
目录
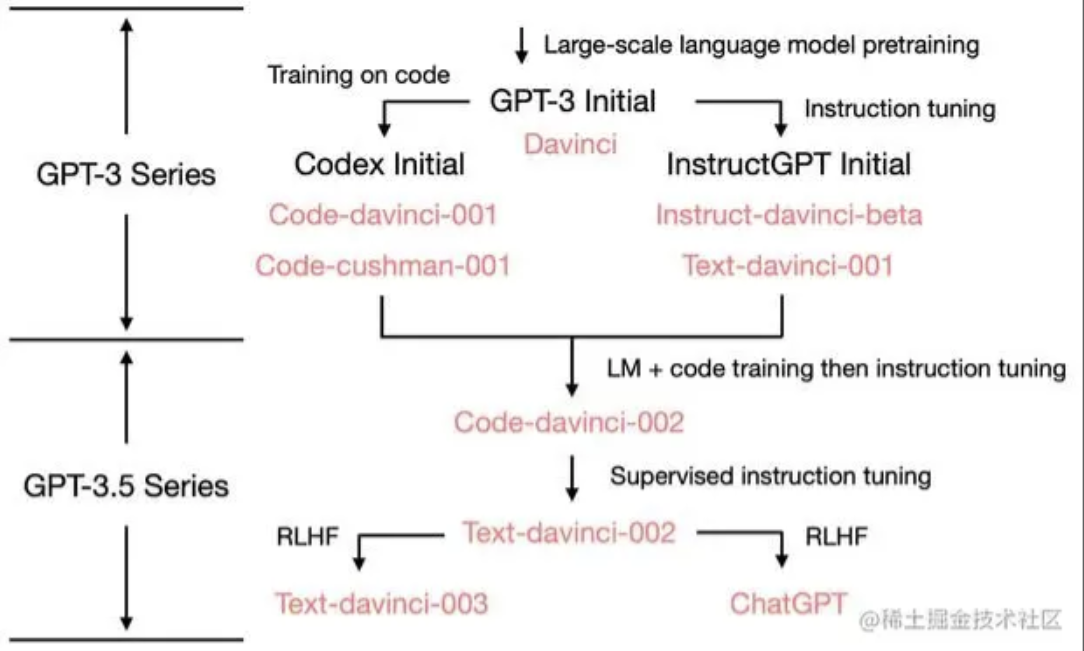
chatGPT 是在经历了多轮迭代之后, 才出现的产物。从最开始的 GPT-1.0, 经历了GPT- 2.0 , GPT-3.0 , GPT-3.5 再到instructGPT、chatGPT. 在官网, 注册账号后, 有 openai python库可以直接使用。 API 调用的 Text-davinci-03, 跟网站模型有些差别。 差别在RLHF
- RL: Reinforcement Learning (强化学习) 强化学习不需要预先给定任何数据, 而是通过接收环境对动作的反馈获得学习信息并更新参数
- RLHF: 以人类反馈进行的强化学习。
OpenAI的语言模型使用了深度神经网络, 并使用了非常大的数据集进行训练, 这导致了模型参数数量的大幅度增加。具体来说, 175亿个参数是指Davinci模型中的参数数量, 该模型使用了一个大型的变压器(transformer)神经网络, 该神经网络由多个Transformer encoder和decoder层组成。每个encoder和decoder层中包含了数百个或数千个神经元, 每个神经元都有若干个权重和一个偏置项, 这些权重和偏置项就是模型的参数。此外, OpenAI还使用了很多技巧来优化模型的训练和表现, 例如动态掩码、学习率调度等, 这些技巧也会导致模型参数数量的增加。
1. 简介
1.1 安装
pip install openai
1.2 模型
OpenAI目前提供了许多语言模型, 包括Ada、Babbage、Curie和Davinci。以下是每个模型的简要介绍:
1.2.1 Ada
Ada是OpenAI推出的最新模型, 它是一种大规模的、多任务的语言模型, 能够执行多种不同的自然语言任务, 如问答、生成、分类等。Ada使用了GPT-3的一部分技术, 并在其上进行了一些改进, 使其具有更好的性能和效率。
base GPT-3, Ada 通常是最快的模型, 可以执行解析文本、地址更正和不需要太多细微差别的某些分类任务等任务。 Ada 的性能通常可以通过提供更多上下文来提高。
1.2.2 Babbage
Babbage是OpenAI推出的一种中型语言模型, 它由6亿个参数组成, 可用于生成文本、回答问题和分类任务等。相比较于Ada、Curie和Davinci, Babbage的规模更小, 因此通常可以更快地生成结果。
Babbage 可以执行简单的任务, 例如简单的分类。 在语义搜索方面, 它也非常有能力对文档与搜索查询的匹配程度进行排名。
1.2.3 Curie
Curie是OpenAI推出的一种中大型语言模型, 它由13亿个参数组成, 可以用于自然语言生成、回答问题和文本分类等任务。相比Babbage, Curie在多任务学习和文本生成等方面表现更好, 同时具有更高的性能和精度。
curie非常强大, 但速度非常快。 虽然 Davinci 在分析复杂文本方面更强大, 但 Curie 能够胜任许多细微的任务, 例如情感分类和摘要。 Curie 还非常擅长回答问题和执行问答以及作为通用服务聊天机器人。
1.2.4 Davinci
Davinci是OpenAI推出的最大型的语言模型, 它由175亿个参数组成, 是目前最先进、最强大的语言模型之一。Davinci能够执行多种自然语言任务, 如问答、生成、摘要等, 并且在这些任务中表现出色。
Davinci 是最有能力的模型系列, 可以执行其他模型可以执行的任何任务, 而且通常只需要很少的指令。 对于需要对内容有大量理解的应用程序, 例如针对特定受众的摘要和创意内容生成, Davinci 将产生最佳结果。 这些增加的功能需要更多的计算资源, 因此 Davinci 每次 API 调用的成本更高, 并且不如其他模型快。
Davinci 的另一个亮点是理解文本的意图。 达芬奇擅长解决多种逻辑问题和解释人物的动机。 达芬奇已经能够解决一些涉及因果关系的最具挑战性的人工智能问题。
需要注意的是, 不同模型的功能和性能存在差异, 并且模型的复杂程度和处理速度也不同。选择适当的模型取决于应用场景和具体需求。
在深度学习中, 参数通常是指神经网络中可调整的权重和偏置项。神经网络中有很多层, 每一层都有很多个神经元, 每个神经元都有若干个权重和一个偏置项, 这些权重和偏置项就是参数。一个神经网络的参数数量取决于神经元的数量和层数。
1.3 模型API分类
打开OpenAI官网API介绍页面, 可以发现涉及到的语言模型API主要有Completion、Chat、Edit、Embedding、Finetunes。由于Embedding和Finetunes跟直接的应用关系较少, 在此主要介绍下Completion、Chat、Edit这三个功能。
