
目录
1. Thrift框架
Thrift是Facebook开源出来的通信服务框架, 典型的C/S架构模式, 支持跨语言编程, 例如Java, C++, Python等主流语言, 能够友好地解决各大系统的数据通信问题和多种语言运行环境不同所引起的信息交互问题。
Thrift采用一种IDL编码通信的方式, 跟业界在以前通常采用的CORBA通信协议标准方式有点类似。它通过创建IDL文件, 生成并编写相关代码文件, 实现其相关的代码, 编译装载即可使用。
Thrift通信框架的编码架构是一种层级的架构, 主要是分5层: 网络通信层(Socket), 传输层(TTransport), 协议层(TProtocol), 和接口实现层(Interface),业务逻辑层(Business)。如下图:
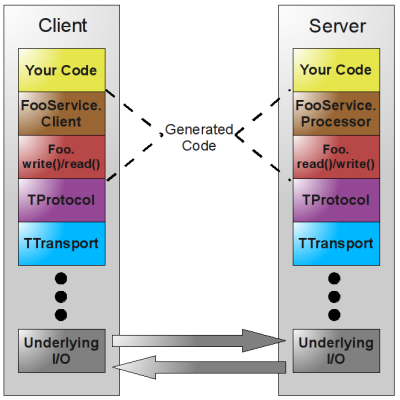
Thrift实现了多种类型的TProtocol和TTransport。
1.1 TProtocol 协议
TProtocol是用来序列化数据结构写入到TTransport中, 或者是把从TTransport中读出来二进制流反序列化成结构化的数据。它的实现有TBinaryProtocol, TCompactProtocol, TJSONProtocol, TSimpleJSONProtocol, TTupleProtocol等。
- TBinaryProtocol: 把数据结构转换成二进制流的方式, 在该层没有进行相关数据的压缩。
- TCompactProtocol: 把数据结构换一定的规则进行压缩, 减少二进制流的大小。主要从以下两个方面入手:
- 尽量使用变长的整数
- 对于复杂的结构(例如嵌套, 多属性, 短字符串, 集全, 值比较小的整形或长整形。
1.2 TTransport 协议
TTransport封装了Socket通信的细节, 提供了多种通信方式, 例如TSocket, TFramedTransport, TFileTransport, TMemoryInputTransport, TZibTransport等。
- TSocket: 是一种典型的阻塞式I/O传输模式。在Java实现中, TSocket继承了TIOStreamTransport类, 该类就管理着输入输出流。其中TServerSocket继承TServerTransport类, 用于服务端, 当客户端有请求是就会创建一个TSocket与客户端进行通信。因此这种很适合于流式传输的C/S通信方式, 当然其它的TTransport也可以调用这种方式。
- TFramedTransport: 可以采用非阻塞的方式进行块大小的传输。
- TFileTransport: 采用文件传输方式。
1.3 TServer 服务
Thrift也提供TServer类用于启动服务, 其有三种实现方式, 其中一种是TSimpleServer, TThreadedSelectorServer, THsHaServer等。
2. HBase Thrift服务
上面我们大概地介绍了一下Thrift框架的结构, 下面我们具体分析一下在HBase里面的Thrift服务性能。
HBase把Thrift结合起来可以向外部应用提供HBase服务。由于HBase本来就自带有JAVA Client API接口, 因此它主要方便其它语言使用HBase。
HBase实现了两套Thrift Server服务, 有两种Thrift IDL文件, 提供了两套数据结构:
- 第一套有TCell, ColumnDescriptor, TRegionInfo等, 它的API比较全, 它不仅有读写API, 同时也有创建删除等API;
- 第二套有TTimeRange, TColumn, TColumnValue等, 它更加接近HBase Java API的调用方式, 但是它的API比较少, 只有读写表的API), 它们最后都是通过HBase Client的Java API来完成操作。
分析HBase Thrift的读写性能, 主要从以下三大方面入手: 请求延迟量(Latency)、系统吞吐量(TPS)、每秒调用数(RPC), 并且尽量找出它的应用瓶颈所在。在此, 它会与HBase原生提供的Java API做对比。
