
目录
JanusGraph是一个图形数据库引擎。其本身专注于紧凑图序列化、丰富图数据建模、高效的查询执行。另外, JanusGraph利用Hadoop进行图分析和批处理图处理。JanusGraph为数据持久性、数据索引、客户端访问实现了强大的模块化接口。JanusGraph的模块化体系结构使其可以与多种存储、索引、客户端技术进行互操作。它还简化了扩展JanusGraph以支持新的过程。
JanusGraph是分布式, 开源, 可大规模扩展的图形数据库。图库也是属于NoSQL一种。
1. 图数据库简介
1.1 NoSQL
NoSQL数据库大致可以分为以下几类:
- 键值对(key-value)数据库: 如Memcache, Redis
- 列簇式数据库: 如HBase
- 文档型数据库: 如Mongodb
- 图数据库: 如Neo4j, JanusGraph
1.2 JanusGraph 与 Tinkerpop 与 Gremlin
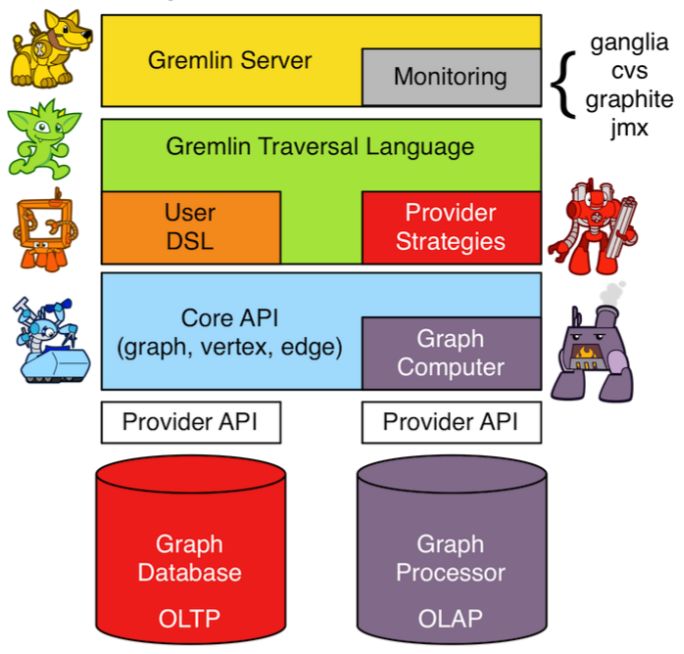
1.2.1 Tinkerpop
Tinkerpop 是Apache基金会下的一个开源的图数据库与图计算框架(OLTP与OLAP)。TinkerPop提供了⼀个标准接⼜, ⽬前已经被超过20个独⽴数据库引擎实现, 包括DBaaS(数据库即服务)产品(⽐如Amazon Neptune和Azure ComosDB)、商业产品(⽐如DataStax Enterprise Graph和Neo4j)和开源软件(⽐如TinkerGraph和JanusGraph)。
TinkerGraph是⼀个内存图引擎, ⽀持OLTP负载和OLAP负载, 是TinkerPop Gremlin Server和Gremlin Console的⼀部分。TinkerGraph是被作为TinkerPop API的参考实现构建出来的。它是TinkerPop的全功能开源实现。
1.2.2 Gremlin
Gremlin 是Tinkerpop的一个组件, 它是一门路径导向语言, 用于图操作和图遍历(也称查询语言)。Gremlin Console 和 Gremlin Server 分别提供了控制台和远程执行Gremlin查询语言的方式。Gremlin Server 在 JanusGraph 中被成为 JanusGraph Server。
Gremlin可以通过⼀系列链接在⼀起的操作对数据进⾏查询和修改, 就像函数式语⾔的⽅法链那样。
Gremlin是独立于 JanusGraph 开发的, 并得到大多数图数据库的支持。通过 Gremlin 查询语言在 JanusGraph 之上构建应用程序, 用户可以避免供应商锁定, 因为他们的应用程序可以迁移到支持 Gremlin 的其他图形数据库。
1.2.3 JanusGraph
JanusGraph是基于Tinkerpop这个框架来开发的, 使用的查询语言也是Gremlin。JanusGraph 使用Gremlin 服务器引擎作为服务器组件来处理和回答客户端查询, 并使用 JanusGraph 的便利功能对其进行扩展。
2. JanusGraph
2.1 交互
应用程序可以通过两种方式与JanusGraph交互:
- 嵌入式: 将JanusGraph嵌入到自己的图Gremlin查询应用中, 与自己的应用公用同一JVM。
查询执行时, JanusGraph的缓存和事务处理都在与应用程序相同的JVM中进行, 当数据模型大时, 很容易OOM, 并且耦合性太高, 生产上一般不这么搞。 - 服务式: JanusGraph单独运行在一个或一组服务器上, 对外提供服务。(推荐的模式)
客户端通过向服务器提交Gremlin查询, 与远程JanusGraph实例进行交互。
2.2 架构
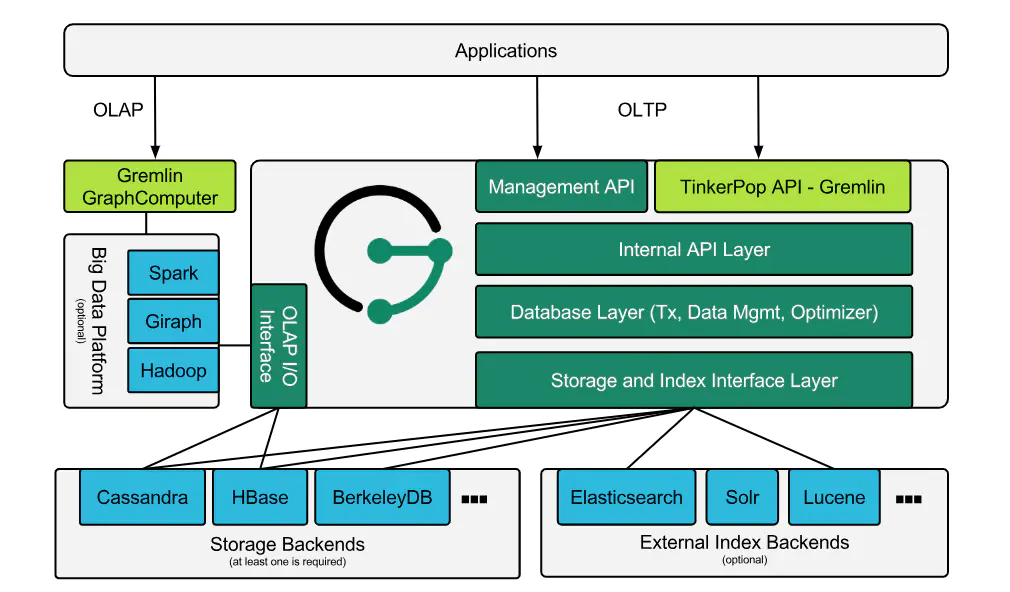
2.3 特点
2.3.1. 可扩展
- 弹性和线性可扩展性, 可用于不断增长的数据和用户群
- 数据分发和复制以提高性能和容错能力
- 多数据中心高可用性和热备份
JanusGraph 支持动态创建图表。这与标准 Gremlin 服务器实现允许访问图形的方式有所不同。
graphs {
graph1: conf/graph1.properties,
graph2: conf/graph2.properties
}
2.3.2. 开源
所有功能 都是完全免费的。无需购买商业许可证。JanusGraph在Apache 2许可下完全开放源代码。
2.3.3. 事务
JanusGraph是一个事务数据库, 可以支持数千个并发用户实时执行复杂的图遍历。支持ACID和最终的一致性。
2.3.4. 数据存储
图数据可以存储在:
Apache Cassandra - 注重在AP上
Apache HBase - 注重在CP上
Google Cloud Bigtable
Oracle BerkeleyDB - 一般用于单机本地验证
ScyllaDB
生产中使用最多的是 Cassandra 和 HBase, 根据业务特性选型。
2.3.5. 检索
JanusGraph支持多种搜索引擎作为索引后端, 索引后端和存储后端并存, 但两者相互独立, 且索引后端不是必须的。目前已支持使用索引后端进行地理位置、数字范围和全文检索等查询类型。所支持的查询引擎包括:
- ElasticSearch™
- Apache Solr™
- Apache Lucene®
2.3.6. 分析
JanusGraph可以与Apache中现有的大数据处理框架相结合, 基于图提供强大的大数据分析、统计报告能力, 并可通过ETL工具与其他系统对接。目前支持的框架包括:
- Apache Spark™