1.3.1 Completion
看名字就能看出来, completion主要是解决补全问题的。具体来说, 就是用户输入一段提示文字, 模型按照文字的提示, 给出对应的输出。换言之, 可以理解为诱导型的对话。
1.3.2 Chat
这类API生来为处理聊天任务。与Completion类API相比, Chat类API在接口上显示定义了system、user和assistant:
- system可以理解为聊天的语境, 可有可无
- user和assistant可以理解为聊天的两个角色
1.3.3 Edit
Edit类API处理的场景是修改输入的问题。用户输入一段待修改的文字(input)和一段修改的引导语(instruct), 模型给出按照引导与修改的文字。
通过API的分类可以看出, Chat和Completion类API其实差别不大, 通过不同的prompt可以达到相似的效果。只是Chat为对话显示定义了三个新角色: system、user、assistant。同时为了达到多轮对话的目的, 用户需要自行维护上下文。当上下文token数量超过了目前API可处理的最大数量时, 用户应该递归的总结、截断上下文。
另外还有一点, Chat类API暂未提供finetune的功能, 而Completion类API提供了对应的finetune方法。
https://api.openai.com/v1/models
https://api.openai.com/v1/models/{模型}
https://api.openai.com/v1/completions
https://api.openai.com/v1/chat/completions
https://api.openai.com/v1/edits
https://api.openai.com/v1/images/generations
https://api.openai.com/v1/images/edits
https://api.openai.com/v1/images/variations
https://api.openai.com/v1/embeddings
https://api.openai.com/v1/audio/transcriptions
https://api.openai.com/v1/audio/translations
https://api.openai.com/v1/files
https://api.openai.com/v1/files/{file_id}
1.3.4 Embedding
# input string or array
curl https://api.openai.com/v1/embeddings \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"input": "The food was delicious and the waiter...",
"model": "text-embedding-ada-002",
"encoding_format": "float"
}'
{
"object": "list",
"data": [
{
"object": "embedding",
"embedding": [
0.0023064255,
-0.009327292,
.... (1536 floats total for ada-002)
-0.0028842222,
],
"index": 0
}
],
"model": "text-embedding-ada-002",
"usage": {
"prompt_tokens": 8,
"total_tokens": 8
}
}
1.4 模型参数的选取
对于模型来说, 控制模型输出的结果有很多, 最主要的就是temperature和top_p。需要注意的是这两个参数一般不同时调整。
可以这样简单的理解, 这两个参数都是调整模型输出多样性的。temperature的取值范围为02, 取值越大, 模型的输出结果越多样。top_p的取值范围为01, 含义是核采样系数, 具体来说, 就是生成结果时token采样考虑的范围。
2. 写好 Prompt
2.1 设计原则
- 清晰, 切忌复杂或歧义, 如果有术语, 应定义清楚。
- 具体, 描述语言应尽量具体, 不要抽象活模棱两可。
- 聚焦, 问题避免太泛或开放。
