
目录
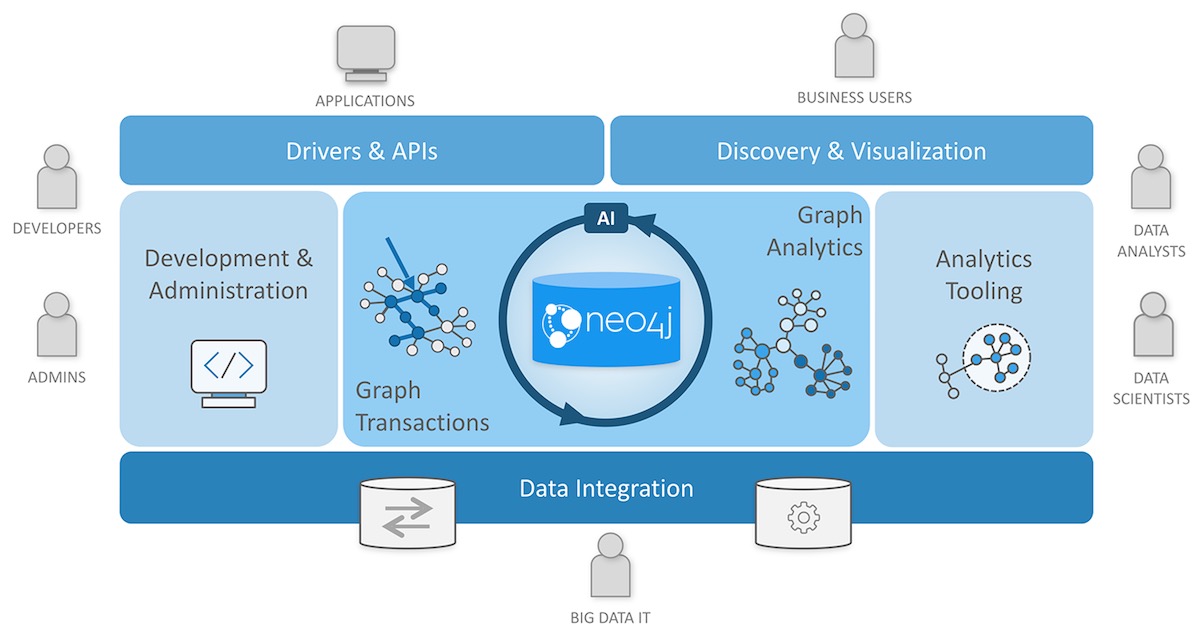
Neo4j是一个高性能的NOSQL图形数据库, 它将结构化数据存储在网络上而不是表中。它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎, 但是它将结构化数据存储在网络(从数学角度叫做图)上而不是表中。Neo4j也可以被看作是一个高性能的图引擎, 该引擎具有成熟数据库的所有特性。程序员工作在一个面向对象的、灵活的网络结构下而不是严格、静态的表中——但是他们可以享受到具备完全的事务特性、企业级的数据库的所有好处。
知识图谱由于其数据包含实体、属性、关系等, 常见的关系型数据库诸如MySQL之类不能很好的体现数据的这些特点, 因此知识图谱数据的存储一般是采用图数据库(Graph Databases)。而Neo4j是其中最为常见的图数据库。
1. Neo4j 基础
1.1 安装和运行
wget -c https://go.neo4j.com/download-thanks.html?edition=community&release=4.4.8&flavour=unix
tar xzf neo4j-community-4.4.8-unix.tar.gz
cd neo4j-community-4.4.8
vim conf/neo4j.conf
dbms.directories.data=/data/neo4j/data
dbms.directories.logs=/data/neo4j/logs
dbms.default_listen_address=0.0.0.0
# Notice JDK11
export JAVA_HOME=/usr/local/jdk-11.0.14
export NEO4J_HOME=/usr/local/neo4j-community-4.4.8
./bin/neo4j
1.2 基本概念
1.2.2 节点标签
在Neo4j中, 节点在默认情况下是没有类型的。确定领域模型中每一个节点应如何描述是开发者应考虑的问题。
每一个节点可以有一个或多个文字描述, 它称为节点标签。具有同样标签的节点用一种专用的方式存储, 因此它们能分为一组并可以一起使用。
标签是Neo4j的一个很好的补充, 不仅仅是一个分类的策略。因为节点可以有多个标签, 所以可以创建标签把经常一起使用的节点分组(即使不同的类型也可以), 从而不必使用属性。
1.2.2 节点(Node)
节点是指一个实实在在的对象, 这个对象可以有好多的标签, 表示对象的种类, 也可以有好多的属性, 描述其特征, 节点与节点之间还可以形成多个有方向(或者没有方向)的关系。
1.2.3 关系(Relationship)
用来描述节点与节点之间的关系, 这也是图数据与与普通数据库最大的区别, 正是因为有这些关系的存在, 才可以描述那些我们普通行列数据库所很难表示的网状关系, 比如我们复杂的人际关系网, 所谓的六度理论, 就可以很方便的用图数据库进行模拟, 比如我们大脑神经元之间的连接方式, 都是一张复杂的网。
有一点需要重点注意, 关系可以拥有属性。Relationship types 使用不常见的字符: CREATE (rob)-[:`TYPE WITH SPACE`]->(charlie)
1.2.4 属性(Property)
描述节点的特性, 采用的是Key-Value结构, 可以随意设定来描述节点的特征。
1.2.5 数据模型的类型
Neo4j是一个无架构数据库。在开始添加数据之前, 你并不需要定义表和关系。一个节点可以具有你喜欢的任何属性, 任何节点都可以与其他任何节点建立关系。Neo4j数据库中的数据模型隐含在它存储的数据中, 而不是明确地将数据模型定义为数据库本身的一个部分。它是对你想要存入数据库的数据的一个描述, 而不是数据库的一系列方法来限制将要存储的内容。