- Apache Giraph™
- Apache Hadoop®
2.3.7. TinkerPop
与 Apache TinkerPop 图栈的本地集成:
- Gremlin graph query language
- Gremlin Server
- Gremlin Console
2.3.8. 适配器
JanusGraph有不同的第三方存储适配器:
- Aerospike
- DynamoDB
- FoundationDB
2.3.9 可视化
JanusGraph基于Gremlin/TinkerPop, 因此支持Gremlin查询语言的图数据库可视化管理和操作工具均可用在JanusGraph中。包括但不限于:
- Cytoscape
- Gephi plugin for Apache TinkerPop
- Graphexp
- KeyLines by Cambridge Intelligence
- Linkurious
2.4 基本操作
2.4.1 启动一个JanusGraph实例
# Docker 部署
docker run -it -p 8182:8182 janusgraph/janusgraph
docker run --rm --link janusgraph-default:janusgraph -e GREMLIN_REMOTE_HOSTS=janusgraph \
-it janusgraph/janusgraph:latest ./bin/gremlin.sh
# 本地机器上启动服务器
./bin/janusgraph-server.sh start
./bin/gremlin.sh
graph = JanusGraphFactory.build().set("storage.backend", "hbase").set("storage.hostname", "xxx.163.org:2181,xxx1.163.org:2181,xxx2.163.org:2181").set("storage.hbase.ext.zookeeper.znode.parent", "/hbase").open()
graph = JanusGraphFactory.open('conf/janusgraph-berkeleyje-es.properties')
g = graph.traversal()
./bin/janusgraph-server.sh start ./conf/gremlin-server/gremlin-server-berkeleyje.yaml
:remote connect tinkerpop.server conf/remote.yaml session
:remote console
# 加载众神图谱示例数据, 只需要执行一次
GraphOfTheGodsFactory.load(graph)
GraphOfTheGodsFactory.loadWithoutMixedIndex(graph,true) # 默认情况下不使用搜索后端, 因此不支持混合索引, 因为未指定搜索后端。
2.4.2 常用操作
| op | 说明 | 备注 |
|---|---|---|
| g | g = graph.traversal() | g指遍历源, ⽽不是图 |
| V(), E() | 返回⼀个包含图中每个顶点/边的迭代器 | |
| has(), hasLabel() | 筛选操作 | |
| out(), in(), both() | 遍历所有 出/入/出入边 到带有指定标签的相邻顶点(如果指定了标签) | ⽅向性会筛选 |
| outE(), inE(), bothE() | 从当前顶点遍历到相邻的 出/入/出入 边 | 如果指定了标签, 只遍历到符合筛选条件的边 |
| outV(), inV() | 从当前边遍历到 出/入 顶点 | |
| otherV() | 遍历到不是出顶点的那个顶点(如另⼀个顶点)。通常和bothE()操作搭配使⽤ | |
| bothV() | 从当前边遍历到两个相邻的顶点 | |
| values(), valueMap() | 值操作检索属性 | values标识和values()操作是不⼀样的。values标识指向键-值对的值部分, ⽽values()指定从元素中返回的属性。 |
| repeat(), times(), until() | 递归操作 | |
| timeLimit() | 时间限定 | |
| emit() | 通知repeat()操作在循环当前位置发送值到控制台 | |
| addV(label), property() | 增加⼀个类型为label的顶点, 顶点或边上增加⼀个属性 | |
| addE(label), from(), to() | 添加⼀条标签为label的边,在添加边时, 需要为它指定⼊顶点和出顶点 | |
| drop() | 删除任何经过它的顶点、边或属性 | |
| iterate() | 触发遍历, 不会返回结果 | |
| next(), next(n) | ⼀个终端操作, 它从上⼀个操作获得迭代遍历源, 迭代⼀次, 然后返回迭代中的第⼀个或下⼀个项 | |
| path() | 当遍历执⾏时, 返回指定遍历器访问顶点(某些时候还有边)的历史 | |
| simplePath() | 筛选掉遍历中被重复访问的顶点 | 在图论中, 有⼀个概念叫简单路径, 指的是不会在任何⼀个顶点上重复的路径。 |
| with() | ||
| order(), group() | ||
| groupCount() | 根据指定的by()调节器对结果分组和计数 | 需要⼀个by()调节器来指定键。值总是通过count()操作进⾏聚合。 |