- 简洁, 避免不必要的描述。
- 相关, 主要指主题相关, 而且是整个对话期间, 不要东一瓢西一瓤。
2.2 编写良好prompt的四种基础模式
2.2.1 By example(示例模式)
在这种模式下, 我们给模型提供一些示例文本, 模型需要生成与示例文本类似的文本。这种模式通常用于生成类似于给定示例的文本, 例如自动生成电子邮件、产品描述、新闻报道等。示例文本可以是单个句子或多个段落, 具体取决于任务的要求。示例中有什么格式或规律, 让AI自己发现。
2.2.2 By instruction template(指令模板)
在这种模式下, 我们给模型提供一些明确的指令, 模型需要根据这些指令生成文本。这种模式通常用于生成类似于技术说明书、操作手册等需要明确指令的文本。指令可以是单个句子或多个段落, 具体取决于任务的要求。在给出prompt的时候, 同时给出指令模板, 约束输入和输出的互动格式。
2.2.3 By specific (特定指令)
在这种模式下, 我们给模型提供一些特定信息, 例如问题或关键词, 模型需要生成与这些信息相关的文本。
这种模式通常用于生成答案、解释或推荐等。特定信息可以是单个问题或多个关键词, 具体取决于任务的要求。这些问题或关键词一定是AI可以理解和接受的, 是预置的已经存在的。
2.2.4 By proxy(代理模式)
在这种模式下, 可以充当了一个代理, 代表某个实体(例如人、角色、机器人等)进行操作或交互。
代理模式的核心思想是引入一个中介对象来控制对实际对象的访问, 从而实现一定程度上的隔离和保护。诸如于在 ChatGPT 中, “act as xxx” 可以让 ChatGPT 充当一个代理, 扮演某个角色或实体的身份, 以此来处理与该角色或实体相关的任务或请求。
2.3 编写一个合格的prompt的要点
2.3.1 让AI扮演角色
你想让它扮演一个什么样的角色, 它便站在这样的角色的立场思考。
2.3.2 提供要执行的任务
可以查到已经支持的任务有: 文本分类、实体标注、信息抽取、翻译、生成、摘要提取、阅读理解、推理、问答、纠错、关键词提取、相似度计算。
这些单词在Prompt中都可以光明正大地出现, 它们都有人使用过, ChatGPT都会理解得很好。
它有十大类基本能力:
- 文本生成: ChatGPT 可以生成各种格式的文本, 例如写故事、写新闻文章或诗歌、写代码等。
- 自动摘要: ChatGPT 可以将一段很长的文本摘要成一个较短的版本。
- 自然语言理解 (NLU): ChatGPT 可以理解文本的含义, 可用于情感分析、命名实体识别和文本分类等任务。
- 语言翻译: ChatGPT 可以针对语言翻译任务进行微调, 将文本从一种语言翻译成另一种语言。
- 对话生成: ChatGPT 可以生成类似人类的对话, 使其适用于聊天机器人和虚拟助手应用程序。
- 文本转语音: ChatGPT 可以针对文本转语音任务进行微调, 将文本转换为口语。
- 图像字幕: ChatGPT 可以针对图像字幕任务进行微调, 它可以为图像和视频生成字幕。
- 阅读理解: ChatGPT 可以针对阅读理解任务进行微调, 它可以根据给定的文本回答问题。
- 问答: ChatGPT 可以根据给定的上下文或知识库回答问题。
- 文本补全: ChatGPT 可以根据给定的上下文或提示来完成给定的文本。
2.3.3 给出完成任务的步骤
步骤是一个大于1的待办事项, 且有先后依赖关系和前后次序。
2.3.4 围绕任务提供上下文
描述上下文是为了让AI更加清晰地理解我们的意图, 是代替多次互动效果的。
2.3.5 陈述具体目标, 给出具体要求
对于多项要求, 也可以使用任务的输入格式。不仅输出格式可以指定, 输入格式也可以预先告知AI, 方便AI理解。
2.3.6 要求格式化输出
2.3.7 明确指定语言风格
2.3.8 让AI站在角色的角度
2.3.9 马上给出具体的样例
df_nert = {
'chinese': ['组织机构', '地点', '人物'],
'english': ['PER', 'LOC', 'ORG', 'MISC'],
}
df_eet = {
