
目录
1. 文件结构
1.1 MANIFEST 文件
1.1.1 结构与解析
MANIFEST 存储量一些基本信息, 比如魔数、当前的Badger数据库适用版本号, 这两者一般都是内嵌在代码里, 比如:
const badgerMagicVersion untyped int = 8
var magicText = [4]byte{'B', 'd', 'g', 'r'}
其他的数据则是通过解析buf(可以有多个类似的buf, 使用protobuf 序列化), 得到ManifestChangeSet(ManifestChange 数组), 然后逐步填充到Manifest 结构体中:
// +---------------------+-------------------------+-----------------------+-----------------------+-----------------------+
// | magicText (4 bytes) | externalMagic (2 bytes) | badgerMagic (2 bytes) | len+crc32(8 bytes) | buf(len) |
// +---------------------+-------------------------+-----------------------+-----------------------+-----------------------+
// | len+crc32(8 bytes) | buf(len) | ... |
// +---------------------+-------------------------+-----------------------+-----------------------+-----------------------+
for {
var lenCrcBuf [8]byte
_, err := io.ReadFull(&r, lenCrcBuf[:])
length := y.BytesToU32(lenCrcBuf[0:4])
var buf = make([]byte, length)
io.ReadFull(&r, buf)
var changeSet pb.ManifestChangeSet
err := proto.Unmarshal(buf, &changeSet)
err := applyChangeSet(&build, &changeSet)
}
主要上面的结构示意图, 早期的 Version 是没有拆分为externalMagic 和 badgerMagic, 如: version := y.BytesToU32(magicBuf[4:8])
externalMagic 是后来将version 拆分为2个 2 byte 的字段(externalMagic 和 badgerMagic), 用户可以通过 db.Options 设置externalMagic。
1.1.2 MANIFEST 相关主要结构体
Manifest 结构里主要的就是 Tables 成员, 它是一个Map结构, key是Table ID, 后面加载 sst文件会用到它来过滤有验证Table的有效性。 value为TableManifest结构, TableManifest 的 Compression 表明量Table 采用的压缩方式, 加载sst 文件时依然要用到。
type Manifest struct {
Levels []levelManifest
Tables map[uint64]TableManifest
Creations int
Deletions int
}
type TableManifest struct {
Level uint8
KeyID uint64
Compression options.CompressionType
}
type levelManifest struct {
Tables map[uint64]struct{} // Set of table id's
}
1.1.3 MANIFEST 示意
00000000 42 64 67 72 00 00 00 08 00 00 00 00 00 00 00 00 |Bdgr............|
00000010 00 00 00 06 ed c5 1a fe 0a 04 08 01 30 01 00 00 |............0...|
00000020 00 06 07 eb da 8d 0a 04 08 02 30 01 00 00 00 06 |..........0.....|
00000030 a2 aa 48 f3 0a 04 08 03 30 01 00 00 00 06 d6 5a |..H.....0......Z|
00000040 2c 9a 0a 04 08 04 30 01 |,.....0.|
1.2 KEYREGISTRY 文件
1.2.1 KEYREGISTRY 文件结构
/*
Structure of Key Registry.
+-------------------+---------------------+--------------------+--------------+------------------+
| IV | Sanity Text | DataKey1 | DataKey2 | ... |
+-------------------+---------------------+--------------------+--------------+------------------+
*/
type KeyRegistry struct {
sync.RWMutex
dataKeys map[uint64]*pb.DataKey
lastCreated int64 //lastCreated is the timestamp(seconds) of the last data key generated.
nextKeyID uint64
fp *os.File
opt KeyRegistryOptions
}
type DataKey struct {
KeyId uint64 `protobuf:"varint,1,opt,name=key_id,json=keyId,proto3" json:"key_id,omitempty"`
Data []byte `protobuf:"bytes,2,opt,name=data,proto3" json:"data,omitempty"`
Iv []byte `protobuf:"bytes,3,opt,name=iv,proto3" json:"iv,omitempty"`
CreatedAt int64 `protobuf:"varint,4,opt,name=created_at,json=createdAt,proto3" json:"created_at,omitempty"`
}
1.2.2 KEYREGISTRY 用途
在测试的过程中, 尚未发现 KEYREGISTRY的实际用途。其使用最多的就是的它的成员函数DataKey:
func (kr *KeyRegistry) DataKey(id uint64) (*pb.DataKey, error)
// 虽然多次调用, 但都是走的一下分支:
if id == 0 {
// nil represent plain text.