| skip(number), limit(number), range(startNumber, endNumber), tail(number) | ||
| as() | 为上⼀个操作的输出分配⼀个(或多个)标签, 这些标签可以在同⼀遍历中被后⾯的操作访问 | |
| project(string[]) | 两种格式化结果的⽅式: 选择(selection)和投射(projection) | |
| select(string[]) | 选择先前遍历中的别名元素。该操作总是回顾遍历中的先前操作以找到别名 | |
| by(key) | 指定属性的键, 以从相应的别名元素返回值 | |
| by(traversal) | 指定要对相应别名元素执⾏的遍历 | |
| unfold() | 将⼀个可迭代或map结果的各个组成部分展开 | |
| where() | ||
| mean() | 聚合⼀组值来计算平均值, 常⽤与group().by().by()操作搭配使⽤ | |
| identity() | 获取进⼊该操作的元素并原封不动地返回 | |
| subgraph(sideEffectKey) | 在⼀组较⼤的图数据中定义⼀个按边归纳⼦图 | |
| cap(sideEffectKey) | 向上迭代遍历到⾃⾝, 并发出sideEffectKey引⽤的副作⽤结果 | |
| optional(traversal) | 尝试遍历, 如果返回结果, 则发出结果; 否则, 发出传⼊元素(与identity()操作⼀样) | |
| textContains(),textNotContains(),textContainsPrefix(), textNotContainsPrefix(),textContainsRegex(),textNotContainsRegex(), textContainsFuzzy(),textNotContainsFuzzy(),textContainsPhrase(), textNotContainsPhrase() |
文本谓词 | |
| textPrefix(),textNotPrefix(),textRegex() textNotRegex(),textFuzzy(),textNotFuzzy() |
文本谓词 | |
| eq(),neq(),gt(), gte(), lt(), lte() | 比较谓词 | |
| geoIntersect(),geoWithin(),geoDisjoint(),geoContains() | 地理谓词 |
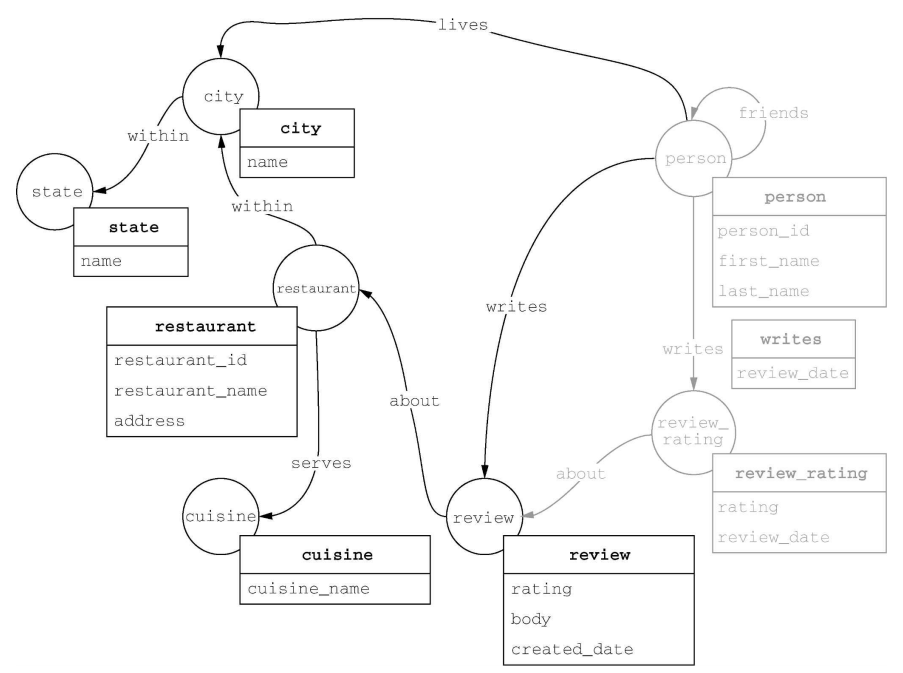
# 汇总
g.V().count()
g.E().count()
g.V().hasLabel("restaurant").count()
g.addV('person').property('first_name', 'Dave')
g.V().has('person', 'first_name', 'Ted').repeat(out('friends')).times(2).values('first_name')
g.V().has('person', 'first_name', 'Ted').until(has('person', 'first_name', 'Hank')).emit().repeat(out('friends').simplePath()).path()
g.V().has('person', 'first_name', 'Dave').out().as('f').out().as('foff').select('f', 'foff').by('first_name').by('first_name')
# eq
g.V().has('person', 'first_name', 'Dave').out().where(__.out()).project('f', 'foff').by('first_name').by(out().values('first_name'))
# 根据日期排序、分页返回数据, 顺带返回元数据和ID
# .skip(3).limit(3) <==> .range(3, 6) # Remark Of range: [)
g.V().has("restaurant", "restaurant_id", 31).in('about').order().by('created_date', desc).skip(3).limit(3).valueMap('created_date', 'body').with(WithOptions.tokens)
g.V().hasLabel('person').group().by(values('first_name')).by(both('friends').count()).unfold().project('first_name','count').by(select(keys)).by(select(values))
g.V().has('person', 'person_id', pid).out('lives').in('within').where(__.inE('about')).order().by(__.in('about').values('rating').mean()).valueMap().with(WithOptions.tokens)
g.V().has('person', 'person_id', pid).out('lives').in('within').