'chinese': {'灾害/意外-坠机': ['时间', '地点', '死亡人数', '受伤人数'], '司法行为-举报': ['时间', '举报发起方', '举报对象'], '财经/交易-涨价': ['时间', '涨价幅度', '涨价物', '涨价方'], '组织关系-解雇': ['时间', '解雇方', '被解雇人员'], '组织关系-停职': ['时间', '所属组织', '停职人员'], '财经/交易-加息': ['时间', '加息幅度', '加息机构'], '交往-探班': ['时间', '探班主体', '探班对象'], '人生-怀孕': ['时间', '怀孕者'], '组织关系-辞/离职': ['时间', '离职者', '原所属组织'], '组织关系-裁员': ['时间', '裁员方', '裁员人数'], '灾害/意外-车祸': ['时间', '地点', '死亡人数', '受伤人数'],
'人生-离婚': ['时间', '离婚双方'], '司法行为-起诉': ['时间', '被告', '原告'], '竞赛行为-禁赛': ['时间', '禁赛时长', '被禁赛人员', '禁赛机构'], '人生-婚礼': ['时间', '地点', '参礼人员', '结婚双方'], '财经/交易-涨停': ['时间', '涨停股票'], '财经/交易-上市': ['时间', '地点', '上市企业', '融资金额'], '组织关系-解散': ['时间', '解散方'], '财经/交易-跌停': ['时间', '跌停股票'], '财经/交易-降价': ['时间', '降价方', '降价物', '降价幅度'], '组织行为-罢工': ['时间', '所属组织', '罢工人数', '罢工人员'], '司法行为-开庭': ['时间', '开庭法院', '开庭案件'],
'竞赛行为-退役': ['时间', '退役者'], '人生-求婚': ['时间', '求婚者', '求婚对象'], '人生-庆生': ['时间', '生日方', '生日方年龄', '庆祝方'], '交往-会见': ['时间', '地点', '会见主体', '会见对象'], '竞赛行为-退赛': ['时间', '退赛赛事', '退赛方'], '交往-道歉': ['时间', '道歉对象', '道歉者'], '司法行为-入狱': ['时间', '入狱者', '刑期'], '组织关系-加盟': ['时间', '加盟者', '所加盟组织'], '人生-分手': ['时间', '分手双方'], '灾害/意外-袭击': ['时间', '地点', '袭击对象', '死亡人数', '袭击者', '受伤人数'], '灾害/意外-坍/垮塌': ['时间', '坍塌主体', '死亡人数', '受伤人数'],
'组织关系-解约': ['时间', '被解约方', '解约方'], '产品行为-下架': ['时间', '下架产品', '被下架方', '下架方'], '灾害/意外-起火': ['时间', '地点', '死亡人数', '受伤人数'], '灾害/意外-爆炸': ['时间', '地点', '死亡人数', '受伤人数'], '产品行为-上映': ['时间', '上映方', '上映影视'], '人生-订婚': ['时间', '订婚主体'], '组织关系-退出': ['时间', '退出方', '原所属组织'], '交往-点赞': ['时间', '点赞方', '点赞对象'], '产品行为-发布': ['时间', '发布产品', '发布方'], '人生-结婚': ['时间', '结婚双方'], '组织行为-闭幕': ['时间', '地点', '活动名称'],
'人生-死亡': ['时间', '地点', '死者年龄', '死者'], '竞赛行为-夺冠': ['时间', '冠军', '夺冠赛事'], '人生-失联': ['时间', '地点', '失联者'], '财经/交易-出售/收购': ['时间', '出售方', '交易物', '出售价格', '收购方'], '竞赛行为-晋级': ['时间', '晋级方', '晋级赛事'], '竞赛行为-胜负': ['时间', '败者', '胜者', '赛事名称'], '财经/交易-降息': ['时间', '降息幅度', '降息机构'], '组织行为-开幕': ['时间', '地点', '活动名称'], '司法行为-拘捕': ['时间', '拘捕者', '被拘捕者'], '交往-感谢': ['时间', '致谢人', '被感谢人'], '司法行为-约谈': ['时间', '约谈对象', '约谈发起方'],
'灾害/意外-地震': ['时间', '死亡人数', '震级', '震源深度', '震中', '受伤人数'], '人生-产子/女': ['时间', '产子者', '出生者'], '财经/交易-融资': ['时间', '跟投方', '领投方', '融资轮次', '融资金额', '融资方'], '司法行为-罚款': ['时间', '罚款对象', '执法机构', '罚款金额'], '人生-出轨': ['时间', '出轨方', '出轨对象'], '灾害/意外-洪灾': ['时间', '地点', '死亡人数', '受伤人数'], '组织行为-游行': ['时间', '地点', '游行组织', '游行人数'], '司法行为-立案': ['时间', '立案机构', '立案对象'], '产品行为-获奖': ['时间', '获奖人', '奖项', '颁奖机构'], '产品行为-召回': ['时间', '召回内容', '召回方']},
