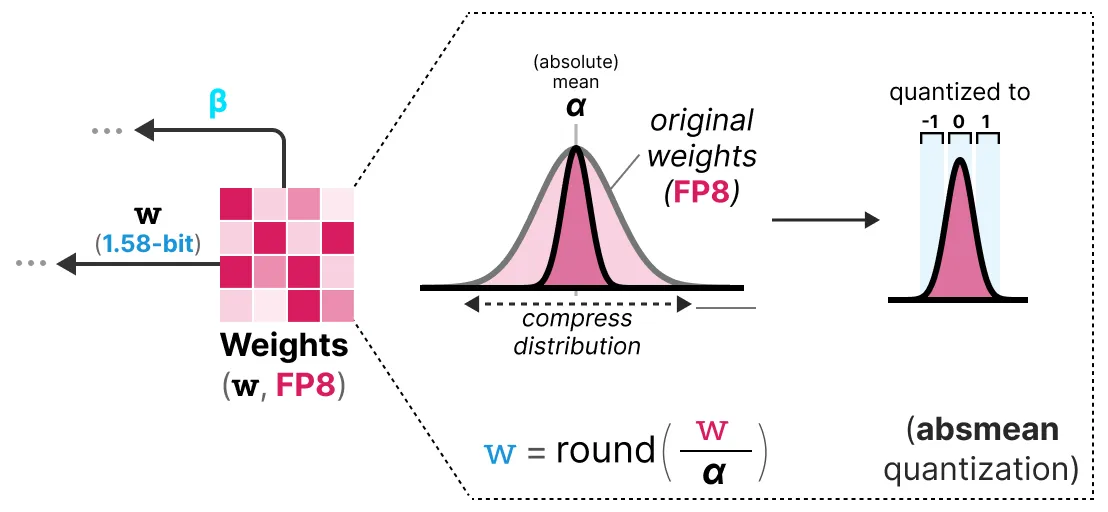
与BitNet相比, 激活量化是相同的, 除了一件事。现在, 它们不再将激活缩放到范围 [0, 2b⁻¹], 而是使用 absmax 量化将其缩放到
[-2b⁻¹, 2b⁻¹]。
就是这样!(大部分)需要 1.58 位量化两个技巧:
- 将 0 相加 以创建三元表示 [-1, 0, 1]
- 权重的 Absmean 量化
参考:
A Visual Guide to Quantization
A minimal Introduction to Quantization
Introduction to Weight Quantization