where(__.inE('about')).group().by(identity()).by(__.in('about').values('rating').mean()).
unfold().order().by(values, desc).limit(10).unfold().
project('name', 'address', 'rating_average').by(select(keys).values('name')).by(select(keys).values('address')).by(select(values))
g.V().has('person', 'person_id', pid).out('lives').in('within').
where(out('serves').has('cuisine', 'name', within(['diner', 'bar']))).
where(__.inE('about')).group().by(identity()).by(__.in('about').values('rating').mean()).
unfold().order().by(values, desc).limit(10).unfold().
project('name', 'address', 'rating_average', 'cuisine').by(select(keys).values('name')).by(select(keys).values('address')).by(select(values)).by(select(keys).out('serves').values('name'))
# 纬度: 37.97 和经度: 23.72, 50 公里范围内
g.E().has('place', geoWithin(Geoshape.circle(37.97, 23.72, 50)))
2.4.3 子图
从概念上讲, ⼦图是⼀个相当简单的东西: 就是顶点和边的⼦集, 通常根据某种规则或对业务领域的理解⽽紧密相连。⼀旦定义, 即使原始数据发⽣变化, ⼦图也不会改变, 尽管该功能既依赖于⽀持subgraph()操作的具体数据库产品, 也依赖于与TinkerPop⾏为⼀致的实现。
subgraph = g.V().has('person', 'person_id', 2).bothE('friends').subgraph('sg').cap('sg').next()
sg = subgraph.traversal()
sg.V().count()
# method 1
pid=2
subgraph = g.V().has('person','person_id',pid).bothE('friends').subgraph('sg').otherV().
outE('wrote').subgraph('sg').inV().optional(hasLabel('review_rating').outE('about').subgraph('sg').inV()).
outE('about').subgraph('sg').inV().
outE('within').subgraph('sg').cap('sg').next()
# method 2
subgraph = g.V().has('person','person_id',pid).bothE('friends').subgraph('sg').otherV().
union(outE('wrote').subgraph('sg').inV(), outE('assigns').subgraph('sg').inV()).
outE('about').subgraph('sg').inV().
outE('within').subgraph('sg').
cap('sg').next()
TinkerPop的subgraph()操作有⼀个关键的限制: Gremlin语⾔变体(GLV)不⽀持它, ⾄少在写作本书时还不⽀持。
3. Gremlin 进阶
3.1 JanusGraph中的索引
JanusGraph包括图索引(Graph Index)和顶点为中心的索引(Vertex-centric Indexes)
- 索引唯一性:
.unique() - 标签约束:
.indexOnly(labelName)
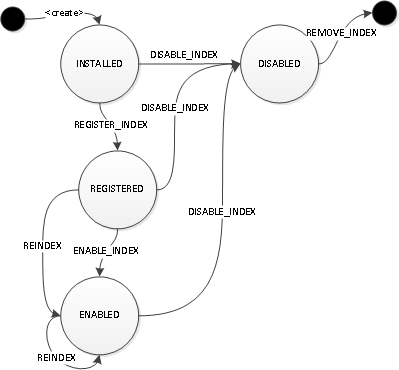
可以对索引执行以下操作以通过以下方式更改其状态mgmt.updateIndex():
- REGISTER_INDEX: 向图集群中的所有实例注册索引。安装索引后, 必须向所有图实例注册
- REINDEX: 从图中重新构建索引
- ENABLE_INDEX: 启用索引以便查询处理引擎可以使用它。必须先注册索引, 然后才能启用它
- DISABLE_INDEX: 禁用图表中的索引, 使其不再使用
- REMOVE_INDEX: 从图中删除索引(可选操作)。仅在复合索引上。
3.1.1 图索引(Graph Index)
