
目录
-
- 1.Elasticsearch 参数与设置
- 2. Elasticsearch 管理
- 3. 基本知识点
-
4. 聚合查询
- 4.1 数据聚合
-
4.2 Mertics 聚合查询
- 4.2.1 avg
- 4.2.2 Weighted Avg(加权平均)
- 4.2.3 Cardinality Aggregation(基数聚合)
- 4.2.4 Extended Stats Aggregation(扩展统计汇总)
- 4.2.5 Geo Bounds Aggregation
- 4.2.6 Geo Centroid Aggregation
- 4.2.7 Max Aggregation
- 4.2.8 Min Aggregation
- 4.2.9 Percentiles Aggregation
- 4.2.10 Percentiles Ranks Aggregation
- 4.2.11 Scripted Metric Aggregation
- 4.2.12 Stats Aggregation
- 4.2.13 Sum Aggregation
- 4.2.14 Top Hits Aggregation
- 4.2.15 Value Count Aggregation
- 4.2.16 Median Absplute Deviation Aggregation
-
4.3 Bucket 聚合查询
- 4.3.1 Adjacency Matrix Aggregation
- 4.3.2 Auto-interval Date Histogram Aggregation
- 4.3.3 Children Aggregation
- 4.3.4 Composite Aggregation
- 4.3.5 Date Histogram Aggregation
- 4.3.6 Date Range Aggregation
- 4.3.7 Diversified Sampler Aggregation
- 4.3.8 Filter Aggregation
- 4.3.9 Filters Aggregation
- 4.3.10 Filters Aggregation
- 4.3.11 Geo Distance Aggregation
- 4.3.12 GeoHash grid Aggregation
- 4.3.13 GeoTile Grid Aggregation
- 4.3.14 Global Aggregation
- 4.3.15 Histogram Aggregation
- 4.3.16 IP Range Aggregation
- 4.3.17 Missing Aggregation
- 4.3.18 Nested Aggregation
- 4.3.19 Parent Aggregation
- 4.3.20 Range Aggregation
- 4.3.21 Rare Terms Aggregation
- 4.3.22 Reverse nested Aggregation
- 4.3.23 Sampler Aggregation
- 4.3.24 Significant Terms Aggregation
- 4.3.25 Significant Text Aggregation
- 4.3.26 Terms Aggregation
- 4.3.27 Subtleties of bucketing range Aggregation
-
4.4 Pipeline 聚合查询
- 4.4.1 Avg bucket Aggregation
- 4.4.2 Derivative Aggregation
- 4.4.3 Max Bucket Aggregation
- 4.4.4 Min Bucket Aggregation
- 4.4.5 Sum Bucket Aggregation
- 4.4.6 Stats Bucket Aggregation
- 4.4.7 Extended Stats Bucket Aggregation
- 4.4.8 Percentiles Bucket Aggregation
- 4.4.9 Moving Average Aggregation
- 4.4.10 Moving Function Aggregation
- 4.4.11 Cumulative Sum Aggregation
- 4.4.12 Cumulative Cardinality Aggregation
- 4.4.13 Bucket Script Aggregation
- 4.4.14 Bucket Selector Aggregation
- 4.4.15 Bucket Sort Aggregation
- 4.4.16 Serial Differencing Aggregation
- 4.5 Matrix 聚合查询
- 4.6 Caching heavy aggregations
- 5. DSL 查询
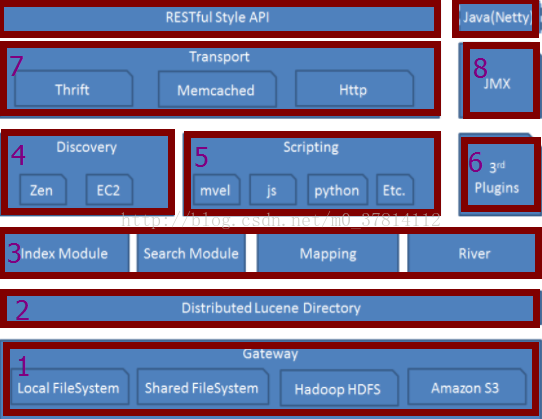
