
目录
PyTorch 是一个基于 Torch 框架的 Python 语言机器学习开源库。Torch 是一个历史悠久的机器学习算法库, 主要支持 Lua 接口语言。PyTorch 同时也提供了变量, 我们在构建神经网络的时候, 在张量之上的封装, 构建自己的计算图, 并自动计算梯度。PyTorch 建立的是动态图, TensorFlow建立的是静态图。PyTorch 更加符合一般的编程习惯, 而不是像 TensorFlow那样需要先定义计算图。
常用的深度学习开源平台有 TensorFlow、Theano、Keras、Caffe 等。
1. 入门
PyTorch 支持动态图的创建。现在的深度学习平台在定义模型的时候主要用两种方式: 静态图模型(Static computation graph)和动态图模型(Dynamic computation graph)。动态图模型作为 NumPy 的替代者, 使用强大的 GPU, 支持 GPU 的 Tensor 库, 可以极大地加速计算。
1.1 安装
1.1.1 官方获取
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu124 -i https://mirrors.aliyun.com/pypi/simple
pip install --force-reinstall torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124 -i https://mirrors.aliyun.com/pypi/simple
pip install --force-reinstall torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
pip install torch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 --index-url https://download.pytorch.org/whl/cu124
1.1.2 手动下载
pytorch的cpu的包可以在国内镜像上下载, 但是gpu版的包只能通过国外镜像下载, 基本都是手动从先将gpu版whl包下载下来, 然后再手动安装。
pip install torch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 -f https://mirrors.aliyun.com/pytorch-wheels/cu124
pip install ninja
# pip install flash-attn --no-build-isolation
# https://github.com/kingbri1/flash-attention/releases
pip install torchvision-0.19.0+cu124-cp311-cp311-win_amd64.whl
python -c "import flash_attn;print(flash_attn.__version__)"
# https://hf-mirror.com/madbuda/triton-windows-builds
import torch
torch.cuda.is_available()
torch.cuda.get_device_capability()
python -c "import torch;print(torch.__version__);print(torch.cuda.is_available());print(torch.cuda.get_device_capability(0))"
1.2 GPU版的安装与问题解决流程
graph TD
A[开始] --> B[确认GPU型号与CUDA支持]
B --> C[安装NVIDIA驱动]
C --> D[安装CUDA Toolkit与cuDNN]
D --> E[选择适配PyTorch版本]
E --> F[安装PyTorch GPU版本]
F --> G验证{"torch.cuda.is_available()"}
G -- True --> H[安装成功]
G -- False --> I[问题排查]
I --> J[升级驱动/更换版本]
J --> K[重新安装]
1.2.1 相关的一些资源链接
ldd --version
nvidia-smi --query-gpu=compute_cap --format=csv
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0
pip install torch==2.7.0 torchvision==0.22.0 torchaudio==2.7.0 --index-url https://download.pytorch.org/whl/cu126
docker pull nvidia/cuda:12.4.0-devel-ubuntu22.04
1.3 基础组件
1.3.1 张量与变量
1.3.1.1 张量
张量是 PyTorch 的一个完美组件, 和 NumPy 类似。将张量从 NumPy转换至 PyTorch 非常容易。可以把它作为 NumPy 的替代品。在数学里, 张量是一种几何实体, 或者说广义上的"数量"。张量概念包括标量、向量和线性算子。张量可以用坐标系统来表达, 记作标量的数组。
在 PyTorch 中, Tensor 代表多维数组, pytorch 中的数据都是封装成 Tensor 来引用的, Tensor实际上就类似于TensorFlow中的 matrix 或ndarrays、numpy 中的数组, 两者可以自由转换。
import torch
z = torch.Tensor(4, 5)
print(z)
# Output
# tensor([[0., 0., 0., 0., 0.],
# [0., 0., 0., 0., 0.],
# [0., 0., 0., 0., 0.],
# [0., 0., 0., 0., 0.]])
print(z.dtype, z.size())
# (torch.float32, torch.Size([4, 5]))
创建Tensor
- torch.zeros()
- torch.randn()
- torch.from_numpy(a)
- torch.numpy()