由于Neo4j的数据建模是描述性的, 而不是规定性的, 因此可以很容易对数据库将要存储的数据进行一致性的描述, 这样就可以以期望的方式构架查询, 并以相似的方式来描述相似的实体。
属性是Neo4j数据模型的重要组成部分, 而且这也是它不同于关系数据库模型的重要特征。在Neo4j中, 节点和关系都可以具有任意数量的属性, 这是非常重要的键/值对。它们通常用来存储节点和关系的特定属性。
2. Cypher
Cypher是对图形的声明查询语言, 使用图形模式匹配作为主要的机制作图形数据选择(包括只读和变更操作)。Cypher的声明模式匹配性质意味着可以通过描述想从它那里得到什么查询图形数据。
Cypher并不是唯一的图形查询语言, 另一个常用的图形查询语言是Gremlin, Neo4j也支持Gremlin。
Cypher和Gremlin的主要区别是它们的性质——Gremlin是命令式语言, 用户需要描述如何遍历图形, Cypher是声明性语言, 它使用模式匹配描述需要哪一部分图形数据。这就使得Cypher易读且易于理解。Gremlin可以在不同的图形数据库中移植, 而Cypher是由Neo4j团队开发, 并仅应用于Neo4j图形数据库。
2.1 关键字
| 关键字 | 说明 | Example |
|---|---|---|
| CREATE OR CREATE UNIQUE | 创建 | CREATE (:monster {name: "nemean"}) |
| MATCH | 匹配 | MATCH (a:demigod {'name': 'hercules'})-[:battled]->(b) |
| OPTIONAL MATCH | 用于搜索其中描述的模式, 同时对模式的缺失部分使用空值 | |
| MANDATORY MATCH | MATCH 的一种变体, 在期望匹配至少一个符合给定模式的节点的情况下强制匹配。 如果未找到匹配项, 则查询将失败。 | |
| RETURN | 返回 | RETURN a, b |
| RETURN DISTINCT | 去除重复后返回 | RETURN DISTINCT a, b |
| WHERE | 提供过滤模式匹配结果的条件 | WHERE NOT john-[:HAS_SEEN]->(movie) |
| AND,OR,XOR and NOT | ||
| MERGE | 保证给出的模式在图中一定存在, 要么复用已经存在的与断言匹配的节点和联系, 要么创建新的节点和联系 As with MATCH, MERGE can match multiple occurrences of a pattern. If there are multiple matches, |
|
| they will all be passed on to later stages of the query. | ||
| DELETE | 删除节点和关系 | MATCH (:god {name:"neptune"})-[r:father]->(:titan {name: "saturn"}) DELETE r; |
| DETACH DELETE | ||
| REMOVE | 删除节点和关系的属性 | MATCH (a:monster {name: "nemean"}) REMOVE a.age; |
| SET | 添加或更新属性 | MATCH (a:monster {name: "nemean"}) SET a += {age: 2300}; |
| ORDER BY xx ASC/DESC | 排序,(NULL的处理, 最大) | |
| SKIP | ||
| LIMIT | ||
| STARTS/ENDS WITH | ||