return nil, nil
}
1.3. .mem 文件
.mem 文件的同 .vlog 文件, 通过 Mmap 映射到 memTable 结构 的wal 成员(即结构体 *logFile )。在文件正常关闭的情况下, 程序会等待memTable 结构体里保存的数据刷新到 Table 结构体, 然后同步目录结构(删除对应的.mem 文件)。非正常关闭的情况下, 程序则会创建一个 skiplist 链表和 memTable, 然后将 .mem 文件映射到结构体的成员wal:
s := skl.NewSkiplist(arenaSize(db.opt))
mt := &memTable{
sl: s,
opt: db.opt,
buf: &bytes.Buffer{},
}
mt.wal = &logFile{
fid: uint32(fid),
path: filepath,
registry: db.registry,
writeAt: vlogHeaderSize,
opt: db.opt,
}
lerr := mt.wal.open(filepath, flags, 2*db.opt.MemTableSize)
1.4 .sst 文件
1.4.1 文件结构
.sst 文件结构可以分为两层: 一层为Block, ;一层为Entry, 。如:
/*
The table structure looks like
+---------+------------+-----------+---------------+
| Block 1 | Block 2 | Block 3 | Block 4 |
+---------+------------+-----------+---------------+
| Block 5 | Block 6 | Block ... | Block N |
+---------+------------+-----------+---------------+
| Index | Index Size | Checksum | Checksum Size |
+---------+------------+-----------+---------------+
*/
/*
Structure of Block.
+-------------------+---------------------+--------------------+--------------+------------------+
| Entry1 | Entry2 | Entry3 | Entry4 | Entry5 |
+-------------------+---------------------+--------------------+--------------+------------------+
| Entry6 | ... | ... | ... | EntryN |
+-------------------+---------------------+--------------------+--------------+------------------+
| Block Meta(contains list of offsets used| Block Meta Size | Block | Checksum Size |
| to perform binary search in the block) | (4 Bytes) | Checksum | (4 Bytes) |
+-----------------------------------------+--------------------+--------------+------------------+
*/
1.4.2 相关数据结构
type Table struct {
sync.Mutex
*z.MmapFile
tableSize int // Initialized in OpenTable, using fd.Stat().
_index *fb.TableIndex // Nil if encryption is enabled. Use fetchIndex to access.
_cheap *cheapIndex
ref int32 // For file garbage collection. Atomic.
// The following are initialized once and const.
smallest, biggest []byte // Smallest and largest keys (with timestamps).
id uint64 // file id, part of filename
Checksum []byte
CreatedAt time.Time
indexStart int
indexLen int
hasBloomFilter bool
IsInmemory bool // Set to true if the table is on level 0 and opened in memory.
opt *Options
}
type TableIndex struct {
_tab flatbuffers.Table
}
Table 结构体在blockIterator、Builder等结构协助下, 封装了对.sst 文件的操作。其中重要的数据有:
- _index *fb.TableIndex: 在非加密模式下, 实际指向了文件块中的 index 区域。数据采用了flatbuffer 的编码
1. latbuffer 的编码性能要比 protobuf 低。在 JSON、protobuf 和 flatbuf 之中, flatbuf 编码性能最差, JSON 介于二者之间
2. 在不压缩的情况下, flatbuffer 的数据长度是最长的, 理由也很简单, 因为二进制流内部填充了很多字节对齐的 0, 并且原始数据也没有采取特殊的压缩处理, 整个数据膨胀的更大了。不管压不压缩, flatbuffer 的数据长度都是最长的。JSON 经过压缩以后, 数据长度会近似于 protocol buffer。protocol buffer 由于自身编码就有压缩, 再经过 GZIP 这些压缩算法压缩以后, 长度始终维持最小
3. flatbuffer 是一种无需解码的二进制格式, 因而解码性能要高许多, 大概要比 protobuf 快几百倍的样子, 因而比 JSON 快的就更多了。
- _cheap *cheapIndex: 对 *fb.TableIndex 的一层封装, 提供了一下便捷操作:
index, err := t.readTableIndex()
if err != nil {
return nil, err
}
if !t.shouldDecrypt() {
// If there's no encryption, this points to the mmap'ed buffer.