Elasticsearch是一个基于Lucene库的搜索引擎。它提供了一个分布式、支持多租户的全文搜索引擎, 具有HTTP Web接口和无模式JSON文档。Elasticsearch是用Java开发的, 并在Apache许可证下作为开源软件发布。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示, Elasticsearch是最受欢迎的企业搜索引擎, 其次是Apache Solr, 也是基于Lucene。
倒排索引(英语: Inverted index), 也常被称为反向索引、置入文件或反向文件, 是一种索引方法, 被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最常用的数据结构。有两种不同的反向索引形式:
- 一条记录的水平反向索引(或者反向文件索引)包含每个引用单词的文档的列表
- 一个单词的水平反向索引(或者完全反向索引)又包含每个单词在一个文档中的位置
以英文为例, 下面是要被索引的文本:
0. "it is what it is"
1. "what is it"
2. "it is a banana"
我们就能得到下面的反向文件索引:
"a": {2}
"banana": {2}
"is": {0, 1, 2}
"it": {0, 1, 2}
"what": {0, 1}
1.Elasticsearch 参数与设置
1.1 环境变量
- ES_HOME
- ES_PATH_CONF, 默认为 $ES_HOME/config
- ES_TMPDIR
- 环境变量使用: \({...}, 如: `node.name: \){HOSTNAME}`
1.2 配置文件
1.2.1 elasticsearch.yml
# 路径设置
path.data: ""
path.logs: ""
# 集群名
cluster.name: ""
# 节点名
node.name: ""
# 网络主机, 默认Elasticsearch 绑定到本地
network.host: ""
# Discovery setting
discovery.seed_host: ""
# 节点名
cluster.inital_master_nodes: ""
discovery.seed_hosts:
- 192.168.1.10:9300
- 192.168.1.11
- seeds.mydomain.com
cluster.initial_master_nodes:
- master-node-a
- master-node-b
- master-node-c
1.2.2 jvm.options
注意, ES 故意忽略了 JAVA_TOOL_OPTIONS, 也不支持 JAVA_OPTS !
# 堆大小(JVM)g = GB, m = MB
-Xms1g
-Xmx1g
# 也可以通过 ES_JAVA_OPTS 环境变量来设置 JVM 选项, 如:
export ES_JAVA_OPTS="$ES_JAVA_OPTS -Djava.io.tmpdir=/path/to/temp/dir"
1.2.3 log4j2.properties
使用 Log4j2 来记录日志, ElasticSearch 提供了三个属性:
1). ${sys:es.logs.base_path} 日志路径
2). ${sys:es.logs.cluster_name} 集群名
3). ${sys:es.logs.node_name} 节点名
有四种方式来配置日志级别:
1). 命令行:
-E <name of logging hierarchy>=<level>(如: -E logger.org.elasticsearch.transport=trace)
2). elasticsearch.yml 文件中,
<name of logging hierarchy>: <level> (e.g., logger.org.elasticsearch.transport: trace).
3). API接口
json PUT /_cluster/settings { "transient": { "logger.org.elasticsearch.transport": "trace" } }
4). log4j2.properties 文件
logger.<unique_identifier>.name = <name of logging hierarchy> logger.<unique_identifier>.level = <level>
1.2.4 elasticsearch.keystore
密钥库, 管理工具: elasticsearch-keystore,
- 应以Elasticsearch 的用户身份来运用管理工具。
- 不正确的设置会导致Elasticsearch 无法启动
- 所有的修改都必需重启Elasticsearch 财生效
- elasticsearch.keystore只是混淆, 并没有提供加密
# 列出设置
./bin/elasticsearch-keystore list
keystore.seed
# 添加设置
./bin/elasticsearch-keystore add the.setting.name.to.set
Enter value for the.setting.name.to.set:
# 从文件中批量导入
./bin/elasticsearch-keystore add-file the.setting.name.to.set /path/example-file.json