图索引是整个图上的全局索引结构, 它允许通过它们的属性有效地检索顶点或边以用于足够的选择性条件。
图索引支持过滤索引, 就是仅在满足特定条件的边或顶点建立索引。其又包括复合索引(Composite Index)和混合索引(Mixed Index)
- 常⽤于按值或按范围进⾏筛选的属性
- 需要全⽂搜索的属性
- 在⽀持地理数据的数据库中需要搜索空间特征
复合索引只能进行等值的, 包括所有索引键的查询。也就是说非等的查询, 或者只包含部分键的查询都无法走复合索引。复合索引不依赖索引后端, 其仅依赖存储后端, 所以未配置索引后端不影响复合索引使用。order by需要在内存中排序, 因为没有索引后端。可以通过unique()来限定某个复合索引是唯一索引。
针对已在使用的属性键构建的图形索引, 不受新创建的标签的约束, 需要执行重新索引过程 以确保索引包含所有先前添加的元素。在重新索引过程完成之前, 索引将不可用。鼓励在与初始模式相同的事务中定义图索引。
复合索引不需要配置外部索引后端, 并通过主存储后端得到支持。因此, 复合索引修改通过与图修改相同的事务进行持久化, 这意味着如果底层存储后端支持原子性和/或一致性, 则这些更改是原子的和/或一致的。
mgmt = graph.openManagement()
firstName = mgmt.getPropertyKey('first_name')
mgmt.buildIndex('byNameComposite', Vertex.class).addKey(firstName).buildCompositeIndex()
mgmt.commit()
mgmt = graph.openManagement()
mgmt.updateIndex(mgmt.getGraphIndex("byNameComposite"), SchemaAction.REINDEX).get()
mgmt.commit()
混合索引类似于数据库常规索引, 提供比复合索引更大的灵活性。其依赖索引后端, 一个JanusGraph实例可以同时配置多个索引后端。混合索引支持全文索引, 地理位置索引, 范围查询等, 默认创建的是全文索引类型。混合索引不具备唯一性。如果order by字段为索引的一部分, 则可以下推到索引后端执行。在此不做展开。
对于已经有数据的边或顶点创建索引, 在索引覆盖所有数据之前, 索引不生效。可使用如下命令完成索引重建
mgmt = graph.openManagement()
mgmt.updateIndex(mgmt.getGraphIndex("byDeepComposite"), SchemaAction.REINDEX).get()
mgmt.commit()
# Wait for the index to become available
ManagementSystem.awaitGraphIndexStatus(graph, 'byNameUnique').call()
# Reindex the existing data
mgmt = graph.openManagement()
mgmt.updateIndex(mgmt.getGraphIndex("byNameUnique"), SchemaAction.REINDEX).get()
mgmt.commit()
3.1.2 顶点为中心的索引(Vertex-centric Indexes)
顶点中心索引, 是局部索引, 只为与顶点相连的某类边建立索引。其是前缀索引, 所以键的先后顺序对索引效率有较大影响。仅支持等值, 范围和包含类查询
以顶点为中心的索引, 也称为关系索引, 是每个顶点单独构建的局部索引结构。它们与边和属性一起存储在edgeStore. 有两种类型的以顶点为中心的索引, 边索引和属性索引。
- 边索引
- 属性索引
mgmt = graph.openManagement()
time = mgmt.getPropertyKey('time')
battled = mgmt.getEdgeLabel('battled')
mgmt.buildEdgeIndex(battled, 'battlesByTime1', Direction.BOTH, Order.decr, time)
mgmt.commit()
3.1.3 混合索引
混合索引通过先前添加的属性键的任意组合来检索顶点或边。混合索引比复合索引提供更大的灵活性, 并支持除相等之外的其他条件谓词。另一方面, 对于大多数相等查询, 混合索引比复合索引要慢。
混合索引需要配置 索引后端并使用该索引后端来执行查找操作。
混合索引支持全文搜索、范围搜索、地理搜索等。
3.2 JanusGraph中的事务
JanusGraph 事务不一定是 ACID。它们可以在 BerkeleyDB 上进行如此配置, 但在 Cassandra 或 HBase 上通常不是这样, 其中底层存储系统不提供可序列化隔离或多行原子写入, 并且模拟这些属性的成本将是巨大的。
JanusGraph中的事务是自动开启(与MySQL类似), 但不会自动commit或rollback的(与MySQL不同), 所有的读写操作都在事务中执行。形如:
juno = graph.addVertex() //Automatically opens a new transaction
juno.property("name", "juno")
graph.tx().commit() //Commits transaction
所以, 如果一直执行插入或更新, 那么会导致隐式开启的事务越来越大。如果一个图数据库实例被close()时, 还有事务在执行中, 那么该事务的状态是未定的(TinkPop语义), 对于隐式开启的与该实例线程绑定的事务, jg会将其提交掉, 如果是显式开启的非线程绑定的事务, 则会被回滚掉。
JanusGraph采用乐观事务模型, 在提交时才会进行冲突检测, 那么会导致在一个长事务中较早插入的具有唯一性约束的记录, 在事务执行过程中被其他事务提交了。针对这种情况, 可以在一个事务里面开启子事务, 让子事务执行插入操作并先提交, 这样能够提交长事务执行效率, 避免无谓的失败。
多个事务间的隔离。JanusGraph中的事务类似于可重复读级别。事务开启后就会获取系统的状态(Snapshot?), 在提交前不会更新, 那么如果其他事务做了新的操作并提交, 该事务是无法看到这些操作的。
实际的锁应用机制是抽象的, 这样 JanusGraph 可以使用锁提供者的多个实现。目前, JanusGraph 发行版中只包含一个锁定提供程序:
一种基于键一致读写操作的锁定实现, 只要它支持键一致操作(包括 Cassandra 和 HBase), 它就与底层存储后端无关。这是默认实现, 并使用基于时间戳的锁应用程序来确定哪个事务持有锁。它要求时钟在集群中的所有机器上同步。
3.2.1 事务层缓存
事务层缓存包括顶点缓存(Vertex Cache)和索引缓存(Index Cache)。
顶点缓存用于缓存顶点及其相连的边, 其大小可通过tx-cache-size 设置, 但被修改的vertex被pin在cache中无法替换, 所以如果事务修改了很多vertex, 那么cache大小会超过设置值。vertex用于加速事务对顶点的多次访问场景。
索引缓存用于缓存使用索引后端进行查询的结果, 这样, 后续使用相同sql进行查询的时候, 就不需要在从索引后端跨网络获取数据, 只需从内存中读取即可。最大大小为tx-cache-size 的一半。这个有点像query cache。
数据库层缓存在事务间共享缓存数据。对于读多写少的场景, 有较好的加速效果。默认关闭, 可通过 cache.db-cache=true开启。cache.db-cache-time是影响该性能和查询行为最重要的参数, 若仅有一个JanusGraph实例打开存储后端, 或仅有该实例有修改存储后端数据, 则可以将过期设置为0, 表示不过期。
从cache.db-cache-time描述可发现, JanusGraph各个实例之间并没有建立数据同步关系, 也就是说, 一个实例修改了数据, 另一个实例是不感知的。可以把JanusGraph理解为HBase等存储后端的客户端。客户端的缓存是本地缓存, 服务器端数据被修改后, 客户端的缓存当然不会感知。 cache.db-cache-size 设置数据库层缓存的大小, 可以是其所属的JVM内存的百分比, 或者是具体的内存byte大小。过大的缓存会引起过多的GC, 从而反过来影响性能, 默认为50%。cache.db-cache-clean-wait表示本地事务修改了某数据后, 等待多少时间将对应数据从缓存中失效掉, 从存储后端重新获取。
3.3 JanusGraph中的缓存
JanusGraph包含了事务层(Transaction-Level)、数据库层(Database Level)和后端存储(Storage Backend)缓存, 其中第三种位于所配置的后端存储上, 下面简单介绍下前2种。
3.4 性能与分析
3.4.1 解释遍历 explain()
使⽤explain()操作定位执⾏糟糕的遍历, 需要对数据库的内部⼯作原理有深⼊的理解。然⽽, explain()操作是不同数据库实例都具备的常⽤⼯具, ⽽且有些⼈发现它和下⼀节中的分析⼯具对于调试都⾮常有⽤, 所以我们也会关注explain()。
重要的部分是以Final Traversal开头的那⼀⾏。这就是在图上执⾏的优化计划。但是我们发现, 仅仅知道遍历会如何执⾏并不⾜以让我们知道如何修复性能问题。
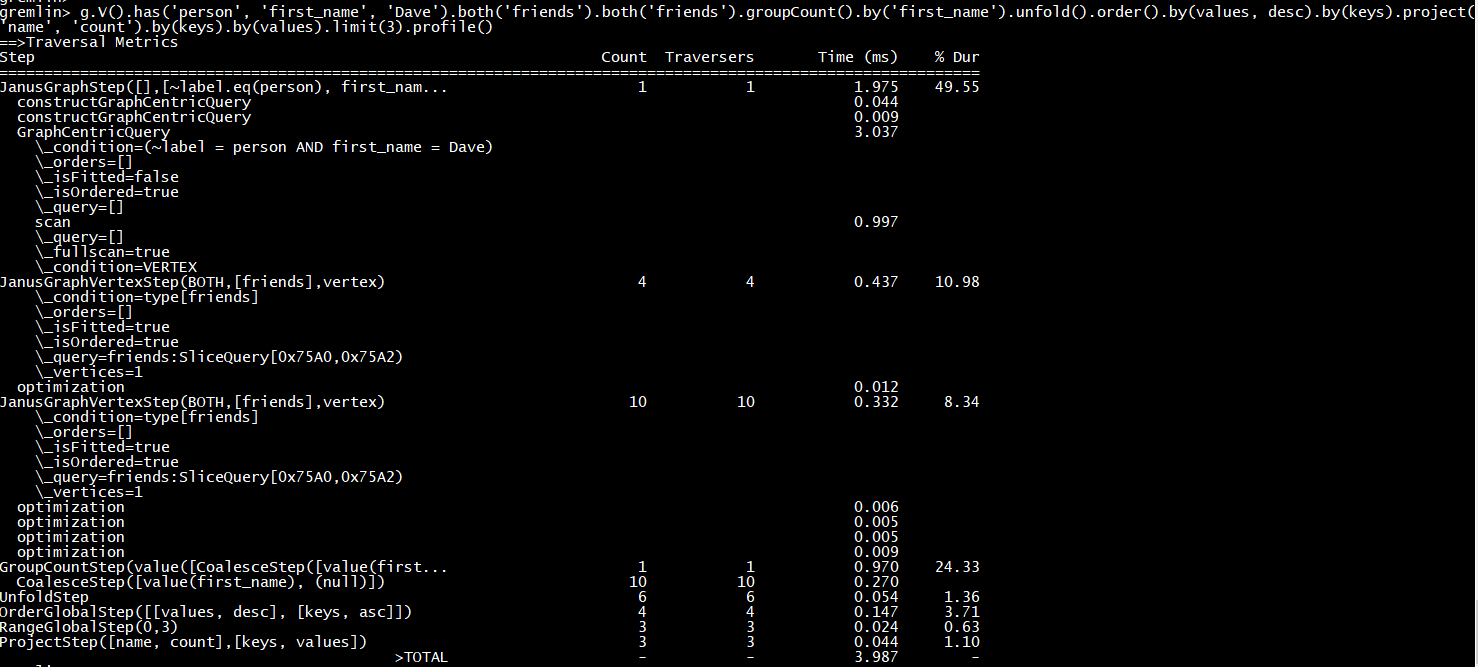
3.4.2 分析工具 profile()
profile()操作运⾏遍历并收集执⾏过程中有关性能特征的统计信息。这些统计信息包括执⾏的细节, 就像关系数据库的真实执⾏计划那样。explain()操作告诉我们⼀个遍历是如何执⾏的, ⽽profile()操作则告诉我们执⾏过程中发⽣了什么。
如果我们发现耗时最长的操作有很多遍历器, 我们应该在这个操作之前增加额外的筛选, 以减少所需要的遍历器。
3.5 图分析
-
度数(degree)中⼼性
度数是指与⼀个顶点相关联的边的数量, 因此度数中⼼性是基于边数对顶点进⾏排序的。度数中⼼性可以通过分别测量内度和外度来进⼀步细分。度数中⼼性通常⽤于确定图连接程度的基线, 尤其是在计算平均值、最⼩值和最⼤值时。 -