数学操作
- torch.squeeze(input, dim=None, out=None): 将输入张量形状中的 1去除并返回。当给定 dim 时, 那么挤压操作只在给定维度上。
- torch.abs(input, out=None): 计算输入张量的每个元素的绝对值。
- torch.acos(input, out=None): 返回一个新张量, 包含输入张量每个元素的反余弦。
- torch.add(input, value, out=None): 对输入张量 input 逐元素加上标量值 value, 并返回结果得到一个新的张量 out。
- torch.cat(): Tensor 的拼接
- torch.mm()
数理统计
- torch.mean(input): 返回输入张量所有元素的均值。
- torch.mean(input, dim, out=None): 返回输入张量给定维度 dim 上每行的均值。
比较操作
- torch.eq(input, other, out=None): 比较元素相等性。第二个参数可为一个数或与第一个参数同类型形状的张量。
- torch.ge(input, other, out=None): 逐元素比较 input 和 other。如果两个张量有相同的形状和元素值, 则返回 True, 否则 False。第二个参数可以为一个数或与第一个参数相同形状和类型的张量。
- torch.gt(input, other, out=None): 逐元素比较 input 和 other。如果两个张量有相同的形状和元素值, 则返回 True, 否则 False。第二个参数可以为一个数或与第一个参数相同形状和类型的张量。
1.3.1.2 变量
变量是神经网络计算图里特有的一个概念, 就是Variable提供了自动求导的功能。
每个变量都有两个标志: requires_grad 和 volatile。
如果一个变量定义 requires_grad 为 True, 后续的这个变量的所有操作可以使用 requires_grad, 如果一个变量定义 requires_grad 为 False, 变量不需要梯度, 在子图中从不执行向后计算。
当我们在用已经训练好的模型进行训练的时候, 如果想要冻结已经训练好的模型参数, 我们只需要使用 requires_grad = False 即可冻结参数。
requires_grad为False, 变量不需要梯度, 在子图中从不执行向后计算。volatile代表require_grad为False。我们在不进行执行计算, 不调用.backward()的时候, volatile参数特别有用。它将使用绝对最小的内存来评估模型。
x = Variable(torch.Tensor([1]), requires_grad=True)
w = Variable(torch.Tensor([2]), requires_grad=True)
b = Variable(torch.Tensor([3]), requires_grad=True)
y = w * x + b
y.backward() # y.backward(torch.FloatTensor([1]))
print(x.grad, w.grad, b.grad)
1.3.1.3 求导
数学上求导简单来说就是求取方程式相对于输入参数的变化率, 也就是加速度。
求导的作用是用导数对神经网络的权重参数进行调整, Pytorch 中为求导提供了专门的包, 包名叫 autograd。如果用autograd.Variable 来定义参数, 则 Variable 自动定义了两个变量, data代表原始权重数据; 而 grad 代表求导后的数据, 也就是梯度。每次迭代过程就用这个 grad 对权重数据进行修正。
import torch
from torch.autograd import Variable
a = Variable(torch.FloatTensor([2, 3]), requires_grad=True)
b = a + 3
c = b*b*3
out = c.mean()
print(out)
# 反向传播, 也就是求导数的意思
out.backward()
print('input', a.data)
print('Compute result is', out.item())
print('input gradients are', x.grad.data)
权值更新方法:weight = weight + learning_rate * gradient
learning_rate 是学习速率, 多数时候就叫做 lr, 是学习步长, 用步长 * 导数就是每次权重修正的 delta 值, lr 越大表示学习的速度越快, 相应的精度就会降低。
1.3.2 函数
1.3.2.1 损失函数
损失函数, 又叫目标函数, 是编译一个神经网络模型必须的两个参数之一。另一个必不可少的参数是优化器。
损失函数是指用于计算标签值和预测值之间差异的函数, 在机器学习过程中, 有多种损失函数可供选择, 典型的有距离向量, 绝对值向量等。
- nn.L1Loss: 取预测值和真实值的绝对误差的平均数即可
criterion = nn.L1Loss()
loss = criterion(sample, target)
print(loss)
# (|0-1|+|1-1|+|2-1|+|3-1|) / 4 = 1
- nn.SmoothL1Loss: 也叫作 Huber Loss, 误差在 (-1,1) 上是平方损失, 其他情况是 L1 损失
- nn.MSELoss: 平方损失函数, 其计算公式是预测值和真实值之间的平方和的平均数
- nn.BCELoss: 二分类用的交叉熵
- nn.CrossEntropyLoss: 交叉熵损失函数, 在图像分类神经网络模型中就常常用到该公式
- nn.NLLLoss: 负对数似然损失函数(Negative Log Likelihood), 在前面接上一个 LogSoftMax 层就等价于交叉熵损失了, 这个损失函数一般也是用在图像识别模型上
- nn.NLLLoss2d: 多了几个维度, 一般用在图片上. 比如用全卷积网络做分类时, 最后图片的每个点都会预测一个类别标签
nn.NLLLoss 和 nn.CrossEntropyLoss 的功能是非常相似的! 通常都是用在多分类模型中, 实际应用中我们一般用 NLLLoss 比较多