# 删除
./bin/elasticsearch-keystore remove the.setting.name.to.remove
# 更新设置
./bin/elasticsearch-keystore upgrade
# 部分安全设置, 可以通过API接口来更新生效:
POST _nodes/reload_secure_settings
1.2.5 重要的系统配置
# 产品模式下, 以下的设置如果不正确, Elasticsearch 将不能启动!
# 禁用swapping
swapoff -a
# 或者配置 sysctl value vm.swappiness is set to 1
vm.swappiness = 1
# 或者配置 config/elasticsearch.yml, 阻止swap
# 查看是否生效: GET _nodes?filter_path=.mlockall (要重启)
bootstrap.memory_lock: true
# 增加文件描述符
# 验证 GET _nodes/stats/process?filter_path=.max_file_descriptors
elasticsearch - nofile 65535
# 确保足够的虚拟内存
sysctl -w vm.max_map_count = 262144
# /ets/sysctl.conf
vm.max_map_count = 262144
sysctl -p
# 确保足够的线程
# JVM DNS 缓存设置
# 临时目录未用noexec挂载
1.2.6 开发与产品
network.host: ""
# 请注意, 可以通过http.host和transport.host独立配置HTTP和传输。 这对于将单个节点配置为可通过HTTP进行访问以进行测试(而不触发生产模式)很有用。
#单节点模式
discovery.type: single-node
1.2.7 其他
-
强制引导检查(bootstrap checks)
- Heap Size Check
- File Descriptor check
- Memory lock check
- Maximum number of threads check
- Max file size check
- Maximum size virtual memory check
- Maximum map count check
- Client JVM check
- Use serial collector check
- System call filter check
- OnError and OnOutOfMemoryError checks
- Early-access check
- G1GC check
- All permission chec
- Discovery configuration check
-
Elasticsearch 终止错误码:
| 错误码 | 说明 |
|---|---|
| 128 | JVM internal error |
| 127 | Out of memory error |
| 126 | Stack overflow error |
| 125 | Unknown virtual machine error |
| 124 | Serious I/O error |
| 1 | Unknown fatal error |
- X-Pack
是Elastic Stack扩展, 提供安全性, 警报, 监视, 报告, 机器学习和许多其他功能。
2. Elasticsearch 管理
2.1 节点升级
升级节点之前, 应该禁用副本分配以避免竞争:
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.enable": "primaries"
}
}
// 刷新索引
POST _flush/synced
// 检查重启后的节点(日志或GET)
GET _cat/nodes
// 恢复
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.enable": null
}
}
// 监控节点恢复状态
GET _cat/recovery
// 重启机器学习 jobs
POST _ml/set_upgrade_mode?enabled=false
2.2 常用的管理API接口
curl -XGET http://192.168.137.3:9200/_cat?v # ?v 显示有意义的标题
# curl -XGET http://192.168.137.3:9200/_cat/indices
# curl -XGET http://192.168.137.3:9200/_cat/nodes
curl -XGET http://192.168.137.3:9200/_stats
curl -XGET http://192.168.137.3:9200/_nodes
3. 基本知识点
3.1 查询分类
-
简单查询
match, multi_match, common, fuzzy_like_this, fuzzy_like_this_field, geoshape, ids, match_all, query_string, simple_query_string, range, prefix, regexp, span_term, term, terms, wildcard -
组合查询
bool, boosting, constant_score, dis_max, filtered, function_score, has_child, has_parent, indices, nested, span_first, span_multi, span_near, span_not, span_or, span_term, top_child -
无分析查询
common, ids, prefix, span_term, term, terms, wildcard -
全文检索查询
match, multi_match, query_string, simple_query_string -
模式匹配查询
prefix, regexp, wildcard -
支持相似度操作查询
fuzzy_like_this, fuzzy_like_this_field, fuzzy, more_like_this, more_like_this_field -
支持打分操作的查询
boosting, constant_score, function_score, indices -
位置敏感查询
match_phrase, span_first, span_multi, span_near, span_not, span_or, span_term -
结构敏感查询
nested, has_child, has_parent, top_child
3.2 数据类型
3.2.1 常见数据类型
- binary: Binary value encoded as a Base64 string.