'english': {'Justice:Appeal': ['Defendant', 'Adjudicator', 'Crime', 'Time', 'Place'], 'Justice:Extradite': ['Agent', 'Person', 'Destination', 'Origin', 'Crime', 'Time'], 'Justice:Acquit': ['Defendant', 'Adjudicator', 'Crime', 'Time', 'Place'], 'Life:Be-Born': ['Person', 'Time', 'Place'], 'Life:Divorce': ['Person', 'Time', 'Place'], 'Personnel:Nominate': ['Person', 'Agent', 'Position', 'Time', 'Place'], 'Life:Marry': ['Person', 'Time', 'Place'], 'Personnel:End-Position': ['Person', 'Entity', 'Position', 'Time', 'Place'],
'Justice:Pardon': ['Defendant', 'Prosecutor', 'Adjudicator', 'Crime', 'Time', 'Place'], 'Business:Merge-Org': ['Org', 'Time', 'Place'], 'Conflict:Attack': ['Attacker', 'Target', 'Instrument', 'Time', 'Place'], 'Justice:Charge-Indict': ['Defendant', 'Prosecutor', 'Adjudicator', 'Crime', 'Time', 'Place'], 'Personnel:Start-Position': ['Person', 'Entity', 'Position', 'Time', 'Place'], 'Business:Start-Org': ['Agent', 'Org', 'Time', 'Place'], 'Business:End-Org': ['Org', 'Time', 'Place'],
'Life:Injure': ['Agent', 'Victim', 'Instrument', 'Time', 'Place'], 'Justice:Fine': ['Entity', 'Adjudicator', 'Money', 'Crime', 'Time', 'Place'], 'Justice:Sentence': ['Defendant', 'Adjudicator', 'Crime', 'Sentence', 'Time', 'Place'], 'Transaction:Transfer-Money': ['Giver', 'Recipient', 'Beneficiary', 'Money', 'Time', 'Place'], 'Justice:Execute': ['Person', 'Agent', 'Crime', 'Time', 'Place'], 'Justice:Sue': ['Plaintiff', 'Defendant', 'Adjudicator', 'Crime', 'Time', 'Place'],
'Justice:Arrest-Jail': ['Person', 'Agent', 'Crime', 'Time', 'Place'], 'Justice:Trial-Hearing': ['Defendant', 'Prosecutor', 'Adjudicator', 'Crime', 'Time', 'Place'], 'Movement:Transport': ['Agent', 'Artifact', 'Vehicle', 'Price', 'Origin'], 'Contact:Meet': ['Entity', 'Time', 'Place'], 'Personnel:Elect': ['Person', 'Entity', 'Position', 'Time', 'Place'], 'Business:Declare-Bankruptcy': ['Org', 'Time', 'Place'], 'Transaction:Transfer-Ownership': ['Buyer', 'Seller', 'Beneficiary', 'Artifact', 'Price', 'Time', 'Place'],