1.3.2.1 优化器Optim
优化器用通俗的话来说就是一种算法, 是一种计算导数的算法。各种优化器的目的和发明它们的初衷其实就是能让用户选择一种适合自己场景的优化器。优化器的最主要的衡量指标就是优化曲线的平稳度, 最好的优化器就是每一轮样本数据的优化都让权重参数匀速的接近目标值, 而不是忽上忽下跳跃的变化。因此损失值的平稳下降对于一个深度学习模型来说是一个非常重要的衡量指标。
所有的 Optimizer 都会实现 step()更新参数的方法, 使用方法如下:
optimizer.step()
一些优化算法例如 Conjugate Gradient 和 LBFGS 需要重复多次计算函数, 因此你需要传入一个闭包来允许它们重新计算你的模型。这个闭包会清空梯度, 计算损失, 然后返回。
for input, target in dataset:
def closure():
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
loss.backward()
return loss
optimizer.step(closure)
pytorch 的优化器都放在 torch.optim 包中。常见的优化器有:
- SGD: 随机梯度下降
SGD, 指stochastic gradient descent
随机的意思是随机选取部分数据集参与计算, 是梯度下降的 batch 版本。SGD 支持动量参数, 支持学习衰减率。SGD 优化器也是最常见的一种优化器, 实现简单, 容易理解
from torch import optim
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
- RMSprop
RMSprop: 通过引入一个衰减系数, 让 r 每回合都衰减一定比例, 类似于Momentum 中的做法, 该优化器通常是面对递归神经网络时的一个良好选择
keras.optimizers.RMSprop(lr=0.001, rho=0.9, epsilon=1e-06)
# epsilon: 大于 0 的小浮点数, 防止除 0 错误
- Adam
Adam: 是一种基于一阶梯度来优化随机目标函数的算法, 名字来源于 adaptive moment estimation, 自适应矩估计. Adam 算法根据损失函数对每个参数的梯度的一阶矩估计和二阶矩估计动态调整针对于每个参数的学习速率。Adam 也是基于梯度下降的方法, 但是每次迭代参数的学习步长都有一个确定的范围, 不会因为很大的梯度导致很大的学习步长, 参数的值比较稳定。
Adam(Adaptive Moment Estimation) 本质上是带有动量项的RMSprop, 它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。Adam 的优点主要在于经过偏置校正后, 每一次迭代学习率都有个确定范围, 使得参数比较平稳。
# torch.optim.Adam([var1, var2], lr = 0.0001)
optimizer = torch.optim.Adam(cnn.parameters(), lr=0.001)
# keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
- Adadelta: 针对Adagrad的问题提出了比较漂亮的解决方案
keras.optimizers.Adadelta(lr=1.0, rho=0.95, epsilon=1e-06)
- Adagrad: 可以自动变更学习速率, 只是需要设定一个全局的学习速率ϵ, 但是这并非是实际学习速率, 实际的速率是与以往参数的模之和的开方成反比的。
经验表明, 在普通算法中也许效果不错, 但在深度学习中, 深度过深时会造成训练提前结束。
keras.optimizers.Adagrad(lr=0.01, epsilon=1e-06)
- Adamax: 来自于 Adam 的论文的 Section7, 该方法是基于无穷范数的 Adam 方法的变体。
keras.optimizers.Adamax(lr=0.002, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
1.3.2.3 激活函数
-
sigmoid:
torch.nn.functional.sigmoid(input)
Sigmoid 函数是一种较早出现的激励函数, 把激励值最终投射到了 0 到 1 的区间上。Sigmoid 激励函数通常可以作为概率解释, 通过这种方式引入了非线性因素。
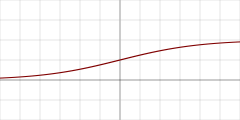
\[ f(x) = \frac{1}{1+e^{-(wx+b)'}} \\ OR \\ z = wx+b, f(z) = \frac{1}{1+e^{-z}} \] -
tanh:
torch.nn.functional.tanh(input)
Tanh 函数也算是比较常见的激励函数了, 在学习循环神经网络(Recurrent Neural Networks, RNN)的过程中我们会经常见到它。Tanh 函数也叫作双曲正切函数, 它的表达式如下。
\[ Tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} \]Tanh 函数和 Sigmoid 函数"长"得很像, 都是"S" 形的曲线, 只不过 Tanh 函数把输入的值投射到 -1 到 1 的区间上了。
-
relu:
torch.nn.functional.relu(input, inplace=False)
ReLU 函数是大部分卷积神经网络(Convolutional Neural Networks, CNN)中经常使用的激励函数, 它的全称是"Rectified Linear Units"
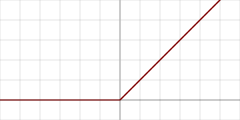
\[ y = max(x, 0) \] -
Leaky ReLU
-
Maxout
1.3.3 nn.Module 模组
在PyTorch里面编写神经网络,所有的层结构和损失函数都来自于torch.nn,所有的模型构建都是从这个基类nn.Module继承的,于是有了下面这个模板:
import torch.nn as nn