- boolean: true and false values.
- Keywords: The keyword family, 包括keyword, constant_keyword, 和wildcard.
- Numbers: Numeric types, such as long and double, used to express amounts.
3.2.2 日期
Date types, including date and date_nanos.
3.2.3 alias
Defines an alias for an existing field.
3.2.4 Objects and relational types
- object: A JSON object.
- flattened: An entire JSON object as a single field value.
- nested: A JSON object that preserves the relationship between its subfields.
- join: Defines a parent/child relationship for documents in the same index.
3.2.5 Structured data types
- Range: Range types, such as long_range, double_range, date_range, and ip_range.
- ip: IPv4 and IPv6 addresses.
- version: Software versions. Supports Semantic Versioning precedence rules.
- murmur3: Compute and stores hashes of values.
3.2.6 聚合数据类型
- aggregate_metric_double: Pre-aggregated metric values.
- histogram: Pre-aggregated numerical values in the form of a histogram.
3.2.7 文本搜索类型
- text fields: The text family, including text and match_only_text. Analyzed, unstructured text.
- annotated-text: Text containing special markup. Used for identifying named entities.
- completion: Used for auto-complete suggestions.
- search_as_you_type: text-like type for as-you-type completion.
- token_count: A count of tokens in a text.
3.2.8 文档排序类型
- dense_vector: Records dense vectors of float values.
- sparse_vector: Records sparse vectors of float values.
- rank_feature: Records a numeric feature to boost hits at query time.
- rank_features: Records numeric features to boost hits at query time.
3.2.9 空间数据类型
- geo_point: Latitude and longitude points.
- geo_shape: Complex shapes, such as polygons.
- point: Arbitrary cartesian points.
- shape: Arbitrary cartesian geometries.
3.2.10 其他
- percolator: 以Query DSL编写的索引查询.
3.2.11 数组
在 Elasticsearch 中, 数组不需要专用的字段数据类型。默认情况下, 任何字段都可以包含零个或多个值, 但是, 数组中的所有值必须具有相同的字段类型。请参阅数组
3.2.12 多领域
为不同的目的以不同的方式索引相同的字段通常很有用。例如, 一个string字段可以被映射为一个text用于全文搜索的keyword字段, 以及一个用于排序或聚合的字段。或者, 您可以使用standard分析器、 english分析器和 french分析器为文本字段编制索引。
这就是多字段的目的。大多数字段类型通过fields参数支持多字段。
3.3 相关概念
| 关系型数据库 | Elasticsearch |
|---|---|
| 数据库 Database | 索引Index, 支持全文检索 |
| 表 Table | 类型 TYpe |
| 数据行 Row | 文档Document, 但不需要固定结构, 不同文档可以具有不同的字段集合 |
| 数据列 Column | 字段 Field |
| 模式 Schema | 映像 Mapping |
3.4 插件安装
# https://github.com/medcl/elasticsearch-analysis-pinyin/releases
# https://github.com/medcl/elasticsearch-analysis-ik/releases/
# 本地安装
./bin/elasticsearch-plugin install file:<path>
# 远程安装
./bin/elasticsearch-plugin install <url>
4. 聚合查询
4.1 数据聚合
4.1.1 聚合的类型
Bucketing
Metric 指标
single-value numeric metrics aggregation
multi-value numeric metrics aggregation
Matrix 矩阵
Pipeline
汇总其他汇总及其相关指标的输出的汇总
# 一般聚合查询的格式如:
# 注: aggregations 可以简写为 aggs
"aggregations" : {
"<aggregation_name>" : {
"<aggregation_type>" : {
<aggregation_body>
}
[,"meta" : { [<meta_data_body>] } ]?