| CONTAINS | ||
| IN | "actor" IN labels(v1) |
|
| FOREACH | 对一个列表中的每个元素执行更新操作 | |
| UNION | 合并两个或更多查询的结果 | |
| WITH/WITH DISTINCT | 链式查询,前一个查询的结果作为后一个查询的条件 | |
| UNWIND | 将列表扩展为记录序列 | UNWIND [1, 2, 3] AS x RETURN x |
| () | 空括号, 匿名节点 | |
| [*] | 任意长度的任意路径 | |
| [:TYPE*minHops..maxHops] | 长度可变的路径 | MATCH (a)-[r1:father*1..2]->(c) RETURN a, c,r1 |
| CALL | CALL db.labels |
|
| START | is deprecated |
// God Graph
CREATE (:monster {name: "nemean"})<-[:battled {time: 1, place: "POINT (23.700001 38.099998)"}]-(hercules:demigod {name: "hercules", age: 30})-[:battled {place: "POINT (23.700001 38.099998)", time: 2}]->(:monster {name: "hydra"}),
(:location {name: "sky"})<-[:lives {reason: "loves fresh breezes"}]-(jupiter:god {name: "jupiter", age: 5000})<-[:father]-(hercules)-[:battled {time: 12, place: "POINT (22 39)"}]->(:monster {name: "cerberus"})<-[:pet]-(pluto:god {name: "pluto", age: 4000})-[:brother]->(neptune:god {name: "neptune", age: 4500})-[:brother]->(pluto),
(:location {name: "sea"})<-[:lives {reason: "loves waves"}]-(neptune)-[:brother]->(jupiter)<-[:brother]-(pluto)<-[:brother]-(jupiter)-[:father]->(:titan {name: "saturn", age: 10000}),
(jupiter)-[:brother]->(neptune),
(hercules)-[:mother]->(:human {name: "alcmene", age: 45}),
(pluto)-[:lives {reason: "no fear of death"}]->(:location {name: "tartarus"});
MATCH (a:demigod)-[:battled]->(b)
WHERE a.name = 'hercules'
RETURN a, b;
MERGE (a:god {name:"neptune"})
MERGE (b:titan {name: "saturn"})
CREATE (a)-[:father]->(b);
OPTIONAL MATCH (:demigod)-[]->(a:titan) RETURN
a
NULL
MATCH (:demigod)-[]->(a:titan) RETURN
(no changes, no records)
2.2 函数
| 函数名 | 说明 | Example |