测试环境为: 在一个机房里, 共有30台服务器位于同一个交换机之下。它们搭有Hadoop 1.0.3和HBase 0.9.4的分布式存储计算集群。其中有一台机器上搭有ThriftServer, 命为Thrift 2, 有一台机器专门用作访问Thrift和HBase的客户端。机器的配置都是统一的: 48G内存, 1000M的网卡, 8个核, 每个核都能开启超线程。
我们将对HBase的API和Thrift接口进行测试, 涉及到随机写(randomWrite), 随机读(randomRead), 顺序写(sequentialWrite), 顺序读(sequentialRead), 批量读(scan)。每个线程会操作1G的数据。下图的测试数据是不同的线程数下的测试结果。
2.1 总时长

2.2 单请求Latency

2.3 吞吐量Throughput

2.4 每秒请求数RPS

从表中可以看出, 这5类操作的测试结果所显示的图形都不一样。
3. 测试总结
3.1 SequentialWrite(RandomWrite):
在单线程的情况下, API的Latency达到0.04毫秒(0.02毫秒), 而thrift2就达到了1.64毫秒(2.08毫秒), 它们之间的差别有40(>100)倍。
随着线程数据 的增加, latency不断的变大, 而randomWrite API明显比sequential API的latency增大快些。
3.2 SequentialRead(randomRead):
在单线程的情况下, API和和thrift2的差别是不到2倍。而且比起SequentialWrite(RandomWrite), 它们所耗时间有7至25倍。
3.3 Scan:
Scan的访问速度介于写于读之间, 它比sequentialWrite/randomWrit慢些, 而比sequentialRead/randomRead快些。
4. 测试结果分析
4.1. Write 比Read 快原因分析
4.1.1 写操作
在HBase里面做put、delete、increment等变更操作时, 通常都会记录一下WAL。因此在变更操作时主要有两步: 写WAL和写MemStore。从常识和经验来说, 写MemStore就是写内存, 这是很快的; 但是写WAL是写HDFS, 而且是写远程的硬盘, 这应该不会快到哪里去的, 即使是是通过异步写WAL时也需要等待写HDFS成功的返回值。仔细分析一下源代码可以发现: RegionServer启了一个后台的线程LogSyncer, 它是在有数据时不断地循环地作sync操作, 而变更操作对WAL主动调用sync函数时很少去完成做真正的sync操作, 它会经常去比较txid值的大小, 当小于syncedTillHere值时就直接返回了。
写操作的关键代码如下:
private void syncer(long txid) throws IOException {
Writer tempWriter;
synchronized (this.updateLock) {
if (this.closed) return;
tempWriter = this.writer; // guaranteed non-null
}
// if the transaction that we are interested in is already
// synced, then return immediately.
if (txid <= this.syncedTillHere) { //比较
return;
}
try {
long doneUpto;
long now = System.currentTimeMillis();
// First flush all the pending writes to HDFS. Then
// issue the sync to HDFS. If sync is successful, then update
// syncedTillHere to indicate that transactions till this
// number has been successfully synced.