'Justice:Release-Parole': ['Person', 'Entity', 'Crime', 'Time', 'Place'], 'Conflict:Demonstrate': ['Entity', 'Time', 'Place'], 'Contact:Phone-Write': ['Entity', 'Time'], 'Justice:Convict': ['Defendant', 'Adjudicator', 'Crime', 'Time', 'Place'], 'Life:Die': ['Agent', 'Victim', 'Instrument', 'Time', 'Place']},
}
re_s1_p = {
'chinese': '''给定的句子为: "{}"\n\n给定关系列表: {}\n\n在这个句子中, 可能包含了哪些关系?\n请给出关系列表中的关系。\n如果不存在则回答: 无\n按照元组形式回复, 如 (关系1, 关系2, ……): ''',
'english': '''The given sentence is "{}"\n\nList of given relations: {}\n\nWhat relations in the given list might be included in this given sentence?\nIf not present, answer: none.\nRespond as a tuple, e.g. (relation 1, relation 2, ......):''',
}
re_s2_p = {
'chinese': '''根据给定的句子, 两个实体的类型分别为({}, {})且之间的关系为{}, 请找出这两个实体, 如果有多组, 则按组全部列出。\n如果不存在则回答: 无\n按照表格形式回复, 表格有两列且表头为({}, {}): ''',
'english': '''According to the given sentence, the two entities are of type ('{}', '{}') and the relation between them is '{}', find the two entities and list them all by group if there are multiple groups.\nIf not present, answer: none.\nRespond in the form of a table with two columns and a header of ('{}', '{}'):''',
}
# -------------
ner_s1_p = {
'chinese': '''给定的句子为: "{}"\n\n给定实体类型列表: {}\n\n在这个句子中, 可能包含了哪些实体类型?\n如果不存在则回答: 无\n按照元组形式回复, 如 (实体类型1, 实体类型2, ……): ''',
'english': '''The given sentence is "{}"\n\nGiven a list of entity types: {}\n\nWhat entity types may be included in this sentence?\nIf not present, answer: none.\nRespond as a list, e.g. [entity type 1, entity type 2, ......]:'''
}
ner_s2_p = {
'chinese': '''根据给定的句子, 请识别出其中类型是"{}"的实体。\n如果不存在则回答: 无\n按照表格形式回复, 表格有两列且表头为(实体类型, 实体名称): ''',
