
目录
给定预训练模型(Pre_trained model),基于模型进行微调(Fine Tune)。相对于从头开始训练(Training a model from scatch), 微调为你省去大量计算资源和计算时间, 提高了计算效率,甚至提高准确率。
微调是为了增加"技能", 而不是"知识"。例如, 问答、摘要、翻译、对话、代码完成、填充掩码、句子/语义相似性, 我相信还有更多。
微调更适合于具有狭窄、定义明确、静态的知识和格式域的方案。正如 Anyscale 所指出的, “fine-tuning is for form, not facts。“例如, 在品牌或创意写作应用程序中, 风格和语气需要与特定的指导方针或独特的声音保持一致, 微调模型确保输出与所需的语言风格或主题一致性相匹配。
在某些情况下, 您可以使用模型优化来提高特定任务的模型性能。当指令不足时, 模型调整还可以帮助它遵守特定的输出要求。
0. 关于微调
0.1 微调指导事项
- 数据量少, 但数据相似度非常高 - 在这种情况下, 我们所做的只是修改最后几层或最终的softmax图层的输出类别。
- 数据量少, 数据相似度低 - 在这种情况下, 我们可以冻结预训练模型的初始层(比如k层), 并再次训练剩余的(n-k)层。由于新数据集的相似度较低, 因此根据新数据集对较高层进行重新训练具有重要意义。
- 数据量大, 数据相似度低 - 在这种情况下, 由于我们有一个大的数据集, 我们的神经网络训练将会很有效。但是, 由于我们的数据与用于训练我们的预训练模型的数据相比有很大不同。使用预训练模型进行的预测不会有效。因此, 最好根据你的数据从头开始训练神经网络(Training from scatch)
- 数据量大, 数据相似度高 - 这是理想情况。在这种情况下, 预训练模型应该是最有效的。使用模型的最好方法是保留模型的体系结构和模型的初始权重。然后, 我们可以使用在预先训练的模型中的权重来重新训练该模型。
0.2 微调指导事项
-
通常的做法是截断预先训练好的网络的最后一层(softmax层), 并用与我们自己的问题相关的新的softmax层替换它。例如, ImageNet上预先训练好的网络带有1000个类别的softmax图层。如果我们的任务是对10个类别的分类, 则网络的新softmax层将由10个类别组成, 而不是1000个类别。然后, 我们在网络上运行预先训练的权重。确保执行交叉验证, 以便网络能够很好地推广。
-
使用较小的学习率来训练网络。由于我们预计预先训练的权重相对于随机初始化的权重已经相当不错, 我们不想过快地扭曲它们太多。通常的做法是使初始学习率比用于从头开始训练(Training from scratch)的初始学习率小10倍。
-
如果数据集数量过少, 我们进来只训练最后一层, 如果数据集数量中等, 冻结预训练网络的前几层的权重也是一种常见做法。这是因为前几个图层捕捉了与我们的新问题相关的通用特征, 如曲线和边。我们希望保持这些权重不变。相反, 我们会让网络专注于学习后续深层中特定于数据集的特征。
0.3 微调 LLM
针对特定任务微调 LLM 可以显著提高性能。如果您的 LLM 是特定功能所必需的, 那么对微调进行一次性投资可以提高其对该任务的有效性。这种方法可以根据您的特定需求定制模型的功能, 从而更有效地利用资源, 从长远来看, 可能会降低总体成本。
0.4 构建更好的Prompt
系统Prompt是 LLM 应用程序中使用的模板, 除了注入特定数据(如用户Prompt)外, 还用于对模型进行信任。 制作更好的系统Prompt可以大大提高 LLM 的准确性并减少幻觉的发生。诸如"思维链"提示之类的技术可以通过引导模型完成生成响应的更合乎逻辑的过程来最大限度地减少错误。但是, 此方法可能会增加发送到模型的数据量, 从而增加成本并可能影响性能。优化提示设计是管理成本、准确性和效率之间权衡的关键方面。