[,"aggregations" : { [<sub_aggregation>]+ } ]?
}
[,"<aggregation_name_2>" : { ... } ]*
}
4.2 Mertics 聚合查询
4.2.1 avg
POST /exams/_search?size=0
{
"aggs" : {
"avg_grade" : { "avg" : { "field" : "grade" } }
}
}
# 使用脚本
POST /exams/_search?size=0
{
"aggs" : {
"avg_grade" : {
"avg" : {
"script" : {
"id": "my_script",
"params": {
"field": "grade"
}
}
}
}
}
}
4.2.2 Weighted Avg(加权平均)
计算公式: ∑(value * weight) / ∑(weight)
符号: weighted_avg
参数:
# value 必须
# weight 必须
# format 可选
# value_type 可选
# 例如:
POST /exams/_search
{
"size": 0,
"aggs" : {
"weighted_grade": {
"weighted_avg": {
"value": {
"field": "grade"
},
"weight": {
"field": "weight"
}
}
}
}
}
4.2.3 Cardinality Aggregation(基数聚合)
基于 HyperLogLog++ 算法
符号: cardinality
4.2.4 Extended Stats Aggregation(扩展统计汇总)
符号: extended_stats
偏差界限: sigma
GET /exams/_search
{
"size": 0,
"aggs" : {
"grades_stats" : {
"extended_stats" :
{
"field" : "grade",
"sigma : 3
}
}
}
}
4.2.5 Geo Bounds Aggregation
符号: geo_bounds
可选参数: wrap_longitude, 用于指定是否应允许边界框与国际日期线重叠。默认为True
POST /museums/_search?size=0
{
"query" : {
"match" : { "name" : "musée" }
},
"aggs" : {
"viewport" : {
"geo_bounds" : {
"field" : "location",
"wrap_longitude" : true
}
}
}
}
4.2.6 Geo Centroid Aggregation
符号: geo_centroid
4.2.7 Max Aggregation
符号: max
4.2.8 Min Aggregation
符号: min
4.2.9 Percentiles Aggregation
符号: percentiles
默认的百分位范围为: [ 1, 5, 25, 50, 75, 95, 99 ]
压缩参数: “tdigest”: { “compression” : 200 }, 压缩参数将最大节点数限制为20 *compression。
HDR 直方图: “hdr”: { “number_of_significant_value_digits” : 3 }
百分位数度量标准使用的算法称为TDigest(由Ted Dunning在“Computing Accurate Quantiles using T-Digests”中引入)。
4.2.10 Percentiles Ranks Aggregation
符号: percentile_ranks
HDR 直方图: “hdr”: { “number_of_significant_value_digits” : 3 }
4.2.11 Scripted Metric Aggregation
符号: scripted_metric
1. init_script
2. map_script
3. combine_script
4. reduce_script
4.2.12 Stats Aggregation
4.2.13 Sum Aggregation
4.2.14 Top Hits Aggregation
符号: top_hits
可以用来组织文档分类
// GET blog/_search/
{
"size": 0,
"aggs": {
"when": {
"histogram": {
"field": "id",
"interval": 500
},
"aggs": {
"title": {
"top_hits": {
"_source": {
"includes": ["title"] // 简化返回结果
},
"size": 1
}
}
}
}
}
}
4.2.15 Value Count Aggregation
符号: value_count
4.2.16 Median Absplute Deviation Aggregation