t._index = index
}
t._cheap = &cheapIndex{
MaxVersion: index.MaxVersion(),
KeyCount: index.KeyCount(),
UncompressedSize: index.UncompressedSize(),
OnDiskSize: index.OnDiskSize(),
OffsetsLength: index.OffsetsLength(),
BloomFilterLength: index.BloomFilterLength(),
}
对数据文件的读取和解析方式, 大致如下代码所示:
// Checksum Size
readPos := t.tableSize
readPos -= 4
buf := t.readNoFail(readPos, 4)
checksumLen := int(y.BytesToU32(buf))
// Checksum
readPos -= checksumLen
buf = t.readNoFail(readPos, checksumLen)
// Index Size
readPos -= 4
buf = t.readNoFail(readPos, 4)
t.indexLen = int(y.BytesToU32(buf))
// Read index.
readPos -= t.indexLen
t.indexStart = readPos
data := t.readNoFail(readPos, t.indexLen)
index := fb.GetRootAsTableIndex(data, 0)
下面两张图是对一个.sst文件的二进制原文与结构解析结构对照:
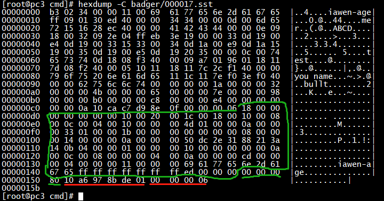
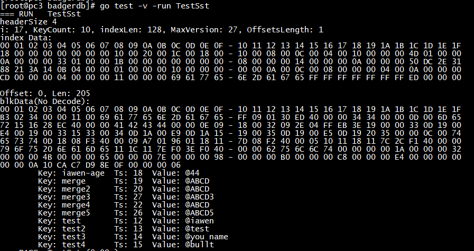
同时, Table 结构体实现了TableInterface 接口, 因而也实现了以下几个函数, 实际上只是对私有数据访问的封装, 优化了数据查询, 提供以快捷查询和操作:
type TableInterface interface {
Smallest() []byte
Biggest() []byte
DoesNotHave(hash uint32) bool
MaxVersion() uint64
}
func (t *Table) Smallest() []byte { return t.smallest }
func (t *Table) MaxVersion() uint64 { return t.cheapIndex().MaxVersion }
如果说 Table._index(*fb.TableIndex) 是对.sst文件第一层的映射, 表现为一系列的BlockOffset, 那么 block 则是对第二层的Entry 映射。block 是一个私有结构, 内嵌在 *fb.TableIndex 的 BlockOffset中。
数据采用了压缩存储(具体压缩方法, 对应 MANIFEST 文件的数据 – Manifest.[fid]Tables.Compression), 解压并解析到 block 结构体中, 代码摘取如下:
// blk.offset = BlockOffset.offset
if blk.data, err = t.read(blk.offset, int(ko.Len()))
offsetlen := index.OffsetsLength()
for j := 0; j < offsetlen; j++ {
var bo fb.BlockOffset
if index.Offsets(&bo, j) {
offsetlen := index.OffsetsLength()
blk, _ := mf.Bytes(int(bo.Offset()), int(bo.Len()))
err = t.decompress(blk)
// chkLen
readPos := len(blk.data) - 4
blk.chkLen = int(y.BytesToU32(blk.data[readPos : readPos+4]))
// checksum
readPos -= blk.chkLen
blk.checksum = blk.data[readPos : readPos+blk.chkLen]
// numEntries
readPos -= 4
numEntries := int(y.BytesToU32(blk.data[readPos : readPos+4]))
entriesIndexStart := readPos - (numEntries * 4)
entriesIndexEnd := entriesIndexStart + numEntries*4
// entryOffsets - Array
blk.entryOffsets = y.BytesToU32Slice(blk.data[entriesIndexStart:entriesIndexEnd])
blk.entriesIndexStart = entriesIndexStart
}
}
以上代码的循环是我自行补上, 是为了更清晰的表明数据结构, 具体block 结构体如下所示(bblock 是一个辅助结构, 保存了一下中间结果, 如baseKey):
type block struct {
offset int
data []byte
checksum []byte
entriesIndexStart int // start index of entryOffsets list
entryOffsets []uint32 // used to binary search an entry in the block.
chkLen int // checksum length.
freeMe bool // used to determine if the blocked should be reused.
ref int32
}
type bblock struct {
data []byte
baseKey []byte // Base key for the current block.
entryOffsets []uint32 // Offsets of entries present in current block.
end int // Points to the end offset of the block.