间隙(betweenness)中⼼性
是指⼀个顶点在图中所有节点对之间的最短路径中被使⽤的次数。间隙中⼼性在寻找连接不同顶点组的临界点⽅⾯很有效。使⽤该算法时, 返回的数越⼤, 表⽰该顶点越重要。 -
亲密度(closeness)中⼼性
是对从⼀个顶点到所有其他顶点的最短路径平均长度的度量, 表⽰相对于所有其他顶点, 哪些顶点位于最中⼼的位置。使⽤亲密度数中⼼性时, 返回值越⼩, 说明该顶点越重要。 -
特征向量(eigenvector)中⼼性
是⼀种复杂的中⼼性测量, 使⽤相邻顶点的相对重要性作为输⼊来计算给定顶点的重要性。 -
PageRank
-
中⼼性⽐较
3.6 JanusGraph数据存储
默认情况下, JanusGraph 使用随机分区策略, 将顶点随机分配给机器。随机分区非常有效, 不需要配置, 并且会产生平衡分区。当前不支持显式分区。
cluster.max-partitions = 32
ids.placement = simple
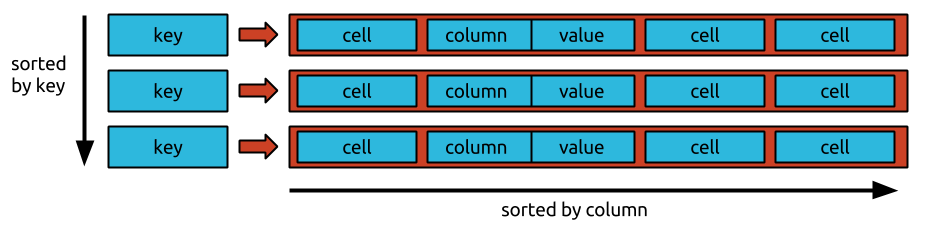
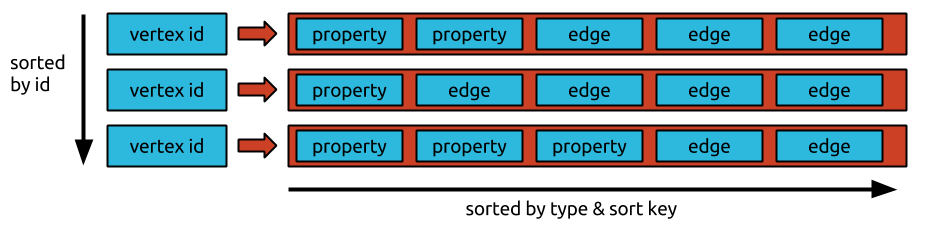
JanusGraph 以邻接列表格式存储图形, 这意味着图形存储为顶点及其邻接列表的集合。顶点的邻接列表包含顶点的所有入射边(和属性)。
JanusGraph 将图的邻接表表示形式存储在任何 支持 Bigtable 数据模型的存储后端中。
3.6.1 大表数据模型
3.6.2 JanusGraph 数据布局
3.6.3 数据分片
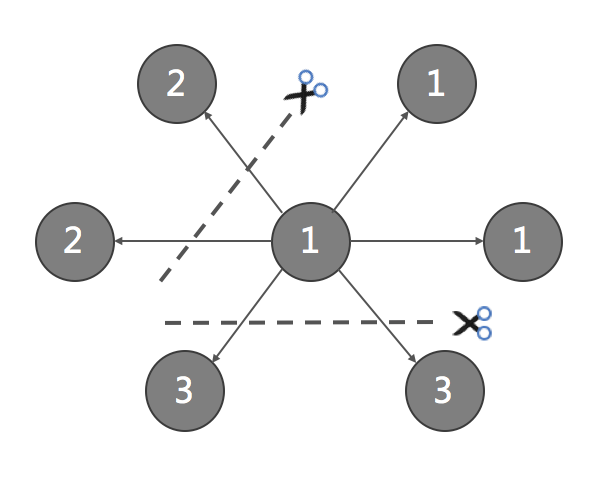
作为一种分布式图数据库, JanusGraph可将数据切分存储到多台机器上。JanusGraph采用的分片方式是按边切割, 而且是对于每一条边, 都会被切断。切断后, 该边会在起始顶点上和目的顶点上各存储一次。通过这种方式, JanusGraph不管是通过起始顶点, 还是从目的顶点, 都能快速找到对端顶点。下图所示就是按边切割的方式:
JanusGraph的数据以邻接表(adjacency list)的方式保存:
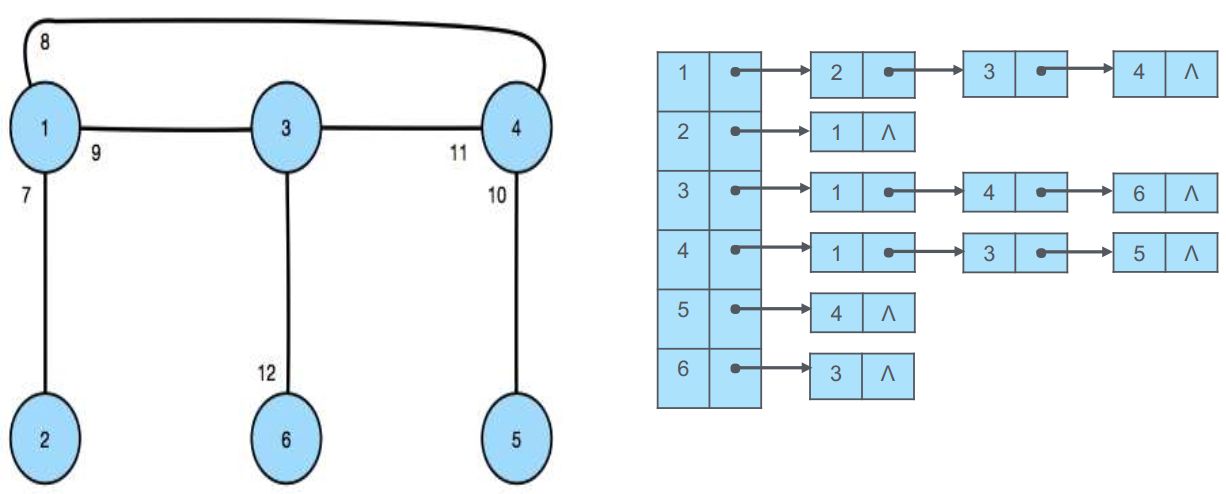
我们考虑下面最简单的图的数据在HBase中的存储方式:
下图为按边切分后的结果:

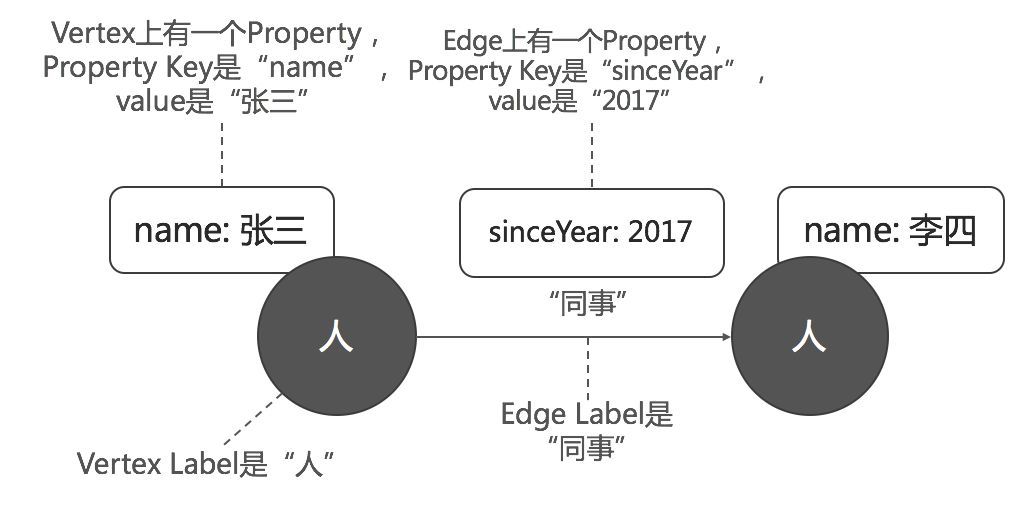
JanusGraph以点为中心, 按切边的方式存储数据。节点的ID作为HBase的Rowkey, 节点上的每一个属性和每一条边, 作为该Rowkey的一个个独立的Cell。即每一个属性、每一条边, 都是一个个独立的KCV结构(Key-Column-Value)。

JanusGraph 最多可以存储 quintillion 个边 (2^60) 和一半的顶点。JanusGraph 的 id 方案施加了这种限制。
4. Schema
mgmt = graph.openManagement()
mgmt.printSchema()
// mgmt.printIndexes(), mgmt.printPropertyKeys(), mgmt.printVertexLabels()
// mgmt.printEdgeLabels()
4.1 Vertex
像边一样, 顶点也有标签。与边标签不同, 顶点标签是可选的。顶点标签可用于区分不同类型的顶点, 例如user vertices 和 product vertices。
尽管标签在概念和数据模型级别是可选的, 但 JanusGraph 为所有顶点分配一个标签作为内部实现细节。这些方法创建的顶点addVertex使用 JanusGraph 的默认标签。
mgmt = graph.openManagement()
mgmt.printVertexLabels()
person = mgmt.makeVertexLabel('person').make()
mgmt.commit()
person = graph.addVertex(label, 'person')
v = graph.addVertex()
graph.tx().commit()
4.1.1 静态顶点
顶点标签可以定义为静态的, 这意味着具有该标签的顶点不能在创建它们的事务之外进行修改。
mgmt = graph.openManagement()
tweet = mgmt.makeVertexLabel('tweet').setStatic().make()
mgmt.commit()
4.2 Edge
连接两个顶点的每条边都有一个标签, 该标签定义了关系的语义。边缘标签多重性:
- MULTI: 允许任何一对顶点之间具有相同标签的多个边
- SIMPLE: 在任何一对顶点之间最多允许此类标签的一条边
- MANY2ONE
- ONE2MANY
- ONE2ONE
mgmt = graph.openManagement()
mgmt.printEdgeLabels()
follow = mgmt.makeEdgeLabel('follow').multiplicity(MULTI).make()