synchronized (flushLock) {
if (txid <= this.syncedTillHere) { //比较
return;
}
doneUpto = this.unflushedEntries.get();
List<Entry> pending = logSyncerThread.getPendingWrites();
try {
logSyncerThread.hlogFlush(tempWriter, pending);
} catch(IOException io) {
synchronized (this.updateLock) {
// HBASE-4387, HBASE-5623, retry with updateLock held
tempWriter = this.writer;
logSyncerThread.hlogFlush(tempWriter, pending);
}
}
}
// another thread might have sync'ed avoid double-sync'ing
if (txid <= this.syncedTillHere) { //比较
return;
}
try {
tempWriter.sync();
} catch(IOException io) {
synchronized (this.updateLock) {
// HBASE-4387, HBASE-5623, retry with updateLock held
tempWriter = this.writer;
tempWriter.sync();
}
}
//更新syncedTillHere
this.syncedTillHere = Math.max(this.syncedTillHere, doneUpto);
syncTime.inc(System.currentTimeMillis() - now);
if (!this.logRollRunning) {
checkLowReplication();
try {
if (tempWriter.getLength() > this.logrollsize) {
//LogRoller
requestLogRoll();
}
} catch (IOException x) {
LOG.debug("Log roll failed and will be retried. (This is not an error)");
}
}
} catch (IOException e) {
LOG.fatal("Could not sync. Requesting close of hlog", e);
requestLogRoll();
throw e;
}
}
在这里有优化的地方, 就是后台进程LogSyncer在等待wait时, 如果有数据写进共享List里面, 可以让他唤醒该LogSyncer进程。这样可以进一步提高写的速度。
下图列出10000次写操作时所耗时间, 通过R语言把它画出来的。
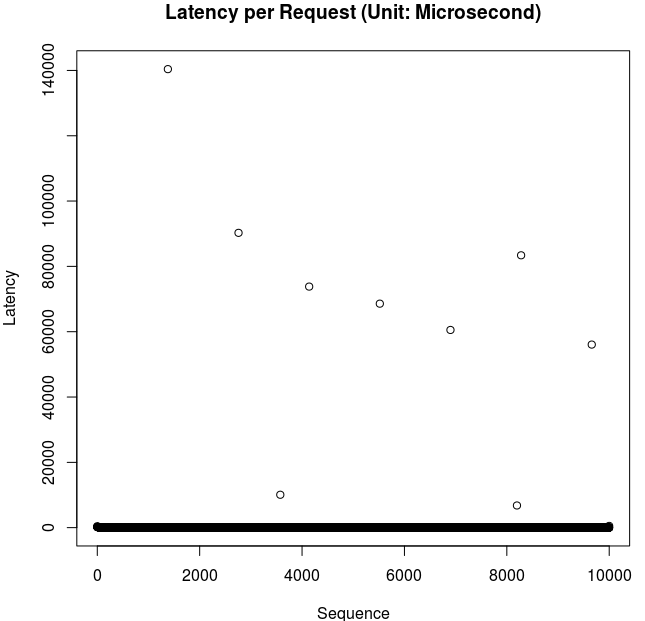
从图表中可以看出, 这1万个请求只有少数几个是该请求直接sync到HDFS上的。概率为1/1000左右。
因此如果批量异步地sync的HDFS里的速度极快的话, 那么这种写速度大于读速度是完全有可能的。测试WAL写HDFS的性能, 参数是value长度是1000 bytes, 迭代1024*1024次, 异步写HLog:
hbase org.apache.hadoop.hbase.regionserver.wal.HLogPerformanceEvaluation -path /user/hbase/aa -nosync -valueSize 1000 -iterations 1048576
测试结果是平均总耗时长是20到25秒。RPS可以达到[40000, 50000]ops/second。 性能相当可观。
4.1.2 读操作
在HBase中的读操作和scan操作时, 在Regionserver里的业务逻辑都是一样的, Get操作就是一个特殊情况下的scan, 其startKey和endKey都一样的。都是进行一堆的Scanner进行操作, 先到Memstore和CacheConfig中找, 如果没有在内存中命中则会把相应的dataBlock相应加载到CacheBlock中。而加载到内存中是需要一定的时间的。下图是顺序读时的latency。
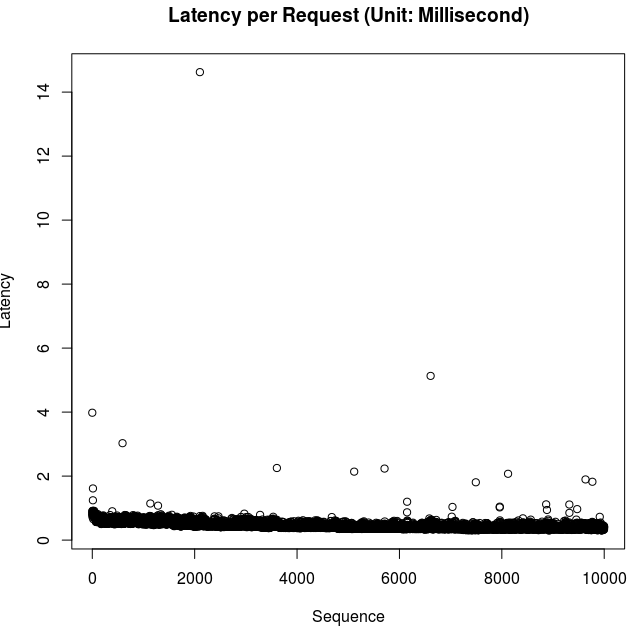
从图中, 可以看出, 大多数请求都在0.5毫秒到1毫秒之间。同时有一定数目的请求latency长是可能因为没有在内存中命中引起的。
在这里我们分析一下scan操作和Get操作在client端的业务逻辑, 它们在客户端里的业务逻辑就不一样了。
5. hbase监控项