'english': '''According to the given sentence, please identify the entity whose type is "{}".\nIf not present, answer: none.\nRespond in the form of a table with two columns and a header of (entity type, entity name):'''
}
# --------------------
ee_s1_p = {
'chinese': '''给定的句子为: "{}"\n\n给定事件类型列表: {}\n\n在这个句子中, 可能包含了哪些事件类型?\n请给出事件类型列表中的事件类型。\n如果不存在则回答: 无\n按照元组形式回复, 如 (事件类型1, 事件类型2, ……): ''',
'english': '''The given sentence is "{}"\n\nGiven a list of event types: {}\n\nWhat event types in the given list might be included in this given sentence?\nIf not present, answer: none.\nRespond as a tuple, e.g. (event type 1, event type 2, ......):'''
}
ee_s2_p = {
'chinese': '''事件类型"{}"对应的论元角色列表为: {}。\n在给定的句子中, 根据论元角色提取出事件论元。\n如果论元角色没有相应的论元内容, 则论元内容回答: 无\n按照表格形式回复, 表格有两列且表头为(论元角色, 论元内容): ''',
'english': '''The list of argument roles corresponding to event type "{}" is: {}.\nIn the given sentence, extract event arguments according to their role.\nIf the argument role does not have a corresponding argument content, then the argument content answer: None\nRespond in the form of a table with two columns and a header of (argument role, argument content):'''
}
"Some text is provided below. Given the text, extract up to "
"{max_knowledge_triplets} "
"knowledge triplets in the form of (subject, predicate, object). Avoid stopwords.\n"
"---------------------\n"
"Example:"
"Text: Alice is Bob's mother."
"Triplets:\n(Alice, is mother of, Bob)\n"
"Text: Philz is a coffee shop founded in Berkeley in 1982.\n"
"Triplets:\n"
"(Philz, is, coffee shop)\n"
"(Philz, founded in, Berkeley)\n"
"(Philz, founded in, 1982)\n"
"---------------------\n"
"Text: {text}\n"
"Triplets:\n"
3. LLM
- ChatGPT: 全能
- Midjourney: 超强绘画
- Notion: 笔记
- D-ID: 让图片说话
- Tome: 做PPT
- wordtune: 写作
- Voicemod: 音乐
- AutoDraw: 设计
- DeepSpeed-chat
- Claude
- MiniGPT-4
- Vicuna
https://github.com/tomasonjo/blogs/blob/master/ie_pipeline/SpaCy_informationextraction.ipynb
参考:
langchain
使用GPT-3训练一个垃圾短信分类器
ChatGPT: 如何写好 Prompt?
ChatGPT Online
Azure OpenAI 服务定价
Extract knowledge from text