}
对block 的压缩目前只支持3种方式(None、Snappy、ZSTD):
type CompressionType uint32
const (
// None mode indicates that a block is not compressed.
None CompressionType = 0
// Snappy mode indicates that a block is compressed using Snappy algorithm.
Snappy CompressionType = 1
// ZSTD mode indicates that a block is compressed using ZSTD algorithm.
ZSTD CompressionType = 2
)
一次修改后的数据文件比对:
curl -i -XPOST http://192.168.137.3:7888/set -d '{"value": "ABCD", "key": "merge"}'
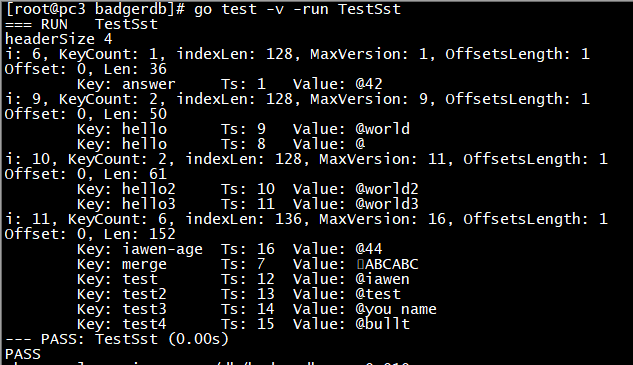
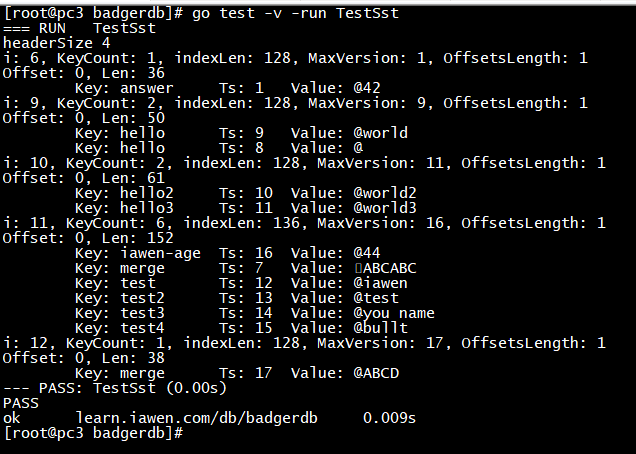
1.5 .vlog 文件和 DISCARD 文件
1.5.1 DISCARD 文件
DISCARD 文件, 同其他文件一样, 都是一个Mmap 映射文件, 其初始化为 1MB 大小, 并且填充为0(非数字0)lf.zeroOut(), 主要数据结构
discardStats。其用途是跟踪给定日志文件可以丢弃的数据量, 可以说它是vlog 的辅助。其成员nextEmptySlot 就是用来追踪下一个可以插入的 slot。
type discardStats struct {
sync.Mutex
*z.MmapFile
opt Options
nextEmptySlot int
}
mf, err := z.OpenMmapFile(fname, os.O_CREATE|os.O_RDWR, 1<<20)
lf := &discardStats{
MmapFile: mf,
opt: opt,
}
if err == z.NewFile {
// We don't need to zero out the entire 1GB.
lf.zeroOut()
} else if err != nil {
return nil, y.Wrapf(err, "while opening file: %s\n", discardFname)
}
如果用 二进制工具查看, 效果如下:

1.5.2 .vlog 文件
// size of vlog header.
// +----------------+------------------+------------------+------------------+
// | keyID(8 bytes) | baseIV(12 bytes)| Entry1 | Entry2... |
// +----------------+------------------+------------------+------------------+
type logFile struct {
*z.MmapFile
path string
// This is a lock on the log file. It guards the fd’s value, the file’s
// existence and the file’s memory map.