中位数绝对偏差是变异性的量度。这是一个可靠的统计信息, 这意味着它对于描述可能具有异常值或未正常分布的数据很有用。 对于此类数据, 它比标准偏差更具描述性。
符号: median_absolute_deviation
压缩: compression, 默认为1000
GET reviews/_search
{
"size": 0,
"aggs": {
"review_variability": {
"median_absolute_deviation": {
"field": "rating",
"compression": 100
}
}
}
}
4.3 Bucket 聚合查询
4.3.1 Adjacency Matrix Aggregation
邻接矩阵汇总
符号: adjacency_matrix
4.3.2 Auto-interval Date Histogram Aggregation
自动间隔日期直方图聚合
符号: auto_date_histogram
参数:
time_zone
minimum_interval
4.3.3 Children Aggregation
一种特殊的单存储桶聚合, 用于选择具有指定类型的子文档, 如联接字段中所定义。
唯一的选项: type
4.3.4 Composite Aggregation
复合聚合
符号: composite
4.3.5 Date Histogram Aggregation
日期直方图聚合
符号: date_histogram
参数:
calendar_interval
fixed_interval
// GET blog/_search/
{
"query": {
"match_all": {}
},
"aggs": {
"my results": {
"date_histogram": {
"field": "post_date",
"interval": "year"
}
}
}
}
4.3.6 Date Range Aggregation
符号: date_range
参数:
“ranges”: [{ “to”: “now-10M/M” }, { “from”: “now-10M/M” }]
“time_zone”: “CET”
4.3.7 Diversified Sampler Aggregation
多元化的采样器聚合
符号: diversified_sampler
4.3.8 Filter Aggregation
符号: filter
4.3.9 Filters Aggregation
符号: filters
GET logs/_search
{
"size": 0,
"aggs" : {
"messages" : {
"filters" : {
"filters" : {
"errors" : { "match" : { "body" : "error" }},
"warnings" : { "match" : { "body" : "warning" }}
}
}
}
}
}
4.3.10 Filters Aggregation
符号: filters
4.3.11 Geo Distance Aggregation
符号: geo_distance
参数:
unit: 默认距离单位为 m(meters米), 可以接受的单位: mi (miles英里), in (inches), yd (yards码), km (kilometers), cm (centimeters), mm (millimeters).
distance_type: 两种计算模式 arc (默认, 更精确), 和 plane
POST /museums/_search?size=0
{
"aggs" : {
"rings_around_amsterdam" : {
"geo_distance" : {
"field" : "location",
"origin" : "52.3760, 4.894",
"unit" : "km",
"distance_type" : "plane",
"ranges" : [
{ "to" : 100000 },
{ "from" : 100000, "to" : 300000 },
{ "from" : 300000 }
]
}
}
}
}
4.3.12 GeoHash grid Aggregation
符号: geohash_grid
精度在 1 - 12 之间
4.3.13 GeoTile Grid Aggregation
符号: geotile_grid
精度在 0 - 29 之间
4.3.14 Global Aggregation
全局聚合器只能作为顶级聚合器放置, 因为将全局聚合器嵌入另一个存储桶聚合器中没有意义。
符号: global
4.3.15 Histogram Aggregation
舍入函数: bucket_key = Math.floor((value - offset) / interval) * interval + offset
符号: histogram
参数:
min_doc_count
extended_bounds extended_bounds is not filtering buckets!