class net_name(nn.Module):
def __init__(sself, other_arguments):
super(net_name, self).__init__()
self.convl = nn.Conv2d(in_channels, out_channels, kernel_size)
# other network layer
def forward(self, x):
x = self.convl(x)
return x
1.3.3.1 卷积层
卷积是一种局部操作, 通过一定大小的卷积核作用于局部图象区域, 从而得到图象的局部信息。
卷积层是用一个固定大小的矩形区去席卷原始数据, 将原始数据分成一个个和卷积核大小相同的小块, 然后将这些小块和卷积核相乘输出一个卷积值。
卷积的本质就是用卷积核的参数来提取原始数据的特征, 通过矩阵点乘的运算, 提取出和卷积核特征一致的值, 如果卷积层有多个卷积核, 则神经网络会自动学习卷积核的参数值, 使得每个卷积核代表一个特征。
- conv2d 是二维度卷积, 对数据在宽度和高度两个维度上进行卷积
nn.Conv2d(
in_channels: int,
out_channels: int,
kernel_size: Union[int, Tuple[int, int]],
stride: Union[int, Tuple[int, int]] = 1,
padding: Union[str, int, Tuple[int, int]] = 0,
dilation: Union[int, Tuple[int, int]] = 1,
groups: int = 1,
bias: bool = True,
padding_mode: str = 'zeros',
device=None,
dtype=None,
) -> None
torch.nn.functional.conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1)
torch.nn.Conv1d(in_channels, out_channels, kernel_size,stride=1, padding=0,dilation=1,groups=1,bias=True)
- conv1d 是一维卷积, 它和 conv2d 的区别在于只对宽度进行卷积, 对高度不卷积
1.3.3.2 池化层
就是将多个元素用一个统计值来表示
- max_pool2d: 二维最大值池化
a = range(20)
x = Variable(torch.Tensor(a))
x = x.view(1, 1, 4, 5)
print('x:', x, x.size())
y = torch.functional.F.max_pool2d(x, kernel_size=2, stride=2)
print("y:", y, y.size())
- avg_pool2d 和 max_pool2d 的计算原理是一样的, 只不过取的是平均值
- max_pool1d 和 max_pool2d 的区别和卷积操作类似, 也是只对宽度进行池化
1.3.3.3 LSTM
nn.RNN()
nn.LSTM()
pytorch 中使用 nn.LSTM 类来搭建基于序列的循环神经网络。
1.3.3.4 Embedding
在 PyTorch 中我们用 nn.Embedding 层来做嵌入词袋模型
1.3.4 保存和加载模型
# 只保存和加载模型参数
torch.save(the_model.state_dict(), PATH)
the_model = TheModelClass(*args, **kwargs)
the_model.load_state_dict(torch.load(PATH))
# 保存和加载整个模型
torch.save(the_model, PATH)
the_model = torch.load(PATH)
1.4 其他
1.4.1 Torchvision
Torchvision 包括了目前流行的数据集、模型结构和常用的图片转换工具。torchvision.models 模块的子模块中包含以下预训练的模型结构。
- AlexNet
- VGG: 深度卷积神经网络, VGGNet 反复堆叠\(3\times3\)小型卷积核和\(2\times2\)最大池化层, 成功构筑16~19层深卷积神经网络。
- ResNet: 一般我们把 ResNet 称作是残差网
- SqueezeNet
- DenseNet
import torchvision.models as models
resnet18 = models.resnet18(pretrained=True)
1.4.1.1 常用的图形变换
- torchvision.transforms.Compose(transforms): 将多个 transform 组合起来使用。
- torchvision.transforms.Resize(size, interpolation=2): 按照规定的尺寸重新调节 PIL.Image。
- torchvision.transforms.RandomHorizontalFlip(): 随机水平翻转给定的 PIL.Image,概率为 0.5。
- torchvision.transforms.RandomCrop(size, padding=0)
- torchvision.transforms.RandomSizeCrop(size, padding=0)
- torchvision.transforms.RandomHorizontalFlip(size, padding=0): 对图片进行概率为 0.5 的随机水平翻转
- torchvision.transforms.Pad()
1.4.2 Torch.nn
Torch.nn 包里面包含了如何定义 Module 神经网络模型, 各种 Functional函数以及如何通过 Optim 实现各种优化算法。Module 是神经网络的基本组成部分, 作为一个抽象类, 可以通过定义成员函数实现不同的神经网络结构。Functional 包括 Convolution 函数、Pooling 函数、非线性激活函数、Normalization 函数、线性函数、Dropout 函数、距离函数(Distance functions)、损失函数(Loss functions)等。Optim 包含了各种优化算法, Momentum 算法、NesterovMomentum 算法、AdaGrad 算法、RMSProp 算法、Adam(Adaptive Moment Estimation)算法等, 我们可以根据神经网络模型的需求选择合适的优化算法。