//
// Use shared ownership when reading/writing the file or memory map, use
// exclusive ownership to open/close the descriptor, unmap or remove the file.
lock sync.RWMutex
fid uint32
size uint32
dataKey *pb.DataKey
baseIV []byte
registry *KeyRegistry
writeAt uint32
opt Options
}
.vlog 文件的用途主要是保证数据的写入安全。但这里并不是无条件的写入, 而是在达到 badger 的 预警线后才开始写入。如果用户没有通过WithValueThreshold() 来设置opt.ValueThreshold, 则默认的值就是maxValueThreshold, 1MB大小。.vlog文件的写入是追加的, 这样能保证更好的写入性能。只有但大于或等于这个值, 才会写入 vlog 文件, 如下:
e := b.Entries[j]
valueSizes = append(valueSizes, int64(len(e.Value)))
if e.skipVlogAndSetThreshold(vlog.db.valueThreshold()) {
b.Ptrs = append(b.Ptrs, valuePointer{})
continue
}
const maxValueThreshold untyped int = 1048576 // 1MB
func (e *Entry) skipVlogAndSetThreshold(threshold int64) bool {
if e.valThreshold == 0 {
e.valThreshold = threshold
}
return int64(len(e.Value)) < e.valThreshold
}
追加到 .vlog文件里的 Entry 在通过编码后, 才会写入到文件:
type Entry struct {
Key []byte
Value []byte
ExpiresAt uint64 // time.Unix
version uint64
offset uint32 // offset is an internal field.
UserMeta byte
meta byte
// Fields maintained internally.
hlen int // Length of the header.
valThreshold int64
}
buf := new(bytes.Buffer)
plen, err := curlf.encodeEntry(buf, e, p.Offset)
// encodeEntry will encode entry to the buf layout of entry
// +--------+-----+-------+-------+
// | header | key | value | crc32 |
// +--------+-----+-------+-------+
1.5.3 valueLog 结构体
type valueLog struct {
dirPath string
// guards our view of which files exist, which to be deleted, how many active iterators
filesLock sync.RWMutex
filesMap map[uint32]*logFile
maxFid uint32
filesToBeDeleted []uint32
// A refcount of iterators -- when this hits zero, we can delete the filesToBeDeleted.
numActiveIterators int32
db *DB
writableLogOffset uint32 // read by read, written by write. Must access via atomics.
numEntriesWritten uint32
opt Options
garbageCh chan struct{}
discardStats *discardStats
}
无论是DISCARD 还是.vlog, 都是通过valueLog 结构体老操作的。discardStats 则对应了 DISCARD 文件的操作。filesMap 对应到 logFile, writableLogOffset 就是用来记录下一次写入的位置。为了并发的写入安全, 对writableLogOffset的操作采用了原子的方式:
endOffset := atomic.AddUint32(&vlog.writableLogOffset, n)
start := int(endOffset - n)
func (vlog *valueLog) init(db *DB) {
// ....
lf, err := InitDiscardStats(vlog.opt)
y.Check(err)
vlog.discardStats = lf
}
func (vlog *valueLog) deleteLogFile(lf *logFile) error {
if lf == nil {
return nil
}
lf.lock.Lock()
defer lf.lock.Unlock()
// Delete fid from discard stats as well.
vlog.discardStats.Update(lf.fid, -1)
return lf.Delete()
}
2. 文件的加载
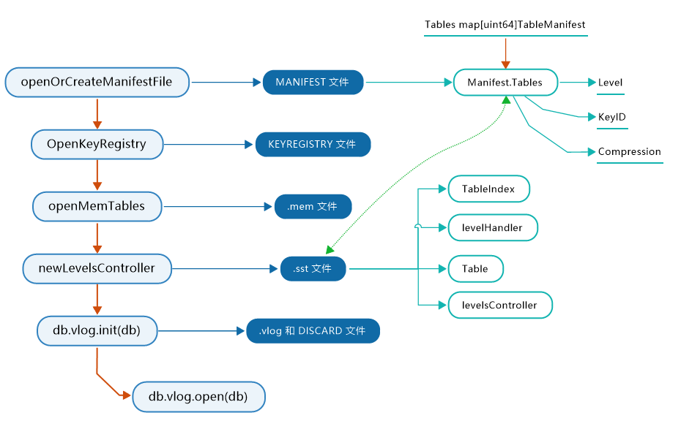
通过上面的分析, 我可以确定正真存储数据的是.sst 文件。而是.sst数据的加载则主要是通过levelsController 和 levelHandler 这两个结构体:
type levelsController struct {
nextFileID uint64 // Atomic
l0stallsMs int64 // Atomic
levels []*levelHandler
kv *DB
cstatus compactStatus
}
type levelHandler struct {
sync.RWMutex
// For level >= 1, tables are sorted by key ranges, which do not overlap.