POST /bank/_search?size=0
{
"query" : {
"constant_balance" : {
"filter": {
"range" : {
"balance" : {
"to" : "40000" ,
"from" : "1000"
}
}
}
}
},
"aggs" : {
"balance" : {
"histogram" : {
"field" : "balance",
"interval" : 5000,
"min_doc_count": 1,
"extended_bounds" : {
"min" : 10000,
"max" : 30000
}
}
}
}
}
GET blog/_search/
{
"query": {
"query_string": {
"default_field": "title",
"query": "破解"
}
},
"aggs": {
"my results": {
"histogram": {
"script": "doc['post_date'].value.year",
"interval": 1
}
}
}
}
4.3.16 IP Range Aggregation
符号: ip_range
4.3.17 Missing Aggregation
符号: missing
4.3.18 Nested Aggregation
符号:
4.3.19 Parent Aggregation
符号:
4.3.20 Range Aggregation
符号: range
参数:
ranges
GET /_search
{
"aggs" : {
"price_ranges" : {
"range" : {
"field" : "price",
"ranges" : [
{ "to" : 100.0 },
{ "from" : 100.0, "to" : 200.0 },
{ "from" : 200.0 }
]
}
}
}
}
4.3.21 Rare Terms Aggregation
稀有条款汇总
符号: rare_terms
4.3.22 Reverse nested Aggregation
符号: reverse_nested
4.3.23 Sampler Aggregation
4.3.24 Significant Terms Aggregation
重要术语汇总
符号: significant_terms
能帮助用户获取跟指定查询高度相关的词项(集), 意义在于不仅能从查询返回结果中提取与查询最相关的一组词项, 并且能找出最相关的那个词项。significant_terms 聚合计算的目标不能是基于浮点数的字段, 可使用基于 long 或 integer 类型的字段。
// GET blog/_search/
{
"query": {
"match": {
"content": "破解"
}
},
"aggs": {
"descripton": {
"significant_terms": {
"field": "title"
}
}
}
}
注意: 已分词字段的聚合非常耗费内存, 因为需要把所有词项加载到内存。
额外的配置:
- 控制返回 bucket 数量
- 后台数据集过滤
- 最小文档数量
- 执行模式
4.3.25 Significant Text Aggregation
重要的文字汇整
符号: significant_text
4.3.26 Terms Aggregation
符号: terms
参数:
min_doc_count
4.3.27 Subtleties of bucketing range Aggregation
符号:
4.4 Pipeline 聚合查询
Pipeline Aggregation 工作在其他聚合而不是文档集的基础上, 输入聚合通过 buckets_path 参数来定义, 并遵循下面的特定格式:
AGG_SEPARATOR = `>` ;
METRIC_SEPARATOR = `.` ;
AGG_NAME = <the name of the aggregation> ;
METRIC = <the name of the metric (in case of multi-value metrics aggregation)> ;
MULTIBUCKET_KEY = `[<KEY_NAME>]`
PATH = <AGG_NAME><MULTIBUCKET_KEY>? (<AGG_SEPARATOR>, <AGG_NAME> )* ( <METRIC_SEPARATOR>, <METRIC> ) ;
buckets_path 还可以使用特殊的 _count 路径来替代 metric
可以分为两类:
- Parent
- Sibling
4.4.1 Avg bucket Aggregation
符号: avg_bucket
4.4.2 Derivative Aggregation
导数/衍生聚合
符号: derivative
参数:
buckets_path
gap_policy
format
4.4.3 Max Bucket Aggregation
符号: max_bucket
参数: 同上
4.4.4 Min Bucket Aggregation
符号: min_bucket
参数: 同上
4.4.5 Sum Bucket Aggregation
符号: sum_bucket
参数: 同上
4.4.6 Stats Bucket Aggregation
符号: stats_bucket
参数: 同上
4.4.7 Extended Stats Bucket Aggregation
符号: extended_stats_bucket
参数: 同上 + sigma
4.4.8 Percentiles Bucket Aggregation
符号: percentiles_bucket
参数: 同上
4.4.9 Moving Average Aggregation
符号: moving_avg
参数:
buckets_path
model simple|linear|ewma|holt|holt_winters
gap_policy
window
minimize
settings
4.4.10 Moving Function Aggregation
符号: moving_fn
参数:
buckets_path
window
script
shift
"moving_fn": {
"buckets_path": "the_sum",
"window": 10,
"script": "MovingFunctions.unweightedAvg(values)"
}
内建函数有:
max(), min(), sum(), stdDev(), unweightedAvg(), linearWeightedAvg(), ewma(), holt(), holtWinters()
4.4.11 Cumulative Sum Aggregation
符号: cumulative_sum
参数:
buckets_path
format
4.4.12 Cumulative Cardinality Aggregation
符号: cumulative_cardinality
参数: 同上
4.4.13 Bucket Script Aggregation
符号: bucket_script
参数:
script
buckets_path
gap_policy
format
4.4.14 Bucket Selector Aggregation
符号: bucket_selector
参数:
script
buckets_path
gap_policy
4.4.15 Bucket Sort Aggregation
符号: bucket_sort
参数:
sort
from
size
gap_policy
4.4.16 Serial Differencing Aggregation
符号: serial_diff
参数:
buckets_path
lag
gap_policy
format
4.5 Matrix 聚合查询
4.5.1 Matrix Stats
符号: matrix_stats
参数:
count
mean
variance
skewness
kurtosis
covariance
correlation
4.6 Caching heavy aggregations
5. DSL 查询
(DSL, Domain Specific Language) 可以分为两大类型:
- Leaf query clauses
- Compound query clauses
5.1 查询和过滤上下文
5.1.1 relevance score
relevance score 是一个相对的浮点数, 返回到 _score 字段
5.1.2 Query context
5.1.3 Filter context
5.2 复合查询
5.2.1 bool query
must 必需满足
should 期望满足
must_not 必需不满足, 被视为过滤条件
filter
range 范围(gte, lte....)