1.4.3 Functional函数
torch.nn.functional 包里面提供的函数如下。
- Convolution 函数
- Pooling 函数
- 非线性激活函数
- Normalization 函数
- 线性函数
- Dropout 函数
- 距离函数(Distance Functions)
- 损失函数(Loss Functions)
- Vision Functions
Torch.nn 包里面只是包装好了神经网络架构的类, nn.functional 与 Torch.nn 包相比, nn.functional 是可以直接调用函数的。
1.4.3.1 Pooling 函数
Pooling 函数主要是用于图像处理的卷积神经网络中, 但随着深层神经网络的发展, Pooling 函数相关技术在其他领域, 其他结构的神经网络中也越来越受关注。
Pooling 函数的结果是特征减少, 参数减少, 但 Pooling 的目的并不仅在于此。Pooling 函数的目的是保持某种不变性(旋转、平移、伸缩等), 常用的有 Mean-Pooling 函数, Max-Pooling 函数和 Stochastic-Pooling 函数三种。
- torch.nn.functional.avg_pool1d
1.4.3.2 Dropout 函数
Dropout 函数是 Hintion 在 2012 年提出的。为了防止模型过拟合, Dropout 可以作为一种 Trikc 供选择。在每个训练批次中, 通过忽略一半的神经元即让一半的隐层节点值为 0, 可以明显地减少过拟合现象。下面我们列出常见的 Dropout 函数:
- torch.nn.functional.dropout(input,p=0.5,training=False,inplace=False)
- torch.nn.functional.alpha_dropout(input,p=0.5,training=False)
- torch.nn.functional.dropout2d(input, p=0.5,training=False,inplace=False)
- torch.nn.functional.dropout3d(input, p=0.5,training=False,inplace=False)
1.4.4 线性回归
线性回归也叫 regression, 它是一个比较简单的模拟线性方程式的模型。线性回归是利用数理统计中的回归分析, 来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法, 运用十分广泛。分析按照自变量和因变量之间的关系类型, 可分为线性回归分析和非线性回归分析。
- \(x_1, x_2, \dots, x_k\) 是一组独立的预测变量。
- \(w_1, w_2, \dots, w_k\)为模型从训练数据中学习到的参数, 或赋予每个变量的"权值"。
- \(b\) 也是一个学习到的参数, 这个线性函数中的常量也称为模型的偏置(Bias)。
一般来说, 线性回归都可以通过最小二乘法求出其方程。线性回归属于监督学习, 因此方法和监督学习应该是一样的, 先给定一个训练集, 根据这个训练集学习出一个线性函数, 然后测试这个函数训练得好不好(即此函数是否足够拟合训练集数据), 挑选出最好的函数(Cost Function 最小)即可。Cost Function 越小的函数, 说明对训练数据拟合得越好。
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
from torch.autograd import Variable
# Hyper Parameters
input_size = 1
output_size = 1
num_epochs = 600
learning_rate = 0.001
x_train = np.array([
[3.3], [4.4], [5.5], [6.71], [6.93], [4.168],
[9.779], [6.182], [7.59], [2.167], [7.042],
[10.791], [5.313], [7.997], [3.1]], dtype=np.float32)
y_train = np.array([
[1.7], [2.76], [2.09], [3.19], [1.694], [1.573],
[3.366], [2.596], [2.53], [1.221], [2.827],
[3.465], [1.65], [2.904], [1.3]], dtype=np.float32)
class LinearRegression(nn.Module):
def __init__(self, input_size, output_size):
super(LinearRegression, self).__init__()
self.linear = nn.Linear(input_size, output_size)
def forward(self, x):
out = self.linear(x)
return out
model = LinearRegression(input_size, output_size)
# 均方损失函数
# 对于这种简单的模型, 将采用总平方误差, 即模型对每个训练样本的预测值与期望输出之差的平方的总和
criterion = nn.MSELoss()
# 随机梯度下降(Stochastic Gradient Descent, SGD)
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
for epoch in range(num_epochs):
inputs = Variable(torch.from_numpy(x_train))
targets = Variable(torch.from_numpy(y_train))
optimizer.zero_grad()
outputs = model(inputs)