mother = mgmt.makeEdgeLabel('mother').multiplicity(MANY2ONE).make()
mgmt.commit()
4.3 Property
属性键是 JanusGraph 模式的一部分, 可以限制允许的数据类型和值的基数。
| Name | Description |
|---|---|
| String | Character sequence |
| Character | Individual character |
| Boolean | true or false |
| Byte | byte value |
| Short | short value |
| Integer | integer value |
| Long | long value |
| Float | 4 byte floating point number |
| Double | 8 byte floating point number |
| Date | Specific instant in time (java.util.Date) |
| Geoshape | Geographic shape like point, circle or box |
| UUID | Universally unique identifier (java.util.UUID) |
用于cardinality(Cardinality)定义与任何给定顶点上的键关联的值的允许基数:
- SINGLE: 对于此类键, 每个元素最多允许一个值
- LIST: 允许此类键的每个元素有任意数量的值
- SET: 对于此类键, 每个元素允许多个值但不允许重复值
mgmt = graph.openManagement()
mgmt.printPropertyKeys()
birthDate = mgmt.makePropertyKey('birthDate').dataType(Long.class).cardinality(Cardinality.SINGLE).make()
name = mgmt.makePropertyKey('name').dataType(String.class).cardinality(Cardinality.SET).make()
sensorReading = mgmt.makePropertyKey('sensorReading').dataType(Double.class).cardinality(Cardinality.LIST).make()
mgmt.commit()
边标签和属性键合称为关系类型。关系类型的名称在图中必须是唯一的, 这意味着属性键和边标签不能具有相同的名称。
4.4 Graph Index(Vertex)
4.5 Graph Index(Edge)
4.6 Relation Index(VCI)
5. 数据处理
5.1 数据加载
- storage.batch-loading: 启用批量加载会在许多地方禁用 JanusGraph 内部一致性检查
- ids.block-size: 增加 ids.block-size会减少获取的数量, 但可能会使许多 id 未分配并因此被浪费
- ids.authority.wait-time: 配置 id 池管理器等待存储后端确认 id 块应用程序的时间(以毫秒为单位)
- ids.renew-timeout: 配置 JanusGraph 的 id 池管理器在尝试获取新的 id 块失败前将等待的总毫秒数
- storage.buffer-size: 增加storage.buffer-size可以通过增加每个请求的写入次数来避免失败, 从而降低请求的数量
5.2 备份与恢复
存储后端的主持久化成功, 但索引后端或日志系统的辅助持久化失败, 事务仍然被认为是成功的, 因为存储后端是图的权威来源。但是, 这可能会导致与索引和日志不一致。为了自动修复这种不一致, JanusGraph 可以维护一个通过配置启用的事务预写日志。
tx.log-tx = true
tx.max-commit-time = 10000
- graphml
- graphson
- gryo
# 导出数据
g.io('/home/test.graphml').with(IO.writer,IO.graphml). write().iterate()
graph.io(IoCore.graphml()).writeGraph("/home/test.graphml")
# 导入数据
g.io('/home/test.graphml').with(IO.reader, IO.graphml).read().iterate()
graph.io(graphml()).readGraph('/home/test.graphml');
Import & export Janusgraph data using gremlin console: https://www.youtube.com/watch?v=jkOEE7VK0us