|---|---|---|
| shortestPath | 两个节点之间找到一条最短路径 | p = shortestPath((martin)-[*..15]-(oliver)) |
| allShortestPaths | ||
| collect | 输出一个逗号分隔的列表 | |
| toUpper,toLower,substring,replace | 字符串函数 | MATCH (a:demigod) return toupper(a.name) |
| COUNT、MAX、MIN、AVG、SUM | 聚合函数,Cypher中的分组关键词被定义为所有的查询非聚合结果. | |
| STARTNODE | 查找关系的起始点 | |
| ENDNODE | 查找关系的终点 | |
| ID | 查找关系的ID | MATCH (a) WHERE id(a)=4 RETURN a |
| TYPE | 查找关系的类型, 也就是我们在图表中看到的名称 | |
| NODES(path) | 把一个路径转换成一个可迭代的节点集 | |
| EXISTS( |
如果一个节点或关系具有给定名字的属性存在, 则返回true | MATCH (v) WHERE exists(v.age) RETURN v |
| ALL(x in collection where predicate(x)) | 如果collection中的每一个单个元素匹配了给定的predicate, 则返回true | |
| NONE(x in collection where predicate(x)) | 如果提供的集合中没有元素匹配谓词表述, 返回true | |
| ANY(x in collection where predicate(x)) | 如果至少有一个元素匹配谓词表述, 返回true | |
| SINGLE(x in collection where predicate(x)) | 如果正好有一个元素匹配谓词表述, 返回true | |
| RAND() | 随机返回0~1之间的小数 | SKIP toInteger(3*rand())+ 1 |
| toInteger() | 返回整数(忽略小数部分) | |
| coalesce() |
2.3 Cypher Shell
Param:
:param { "props" : { "name" : "Andres", "position" : "Developer" } }
3. 索引
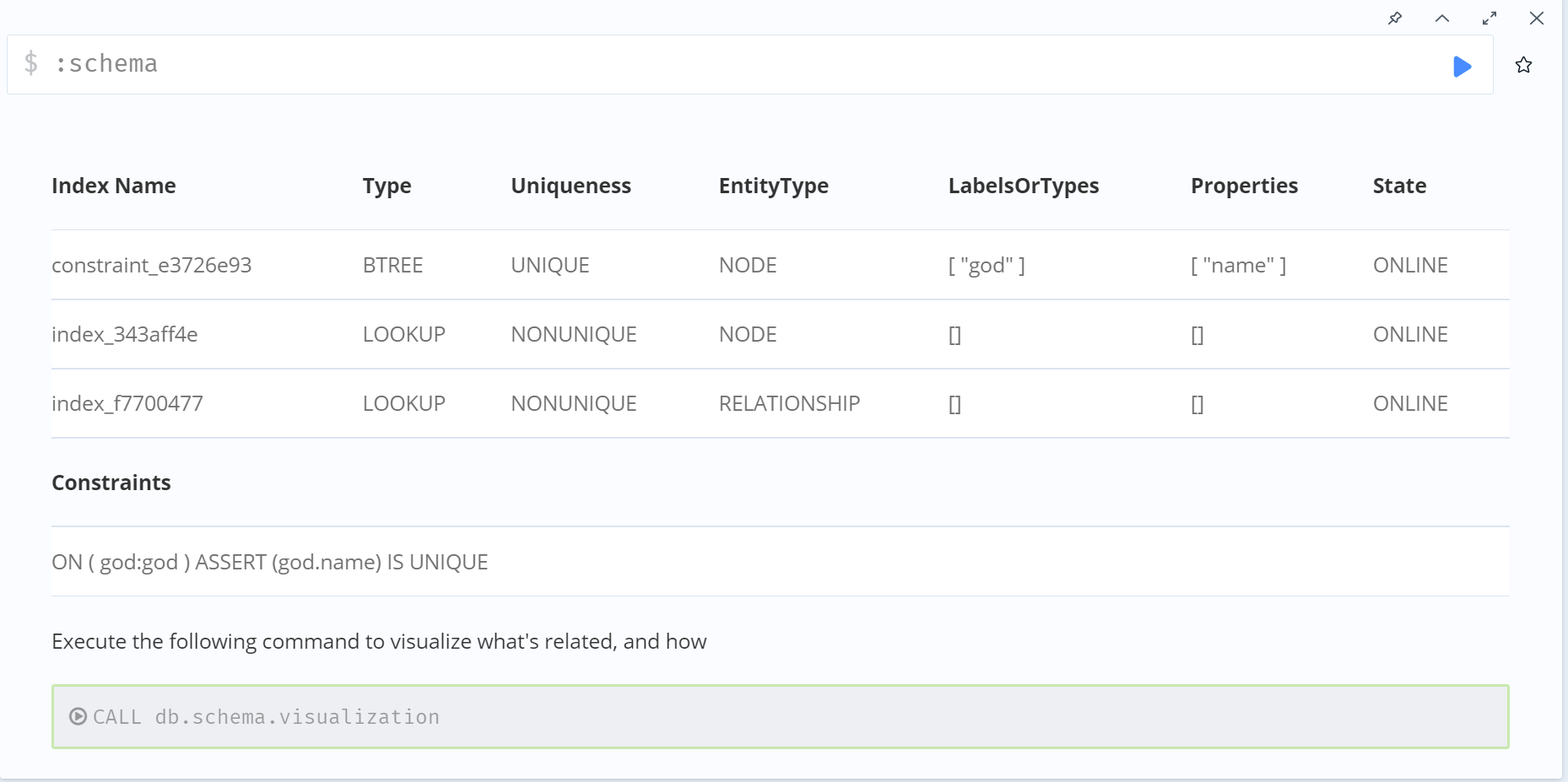
在默认情况下, Neo4j引擎通过标签和属性查找节点是以蛮力执行的(通过循环查找所有具有给定标签的节点, 并比较需要的属性名和值)。但是, 如果对标签和属性定义了模式索引, Neo4j引擎将会使用更快的索引查找。
- CREATE INDEX ON :LabelName(propertyName)
- DROP INDEX ON :LabelName(propertyName)
- CREATE CONSTRAINT ON (c:LabelName) ASSERT c.name IS UNIQUE: 唯一性限制
- DROP CONSTRAINT ON (c:god) ASSERT c.name IS UNIQUE
- :schema 查看所有索引和约束
因为应用开发者对使用的索引策略非常谨慎, 所以Neo4j并不自动更新由手动做的索引引起的图形数据库本身的数据改变。
一旦已经查找过一个索引, 就没有方法对这个已经存在的索引进行修改。解决的方法非常简单: 当处理Neo4j索引时, “先删除后添加”等于“更新”。
3.1 模式索引
在2.0版本中, Neo4j引进了模式索引的概念, 从概念上讲, 这与传统的关系数据库使用的索引处理方法很相似。模式索引与节点标签的概念紧密相关.