# 前向传播
loss = criterion(outputs, targets)
# 计算 loss
loss.backward()
# 更新参数
optimizer.step()
if (epoch+1) % 5 == 0:
print("Epoch [%d/%d], Loss: %.4f" % (epoch+1, num_epochs, loss.item()))
predicted = model(Variable(torch.from_numpy(x_train))).data.numpy()
plt.plot(x_train, y_train, "ro", label="Original data")
plt.plot(x_train, predicted, label="Fitted line")
plt.legend()
plt.show()
逻辑回归
Logistic Regression(逻辑回归)是当前业界比较常用的机器学习方法, 用于估计某种事物的可能性。比如某用户购买某商品的可能性, 某病人患有某种疾病的可能性, 以及某广告被用户点击的可能性等。
- 二分类问题: 是指预测的 y 值只有两个取值(0 或 1), 二分类问题可以扩展到多分类问题。
- Logistic 函数: LR 分类器(Logistic Regression Classifier), 在分类情形下, 经过学习
之后的 LR 分类器其实就是一组权值\(w_0, w_1, \dots, w_m\)。当测试样本集中的测试数据来到时, 这一组权值按照与测试数据线性加和的方式, 求出一个\(z\)值。
逻辑回归使用一个函数来归一化\(y\)值, 使\(y\)的取值在区间\((0, 1)\)内, 这个函数称为 Logistic 函数(Logistic Function), 也称为Sigmoid 函数(Sigmoid Function)。
2. Visdom
Visdom是一个灵活的可视化工具, 可以实时显示新创建的数据, 支持 Torch 和 Numpy。
Visdom 的目的是促进远程数据的可视化, 支持科学实验。可以发送可视化图像和文本。通过 UI 为实时数据创建 dashboards, 检查实验的结果。
2.1 Panes(窗格)
UI 刚开始是个白板, 你可以用图像和文本填充它。这些填充的数据出现在 Panes 中, 你可以对这些 Panes 进行拖放、删除、调整大小和销毁操作。Panes 是保存在 Environments(环境)中的, Environments(环境)的状态存储在会话之间。你可以下载 Panes 中的内容, 包括你在 SVG 中的绘图。
2.2 Environments(环境)
可以使用 Envs 对可视化空间进行分区。每个用户都会有一个叫作 main的 Envs。可以通过编程或 UI 创建新的 Envs。Envs 的状态是长期保存的。
2.3 State(状态)
一旦你创建了一些可视化, 状态是被保存的。服务器自动缓存你的可视化, 如果你重新加载网页, 你的可视化就会重新出现。
3. 实战
常见的前馈神经网络有感知机(Perceptrons)、BP(Back Propagation)网络、RBF(Radial Basis Function)网络等。
- 感知器(又叫感知机)是最简单的前馈网络, 它主要用于模式分类, 也可用在基于模式分类的学习控制和多模态控制中。感知器网络可分为单层感知器网络和多层感知器网络。
- BP 网络是指连接权调整采用了反向传播(Back Propagation)学习算法的前馈网络。与感知器不同之处在于, BP 网络的神经元变换函数采用了 S形函数(Sigmoid 函数), 因此输出量是 0~1 之间的连续量, 可实现从输入到输出的任意的非线性映射。
- RBF 网络是指隐含层神经元由 RBF 神经元组成的前馈网络。RBF 神经元是指神经元的变换函数为 RBF(Radial Basis Function, 径向基函数)的神经元。典型的 RBF 网络由三层组成: 一个输入层, 一个或多个由 RBF神经元组成的 RBF 层(隐含层), 一个由线性神经元组成的输出层。
3.1 全连接网络
import torch
import torch.nn as nn
import torchvision.datasets as dsets
import torchvision.transforms as transforms
from torch.autograd import Variable
input_size = 784
hidden_size = 500
num_classes = 10
num_epochs = 5
batch_size = 100
learning_rate = 0.001
# MNIST Dataset
train_dataset = dsets.MNIST(root='E:/Learn/datasets/MNIST数据', train=True, transform=transforms.ToTensor(), download=True)
test_dataset = dsets.MNIST(root='E:/Learn/datasets/MNIST数据', train=False, transform=transforms.ToTensor())
# Data Loader (Input Pipeline)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)
class Net(nn.Module):
def __init__(self, input_size, hidden_size, num_classes):
super(Net, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, num_classes)
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out
net = Net(input_size, hidden_size, num_classes)
# Loss and Optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=learning_rate)
# Train the Model
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