5.2.2 boosting query
返回与肯定查询匹配的文档, 但减少与否定查询匹配的文档的分数。
positive
negative
negative_boost
5.2.3 constant_score query
一个查询, 它包装另一个查询, 但是在过滤器上下文中执行它。 所有匹配的文档都使用相同的“常量” _score。
5.2.4 dis_max query
一个查询, 它接受多个查询, 并返回与任何查询子句匹配的任何文档。 当布尔查询合并所有匹配查询的分数时, dis_max查询使用单个最佳匹配查询子句的分数。
queries
tie_breaker
5.2.5 function_score query
使用函数修改主查询返回的分数, 以考虑诸如受欢迎程度, 新近度, 距离或使用脚本实现的自定义算法等因素。
multiply
sum
avg
first
max
min
提供几种类型的计分功能:
script_score
weight
random_score
field_value_factor
decay function: gauss, linear, exp
5.3 Full text query
5.3.1 intervals query
可以对匹配项的顺序和接近度进行细粒度控制
TOP参数:
match
query 必须
max_gaps
ordered
analyzer
filter
use_field
prefix
prefix 必须
analyzer
use_field
wildcard
pattern 必须
analyzer
use_field
all_of
intervals 必须,An array of rules to combine
max_gaps
ordered
filter
any_of
intervals 必须
filter
filter
after
before
contained_by
containing
not_contained_by
not_containing
not_overlapping
overlapping
script
5.3.2 match query
用于执行全文查询的标准查询, 包括模糊匹配和短语或接近查询
5.3.3 match_bool_prefix query
创建一个布尔查询, 将与每个词匹配的词查询作为词查询, 但最后一个词除外, 后者作为前缀查询匹配
5.3.4 match_phrase query
类似于匹配查询, 但用于匹配精确短语或单词接近匹配
5.3.5 match_phrase_prefix query
类似于match_phrase查询, 但是对最后一个单词进行通配符搜索
5.3.6 multi_match query
匹配查询的多字段版本
5.3.7 common_terms query
一个更专业的查询, 它对不常见的单词给予更多的偏爱
5.3.8 query_string query
支持紧凑的Lucene查询字符串语法, 允许您在单个查询字符串中指定AND | OR | NOT条件和多字段搜索。 仅限于专业用户
5.3.9 simple_query_string query
适用于直接向用户公开的query_string语法的更简单
5.4 indices 与 bulk (批量索引与块)
- 审核安全设置
- 远程恢复设置
- 高级远程恢复设置
- 索引生命周期管理设置
- 许可证设置
- 机器学习
默认允许, 使用 SSE4.2结构, 因此仅当CPU 支持 SSE4.2。如果要运行 jobs, 集群中必须至少有一个机器学习节点。 - 监控设置
要调整监视数据在监视UI中的显示方式, 请在kibana.yml中配置xpack.monitoring设置。要控制如何从Logstash收集监视数据, 请在logstash.yml中配置xpack.monitoring设置。 - X-Pack 监控 TLS/SSL 设置
- PKCS#12 文件
- PKCS#11令牌
- 安全设置