3.2 自动索引
要使用自动索引, 需要告诉Neo4j打开节点或关系, 或两者同时自动索引。但是, 仅仅是打开自动索引并不会引起任何变化。
在单机运行模式下打开自动索引, 需要以额外的属性修改配置文件。配置文件在$NEO4J_SERVER/conf/neo4j.properties文件夹中, 需要添加以下两行:
node_auto_indexing=true
relationship_auto_indexing=true
4. Neo4j 进阶
4.1 集群
Neo4j 集群使用主从复制实现高可用性和水平读扩展。
Neo4j 也允许通过从节点进行写入操作, 不过此时, 被写入的从节点会先将数据同步到主节点, 再将数据返回客户端。
ha.tx_push_factor = 2
ha.tx_push_strategy = ""
4.2 数据导入和导出
neo4j-admin import \
-multiline-fields**=true \
-database test1.db \
-nodes "/home/neo4j/node.csv" \
-relationships "/home/neo4j/relation.csv"
# –multiline-fields: 是否允许多行插入(即有些换行的数据也可读取)
# 数据库的名字, 必须是新的空的数据库
# 节点文件的位置
# 关系文件的位置
LOAD CSV WITH HEADERS FROM "/home/neo4j/locations.csv" AS line
WITH split(line.locations, ";") as locations, line.title as title
UNWIND locations AS location
MERGE (x:location {name:location})
MERGE (m:Movie {title:title})
MERGE (m)-[:FILMED_IN]->(x)
neo4j-admin dump
neo4j-admin load
4.3 清空 Neoj4
对于少量数据, 第一种方案是很方便的, 但是数据量大的时候很慢, 而且容易造成内存溢出, 毕竟是先查出来再删除, 这个时候就应该用第二种方案了, 方便, 快速。
方法一: Cypher 语法
match (n) detach delete n
方法一: 删除目录
- 停掉服务
- 删除 graph.db 目录
- 重启服务
4.4 事务
Neo4j与其他一些没有结构化查询(NoSQL)技术的不同点在于, Neo4j是ACID完全兼容的(ACID是Atomic、Consistent、Isolated、Durable的首字母缩写——原子的、一致的、隔离的、持续的)。ACID完全兼容意味着Neo4j与使用传统的关系数据库一样有保证。
Neo4j事务的默认设置并不自动获取读锁。因此, 读的数据是节点、关系、索引实体最新提交的状态, 除非在它自己的事务中, 局域的修改(即使没提交)是可见的。
写锁则是在对任意图形资源试图做变更操作时自动获得, 在事务的持续时间内都有效。每一个事务确保在完成时自动释放所有的锁。这个默认行为与关系数据库中的读提交隔离级别非常相似, 隔离级别除去了潜在的脏读, 但是仍然允许幻像读和不可重复读的发生。
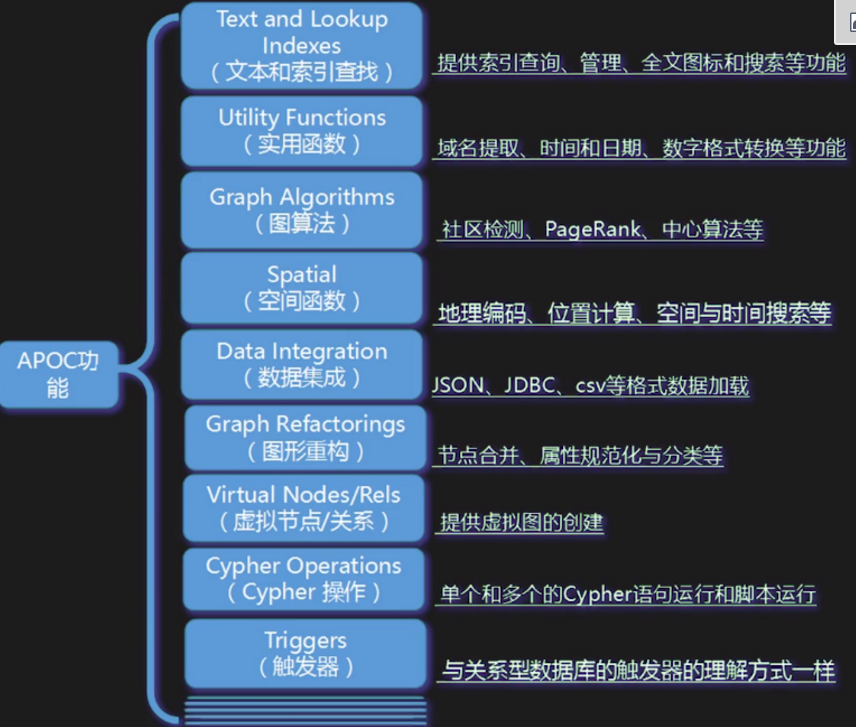
5. APOC
APOC - Awesome Procedures of Cypher 是Neo4j图数据库的扩展过程和函数库。
Neo4j图数据库扩展是基于Neo4j相关API和开发框架、使用Java开发的、部署在服务器端的过程和函数。这些过程和函数可以在Cypher中被调用, 就像存储过程可以在SQL中被调用一样, 因此我们有时也称这些过程为“存储过程”。