// For level 0, tables are sorted by time.
// For level 0, newest table are at the back. Compact the oldest one first, which is at the front.
tables []*table.Table
totalSize int64
totalStaleSize int64
level int
strLevel string
db *DB
}
它们之间的关联表现如下图:
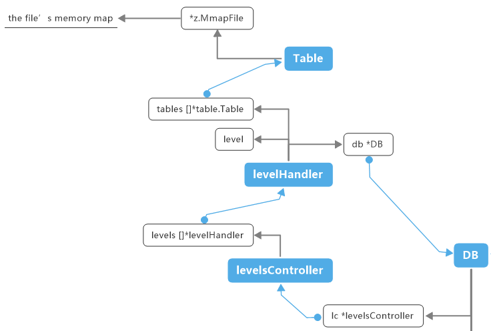
从 newLevelsController() 看起, 其加载的过程可以分为:
2.1 文件ID 的处理
- 遍历数据目录下的文件面, 然后通过文件名解析得到 ID 的 idMap:
getIDMap(dir string) map[uint64]struct{}. - 与 Manifest.Tables 对比, 删除 Manifest.Tables 里不存在的 .sst 文件:
// Compare manifest against directory, check for existent/non-existent files, and remove.
// 2. Delete files that shouldn't exist.
for id := range idMap {
if _, ok := mf.Tables[id]; !ok {
kv.opt.Debugf("Table file %d not referenced in MANIFEST\n", id)
filename := table.NewFilename(id, kv.opt.Dir)
if err := os.Remove(filename); err != nil {
return y.Wrapf(err, "While removing table %d", id)
}
}
}
2.2 创建对应的 Table 二维数组
tables 这个二维数组对应了 skiplist 结构。Badger 并发读取 .sst 文件内容到 Table, 然后将 Table插入到对应 Manifest.Tables 里存储的 Level 的位置。作者在代码里注释说: 发现使用 3 个 goroutine 可以最大限度地利用磁盘吞吐量, 在尝试读取数据时, 磁盘利用率是我们应该关注的主要问题, 这是 HDD 和 SSD 之间保持不变的一个因素。
tables := make([][]*table.Table, db.opt.MaxLevels)
throttle := y.NewThrottle(3)
// 这里的 mf 是 Manifest 结构,
for fileID, tf := range mf.Tables {
fname := table.NewFilename(fileID, db.opt.Dir)
go func(fname string, tf TableManifest) {
dk, err := db.registry.DataKey(tf.KeyID)
if err != nil {
rerr = y.Wrapf(err, "Error while reading datakey")
return
}
mf, err := z.OpenMmapFile(fname, db.opt.getFileFlags(), 0)
t, err := table.OpenTable(mf, topt)
mu.Lock()
tables[tf.Level] = append(tables[tf.Level], t)
mu.Unlock()
}(fname, tf)
}
2.3 构建 levelsController 和 levelsController下的levelHandler
挂载 Table 二维数组到对应的 levelHandler。因为这里的 levels 就是一个*levelHandler 数组。MaxLevels, 是LSM中允许的最大压实级别数, 默认是7, 可以通过Options更改: func (opt Options) WithMaxLevels(val int) Options。
func newLevelHandler(db *DB, level int) *levelHandler {
return &levelHandler{
level: level,
strLevel: fmt.Sprintf("l%d", level),
db: db,
}
}
for i := 0; i < db.opt.MaxLevels; i++ {
s.levels[i] = newLevelHandler(db, i)
s.cstatus.levels[i] = new(levelCompactStatus)
}
for i, tbls := range tables {
s.levels[i].initTables(tbls)
}
正如结构里的注释说明: 对应 Level0, 对Table 按 id 排序, 其他的则按 Table的最小Key 排序。有些不同的则是, Level的排序不是现实时间意义的时间戳, 而是文件的名ID, 可以通过解析文件名得到。这是一个Badger 维护的递增的uint64: id, ok := ParseFileID(filename)。
func (s *levelHandler) initTables(tables []*table.Table) {
s.Lock()
defer s.Unlock()
s.tables = tables
s.totalSize = 0
s.totalStaleSize = 0