# Convert torch tensor to Variable
images = Variable(images.view(-1, 28*28))
labels = Variable(labels)
# Forward + Backward + Optimize
optimizer.zero_grad() # zero the gradient buffer
outputs = net(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
if (i+1) % 100 == 0:
print('Epoch [%d/%d], Step [%d/%d], Loss: %.4f' % (epoch+1, num_epochs, i+1, len(train_dataset)//batch_size, loss.item()))
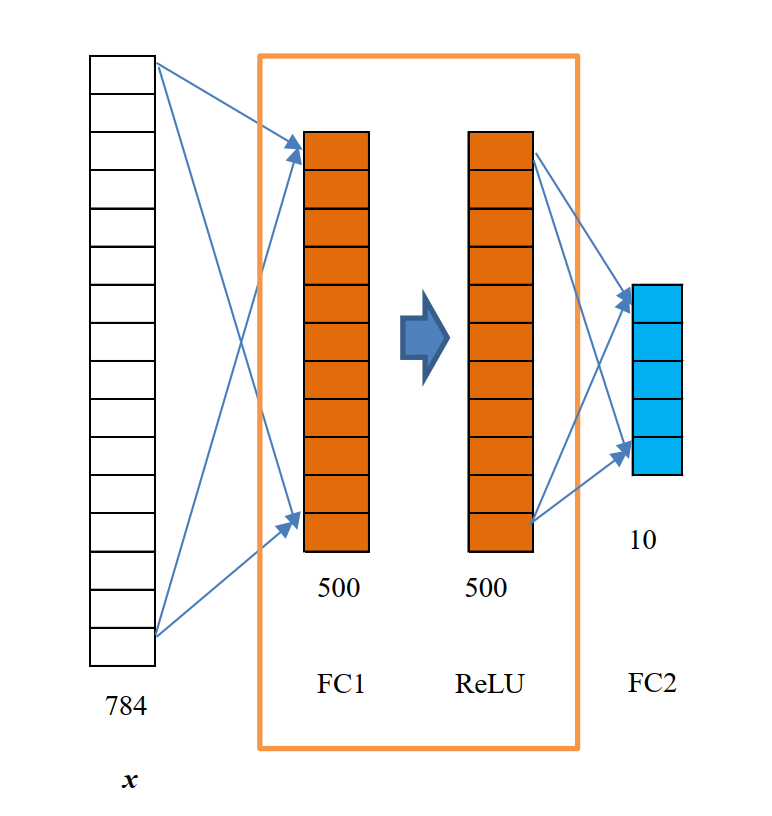
输入为 x, 一个 784 维(1x784)的矩阵。FC1 是一个全连接层, 其中有 500 个神经元, 其实
是一个 784x500 的矩阵(应该如何计算, 会在后面介绍)。ReLU 是激励函数, 对于 FC1 输出的
1x500 的矩阵, 每一个维度值都被一个非线性激励函数 ReLU 处理过。FC2 也是一个全连接层,
相当于一个 500x10 的矩阵。方框中是一个完整的隐藏层, 即一个线性函数 \(y=wx+b\) 和一个非线性函数 ReLU 叠加的过程。
3.2 卷积神经网络
卷积神经网络(Convolutional Neural Network, CNN)因为在网络中有卷积核(Convolution Kernel)这样一个功能组件而得名。
卷积核通常是一个正方形的框, 尺寸可以是 1x1、2x2、3x3 等。当然, 在一些特殊的场景中, 卷积核也可以是非正方形的。
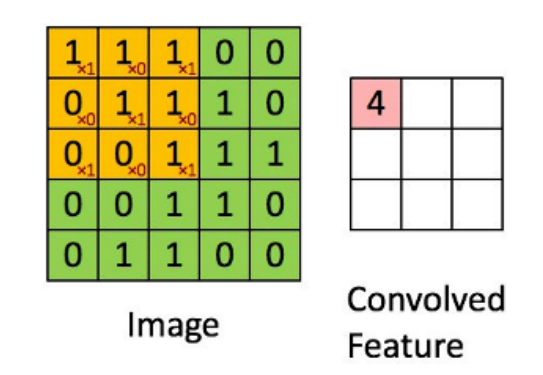
卷积核所做的事情就是把前一层输入的数据特征提取出来。所谓特征提取, 就是通过一个线性计算映射和一个激励函数(可选), 让它在后一层成为一个数值形式的激励值。
由于 CNN 的特征检测层通过训练数据进行学习, 因此可以隐式地从训练数据中进行学习。
CNN 主要用来识别位移、缩放及其他形式扭曲不变性的二维图形。
# CNN Model (2 conv layer)
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, padding=2),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(2))
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=5, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2))
self.fc = nn.Linear(7*7*32, 10)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
cnn = CNN()
# Loss and Optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(cnn.parameters(), lr=learning_rate)
# Train the Model
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
images = Variable(images)
labels = Variable(labels)
# Forward + Backward + Optimize
optimizer.zero_grad()
outputs = cnn(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
if (i+1) % 100 == 0:
print ('Epoch [%d/%d], Iter [%d/%d] Loss: %.4f' %(epoch+1, num_epochs, i+1, len(train_dataset)//batch_size, loss.item()))
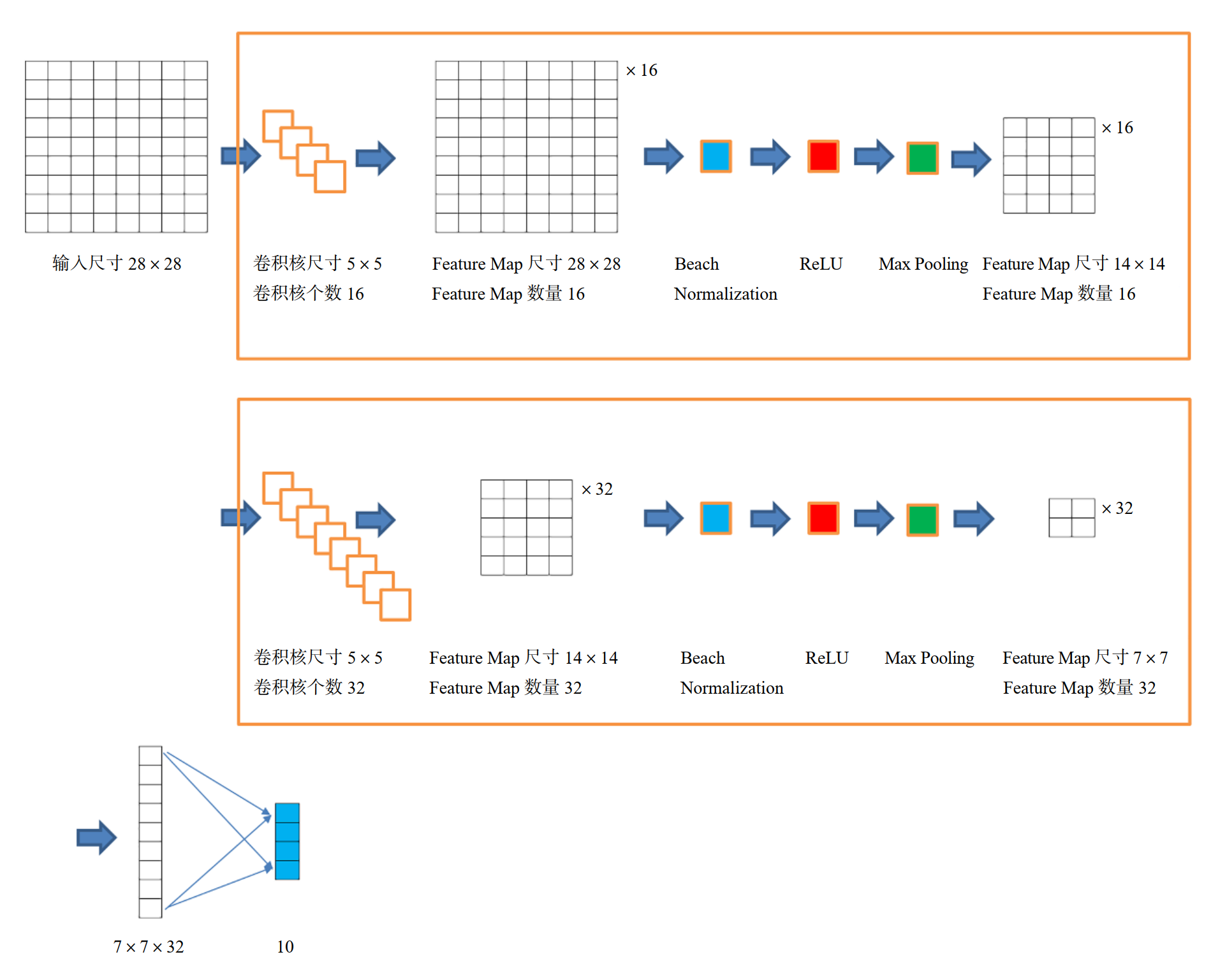
3.2.1 卷积神经网络结构
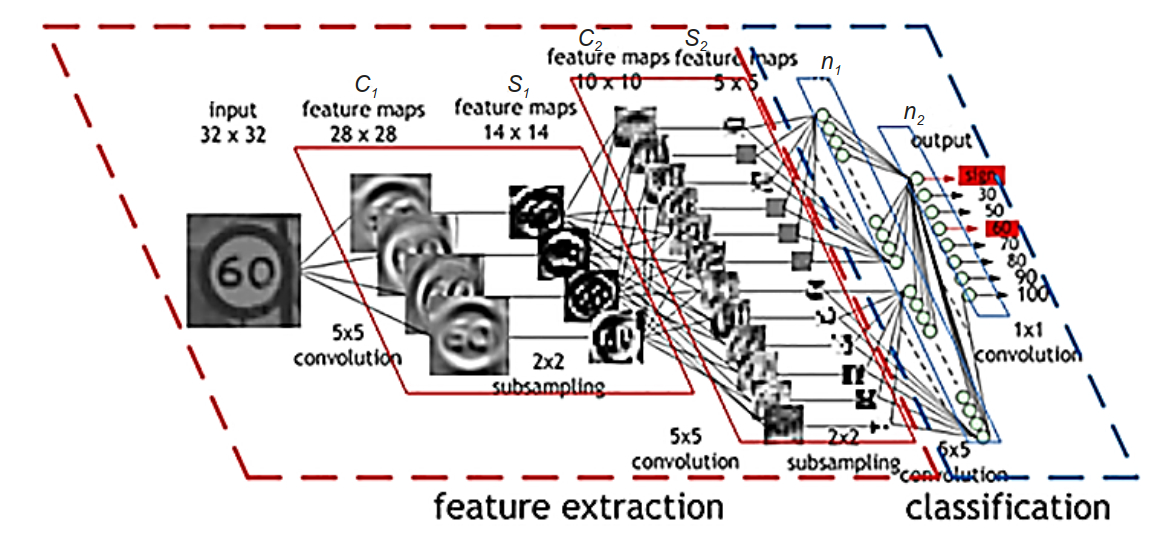
希望将一幅 32 像素x32 像素的灰度图片输入卷积神经网络, 让网络自动输出这幅图片的分类。
-
输入的 32x32 的图标, 经过 4 个 5x5 的卷积核的计算, 会在 \(C_1\) 层产生 4 个 28x28 的Feature Map。
从 Feature Map 的尺寸来看, 显然没有进行 Padding 操作。关于在卷积层中要不要进行 Padding 操作, 需要根据输入图像的边缘携带的信息的特征及其是否足以影响分类的准确率来决定。 -
\(C_1\) 层的 4 个 28x28 的 Feature Map, 通过一个 2x2 的降采样处理后, 会变成一个新的 14x14 的 Feature Map——无疑, 通过了 Pooling 层。
这个地方可以是 Max Pooling, 也可以是 AveragePooling, 在不同的业务场景中, 两种 Pooling 各有特点。 -
\(C_2\) 层和 \(S_2\) 层, 分别相当于又一次进行了多通道卷积核的特征提取和进一步的降维操作。也就是说, 通过 12 个卷积核对前面的 Feature Map 进行处理, 输出 12 个新的 Feature Map, 再分别进行降采样, 最后输出 12 个 5x5 的 Feature Map。
3.3 循环神经网络
LSTM 网络(长短期记忆, Long ShortTerm Memory)是循环神经网络(Recurrent Neural Networks, RNN)的一种形式, 也是当前较为流行的循环神经网络的实现方式。
LSTM 网络是用循环层实现的。循环层有一个特点, 就是把前一次(时序上)输入的内容或者其中间的激励值, 以及当前这一次的输入值, 一起作为网络的输入。
Neuraltalk2: 可以根据输入的图片生成一个描述图片内容的短句。