Hadoop 系统都提供了丰富的 JMX 监控项, 所以我们可以直接从 HBase 系统本身提供的 JMX 信息获取我们需要的监控项。 HBase 提供的 JMX 信息的 web 页面, 地址就是 http://host:16010/jmx , JMX web页面的数据格式是 json 格式。由于信息比较多, 也提供了一个qry=name的方式获取具体某一项所需的数据, 例如: http://host:16010/jmx?qry=Hadoop:service=HBase,name=Master,sub=Server
JMX: Java Management Extensions, 用于用于Java程序扩展监控和管理项
GC: Garbage Collection, 垃圾收集, 垃圾回收机制
主机基本监控项
CPU, 内存, 磁盘, 网络 主机四大基本监控项, 这4项机器监控保证我们运行我们HBase集群的机器是正常的。
5.1 指标项说明
| 指标项 | 说明 |
|---|---|
| FreePhysicalMemorySize | 空闲物理内存大小 |
| ProcessCpuLoad | 进程cpu使用率 |
| SystemCpuLoad | 系统cpu使用率 |
| AvailableProcessors | 处理器核数 |
5.2 JVM监控项
HBase 集群涉及的系统 HDFS, HBase, ZooKeeper都是用 Java 编写的, 运行在 JVM 中, 必须采集 JVM 相关的监控项。Hbase 中对于 JVM 的监控数据, 主要是 JvmMetrics 的对象来进行的。
| 类型 | 指标项 | 说明 |
|---|---|---|
| 内存 | MemNonHeapUsedM | JVM 当前已经使用的 NonHeapMemory 的大小 |
| 内存 | MemNonHeapMaxM | JVM 配置的 NonHeapMemory 的大小 |
| 内存 | MemHeapUsedM | JVM 当前已经使用的 HeapMemory 的大小 |
| 内存 | MemHeapMaxM | JVM 配置的 HeapMemory 的大小 |
| 内存 | MemMaxM | JVM 运行时的可以使用的最大的内存的大小 |
| GC | GcCountParNew | 新生代GC次数 |
| GC | GcTimeMillisParNew | 新生代GC耗时(ms) |
| GC | GcCountConcurrentMarkSweep | 老年代GC次数 |
| GC | GcTimeMillisConcurrentMarkSweep | 老年代GC耗时 |
| 线程 | ThreadsNew | 当前线程的处于 NEW 状态下的线程数量 |
| 线程 | ThreadsRunnable | 当前线程的处于 RUNNABLE 状态下的线程数量 |
| 线程 | ThreadsBlocked | 当前线程的处于 BLOCKED 状态下的线程数量 |
| 线程 | ThreadsWaiting | 当前线程的处于 WAITING 状态下的线程数量 |
| 线程 | ThreadsTimedWaiting | 当前线程的处于 TIMED_WAITING 状态下的线程数量 |
| 线程 | ThreadsTerminated | 当前线程的处于 TERMINATED 状态下的线程数量 |
| 事件 | LogFatal | 固定时间间隔内的 Fatal 的数量 |
| 事件 | LogError | 固定时间间隔内的 Error 的数量 |
| 事件 | LogWarn | 固定时间间隔内的 Warn 的数量 |
| 事件 | LogInfo | 固定时间间隔内的 Info 的数量 |
5.3 HBase集群各系统存活监控项
HBase集群各个系统的进程是否存活是必须也是最基本的监控项。具体有hmaster; regionserver; namenode; datanode; journalnode; zkfc; zookeeper的存活监控。具体判断存活的方式我们可以去判断各系统相应的进程是否存在, 也可以去判断各系统的web页面或者jmx页面是否正常。
master监控: http://host:16010/jmx?qry=Hadoop:service=HBase,name=Master,sub=Server
| 指标项 | 说明 |
|---|---|
| tag.liveRegionServers | 活动的region |
| tag.deadRegionServers | 停止的region |
5.4 regionserver监控
我们可以用多线程或多进程同时采集多个指标项, 同时也要注意在每个线程处理的时候数据应该是异步的, 否则同步可能导致某一个指标项采集阻塞, 使得之后的所有指标项在一个采集周期内无法正常返回数据。
地址:
http://host02:16030/jmx?qry=Hadoop:service=HBase,name=RegionServer,sub=Regions