APOC提供了丰富的与查询执行、数据集成、数据库管理等相关的过程和函数。其他的扩展库例如ALGO则包含常用的图算法过程。
ALGO扩展包是二进制JAR文件, 可以直接下载、安装, 经过简单配置即可使用。
APOC的下载链接是: http://github.com/neo4j-contrib/neo4j-apoc-procedures/releases/
在线文档: https://neo4j.com/docs/labs/apoc/current/
5.1 安装
安装完成、重新启动服务器后, 可以在Neo4j Browser中输入以下命令测试安装:
RETURN apoc.version()
5.1.1 自动安装
在Neo4j Desktop中安装APOC扩展包只需找到’Plugins’面板, 然后点击’Install’按钮。安装过程会自动下载最新版本的JAR文件、复制到特定本地目录下, 并修改配置文件。
5.1.2 手动安装
手动安装扩展包包括以下步骤:
- 根据Neo4j版本选择兼容的ALGO和APOC扩展包进行下载
- 将下载的JAR文件复制到
<NEO4J_HOME>/plugins目录下 - 打开
<NEO4J_HOME>/conf/neo4j.conf文件, 添加以下配置选项:
dbms.security.procedures.unrestricted=apoc.*
如果需要使用APOC的导入导出过程, 还需要添加下面的行:
apoc.export.file.enabled=true
apoc.import.file.enabled=true
- 重新启动Neo4j数据库服务。
5.1.2 在Docker部署的Neo4j实例上安装
如果使用Docker部署Neo4j服务器, 可以先将扩展包JAR文件下载存储在本地或网络存储的/plugins卷中, 在Docker实例启动时加载该卷。例子如下:
mkdir plugins
pushd plugins
wget https://github.com/neo4j-contrib/neo4j-apoc-procedures/releases/download/3.5/apoc-3.5-all.jar
popd
docker run --rm -e NEO4J_AUTH=none -p 7474:7474 -v \
$PWD/plugins:/plugins -p 7687:7687 neo4j:3.5
5.2 主要功能
6. 常用语法
MERGE (a:User {uid:'6ce58d75129d1dbdc472349251936d35', name: 'Lisi'}) MERGE (b:Movie {id:'m10727641'}) CREATE (a)-[:RATING {rating:4}]->(b);
MERGE (a:User {uid:'6ce58d75129d1dbdc472349251936d35', name: 'Lisi'}) MERGE (b:Movie {id:'m1308767'}) CREATE (a)-[:RATING {rating:3}]->(b);
MATCH (u1:User {uid:'6ce58d75129d1dbdc472349251936d35'})-[r1:RATING]->(m1)-[r2:DIRECTED|STARRING|HAS_TAG]-(u2)-[r3:DIRECTED|STARRING|HAS_TAG]-(m2:Movie {id: 'm26336252'}) RETURN u1,u2, r1, r2,r3, m1, m2