1. 微调方法
- Adapter Tuning
- Prompt Tuning
- prefix tuning
- p-tuning & P-tuning V2
- LoRA & AdaLoRA & QLoRA
1.1 Adapter Tuning
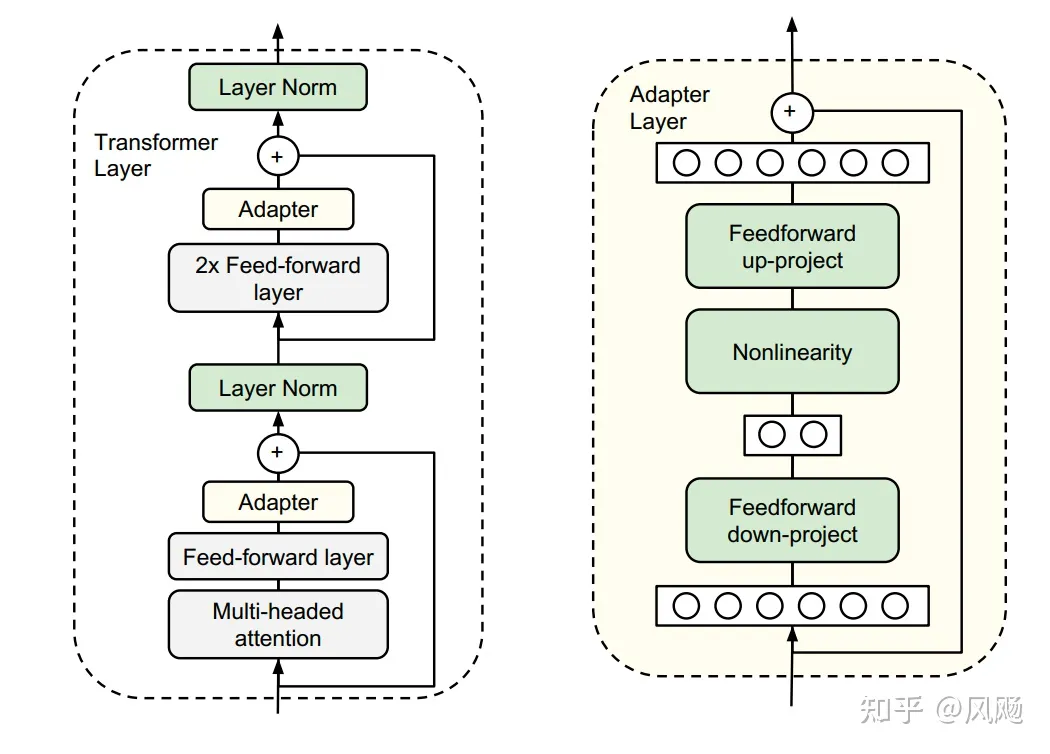
谷歌的研究人员首次在论文《Parameter-Efficient Transfer Learning for NLP》提出针对BERT的PEFT微调方式, 拉开了PEFT研究的序幕。他们指出, 在面对特定的下游任务时, 如果进行Full-fintuning(即预训练模型中的所有参数都进行微调), 太过低效;而如果采用固定预训练模型的某些层, 只微调接近下游任务的那几层参数, 又难以达到较好的效果。
于是他们设计了如下图所示的Adapter结构, 将其嵌入Transformer的结构里面, 在训练时, 固定住原来预训练模型的参数不变, 只对新增的Adapter结构进行微调。同时为了保证训练的高效性(也就是尽可能少的引入更多参数), 他们将Adapter设计为这样的结构: 首先是一个down-project层将高维度特征映射到低维特征, 然后过一个非线形层之后, 再用一个up-project结构将低维特征映射回原来的高维特征; 同时也设计了skip-connection结构, 确保了在最差的情况下能够退化为identity。
1.2 Prompt Tuning
论文: The Power of Scale for Parameter-Efficient Prompt Tuning
Official Code: https://github.com/google-research/prompt-tuning
离散的Prompt Tuning(Prompt Design)基本不能达到fine-tuning的效果; Soft Prompt Tuning在模型增大时可以达到接近fine-tuning的效果, 并且有进一步超越fine-tuning的趋势。
另外, Prompt Tuning往往比模型调优提供更强的零样本性能, 尤其是在像 TextbookQA 这样具有大域变化的数据集上。主要在T5预训练模型上做实验。似乎只要预训练模型足够强大, 其他的一切都不是问题。
固定预训练参数, 为每一个任务额外添加一个或多个embedding, 之后拼接query正常输入LLM, 并只训练这些embedding。左图为单任务全参数微调, 右图为prompt tuning。
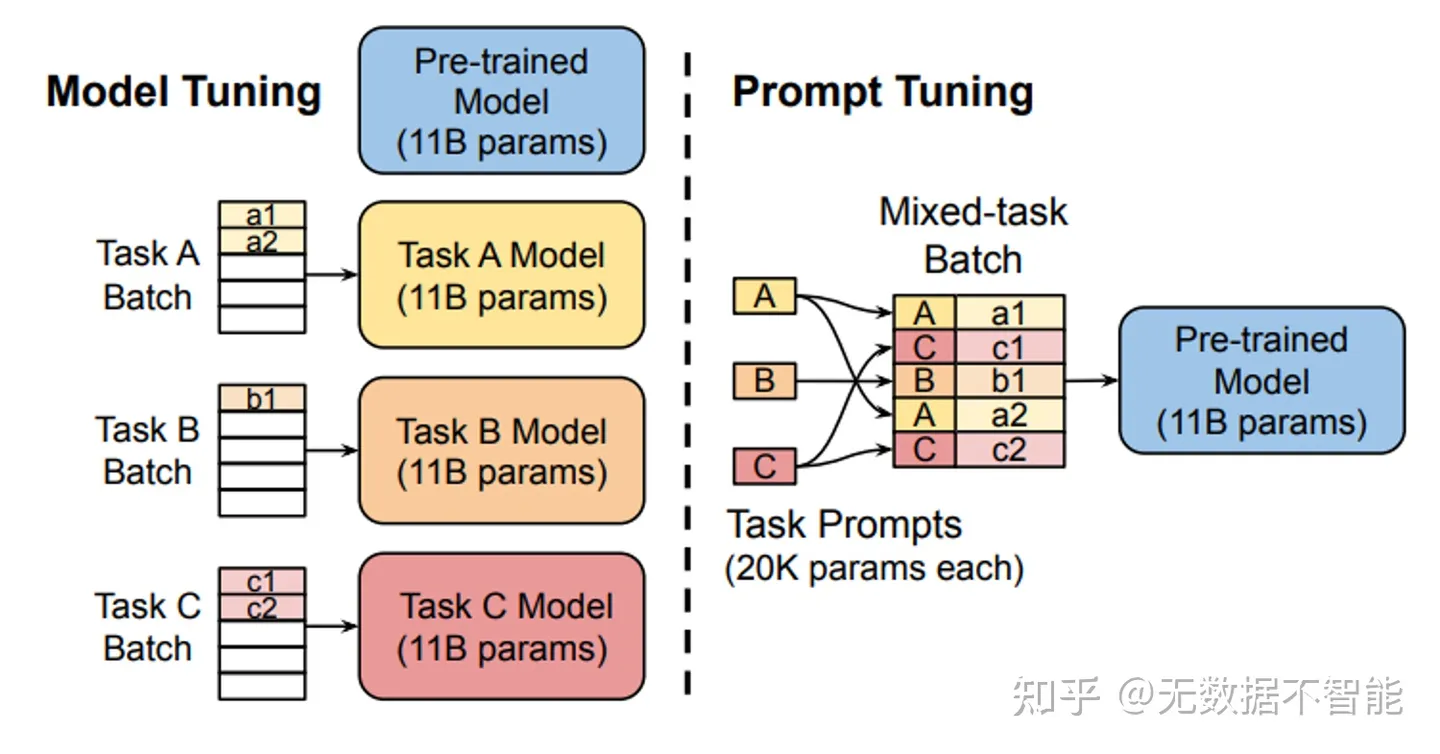
- 标准的T5模型(橙色线)多任务微调实现了强大的性能, 但需要为每个任务存储单独的模型副本。
- prompt tuning也会随着参数量增大而效果变好, 同时使得单个冻结模型可重复使用于所有任务。
- 显著优于使用GPT-3进行fewshot prompt设计。
- 当参数达到100亿规模与全参数微调方式效果无异。
peft_config = PromptTuningConfig(task_type="SEQ_CLS", num_virtual_tokens=10)
model = AutoModelForSequenceClassification.from_pretrained(model_name_or_path, return_dict=True, num_labels=labels)
model = get_peft_model(model, peft_config)
1.3 prefix tuning
论文: Prefix-Tuning: Optimizing Continuous Prompts for Generation, P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