# Hyper Parameters
sequence_length = 28
input_size = 28
hidden_size = 32
num_layers = 2
num_classes = 10
batch_size = 100
num_epochs = 2
learning_rate = 0.01
# RNN Model (Many-to-One)
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, num_classes):
super(RNN, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, num_classes)
def forward(self, x):
# Set initial states
h0 = Variable(torch.zeros(self.num_layers, x.size(0), self.hidden_size))
c0 = Variable(torch.zeros(self.num_layers, x.size(0), self.hidden_size))
# Forward propagate RNN
out, _ = self.lstm(x, (h0, c0))
# Decode hidden state of last time step
out = self.fc(out[:, -1, :])
return out
rnn = RNN(input_size, hidden_size, num_layers, num_classes)
LSTM 由于自身的特殊性质, 可以实现"一到一"、“一到多”、“多到一"“多到多” 的映射拟合。这个例子是"多到一” 的映射, 输入是 28 行, 每行是一个 28 维的向量, 输出是一个独热向量的分类标签。
3.3.1 深层双向 RNN
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True, bidirectional=True)
4. 自编码神经网络
自编码神经网络是一种无监督学习算法, 它使用了反向传播算法, 并让目标值等于输入值, 简单的自编码是一种三层神经网络模型, 包含了数据输入层、隐藏层、输出重构层, 同时它是一种无监督学习模型。
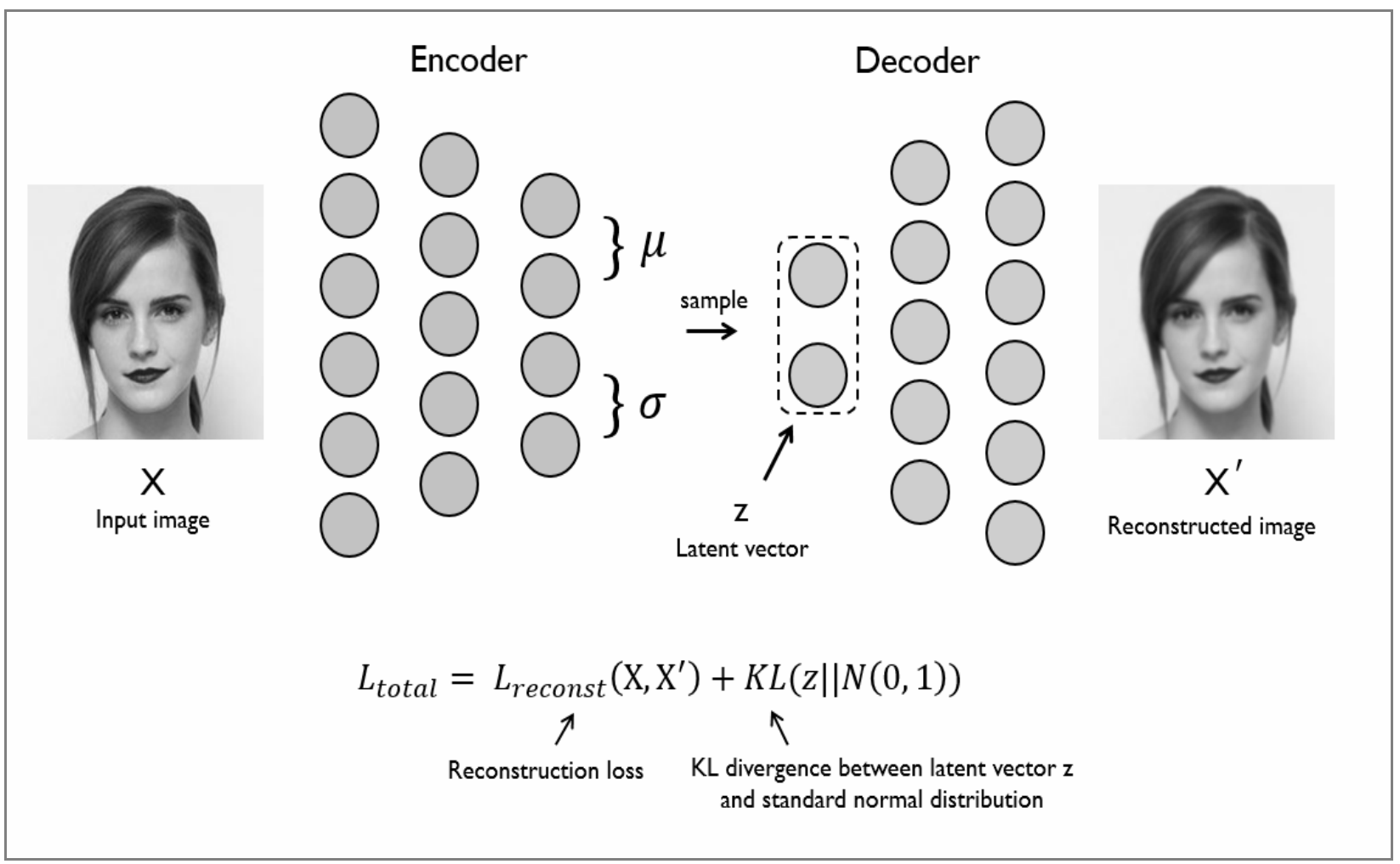
class AutoEncoder(nn.Module):
def __init__(self):
super(AutoEncoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(28*28, 128),
nn.Tanh(),
nn.Linear(128, 64),
nn.Tanh(),
nn.Linear(64, 12),
nn.Tanh(),
nn.Linear(12, 3), # compress to 3 features which can be visualized in plt
)
self.decoder = nn.Sequential(
nn.Linear(3, 12),
nn.Tanh(),
nn.Linear(12, 64),
nn.Tanh(),
nn.Linear(64, 128),
nn.Tanh(),
nn.Linear(128, 28*28),
nn.Sigmoid(), # compress to a range (0, 1)
)
def forward(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return encoded, decoded
5. 对抗生成网络
Ian J. Goodfellow 在 2014 年的 Generative Adversative Nets 论文中, 第一次提出了对抗网络模型, 如今对抗网络模型在深度学习生成模型领域已经取得了不错的成果。论文提出利用对抗过程估计生成模型, 可以认为是在无监督表示学习(Unsuperivised representation learning)上的一个突破, 现在主要的应用是用其生成自然图片(natural images)。
GAN 的原理很简单, 简单说是概率生成模型的目的, 就是找出给定观测数据内部的统计规律, 并且能够基于所得到的概率分布模型, 产生全新的, 与观测数据类似的数据。
GAN 很好地解决了这两大难题。GAN 网络的巧妙在于其设计思维, 而技术上是对现有算法的组合, GAN 网络主要由两个网络合成。一个是 G生成网络: 输入为随机数, 输出为生成数据。目的是为了生成数据的取值范围与真实数据相似, 具体使用什么函数视情况而定。另一个是 D 区分网络。D 区分网络输入数据为混合 G 的输出数据及样本数据。输出一个判别概率。
GAN 最直接的应用, 就是用于真实数据分布的建模和生成, 包括可以生成一些图像和视频, 以及生成一些自然语句和音乐等。由于 GAN 可以生成大量数据, 可以解决一些传统的机器学习中所面临的数据不足的问题, 因此可以应用在半监督学习、无监督学习、多视角、多任务学习的任务中。
5.1 DCGAN
在 GAN 的基础上, DCGAN 的一大特点就是使用了卷积层。DCGAN的基本架构就是使用几层"反卷积"(Deconvolution)网络。“反卷积"类似于一种反向卷积, 这跟用反向传播算法训练监督的卷积神经网络(CNN)是类似的操作。
6. Seq2seq自然语言
目前比较流行的 Seq2Seq 模型, 由 Sutskever 等人提出, 基于一个Encoder-Decoder 的结构, 将 Source 句子先 Encode 成一个固定维度 d 的向量, 然后通过 Decoder 部分一个字符一个字符生成 Target 句子。加入了Attention 注意力分配机制后, 使得 Decoder 在生成新的 Target Sequence 时, 能得到之前 Encoder 编码阶段每个字符的隐藏层的信息向量 Hidden State, 使得生成新序列的准确度提高。
最基础的 Seq2Seq 模型包含了三个部分, 即 Encoder、 Decoder 以及连接两者的中间状态向量, Encoder 通过学习输入, 将其编码成一个固定大小的状态向量 S, 继而将 S 传给 Decoder, Decoder 再通过对状态向量 S 的学习来进行输出。