http://host03:16030/jmx?qry=Hadoop:service=HBase,name=RegionServer,sub=Regions
| 指标项 | 说明 |
|---|---|
| Namespace_xxx_table_xxx_region_xxx_metric_storeCount | Store个数 |
| Namespace_xxx_table_xxx_region_xxx_metric_storeFileCount | StoreFile个数 |
| Namespace_xxx_table_xxx_region_xxx_metric_memStoreSize | |
| Namespace_xxx_table_xxx_region_xxx_metric_storeFileSize | |
| Namespace_xxx_table_xxx_region_xxx_metric_compactionsCompletedCount | 合并完成次数 |
| Namespace_xxx_table_xxx_region_xxx_metric_numBytesCompactedCount | 合并文件总大小 |
| Namespace_xxx_table_xxx_region_xxx_metric_numFilesCompactedCount | 合并完成文件个数 |
| 指标项 | 类型 | 说明 |
|---|---|---|
| regionCount | Server | Regionserver管理region数量 |
| memStoreSize | Server | Regionserver管理的总memstoresize |
| storeFileSize | Server | Regionserver管理的storefile大小 |
| staticIndexSize | Server | regionserver所管理的表索引大小 |
| storeFileCount | Server | regionserver所管理的storefile个数 |
| hlogFileSize | Server | WAL文件大小 |
| hlogFileCount | Server | WAL文件个数 |
| storeCount | Server | regionserver所管理的store个数 |
| storeFileCount | Server | regionserver所管理的storefile个数 |
| totalRequestCount | Server | 总请求数 |
| readRequestCount | Server | 读请求数 |
| writeRequestCount | Server | 写请求数 |
| compactedCellsCount | Server | 合并cell个数 |
| majorCompactedCellsCount | Server | 大合并cell个数 |
| flushedCellsSize | Server | flush到磁盘的大小 |
| splitRequestCount | Server | region分裂请求次数 |
| splitSuccessCount | Server | region分裂成功次数 |
| slowGetCount | Server | 请求完成时间超过1000ms的次数 |
| numOpenConnections | IPC | 该regionserver打开的连接数 |
| numActiveHandler | IPC | rpc handler数 |
| receivedBytes | IPC | 收到数据量 |
| sentBytes | IPC | 发出数据量 |
| SyncTime_mean | WAL | WAL写hdfs的平均时间 |
| HeapMemoryUsage»used | Memory | 堆内存使用量 |
| Par Survivor Space»CollectionUsage»used | MemoryPool | Survivor内存大小 |
| Par Eden Space»CollectionUsage»used | MemoryPool | Eden区使用空间大小 |
| CMS Old Gen»CollectionUsage»used | MemoryPool | 老年代内存大小 |
5.5 hbase监控工具
hbase原生支持ganglia, 如果发送给zabbix, 需要自己开发获取其中的数据, 解析出来。数据的格式一般是最外层一个beans的key, 里面的value是一个jsonarray。arrayobject里面可能包含jsonobjec或者jsonarray。
目前测试集群使用jmxtrans+influxdb+granafa套件监控。
监控地址: http://dev01:3000/login