Code: https://github.com/XiangLi1999/PrefixTuning
peft_config = PrefixTuningConfig(task_type="SEQ_CLS", num_virtual_tokens=20)
model = AutoModelForSequenceClassification.from_pretrained(model_name_or_path, return_dict=True, num_labels=labels)
model = get_peft_model(model, peft_config)
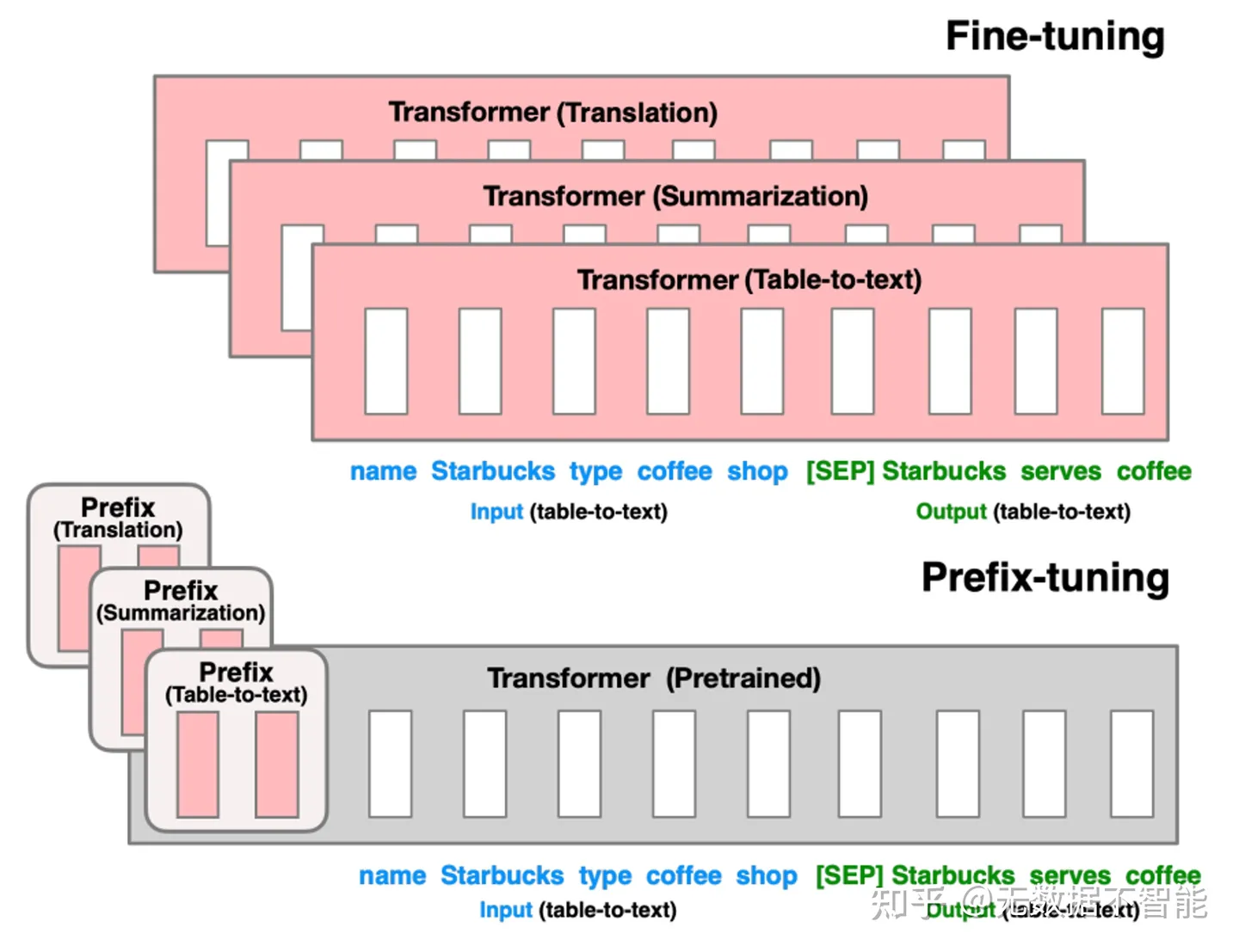
prefix tuning依然是固定预训练参数,但除为每一个任务额外添加一个或多个embedding之外,利用多层感知编码prefix,注意多层感知机就是prefix的编码器,不再像prompt tuning继续输入LLM。
1.3 p-tuning
论文: GPT Understands, Too
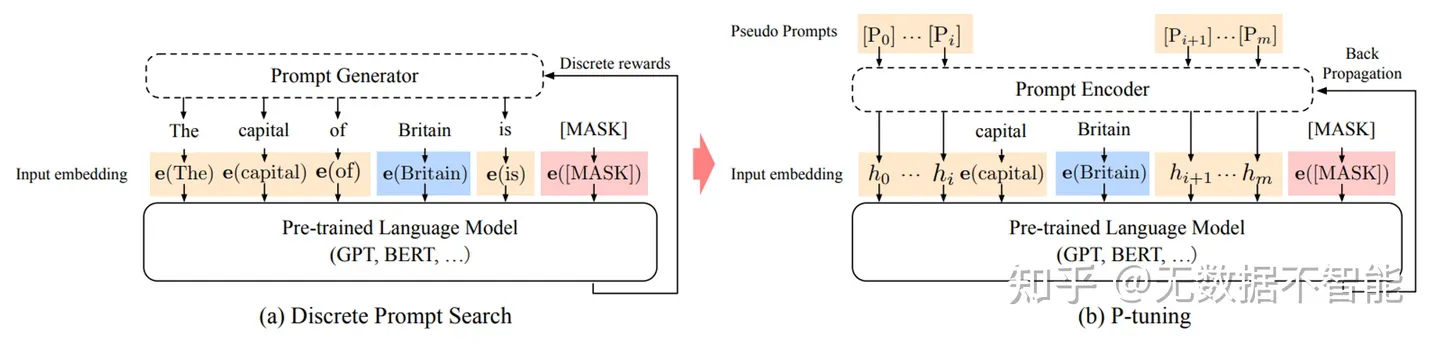
p-tuning依然是固定LLM参数,利用多层感知机和LSTM对prompt进行编码,编码之后与其他向量进行拼接之后正常输入LLM。注意,训练之后只保留prompt编码之后的向量即可,无需保留编码器。
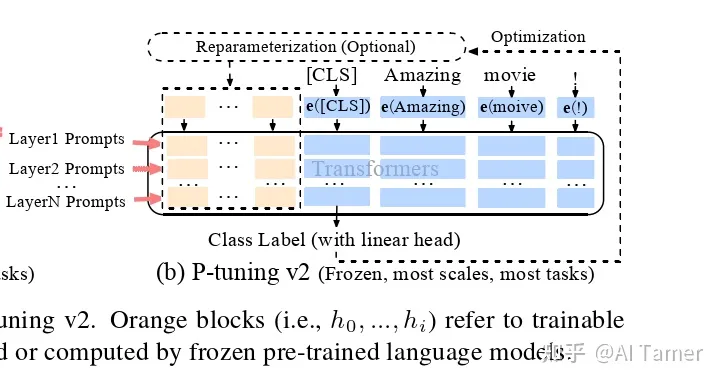
1.3.1 P-tuning v2
论文: P-Tuning v2: Prompt Tuning Can Be Comparable to Finetuning Universally Across Scales and Tasks
Code: P-tuning v2
p-tuning的问题是在小参数量模型上表现差(如上图所示),于是有了V2版本,类似于LoRA每层都嵌入了新的参数(称之为Deep FT). 具体来说, P-Tuning v2是基于P-Tuning v1的升级版, 主要的改进在于采用了更加高效的剪枝方法, 可以进一步减少模型微调的参数量。
P-tuning V2不是一个新东西, 它是Deep Prompt Tuning (Li and Liang,2021; Qin and Eisner,2021)的一个优化和适应实现。与深度提示调整类似, P-tuning v2被设计用于生成和知识探索, 但最重要的改进之一是将连续提示应用于预训练模型的每个层, 而不仅仅是输入层。
- 仅需微调0.1%-3%的参数, 就能和Fine-tuning比肩
- 将Prompt tuning技术首次应用到序列标注等复杂的NLU任务
peft_config = PromptEncoderConfig(task_type="SEQ_CLS", num_virtual_tokens=20, encoder_hidden_size=128)
model = AutoModelForSequenceClassification.from_pretrained(model_name_or_path, return_dict=True, num_labels=labels)
model = get_peft_model(model, peft_config)
1.4 LoRA
论文: LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
Code: https://github.com/microsoft/LoRA
LoRA冻结了预训练模型的参数,并在每一层decoder中加入dropout+Linear+Conv1d额外的参数. 那么,LoRA是否能达到全参数微调的性能呢? 根据实验可知,全参数微调要比LoRA方式好的多,但在低资源的情况下也不失为一种选择.
LoRA允许我们通过优化密集层在适应过程中的变化的秩分解矩阵来间接地训练神经网络中的一些密集层, 而保持预训练的权重冻结
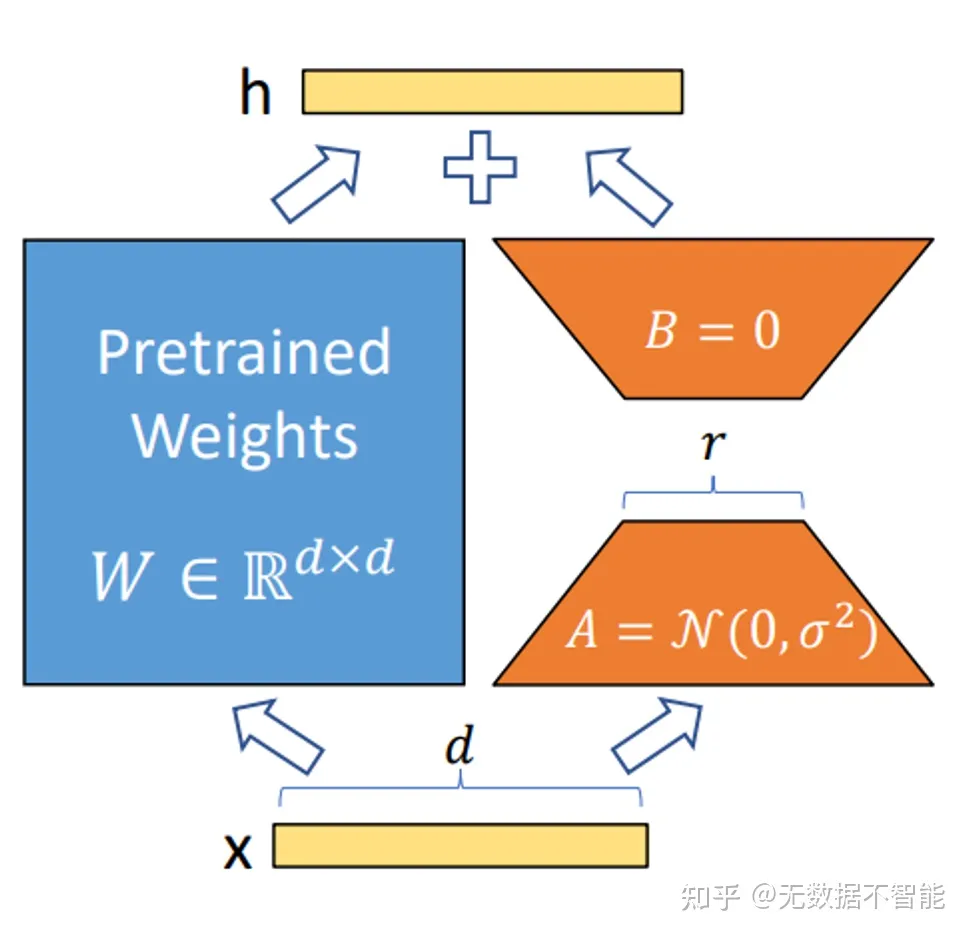
LoRA拥有几个关键优势。
- 一个预训练好的模型可以被共享, 用来为不同的任务建立许多小的LoRA模块。我们可以冻结共享模型, 并通过替换图1中的矩阵A和B来有效地切换任务, 从而大大减少存储需求和任务切换的开销。
- LoRA使训练更加有效, 在使用自适应优化器时, 硬件门槛降低了3倍, 因为我们不需要计算梯度或维护大多数参数的优化器状态。相反, 我们只优化注入的、小得多的低秩矩阵。
- 我们简单的线性设计允许我们在部署时将可训练矩阵与冻结权重合并, 与完全微调的模型相比, 在结构上没有引入推理延迟。
- LoRA与许多先前的方法是不相关的, 并且可以与许多方法相结合, 例如前缀微调。我们在附录E中提供了一个例子。
1.3.1 PEFT对LoRA的实现
以LORA为例, PEFT模型的使用非常方便, 只需要按照原本的方式实例化模型, 然后设置一下LORA的config, 调用一下get_peft_model方法, 就获得了在原模型基础上的PEFT模型, 对于LORA策略来讲, 就是在某些参数矩阵W的基础上增加了矩阵分解的旁支。
import torch
from peft import LoraConfig, get_peft_model
cls = torch.nn.Linear
lora_module_names = set()
for name, module in model.named_modules():
if isinstance(module, cls):
names = name.split('.')
lora_module_names.add(names[0] if len(names) == 1 else names[-1])
lora_config = LoraConfig(
r=args.lora_r,
lora_alpha=args.lora_alpha,
lora_dropout=args.lora_dropout,
bias="none",
task_type="CAUSAL_LM",
target_modules = list(lora_module_names)
# target_modules = ["c_proj", "c_attn", "q_attn"]
)
model = get_peft_model(model, lora_config)
Lora config相关的配置:
| 参数名 | 含义 |
|---|---|
| r | lora的秩, 矩阵A和矩阵B相连接的宽度, r«d |
| lora_alpha | 归一化超参数, lora参数Δ Wₓ 会被以α/r归一化, 以便减少改变r时需要重新训练的计算量 |
| lora_dropout | lora层的dropout比率 |
| merge_weights | eval模式中, 是否将lora矩阵的值加到原有W₀的值上 |
| fan_in_fan_out | 只有应用在Conv1D层时置为True, 其他情况False |
| bias | 是否可训练bias, none: 均不可; all: 均可; lora_only: 只有lora部分的bias可训练 |
| modules_to_save | 除了lora部分之外, 还有哪些层可以被训练, 并且需要保存 |
1.5 AdaLoRA
论文: https://arxiv.org/pdf/2303.10512.pdf
Code: https://github.com/QingruZhang/AdaLoRA
通过奇异值分解将权重矩阵分解为增量矩阵,并根据新的重要性度量动态地调整每个增量矩阵中奇异值的大小。这样可以使得在微调过程中只更新那些对模型性能贡献较大或必要的参数,从而提高了模型性能和参数效率。
# AdaLoraConfig需要使用peft的main分支----v3版本
peft_config = AdaLoraConfig(task_type="SEQ_CLS", inference_mode=False, r=8, lora_alpha=16, lora_dropout=0.1,
target_modules=["query", "value"])
model = AutoModelForSequenceClassification.from_pretrained(model_name_or_path, return_dict=True, num_labels=labels)
model = get_peft_model(model, peft_config)
1.6 QLoRA
论文: QLORA: Efficient Finetuning of Quantized LLMs
Code: https://github.com/artidoro/qlora
QLoRA, 它是一种"高效的微调方法”, 可以在保持完整的16位微调任务性能的情况下, 将内存使用降低到足以"在单个48GB GPU上微调650亿参数模型”。QLORA通过冻结的4位量化预训练语言模型向低秩适配器(LoRA)反向传播梯度。
1.7 奇异值微调
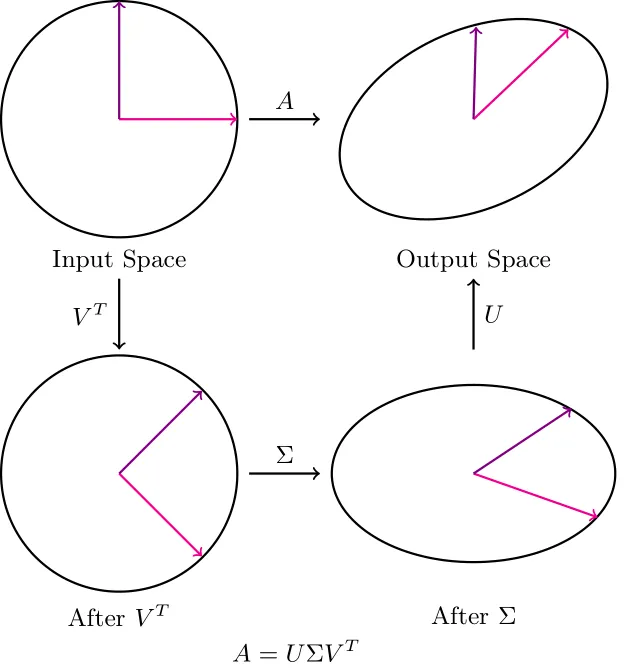
在 SVD 中, U 和 V 都旋转向量空间。我们这里感兴趣的主题是\(\sum\)矩阵。
请注意, 当 Σ 按向量的相应奇异值缩放向量时, 基向量与主轴(最大方差方向)对齐。因此, 更改缩放值可以看作是更改我们给任何特定主轴的权重量。
由于这些奇异值可以近似于不同"特征"的"重要性", 因此我们可以忽略 V 和 U 的变化。
因此, 我们只更新权重矩阵的奇异值, 同时微调网络, 这会导致需要训练的参数数量呈指数级减少。
这种方法的唯一缺点是, 当我们只训练前 k 个奇异值时, 可能会有一些信息丢失(取决于不同方向的方差的均匀程度)。
from transformers import AutoModelForCausalLM, AutoTokenizer
name = "Qwen/Qwen2.5-1.5B-Instruct"
model = AutoModelForCausalLM.from_pretrained(name)
tokenizer = AutoTokenizer.from_pretrained(name)
# SVD
from svd_training.svd_model import SVDForCausalLM
svd_model = SVDForCausalLM.create_from_model(model, rank_fraction=0.1)
print(f"trainable params: {svd_model.num_parameters(only_trainable=True)} || all params: {svd_model.num_parameters()} || trainable%: {svd_model.num_parameters(only_trainable=True) / svd_model.num_parameters()}")
2. 相关框架
2.1 DeepSpeed和LoRA
DeepSpeed 是一个深度学习优化库, 它使分布式训练变得简单、高效和有效。
DeepSpeed 的主要功能之一是 ZeRO, 它是 DP 的超级可扩展扩展。ZeRO Data Parallelism 中已经在前文讨论过了。通常它是一个独立的功能, 不需要 PP 或 TP。但可以与PP、TP结合使用。 当 ZeRO-DP 与 PP(和可选的 TP)结合时, 它通常只启用 ZeRO 阶段 1, 它只对优化器状态进行分片。 ZeRO 第 2 阶段还对梯度进行分片, 第 3 阶段也对模型权重进行分片。
2.2 petals
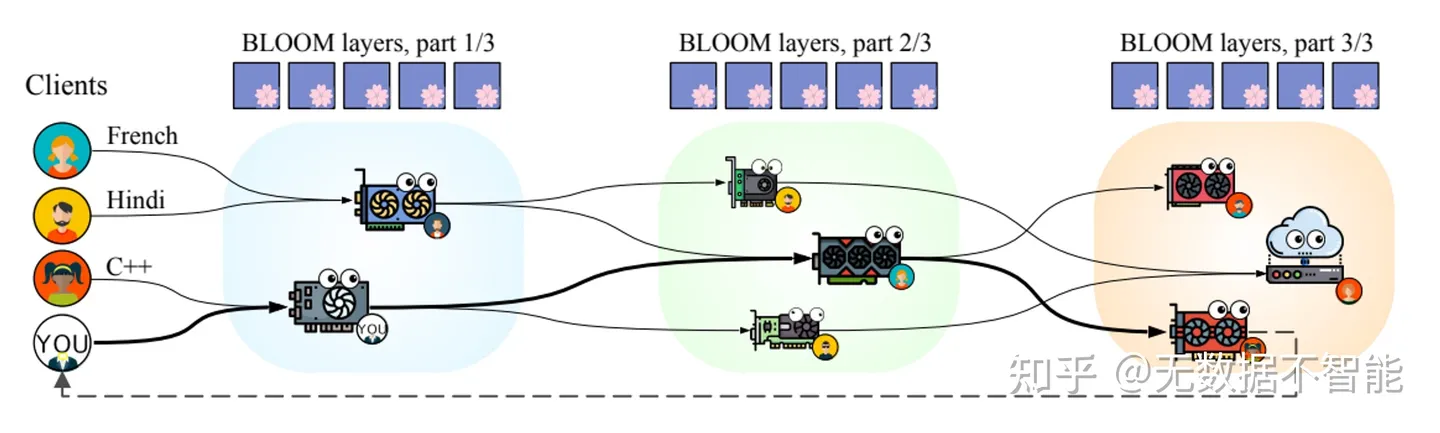
petals将模型划分为多个块,每个用户的机器负责其中一块,分摊了计算压力,类似于某磁力链接下载工具,利用hivemind库进行去中心化的训练与推理。当然你也可以创建自己局域网的群组,对自己独有的模型进行分块等自定义操作。
2.3 Transformers
2.4 Megatron-LM
Megatron-LM 是由 NVIDIA 的应用深度学习研究团队开发的大型、强大的 Transformer 模型框架。它基于PyTorch的框架,用于训练基于Transformer架构的巨型语言模型。它实现了高效的大规模语言模型训练,主要通过以下几种方式:
- 模型并行: 将模型参数分散在多个GPU上,减少单个GPU的内存占用23。
- 数据并行: 将数据批次分散在多个GPU上,增加训练吞吐量4。
- 混合精度: 使用16位浮点数代替32位浮点数,减少内存和带宽需求,提高计算速度4。
- 梯度累积: 在多个数据批次上累积梯度,然后再更新参数,降低通信开销4。
- Megatron-LM还可以与其他框架如DeepSpeed结合,实现更高级的并行技术,如ZeRO分片和管道并行5。这样可以进一步提升训练效率和规模。
git clone https://github.com/huggingface/transformers.git
git clone https://github.com/NVIDIA/Megatron-LM.git
# 如果Megatron-DeepSpeed, 需要对应的, 例如:
# git clone https://github.com/bigcode-project/Megatron-LM
export PYTHONPATH=Megatron-LM
python transformers/src/transformers/models/megatron_gpt2/convert_megatron_gpt2_checkpoint.py <path-to-checkpoint>/model_optim_rng.pt
2.5 Megatron-DeepSpeed
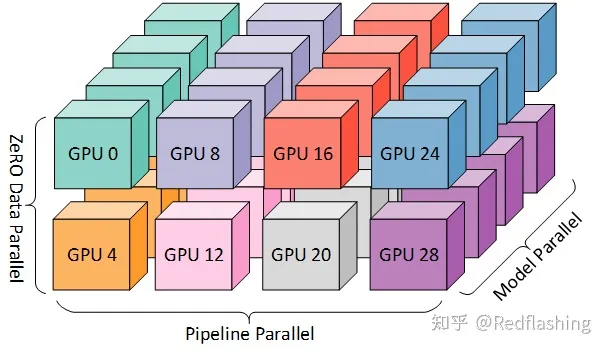
DeepSpeed 团队通过将 DeepSpeed 库中的 ZeRO 分片(ZeRO sharding)和管道并行(pipeline parallelism)与 Megatron-LM 中的张量并行(Tensor Parallelism)相结合, 开发了一种基于 3D 并行的实现。下文会更为详细介绍这些技术。
Megatron-DeepSpeed 实施 3D 并行以可以让大型模型以非常有效的方式进行训练。
- DataParallel (DP) - 相同的初始化模型被复制多次, 并且每次都被馈送 minibatch 的一部分。处理是并行完成的, 所有设置在每个训练步骤结束时进行同步。
- TensorParallel (TP) - 每个张量都被分成多个块, 因此不是让整个张量驻留在单个 GPU 上, 而是张量的每个分片都驻留在其指定的 GPU 上。在处理过程中, 每个分片在不同的 GPU 上分别并行处理, 最终结果在步骤结束时同步。这也被称作横向并行。
- PipelineParallel (PP) - 模型在多个 GPU 上垂直(层级)拆分, 因此只有模型的一个或多个层放置在单个 GPU 上。每个 GPU 并行处理管道的不同阶段, 并处理一小部分批处理。
- 零冗余优化器 (ZeRO) - 也执行与 TP 有点类似的张量分片, 除了整个张量会及时重建以进行前向或反向计算, 因此不需要修改模型。它还支持各种卸载技术以补偿有限的 GPU 内存。
为了获得更高效的训练, PP 与 TP 和 DP 相结合, 称为 3D 并行性:
2.6 其他
2.6.1 AutoTrain
Github: https://github.com/huggingface/autotrain-advanced
Documentation: https://hf.co/docs/autotrain/
AutoTrain Advanced: 更快、更轻松地训练和部署最先进的机器学习模型。AutoTrain Advanced 是一种无代码解决方案, 只需单击几下即可训练机器学习模型。请注意, 您必须以正确的格式上传数据才能创建项目。有关正确数据格式和定价的帮助, 请查看文档。
AutoTrain 支持各种类型的 sentence transformer 微调任务:
- pair: 包含两个句子的数据集: anchor 和 positive。
- pair_class: 包含两个句子的数据集: 带有目标标签的前提和假设。
- pair_score: 包含两个句子的数据集: sentence1 和 sentence2, 以及目标分数。
- triplet: 包含三个句子的数据集: anchor、positive 和 negative。
- qa: 包含两个句子的数据集: query 和 answer。
3. Merge
3.1 Merge Model
解决方案涉及通过在微调期间添加新层来扩展模型的架构, 并在保持原始层固定的同时仅解锁这些新层。
使用 mergekit(https://github.com/arcee-ai/mergekit).使用以下设置。解冻和训练仅添加的层是一项简单的任务。
通常, 变压器模块的开头和结尾包含模型的关键信息。
slices:
- sources:
- model: meta-llama/Meta-Llama-3-8B-Instruct
layer_range: [0, 20]
- sources:
- model: meta-llama/Meta-Llama-3-8B-Instruct
layer_range: [12, 32]
merge_method: passthrough
dtype: bfloat16
3.1.1 Copy Layer
import torch
from transformers import BertModel
def copy_layer(source_layer, target_layer):
for name, param in source_layer.named_parameters():
target_param = target_layer.get_parameter(name)
target_param.data.copy_(param.data)
# Create a source model
source_model = BertModel.from_pretrained('bert-base-uncased')
# Create a target model with the same architecture
target_model = BertModel(source_model.config)
# Copy the layers from the source model to the target model
for source_layer, target_layer in zip(source_model.encoder.layer, target_model.encoder.layer):
copy_layer(source_layer, target_layer)
# Verify that the layers are copied correctly
for source_layer, target_layer in zip(source_model.encoder.layer, target_model.encoder.layer):
for source_param, target_param in zip(source_layer.parameters(), target_layer.parameters()):
assert torch.equal(source_param, target_param)
print("Layer copying completed successfully!")
3.2 Mergekit
模型合并是一种将两个或多个法学硕士合并为一个模型的技术。这是一种相对较新的实验性方法, 可以廉价地创建新模型(不需要 GPU)。模型合并的效果出人意料地好, 并在Open LLM 排行榜上产生了许多最先进的模型。这些通常被称为 frankenMoE 或 MoErges, 以区别于预先训练的 MoE。
真正的 MoE 和 frankenMoE 之间的主要区别在于它们的训练方式。在真正的MoE的情况下, 专家和路由器是联合培训的。在frankenMoE的情况下, 我们对现有模型进行升级改造, 然后初始化路由器。
mergekit是一个用于合并预先训练的语言模型的工具包, 使用多种合并方法, 包括 TIES、线性和 slerp 合并。该工具包还可以使用从其他模型中选择的层来分段组装语言模型。
Paper: Arcee’s MergeKit: A Toolkit for Merging Large Language Models
3.2.1 合并算法
mergekit目前实现四种方法:
- SLERP
SLERP是目前最流行的合并方法, 但它仅限于一次只能合并两个模型。仍然可以分层组合多个模型, 如Mistral-7B-Merge-14-v0.1中所示。
slices:
- sources:
- model: OpenPipe/mistral-ft-optimized-
layer_range: [0, 32]
- model: mlabonne/NeuralHermes-2.5-Mistral-7B
layer_range: [0, 32]
merge_method: slerp
base_model: OpenPipe/mistral-ft-optimized-
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
-
TIES
TIES-Merging旨在有效地将多个特定于任务的模型合并为单个多任务模型。 -
DARE
DARE使用与 TIES 类似的方法, 但有两个主要区别:- 修剪: DARE 将微调权重随机重置为其原始值(基本模型的权重)。
- 重新调整: DARE 重新调整权重以保持模型输出的期望大致不变。它将两个(或多个)模型的重新调整后的权重添加到具有比例因子的基本模型的权重中。
-
Passthrough
直通方法与之前的方法有很大不同。通过连接来自不同 LLM 的层, 它可以生成具有大量参数的模型(例如, 具有两个 7B 参数模型的 9B)。这些模型通常被社区称为"弗兰肯合并"或"弗兰肯斯坦模型"。
3.3 medusa
Medusa 为 LLM 添加了额外的"头", 以同时预测多个未来代币。当使用 Medusa 增强模型时, 原始模型保持不变, 只有新的头部在训练过程中进行微调。在生成过程中, 这些头每个都会为相应位置生成多个可能的单词。然后使用基于树的注意力机制组合和处理这些选项。最后, 采用典型的接受方案从候选者中挑选最长的合理前缀以进行进一步解码。
3.4 Mergoo
博客: https://huggingface.co/blog/alirezamsh/mergoo
Github: https://github.com/Leeroo-AI/mergoo
在mergoo中, 通过整合多个开源LLM专家的知识, 轻松构建自己的 MoE LLM:
- 支持 Mixture-of-Experts、Mixture-of-Adapters(新功能)和 Layer-wise merge
- 高效训练您的 MoE 风格合并 LLM, 无需从头开始
- 兼容 Hugging Face 模型和训练
5. 相关数值理解
5.1 查看参数
# 可训练
for name, param in model.named_parameters():
if param.requires_grad:
print(name)
# 查看网络总参数
model = Model()
print('# Model parameters:', sum(param.numel() for param in model.parameters()))
5.2 理解loss和val_loss
loss: 训练集的损失值; val_loss: 测试集的损失值。
一般训练规律:
- loss下降, val_loss下降: 训练网络正常, 最理想情况情况。
- loss下降, val_loss稳定: 网络过拟合。解决办法: ①数据集没问题: 可以向网络"中间深度"的位置添加Dropout层; 或者逐渐减少网络的深度(靠经验删除一部分模块)。②数据集有问题: 可将所有数据集混洗重新分配, 通常开源数据集不容易出现这种情况。
- loss稳定, val_loss下降: 数据集有严重问题, 建议重新选择。一般不会出现这种情况。
- loss稳定, val_loss稳定: 学习过程遇到瓶颈, 需要减小学习率(自适应动量优化器小范围修改的效果不明显)或batch数量。
- loss上升, val_loss上升: 可能是网络结构设计问题、训练超参数设置不当、数据集需要清洗等问题。属于训练过程中最差情况。
5.3 调大batch_size对网络训练的影响
优点:
- 内存的利用率提高了, 大矩阵乘法的并行化效率提高
- 跑完一次epoch(全数据集)所需迭代次数减少, 对于相同的数据量的处理速度进一步加快
- 一定范围内, batchsize越大, 其确定的下降方向就越准, 引起训练震荡越小
- batchsize增大, 处理相同的数据量的速度越快
缺点
- 内存消耗严重, 面临显卡内存不足问题
- 训练速度慢, loss不容易收敛
- batch_size过大导致网络收敛到局部最优点, loss下降不再明显
- batchsize增大, 达到相同精度所需要的epoch数量越来越多
5.4 loss不收敛
此处包含两种情况,一种是loss一直在震荡,一种是loss下降一点后不再下降到理想水平,而验证集上的表现保持不变.
- 保持需要的batchsize不变;
- 查看是否有梯度回传
- 查看数据是否有问题,如标签错乱等现象;
- 调节学习率,从大向小调,建议每次除以5;我的项目即是因为学习率过大过小都不收敛引起的;
- 如果学习率调好后,需要调节batchsize大小,如batchsize调大2倍,则将学习率对应调大(项目测试调大2~3倍OK),反之,学习率对应调小
6. 其他
6.1 术语
- perform fullparameter fine-tuning (FFT)
- parameter-efficient fine-tuning (PEFT)
6.2 代码大模型的微调
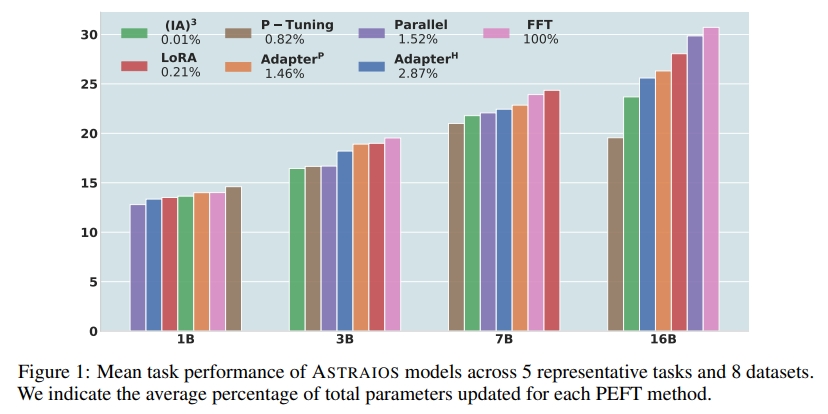
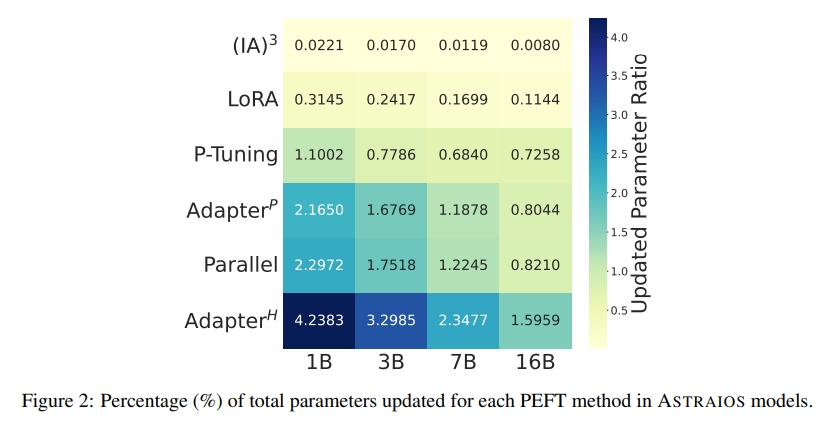
Paper:Astraios: Parameter-Efficient Instruction Tuning Code Large Language Models
论文介绍了Astraios, 一个使用7种微调方法和4种模型规模的28个指令调整的OctoCoder模型套件, 通过对5个任务和8个不同数据集的研究, 发现全参数微调通常在所有规模下都能提供最佳的下游性能, 而参数高效微调方法在模型规模不同时的效果有很大差异。LoRA通常提供了最有利的成本和性能平衡。
论文使用了多个数据集和任务, 对比了不同微调方法和模型规模的性能表现, 并探究了这些方法对模型鲁棒性和代码安全性的影响。实验结果显示, LoRA通常提供了最佳的成本和性能平衡。
6.3 LLM Twin 架构
- 数据收集管道: 从各种社交媒体平台抓取您的数字数据。通过一系列 ETL 管道清理、规范化数据并将其加载到 NoSQL 数据库。使用 CDC 模式将数据库更改发送到队列。
- 功能流水线: 通过 Bytewax 流式流水线使用队列中的消息。每条消息都将被清理、分块、嵌入(使用 Superlinked), 并实时加载到 Qdrant 向量数据库中。
- 训练管道: 基于数字数据创建自定义数据集。 使用 QLoRA 微调 LLM。使用 Comet ML 的实验跟踪器来监控实验。评估最佳模型并将其保存到 Comet 的模型注册表中。
- 推理管道: 从 Comet 的模型注册表中加载并量化微调的 LLM。将其部署为 REST API。使用 RAG 增强提示。使用 LLM 孪生生成内容。使用 Comet 的提示监视仪表板监视 LLM。
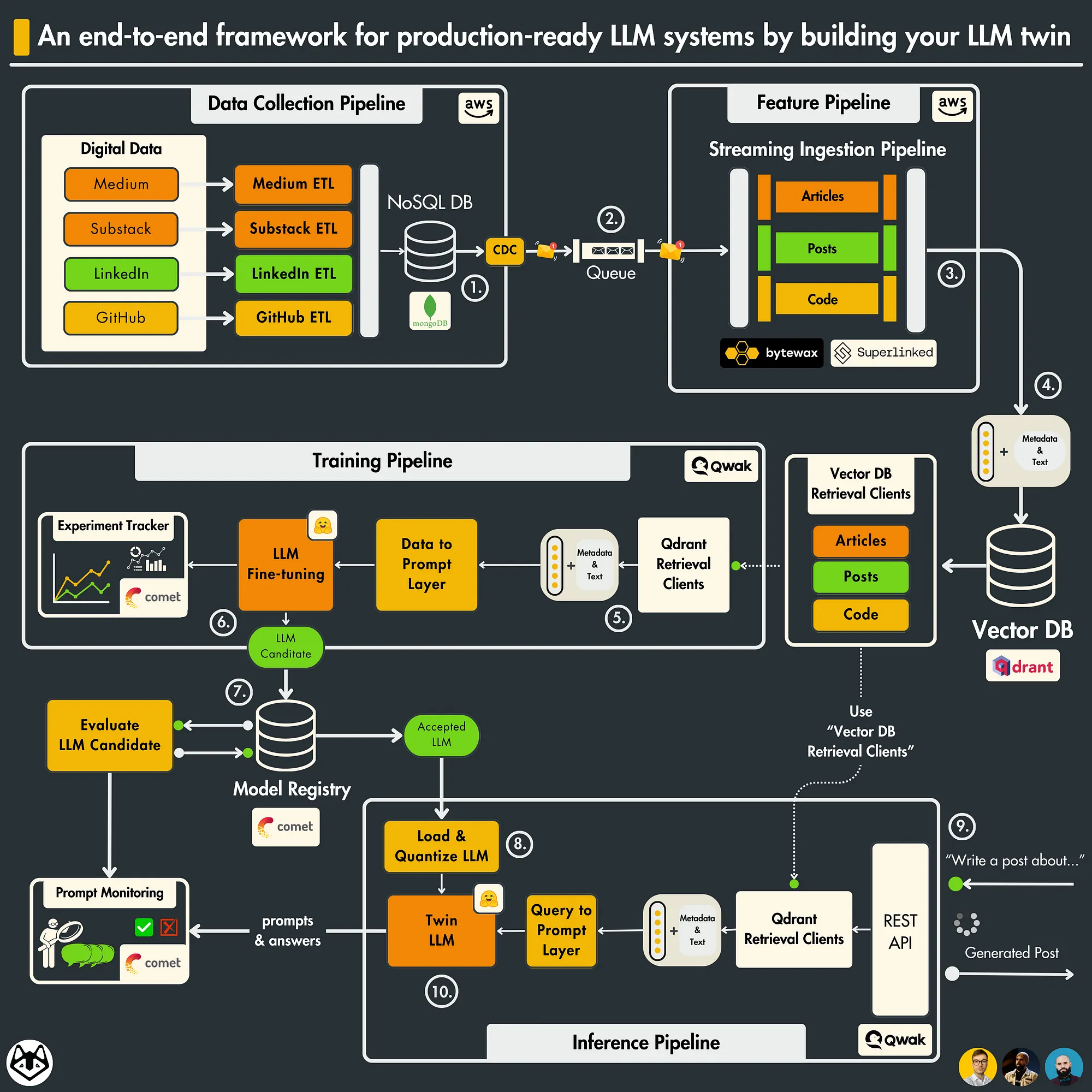
除了 4 个微服务, 还需要了解 3 个无服务器工具
- Comet ML作为ML平台;
- Qdrant 作为向量数据库;
- Qwak 作为 ML 基础设施;
6.4 BF16Optimizer
在 FP16 中训练巨大的 LLM 模型是一个禁忌(在 FP16 训练会导致数值不稳定, 或者不能产生足够的精度使模型正确收敛 )。
BF16 格式的关键是具有与 FP32 相同的指数位, 因此不会与 FP16 一样容易溢出, 使用最大数值范围为 64k 的 FP16, 只能乘以小范围的数。例如可以做 250250=62500, 但如果你尝试 255255=65025, 结果就会溢出, 这是导致训练期间出现主要问题的原因。这意味着你的权重必须保持很小。一种称为损失缩放的技术可以帮助解决这个问题, 但是当模型变得非常大时, FP16 的有限范围仍然是一个问题。 BF16 就没有这个问题, 可以轻松做到 10 000*10 000=100 000 000 当然, 由于 BF16 和 FP16 的大小相同, 均为 2 个字节, 因此, 当使用 BF16 时, 它的劣势也会暴露: 精度非常差。 无论使用 BF16 还是 FP16, 都有一个权重副本始终在 FP32 中——这是由优化器更新的内容。因此 16 位格式仅用于计算, 优化器以全精度 FP32 更新权重, 然后将它们转换为 16 位格式以用于下一次迭代。
6.5 NCCL
NCCL 全称 Nvidia Collective multi-GPU Communication Library , 是一个实现多 GPU 的collective communication 通信(all-gather, reduce, broadcast)库, Nvidia 做了很多优化, 可以在 PCIe、Nvlink、InfiniBand 上实现较高的通信速度。
NCCL 具有以下技术特性:
- 高性能: NCCL 方便地消除了开发人员针对特定机器优化应用程序的需要。 NCCL 在节点内和跨节点的多个 GPU 上提供快速集合。
- 易于编程: NCCL 使用一个简单的 C API, 可以很容易地从各种编程语言中访问。NCCL 紧跟由 MPI(消息传递接口)定义的流行的集合 API。
- 兼容性: NCCL 几乎与任何多 GPU 并行化模型兼容, 例如: 单线程、多线程(每个 GPU 使用一个线程)和多进程(MPI 与 GPU 上的多线程操作相结合)。
6.6 torchtune vs axolotl vs unsloth Trainer Performance Comparison
参考: torchtune vs axolotl vs unsloth Trainer Performance Comparison
参考:
大模型训练之微调篇
[译] DeepSpeed: 所有人都能用的超大规模模型训练工具
Optimizer state sharding (ZeRO)
DeepSpeed Integration
Megatron-LM 论文
提示学习Prompt Tuning: 面向研究综述
Prompt Tuning里程碑作品: The Power of Scale for Parameter-Efficient Prompt Tuning
大模型训练——PEFT与LORA介绍
QLoRA: 一种高效LLMs微调方法, 48G内存可调65B 模型, 调优模型Guanaco 堪比Chatgpt的99.3%!
P-tuning V2论文和代码实现解析
LLM/a0——–高效调参____PEFT库简介及使用
Relation Extraction with Llama3 Models
使用 mergekit 合并大型语言模型
使用 Sentence Transformers v3 训练和微调嵌入模型
How to Fine-Tune Custom Embedding Models Using AutoTrain
Training language models to follow instructions with human feedback
Transformer²: The Death of LoRA?