for _, t := range tables {
s.addSize(t)
}
if s.level == 0 {
sort.Slice(s.tables, func(i, j int) bool {
return s.tables[i].ID() < s.tables[j].ID()
})
} else {
sort.Slice(s.tables, func(i, j int) bool {
return y.CompareKeys(s.tables[i].Smallest(), s.tables[j].Smallest()) < 0
})
}
}
接下来, 对Level数据进行里验证。Level0 直接忽略, 其他的Level, 主要是验证了 Key是否重叠。验证通过后, 同步更新数据目录:
err := s.validate()
err := syncDir(db.opt.Dir)
func (s *levelHandler) validate() error {
for j := 1; j < numTables; j++ {
if y.CompareKeys(s.tables[j-1].Biggest(), s.tables[j].Smallest()) >= 0 {} //ERROR
if y.CompareKeys(s.tables[j].Smallest(), s.tables[j].Biggest()) > 0 {} // ERROR
}
}
2.4 .vlog 文件
对应vlog 文件, 需要主要是: vlog只包括最新的日志文件, 同时又创建一个新文件用于新的写入。它永远不会忘旧的 vlog 上追加任何数据:
// We shouldn't delete the maxFid file.
if lf.size == vlogHeaderSize && fid != vlog.maxFid {
vlog.opt.Infof("Deleting empty file: %s", lf.path)
if err := lf.Delete(); err != nil {
return y.Wrapf(err, "while trying to delete empty file: %s", lf.path)
}
delete(vlog.filesMap, fid)
}
然后遍历最新的 vlog 文件:
last, ok := vlog.filesMap[vlog.maxFid]
lastOff, err := last.iterate(vlog.opt.ReadOnly, vlogHeaderSize,
func(_ Entry, vp valuePointer) error {
return nil
})
最后, 创建一个新的 vlog 文件用来记录, 而不是往旧的 vlog 上追加:
// Don't write to the old log file. Always create a new one.
if _, err := vlog.createVlogFile(); err != nil {
return y.Wrapf(err, "Error while creating log file in valueLog.open")
}
3. 文件的写入
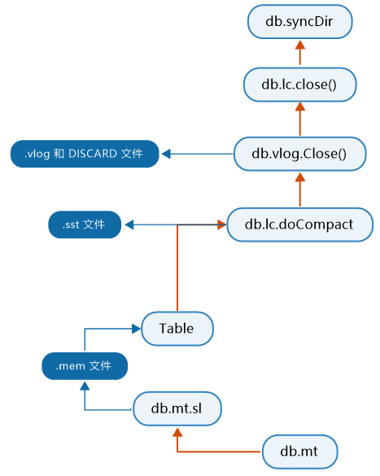
3.1 停止所有后台和前台操作
// Stop writes next.
db.closers.writes.SignalAndWait()
// Don't accept any more write.
close(db.writeCh)
close(db.sklCh)
db.closers.pub.SignalAndWait()
db.closers.cacheHealth.Signal()
3.2 刷新memTable 里的数据到 skiplist
把 db.mt 下 db.mt.sl 里的数据发送到 db.flushChan 通道, 直到 db.mt 无数据
case db.flushChan <- flushTask{mt: db.mt}:
db.imm = append(db.imm, db.mt) // Flusher will attempt to remove this from s.imm.
db.mt = nil // Will segfault if we try writing!
db.opt.Debugf("pushed to flush chan\n")
return true
func (db *DB) handleFlushTask(ft flushTask) error {
builder := buildL0Table(ft, bopts)
tbl, err = table.CreateTable(table.NewFilename(fileID, db.opt.Dir), builder)
err = db.lc.addLevel0Table(tbl)
}
3.3 对 Skiplist 进行 compact
先进行一些前期准备, 然后开始对 Skiplist 进行 compact
db.stopMemoryFlush()
db.stopCompactions()
err := db.lc.doCompact(173, compactionPriority{level: 0, score: 1.73})
badger 的 Compact 参照里RocksDb, 见: https://github.com/facebook/rocksdb/wiki/Leveled-Compaction, 这里不再细说细节。
在完成这些工作之后, 就是同步数据目录和valueLog目录里。