MATCH (u1:User {uid:'6ce58d75129d1dbdc472349251936d35'})-[r1:RATING]->(m1)-[r2:DIRECTED|STARRING]-(u2)-[r3:DIRECTED|STARRING]->(m2) RETURN u1,u2, r1, r2,r3, m1, m2
MATCH (u1:User {uid:'6ce58d75129d1dbdc472349251936d35'})-[r1:RATING]->(m1)-[r2:DIRECTED|STARRING|HAS_TAG]-(u2)-[r3:DIRECTED|STARRING|HAS_TAG]-(m2:Movie {id: 'm3274505'}) RETURN u1,u2, r1, r2,r3, m1, m2
MATCH (a:Movie {id: "m1401533"}) SET a.score = 0;
MATCH (n:Movie) WHERE n.name=~'碟中谍.*' RETURN n
MATCH (n:Movie) WHERE n.name starts with '碟中谍' RETURN n
CALL apoc.periodic.iterate("
MATCH (e:Entity)
WHERE e.id STARTS WITH 'Q'
RETURN e
","
// Prepare a SparQL query
WITH 'SELECT * WHERE{ ?item rdfs:label ?name . filter (?item = wd:' + e.id + ') filter (lang(?name) = \\"en\\") ' +
'OPTIONAL {?item wdt:P31 [rdfs:label ?label] .filter(lang(?label)=\\"en\\")}}' AS sparql, e
// make a request to Wikidata
CALL apoc.load.jsonParams(
'https://query.wikidata.org/sparql?query=' +
sparql,
{ Accept: 'application/sparql-results+json'}, null)
YIELD value
UNWIND value['results']['bindings'] as row
SET e.wikipedia_name = row.name.value
WITH e, row.label.value AS label
MERGE (c:Class {id:label})
MERGE (e)-[:INSTANCE_OF]->(c)
RETURN distinct 'done'", {batchSize:1, retry:1})
UNWIND $data AS row
MERGE (h:Entity {id: CASE WHEN NOT row.head_span.id = 'id-less' THEN row.head_span.id ELSE row.head_span.text END})
ON CREATE SET h.text = row.head_span.text
MERGE (t:Entity {id: CASE WHEN NOT row.tail_span.id = 'id-less' THEN row.tail_span.id ELSE row.tail_span.text END})
ON CREATE SET t.text = row.tail_span.text
WITH row, h, t
CALL apoc.merge.relationship(h, toUpper(replace(row.relation,' ', '_')),
{},
{},
t,
{}
)
YIELD rel
RETURN distinct 'done' AS result;
参考:
